
الكيان SEO: الدليل النهائي
نشرت: 2023-04-06شارك Andrew Ansley في تأليف المقال .
الأشياء لا الخيوط. إذا لم تكن قد سمعت بهذا من قبل ، فسيأتي من منشور مشهور في مدونة Google يعلن عن الرسم البياني المعرفي.
لم يتبق سوى شهر واحد على الذكرى الحادية عشرة للإعلان ، ومع ذلك لا يزال الكثيرون يكافحون لفهم ما تعنيه عبارة "الأشياء ، وليس الخيوط" بالنسبة إلى مُحسنات محركات البحث.
الاقتباس هو محاولة للتعبير عن أن Google تفهم الأشياء ولم تعد خوارزمية بسيطة للكشف عن الكلمات الرئيسية.
في مايو 2012 ، يمكن للمرء أن يجادل بأن الكيان مُحسّنات محرّكات البحث قد وُلد. يمكن لتعلم الآلة من Google ، بمساعدة قواعد المعرفة شبه المنظمة والمنظمة ، فهم المعنى الكامن وراء الكلمة الرئيسية.
أخيرًا كان للطبيعة الغامضة للغة حل طويل الأمد.
لذلك ، إذا كانت الكيانات مهمة بالنسبة إلى Google لأكثر من عقد ، فلماذا لا تزال مُحسّنات محرّكات البحث مشوشة بشأن الكيانات؟
سؤال جيد. أرى أربعة أسباب:
- لم يتم استخدام مُحسّنات محرّكات البحث (Entity SEO) كمصطلح على نطاق واسع بما يكفي لجعل مُحسّنات محرّكات البحث مرتاحين لتعريفها وبالتالي دمجها في مفرداتهم.
- يتداخل التحسين للكيانات بشكل كبير مع طرق التحسين القديمة التي تركز على الكلمات الرئيسية. نتيجة لذلك ، يتم الخلط بين الكيانات والكلمات الرئيسية. علاوة على ذلك ، لم يكن من الواضح كيف لعبت الكيانات دورًا في تحسين محركات البحث ، وأحيانًا تكون كلمة "كيانات" قابلة للتبديل مع "الموضوعات" عندما يتحدث Google عن هذا الموضوع.
- فهم الكيانات مهمة مملة. إذا كنت تريد معرفة عميقة بالكيانات ، فستحتاج إلى قراءة بعض براءات اختراع Google ومعرفة أساسيات التعلم الآلي. يعد Entity SEO نهجًا علميًا إلى حد بعيد لتحسين محركات البحث - والعلم ليس متاحًا للجميع.
