
نظام Hadoop البيئي ومكوناته
نشرت: 2015-04-23البيانات الضخمة هي الكلمة الطنانة المتداولة في صناعة تكنولوجيا المعلومات منذ عام 2008. إن كمية البيانات التي يتم إنشاؤها بواسطة الشبكات الاجتماعية ، والتصنيع ، وتجارة التجزئة ، والأسهم ، والاتصالات ، والتأمين ، والخدمات المصرفية ، وصناعات الرعاية الصحية تفوق خيالنا.
قبل ظهور Hadoop ، كان تخزين البيانات الضخمة ومعالجتها يمثل تحديًا كبيرًا. ولكن الآن بعد أن أصبح Hadoop متاحًا ، أدركت الشركات تأثير البيانات الضخمة على الأعمال وكيف سيؤدي فهم هذه البيانات إلى دفع النمو. علي سبيل المثال:
• تتمتع القطاعات المصرفية بفرصة أفضل لفهم العملاء المخلصين والمتخلفين عن سداد القروض ومعاملات الاحتيال.
• لدى قطاعات البيع بالتجزئة الآن بيانات كافية للتنبؤ بالطلب.
• لا تحتاج قطاعات التصنيع إلى الاعتماد على الآليات المكلفة لاختبار الجودة. سيكشف التقاط بيانات أجهزة الاستشعار وتحليلها عن العديد من الأنماط.
• التجارة الإلكترونية ، يمكن للشبكات الاجتماعية تخصيص الصفحات بناءً على اهتمامات العملاء.
• تولد أسواق الأسهم كمية هائلة من البيانات ، وسيكشف الارتباط من وقت لآخر عن رؤى جميلة.
تحتوي البيانات الضخمة على العديد من التطبيقات المفيدة والثاقبة.
Hadoop هو الحل المباشر لمعالجة البيانات الضخمة. نظام Hadoop البيئي هو مزيج من التقنيات التي تتمتع بميزة بارعة في حل مشاكل الأعمال.
دعونا نفهم المكونات في Hadoop Ecosytem لبناء الحلول الصحيحة لمشكلة عمل معينة.
نظام Hadoop البيئي:
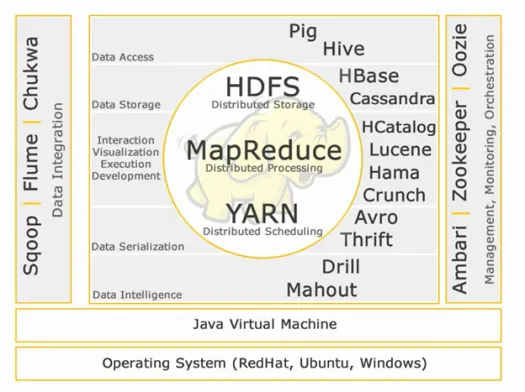

كور هادوب:
HDFS:
يرمز HDFS إلى نظام الملفات الموزعة Hadoop لإدارة مجموعات البيانات الضخمة ذات الحجم الكبير والسرعة والتنوع. يطبق HDFS هندسة الرقيق الرئيسية. السيد هو اسم العقدة والعبد هو عقدة البيانات.
سمات:
• القابلة للتطوير
• موثوق
• الأجهزة السلع
HDFS معروف جيدًا بتخزين البيانات الضخمة.
تقليل الخريطة:
Map Reduce هو نموذج برمجة مصمم لمعالجة البيانات الموزعة بكميات كبيرة. تم بناء النظام الأساسي باستخدام Java لتحسين معالجة الاستثناءات. يتضمن Map Reduce اثنين من الشياطين ، ومتعقب الوظائف ومتعقب المهام.
سمات:
• البرمجة الوظيفية.
• يعمل بشكل جيد للغاية على البيانات الضخمة.
• يمكن معالجة مجموعات البيانات الكبيرة.
يعد Map Reduce المكون الرئيسي المعروف بمعالجة البيانات الضخمة.
غزل:
YARN تعني مفاوض موارد آخر. ويسمى أيضًا باسم MapReduce 2 (MRv2). يتم تقسيم الوظيفتين الرئيسيتين لـ Job Tracker في MRv1 ، وإدارة الموارد وجدولة / مراقبة الوظائف إلى شياطين منفصلة وهي ResourceManager و NodeManager و ApplicationMaster.
سمات:
• إدارة أفضل للموارد.
• قابلية التوسع
• التخصيص الديناميكي لموارد الكتلة.
الدخول الى البيانات:
شخص شره:
Apache Pig هي لغة عالية المستوى تم إنشاؤها فوق MapReduce لتحليل مجموعات البيانات الكبيرة باستخدام برامج تحليل بيانات مخصصة بسيطة. يُعرف الخنزير أيضًا باسم لغة تدفق البيانات. إنه مدمج جيدًا مع بيثون. تم تطويره في البداية بواسطة ياهو.
السمات البارزة للخنزير:
• سهولة البرمجة
• فرص التحسين
• القابلية للتوسعة.
سيتم تحويل البرامج النصية للخنزير داخليًا إلى برامج تقليل الخريطة.

