
كيفية استخدام كيانات Google و GPT-4 لإنشاء مخططات المقالة
نشرت: 2023-06-06في هذه المقالة ، ستتعلم كيفية استخدام بعض عمليات الكشط والرسم البياني المعرفي من Google للقيام بهندسة فورية مؤتمتة تولد مخططًا وملخصًا لمقالة ، إذا تمت كتابتها جيدًا ، فستحتوي على العديد من المكونات الرئيسية لترتيبها جيدًا.
في جذر الأشياء ، نطلب من GPT-4 إنتاج مخطط مقال بناءً على كلمة رئيسية وأهم الكيانات التي عثروا عليها في صفحة مرتبة جيدًا من اختيارك.
يتم ترتيب الكيانات حسب درجة بروزها.
"لماذا تسجل البروز؟" ربما تسال.
تصف Google البروز في مستندات API الخاصة بهم على النحو التالي:
"توفر درجة البروز الخاصة بالكيان معلومات حول أهمية أو مركزية هذا الكيان بالنسبة إلى نص المستند بأكمله. الدرجات الأقرب إلى 0 تكون أقل بروزًا ، في حين أن الدرجات الأقرب من 1.0 تكون بارزة للغاية ".
يبدو مقياسًا جيدًا لاستخدامه للتأثير على الكيانات التي يجب أن توجد في جزء من المحتوى قد ترغب في كتابته ، أليس كذلك؟
ابدء
هناك طريقتان يمكنك اتباعهما للقيام بذلك:
- اقضِ حوالي 5 دقائق (ربما 10 دقائق إذا كنت بحاجة إلى إعداد جهاز الكمبيوتر الخاص بك) وقم بتشغيل البرامج النصية من جهازك ، أو ...
- اقفز إلى Colab التي أنشأتها وابدأ اللعب على الفور.
أنا متحيز للأول ، لكنني قفزت أيضًا إلى كولاب أو اثنين في يومي. 😀
بافتراض أنك ما زلت هنا وترغب في إعداد هذا الإعداد على جهازك الخاص ولكن لم يتم تثبيت Python أو IDE (بيئة التطوير المتكاملة) ، سأوجهك أولاً إلى قراءة سريعة حول إعداد جهازك للاستخدام دفتر Jupyter. لن يستغرق الأمر أكثر من 5 دقائق.
الآن ، حان وقت الانطلاق!
استخدام كيانات Google و GPT-4 لإنشاء مخططات المقالة
لتسهيل المتابعة ، سأقوم بتنسيق التوجيهات على النحو التالي:
- الخطوة : وصف موجز للخطوة التي نحن بصددها.
- الكود : الكود لإكمال تلك الخطوة.
- شرح : شرح قصير لما تقوم به الكود.
الخطوة 1: قل لي ماذا تريد
قبل أن نتعمق في إنشاء الخطوط العريضة ، نحتاج إلى تحديد ما نريد.
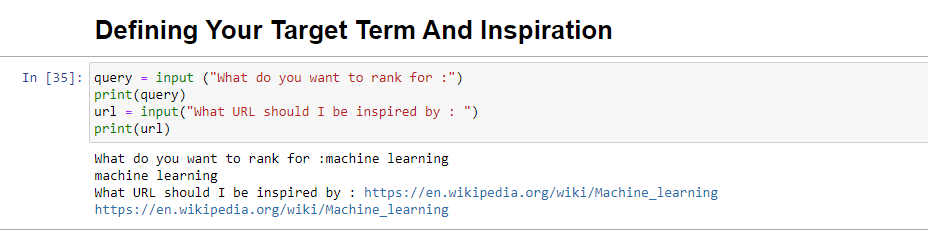
query = input ("What do you want to rank for :") print(query) url = input("What URL should I be inspired by : ") print(url)عند التشغيل ، سيطالبك هذا الحظر المستخدم (ربما أنت) بإدخال الاستعلام الذي تريد أن ترتب المقالة عليه / تكون حوله ، بالإضافة إلى منحك مكانًا لوضع عنوان URL لمقال تريده قطعة مستوحاة من.
أود أن أقترح مقالة مرتبة بشكل جيد ، بتنسيق مناسب لموقعك ، وتعتقد أنه يستحق التصنيف حسب قيمة المقالة وحدها وليس فقط قوة الموقع.
عند الجري ، سيبدو كما يلي:
الخطوة الثانية: تركيب المكتبات المطلوبة
بعد ذلك ، يجب علينا تثبيت جميع المكتبات التي سنستخدمها لتحقيق السحر.
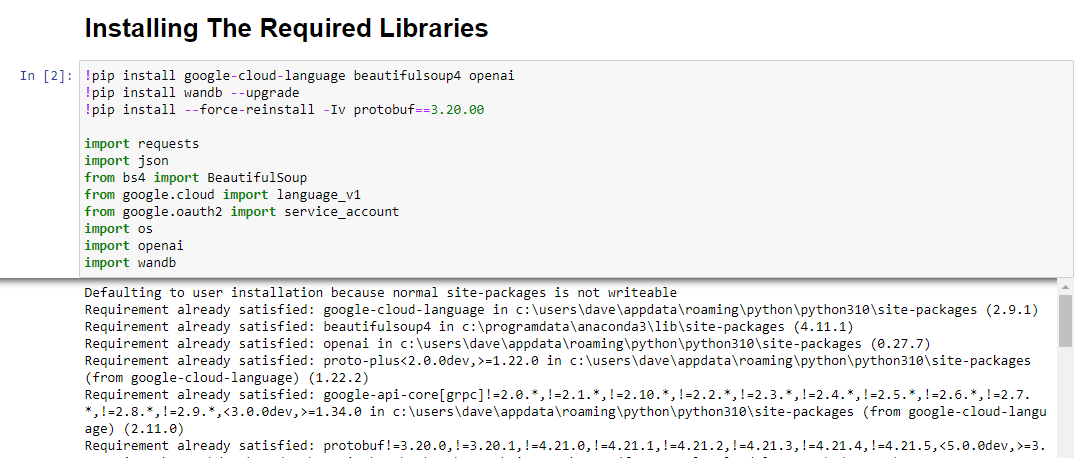
!pip install google-cloud-language beautifulsoup4 openai !pip install wandb --upgrade !pip install --force-reinstall -Iv protobuf==3.20.00 import requests import json from bs4 import BeautifulSoup from google.cloud import language_v1 from google.oauth2 import service_account import os import openai import pandas as pd import wandbنقوم بتثبيت المكتبات التالية:
- الطلبات : تسمح هذه المكتبة بإجراء طلبات HTTP لاسترداد المحتوى من مواقع الويب أو واجهات برمجة تطبيقات الويب.
