
هل تستخدم Google نظامًا شبيهًا بـ ChatGPT للكشف عن البريد العشوائي ومواقع الويب الخاصة بالذكاء الاصطناعي وترتيبها؟
نشرت: 2023-02-01العنوان مضلل عمدًا - ولكن فقط فيما يتعلق باستخدام مصطلح "ChatGPT".
"ChatGPT-like" يتيح لك على الفور ، القارئ ، معرفة نوع التكنولوجيا التي أشير إليها ، بدلاً من وصف النظام بأنه "نموذج إنشاء نص مثل GPT-2 أو GPT-3." (أيضًا ، لن يكون الأخير حقًا قابلاً للنقر ...)
ما سننظر إليه في هذه المقالة هو ورقة بحثية قديمة من Google ، لكنها وثيقة الصلة بالموضوع من عام 2020 ، "النماذج التوليدية هي نماذج غير خاضعة للإشراف للتنبؤ بجودة الصفحة: دراسة على نطاق واسع."
ما هو موضوع الورقة؟
لنبدأ بوصف المؤلفين. يقدمون الموضوع وبالتالي:
"أثار الكثيرون مخاوف بشأن المخاطر المحتملة لمولدات النص العصبي في البرية ، ويرجع ذلك إلى حد كبير إلى قدرتها على إنتاج نص يشبه الإنسان على نطاق واسع.
تم مؤخرًا استخدام المصنفات المدربة على التمييز بين النص الذي تم إنشاؤه بواسطة الإنسان والآلة لمراقبة وجود نص تم إنشاؤه آليًا على الويب [29]. ومع ذلك ، فقد تم بذل القليل من العمل في تطبيق هذه المصنفات لاستخدامات أخرى ، على الرغم من خصائصها الجذابة التي لا تتطلب أي تسميات - فقط مجموعة من النص البشري ونموذج توليدي. في هذا العمل ، نظهر من خلال التقييم البشري الصارم أن أدوات التمييز الجاهزة للإنسان مقابل الآلة تعمل كمصنفات قوية لجودة الصفحة . وهذا يعني أن النصوص التي تبدو مُنشأة آليًا تميل إلى أن تكون غير متماسكة أو غير مفهومة. لفهم وجود جودة صفحة منخفضة في البرية ، نطبق المصنفات على عينة من نصف مليار صفحة ويب إنجليزية. "
ما يقولونه بشكل أساسي هو أنهم اكتشفوا أن نفس المصنفات التي تم تطويرها للكشف عن النسخ القائمة على الذكاء الاصطناعي ، باستخدام نفس النماذج لإنشائها ، يمكن استخدامها بنجاح لاكتشاف المحتوى منخفض الجودة.
بالطبع ، هذا يترك لنا سؤالًا مهمًا:
هل هذه العلاقة السببية (أي هل يلتقطها النظام لأنها جيدة حقًا) أم الارتباط (على سبيل المثال ، هل تم إنشاء الكثير من الرسائل الإلكترونية العشوائية الحالية بطريقة يسهل الالتفاف عليها باستخدام أدوات أفضل)؟
قبل أن نستكشف ذلك ، دعونا نلقي نظرة على بعض أعمال المؤلفين ونتائجهم.
وانشاء
كمرجع ، استخدموا ما يلي في تجربتهم:
- نموذجان لتوليد النص ، كاشف GPT-2 المستند إلى RoBERTa من OpenAI (كاشف يستخدم نموذج RoBERTa مع إخراج GPT-2 ويتنبأ بما إذا كان من المحتمل أن يتم إنشاؤه بواسطة AI أم لا) ونموذج GLTR ، الذي يمكنه أيضًا الوصول إلى الجزء العلوي مخرج GPT-2 ويعمل بالمثل.