- بينما أثر YouTube بشكل كبير في توزيع المعرفة ، فقد أدى إلى تسوية تجربة التعلم للعديد من الموضوعات. تاريخياً ، سلك المبدعون الذين حققوا أكبر قدر من النجاح على المنصة الطريق السهل عند تثقيف جمهورهم. نتيجة لذلك ، لم يقض منشئو المحتوى الكثير من الوقت في الكيانات حتى وقت قريب. لهذا السبب ، تحتاج إلى التعرف على الكيانات من الباحثين في البرمجة اللغوية العصبية ، ومن ثم تحتاج إلى تطبيق المعرفة على مُحسنات محركات البحث. براءات الاختراع والأوراق البحثية هي المفتاح. مرة أخرى ، هذا يعزز النقطة الأولى أعلاه.
هذه المقالة هي حل لجميع المشاكل الأربع التي منعت مُحسّنات محرّكات البحث من إتقان نهج قائم على الكيان لتحسين محركات البحث.
من خلال قراءة هذا ، ستتعلم:
- ما هو الكيان ولماذا هو مهم.
- تاريخ البحث الدلالي.
- كيفية تحديد واستخدام الكيانات في SERP.
- كيفية استخدام الكيانات لتصنيف محتوى الويب.
لماذا الكيانات مهمة؟
الكيان SEO هو المستقبل الذي تتجه إليه محركات البحث فيما يتعلق باختيار المحتوى الذي يجب ترتيبه وتحديد معناه.
اجمع هذا مع الثقة القائمة على المعرفة ، وأعتقد أن مُحسّنات محرّكات البحث (SEO) للكيان ستكون مستقبل كيفية إجراء مُحسّنات محرّكات البحث في العامين المقبلين.
أمثلة على الكيانات
إذن كيف تتعرف على الكيان؟
يحتوي SERP على العديد من الأمثلة للكيانات التي من المحتمل أن تكون قد شاهدتها.
ترتبط أكثر أنواع الكيانات شيوعًا بالمواقع أو الأشخاص أو الشركات.
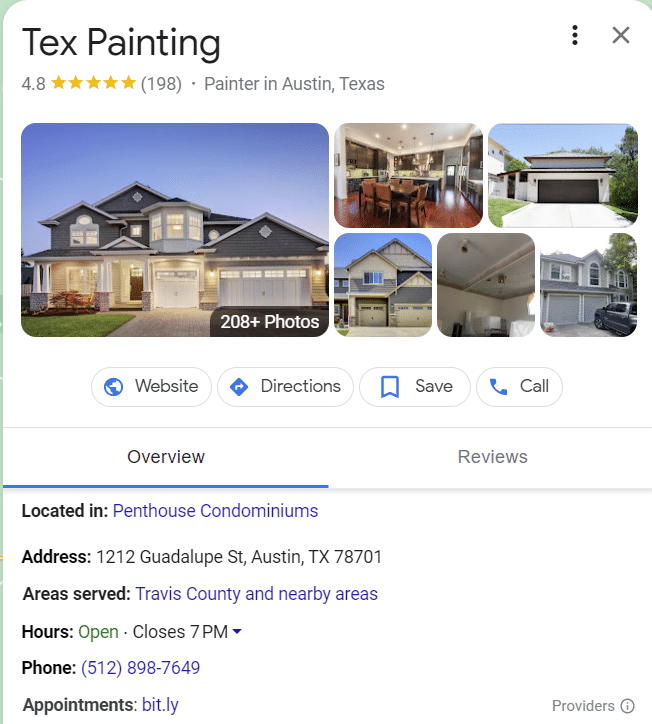
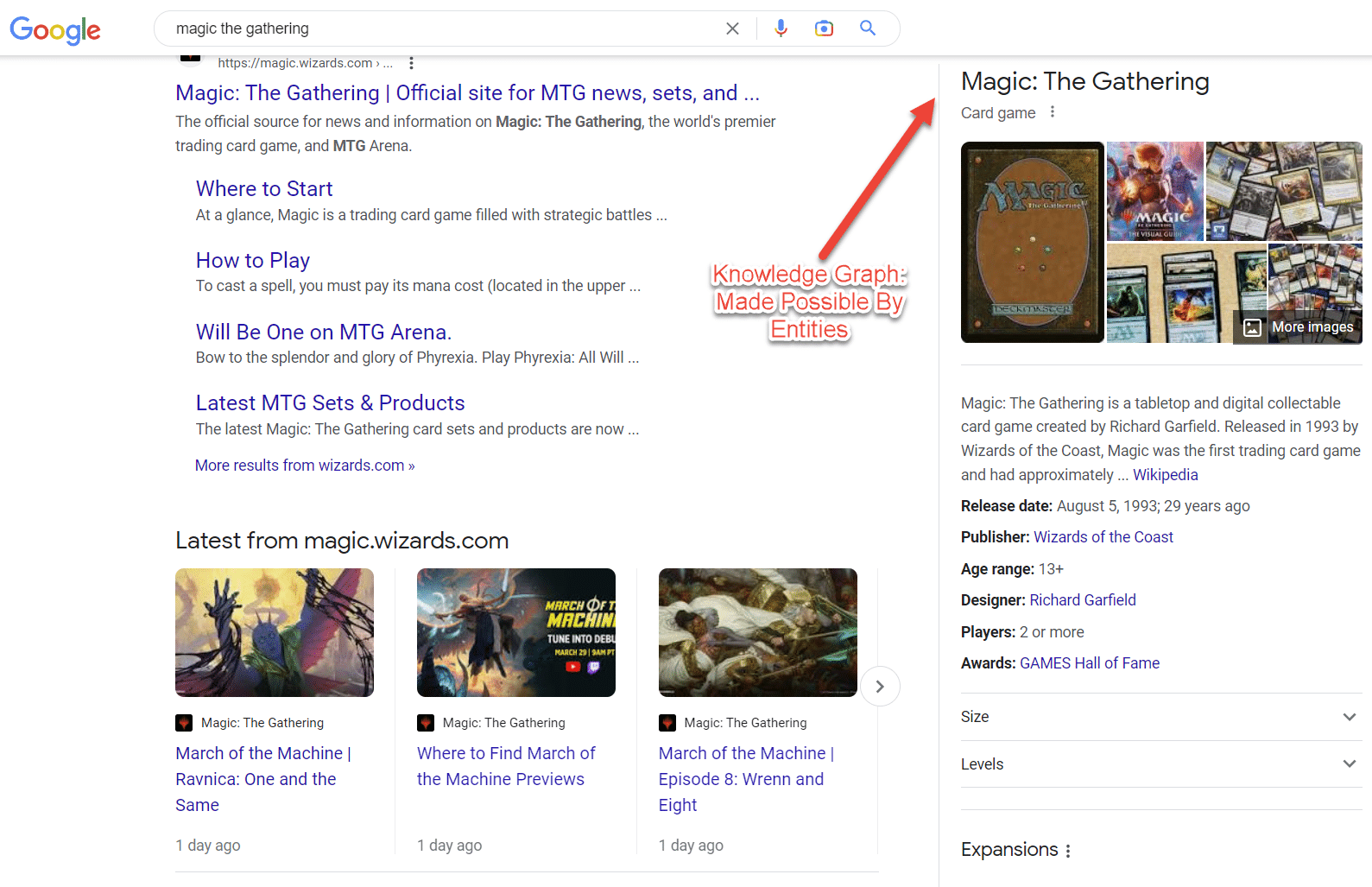
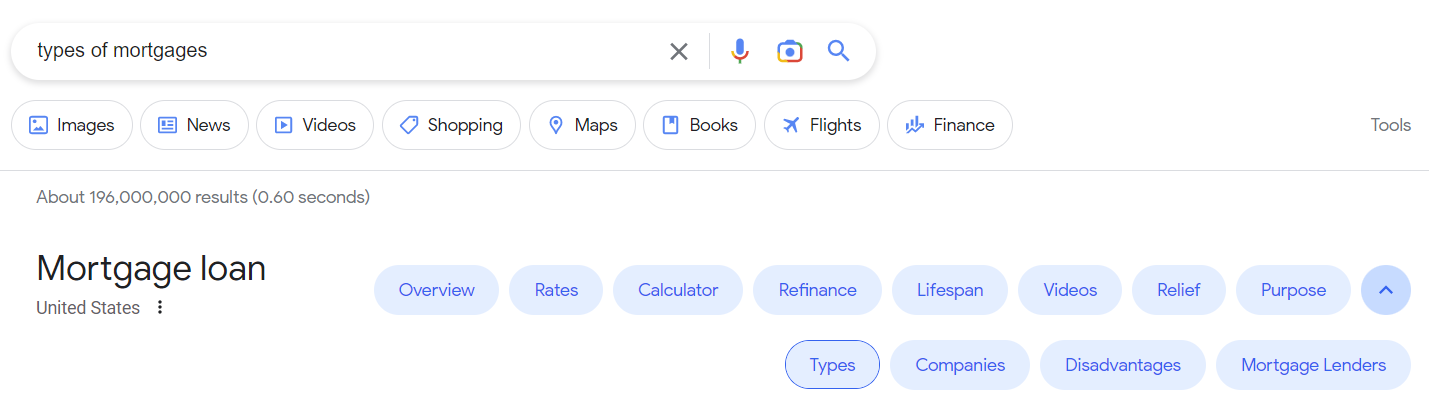
ربما يكون أفضل مثال للكيانات في SERP هو مجموعات النوايا. كلما زاد فهم الموضوع ، زادت ميزات البحث هذه.
ومن المثير للاهتمام أن حملة تحسين محركات البحث (SEO) واحدة يمكن أن تغير وجه SERP عندما تعرف كيفية تنفيذ حملات تحسين محركات البحث (SEO) التي تركز على الكيان.
إدخالات ويكيبيديا هي مثال آخر للكيانات. توفر ويكيبيديا مثالاً رائعًا للمعلومات المرتبطة بالكيانات.
كما ترى من أعلى اليسار ، فإن للكيان جميع أنواع السمات المرتبطة بـ "الأسماك" ، بدءًا من تشريحها وحتى أهميتها بالنسبة للإنسان.