- JSON : يوفر وظائف للعمل مع بيانات JSON ، بما في ذلك تحليل سلاسل JSON في كائنات Python وتسلسل كائنات Python في سلاسل JSON.
- BeautifulSoup : تُستخدم هذه المكتبة لأغراض تجريف الويب. يساعد في التحليل والتنقل في مستندات HTML أو XML واستخراج المعلومات ذات الصلة منها.
- Google.cloud.language_v1 : هي مكتبة من Google Cloud توفر إمكانات معالجة اللغة الطبيعية. يسمح لأداء المهام المختلفة مثل تحليل المشاعر والتعرف على الكيانات وتحليل بناء الجملة على البيانات النصية.
- Google.oauth2.service_account : هذه المكتبة جزء من حزمة Google OAuth2 Python. يوفر دعمًا للمصادقة باستخدام Google APIs باستخدام حساب خدمة ، وهي طريقة لمنح وصول محدود إلى موارد مشروع Google Cloud.
- نظام التشغيل : توفر هذه المكتبة طريقة للتفاعل مع نظام التشغيل. يسمح بالوصول إلى وظائف مختلفة مثل عمليات الملفات ومتغيرات البيئة وإدارة العمليات.
- OpenAI : هذه المكتبة هي حزمة OpenAI Python. يوفر واجهة للتفاعل مع نماذج لغة OpenAI ، بما في ذلك GPT-4 (و 3). يسمح للمطورين بإنشاء نص وتنفيذ عمليات إكمال النص والمزيد.
- الباندا : مكتبة قوية لمعالجة البيانات وتحليلها. يوفر هياكل ووظائف للبيانات للتعامل بكفاءة مع البيانات المنظمة وتحليلها ، مثل الجداول أو ملفات CSV.
- WandB : هذه المكتبة تعني "الأوزان والتحيزات" وهي أداة لتتبع التجربة والتصور. يساعد في تسجيل وتصور المقاييس والمعلمات الفائقة والجوانب المهمة الأخرى لتجارب التعلم الآلي.
عند الجري ، يبدو كالتالي:
احصل على النشرة الإخبارية اليومية التي يعتمد عليها المسوقون.
انظر الشروط.
الخطوة 3: المصادقة
سأضطر إلى تشتيت انتباهنا للحظة للتراجع والحصول على مصادقتنا في مكانها. سنحتاج إلى مفتاح OpenAI API وبيانات اعتماد Google Knowledge Graph Search.
لن يستغرق ذلك سوى بضع دقائق.
الحصول على OpenAI API الخاص بك
في الوقت الحالي ، من المحتمل أن تحتاج إلى الانضمام إلى قائمة الانتظار. أنا محظوظ لأنني تمكنت من الوصول إلى واجهة برمجة التطبيقات مبكرًا ، ولذا أكتب هذا لمساعدتك في الإعداد بمجرد الحصول عليها.
صور التسجيل مأخوذة من GPT-3 وسيتم تحديثها لـ GPT-4 بمجرد أن يصبح التدفق متاحًا للجميع.
قبل أن تتمكن من استخدام GPT-4 ، ستحتاج إلى مفتاح API للوصول إليه.
للحصول على واحدة ، ما عليك سوى التوجه إلى صفحة منتج OpenAI ، والنقر فوق البدء .
اختر طريقة التسجيل الخاصة بك (اخترت Google) وقم بإجراء عملية التحقق. ستحتاج إلى الوصول إلى هاتف يمكنه تلقي رسائل نصية لهذه الخطوة.
بمجرد اكتمال ذلك ، ستقوم بإنشاء مفتاح API. هذا حتى يتمكن OpenAI من ربط البرامج النصية بحسابك.
يجب أن يعرفوا من يفعل ماذا وأن يحددوا ما إذا كان يجب أن يفرضوا عليك رسومًا مقابل ما تفعله ومقدار ذلك.
تسعير OpenAI
عند التسجيل ، ستحصل على رصيد بقيمة 5 دولارات مما يجعلك تحصل على الكثير بشكل مدهش إذا كنت تقوم بالتجربة فقط.
حتى كتابة هذه السطور ، كان ماضي التسعير هو:

إنشاء مفتاح OpenAI الخاص بك
لإنشاء مفتاحك ، انقر فوق ملف التعريف الخاص بك في الجزء العلوي الأيمن واختر عرض مفاتيح API .
... وبعد ذلك ستنشئ مفتاحك.
