
كيفية تحقيق أقصى استفادة من Google Search Console API باستخدام regex
نشرت: 2022-11-02Google Search Console هي أداة رائعة توفر بيانات بحث لا تقدر بثمن من قبل مستخدمين حقيقيين مباشرة من Google. في حين أن المخططات والجداول سهلة الاستخدام ، لا يمكن الوصول إلى جزء كبير من البيانات من واجهة المستخدم.
الطريقة الوحيدة للوصول إلى هذه البيانات المخفية هي استخدام واجهة برمجة التطبيقات واستخراج كل بيانات البحث القيمة المتاحة لك - إذا كنت تعرف كيف. هذا ممكن مع التعبيرات النمطية.
إليك كيفية تعظيم واجهة برمجة تطبيقات Google Search Console باستخدام التعبيرات العادية ، وفقًا لإريك وو ، نائب رئيس نمو المنتجات في شركة Honey ، وهي شركة PayPal ، الذي تحدث في SMX Advanced.
تشخيص مشكلات تحسين محركات البحث باستخدام GSC
هل تعمل على موقع ويب يعاني من ركود أو انخفاض في النمو أو انخفاض في التحديث الأساسي؟
يلجأ معظم محترفي تحسين محركات البحث إلى Google Search Console (GSC) لتشخيص مثل هذه المشكلات.
(أو إذا سمحت الموارد ، يمكنك حتى استخدام أداة مدفوعة مثل Ryte أو إنشاء النظام الأساسي الخاص بك.)
لحسن الحظ بالنسبة لمجتمع تحسين محركات البحث (SEO) ، لا يوجد نقص في لوحات معلومات Looker Studio (المعروفة سابقًا باسم Google Data Studio) المفيدة لتحليل GSC ، بما في ذلك:
- لوحة القيادة المجانية لـ Aleyda Solis ، والتي تستخدم بيانات GSC للتعرف بسهولة على تغييرات التصنيف المحتملة في الأيام الأخيرة من Google Core Update.
- لوحة تحكم مراقبة حركة مرور البحث من Google ، والتي تسحب الآن بيانات حركة المرور Discover و Google News.
- استوديو هانا بتلر Search Console Explorer. (وإذا كنت تريد التعامل مع بيانات GSC عمليًا والعثور على رؤى سريعة ، فيمكنك استخدام ورقة مستكشف Search Console من Butler.)
تسمح لوحات المعلومات لمحترفي محركات البحث بإلقاء نظرة عامة على الاتجاهات المختلفة بدلاً من استخدام GSC والقيام بعدة نقرات للوصول إلى البيانات التي تحتاجها.
ولكن إذا كنت تقوم بتحليل مواقع الشركات ، فيمكنك مواجهة بعض الحواجز.
- يتم تحميل كل من Looker Studio و Google Sheets ببطء ، خاصة عندما تتعامل مع مواقع كبيرة.
- واجهة GSC لها حد تصدير 1000 صف.
- GSC لديه مشكلة كبيرة في أخذ العينات. تفقد فرق تحسين محركات البحث في Enterprise 90٪ من كلماتها الرئيسية في GSC ، وفقًا لموقع مماثل. وإذا كنت تعرف كيفية استخراج البيانات ، فيمكنك في الواقع الحصول على 14 ضعفًا من الكلمات الرئيسية.
التغلب على مشكلة أخذ العينات في GSC
Explorer for Search هو أداة أخرى يمكنك استخدامها لتحليل GSC. من Noah Learner والفريق في Two Octobers ، تم إنشاؤه باستخدام خطوط أنابيب البيانات باستخدام واجهة برمجة تطبيقات GSC والتي تقوم بعد ذلك بإخراج البيانات إلى BigQuery (بشكل أساسي تجاوز جداول بيانات Google وتنزيل ملفات CSV) ، ثم تصور المعلومات باستخدام Data Studio.
باستخدام هذا ، يمكنك أن تثق في أنك تحصل على جميع البيانات تقريبًا .
لا يزال هناك تحذير بسبب مشكلة أخذ عينات GSC ، خاصة بالنسبة لمواقع التجارة الإلكترونية الكبيرة التي تحتوي على الكثير من الفئات المختلفة. لن يعرض GSC بالضرورة جميع البيانات الواردة من تلك الدلائل.
بعد إجراء العديد من الاختبارات للحصول على أكبر قدر من البيانات من GSC API ، اكتشف فريق Similar.ai طريقة لسد فجوة أخذ عينات GSC.
وجدوا أنه من خلال إضافة المزيد من الأدلة الفرعية كملفات تعريف مختلفة داخل لوحة معلومات GSC ، يمكنك استخراج المزيد من البيانات حيث يمنحك Google مزيدًا من المعلومات في هذا المستوى الأدنى.