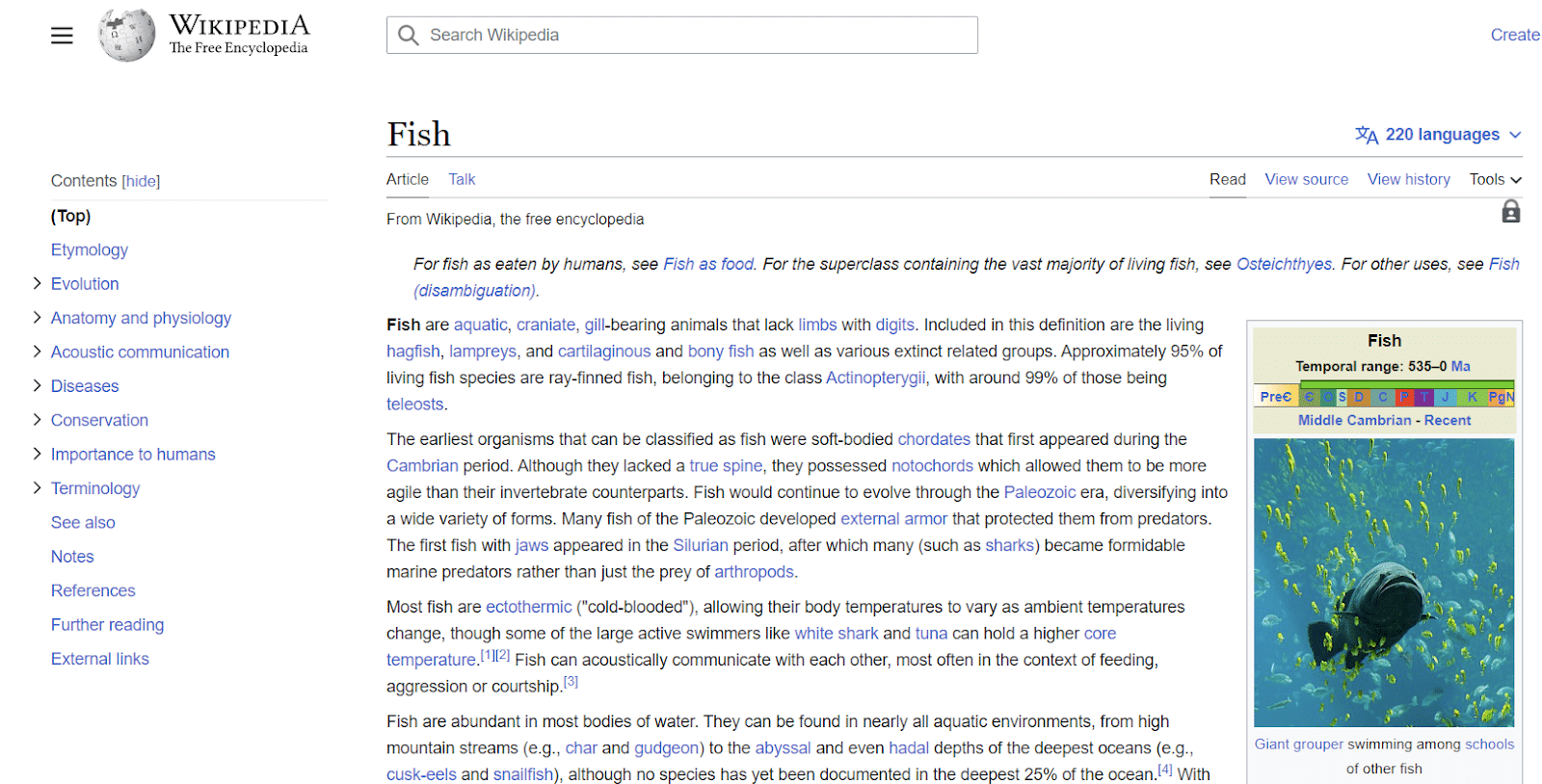
بينما تحتوي ويكيبيديا على العديد من نقاط البيانات حول موضوع ما ، فهي ليست شاملة بأي حال من الأحوال.
ما هو الكيان؟
الكيان هو كائن أو شيء يمكن التعرف عليه بشكل فريد يتميز باسمه (أسماءه) ونوعه (أنواعه) وسماته وعلاقاته بالكيانات الأخرى. يعتبر الكيان موجودًا فقط عندما يكون موجودًا في كتالوج الكيان.
تقوم كتالوجات الكيانات بتعيين معرف فريد لكل كيان. تمتلك وكالتي حلولًا آلية تستخدم المعرّف الفريد المرتبط بكل كيان (يتم تضمين جميع الخدمات والمنتجات والعلامات التجارية).
إذا كانت الكلمة أو العبارة غير موجودة داخل كتالوج موجود ، فهذا لا يعني أن الكلمة أو العبارة ليست كيانًا ، ولكن يمكنك عادةً معرفة ما إذا كان شيء ما كيانًا من خلال وجوده في الفهرس.
من المهم أن نلاحظ أن ويكيبيديا ليست العامل الحاسم فيما إذا كان شيء ما كيانًا ، ولكن الشركة معروفة بقاعدة بيانات الكيانات الخاصة بها.
يمكن استخدام أي كتالوج عند الحديث عن الكيانات. عادةً ما يكون الكيان هو شخص أو مكان أو شيء ، ولكن يمكن أيضًا تضمين الأفكار والمفاهيم.
تتضمن بعض أمثلة كتالوجات الكيانات ما يلي:
- ويكيبيديا
- ويكي بيانات
- DBpedia
- Freebase
- ياغو

تساعد الكيانات على سد الفجوة بين عوالم البيانات غير المهيكلة والمنظمة.
يمكن استخدامها لإثراء النص غير المهيكل لغويًا ، بينما يمكن استخدام المصادر النصية لتعبئة قواعد المعرفة المنظمة.
يُعرف التعرف على إشارات الكيانات في النص وربط هذه الإشارات بالإدخالات المقابلة في قاعدة المعرفة بمهمة ربط الكيانات.
تسمح الكيانات بفهم أفضل لمعنى النص ، لكل من البشر والآلات.
بينما يمكن للبشر حل غموض الكيانات بسهولة نسبيًا بناءً على السياق الذي تم ذكرهم فيه ، فإن هذا يمثل العديد من الصعوبات والتحديات للآلات.
يلخص إدخال قاعدة المعرفة للكيان ما نعرفه عن هذا الكيان.
نظرًا لأن العالم يتغير باستمرار ، كذلك تظهر حقائق جديدة. تتطلب مواكبة هذه التغييرات جهدًا مستمرًا من المحررين ومديري المحتوى. هذه مهمة شاقة على نطاق واسع.
من خلال تحليل محتويات المستندات التي يتم ذكر الكيانات فيها ، قد يتم دعم عملية العثور على الحقائق أو الحقائق الجديدة التي تحتاج إلى تحديث أو حتى آلية بالكامل.
يشير العلماء إلى هذا على أنه مشكلة مجتمع قاعدة المعرفة ، وهذا هو سبب أهمية ربط الكيانات.
تسهل الكيانات الفهم الدلالي لاحتياجات المستخدم من المعلومات ، كما يعبر عنها استعلام الكلمات الرئيسية ومحتوى المستند. وبالتالي يمكن استخدام الكيانات لتحسين الاستعلام و / أو تمثيل المستندات.
في الورقة البحثية للكيانات المسماة الموسعة ، حدد المؤلف حوالي 160 نوعًا من الكيانات. هنا اثنان من سبع لقطات من القائمة.


يتم تحديد فئات معينة من الكيانات بسهولة أكبر ، ولكن من المهم تذكر أن المفاهيم والأفكار كيانات. هاتان الفئتان من الصعب جدًا على Google توسيع نطاقهما بمفرده.
لا يمكنك تعليم Google بصفحة واحدة فقط عند العمل بمفاهيم غامضة. يتطلب فهم الكيانات العديد من المقالات والعديد من المراجع المستمرة بمرور الوقت.
تاريخ Google مع الكيانات
في 16 يوليو 2010 ، اشترت Google Freebase. كان هذا الشراء هو الخطوة الرئيسية الأولى التي أدت إلى نظام البحث عن الكيانات الحالي.

بعد الاستثمار في Freebase ، أدركت Google أن ويكي بيانات لديها حل أفضل. ثم عملت Google على دمج Freebase في Wikidata ، وهي مهمة كانت أصعب بكثير مما كان متوقعًا.
كتب خمسة من علماء Google ورقة بحثية بعنوان "From Freebase إلى Wikidata: The Great Migration". تشمل الوجبات الجاهزة الرئيسية.