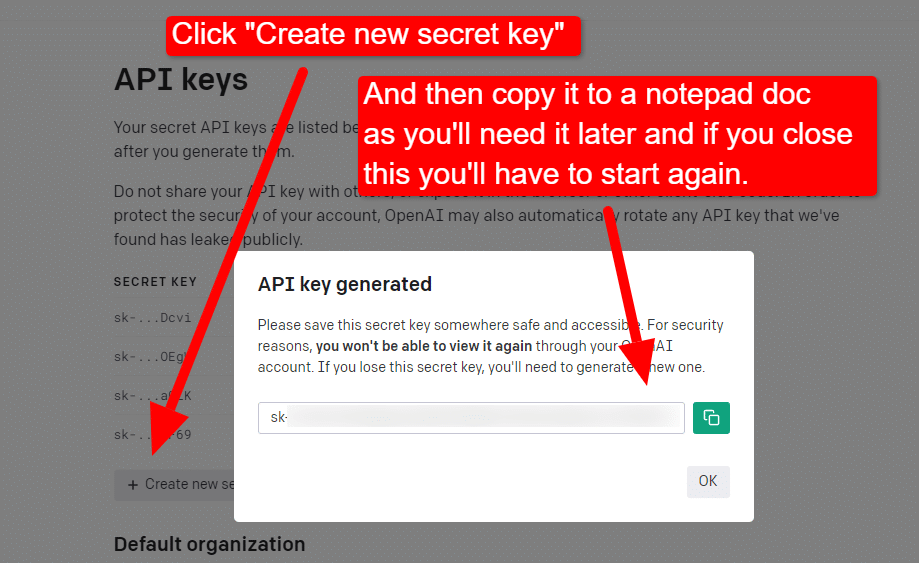
بمجرد إغلاق Lightbox ، لا يمكنك عرض مفتاحك وسيتعين عليك إعادة إنشائه ، لذلك بالنسبة لهذا المشروع ، ما عليك سوى نسخه إلى مستند Notepad لاستخدامه قريبًا.
ملاحظة: لا تحفظ مفتاحك (مستند المفكرة الموجود على سطح المكتب ليس آمنًا للغاية). بمجرد استخدامه للحظات ، أغلق مستند المفكرة دون حفظه.
الحصول على مصادقة Google Cloud
أولاً ، ستحتاج إلى تسجيل الدخول إلى حساب Google الخاص بك. (أنت على أحد مواقع تحسين محركات البحث ، لذا أفترض أن لديك واحدًا. 🙂)
بمجرد القيام بذلك ، يمكنك مراجعة معلومات واجهة برمجة تطبيقات الرسم البياني المعرفي إذا شعرت بالميل الشديد أو انتقل مباشرة إلى وحدة تحكم واجهة برمجة التطبيقات وانطلق.
بمجرد وصولك إلى وحدة التحكم:
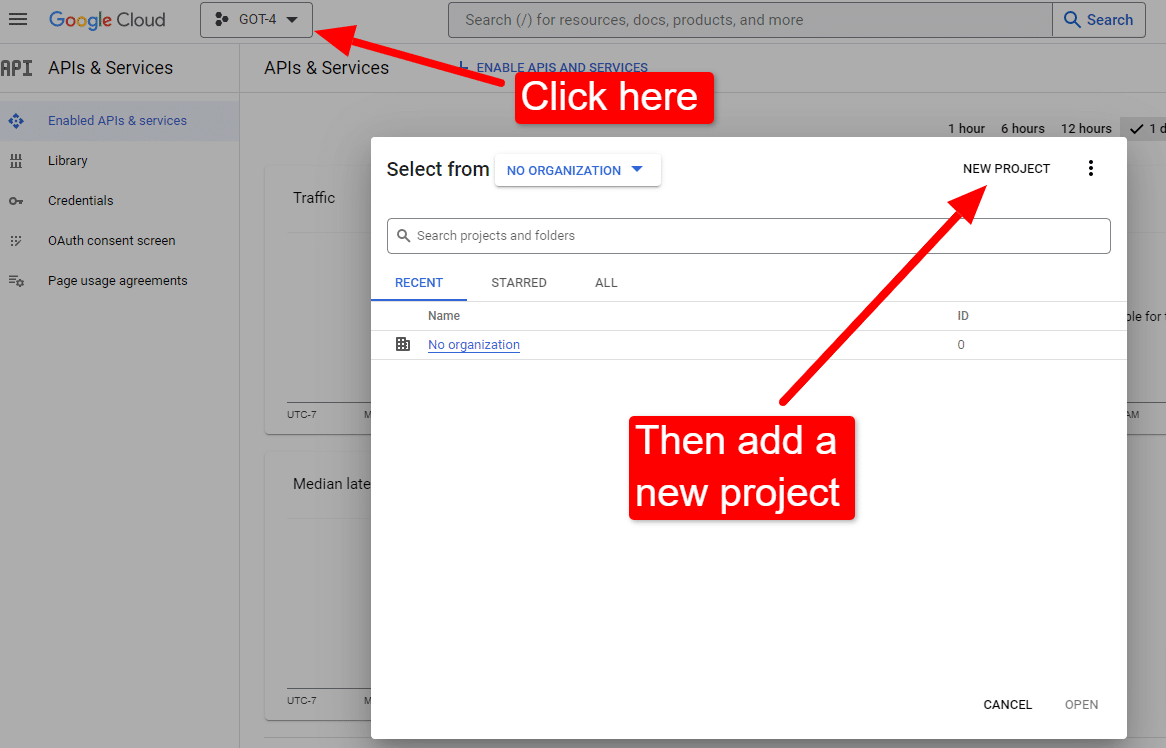
سمها بشيء مثل "مقالات ديف الرائعة". أنت تعرف ... من السهل تذكرها.
بعد ذلك ، ستقوم بتمكين API بالنقر فوق تمكين واجهات برمجة التطبيقات والخدمات .
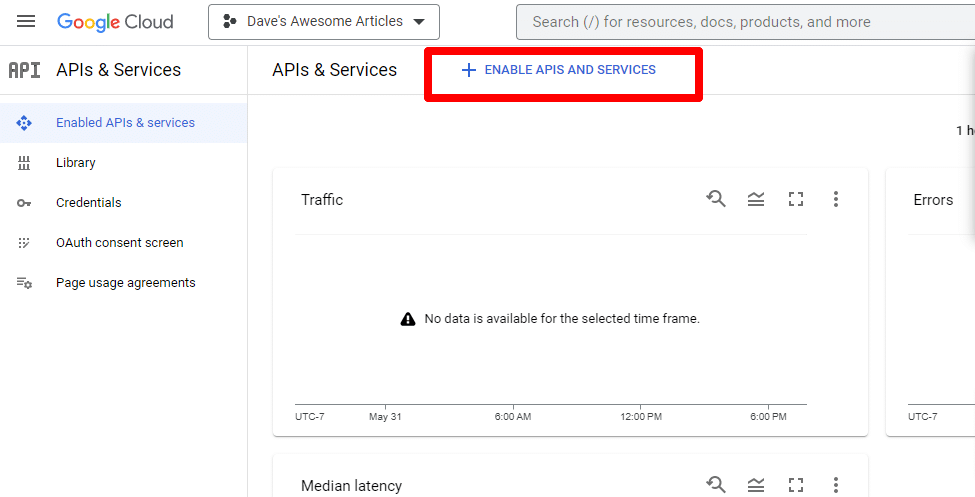
ابحث عن واجهة برمجة تطبيقات البحث في الرسم البياني المعرفي ، وقم بتمكينها.

