
أباتشي سبارك: نجم لامع في سماء البيانات الضخمة.
نشرت: 2015-09-24- التوصية بملايين المنتجات للعملاء المناسبين.
- تتبع سجل البحث وتقديم أسعار مخفضة لرحلات الطيران.
- مقارنة المهارات الفنية للشخص واقتراح الأشخاص بشكل مناسب للتواصل معهم في مجال عملك.
- فهم الأنماط في مليارات الكائنات المحمولة وأبراج الشبكة ومعاملات المكالمات وحساب تحسينات شبكة الاتصالات أو إيجاد ثغرات في الشبكة.
- دراسة الملايين من ميزات أجهزة الاستشعار وتحليل الأعطال في شبكات الاستشعار.
البيانات الأساسية اللازمة لاستخدامها للحصول على النتائج الصحيحة لجميع المهام المذكورة أعلاه كبيرة نسبيًا. لا يمكن التعامل معها بكفاءة (من حيث المكان والزمان) بواسطة الأنظمة التقليدية.
هذه كلها سيناريوهات البيانات الضخمة.
لجمع وتخزين وإجراء عمليات حسابية على هذا النوع من البيانات الضخمة ، نحتاج إلى نظام حوسبة عنقودية متخصص. حل Apache Hadoop لنا هذه المشكلة.
يوفر نظام تخزين موزع (HDFS) ومنصة حوسبة متوازية (MapReduce).
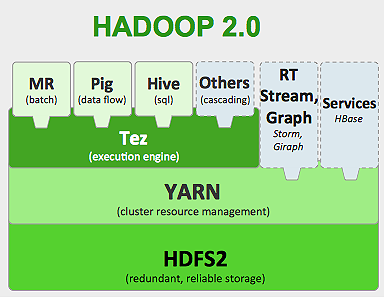
يعمل إطار Hadoop على النحو التالي:
- يكسر ملفات البيانات الكبيرة إلى أجزاء أصغر لتتم معالجتها بواسطة الأجهزة الفردية (تخزين التوزيع).
- يقسم المهام الأطول إلى مهام أصغر ليتم تنفيذها بطريقة متوازية (الحساب المتوازي).
- يعالج الفشل تلقائيًا.
حدود Hadoop
حصلت Hadoop على أدوات متخصصة في نظامها البيئي لأداء مهام مختلفة. لذلك ، إذا كنت ترغب في تشغيل دورة حياة شاملة لتطبيق ما ، فأنت بحاجة إلى استخدام أدوات متعددة. على سبيل المثال ، بالنسبة لاستعلامات SQL التي ستستخدمها ، خلية / خنزير ، لمصادر الدفق ، يجب عليك استخدام Hadoop المتدفق المدمج أو Apache Storm (والذي ليس جزءًا من نظام Hadoop البيئي) أو لخوارزميات التعلم الآلي ، يجب عليك استخدام Mahout . يعد دمج كل هذه الأنظمة معًا لبناء حالة استخدام واحدة لخط أنابيب البيانات مهمة كبيرة.
في وظيفة MapReduce ،
- يتم التخلص من جميع مخرجات مهام الخريطة على الأقراص المحلية (أو HDFS).
- يقوم Hadoop بدمج جميع ملفات الانسكاب في ملف أكبر يتم فرزها وتقسيمها وفقًا لعدد المخفضات.
- وتقليل المهام يجب تحميلها مرة أخرى في الذاكرة.
هذه العملية تجعل المهمة أبطأ مما يتسبب في إدخال / إخراج القرص والشبكة I / O. هذا أيضًا يجعل Mapreduce غير مناسب للمعالجة التكرارية حيث يتعين عليك تطبيق خوارزميات التعلم الآلي على نفس مجموعة البيانات مرارًا وتكرارًا.