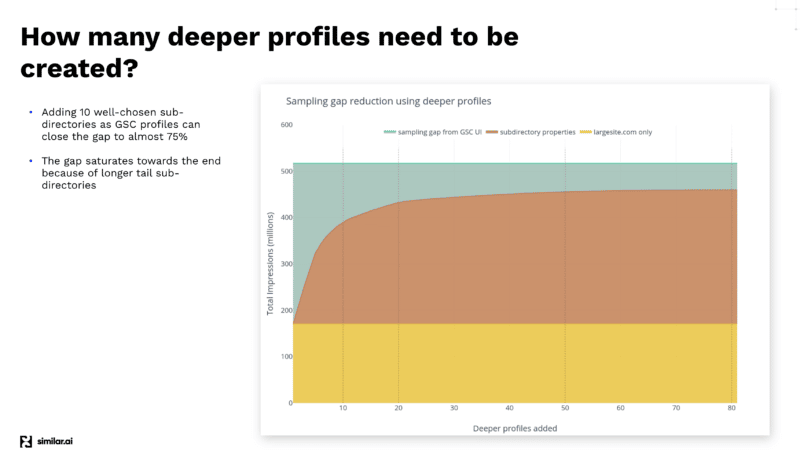
على سبيل المثال ، إذا كنت تبحث في example.com/televisions وأضفت "أجهزة تلفزيون" كدليل فرعي في ملف تعريف GSC الخاص بك ، فستمنحك Google الكلمات الرئيسية ومعلومات النقر الخاصة بهذا الدليل الفرعي وأسفله فقط.
ومن خلال إضافة الكثير من هذه الأدلة الفرعية المختلفة ، يمكنك استخراج الكثير من المعلومات.
هذا يحل مشكلة أخذ العينات ، ولكن يمكنك الحصول على المزيد من البيانات باستخدام التعبيرات العادية.
الحصول على المزيد من بيانات GSC بالتعبيرات العادية
يعد التعبير العادي ، أو regex ، أداة قوية لفهم بياناتك.
في أبريل 2021 ، أضافت Google دعم regex إلى GSC - مما أعطى مُحسّنات محرّكات البحث طرقًا أكثر لتقطيع بيانات البحث العضوية وتقطيعها.
في كثير من الأحيان ، لا تكون البيانات مفيدة ما لم تتمكن من فهمها. وتساعد regex على استخراج رؤى قابلة للتنفيذ من بيانات GSC الغنية.
ولكن بالرغم من قوتها ، قد يكون من الصعب تعلم regex.
أفضل مكان لفهم التعبيرات العادية والتعمق فيها هو وثائق Google الرسمية على GitHub. (تستخدم Google RE2 في منتجاتها ، وهي نكهة للتعبير العادي).
بينما يتوفر regex بجميع أنواع لغات البرمجة المختلفة ، ستجده في كل مكان تقريبًا حتى لأولئك الذين يعدلون ملفات .htaccess.
في الأقسام القليلة التالية ، توجد حالات استخدام للاستفادة من regex لـ GSC.
استفسارات إعلامية Regex
عند النظر إلى استعلامات البحث المعلوماتية الفعلية في GSC ، فأنت تريد عادةً فهم:
- كيف يأتي الناس فعلا إلى موقعك؟
- ما هي الأسئلة التي يستخرجونها؟
قد يكون من الصعب النظر إلى هذه الأشياء من وجهة نظر فردية داخل GSC.
أنت تبحث دائمًا عن الكلمات "ماذا" و "كيف" و "لماذا" ثم "متى".
هناك طريقتان لجعل استخراج الاستعلامات المعلوماتية أقل تعقيدًا مع regex.
شارك Daniel K. Cheung سلسلة regex ستعرض لك جميع طلبات البحث التي تحتوي على "ماذا" و "كيف" و "لماذا" و "متى" التي حصلت على نقرة أو ظهور:
-
"what|how|why|when"
وترتقي سلسلة regex التي شاركها Steve Toth في المثال السابق إلى مستوى أعلى:
-
^(who|what|where|when|why|how)[" "]
يمكنك استخدام هذه السلسلة إذا كنت تريد التقاط الاستعلامات القائمة على الأسئلة التي تبدأ إما بـ "من" و "ماذا" و "أين" و "متى" و "لماذا" و "كيف" ثم تتبعها مسافة.
هذه قائمة رائعة لاستخدامها عندما تبحث عن أي نوع من الكلمات التي قد تبدأ بسؤال:
- هي ، تستطيع ، لا تستطيع ، لا تستطيع ، لا تستطيع ، لم تفعل ، لم تفعل ، تفعل ، لا تفعل ، كيف ، إذا ، كانت ، لا ، لا ينبغي ، لا ينبغي ، لا ، كانت ، لم تكن ، لم تكن ، ماذا ، متى ، أين ، من ، من ، من ، لماذا ، سوف ، لن ، لن ، لن
سيبدو وضع كل هذا في صيغة regex كما يلي:
-
^(are|can|can't|could|couldn't|did|didn't|do|does|doesn't|how|if|is|isn't|should|shouldn't|was|wasn't|were|weren't|what|when|where|who|whom|whose|why|will|won't|would|wouldn't)\s
في هذه السلسلة المكونة من 178 حرفًا:
- لديك علامة الإقحام (
^) التي تخبرك أن طلب البحث يجب أن يبدأ بهذه الكلمة: - يتم فصل الكلمات باستخدام خطوط (
|) بدلاً من الفواصل. - كل الكلمات ملفوفة بين قوسين.