"Freebase مبني على مفاهيم الكائنات والحقائق والأنواع والخصائص. يحتوي كل كائن Freebase على معرف ثابت يسمى "mid" (لمعرف الجهاز). "
يعتمد نموذج بيانات ويكي بيانات على مفاهيم العنصر والبيان. يمثل العنصر كيانًا ، وله معرف ثابت يسمى "qid" ، وقد يكون له تسميات وأوصاف وأسماء مستعارة بلغات متعددة ؛ المزيد من البيانات والروابط لصفحات حول الكيان في مشاريع ويكيميديا الأخرى - وأبرزها ويكيبيديا. على عكس Freebase ، لا تهدف عبارات Wikidata إلى ترميز الحقائق الحقيقية ، ولكن الادعاءات من مصادر مختلفة ، والتي يمكن أن تتعارض أيضًا مع بعضها البعض ... "
يتم تحديد الكيانات في قواعد المعرفة هذه ، ولكن لا يزال يتعين على Google بناء معرفة الكيانات الخاصة بها للبيانات غير المنظمة (أي المدونات).
دخلت Google في شراكة مع Bing و Yahoo وأنشأت Schema.org لإنجاز هذه المهمة.
توفر Google توجيهات المخطط حتى يمكن لمديري مواقع الويب الحصول على أدوات تساعد Google في فهم المحتوى. تذكر أن Google تريد التركيز على الأشياء وليس على الخيوط.
بكلمات جوجل:
"يمكنك مساعدتنا من خلال تقديم أدلة واضحة حول معنى الصفحة إلى Google من خلال تضمين البيانات المنظمة على الصفحة. البيانات المهيكلة هي تنسيق موحد لتوفير معلومات حول الصفحة وتصنيف محتوى الصفحة ؛ على سبيل المثال ، في صفحة الوصفات ، ما هي المكونات ووقت الطهي ودرجة الحرارة والسعرات الحرارية وما إلى ذلك. "
تواصل جوجل بالقول:
"يجب عليك تضمين جميع الخصائص المطلوبة لكائن ما ليكون مؤهلاً للظهور في بحث Google مع عرض محسّن. بشكل عام ، يمكن أن يؤدي تحديد المزيد من الميزات الموصى بها إلى زيادة احتمالية ظهور معلوماتك في نتائج البحث مع العرض المحسّن. ومع ذلك ، من المهم توفير عدد أقل من الخصائص الموصى بها ولكن كاملة ودقيقة بدلاً من محاولة توفير كل خاصية موصى بها محتملة ببيانات أقل اكتمالاً أو سيئة التكوين أو غير دقيقة ".
يمكن قول المزيد عن المخطط ، ولكن يكفي أن نقول أن المخطط أداة رائعة لمحركات البحث التي تتطلع إلى جعل محتوى الصفحة واضحًا لمحركات البحث.
يأتي الجزء الأخير من اللغز من إعلان مدونة Google بعنوان "تحسين البحث خلال العشرين عامًا القادمة".
أهمية الوثيقة وجودتها هي الأفكار الرئيسية وراء هذا الإعلان. كانت الطريقة الأولى التي استخدمتها Google لتحديد محتوى الصفحة تركز بالكامل على الكلمات الرئيسية.
ثم أضاف Google طبقات الموضوع للبحث. أصبحت هذه الطبقة ممكنة بفضل الرسوم البيانية المعرفية ومن خلال تجريف البيانات وتنظيمها بشكل منهجي عبر الويب.
هذا يقودنا إلى نظام البحث الحالي. انتقلت Google من 570 مليون كيان و 18 مليار حقيقة إلى 800 مليار حقيقة و 8 مليارات كيان في أقل من 10 سنوات. مع نمو هذا الرقم ، يتحسن البحث عن الكيانات.
كيف يتم تحسين نموذج الكيان من نماذج البحث السابقة؟
نماذج استرجاع المعلومات (IR) التقليدية القائمة على الكلمات الرئيسية لها قيود متأصلة تتمثل في عدم القدرة على استرداد المستندات (ذات الصلة) التي ليس لها مصطلح واضح يتطابق مع الاستعلام.
إذا كنت تستخدم ctrl + f للبحث عن نص في صفحة ، فإنك تستخدم شيئًا مشابهًا لنموذج استرجاع المعلومات التقليدي المستند إلى الكلمات الرئيسية.
يتم نشر كمية مجنونة من البيانات على الويب كل يوم.
ببساطة ، ليس من الممكن لـ Google فهم معنى كل كلمة وكل فقرة وكل مقالة وكل موقع.
بدلاً من ذلك ، توفر الكيانات هيكلًا يمكن لـ Google من خلاله تقليل العبء الحسابي مع تحسين الفهم.
تحاول طرق الاسترجاع القائمة على المفاهيم مواجهة هذا التحدي من خلال الاعتماد على الهياكل المساعدة للحصول على تمثيلات دلالية للاستعلامات والوثائق في مساحة مفهوم ذات مستوى أعلى. وتشمل هذه الهياكل المفردات الخاضعة للرقابة (القواميس وقواميس المترادفات) والأنطولوجيات والكيانات من مستودع المعرفة ".
- البحث الموجه للكيان ، الفصل 8.3
Krisztian Balog ، الذي كتب الكتاب النهائي عن الكيانات ، يحدد ثلاثة حلول ممكنة لنموذج استرجاع المعلومات التقليدي.
- قائم على التوسيع : يستخدم الكيانات كمصدر لتوسيع الاستعلام بمصطلحات مختلفة.
- قائم على الإسقاط : يتم فهم الصلة بين الاستعلام والوثيقة من خلال إسقاطها على مساحة كامنة من الكيانات
- على أساس الكيان : يتم الحصول على تمثيلات دلالية صريحة للاستعلامات والوثائق في مساحة الكيان لزيادة التمثيلات القائمة على المصطلحات.
الهدف من هذه الأساليب الثلاثة هو الحصول على تمثيل أكثر ثراءً لمعلومات المستخدم المطلوبة من خلال تحديد الكيانات المرتبطة بشدة بالاستعلام.
ثم يحدد Balog ست خوارزميات مرتبطة بالطرق القائمة على الإسقاط لرسم خرائط الكيانات (تتعلق طرق الإسقاط بتحويل الكيانات إلى فضاء ثلاثي الأبعاد وقياس المتجهات باستخدام الهندسة).
- التحليل الدلالي الصريح (ESA) : يتم وصف دلالات كلمة معينة بواسطة ناقل يخزن قوة ارتباط الكلمة بالمفاهيم المشتقة من ويكيبيديا.
- نموذج فضاء الكيان الكامن (LES) : يعتمد على إطار احتمالي توليدي. يتم أخذ درجة استرداد المستند على أنها مزيج خطي من درجة مساحة الكيان الكامن ودرجة احتمالية الاستعلام الأصلية.
- EsdRank: EsdRank مخصص لترتيب المستندات ، باستخدام مجموعة من ميزات كيان الاستعلام ومستند الكيان. تتوافق هذه مع مفاهيم إسقاط الاستعلام ومكونات إسقاط المستندات لـ LES ، على التوالي ، من قبل. باستخدام إطار عمل تعليمي تمييزي ، يمكن أيضًا دمج إشارات إضافية بسهولة ، مثل شعبية الكيان أو جودة المستند
- الترتيب الدلالي الصريح (ESR): يشتمل نموذج التصنيف الدلالي الصريح على معلومات العلاقة من الرسم البياني للمعرفة لتمكين "المطابقة الناعمة" في مساحة الكيان.
- إطار عمل ثنائي الكيان Word: يتضمن تفاعلات عبر المسافات بين التمثيلات القائمة على المصطلحات والكيانات ، مما يؤدي إلى أربعة أنواع من التطابقات: مصطلحات الاستعلام عن مصطلحات المستند ، وكيانات الاستعلام لتوثيق المصطلحات ، ومصطلحات الاستعلام لكيانات المستند ، وكيانات الاستعلام لتوثيق الكيانات.
