
هل يمكن لمحركات البحث اكتشاف محتوى الذكاء الاصطناعي؟
نشرت: 2023-08-04أثر انفجار أدوات الذكاء الاصطناعي في العام الماضي بشكل كبير على المسوقين الرقميين ، وخاصة أولئك الذين يعملون في تحسين محركات البحث.
نظرًا لطبيعة إنشاء المحتوى التي تستغرق وقتًا طويلاً والمكلفة ، فقد لجأ المسوقون إلى الذكاء الاصطناعي للحصول على المساعدة ، مما أدى إلى نتائج مختلطة
على الرغم من المشكلات الأخلاقية ، فإن أحد الأسئلة التي تطرأ مرارًا وتكرارًا هو ، "هل يمكن لمحركات البحث اكتشاف محتوى الذكاء الاصطناعي الخاص بي؟"
يعتبر السؤال مهمًا بشكل خاص لأنه إذا كانت الإجابة "لا" ، فإنه يبطل العديد من الأسئلة الأخرى حول ما إذا كان ينبغي استخدام الذكاء الاصطناعي وكيفية استخدامه.
تاريخ طويل من المحتوى الذي تم إنشاؤه آليًا
على الرغم من أن تكرار إنشاء المحتوى الذي يتم إنشاؤه بواسطة الآلة أو بمساعدة غير مسبوق ، إلا أنه ليس جديدًا تمامًا وليس دائمًا سلبيًا.
تعتبر القصص العاجلة أولاً أمرًا ضروريًا لمواقع الأخبار ، وقد استخدموا البيانات من مصادر مختلفة ، مثل أسواق الأسهم ومقاييس الزلازل ، لتسريع إنشاء المحتوى.
على سبيل المثال ، من الصحيح فعليًا نشر مقالة روبوت تقول:
- "تم الكشف عن زلزال [بقوة] في [موقع ، مدينة] في [الوقت] / [التاريخ] هذا الصباح ، وهو أول زلزال منذ [تاريخ آخر حدث]. المزيد من الأخبار لمتابعة ".
تحديثات مثل هذه مفيدة أيضًا للقارئ النهائي الذي يحتاج إلى الحصول على هذه المعلومات في أسرع وقت ممكن.
في الطرف الآخر من الطيف ، رأينا العديد من تطبيقات "القبعة السوداء" للمحتوى الذي تم إنشاؤه آليًا.
أدانت Google استخدام سلاسل Markov لإنشاء نص لمحتوى منخفض الجهد يدور لسنوات عديدة ، تحت شعار "الصفحات التي تم إنشاؤها تلقائيًا والتي لا تقدم أي قيمة مضافة".
الأمر المثير للاهتمام بشكل خاص ، والذي غالبًا ما يمثل نقطة ارتباك أو منطقة رمادية بالنسبة للبعض ، هو معنى "لا قيمة مضافة".
كيف يمكن أن تضيف LLM قيمة؟
ارتفعت شعبية محتوى الذكاء الاصطناعي بسبب الاهتمام الذي حظيت به نماذج اللغات الكبيرة (LLM) وروبوت الدردشة المدعم بالذكاء الاصطناعي ChatGPT ، مما أدى إلى تحسين تفاعل المحادثة.
بدون الخوض في التفاصيل الفنية ، هناك بضع نقاط مهمة يجب مراعاتها حول هذه الأدوات:
النص الذي تم إنشاؤه يعتمد على توزيع احتمالي
- على سبيل المثال ، إذا كتبت ، "أن تكون مُحسِّن محركات بحث أمر ممتع لأن ..." ، فإن LLM تبحث في جميع الرموز وتحاول حساب الكلمة التالية الأكثر احتمالًا بناءً على مجموعة التدريب الخاصة بها. على نطاق واسع ، يمكنك التفكير في الأمر على أنه نسخة متقدمة حقًا من النص التنبؤي لهاتفك.