أدخل عالم Apache Spark:
تم تطوير Apache Spark في جامعة كاليفورنيا في بيركلي AMPLAB في عام 2009 وفي عام 2010 أصبحت حتى الآن أكبر مشروع مفتوح المصدر ساهم به أباتشي.
يعد Apache Spark نظامًا أكثر عمومية ، حيث يمكنك تشغيل وظائف الدُفعات والمهام المتدفقة في وقت واحد. إنها تحل محل سابقتها MapReduce في السرعة عن طريق إضافة قدرات لمعالجة البيانات بشكل أسرع في الذاكرة. كما أنه أكثر كفاءة على القرص. تستفيد من معالجة الذاكرة باستخدام وحدة البيانات الأساسية الخاصة بها RDD (مجموعة البيانات الموزعة المرنة). هذه تحتوي على أكبر قدر ممكن من مجموعات البيانات في الذاكرة لدورة حياة كاملة للمهمة وبالتالي الحفظ على القرص I / O. يمكن أن تتسرب بعض البيانات عبر القرص بعد الحدود العليا للذاكرة.
يظهر الرسم البياني أدناه وقت التشغيل بالثواني لكل من Apache Hadoop و Spark لحساب الانحدار اللوجستي. استغرق Hadoop 110 ثانية بينما أنهى شرارة نفس الوظيفة في 0.9 ثانية فقط.
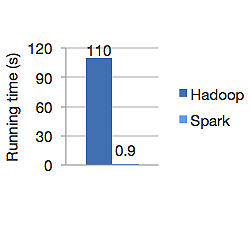
لا يقوم Spark بتخزين جميع البيانات في الذاكرة. ولكن إذا كانت البيانات في الذاكرة ، فإنها تحقق أفضل استخدام لذاكرة التخزين المؤقت LRU لمعالجتها بشكل أسرع. إنه أسرع 100 مرة أثناء حساب البيانات في الذاكرة ولا يزال أسرع على القرص من Hadoop.
يضمن نموذج تخزين البيانات الموزعة من Spark ، ومجموعات البيانات الموزعة المرنة (RDD) ، التسامح مع الخطأ والذي بدوره يقلل من إدخال / إخراج الشبكة. ورقة شرارة تقول:

"تحقق RDDs التسامح مع الخطأ من خلال فكرة النسب: في حالة فقد قسم من RDD ، فإن RDD لديه معلومات كافية حول كيفية اشتقاقه من RDDs الأخرى حتى يتمكن من إعادة بناء هذا القسم فقط."
لذلك لا تحتاج إلى نسخ البيانات لتحقيق التسامح مع الخطأ.
في Spark MapReduce ، يتم الاحتفاظ بإخراج رسامي الخرائط في ذاكرة التخزين المؤقت لنظام التشغيل OS وتسحبه المخفضات إلى جانبهم وتكتبه مباشرة إلى ذاكرتهم ، على عكس Hadoop حيث يتم سكب المخرجات على القرص وقراءتها مرة أخرى.
تجعل ذاكرة Spark في ذاكرة التخزين المؤقت مناسبة لخوارزميات التعلم الآلي حيث تحتاج إلى استخدام نفس البيانات مرارًا وتكرارًا. يمكن لـ Spark تشغيل وظائف معقدة ، وخطوط بيانات متعددة الخطوات باستخدام الرسم البياني المباشر المباشر (DAGs).
Spark مكتوب بلغة Scala ويعمل على JVM (Java Virtual Machine). تقدم Spark واجهات برمجة تطبيقات تطوير للغات Java و Scala و Python و R. تعمل Spark على Hadoop YARN و Apache Mesos بالإضافة إلى أن لديها مدير مجموعة مستقل خاص بها.
