
كيف يمكن لأباتشي سبارك أن تعطي أجنحة لتحليلات شركات الطيران؟
نشرت: 2015-10-30تستمر صناعة الطيران العالمية في النمو بسرعة ، ولكن الربحية المتسقة والقوية لم تظهر بعد. وفقًا لاتحاد النقل الجوي الدولي (IATA) ، ضاعفت الصناعة إيراداتها خلال العقد الماضي ، من 369 مليار دولار أمريكي في عام 2005 إلى 727 مليار دولار أمريكي في عام 2015.

في قطاع الطيران التجاري ، يحقق كل لاعب في سلسلة القيمة - المطارات ، ومصنعي الطائرات ، وصانعي المحركات النفاثة ، ووكلاء السفر ، وشركات الخدمات أرباحًا جيدة.
يقوم كل هؤلاء اللاعبين بشكل فردي بإنشاء كميات كبيرة جدًا من البيانات بسبب ارتفاع معدل عمليات الطيران. يعد تحديد الطلب والتقاطه هو المفتاح هنا الذي يوفر فرصة أكبر لشركات الطيران لتمييز نفسها. ومن ثم ، يمكن لصناعات الطيران الاستفادة من رؤى البيانات الضخمة لزيادة مبيعاتها وتحسين هامش الربح.
البيانات الضخمة هي مصطلح يشير إلى جمع مجموعات البيانات الكبيرة والمعقدة بحيث لا يمكن التعامل مع الحوسبة الخاصة بها عن طريق أنظمة معالجة البيانات التقليدية أو أدوات نظام إدارة قواعد البيانات (DBMS).
Apache Spark هو إطار عمل حوسبة عنقودية موزع مفتوح المصدر مصمم خصيصًا للاستعلامات التفاعلية والخوارزميات التكرارية.
تجريد Spark DataFrame هو كائن بيانات جدولي مشابه لإطار البيانات الأصلي الخاص بـ R أو حزمة Pythons pandas ، ولكن يتم تخزينه في بيئة الكتلة.
وفقًا لأحدث استطلاع لـ Fortunes ، فإن Apache Spark هي أكثر التقنيات شيوعًا لعام 2015.
يقول أكبر بائع Hadoop Cloudera أيضًا GoodBye لـ Hadoops MapReduce و Hello to Spark.
ما يمنح Spark حقًا ميزة على Hadoop هو السرعة . تتعامل Spark مع معظم عملياتها في الذاكرة - نسخها من التخزين الفعلي الموزع إلى ذاكرة RAM منطقية أسرع بكثير. هذا يقلل من مقدار الوقت المستغرق في الكتابة والقراءة من وإلى محركات الأقراص الصلبة الميكانيكية البطيئة والخطيرة والتي يجب القيام بها في ظل نظام Hadoops MapReduce.
يتضمن Spark أيضًا أدوات (معالجة في الوقت الفعلي ، وتعلم آلي و SQL تفاعلي) تم تصميمها جيدًا لدعم أهداف العمل مثل تحليل البيانات في الوقت الفعلي من خلال دمج البيانات التاريخية من الأجهزة المتصلة ، والمعروفة أيضًا باسم إنترنت الأشياء .
اليوم ، دعنا نجمع بعض الأفكار حول عينة من بيانات المطار باستخدام Apache Spark .
رأينا في المدونة السابقة كيفية التعامل مع البيانات المنظمة وشبه المهيكلة في Spark باستخدام Dataframes API الجديدة وتناولنا أيضًا كيفية معالجة بيانات JSON بكفاءة.
في هذه المدونة ، سوف نفهم كيفية الاستعلام عن البيانات في DataFrames باستخدام SQL وكذلك حفظ الإخراج إلى نظام الملفات بتنسيق CSV.
باستخدام مكتبة التحليل Databricks CSV
لهذا سأستخدم مكتبة تحليل CSV مقدمة من Databricks ، وهي شركة أسسها Creators of Apache Spark والتي تتعامل مع Spark Development والتوزيعات حاليًا.
يتكون مجتمع Spark من حوالي 600 مساهم يجعلونه المشروع الأكثر نشاطًا في مؤسسة Apache Software Foundation بأكملها ، وهي هيئة إدارية رئيسية لبرامج مفتوحة المصدر ، من حيث عدد المساهمين.