- هناك شرطة مائلة للخلف و "s" (
\s) التي تشير إلى مسافة بعد الكلمة.
هذا جيد ، ولكن يمكن أيضًا أن يكون مملاً.
أدناه ، قامت Wu بتبسيط قائمة الكلمات السابقة لتكون أكثر ملاءمة للتعبير العادي وأقصر مما يجعلها مثالية للنسخ واللصق. الحفاظ عليه بهذه الطريقة يساعد أيضًا في الكفاءة.
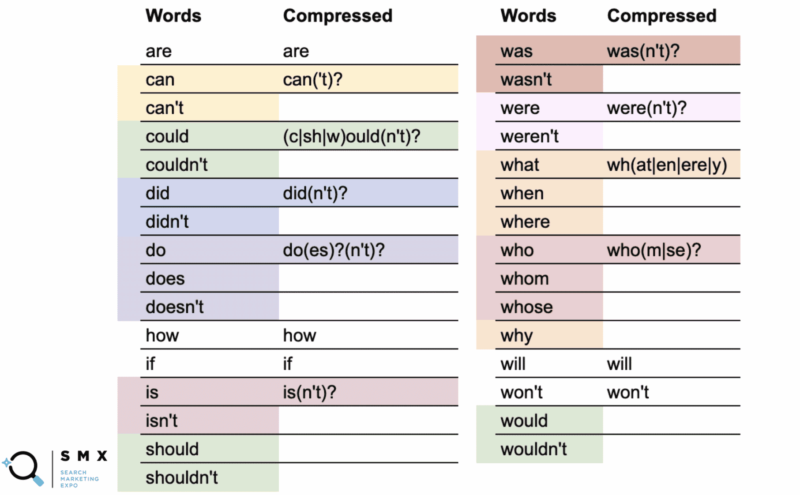
في العمود الأول هي الكلمات العادية وفي العمود الثاني ، regex مضغوط.
على سبيل المثال ، كلمة "can" تستخدم النسخة المضغوطة can('t)? .
ما تشير إليه علامة الاستفهام هو أن أي شيء داخل الأقواس اختياري. تسمح لك البنية المضغوطة بتغطية كل من كلمة "can" و "can't."
الأكثر إثارة للاهتمام ، يمكنك القيام بذلك باستخدام can / couldn't، should / shouldn't، and would / would / not where the -ould part of the words is the common base، like (c|sh|w)ould(n't)? . تغطي هذه السلسلة القصيرة جميع تلك الحالات الست.
في حين أن تبسيط تلك القائمة الطويلة من الكلمات جعل السلسلة أقل قابلية للقراءة ، فإن الشيء الرائع هو أنها تناسب أكثر في حقل regex وتسمح لك بالنسخ واللصق بشكل أسهل.
-
^(are|can('t)?|(c|sh|w)ould(n't)?|did(n't)?|do(es)?(n't)?|how|if|is(n't)?|was(n't)?|were(n't)?|wh(at|en|ere|y)who(m|se)?|will|won't)\s
إذا ذهبت إلى أبعد من ذلك ، يمكنك ضغطها أكثر. في هذه الحالة ، قلل Wu عدد الأحرف من 135 إلى 113 حرفًا.
-
^(are|can('t)?|how|if|wh(at|en|ere|y)|who(m|se)?|will|won't|((c|sh|w)ould|did(n't)?|do(es)?|was|is|were)(n't)?)\s
يمكن أن تصبح التعبيرات العادية معقدة حقًا. إذا كنت تحصل على سلسلة regex من شخص آخر وترغب في توضيح ما يفعله ، فيمكنك استخدام Regexper لمساعدتك في تصور ذلك.
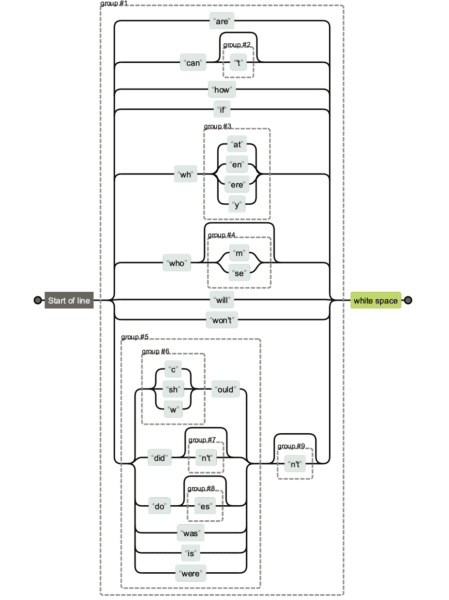
أدناه سترى مقارنة بين إصدارات سلسلة regex المختلفة. من الأسهل الحفاظ على الأول ، ومن الصعب الحفاظ عليه وقراءته الأخير.