خلية نحل:
Apache Hive هي لغة استعلام أخرى عالية المستوى وبنية تحتية لمستودع البيانات تم إنشاؤها فوق Hadoop لتوفير تلخيص البيانات والاستعلام والتحليل. تم تطويره في البداية بواسطة yahoo وجعله مفتوح المصدر.
السمات البارزة للخلية:
• SQL مثل لغة الاستعلام تسمى HQL.
• التقسيم والتجميع لمعالجة البيانات بشكل أسرع.
• التكامل مع أدوات التصور مثل Tableau.
سيتم تحويل استعلامات الخلية داخليًا إلى برامج تقليل الخريطة.
إذا كنت تريد أن تصبح محلل بيانات كبير ، فهذه اللغتان رفيعتا المستوى يجب أن تعرفهما !!

مخزن البيانات:
Hbase:
Apache HBase هي قاعدة بيانات NoSQL مصممة لاستضافة جداول كبيرة بمليارات الصفوف وملايين الأعمدة فوق أجهزة أجهزة Hadoop للسلع. استخدم Apache Hbase عندما تحتاج إلى وصول عشوائي للقراءة / الكتابة في الوقت الفعلي إلى بياناتك الضخمة.
سمات:
• قراءة وكتابة متسقة بدقة. في عمليات الذاكرة.
• سهولة استخدام Java API لوصول العميل.
• تتكامل بشكل جيد مع الخنازير والخلية و sqoop.
• هو نظام متسق ومتسامح في نظرية CAP.

كاساندرا:
Cassandra هي قاعدة بيانات NoSQL مصممة للتوسع الخطي والتوافر العالي. تعتمد كاساندرا على نموذج القيمة الرئيسية. تم تطويره بواسطة Facebook وهو معروف باستجابة أسرع للاستفسارات.
سمات:
• فهارس العمود
• دعم إزالة التطبيع
• الآراء المجسدة
• ذاكرة تخزين مؤقت مدمجة قوية.

التفاعل - التصور - التنفيذ - التطوير:
كتالوج H:
HCatalog عبارة عن طبقة إدارة جدول توفر تكامل بيانات تعريف الخلية لتطبيقات Hadoop الأخرى. إنه يمكّن المستخدمين الذين لديهم أدوات معالجة بيانات مختلفة مثل Apache pig و Apache MapReduce و Apache Hive لقراءة البيانات وكتابتها بسهولة أكبر.
سمات:
• عرض جدولي لتنسيقات مختلفة.

