
الذكاء الاصطناعي في تحسين محركات البحث: كيفية التغلب على التحديات القانونية وضمان الامتثال
نشرت: 2023-09-26من المتوقع أن يصبح الذكاء الاصطناعي (AI) أداة حيوية للعلامات التجارية التي تسعى إلى تعزيز تواجدها عبر الإنترنت.
ومع ذلك، فإن دمج الذكاء الاصطناعي في استراتيجيات التسويق يؤدي حتماً إلى خلق اعتبارات قانونية ولوائح جديدة يجب على الوكالات التعامل معها بعناية.
في هذه المقالة سوف تكتشف:
- كيف يمكن للشركات وكبار المسئولين الاقتصاديين ووكالات الإعلام تقليل المخاطر القانونية لتنفيذ الاستراتيجيات المعززة بالذكاء الاصطناعي.
- أدوات مفيدة لتقليل تحيز الذكاء الاصطناعي وعملية سهلة لمراجعة جودة المحتوى الناتج عن الذكاء الاصطناعي.
- كيف يمكن للوكالات التغلب على تحديات تنفيذ الذكاء الاصطناعي الرئيسية لضمان الكفاءة والامتثال لعملائها.
اعتبارات الامتثال القانوني
الملكية الفكرية وحقوق النشر
أحد الاهتمامات القانونية الحاسمة عند استخدام الذكاء الاصطناعي في تحسين محركات البحث والوسائط هو اتباع قوانين الملكية الفكرية وحقوق النشر.
غالبًا ما تقوم أنظمة الذكاء الاصطناعي بجمع وتحليل كميات هائلة من البيانات، بما في ذلك المواد المحمية بحقوق الطبع والنشر.
توجد بالفعل دعاوى قضائية متعددة ضد OpenAI بسبب انتهاكات حقوق الطبع والنشر والخصوصية.
تواجه الشركة دعاوى قضائية تزعم الاستخدام غير المصرح به للكتب المحمية بحقوق الطبع والنشر لتدريب ChatGPT وجمع المعلومات الشخصية بشكل غير قانوني من مستخدمي الإنترنت باستخدام نماذج التعلم الآلي الخاصة بهم.
كما تسببت المخاوف المتعلقة بالخصوصية بشأن معالجة OpenAI وحفظ بيانات المستخدم في قيام إيطاليا بحظر استخدام ChatGPT بالكامل في نهاية مارس.
تم رفع الحظر الآن بعد أن أجرت الشركة تغييرات لزيادة الشفافية في معالجة بيانات مستخدم chatbot وإضافة خيار لإلغاء الاشتراك في محادثات ChatGPT المستخدمة لخوارزميات التدريب.
ومع ذلك، مع إطلاق GTBot، زاحف OpenAI، من المرجح أن تنشأ اعتبارات قانونية أخرى.
لتجنب المشكلات القانونية المحتملة وادعاءات الانتهاك، يجب على الوكالات التأكد من تدريب أي نماذج للذكاء الاصطناعي على مصادر البيانات المعتمدة واحترام قيود حقوق الطبع والنشر:
- التأكد من الحصول على البيانات بشكل قانوني وأن الوكالة لديها الحقوق المناسبة لاستخدامها.
- قم بتصفية البيانات التي لا تحتوي على الأذونات القانونية المطلوبة أو ذات الجودة الرديئة.
- قم بإجراء عمليات تدقيق منتظمة للبيانات ونماذج الذكاء الاصطناعي للتأكد من امتثالها لحقوق وقوانين استخدام البيانات.
- إجراء استشارة قانونية حول حقوق البيانات والخصوصية لضمان عدم تعارضها مع السياسات القانونية.
من المحتمل أن تحتاج الفرق القانونية للوكالة والعملاء إلى المشاركة في المناقشات المذكورة أعلاه قبل أن يتم دمج نماذج الذكاء الاصطناعي في مسارات العمل والمشاريع.
خصوصية البيانات وحمايتها
تعتمد تقنيات الذكاء الاصطناعي بشكل كبير على البيانات، والتي قد تتضمن معلومات شخصية حساسة.