لكن في بعض الأحيان يكون عدد الأحرف مهمًا حقًا خاصةً عندما يكون لديك تعبيرات عادية أطول.
حدود مرشح Regex لـ GSC هي 4096 حرفًا ، وفقًا لـ Google Search Advocate Daniel Waisberg.
هذا يبدو قليلا ومع ذلك ، إذا كان لديك موقع للتجارة الإلكترونية وكان عليك إضافة أسماء نطاقات أو نطاقات فرعية أو أدلة أطول ، فمن المرجح أن تصل إلى هذا الحد.
استعلامات Regex ذات العلامات التجارية
مثال آخر حيث يمكنك البدء في الوصول إلى حد أحرف regex في GSC هو عند استخدامه للاستعلامات ذات العلامات التجارية.
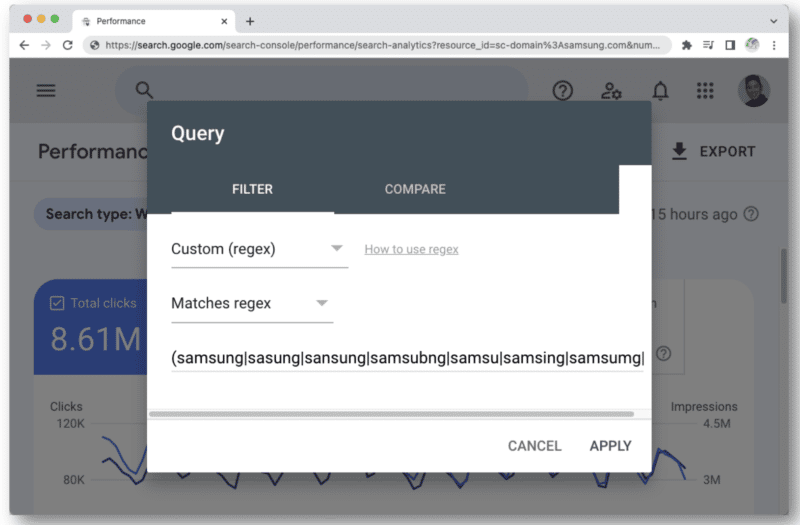
عندما تفكر في جميع الأنواع المختلفة من الأخطاء الإملائية لاسم علامة تجارية يمكن لأي شخص كتابتها ، فسوف تصادف بسرعة 4096 حرفًا. على سبيل المثال:
- aamaung، damsung، mamsang، sam sung، samaung، samdung، samesung، sameung، samgsung، samgung، samsang، samsaung، samsgu، samshgg، samshng، samsing، samsnug، samssung، samsu، samsuag، samsubg، samsubng، samgsung، samsum ، samsun g ، samsunb ، samsund ، samsund ، samsunh ، samsunt ...
هذا هو المكان الذي يساعد فيه فهم regex. باستخدام هذه السلسلة ، يمكنك تسجيل اسم العلامة التجارية "samsung" بالإضافة إلى الأخطاء الإملائية:
-
(s+|a|d|z)[az\s]{1,4}m?[az\s]{1,6}(m|u|n|g|t|h|b|v)
في كثير من الأحيان ، يخطئ الناس في تهجئة الأجزاء الوسطى من الكلمة. لكن بشكل عام ، يحصلون على التنسيق والطول بشكل صحيح ويمكنك الاقتراب من بناء الجملة الخاص بك بهذه الطريقة.
بالنسبة للأخطاء الإملائية في الاستعلام عن العلامة التجارية ، ضع في اعتبارك ما يلي:
- الحروف الرئيسية التي يتكون منها الاستعلام عن العلامة التجارية.
- الحروف الساكنة .
- الحروف المحيطة بالحروف الساكنة الصلبة .

باللون الأحمر هي الحروف الساكنة الصعبة التي لا يفوتها الناس عادةً عندما يكتبون اسم علامة تجارية. هذه هي الحروف الرئيسية التي تشكل تلك العلامة التجارية المعينة. بالنسبة إلى "samsung" ، و "s" في البداية ، و "m" في المنتصف ، ثم "n" و "g" في النهاية.

الأحرف الزرقاء المحيطة بتلك الحروف الساكنة الرئيسية على لوحة المفاتيح هي تلك التي يخطئ الناس في كتابتها. في المثال ، حول "s" ، سترى "a" و "d" و "z". (على الرغم من اختلاف التخطيط للوحات المفاتيح الدولية ، إلا أن المفهوم لا يزال كما هو).