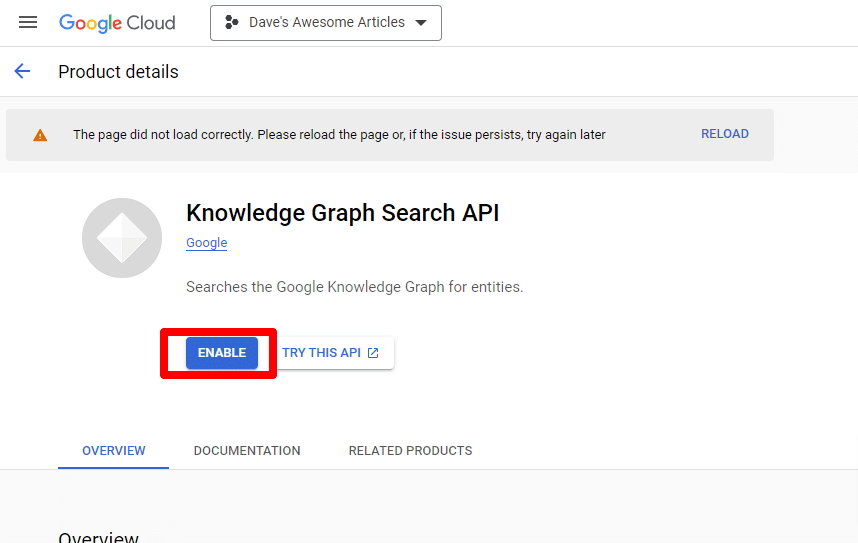
ستتم إعادتك بعد ذلك إلى صفحة واجهة برمجة التطبيقات الرئيسية ، حيث يمكنك إنشاء بيانات اعتماد:
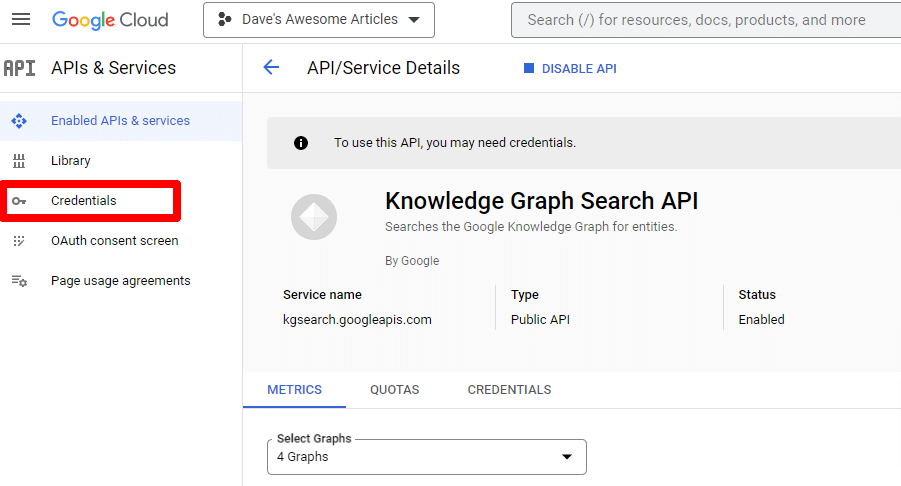
وسننشئ حساب خدمة.
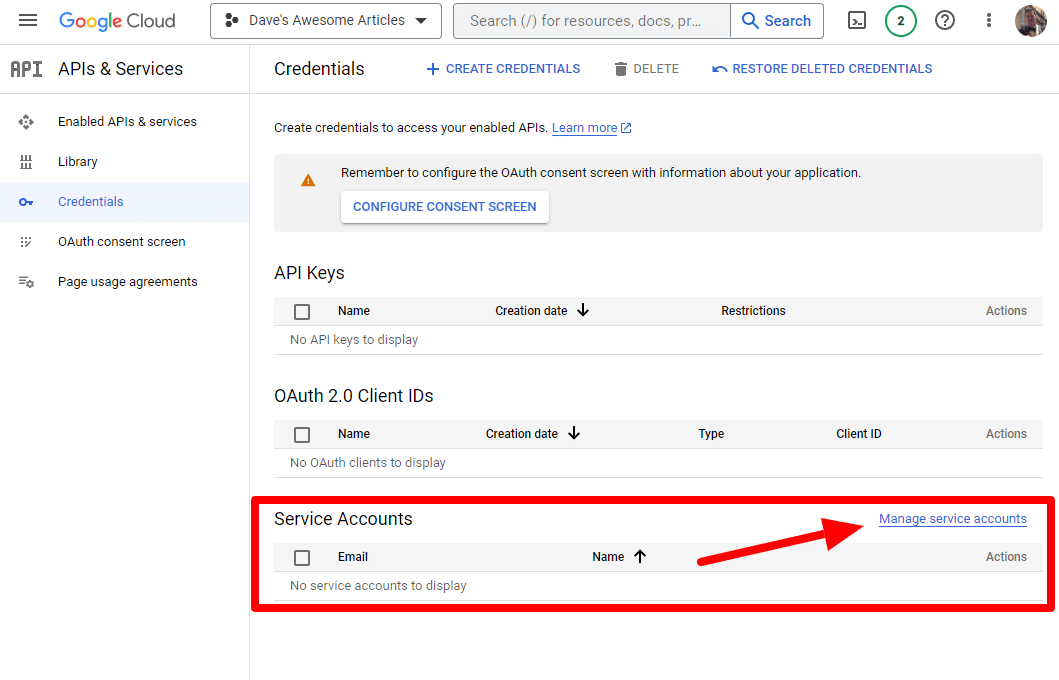
ببساطة قم بإنشاء حساب خدمة:
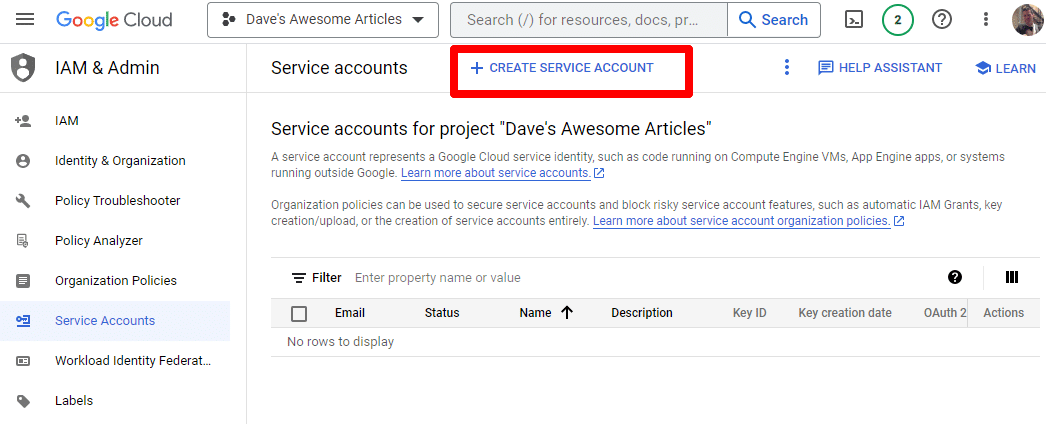
املأ المعلومات المطلوبة:
