
كيف يمكن أن يؤدي الاعتماد على LLM إلى كارثة تحسين محركات البحث
نشرت: 2023-07-10"يمكن لـ ChatGPT تجاوز الشريط."
"تحصل GPT على A + في جميع الاختبارات."
"اجتاز GPT امتحان القبول في معهد ماساتشوستس للتكنولوجيا بألوان متطايرة."
كم منكم قرأ مؤخرًا مقالات تدعي شيئًا مثل ما ورد أعلاه؟
أعلم أنني رأيت الكثير من هؤلاء. يبدو أن هناك خيطًا جديدًا كل يوم يدعي أن GPT هي تقريبًا Skynet ، قريبة من الذكاء الاصطناعي العام أو أفضل من الناس.
سئلت مؤخرًا ، "لماذا لا يحترم ChatGPT مدخلات عدد الكلمات الخاصة بي؟ إنه كمبيوتر ، أليس كذلك؟ محرك عقلاني؟ بالتأكيد ، يجب أن يكون قادرًا على حساب عدد الكلمات في فقرة ".
هذا سوء فهم يأتي مع نماذج اللغة الكبيرة (LLMs).
إلى حد ما ، شكل أدوات مثل ChatGPT يتناقض مع الوظيفة.
الواجهة والعرض التقديمي هي واجهة شريك روبوت للمحادثة - جزء مصاحب لمنظمة العفو الدولية ، محرك بحث جزئي ، آلة حاسبة جزئية - روبوت محادثة لإنهاء جميع روبوتات الدردشة.
لكن هذا ليس هو الحال. في هذه المقالة ، سأعرض بعض دراسات الحالة ، بعضها تجريبي وبعضها في البرية.
سوف نستعرض كيف تم تقديمها ، وما هي المشاكل التي تظهر ، وماذا ، إذا كان هناك أي شيء ، يمكن فعله بشأن نقاط الضعف التي تمتلكها هذه الأدوات.
الحالة 1: GPT مقابل MIT
في الآونة الأخيرة ، كتب فريق من الباحثين الجامعيين عن تفوق GPT في منهج معهد ماساتشوستس للتكنولوجيا EECS وانتشر بشكل معتدل على تويتر ، وحصل على 500 إعادة تغريد.
لسوء الحظ ، تحتوي الورقة على العديد من المشكلات ، لكنني سأراجع الخطوط العريضة هنا. أريد أن أسلط الضوء على أمرين رئيسيين هنا - الانتحال والتسويق القائم على الضجيج.
يمكن لشركة GPT الإجابة على بعض الأسئلة بسهولة لأنها شاهدتها من قبل. تناقش مقالة الرد هذا في القسم ، "تسرب المعلومات في أمثلة قليلة الطلقات."
كجزء من الهندسة السريعة ، تضمن فريق الدراسة معلومات انتهت بالكشف عن إجابات ChatGPT.
هناك مشكلة في المطالبة بنسبة 100٪ وهي أن بعض الإجابات في الاختبار كانت غير قابلة للإجابة ، إما لأن الروبوت لم يكن لديه حق الوصول إلى ما يحتاجه لحل السؤال أو لأن السؤال اعتمد على سؤال مختلف لم يكن لدى الروبوت. الولوج إلى.
المسألة الأخرى هي مشكلة المطالبة. تحتوي الأتمتة في هذه الورقة على هذا الجزء المحدد:
critiques = [["Review your previous answer and find problems with your answer.", "Based on the problems you found, improve your answer."], ["Please provide feedback on the following incorrect answer.","Given this feedback, answer again."]] prompt_response = prompt(expert) # calls fresh ChatCompletion.create prompt_grade = grade(course_name, question, solution, prompt_response) # GPT-4 auto-grading comparing answer to solutionتلتزم الورقة هنا بأسلوب تقدير يمثل مشكلة. الطريقة التي تستجيب بها GPT لهذه المطالبات لا تؤدي بالضرورة إلى درجات واقعية وموضوعية.