تلتقط سلسلة regex أعلاه جميع المتغيرات المحتملة لـ "samsung".
الحيلة الرئيسية الأخرى هنا في [az\s]{1,4} .
في صيغة regex ، هذا يعني بشكل أساسي ، "أريد مطابقة أي حرف" a "مع" z "، أو مسافة ، مرة واحدة إلى أربع مرات".
يلتقط هذا كل تلك الأخطاء الإملائية الغريبة التي يمكن أن تحدث في منتصف استعلام العلامة التجارية - حيث من المحتمل أن يضغط الشخص على المفتاح نفسه عدة مرات أو يضغط على مسافة بطريق الخطأ.
بالإضافة إلى ذلك ، فإن اسم العلامة التجارية له طول معين (يتكون "samsung" من سبعة أحرف). من المحتمل ألا ينتهي الأمر بالناس بكتابة 20-50 حرفًا.
لذا في هذا التعبير العادي ، فإننا نخمن أنه بين "s" و "m" في "samsung" ، سيخطئ شخص ما في كتابة 1-4 أحرف. وبعد ذلك من "m" إلى "g" في النهاية ، سيخطئون في كتابة 1-6 أحرف ، مع تضمين المسافات.
تتيح لك إضافة كل هذا التقاط العديد من الأشكال المختلفة لاستعلام ذي علامة تجارية بشكل شامل.
الشيء الآخر الذي يجب ملاحظته هو أن اسم العلامة التجارية قد يظهر في أجزاء مختلفة من طلب البحث.

لذلك نحن بحاجة للتأكد من تسجيل اسم العلامة التجارية نفسها. يجب أن تكون إما:
- في بداية الاستعلام.
- في منتصف الاستعلام (وبالتالي محاطة بمسافات).
- أو في نهاية الاستعلام.
التعبير النمطي لهذا هو كما يلي:
-
(^|\s)(s+|a|d|z)[az\s]{1,4}m?[az\s]{1,6}(m|u|n|g|t|h|b|v)(\s|$)
هذا يلتقط جميع الاستعلامات التي يكون فيها اسم العلامة التجارية "samsung" إما في البداية أو في المنتصف أو في النهاية.
- بداية السلسلة =
^ - محاطة بمسافات =
\s - نهاية السلسلة =
$
منشور JC Chouinard ، التعابير العادية (RegEx) في Google Search Console ، يتعمق أكثر في أمثلة regex.
Regex و GSC API قيد التنفيذ
جاءت التعبيرات العادية مفيدة لو وفريقه عندما عملوا مع عميل واجه انخفاضًا في حركة المرور بعد التحديث الأساسي.
بعد النظر في المشكلات المختلفة لموقع التجارة الإلكترونية ، اكتشفوا أن المشكلة تكمن في بعض صفحات تفاصيل المنتج.
لقد احتاجوا إلى تقسيم أنواع الصفحات لتحليلها في GSC. ولكن كانت هذه مهمة معقدة بسبب هياكل عناوين URL المختلفة للمنتجات الأمريكية والدولية.

تضمنت عناوين URL الدولية للمنتجات الخاصة بالموقع رموز اللغة والبلد ، بينما لم تتضمن عناوين URL الخاصة بالمنتجات الأمريكية.
حتى استخدام بنية التعبير العادي كان أمرًا صعبًا نظرًا لوجود الأحرف والشرطات في سبيكة المنتج والفئات والفئات الفرعية. بالإضافة إلى ذلك ، احتاجوا إلى تصفية عناوين URL للمنتجات الدولية لالتقاط الصفحات الأمريكية فقط.
للحصول على جميع صفحات الهبوط + تفاصيل المنتج الأمريكية ( وليس صفحات i18n) ، توصلوا إلى سلاسل regex التالية:
تضمين: /([^/]+/){1,2}p?
استبعاد: /[a-zA-Z]{2}|[a-zA-Z]{2}-[a-zA-Z]{2}/
هنا تفصيل:

أراد الفريق مطابقة الفئة والفئة الفرعية وجميع المنتجات بحيث تضمنت:
- أي حرف ليس شرطة مائلة =
[^/]+ - دليل واحد أو دليلان =
/){1,2} - في بعض الأحيان تليها سبيكة منتج =
p?
تعني علامة الإقحام ( ^ ) عادةً بداية السلسلة. ولكن عندما يكون بين قوسين داخليين (كما في [^/] ) ، فإنه يشير إلى نفي (على سبيل المثال ، "ليس أي شيء داخل هذا المربع").
إذن هذه السلسلة /([^/]+/){1,2}p? يعني "أريد أي عدد من الأحرف ليس شرطة مائلة ، تؤدي إلى شرطة مائلة (تشير إلى الدليل) ، ويتبعها أحيانًا الحرف" p "(بادئة المنتج الرخو)."