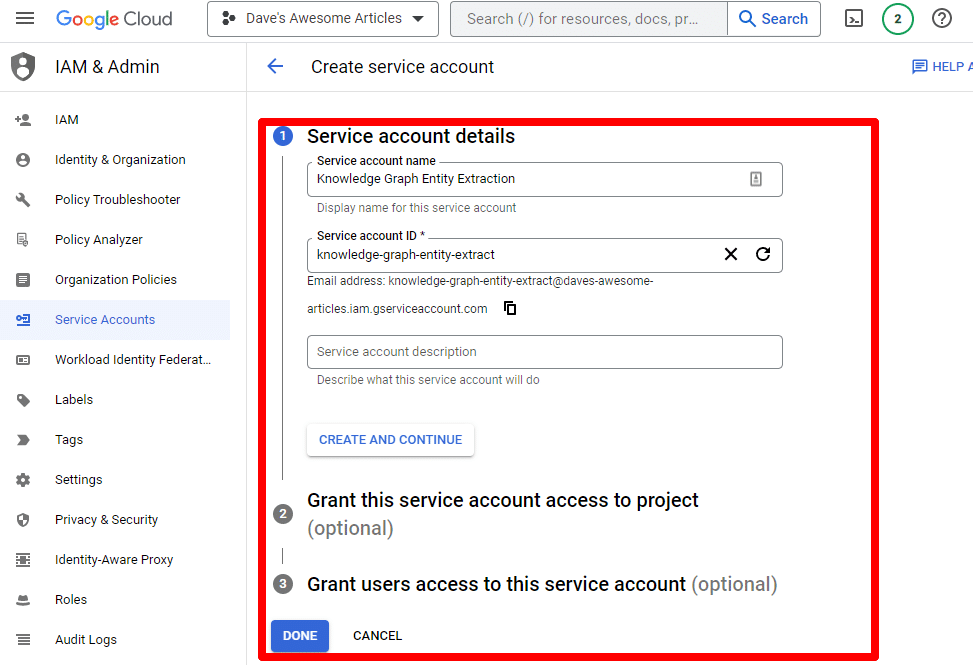
(ستحتاج إلى إعطائها اسمًا ومنحها امتيازات المالك.)
الآن لدينا حساب خدمتنا. كل ما تبقى هو إنشاء مفتاحنا.
انقر فوق النقاط الثلاث ضمن الإجراءات وانقر فوق إدارة المفاتيح .
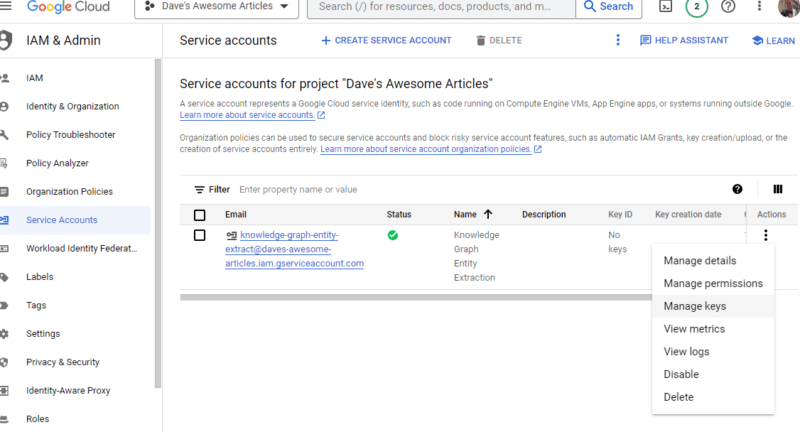
انقر فوق إضافة مفتاح ثم إنشاء مفتاح جديد :
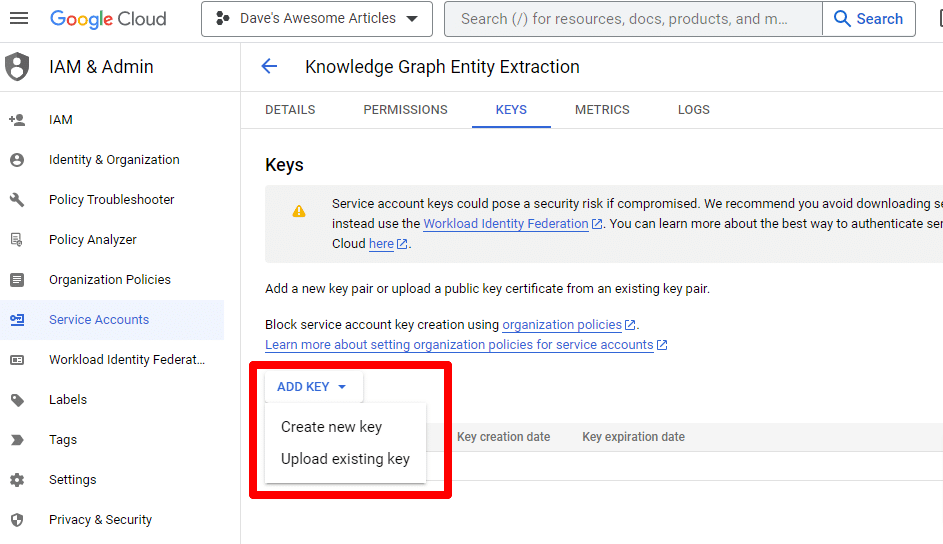
سيكون نوع المفتاح هو JSON.