في عام 2014 ، حصلت على المركز الأول في الرقم القياسي العالمي لفرز بيانات 100 تيرابايت (1 تريليون سجل) في 23 دقيقة فقط ، حيث كان الرقم القياسي السابق لـ Hadoop بواسطة Yahoo حوالي 72 دقيقة. هذا يثبت أن شرارة البيانات المصنفة أسرع 3 مرات وبأجهزة أقل 10 مرات. حدث كل الفرز على القرص (HDFS) ، دون استخدام قدرة التخزين المؤقت في الذاكرة الشرارة.
نظام سبارك البيئي
يهدف Spark إلى إجراء تحليلات متقدمة دفعة واحدة ، لتحقيق أنه يوفر المكونات التالية:
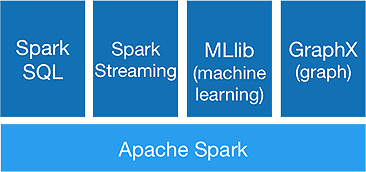
1. شرارة كور:
Spark core API هو أساس إطار عمل Apache Spark ، والذي يتعامل مع جدولة الوظائف وتوزيع المهام وإدارة الذاكرة وعمليات الإدخال / الإخراج والتعافي من حالات الفشل. تسمى وحدة البيانات المنطقية الرئيسية في شرارة RDD (مجموعة البيانات الموزعة المرنة) ، والتي تخزن البيانات بطريقة موزعة لتتم معالجتها بالتوازي لاحقًا. يحسب العمليات بتكاسل. لذلك ، لا يلزم شغل الذاكرة طوال الوقت ، ويمكن لوظائف أخرى الاستفادة منها.
2-سبارك SQL:
يوفر إمكانات استعلام تفاعلية مع زمن انتقال منخفض. يمكن لواجهة برمجة تطبيقات DataFrame الجديدة الاحتفاظ بكل من البيانات المنظمة وشبه المنظمة والسماح لجميع عمليات ووظائف SQL بالقيام بالحسابات.
3-شرارة الجري:
إنه يوفر واجهات برمجة التطبيقات المتدفقة في الوقت الفعلي ، والتي تجمع البيانات وتعالجها على دفعات صغيرة.
يستخدم Dstreams وهو ليس سوى تسلسل مستمر من RDDs ، لحساب منطق الأعمال على البيانات الواردة وتوليد النتائج على الفور.
4-ملليب :
إنها مكتبة سبارك للتعلم الآلي (ما يقرب من 9 مرات أسرع من Mahout) والتي توفر التعلم الآلي بالإضافة إلى الخوارزميات الإحصائية مثل التصنيف والانحدار والتصفية التعاونية وما إلى ذلك.
5.GraphX :
توفر واجهة برمجة تطبيقات GraphX إمكانات للتعامل مع الرسوم البيانية وإجراء العمليات الحسابية الموازية للرسم البياني. يتضمن خوارزميات الرسم البياني مثل PageRank ووظائف مختلفة لتحليل الرسوم البيانية.
هل ستعلن سبارك نهاية Hadoop Era؟
لا يزال Spark نظامًا شابًا ، ولم ينضج مثل Hadoop. لا توجد أداة لـ NOSQL مثل HBase. بالنظر إلى متطلبات الذاكرة العالية لمعالجة البيانات بشكل أسرع ، لا يمكنك حقًا القول أنها تعمل على أجهزة سلعة. لا تملك Spark نظام التخزين الخاص بها. وهي تعتمد على HDFS لذلك.
لذلك ، لا يزال Hadoop MapReduce جيدًا لبعض الوظائف المجمعة ، والتي لا تتضمن الكثير من خطوط أنابيب البيانات.
"التكنولوجيا الجديدة لا تحل محل القديمة تمامًا ؛ كلاهما يفضل التعايش ".
خاتمة
في هذه المدونة ، نظرنا في سبب حاجتك إلى أداة مثل Spark ، وما الذي يجعلها أسرع في نظام الحوسبة العنقودية ومكوناتها الأساسية. الجزء التالي سوف نتعمق أكثر في Spark core API RDDs والتحويلات والإجراءات.