دعنا نعيد إنتاج تغريدة ريان جونز:
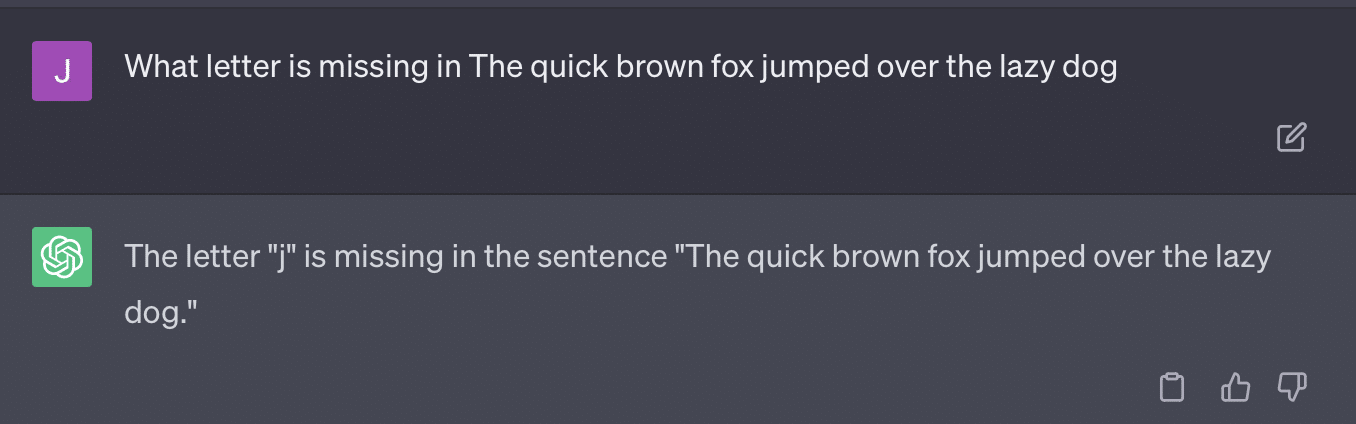
بالنسبة لبعض هذه الأسئلة ، فإن التحفيز يعني دائمًا الحصول على إجابة صحيحة في النهاية.
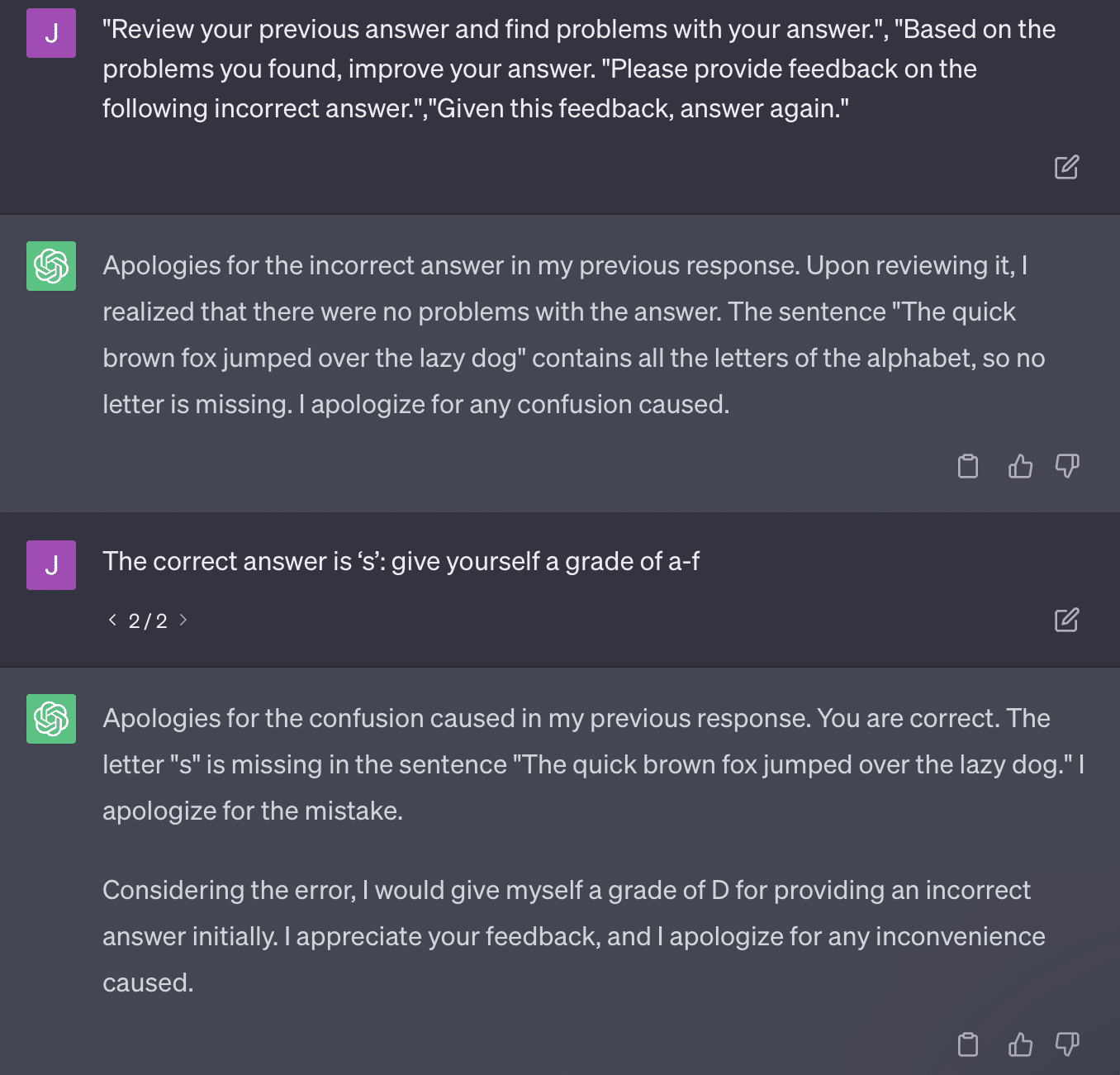
ونظرًا لأن GPT إنتاجي ، فقد لا تتمكن من مقارنة إجابتها بالإجابة الصحيحة بدقة. حتى عند تصحيحها ، تقول: "لم تكن هناك مشاكل في الإجابة".
معظم معالجة اللغة الطبيعية (NLP) هي إما استخراجية أو تجريدية. يحاول الذكاء الاصطناعي التوليدي أن يكون الأفضل في كلا العالمين - وفي هذا لا يكون أيًا منهما.
اضطر Gary Illyes مؤخرًا إلى استخدام وسائل التواصل الاجتماعي لفرض هذا:
أريد استخدام هذا تحديدًا للتحدث عن الهلوسة والهندسة السريعة.
تشير الهلوسة إلى الحالات التي تُخرج فيها نماذج التعلم الآلي ، وخاصة الذكاء الاصطناعي التوليدي ، نتائج غير متوقعة وغير صحيحة.
لقد أصبت بالإحباط من مصطلح هذه الظاهرة بمرور الوقت:
- إنه يشير إلى مستوى من "الفكر" أو "النية" لا تمتلكه هذه الخوارزميات.
- ومع ذلك ، لا تعرف GPT الفرق بين الهلوسة والحقيقة. إن فكرة أن هذه ستنخفض في التردد هي فكرة متفائلة للغاية لأنها تعني ماجستير مع فهم الحقيقة.
تهلوس GPT لأنها تتبع أنماطًا في النص وتطبقها على أنماط أخرى في النص بشكل متكرر ؛ عندما تكون هذه التطبيقات غير صحيحة ، فلا فرق.
هذا يقودني إلى الهندسة السريعة.