تساعدنا مكتبة Spark-csv في تحليل بيانات csv والاستعلام عنها في الشرارة. يمكننا استخدام هذه المكتبة لقراءة وكتابة بيانات csv من وإلى أي نظام ملفات متوافق مع Hadoop.
تحميل البيانات في Spark DataFrames
لنقم بتحميل ملفات الإدخال الخاصة بنا في Spark DataFrames باستخدام مكتبة تحليل spark-csv من Databricks.
يمكنك استخدام هذه المكتبة في Spark shell بتحديد –packages com.databricks: spark-csv_2.10: 1.0.3
أثناء بدء الهيكل كما هو موضح أدناه:
$ bin / spark-shell –packages com.databricks: spark-csv_2.10: 1.0.3
تذكر أنه يجب أن تكون متصلاً بالإنترنت ، لأنه سيتم تنزيل حزمة spark-csv تلقائيًا عند إعطاء هذا الأمر. أنا أستخدم إصدار Spark 1.4.0
لنقم بإنشاء sqlContext باستخدام كائن SparkContext (sc) الذي تم إنشاؤه بالفعل
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
import sqlContext.implicits._
لنقم الآن بتحميل بيانات csv الخاصة بنا من ملف airports.csv (مطار csv github) الذي يكون مخططه على النحو التالي
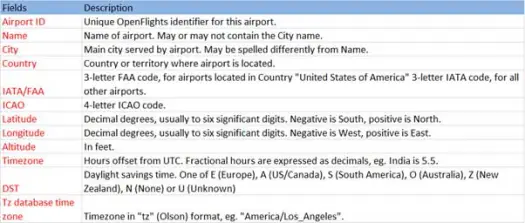
scala> val airportDF = sqlContext.load("com.databricks.spark.csv", Map("path" -> "/home /poonam/airports.csv", "header" -> "true"))ستعمل عملية التحميل على تحليل ملف * .csv باستخدام مكتبة Databricks spark-csv وإرجاع إطار بيانات بأسماء الأعمدة كما هو الحال في سطر العنوان الأول في الملف.
فيما يلي المعلمات التي تم تمريرها لتحميل الأسلوب.
- المصدر : "com.databricks.spark.csv" يخبر شرارة أننا نريد تحميل كملف csv.
- خيارات:
- المسار - مسار الملف ، حيث يوجد.
- Header : "header" -> "true" تخبر شرارة لتعيين السطر الأول من الملف لأسماء الأعمدة لإطار البيانات الناتج.
دعنا نرى ما هو مخطط إطار البيانات لدينا
تحقق من بيانات العينة في إطار البيانات لدينا
scala> airportDF.show

الاستعلام عن بيانات CSV باستخدام الجداول المؤقتة:

لتنفيذ استعلام على جدول ، نقوم باستدعاء طريقة sql () في SQLContext.
لقد أنشأنا إطار بيانات المطارات وقمنا بتحميل بيانات CSV ، للاستعلام عن بيانات DF هذه ، يتعين علينا تسجيلها كجدول مؤقت يسمى المطارات.
>
scala> airportDF.registerTempTable("airports")
دعنا نتعرف على عدد المطارات الموجودة في الجزء الجنوبي الشرقي في مجموعة البيانات الخاصة بنا
scala> sqlContext.sql("select AirportID, Name, Latitude, Longitude from airports where Latitude<0 and Longitude>0").collect.foreach(println)
[1,Goroka,-6.081689,145.391881]
[2,Madang,-5.207083,145.7887]
[3,Mount Hagen,-5.826789,144.295861
]
[4,Nadzab,-6.569828,146.726242]
[5,Port Moresby Jacksons Intl,-9.443383,147.22005]
[6,Wewak Intl,-3.583828,143.669186]
يمكننا إجراء تجميعات في استعلامات SQL على Spark
سنكتشف عدد المدن الفريدة التي بها مطارات في كل بلد
scala> sqlContext.sql("select Country, count(distinct(City)) from airports group by Country").collect.foreach(println)
[Iceland,10]
[Greenland,4]
[Canada,131]
[Papua New Guinea,6]
ما هو متوسط ارتفاع المطارات (بالقدم) في كل دولة؟
scala> sqlContext.sql("select Country , avg(Altitude) from airports group by Country").collect
res6: Array[org.apache.spark.sql.Row] =Array(
[Iceland,72.8],
[Greenland,202.75],
[Canada,852.6666666666666],
[Papua New Guinea,1849.0])
الآن لمعرفة في كل منطقة زمنية كم عدد المطارات العاملة؟