يجب أن يتوافق جمع بيانات المستخدم وتخزينها ومعالجتها مع قوانين الخصوصية ذات الصلة، مثل اللائحة العامة لحماية البيانات (GDPR) في الاتحاد الأوروبي.
علاوة على ذلك، يؤكد قانون الذكاء الاصطناعي للاتحاد الأوروبي الذي تم طرحه مؤخرًا على معالجة المخاوف المتعلقة بخصوصية البيانات المرتبطة بأنظمة الذكاء الاصطناعي.
وهذا لا يخلو من الجدارة. قامت الشركات الكبيرة، مثل Samsung، بحظر الذكاء الاصطناعي تمامًا بسبب الكشف عن البيانات السرية التي تم تحميلها على ChatGPT.
لذلك، إذا كانت الوكالات تستخدم بيانات العملاء جنبًا إلى جنب مع تقنية الذكاء الاصطناعي، فيجب عليها:
- إعطاء الأولوية للشفافية في جمع البيانات.
- الحصول على موافقة المستخدم.
- تنفيذ تدابير أمنية قوية لحماية المعلومات الحساسة.
في هذه الحالات، يمكن للوكالات إعطاء الأولوية للشفافية في جمع البيانات من خلال إبلاغ المستخدمين بوضوح بالبيانات التي سيتم جمعها، وكيف سيتم استخدامها، ومن سيكون لديه حق الوصول إليها.
للحصول على موافقة المستخدم، تأكد من أن الموافقة مستنيرة ومُعطاة بحرية من خلال نماذج موافقة واضحة وسهلة الفهم تشرح الغرض من جمع البيانات وفوائده.
بالإضافة إلى ذلك، تشمل التدابير الأمنية القوية ما يلي:
- تشفير البيانات.
- صلاحية التحكم صلاحية الدخول.
- إخفاء هوية البيانات (حيثما أمكن ذلك).
- عمليات التدقيق والتحديثات المنتظمة.
على سبيل المثال، تتوافق سياسات OpenAI مع الحاجة إلى خصوصية البيانات وحمايتها والتركيز على تعزيز الشفافية وموافقة المستخدم وأمن البيانات في تطبيقات الذكاء الاصطناعي.
الإنصاف والتحيز
تتمتع خوارزميات الذكاء الاصطناعي المستخدمة في تحسين محركات البحث والوسائط بالقدرة على إدامة التحيزات أو التمييز ضد أفراد أو مجموعات معينة عن غير قصد.
يجب أن تكون الوكالات استباقية في تحديد وتخفيف التحيز الخوارزمي. وهذا مهم بشكل خاص بموجب قانون الاتحاد الأوروبي الجديد بشأن الذكاء الاصطناعي، والذي يحظر على أنظمة الذكاء الاصطناعي التأثير بشكل غير عادل على السلوك البشري أو عرض السلوك التمييزي.
وللتخفيف من هذه المخاطر، يجب على الوكالات التأكد من إدراج بيانات ووجهات نظر متنوعة في تصميم نماذج الذكاء الاصطناعي ومراقبة النتائج باستمرار بحثًا عن التحيز والتمييز المحتملين.
إحدى الطرق لتحقيق ذلك هي استخدام الأدوات التي تساعد على تقليل التحيز، مثل AI Fairness 360، وIBM Watson Studio، وأداة What-If من Google.
محتوى كاذب أو مضلل
يمكن لأدوات الذكاء الاصطناعي، بما في ذلك ChatGPT، إنشاء محتوى اصطناعي قد يكون غير دقيق أو مضللًا أو مزيفًا.
على سبيل المثال، غالبًا ما يقوم الذكاء الاصطناعي بإنشاء مراجعات مزيفة عبر الإنترنت للترويج لأماكن أو منتجات معينة. يمكن أن يؤدي هذا إلى عواقب سلبية على الشركات التي تعتمد على المحتوى الناتج عن الذكاء الاصطناعي.
يعد تنفيذ سياسات وإجراءات واضحة لمراجعة المحتوى الناتج عن الذكاء الاصطناعي قبل النشر أمرًا بالغ الأهمية لمنع هذا الخطر.