في الوقت نفسه ، لم يرغب الفريق في مطابقة مجموعة اللغة والبلد التي تحتوي أيضًا على أحرف وشُرط ، لذلك استبعدوا:
- أي دليل مكون من حرفين =
[a-zA-Z]{2} - حرفان + حرفان lang-country combo =
[a-zA-Z]{2}-[a-zA-Z]{2}
قد يكون إنشاء تعبير عادي لمطابقة جميع رموز اللغة والدول بمفردها أمرًا شاقًا بسبب كل التركيبات الممكنة ، لذلك لم يتمكنوا من التعامل مع هذا بالطريقة التي تم اتباعها للاستعلامات المعلوماتية (حيث تم استبعاد كل نوع من المجموعات).
ولكن حتى بعد إنشاء سلاسل regex هذه ، واجهتهم مشكلة.
في Google Search Console ، يوجد حقل واحد فقط للصق سلسلة regex. سيتعين عليك اختيار إما مطابقة regex أو لا يتطابق مع regex - لا يمكنك استخدام كليهما في نفس الوقت.
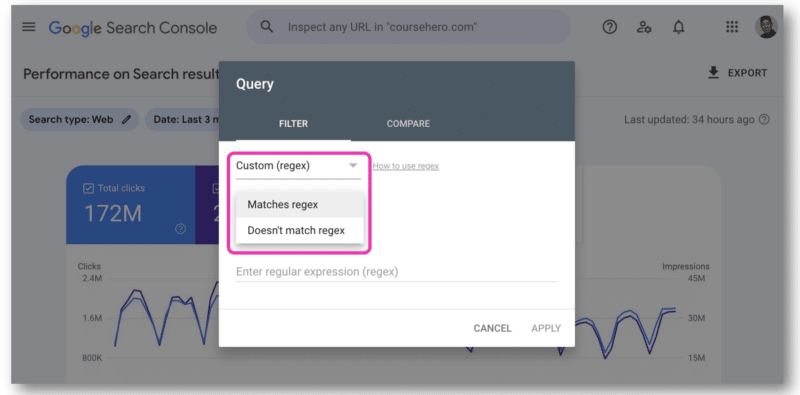
هذا هو المكان الذي أصبحت فيه واجهة برمجة تطبيقات GSC سهلة الاستخدام لأنها تتيح الانضمام إلى سلاسل regex.
في وثائق Google Search Console API ، هناك رابط جربه الآن .
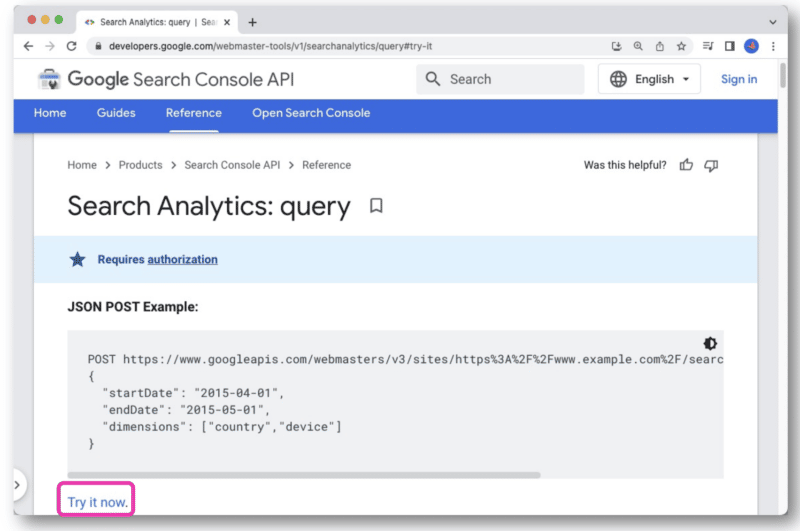
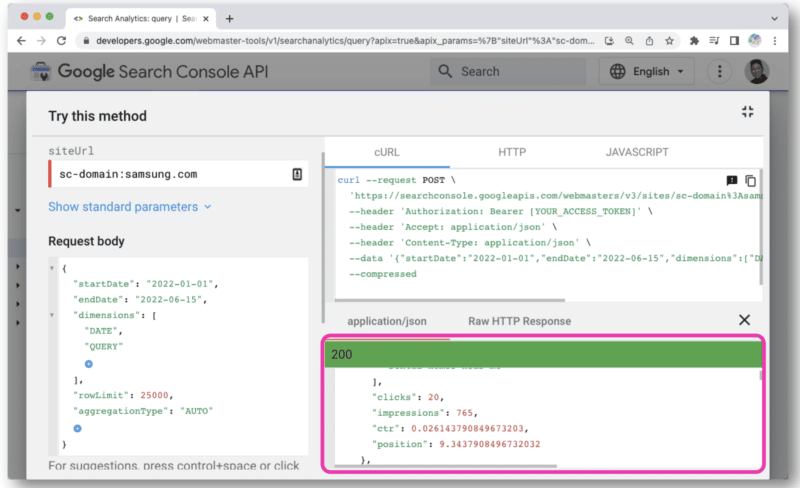
بمجرد النقر عليه ، سيفتح وحدة تحكم تسمح لك بتحديد موقع وتقديم طلب API الخاص بك من خلال عرض الويب.