على الفور ، سترى تنزيله إلى موقع التنزيل الافتراضي الخاص بك.
يمنحك هذا المفتاح إمكانية الوصول إلى واجهات برمجة التطبيقات الخاصة بك ، لذا احتفظ بها آمنة ، تمامًا مثل OpenAI API.
حسنًا ... لقد عدنا. جاهز للاستمرار مع السيناريو الخاص بنا؟
الآن بعد أن أصبح لدينا ، نحتاج إلى تحديد مفتاح API الخاص بنا والمسار إلى الملف الذي تم تنزيله. الكود للقيام بذلك هو:
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = '/PATH-TO-FILE/FILENAME.JSON' %env OPENAI_API_KEY=YOUR_OPENAI_API_KEY openai.api_key = os.environ.get("OPENAI_API_KEY") ستستبدل YOUR_OPENAI_API_KEY بمفتاحك الخاص.
ستقوم أيضًا باستبدال /PATH-TO-FILE/FILENAME.JSON بالمسار إلى مفتاح حساب الخدمة الذي قمت بتنزيله للتو ، بما في ذلك اسم الملف.
قم بتشغيل الخلية وأنت على استعداد للمضي قدمًا.
الخطوة 4: إنشاء الوظائف
بعد ذلك ، سننشئ الوظائف من أجل:
- كشط صفحة الويب التي أدخلناها أعلاه.
- تحليل المحتوى واستخراج الكيانات.
- قم بإنشاء مقال باستخدام GPT-4.
#The function to scrape the web page def scrape_url(url): response = requests.get(url) soup = BeautifulSoup(response.content, "html.parser") paragraphs = soup.find_all("p") text = " ".join([p.get_text() for p in paragraphs]) return text #The function to pull and analyze the entities on the page using Google's Knowledge Graph API def analyze_content(content): client = language_v1.LanguageServiceClient() response = client.analyze_entities( request={"document": language_v1.Document(content=content, type_=language_v1.Document.Type.PLAIN_TEXT), "encoding_type": language_v1.EncodingType.UTF8} ) top_entities = sorted(response.entities, key=lambda x: x.salience, reverse=True)[:10] for entity in top_entities: print(entity.name) return top_entities #The function to generate the content def generate_article(content): openai.api_key = os.environ["OPENAI_API_KEY"] response = openai.ChatCompletion.create( messages = [{"role": "system", "content": "You are a highly skilled writer, and you want to produce articles that will appeal to users and rank well."}, {"role": "user", "content": content}], model="gpt-4", max_tokens=1500, #The maximum with GPT-3 is 4096 including the prompt n=1, #How many results to produce per prompt #best_of=1 #When n>1 completions can be run server-side and the "best" used stop=None, temperature=0.8 #A number between 0 and 2, where higher numbers add randomness ) return response.choices[0].message.content.strip()هذا إلى حد كبير بالضبط ما تصفه التعليقات. نقوم بإنشاء ثلاث وظائف للأغراض الموضحة أعلاه.
ستلاحظ العيون الشديدة:
messages = [{"role": "system", "content": "You are a highly skilled writer, and you want to produce articles that will appeal to users and rank well."}, يمكنك تحرير المحتوى ( You are a highly skilled writer, and you want to produce articles that will appeal to users and rank well. ) ووصف الدور الذي تريد أن يقوم به ChatGPT. يمكنك أيضًا إضافة نغمة (على سبيل المثال ، "أنت كاتب ودود ...").
الخطوة 5: كشط عنوان URL واطبع الكيانات
الآن نحن نتسخ أيدينا. انه الوقت ل:
- كشط عنوان URL الذي أدخلناه أعلاه.
- اسحب كل المحتوى الموجود داخل علامات الفقرة.
- قم بتشغيله من خلال Google Knowledge Graph API.
- إخراج الكيانات لمعاينة سريعة.
في الأساس ، تريد أن ترى أي شيء في هذه المرحلة. إذا لم تر شيئًا ، فتحقق من موقع مختلف.
content = scrape_url(url) entities = analyze_content(content)يمكنك أن ترى أن السطر الأول يستدعي الوظيفة التي تلغي عنوان URL الذي أدخلناه أولاً. يحلل السطر الثاني المحتوى لاستخراج الكيانات والمقاييس الرئيسية.
يطبع جزء من وظيفة analysis_content أيضًا قائمة بالكيانات التي تم العثور عليها للرجوع إليها سريعًا والتحقق منها.
الخطوة السادسة: تحليل الكيانات
عندما بدأت اللعب بالسيناريو لأول مرة ، بدأت بـ 20 كيانًا واكتشفت سريعًا أن هذا كثيرًا في العادة. لكن هل التقصير (10) صحيح؟
لمعرفة ذلك ، سنكتب البيانات إلى W & B Tables لسهولة التقييم. ستحتفظ بالبيانات إلى أجل غير مسمى للتقييم المستقبلي.