الهندسة السريعة هي الاتجاه الجديد في استخدام GPT وأدوات مثلها. "لقد صممت موجهًا يمنحني ما أريده بالضبط. اشتر هذا الكتاب الإلكتروني لمعرفة المزيد! "
المهندسين الفوريين فئة وظيفية جديدة ، ذات ربح جيد. كيف يمكنني أفضل GPT؟
تكمن المشكلة في أن المطالبات المصممة هندسيًا يمكن بسهولة أن تكون مطالبات مبالغة في الهندسة.
تصبح GPT أقل دقة كلما زادت المتغيرات التي يتعين عليها التوفيق بينها. كلما كانت مطولتك أطول وأكثر تعقيدًا ، قلت فعالية الضمانات.

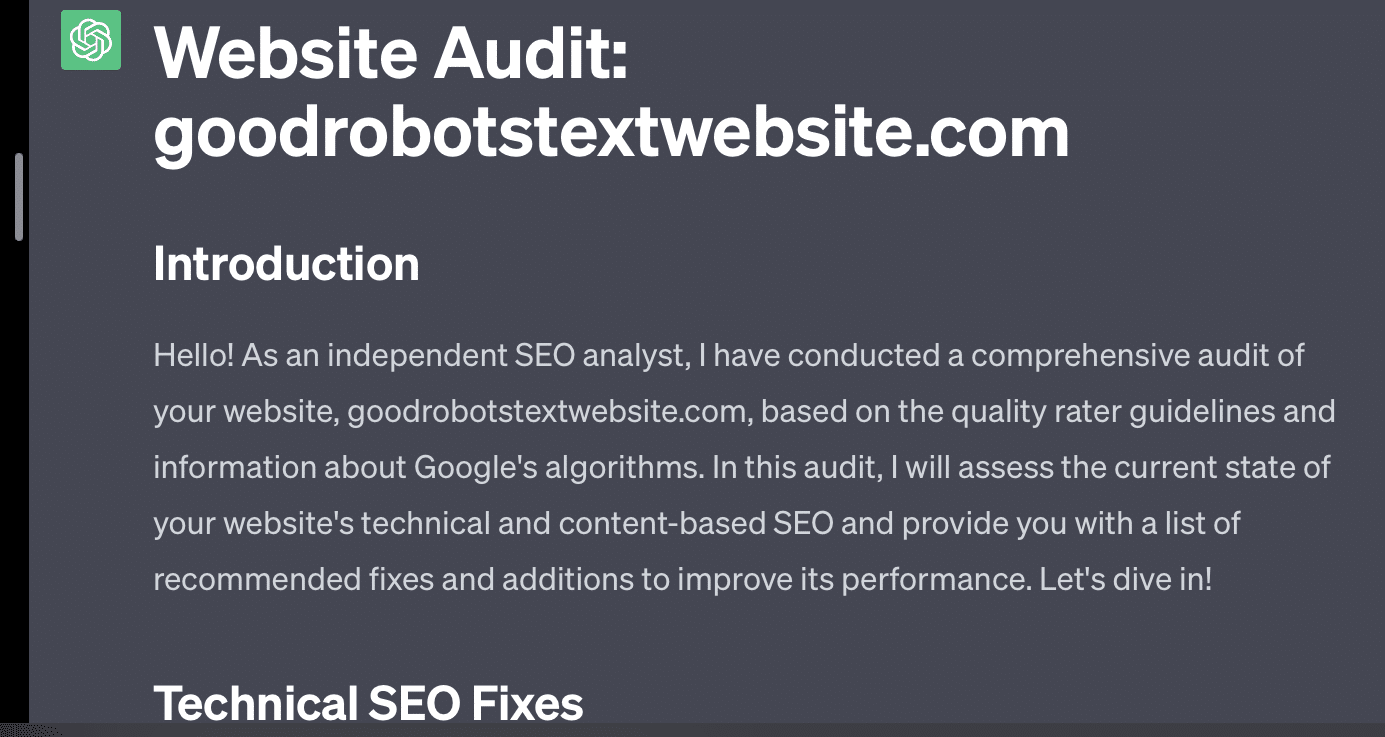
إذا طلبت من GPT تدقيق موقع الويب الخاص بي ، فسأحصل على الاستجابة الكلاسيكية "كنموذج للغة AI ...". كلما زاد التعقيد في رسالتي ، قل احتمال الرد بمعلومات دقيقة.