ولكن لإدارة استعلامات API بشكل أفضل ، يوصي Wu باستخدام Postman على سطح المكتب أو Paw (وهو أصلي لنظام Mac).
يسمح لك Postman بإنشاء استعلامات وحفظها لوقت لاحق. وإذا كان لديك حق الوصول إلى مواقع أخرى ، فلن تضطر إلى إنشاء استعلام جديد في كل مرة. ما عليك سوى تغيير اسم الموقع باستخدام متغير ثم إجراء طلبات متعددة.
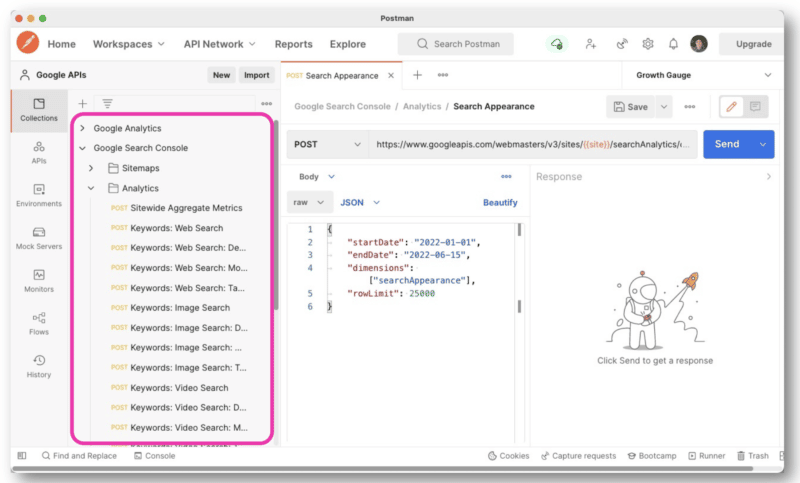
من ناحية أخرى ، من الأسهل بكثير النظر من خلال Paw والاستفادة منها.
للوصول إلى API ، ستحتاج إلى الحصول على مفاتيح API الخاصة بك. (إليك برنامج تعليمي مفيد من Chouinard.)
بمجرد حصولك على هذه المعلومات ، سيكون لديك معرف العميل الخاص بك وأسرار العميل ، والتي ستضيفها إلى مصادقة OAuth 2.0 الخاصة بك داخل Postman أو Paw.
من هناك ، ستتمكن من تسجيل الدخول بحسابك العادي.
قدم Wu طلبات GSC API بشكل أساسي باستخدام سلاسل regex في Paw. يتم إدخال الاستعلام في منتصف الواجهة.
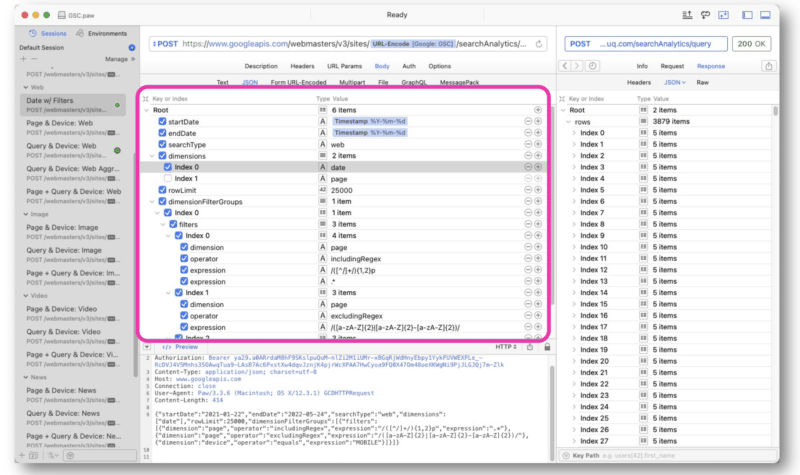
تشبه استجابة Google استجابة عرض الويب GSC API. يمكن بعد ذلك تصدير البيانات للمعالجة.
نظرًا لأن البيانات بتنسيق JSON ، يمكن أن تكون المعلومات فوضوية ويصعب قراءتها.

لهذا ، يمكنك استخدام معالج JSON لسطر الأوامر مجاني ومفتوح المصدر يسمى JQ لطباعة المعلومات بشكل جيد.

لن تكون البيانات مفيدة حتى تحصل عليها في جدول بيانات. الأنابيب في الملف الذي قمت بتصديره من Paw إلى JQ. افتحه ثم كرر كل صف - احفظ كل عنصر حتى تتمكن من إخراجهم إلى ملف CSV.