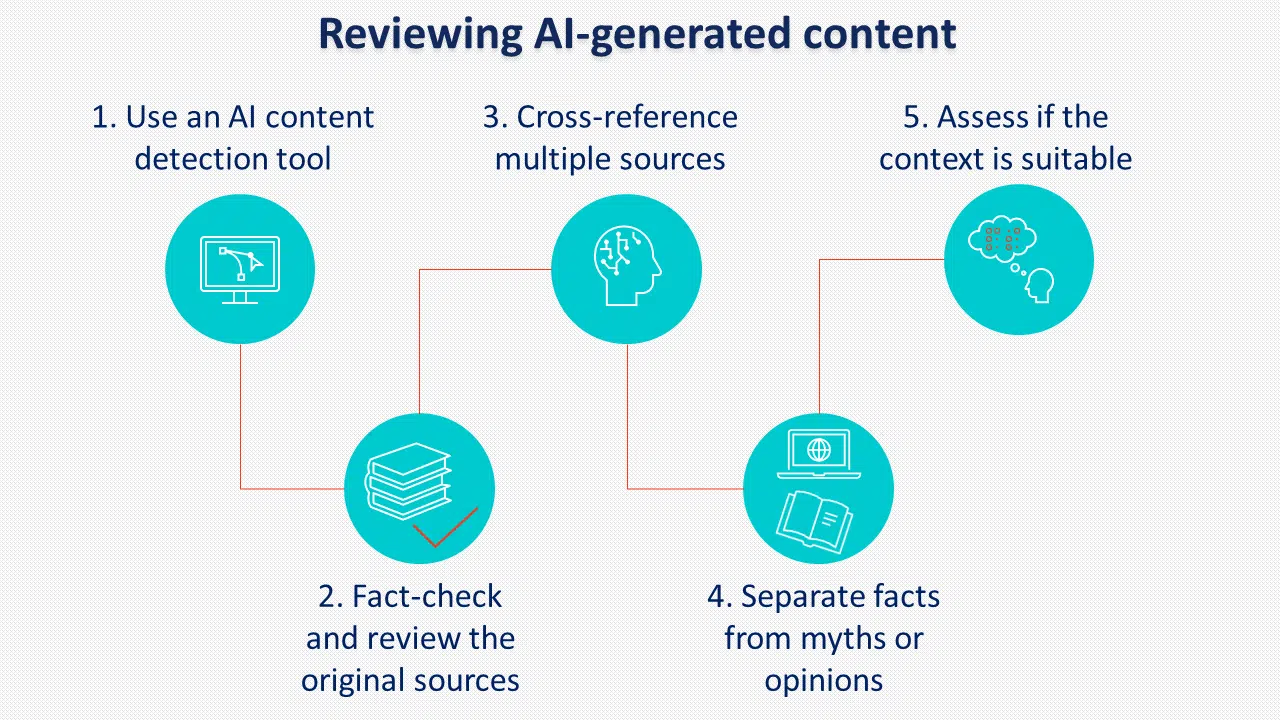
هناك ممارسة أخرى يجب مراعاتها وهي تصنيف المحتوى الذي تم إنشاؤه بواسطة الذكاء الاصطناعي. على الرغم من أن جوجل لا يبدو أنها تنفذ ذلك، فإن العديد من صناع السياسات يدعمون تصنيف الذكاء الاصطناعي.
المسؤولية والمساءلة
مع ازدياد تعقيد أنظمة الذكاء الاصطناعي، تنشأ أسئلة حول المسؤولية.
يجب أن تكون الوكالات التي تستخدم الذكاء الاصطناعي مستعدة لتحمل المسؤولية عن أي عواقب غير مقصودة تنتج عن استخدامه، بما في ذلك:
- التحيز والتمييز عند استخدام الذكاء الاصطناعي لفرز المرشحين للتوظيف.
- إمكانية إساءة استخدام قوة الذكاء الاصطناعي لأغراض ضارة مثل الهجمات الإلكترونية.
- فقدان الخصوصية إذا تم جمع المعلومات دون موافقة.