- نموذج التصنيف القائم على الانتباه : هذا هو إلى حد بعيد أكثر ما يمكن وصفه تعقيدًا.
إليكم ما يكتبه بالوج:
"تم تصميم ما مجموعه أربع ميزات الانتباه ، والتي يتم استخراجها لكل كيان استعلام. تهدف ميزات غموض الكيان إلى وصف المخاطر المرتبطة بتعليق توضيحي للكيان. هذه هي: (1) إنتروبيا احتمالية ارتباط شكل السطح بكيانات مختلفة (على سبيل المثال ، في ويكيبيديا) ، (2) ما إذا كان الكيان المشروح هو المعنى الأكثر شيوعًا للشكل السطحي (أي لديه أعلى نسبة انتشار النتيجة ، و (3) الفرق في درجات الشهرة بين المرشحين الأكثر ترجيحًا والثاني الأكثر ترجيحًا لشكل السطح المحدد. الميزة الرابعة هي التقارب ، والتي تُعرّف على أنها تشابه جيب التمام بين كيان الاستعلام والاستعلام في مساحة التضمين . على وجه التحديد ، يتم تدريب التضمين المشترك لمصطلح الكيان باستخدام نموذج تخطي الجرام في مجموعة ، حيث يتم استبدال إشارات الكيان بمعرفات الكيانات المقابلة. ويُعتبر تضمين الاستعلام بمثابة النقطة الوسطى لمصطلحات الاستعلام "حفلات الزفاف".

في الوقت الحالي ، من المهم أن يكون لديك معرفة على مستوى السطح بهذه الخوارزميات الست المتمحورة حول الكيانات.
الخلاصة الرئيسية هي وجود طريقتين: إسقاط المستندات على طبقة كيان كامنة وتعليقات الكيان التوضيحية الصريحة للمستندات.
ثلاثة أنواع من هياكل البيانات
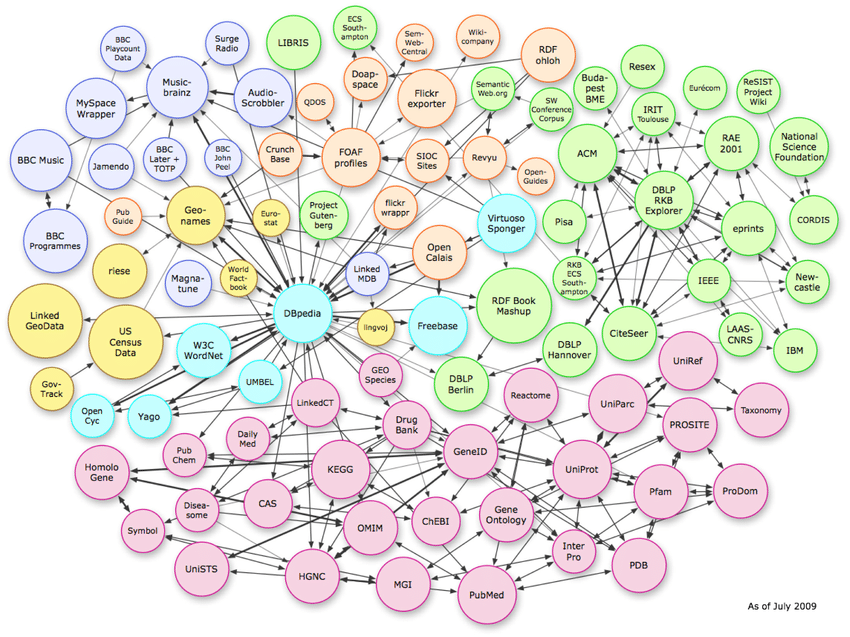
توضح الصورة أعلاه العلاقات المعقدة الموجودة في الفضاء المتجه. بينما يوضح المثال اتصالات الرسم البياني المعرفي ، يمكن تكرار هذا النمط نفسه على مستوى مخطط صفحة بصفحة.
لفهم الكيانات ، من المهم معرفة الأنواع الثلاثة لهياكل البيانات التي تستخدمها الخوارزميات.
- باستخدام أوصاف الكيانات غير المنظمة ، يجب التعرف على الإشارات إلى الكيانات الأخرى وتوضيحها. تتم إضافة الحواف الموجهة (الارتباطات التشعبية) من كل كيان إلى جميع الكيانات الأخرى المذكورة في وصفه.
- في إعداد شبه منظم (على سبيل المثال ، ويكيبيديا) ، قد يتم توفير روابط لكيانات أخرى بشكل صريح.
- عند العمل مع البيانات المهيكلة ، تحدد RDF الثلاثيات رسمًا بيانيًا (أي الرسم البياني المعرفي). على وجه التحديد ، تعد موارد الموضوع والكائن (URIs) عقدًا ، والمسندات عبارة عن حواف.
تكمن المشكلة في السياق شبه المنظم والمشتت لنتيجة IR في أنه إذا لم يتم تكوين مستند لموضوع واحد ، فيمكن تخفيف درجة IR من خلال السياقين المختلفين مما يؤدي إلى فقد ترتيب نسبي في مستند نصي آخر.
يتضمن تخفيف درجة الأشعة تحت الحمراء علاقات معجمية سيئة التنظيم وتقارب الكلمات السيئة.
يجب استخدام الكلمات ذات الصلة التي تكمل بعضها البعض بشكل وثيق داخل فقرة أو قسم من المستند للإشارة إلى السياق بشكل أكثر وضوحًا لزيادة درجة IR.
يؤدي استخدام سمات وعلاقات الكيانات إلى تحسينات نسبية في نطاق 5-20٪. يعد استغلال المعلومات من نوع الكيان أكثر فائدة ، حيث تتراوح التحسينات النسبية من 25٪ إلى أكثر من 100٪.
يمكن أن يؤدي التعليق التوضيحي على المستندات مع الكيانات إلى إحضار بنية إلى المستندات غير المهيكلة ، والتي يمكن أن تساعد في تعبئة قواعد المعرفة بمعلومات جديدة حول الكيانات.
استخدام ويكيبيديا كإطار عمل تحسين محركات البحث لكيانك
هيكل صفحات ويكيبيديا
- العنوان (I.)
- قسم الرصاص (II.)
- روابط توضيح (II.a)
- Infobox (II.b)
- نص تمهيدي (II.c)
- جدول المحتويات (III.)
- محتوى الجسم (IV.)
- الملاحق والمادة السفلية (V.)
- المراجع والملاحظات (Va)
- روابط خارجية (Vb)
- الفئات (Vc)
تتضمن معظم مقالات ويكيبيديا نصًا تمهيديًا ، "المقدمة" ، ملخصًا موجزًا للمقال - لا يزيد طوله عادةً عن أربع فقرات. يجب كتابة هذا بطريقة تثير الاهتمام بالمقال.
الجملة الأولى والفقرة الافتتاحية لها أهمية خاصة. الجملة الأولى "يمكن اعتبارها تعريف الكيان الموصوف في المقالة". تقدم الفقرة الأولى تعريفًا أكثر تفصيلاً دون الكثير من التفاصيل.