أولاً ، ستحتاج إلى حوالي 30 ثانية للتسجيل. (لا تقلق ، إنه مجاني لهذا النوع من الأشياء!) يمكنك القيام بذلك على https://wandb.ai/site.
بمجرد القيام بذلك ، فإن الكود للقيام بذلك هو:
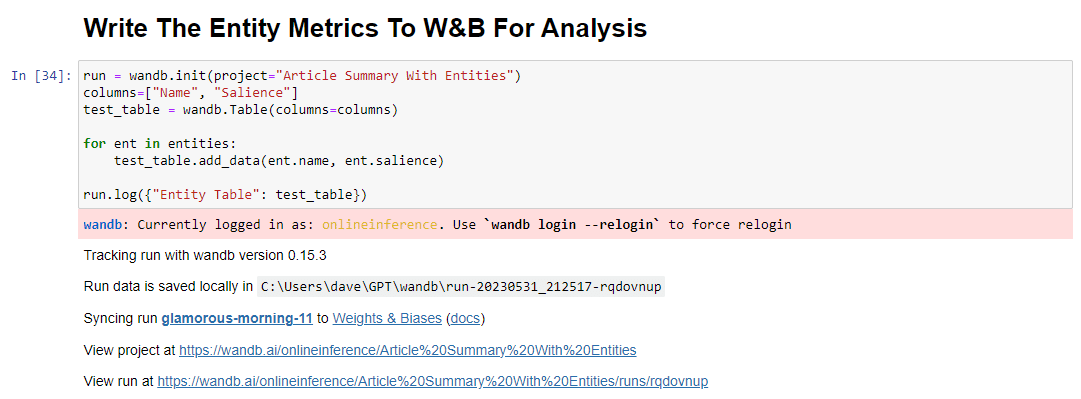
run = wandb.init(project="Article Summary With Entities") columns=["Name", "Salience"] ent_table = wandb.Table(columns=columns) for entity in entities: ent_table.add_data(entity.name, entity.salience) run.log({"Entity Table": ent_table}) wandb.finish()عند التشغيل ، يبدو الإخراج كما يلي:
وعندما تنقر على الرابط لعرض الجري ، ستجد:
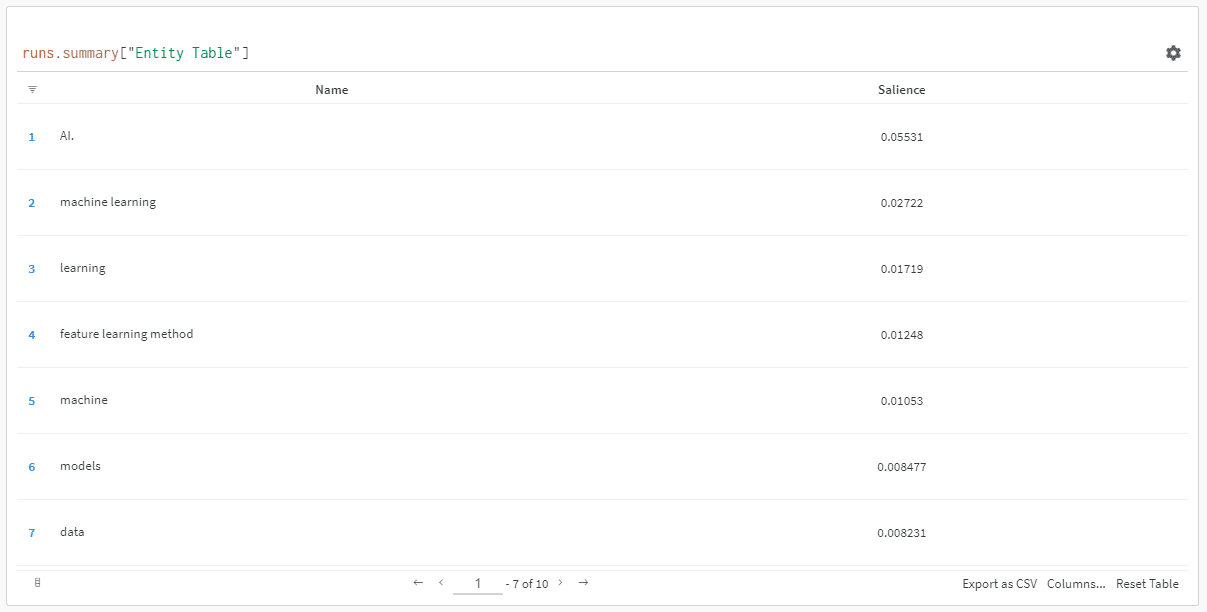
يمكنك أن ترى انخفاضًا في درجة البروز. تذكر أن هذه النتيجة تحسب مدى أهمية هذا المصطلح للصفحة ، وليس الاستعلام.
عند مراجعة هذه البيانات ، يمكنك اختيار تعديل عدد الكيانات بناءً على الأهمية ، أو فقط عندما ترى عبارات غير ذات صلة منبثقة.
لضبط عدد الكيانات ، عليك التوجه إلى خلية الوظائف وتعديل:
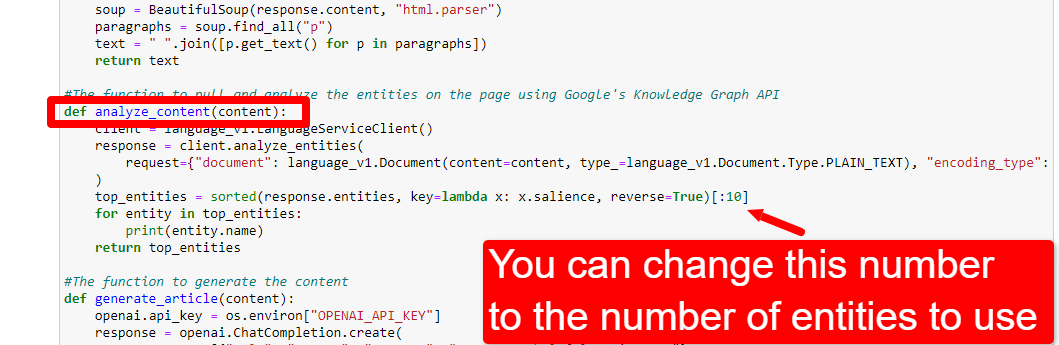
ستحتاج بعد ذلك إلى تشغيل الخلية مرة أخرى والخلية التي قمت بتشغيلها لكشط المحتوى وتحليله لاستخدام عدد الكيانات الجديد.