يقدم قانون الاتحاد الأوروبي للذكاء الاصطناعي أحكامًا جديدة بشأن أنظمة الذكاء الاصطناعي عالية المخاطر التي يمكن أن تؤثر بشكل كبير على حقوق المستخدمين، مع تسليط الضوء على سبب وجوب امتثال الوكالات والعملاء للشروط والسياسات ذات الصلة عند استخدام تقنيات الذكاء الاصطناعي.
تتعلق بعض شروط وسياسات OpenAI الأكثر أهمية بالمحتوى الذي يقدمه المستخدم ودقة الردود ومعالجة البيانات الشخصية.
تنص سياسة المحتوى على أن OpenAI تقوم بتعيين حقوق المحتوى الذي تم إنشاؤه للمستخدم. كما تحدد أيضًا أنه يمكن استخدام المحتوى الذي تم إنشاؤه لأي غرض، بما في ذلك الأغراض التجارية، بشرط أن يتوافق مع القيود القانونية.

ومع ذلك، فإنه ينص أيضًا على أن المخرجات قد لا تكون فريدة أو دقيقة تمامًا، مما يعني أنه يجب دائمًا مراجعة المحتوى الذي يتم إنشاؤه بواسطة الذكاء الاصطناعي بدقة قبل الاستخدام.
فيما يتعلق بالبيانات الشخصية، تقوم OpenAI بجمع جميع المعلومات التي يدخلها المستخدمون، بما في ذلك تحميل الملفات.
عند استخدام الخدمة لمعالجة البيانات الشخصية، يجب على المستخدمين تقديم إشعارات خصوصية كافية قانونيًا وملء نموذج لطلب معالجة البيانات.
يجب على الوكالات معالجة مشكلات المساءلة بشكل استباقي، ومراقبة مخرجات الذكاء الاصطناعي، وتنفيذ تدابير قوية لمراقبة الجودة للتخفيف من المسؤوليات القانونية المحتملة.
احصل على النشرة الإخبارية اليومية التي يعتمد عليها مسوقو البحث.
انظر الشروط.
تحديات تنفيذ الذكاء الاصطناعي للوكالات
منذ أن أطلقت OpenAI ChatGPT العام الماضي، كانت هناك العديد من المحادثات حول كيفية تغيير الذكاء الاصطناعي المنتج لتحسين محركات البحث كمهنة وتأثيره العام على صناعة الإعلام.
على الرغم من أن التغييرات تأتي مع مزيج من التحسينات على عبء العمل اليومي، إلا أن هناك بعض التحديات التي يجب على الوكالات مراعاتها عند تطبيق الذكاء الاصطناعي في استراتيجيات العميل.
التعليم والتوعية
قد يفتقر العديد من العملاء إلى الفهم الشامل للذكاء الاصطناعي وآثاره.
ولذلك، تواجه الوكالات التحدي المتمثل في تثقيف العملاء حول الفوائد والمخاطر المحتملة المرتبطة بتنفيذ الذكاء الاصطناعي.
يتطلب المشهد التنظيمي المتطور التواصل الواضح مع العملاء فيما يتعلق بالتدابير المتخذة لضمان الامتثال القانوني.
ولتحقيق ذلك، يجب على الوكالات:
- لديهم فهم واضح لأهداف عملائهم.
- تكون قادرة على شرح الفوائد.
- إظهار الخبرة في تنفيذ الذكاء الاصطناعي.
- معالجة التحديات والمخاطر.
تتمثل إحدى طرق القيام بذلك في الحصول على صحيفة حقائق لمشاركتها مع العملاء تحتوي على جميع المعلومات الضرورية، وإذا أمكن، تقديم دراسات حالة أو أمثلة أخرى حول كيفية الاستفادة من استخدام الذكاء الاصطناعي.
تخصيص الموارد
يتطلب دمج الذكاء الاصطناعي في استراتيجيات تحسين محركات البحث والإعلام موارد كبيرة، بما في ذلك الاستثمارات المالية والموظفين المهرة وتحديث البنية التحتية.
يجب على الوكالات تقييم احتياجات عملائها وقدراتهم بعناية لتحديد مدى جدوى تنفيذ حلول الذكاء الاصطناعي في حدود قيود ميزانيتها، حيث قد تحتاج إلى متخصصين في الذكاء الاصطناعي، ومحللي بيانات، ومُحسني محركات البحث (SEO)، ومتخصصين في المحتوى يمكنهم التعاون معًا بشكل فعال.