تمتد قيمة الروابط إلى ما وراء الأغراض الملاحية ؛ يلتقطون العلاقات الدلالية بين المقالات. بالإضافة إلى ذلك ، تعد نصوص الإرساء مصدرًا غنيًا لمتغيرات اسم الكيان. يمكن استخدام روابط ويكيبيديا ، من بين أمور أخرى ، للمساعدة في تحديد وإزالة الغموض عن الكيانات التي تم ذكرها في النص.
- لخص الحقائق الأساسية عن الكيان (صندوق المعلومات).
- مقدمة مختصرة.
- الروابط الداخلية. القاعدة الأساسية الممنوحة للمحررين هي الارتباط فقط بالحدث الأول لكيان أو مفهوم.
- قم بتضمين جميع المرادفات الشائعة للكيان.
- تسمية صفحة الفئة.
- قالب التنقل.
- مراجع.
- أدوات التحليل الخاصة لفهم صفحات Wiki.
- أنواع وسائط متعددة.
كيفية التحسين للكيانات
فيما يلي اعتبارات رئيسية عند تحسين الكيانات للبحث:
- تضمين الكلمات ذات الصلة لغويًا في الصفحة.
- تكرار الكلمات والعبارة على الصفحة.
- تنظيم المفاهيم على الصفحة.
- بما في ذلك البيانات غير المنظمة والبيانات شبه المنظمة والبيانات المنظمة على الصفحة.
- أزواج الموضوع - المسند - الكائن (SPO).
- مستندات الويب على موقع تعمل كصفحات من كتاب.
- تنظيم مستندات الويب على موقع ويب.
- قم بتضمين مفاهيم في مستند ويب تُعرف بميزات الكيانات.
ملاحظة مهمة: عندما يكون التركيز على العلاقات بين الكيانات ، غالبًا ما يشار إلى قاعدة المعرفة باسم الرسم البياني للمعرفة.
نظرًا لأنه يتم تحليل النية بالاقتران مع سجلات بحث المستخدم وأجزاء أخرى من السياق ، يمكن أن تؤدي عبارة البحث نفسها من الشخص 1 إلى نتيجة مختلفة عن الشخص 2. يمكن أن يكون لدى الشخص نية مختلفة باستخدام نفس الاستعلام بالضبط.
إذا كانت صفحتك تغطي كلا النوعين من النوايا ، فإن صفحتك هي أفضل مرشح لترتيب الويب. يمكنك استخدام بنية قواعد المعرفة لتوجيه قوالب نية الاستعلام (كما هو مذكور في القسم السابق).
يسأل الأشخاص أيضًا ، ويبحث الناس عن ، والإكمال التلقائي مرتبطان ارتباطًا معنويًا بالاستعلام المقدم وإما الغوص بشكل أعمق في اتجاه البحث الحالي أو الانتقال إلى جانب مختلف من مهمة البحث.
نحن نعلم هذا ، فكيف يمكننا تحسينه؟
يجب أن تحتوي مستنداتك على أكبر عدد ممكن من الاختلافات في هدف البحث. يجب أن يحتوي موقع الويب الخاص بك على كل اختلاف نية البحث عن مجموعتك. يعتمد التجميع على ثلاثة أنواع من التشابه:
- تشابه معجمي.
- التشابه الدلالي.
- انقر فوق التشابه.
تغطية الموضوع
ما هو -> قائمة السمات -> قسم مخصص لكل سمة -> يرتبط كل قسم بمقال مخصص بالكامل لهذا الموضوع -> يجب تحديد الجمهور وتحديد تعريفات القسم الفرعي -> ما الذي يجب مراعاته ؟ -> ما هي الفوائد؟ -> فوائد المُعدِّل -> ما هو ___ -> ماذا يفعل؟ -> كيفية الحصول عليها -> كيفية القيام بذلك -> من يمكنه القيام بذلك -> قم بالرجوع إلى جميع الفئات

تقدم Google أداة توفر درجة بروز (على غرار الطريقة التي نستخدم بها كلمة "قوة" أو "ثقة") تخبرك كيف يرى Google المحتوى.

يأتي المثال أعلاه من مقالة Search Engine Land حول الكيانات من 2018.
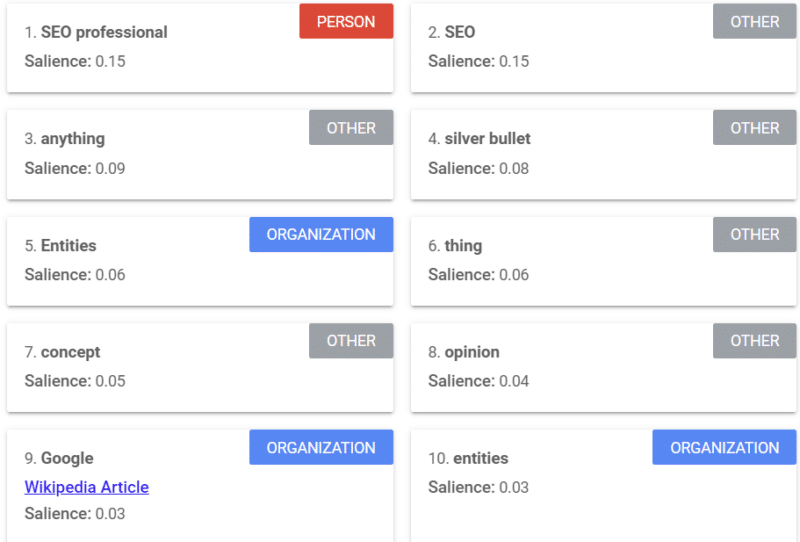
يمكنك رؤية شخص وآخر ومؤسسات من المثال. الأداة هي Google Cloud's Natural Language API.
كل كلمة وجملة وفقرة مهمة عند الحديث عن كيان ما. كيف تنظم أفكارك يمكن أن تغير فهم Google للمحتوى الخاص بك.
يمكنك تضمين كلمة رئيسية حول مُحسّنات محرّكات البحث ، لكن هل تفهم Google هذه الكلمة الأساسية بالطريقة التي تريدها لفهمها؟
حاول وضع فقرة أو فقرتين في الأداة وإعادة تنظيم وتعديل المثال لترى كيف يزيد أو يقلل من البروز.
هذا التمرين ، المسمى "توضيح الغموض" ، مهم للغاية للكيانات. اللغة غامضة ، لذلك يجب أن نجعل كلماتنا أقل غموضًا لـ Google.
مناهج توضيح الغموض الحديثة تأخذ بعين الاعتبار ثلاثة أنواع من الأدلة:
الأهمية السابقة للكيانات والإشارات.
التشابه السياقي بين النص المحيط بالإشارة والكيان المرشح والتماسك بين جميع قرارات ربط الكيانات في الوثيقة.
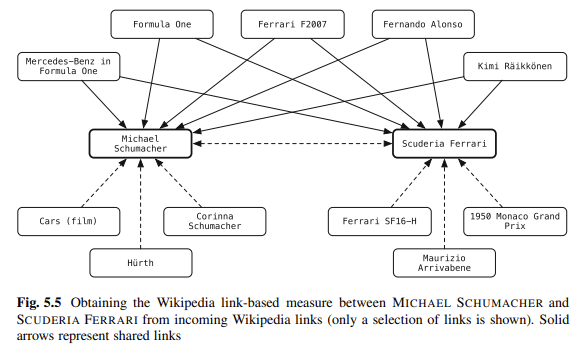
المخطط هو أحد طرقي المفضلة لإزالة الغموض عن المحتوى. أنت تربط كيانات في مدونتك بمستودعات المعرفة. يقول بالوج:
"[L] يمكن للكيانات التحبير في نص غير منظم إلى مستودع معرفة منظم تمكين المستخدمين بشكل كبير في أنشطة استهلاك المعلومات الخاصة بهم."