يمكننا أن نرى مثالاً لإخراج هذا النموذج على المحتوى الذي نسخته من الورقة أعلاه:
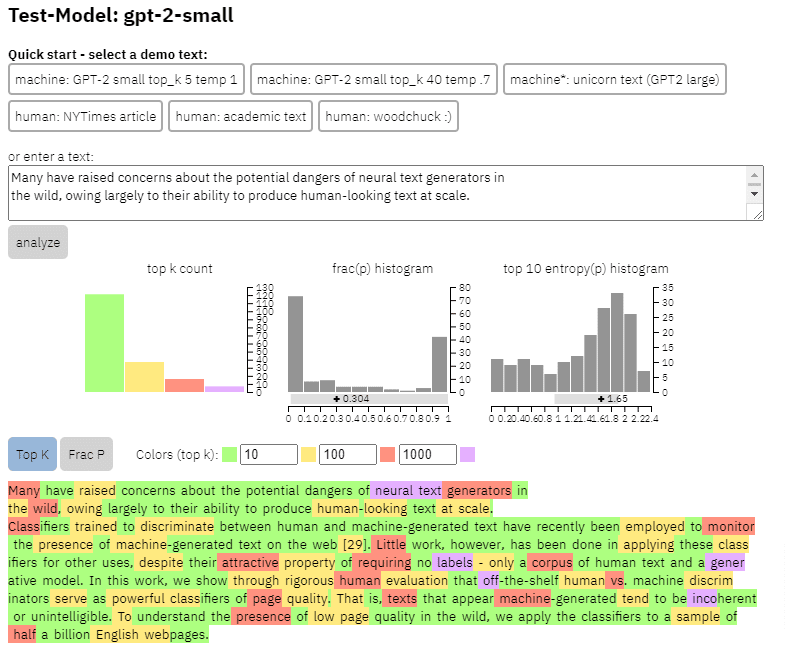
- ثلاث مجموعات بيانات Web500M (عينة عشوائية من 500 مليون صفحة ويب إنجليزية) ، إخراج GPT-2 (250 ألف جيل نصي GPT-2) و Grover-Output (قاموا بإنشاء 1.2 مليون مقال داخليًا باستخدام نموذج Grover-Base المدربين مسبقًا ، والذي تم تصميمه لاكتشاف الأخبار الكاذبة).
- خط الأساس للبريد العشوائي ، وهو مصنف تم تدريبه على مجموعة بيانات Enron Spam Email. استخدموا هذا المصنف لإنشاء رقم جودة اللغة الذي سيقومون بتعيينه ، لذلك إذا حدد النموذج أن المستند ليس بريدًا عشوائيًا مع احتمال 0.2 ، فإن درجة جودة اللغة (LQ) المعينة كانت 0.2.
احصل على النشرة الإخبارية اليومية التي يعتمد عليها المسوقون.