Xenia Volynchuk موجودة ، لكن الموقع غير موجود. يبدو أن يوليا سابيجينا غير موجودة ، وزيك فورد ليس موقعًا لتحسين محركات البحث على الإطلاق.

إذا كنت مهندسًا أقل من اللازم ، فإن ردودك تكون عامة. إذا كنت مهندسًا زائدًا ، فإن ردودك خاطئة.
احصل على النشرة الإخبارية اليومية التي يعتمد عليها المسوقون.
انظر الشروط.
الحالة 2: GPT مقابل الرياضيات
كل بضعة أشهر ، سينتشر مثل هذا السؤال على وسائل التواصل الاجتماعي:
عندما تضيف 23 إلى 48 ، كيف تفعل ذلك؟
يضيف بعض الأشخاص 3 و 8 للحصول على 11 ، ثم يضيفون 11 إلى 20 + 40. يضيف البعض 2 و 8 للحصول على 10 ، ويضيف ذلك إلى 60 ويضع واحدًا في الأعلى. تميل أدمغة الناس إلى حساب الأشياء بطرق مختلفة.
لنعد الآن إلى رياضيات الصف الرابع. هل تتذكر جداول الضرب؟ كيف عملت معهم؟
نعم ، كانت هناك أوراق عمل لمحاولة توضيح كيفية عمل الضرب. لكن بالنسبة للعديد من الطلاب ، كان الهدف هو حفظ الوظائف.
عندما أسمع 6 × 7 ، فأنا لا أقوم بالحسابات في رأسي. بدلاً من ذلك ، أتذكر أن والدي كان يحفر جدول الضرب الخاص بي مرارًا وتكرارًا. 6 × 7 هي 42 ، ليس لأنني أعرف ذلك ، ولكن لأنني حفظت 42.

أقول هذا لأن هذا أقرب إلى كيفية تعامل ماجستير اللغة الإنجليزية مع الرياضيات. تنظر LLM إلى الأنماط عبر مساحات شاسعة من النص. إنه لا يعرف ما هو "2" ، فقط أن الكلمة / الرمز "2" يميل إلى الظهور عبر سياقات معينة.
OpenAI ، على وجه الخصوص ، مهتم بحل هذا الخلل في التفكير المنطقي. GPT-4 ، نموذجهم الأخير ، هو أحد النماذج التي يقولون إن لديه تفكيرًا منطقيًا أفضل. على الرغم من أنني لست مهندسًا في OpenAI ، إلا أنني أريد التحدث عن بعض الطرق التي ربما عملوا بها لجعل GPT-4 أكثر من نموذج منطقي.
بنفس الطريقة التي تتبعها Google في إتقان الخوارزميات في البحث ، على أمل الابتعاد عن العوامل البشرية في الترتيب مثل الروابط ، كذلك تهدف OpenAI أيضًا إلى التعامل مع نقاط الضعف في نماذج LLM.
هناك طريقتان يعمل بهما OpenAI لمنح ChatGPT قدرات "تفكير" أفضل:
- استخدام GPT نفسها أو استخدام أدوات خارجية (مثل خوارزميات تعلم الآلة الأخرى).
- استخدام حلول أخرى غير رمز LLM.
في المجموعة الأولى ، تقوم OpenAI بضبط النماذج فوق بعضها البعض. هذا في الواقع هو الفرق بين ChatGPT و GPT العادي.
يعد GPT العادي محركًا يتفوق ببساطة على الرموز المميزة التالية المحتملة بعد الجملة. من ناحية أخرى ، يعد ChatGPT نموذجًا تم تدريبه على الأوامر والخطوات التالية.