الخطوة 7: إنشاء مخطط المقال
في اللحظة التي كنت تنتظرها جميعًا ، حان الوقت لإنشاء مخطط المقالة.
يتم ذلك في جزأين. أولاً ، نحتاج إلى إنشاء الموجه عن طريق إضافة الخلية:
entity_names = [entity.name for entity in entities] gpt_prompt = f"Create an outline for an article about {query} that includes the following entities: {', '.join(entity_names)}." print(gpt_prompt)يؤدي هذا بشكل أساسي إلى إنشاء مطالبة لإنشاء مقالة:

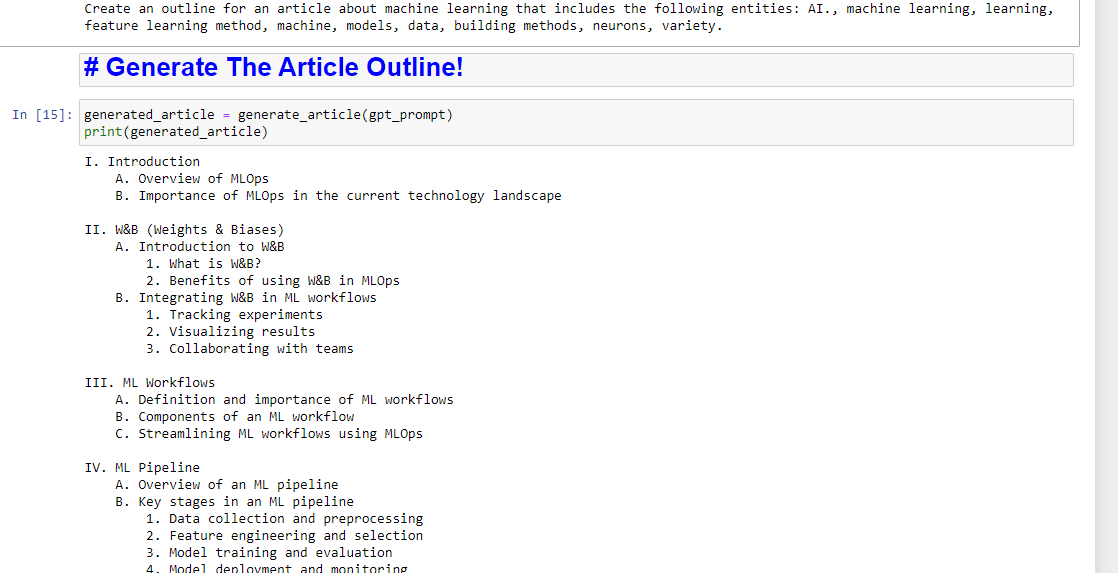
وبعد ذلك ، كل ما تبقى هو إنشاء مخطط المقالة باستخدام ما يلي:
generated_article = generate_article(gpt_prompt) print(generated_article)والذي سينتج شيئًا مثل:
وإذا كنت ترغب أيضًا في كتابة ملخص ، فيمكنك إضافة:
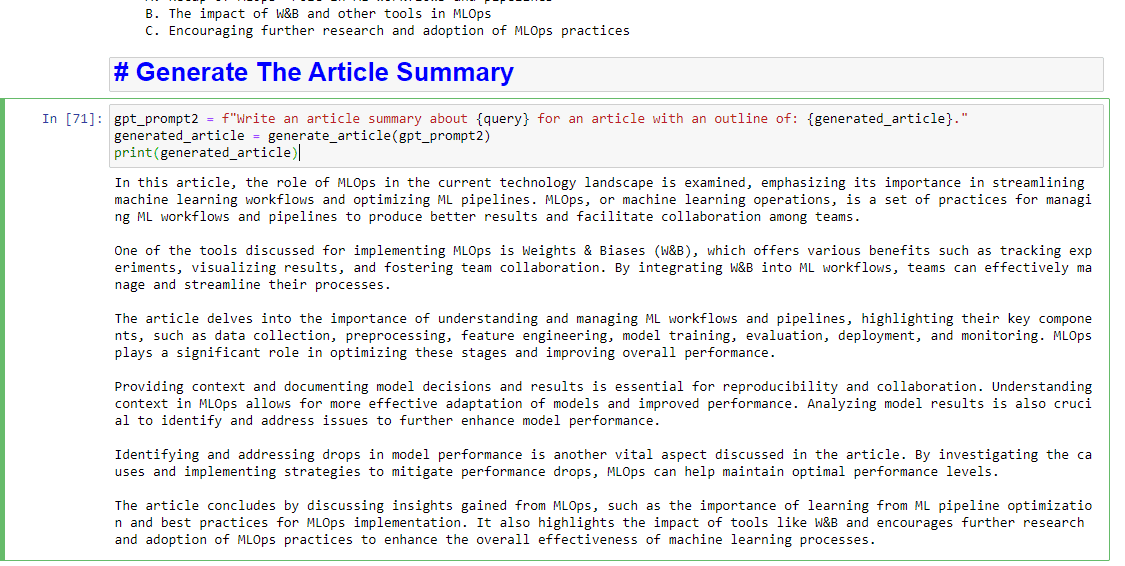
gpt_prompt2 = f"Write an article summary about {query} for an article with an outline of: {generated_article}." generated_article = generate_article(gpt_prompt2) print(generated_article)والذي سينتج شيئًا مثل:
الآراء الواردة في هذا المقال هي آراء المؤلف الضيف وليست بالضرورة آراء محرك البحث. مؤلفو طاقم العمل مدرجون هنا.