على سبيل المثال ، يمكن لقراء المستند الحصول على معلومات سياقية أو خلفية بنقرة واحدة ، ويمكنهم الوصول بسهولة إلى الكيانات ذات الصلة.
يمكن أيضًا استخدام التعليقات التوضيحية للكيان في المعالجة النهائية لتحسين أداء الاسترجاع أو لتسهيل تفاعل المستخدم بشكل أفضل مع نتائج البحث.
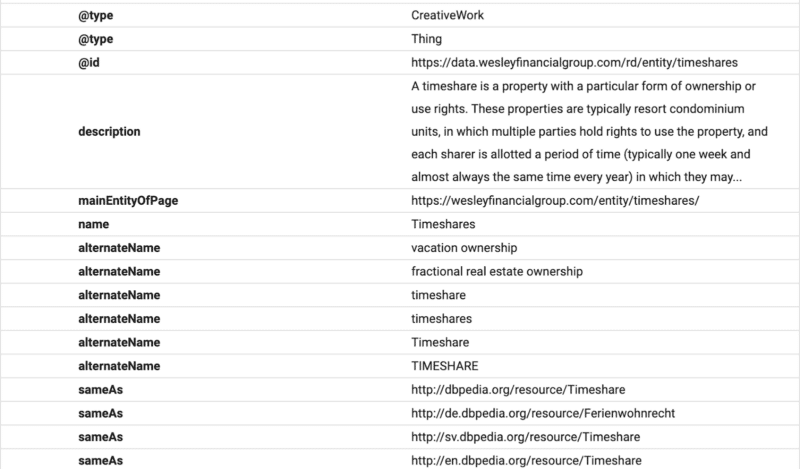
هنا يمكنك أن ترى أن محتوى الأسئلة الشائعة منظم لـ Google باستخدام مخطط الأسئلة الشائعة.
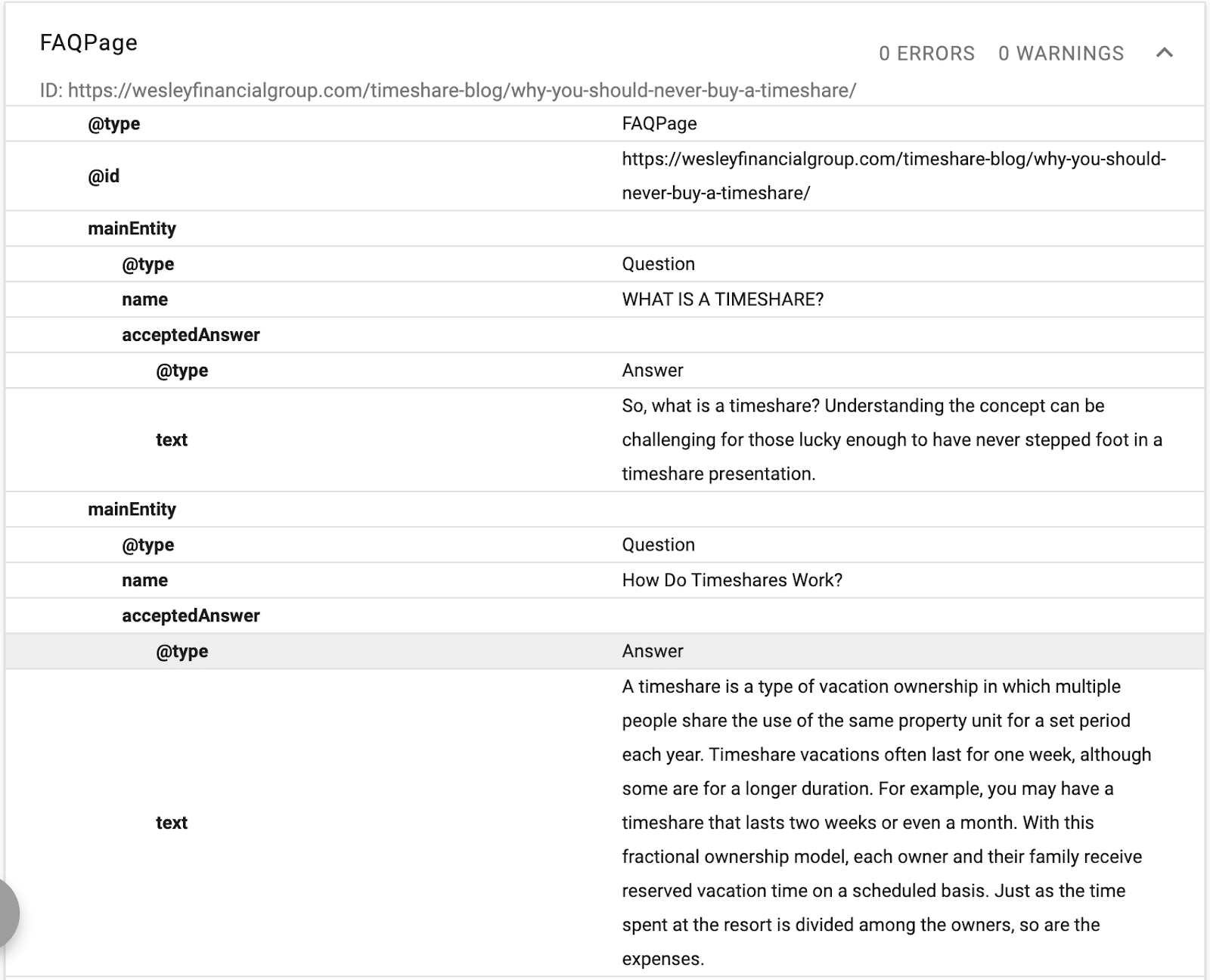
في هذا المثال ، يمكنك مشاهدة مخطط يوفر وصفًا للنص ومعرفًا وإعلانًا عن الكيان الرئيسي للصفحة.
(تذكر أن Google تريد فهم التسلسل الهرمي للمحتوى ، وهذا هو سبب أهمية H1 – H6.)
سترى أسماء بديلة ونفس التصريحات. الآن ، عندما تقرأ Google المحتوى ، ستعرف قاعدة البيانات المهيكلة التي سيتم ربطها بالنص ، وسيكون لها مرادفات وإصدارات بديلة من كلمة مرتبطة بالكيان.
عندما تقوم بالتحسين باستخدام المخطط ، فإنك تقوم بالتحسين لـ NER (التعرف على الكيان المسمى) ، والمعروف أيضًا باسم تعريف الكيان ، واستخراج الكيان ، وتقسيم الكيان.
الفكرة هي الدخول في توضيح الكيان المحدد> Wikification> ربط الكيان.