ChatGPT هو نوع من الذكاء الاصطناعي التوليدي
- هذا يعني أن الإخراج لا يمكن التنبؤ به. يوجد عنصر عشوائي ، وقد يستجيب بشكل مختلف لنفس الموجه.
عندما تقدر هاتين النقطتين ، يصبح من الواضح أن أدوات مثل ChatGPT ليس لديها أي معرفة تقليدية أو "تعرف" أي شيء. هذا النقص هو أساس كل الأخطاء ، أو "الهلوسة" كما يطلق عليها.
توضح المخرجات العديدة الموثقة كيف يمكن لهذا الأسلوب أن يولد نتائج غير صحيحة ويتسبب في تعارض ChatGPT مع نفسه بشكل متكرر.
وهذا يثير شكوكًا جدية حول اتساق "القيمة المضافة" مع النص المكتوب بالذكاء الاصطناعي ، نظرًا لاحتمال تكرار الهلوسة.
يكمن السبب الأساسي في كيفية إنشاء LLM للنص ، والذي لن يتم حله بسهولة دون اتباع نهج جديد.
هذا اعتبار حيوي ، خاصة بالنسبة لموضوعات "أموالك ، حياتك" (YMYL) ، والتي يمكن أن تضر ماديًا بأموال الناس أو بحياتهم إذا كانت غير دقيقة.
تم القبض على منشورات رئيسية مثل Men's Health و CNET وهي تنشر معلومات غير صحيحة بشكل واقعي تم إنشاؤها بواسطة الذكاء الاصطناعي هذا العام ، مما يسلط الضوء على القلق.
الناشرون ليسوا وحدهم مع هذه المشكلة ، حيث واجهت Google صعوبة في كبح جماح محتوى تجربة البحث التوليد (SGE) بمحتوى YMYL.
على الرغم من تصريح Google بأنه سيكون حريصًا مع الإجابات التي تم إنشاؤها والذهاب إلى أبعد من ذلك لإعطاء مثال على وجه التحديد "لن تظهر إجابة على سؤال حول إعطاء طفل Tylenol لأنه موجود في المجال الطبي" ، فإن SGE ستفعل بشكل واضح هذا بمجرد طرح السؤال عليها.
احصل على النشرة الإخبارية اليومية التي يعتمد عليها المسوقون.
انظر الشروط.
جوجل SGE و MUM
من الواضح أن Google تعتقد أن هناك مكانًا للمحتوى الذي يتم إنشاؤه آليًا للإجابة على استفسارات المستخدمين. لقد ألمحت Google إلى هذا منذ مايو 2021 ، عندما أعلنت MUM ، نموذجها الموحد متعدد المهام.
كان أحد التحديات التي وضعت MUM لمعالجتها استنادًا إلى البيانات التي يصدرها الأشخاص ثمانية استفسارات في المتوسط للمهام المعقدة.
في الاستعلام الأولي ، سيتعلم الباحث بعض المعلومات الإضافية ، ويطالب بعمليات البحث ذات الصلة ويظهر صفحات ويب جديدة للإجابة على هذه الاستفسارات.
اقترحت Google: ماذا لو كان بإمكانهم أخذ الاستعلام الأولي ، وتوقع أسئلة متابعة المستخدم ، وإنشاء إجابة كاملة باستخدام معلومات الفهرس الخاصة بهم؟

إذا نجحت ، في حين أن هذا النهج قد يكون رائعًا للمستخدم ، فإنه يمحو بشكل أساسي العديد من استراتيجيات الكلمات الرئيسية "طويلة الذيل" أو ذات الحجم الصفري التي تعتمد عليها مُحسنات محركات البحث للحصول على موطئ قدم داخل SERPs.
بافتراض أن Google يمكنها تحديد الاستعلامات المناسبة للإجابات التي تم إنشاؤها بواسطة الذكاء الاصطناعي ، يمكن اعتبار العديد من الأسئلة "محلولة".