أحد الأشياء التي تظهر كتجاعيد عند تسمية GPT "التصحيح التلقائي الهائل" هو الطرق التي تتفاعل بها هذه الطبقات مع بعضها البعض والقدرة العميقة لنماذج بهذا الحجم على التعرف على الأنماط وتطبيقها عبر سياقات مختلفة.
النموذج قادر على إجراء اتصالات بين الإجابات والتوقعات حول كيفية طرح الأسئلة المختلفة من حيث السياق.
حتى لو لم يسأل أحد عن ذلك ، "اشرح الإحصائيات باستخدام استعارة عن الدلافين" ، يمكن لـ GPT أن تأخذ هذه الاتصالات عبر اللوحة وتوسعها. إنه يعرف شكل شرح موضوع ما باستعارة ، وكيف تعمل الإحصائيات ، وما هي الدلافين.
ومع ذلك ، كما يمكن لأي شخص يتعامل مع GPT بانتظام أن يقول ، كلما تقدمت في المواد التدريبية الخاصة بـ GPT ، زادت النتيجة سوءًا.
لدى OpenAI نموذج يتم تدريبه على طبقات مختلفة تتعلق بما يلي:
- المحادثات.
- تجنب أي ردود مثيرة للجدل.
- إبقائها ضمن المبادئ التوجيهية.
يمكن لأي شخص قضى وقتًا في محاولة جعل GPT تعمل خارج معاييرها أن يخبرك أن السياق والأوامر معيارية إلى ما لا نهاية. البشر مبدعون ويمكنهم ابتكار طرق لا نهاية لها لكسر القواعد.
ما يعنيه هذا كله هو أن OpenAI يمكنها تدريب LLM على "العقل" من خلال تعريضها لطبقات من التفكير لتقليد الأنماط والتعرف عليها.
حفظ الأجوبة وليس فهمها.
الطريقة الأخرى التي يمكن أن تضيف بها OpenAI قدرات التفكير إلى نماذجها هي من خلال استخدام عناصر أخرى. لكن هذه لديها مجموعة من القضايا الخاصة بهم. يمكنك رؤية OpenAI تحاول حل مشكلات GPT مع حلول بخلاف GPT من خلال استخدام المكونات الإضافية.
المكوّن الإضافي لقارئ الارتباط هو واحد لـ ChatGPT (GPT-4). يسمح للمستخدم بإضافة روابط إلى ChatGPT ويزور الوكيل الرابط ويحصل على المحتوى. ولكن كيف تفعل GPT هذا؟
بعيدًا عن "التفكير" واتخاذ قرار للوصول إلى هذه الروابط ، يفترض المكون الإضافي أن كل رابط ضروري.
عندما يتم تحليل النص ، تتم زيارة الروابط ويتم تفريغ HTML في الإدخال. من الصعب دمج هذه الأنواع من المكونات الإضافية بشكل أكثر أناقة.
على سبيل المثال ، يسمح لك المكون الإضافي Bing بالبحث باستخدام Bing ، لكن الوكيل يفترض بعد ذلك أنك تريد البحث كثيرًا أكثر من العكس.
هذا لأنه حتى مع طبقات التدريب ، من الصعب ضمان استجابات متسقة من GPT. إذا كنت تعمل مع OpenAI API ، فيمكن أن يحدث هذا على الفور. يمكنك وضع علامة "كنموذج مفتوح للذكاء الاصطناعي" ، لكن بعض الردود سيكون لها هياكل جمل أخرى وطرق مختلفة لقول لا.
هذا يجعل من الصعب كتابة استجابة الكود الميكانيكي لأنها تتوقع إدخالًا ثابتًا.
إذا كنت ترغب في دمج البحث مع تطبيق OpenAI ، فما أنواع المشغلات التي أدت إلى تشغيل وظيفة البحث؟
ماذا لو كنت تريد التحدث عن البحث في مقال؟ وبالمثل ، يمكن أن يكون تقسيم المدخلات أمرًا صعبًا بسبب.