قد تشمل احتياجات البنية التحتية أدوات الذكاء الاصطناعي ومعالجة البيانات ومنصات التحليلات لاستخراج الأفكار. يعتمد تقديم الخدمات أو تسهيل الموارد الخارجية على القدرات والميزانية الحالية لكل وكالة.
قد يؤدي الاستعانة بمصادر خارجية لوكالات أخرى إلى تنفيذ أسرع، بينما قد يكون الاستثمار في قدرات الذكاء الاصطناعي الداخلية أفضل للتحكم في الخدمات المقدمة وتخصيصها على المدى الطويل.
الخبرات التقنية
يتطلب تنفيذ الذكاء الاصطناعي معرفة وخبرة تقنية متخصصة.
قد تحتاج الوكالات إلى توظيف فرقها أو تحسين مهاراتها لتطوير أنظمة الذكاء الاصطناعي ونشرها وإدارتها بشكل فعال بما يتماشى مع المتطلبات التنظيمية الجديدة.
لتحقيق أقصى استفادة من الذكاء الاصطناعي، يجب أن يتمتع أعضاء الفريق بما يلي:
- معرفة جيدة بالبرمجة.
- معالجة البيانات والمهارات التحليلية لإدارة كميات كبيرة من البيانات.
- المعرفة العملية للتعلم الآلي.
- مهارات ممتازة في حل المشكلات.
الاعتبارات الاخلاقية
يجب على الوكالات أن تأخذ في الاعتبار الآثار الأخلاقية لاستخدام الذكاء الاصطناعي بالنسبة لعملائها.
وينبغي إنشاء أطر ومبادئ توجيهية أخلاقية لضمان ممارسات مسؤولة للذكاء الاصطناعي طوال العملية، ومعالجة المخاوف التي أثيرت في اللوائح المحدثة.
وتشمل هذه:
- الشفافية والإفصاح والمساءلة عند استخدام الذكاء الاصطناعي.
- احترام خصوصية المستخدم والملكية الفكرية.
- الحصول على موافقة العميل لاستخدام الذكاء الاصطناعي.
- السيطرة البشرية على الذكاء الاصطناعي مع الالتزام المستمر بالتحسين والتكيف مع تقنيات الذكاء الاصطناعي الناشئة.
مسائل المساءلة: مواجهة التحديات القانونية لتنفيذ الذكاء الاصطناعي
بينما يقدم الذكاء الاصطناعي فرصًا مثيرة لتحسين ممارسات تحسين محركات البحث والإعلام، يجب على الوكالات التغلب على التحديات القانونية والالتزام باللوائح المحدثة المرتبطة بتنفيذه.
يمكن للشركات والوكالات تقليل المخاطر القانونية من خلال:
- التأكد من أن البيانات قد تم الحصول عليها بشكل قانوني وأن الوكالة لديها الحقوق المناسبة لاستخدامها.
- تصفية البيانات التي لا تحتوي على الأذونات القانونية المطلوبة أو ذات الجودة الرديئة.
- إجراء عمليات تدقيق للبيانات ونماذج الذكاء الاصطناعي للتأكد من امتثالها لحقوق وقوانين استخدام البيانات.
- إجراء استشارة قانونية حول حقوق البيانات والخصوصية لضمان عدم تعارضها مع السياسات القانونية.
- إعطاء الأولوية للشفافية في جمع البيانات والحصول على موافقة المستخدم من خلال نماذج موافقة واضحة وسهلة الفهم.
- استخدام الأدوات التي تساعد على تقليل التحيز، مثل AI Fairness 360، وIBM Watson Studio، وأداة What-If من Google.
- تنفيذ سياسات وإجراءات واضحة لمراجعة جودة المحتوى الناتج عن الذكاء الاصطناعي قبل النشر.
الآراء الواردة في هذه المقالة هي آراء المؤلف الضيف وليست بالضرورة Search Engine Land. يتم سرد المؤلفين الموظفين هنا.