هذا يثير السؤال ...
- لماذا يُظهر محرك بحث Google للباحث صفحة الويب الخاصة بك بإجابة مُنشأة مسبقًا عندما يمكنه الاحتفاظ بالمستخدم داخل نظام البحث البيئي الخاص به وإنشاء الإجابة بأنفسهم؟
تمتلك Google حافزًا ماليًا لإبقاء المستخدمين في نظامها البيئي. لقد رأينا طرقًا مختلفة لتحقيق ذلك ، من المقتطفات المميزة إلى السماح للأشخاص بالبحث عن رحلات جوية في SERPs.
لنفترض أن Google تعتبر أن النص الذي تم إنشاؤه لا يقدم قيمة تفوق ما يمكن أن يقدمه بالفعل. في هذه الحالة ، يصبح الأمر ببساطة مسألة تكلفة مقابل فائدة لمحرك البحث.
هل يمكنهم توليد المزيد من الإيرادات على المدى الطويل من خلال استيعاب نفقات التوليد وجعل المستخدم ينتظر إجابة مقابل إرسال المستخدم بسرعة وبتكلفة زهيدة إلى صفحة يعلمون أنها موجودة بالفعل؟
الكشف عن محتوى الذكاء الاصطناعي
إلى جانب انتشار استخدام ChatGPT ، ظهرت العشرات من "أجهزة الكشف عن المحتوى بالذكاء الاصطناعي" والتي تتيح لك إدخال محتوى نصي وإخراج نسبة مئوية - وهذا هو المكان الذي تكمن فيه المشكلة.
على الرغم من وجود بعض الاختلاف في كيفية تسمية أجهزة الكشف المختلفة لدرجة النسبة المئوية هذه ، فإنها تعطي دائمًا نفس النتيجة تقريبًا: النسبة المئوية التيقن من أن النص المقدم بالكامل تم إنشاؤه بواسطة الذكاء الاصطناعي.
يؤدي هذا إلى الارتباك عند تسمية النسبة ، على سبيل المثال ، "75٪ AI / 25٪ بشري".
كثير من الناس يسيئون فهم هذا على أنه يعني أن "النص مكتوب بنسبة 75٪ بواسطة ذكاء اصطناعي و 25٪ بواسطة إنسان" ، عندما يعني ذلك ، "أنا متأكد بنسبة 75٪ أن الذكاء الاصطناعي كتب 100٪ من هذا النص."
أدى سوء الفهم هذا إلى تقديم بعض النصائح حول كيفية تعديل إدخال النص لجعله "يمر" بكاشف الذكاء الاصطناعي.
على سبيل المثال ، يعد استخدام علامة التعجب المزدوجة (!!) خاصية إنسانية للغاية ، لذا فإن إضافة هذه إلى بعض النصوص التي تم إنشاؤها بواسطة الذكاء الاصطناعي ستؤدي إلى وجود كاشف للذكاء الاصطناعي يعطي درجة "99٪ + بشري".
ثم يُساء تفسير ذلك بأنك "خدعت" الكاشف.
ولكنه مثال على عمل الكاشف بشكل مثالي لأن الممر المقدم لم يعد يتم إنشاؤه بنسبة 100٪ بواسطة الذكاء الاصطناعي.
لسوء الحظ ، فإن هذا الاستنتاج المضلل المتمثل في القدرة على "خداع" أجهزة الكشف عن الذكاء الاصطناعي يتم الخلط أيضًا بشكل شائع مع محركات البحث مثل Google التي لا تكتشف محتوى AI مما يمنح مالكي مواقع الويب إحساسًا زائفًا بالأمان.
سياسات وإجراءات جوجل بشأن محتوى الذكاء الاصطناعي
كانت بيانات Google حول محتوى الذكاء الاصطناعي تاريخيًا غامضة بما يكفي لمنحهم مساحة كبيرة للمناورة فيما يتعلق بالإنفاذ.