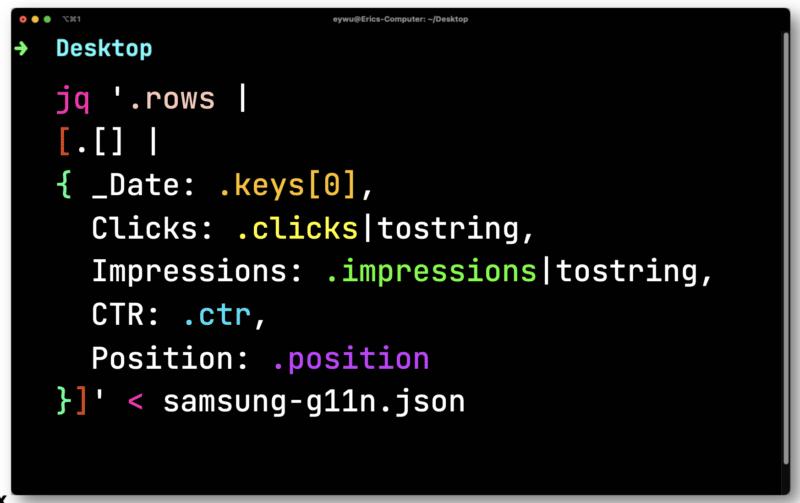
هنا ، ستحتاج إلى تحويل النقرات ومرات الظهور التي تكون عائمة (رقم به منزلة عشرية). كلاهما بحاجة إلى أن يتم تحويلهما إلى سلاسل متوافقة مع CSV.
سيقوم JQ بعد ذلك بإخراج التنسيق الأبسط التالي.
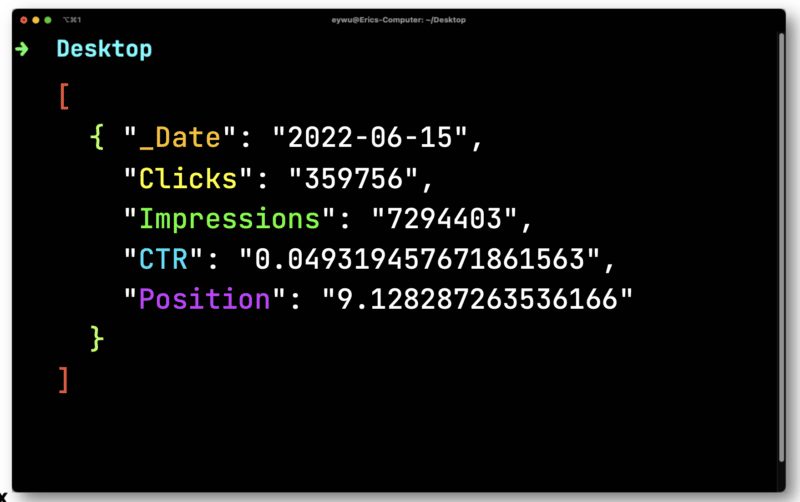
بعد ذلك ، ستستخدم Dasel لأخذ هذا التنسيق ثم تحويله إلى ملف CSV.
وهذه هي النتيجة النهائية.
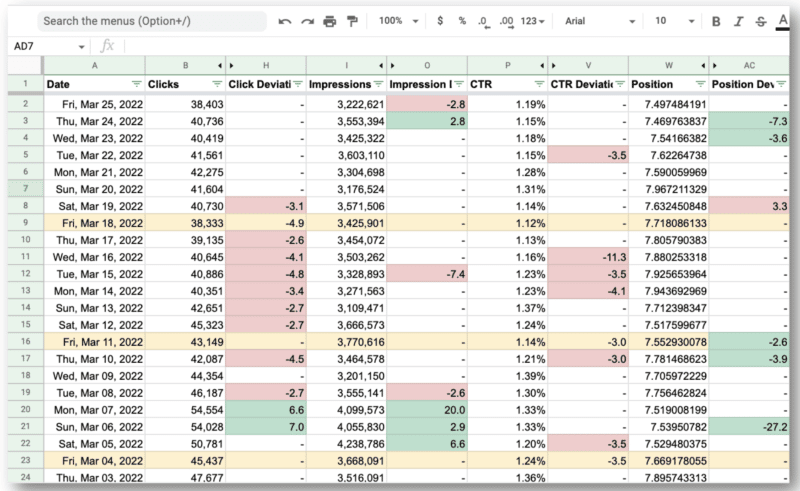
الأمر المذهل بالنسبة لفريق Wu هو أنهم كانوا قادرين على استخدام Google Search Console API والتعبيرات العادية من أجل:
- قم بتصفية جميع الاستفسارات الدولية وإلقاء نظرة على الولايات المتحدة فقط حيث كانت تواجه المشكلات الرئيسية.
- حدد الأيام التي واجه فيها الموقع مشكلات.
شاهد: تحقيق أقصى استفادة من Google Search Console API
يوجد أدناه الفيديو الكامل لعرض Wu's SMX Advanced.