scala> sqlContext.sql("select Tz , count(Tz) from airports group by Tz").collect.foreach(println)
[America/Dawson_Creek,1]
[America/Coral_Harbour,3]
[America/Halifax,9]
[America/Toronto,48]
[America/Vancouver,19]
[America/Godthab,3]
[Pacific/Port_Moresby,6]
[Atlantic/Reykjavik,10]
[America/Thule,1]
[America/St_Johns,4]
[America/Winnipeg,14]
[America/Edmonton,27]
[America/Regina,10]
يمكننا أيضًا حساب متوسط خطوط الطول والعرض لهذه المطارات في كل بلد
scala> sqlContext.sql("select Country, avg(Latitude), avg(Longitude) from airports group by Country").collect.foreach(println)
[Iceland,65.0477736,-19.5969224]
[Greenland,67.22490275,-54.124131999999996]
[Canada,53.94868565185185,-93.950036237037]
[Papua New Guinea,-6.118766666666666,145.51532]
دعونا نحسب عدد DSTs المختلفة هناك
scala> sqlContext.sql("select count(distinct(DST)) from airports").collect.foreach(println)
[4]
حفظ البيانات بصيغة CSV
حتى الآن قمنا بتحميل بيانات csv والاستعلام عنها. سنرى الآن كيفية حفظ النتائج بتنسيق CSV مرة أخرى إلى نظام الملفات.
لنفترض أننا نريد إرسال تقرير إلى العميل حول جميع المطارات في الجزء الشمالي الغربي من جميع البلدان.
دعونا نحسب ذلك أولا.
scala> val NorthWestAirportsDF=sqlContext.sql("select AirportID, Name, Latitude, Longitude from airports where Latitude>0 and Longitude<0")
NorthWestAirportsDF: org.apache.spark.sql.DataFrame = [AirportID: string, Name: string, Latitude: string, Longitude: string]
واحفظه في ملف CSV
scala> NorthWestAirportsDF.save("com.databricks.spark.csv", org.apache.spark.sql.SaveMode.ErrorIfExists, Map("path" -> "/home/poonam/NorthWestAirports.csv","header"->"true"))
فيما يلي المعلمات التي تم تمريرها لحفظ الطريقة.
- المصدر : نفس طريقة التحميل com.databricks.spark.csv التي تخبر شرارة لحفظ البيانات كملف csv.
- SaveMode : هذا يسمح للمستخدم بتحديد ما يجب القيام به مسبقًا إذا كان مسار الإخراج المحدد موجودًا بالفعل. حتى لا تضيع البيانات الموجودة عن طريق الخطأ. يمكنك رمي الخطأ أو الإلحاق أو الكتابة. هنا ، ألقينا خطأ ErrorIfExists لأننا لا نريد الكتابة فوق أي ملف موجود.
- الخيارات : هذه الخيارات هي نفسها التي مررناها لطريقة التحميل . خيارات:
- المسار - مسار الملف ، حيث يجب تخزينه.
- Header : "header" -> "true" تخبر شرارة لتعيين أسماء عمود dataframe إلى السطر الأول من ملف الإخراج الناتج.
تحويل صيغ البيانات الأخرى إلى CSV
يمكننا أيضًا تحويل أي تنسيق بيانات آخر مثل JSON والباركيه والنص إلى CSV باستخدام هذه المكتبة.
في المدونة السابقة ، قمنا بإنشاء بيانات json. يمكنك العثور عليه على جيثب
scala> val employeeDF = sqlContext.read.json("/home/poonam/employee.json")
يتيح فقط حفظه كملف CSV.
scala> employeeDF.save("com.databricks.spark.csv", org.apache.spark.sql.SaveMode.ErrorIfExists, Map("path" -> "/home/poonam/employee.csv", "header"->"true"))
خاتمة:
في هذا المنشور ، جمعنا بعض الأفكار حول بيانات المطارات باستخدام استعلامات SparkSQL التفاعلية
واستكشفت مكتبة تحليل ملفات csv من Spark
المدونة التالية سوف نستكشف مكونًا مهمًا جدًا من Spark ، أي Spark Streaming.
يسمح Spark Streaming للمستخدمين بجمع بيانات الوقت الفعلي في Spark ومعالجتها فور حدوثها وتعطي النتائج على الفور.