انظر الشروط.
جانبا حول انتشار البريد العشوائي
أردت أن أتوقف بسرعة لمناقشة بعض النتائج المثيرة للاهتمام التي عثر عليها المؤلفون. واحد موضح في الشكل التالي (الشكل 3 من الورقة):
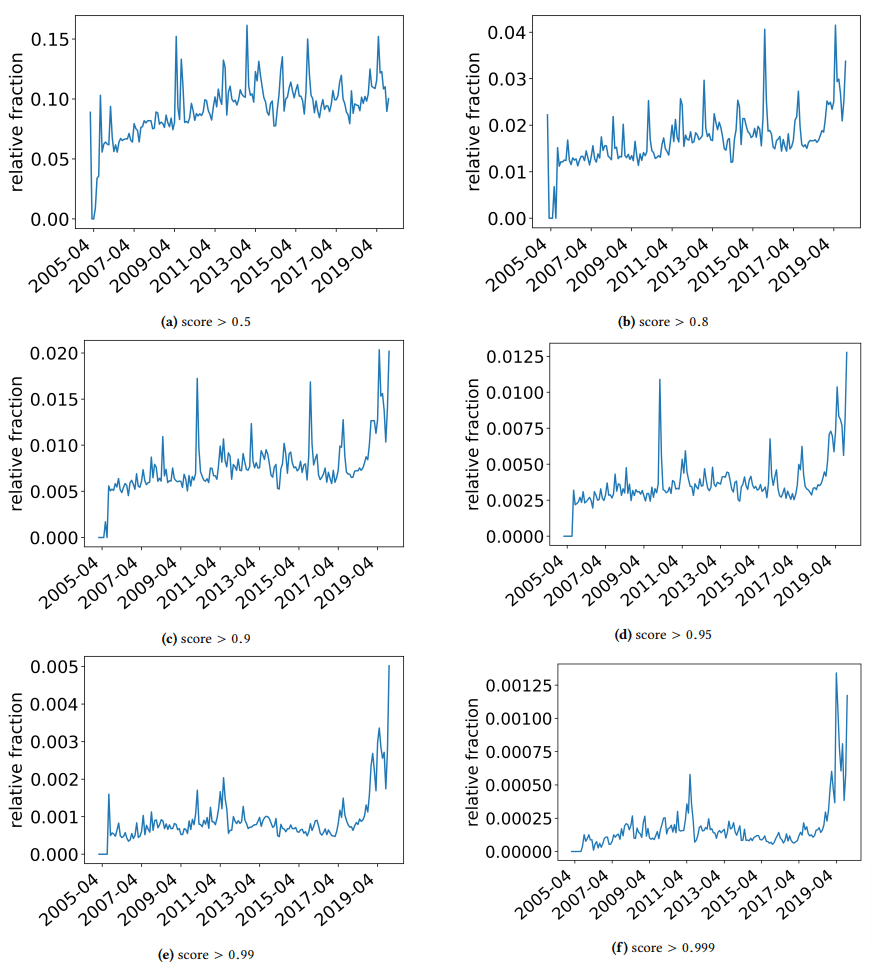
من المهم ملاحظة النتيجة أسفل كل رسم بياني. يتجه الرقم نحو 1.0 إلى الثقة في أن المحتوى هو بريد عشوائي. ما نراه بعد ذلك هو أنه اعتبارًا من عام 2017 فصاعدًا - وارتفاعاً حادًا في عام 2019 - كان هناك انتشار للوثائق منخفضة الجودة.
بالإضافة إلى ذلك ، وجدوا أن تأثير المحتوى منخفض الجودة كان أعلى في بعض القطاعات مقارنة بالقطاعات الأخرى (تذكر أن النتيجة الأعلى تعكس احتمالية أعلى للبريد العشوائي).
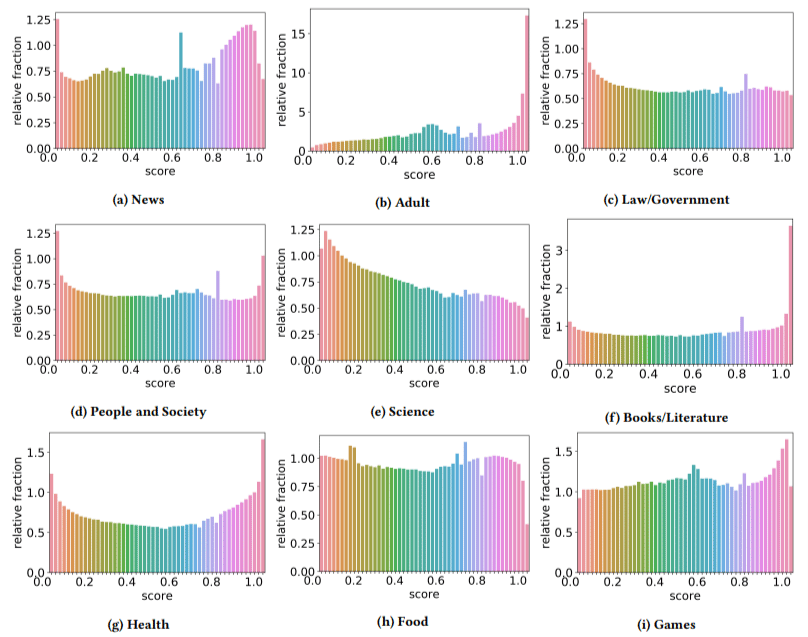
لقد خدشت رأسي في اثنين من هؤلاء. الكبار منطقي ، من الواضح.