ومع ذلك ، تم نشر إرشادات محدثة هذا العام في Google Search Central والتي تنص صراحة على:
"ينصب تركيزنا على جودة المحتوى ، بدلاً من كيفية إنتاج المحتوى."
حتى قبل ذلك ، شارك داني سوليفان في بحث Google في تحفظات تويتر ليؤكد أنهم "لم يقلوا أن محتوى الذكاء الاصطناعي سيء".
يسرد Google أمثلة محددة لكيفية إنشاء الذكاء الاصطناعي لمحتوى مفيد ، مثل النتائج الرياضية وتوقعات الطقس والنصوص.
من الواضح أن Google تهتم بالنتائج أكثر بكثير من اهتمامها بوسائل الوصول إلى هناك ، ومضاعفة اهتمامها بـ "إنشاء محتوى لغرض أساسي هو التلاعب بالترتيب في نتائج البحث يعد انتهاكًا لسياساتنا بشأن الرسائل غير المرغوب فيها".
مكافحة التلاعب بـ SERP هو شيء تمتلك Google سنوات عديدة من الخبرة فيه ، حيث تدعي أن التطورات في أنظمتها ، مثل SpamBrain ، جعلت 99٪ من عمليات البحث "خالية من الرسائل غير المرغوب فيها" ، والتي قد تتضمن محتوى UGC غير مرغوب فيه ، وكشط ، وإخفاء ، وجميع أشكال المحتوى المختلفة جيل.
أجرى العديد من الأشخاص اختبارات لمعرفة كيفية تفاعل Google مع محتوى الذكاء الاصطناعي وأين يرسمون خطًا على الجودة.
قبل إطلاق ChatGPT ، أنشأت موقعًا على الويب من 10000 صفحة من المحتوى تم إنشاؤه بشكل أساسي بواسطة نموذج GPT3 غير خاضع للإشراف ، حيث أجاب الأشخاص أيضًا على طرح أسئلة حول ألعاب الفيديو.
مع الحد الأدنى من الروابط ، تمت فهرسة الموقع سريعًا ونما بشكل مطرد ، مما أدى إلى جلب الآلاف من الزوار شهريًا.
خلال تحديثين لنظام Google في عام 2022 ، تحديث المحتوى المفيد وتحديث البريد العشوائي اللاحق ، قامت Google فجأة وبشكل شبه كامل بقمع الموقع.