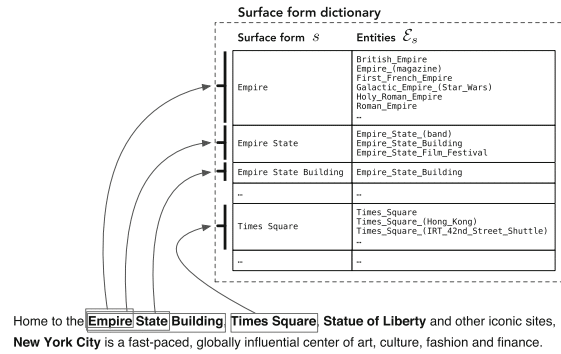
"أدى ظهور ويكيبيديا إلى تسهيل التعرف على الكيانات على نطاق واسع وإزالة اللبس من خلال توفير فهرس شامل للكيانات جنبًا إلى جنب مع موارد أخرى لا تقدر بثمن (على وجه التحديد ، الارتباطات التشعبية والفئات وصفحات إعادة التوجيه والتوضيح."
- البحث عن الكيانات
كيف تجاوز اقتراحات أداة تحسين محركات البحث
تستخدم معظم مُحسّنات محرّكات البحث بعض الأدوات الموجودة على الصفحة لتحسين محتواها. كل أداة محدودة في قدرتها على تحديد فرص المحتوى الفريدة واقتراحات عمق المحتوى.
بالنسبة للجزء الأكبر ، فإن الأدوات الموجودة على الصفحة تقوم فقط بتجميع أفضل نتائج SERP وإنشاء متوسط يمكنك محاكاته.
يجب أن تتذكر مُحسّنات محرّكات البحث أن Google لا تبحث عن نفس المعلومات المعاد صياغتها. يمكنك نسخ ما يفعله الآخرون ، ولكن المعلومات الفريدة هي المفتاح لتصبح موقعًا أساسيًا / موقع سلطة.
فيما يلي وصف مبسط لكيفية تعامل Google مع المحتوى الجديد:
بمجرد العثور على مستند يذكر كيانًا معينًا ، قد يتم فحص هذا المستند لاكتشاف الحقائق الجديدة التي يمكن من خلالها تحديث إدخال قاعدة المعرفة لهذا الكيان.
يكتب بالوج:
"نرغب في مساعدة المحررين على البقاء على اطلاع دائم بالتغييرات من خلال تحديد المحتوى تلقائيًا (المقالات الإخبارية ، منشورات المدونة ، إلخ) التي قد تتضمن تعديلات على إدخالات قاعدة المعارف لمجموعة معينة من الكيانات محل الاهتمام (على سبيل المثال ، الكيانات التي يمثلها محرر معين مسؤولة عن)."
أي شخص يعمل على تحسين قواعد المعرفة والتعرف على الكيانات وإمكانية الزحف إلى المعلومات سيحظى بحب Google.
يمكن تتبع التغييرات التي تم إجراؤها في مستودع المعرفة مرة أخرى إلى المستند كمصدر أصلي.
إذا قدمت محتوى يغطي الموضوع وأضفت مستوى من العمق نادرًا أو جديدًا ، يمكن لـ Google تحديد ما إذا كان المستند الخاص بك قد أضاف تلك المعلومات الفريدة.
في النهاية ، قد تؤدي هذه المعلومات الجديدة التي تم الحفاظ عليها على مدى فترة زمنية إلى أن يصبح موقع الويب الخاص بك مرجعية.
هذه ليست سلطة تعتمد على تصنيف المجال ولكن التغطية الموضعية ، والتي أعتقد أنها أكثر قيمة بكثير.
مع نهج الكيان لتحسين محركات البحث ، فأنت لست مقيدًا باستهداف الكلمات الرئيسية ذات حجم البحث.
كل ما عليك القيام به هو التحقق من المصطلح الرئيسي (على سبيل المثال "قضبان صيد الذباب") ، وبعد ذلك يمكنك التركيز على استهداف اختلافات هدف البحث بناءً على التفكير البشري الجيد في الموضة.
نبدأ مع ويكيبيديا. بالنسبة لمثال الصيد باستخدام الذباب ، يمكننا أن نرى أنه ، على الأقل ، يجب تغطية المفاهيم التالية على موقع ويب لصيد الأسماك:
- أنواع الأسماك ، التاريخ ، الأصول ، التطوير ، التحسينات التكنولوجية ، التوسع ، طرق الصيد بالذباب ، الصب ، صب الجاسوس ، صيد سمك السلمون المرقط ، تقنيات الصيد بالذباب ، الصيد في المياه الباردة ، صيد سمك السلمون المرقط الجاف ، حوريات سمك السلمون المرقط ، المياه الساكنة صيد سمك السلمون المرقط ، ولعب التراوت ، وإطلاق التراوت ، وصيد الذباب في المياه المالحة ، والذباب الاصطناعي ، والعُقد.
جاءت الموضوعات أعلاه من صفحة ويكيبيديا الخاصة بصيد الذباب. بينما توفر هذه الصفحة نظرة عامة رائعة على الموضوعات ، أود إضافة أفكار موضوعات إضافية تأتي من موضوعات ذات صلة لغويًا.
بالنسبة لموضوع "الأسماك" ، يمكننا إضافة العديد من الموضوعات الإضافية ، بما في ذلك أصل الكلمة ، والتطور ، وعلم التشريح وعلم وظائف الأعضاء ، والتواصل مع الأسماك ، وأمراض الأسماك ، والحفظ ، والأهمية بالنسبة للإنسان.
هل ربط أي شخص تشريح التراوت بفاعلية تقنيات صيد معينة؟
هل غطى موقع واحد لصيد الأسماك جميع أنواع الأسماك مع ربط أنواع تقنيات الصيد والقضبان والطُعم بكل سمكة؟
الآن ، يجب أن تكون قادرًا على رؤية كيف يمكن أن ينمو توسيع الموضوع. ضع ذلك في الاعتبار عند التخطيط لحملة محتوى.
لا تعيد صياغتها فقط. إضافة قيمة. كن فريدا. استخدم الخوارزميات المذكورة في هذه المقالة كدليل لك.
خاتمة
هذه المقالة جزء من سلسلة مقالات تركز على الكيانات. في المقالة التالية ، سأتعمق أكثر في جهود التحسين حول الكيانات وبعض الأدوات التي تركز على الكيانات في السوق.
أريد أن أنهي هذا المقال بإعطاء صيحة لشخصين شرحا لي العديد من هذه المفاهيم.
Bill Slawski من SEO by the Sea و Koray Tugbert من Holistic SEO. بينما لم يعد Slawski معنا ، تستمر مساهماته في التأثير بشكل مضاعف في صناعة تحسين محركات البحث.
أعتمد بشدة على المصادر التالية لمحتوى المقالة ، فهذه المصادر هي أفضل الموارد الموجودة في الموضوع:
- توسيع التسلسل الهرمي للكيان المُسمى بواسطة ساتوشي كيتين ، وكيوشي سودو ، وتشيكاشي نوباتا
- البحث الموجه نحو الكيان بواسطة Krisztian Balog ، سلسلة استرداد المعلومات (INRE ، المجلد 39)
- إعادة كتابة الاستعلام مع كشف الكيان ، براءات الاختراع من Google
- تنقية استعلامات البحث ، براءات الاختراع جوجل
- إقران كيان باستعلام بحث ، براءات اختراع Google
الآراء الواردة في هذا المقال هي آراء المؤلف الضيف وليست بالضرورة آراء محرك البحث. مؤلفو طاقم العمل مدرجون هنا.