لكن الكتب والأدب كانت مفاجأة بعض الشيء. وكذلك كانت الصحة - حتى طرح المؤلفون الفياجرا ومواقع "منتجات صحة البالغين" الأخرى على أنها "صحة" ومزارع المقالات باعتبارها "أدبًا" - أي.
النتائج التي توصلوا إليها
بصرف النظر عما ناقشناه حول القطاعات والارتفاع المفاجئ في عام 2019 ، وجد المؤلفون أيضًا عددًا من الأشياء المثيرة للاهتمام التي يمكن أن تتعلم منها مُحسّنات محرّكات البحث ويجب أن تضعها في الاعتبار ، خاصة عندما نبدأ في الاعتماد على أدوات مثل ChatGPT.
- يميل المحتوى منخفض الجودة إلى أن يكون أقل طولًا (يصل ذروته إلى 3000 حرف).
- أنظمة الكشف المدربة على تحديد ما إذا كان النص قد تمت كتابته بواسطة آلة أم لا هي جيدة أيضًا في تصنيف المحتوى منخفض المستوى مقابل المحتوى عالي المستوى.
- يطلقون على المحتوى الخاص بنا المصمم للترتيب باعتباره مسببًا محددًا ، على الرغم من أنني أشك في أنهم يشيرون إلى المهملات التي نعلم جميعًا أنه لا ينبغي أن تكون هناك.
لا يدعي المؤلفون أن هذا هو الحل النهائي ، بل هو نقطة انطلاق وأنا متأكد من أنهم قد نقلوا الشريط إلى الأمام في العامين الماضيين.
ملاحظة حول المحتوى الذي تم إنشاؤه بواسطة الذكاء الاصطناعي
تطورت نماذج اللغة بالمثل على مر السنين. بينما كان GPT-3 موجودًا عند كتابة هذه الورقة ، فإن أجهزة الكشف التي كانوا يستخدمونها كانت تستند إلى GPT-2 وهو نموذج أدنى بكثير.
من المحتمل أن يكون GPT-4 قاب قوسين أو أدنى ، ومن المقرر إطلاق Sparrow من Google في وقت لاحق من هذا العام. هذا يعني أن التقنية لا تتحسن فقط على جانبي ساحة المعركة (مولدات المحتوى مقابل محركات البحث) ، بل سيكون من الأسهل جذب المجموعات إلى اللعب.
هل يمكن لـ Google اكتشاف المحتوى الذي تم إنشاؤه بواسطة Sparrow أو GPT-4؟ يمكن.
ولكن ماذا لو تم إنشاؤه باستخدام Sparrow ثم إرساله إلى GPT-4 مع موجه إعادة الكتابة؟
هناك عامل آخر يجب تذكره وهو أن التقنيات المستخدمة في هذه الورقة تعتمد على نماذج الانحدار التلقائي. ببساطة ، فهم يتوقعون درجة لكلمة بناءً على ما يتوقعون أن تعطى هذه الكلمة لتلك التي سبقته.
نظرًا لأن النماذج تطور درجة أعلى من التطور وتبدأ في إنشاء أفكار كاملة في وقت واحد بدلاً من كلمة متبوعة بأخرى ، فقد ينخفض اكتشاف الذكاء الاصطناعي.
من ناحية أخرى ، يجب أن يتصاعد اكتشاف المحتوى السيء ببساطة - مما قد يعني أن المحتوى "منخفض الجودة" الوحيد الذي سيفوز ، هو الذي يتم إنشاؤه بواسطة الذكاء الاصطناعي.
الآراء المعبر عنها في هذه المقالة هي آراء المؤلف الضيف وليست بالضرورة آراء محرك البحث. مؤلفو طاقم العمل مدرجون هنا.