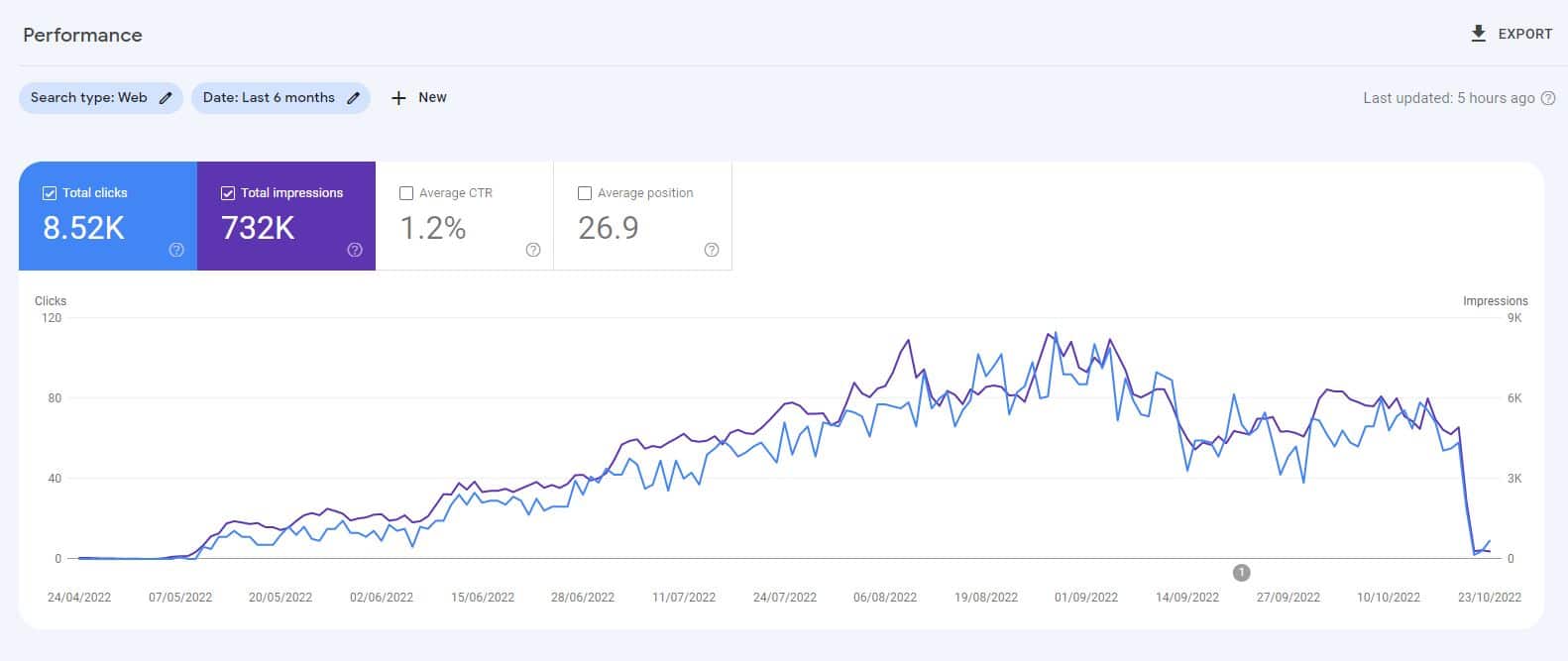
سيكون من الخطأ استنتاج أن "محتوى الذكاء الاصطناعي لا يعمل" من مثل هذه التجربة.
ومع ذلك ، فقد أوضح لي هذا أنه في ذلك الوقت بالذات ، فإن Google:
- لم يتم تصنيف محتوى GPT-3 غير الخاضع للإشراف على أنه "جودة".
- يمكن الكشف عن هذه النتائج وإزالتها بمجموعة كبيرة من الإشارات الأخرى.
للحصول على الإجابة النهائية ، تحتاج إلى سؤال أفضل
استنادًا إلى إرشادات Google ، ما نعرفه عن أنظمة البحث وتجارب تحسين محركات البحث والفطرة السليمة ، "هل يمكن لمحركات البحث اكتشاف محتوى الذكاء الاصطناعي؟" من المحتمل أن يكون السؤال الخطأ.
في أحسن الأحوال ، إنها وجهة نظر قصيرة المدى للغاية.
في معظم الموضوعات ، تكافح LLM لإنتاج محتوى "عالي الجودة" باستمرار من حيث الدقة الواقعية وتلبية معايير EEAT من Google ، على الرغم من وجود وصول مباشر إلى الويب للحصول على معلومات تتجاوز بيانات التدريب الخاصة بهم.
يخطو الذكاء الاصطناعي خطوات كبيرة في توليد إجابات لاستعلامات شحيحة المحتوى سابقًا. ولكن نظرًا لأن Google تهدف إلى تحقيق أهداف أعلى على المدى الطويل مع SGE ، فقد يتلاشى هذا الاتجاه.
من المتوقع أن يعود التركيز إلى محتوى الخبراء الأطول ، حيث تقدم أنظمة المعرفة من Google إجابات لتلبية العديد من الاستفسارات الطويلة بدلاً من توجيه المستخدمين إلى العديد من المواقع الصغيرة.
الآراء الواردة في هذا المقال هي آراء المؤلف الضيف وليست بالضرورة آراء محرك البحث. مؤلفو طاقم العمل مدرجون هنا.