• إخطارات توافر البيانات.
• REST API للأنظمة الخارجية للوصول إلى البيانات الوصفية.
لوسين:
Apache LuceneTM هي مكتبة محرك بحث نصي كامل الميزات وعالية الأداء مكتوبة بالكامل بلغة Java. إنها تقنية مناسبة لأي تطبيق تقريبًا يتطلب البحث في النص الكامل ، وخاصة عبر الأنظمة الأساسية.
سمات:
• فهرسة عالية الأداء وقابلة للتطوير.
• خوارزميات بحث قوية ودقيقة وفعالة.
• حل متعدد المنصات.
حماة:
Apache Hama هو إطار عمل موزع يعتمد على الحوسبة المتوازية المتزامنة (BSP). قادر ومعروف جيدًا بالحسابات العلمية الضخمة مثل خوارزميات المصفوفة والرسم البياني والشبكة.
سمات:
• نموذج برمجة بسيط
• مناسب تمامًا للخوارزميات التكرارية
• دعم الغزل
• التصفية التعاونية للتعلم الآلي غير الخاضع للإشراف.
• K-Means clustering.
سحق:
تم تصميم Apache crunch لتوجيه برامج MapReduce التي تتسم بالبساطة والفعالية. يستخدم هذا الإطار لكتابة واختبار وتشغيل خطوط أنابيب MapReduce.
سمات:
• التركيز على المطور.
• الحد الأدنى من التجريدات
• نموذج بيانات مرن.
تسلسل البيانات:
أفرو:
Apache Avro هو إطار عمل لتسلسل البيانات وهو لغة محايدة. مصمم لإمكانية نقل اللغة ، مما يسمح للبيانات بأن تعمر أكثر من اللغة لقراءتها وكتابتها.

تقطير:
Thrift هي لغة تم تطويرها لبناء واجهات للتفاعل مع التقنيات المبنية على Hadoop. يتم استخدامه لتعريف وإنشاء خدمات للعديد من اللغات.
ذكاء البيانات:
تدريبات:
Apache Drill هو محرك استعلام SQL منخفض التأخير لكل من Hadoop و NoSQL.
سمات:
• رشاقة
• المرونة
• المألوفة.

الفيال:
Apache Mahout هي مكتبة تعلم آلي قابلة للتطوير مصممة لبناء تحليلات تنبؤية على البيانات الضخمة. لدى Mahout الآن تطبيقات Apache Spark بشكل أسرع في حوسبة الذاكرة.
سمات:
• تصفية التعاونية.
• تصنيف
• تجمع
• تخفيض الأبعاد

تكامل البيانات:
اباتشي سكووب:

Apache Sqoop هي أداة مصممة لنقل البيانات بالجملة بين قواعد البيانات العلائقية و Hadoop.
سمات:
• الاستيراد والتصدير من وإلى HDFS.
• الاستيراد والتصدير من وإلى Hive.
• الاستيراد والتصدير إلى HBase.
اباتشي فلوم:
Flume هي خدمة موزعة وموثوقة ومتاحة لجمع كميات كبيرة من بيانات السجل وتجميعها ونقلها بكفاءة.
سمات:
• قوي
• مستحمل للخطأ
• بنية بسيطة ومرنة تعتمد على تدفق تدفقات البيانات.

اباتشي تشوكوا:
أداة تجميع السجلات القابلة للتطوير تستخدم لمراقبة أنظمة الملفات الموزعة الكبيرة.
سمات:
• تحجيم لآلاف العقد.
• تسليم موثوق.
• يجب أن تكون قادرة على تخزين البيانات إلى أجل غير مسمى.

الإدارة والمراقبة والتنظيم:
اباتشي أمباري:
تم تصميم Ambari لجعل إدارة hadoop أبسط من خلال توفير واجهة لتزويد Apache Hadoop Clusters وإدارتها ومراقبتها.
سمات:
• توفير Hadoop الكتلة.
• إدارة Hadoop الكتلة.
• مراقبة مجموعة Hadoop.

اباتشي زوكيبير:
Zookeeper هي خدمة مركزية مصممة للحفاظ على معلومات التكوين والتسمية وتوفير التزامن الموزع وتوفير خدمات المجموعة.
سمات:
• التسلسل
• الذرية
• الموثوقية
• واجهة برمجة تطبيقات بسيطة

اباتشي اوزي:
Oozie هو نظام جدولة سير عمل لإدارة وظائف Apache Hadoop.
سمات:
• نظام قابل للتطوير وموثوق وقابل للتوسيع.
• يدعم عدة أنواع من وظائف Hadoop مثل Map-Reduce و Hive و Pig و Sqoop.
• بسيطة وسهلة الاستخدام.

سنناقش حول المكونات بالتفصيل في المقالات القادمة. ابقوا متابعين.