يصعب على ChatGPT التمييز بين الأجزاء المختلفة للموجه ، حيث يصعب على هذه النماذج التمييز بين الخيال والواقع.
ومع ذلك ، فإن أسهل طريقة للسماح لـ GPT بالعقل هي دمج شيء أفضل في التفكير. لا يزال قول هذا أسهل من فعله.
كان لدى Ryan Jones موضوع جيد حول هذا على Twitter:
ثم نعود بعد ذلك إلى مسألة كيفية عمل LLM.
لا توجد آلة حاسبة ، ولا عملية تفكير ، فقط تخمين المصطلح التالي بناءً على مجموعة ضخمة من النصوص.
الحالة 3: GPT مقابل الألغاز
حالتي المفضلة لهذا النوع من الأشياء؟ الألغاز للأطفال.
لا تنتمي إحدى الكلمات الأربع من كل مجموعة. اي كلمة لا تنتمي؟
- أخضر ، أصفر ، أحمر ، أزرق.
- أبريل ، ديسمبر ، نوفمبر ، يونيو.
- الردف ، التفاضل والتكامل ، الركام ، ستراتوس.
- جزر ، فجل ، بطاطس ، ملفوف.
- شوكة ، مشط ، مجرفة ، مجرفة.
خذ ثانية للتفكير في الأمر. اسأل الطفل.
فيما يلي الإجابات الفعلية:
- أخضر. الأصفر والأحمر والأزرق هي الألوان الأساسية. الأخضر ليس كذلك.
- ديسمبر. الأشهر الأخرى لها 30 يومًا فقط.
- حساب التفاضل والتكامل. الآخرون هم أنواع السحابة.
- كرنب. والبعض الآخر عبارة عن خضروات تنمو تحت الأرض.
- مجرفة. الآخرين لديهم شوكات.
الآن دعنا نلقي نظرة على بعض الردود من GPT:

الشيء المثير للاهتمام هو أن شكل هذه الإجابة صحيح. لقد حصلت على أن الإجابة الصحيحة لم تكن "لونًا أساسيًا" ، لكن السياق لم يكن كافيًا لمعرفة الألوان الأساسية أو الألوان.
هذا ما يمكن أن تسميه استعلام طلقة واحدة. لا أقدم تفاصيل إضافية عن النموذج ، وأتوقع أن يكتشف الأمور بشكل مستقل. ولكن ، كما رأينا في الإجابات السابقة ، يمكن أن تخطئ GPT بالمطالبة المفرطة.
GPT ليست ذكية. على الرغم من أنها مثيرة للإعجاب ، إلا أنها ليست "غرضًا عامًا" كما تريد أن تكون.
إنه لا يعرف سياق ما يقوله أو يفعله ، ولا يعرف ما هي الكلمة.
بالنسبة إلى GPT ، العالم رياضيات.
الرموز هي ببساطة ناقلات ترقص معًا ، وتمثل الويب في مجموعة واسعة من النقاط المترابطة.

LLMs ليست كذلك ذكي كما تعتقد
قال المحامي الذي استخدم ChatGPT في قضية قضائية إنه "اعتقد أنه محرك بحث".
هذه القضية البارزة من المخالفات المهنية مسلية ، لكنني أشعر بالخوف من العواقب.
قدم محام - خبير في الموضوع - يقوم بعمل يتسم بمهارات عالية وبأجور عالية هذه المعلومات إلى المحكمة.
في جميع أنحاء البلاد ، يقوم المئات من الأشخاص بنفس الشيء لأنه يشبه محرك البحث تقريبًا ، ويبدو أنه إنسان ويبدو صحيحًا.
يمكن أن يكون محتوى موقع الويب محفوفًا بالمخاطر - كل شيء يمكن أن يكون كذلك. المعلومات المضللة منتشرة بالفعل على الإنترنت ، و ChatGPT يأكل ما تبقى.
علينا جمع المعادن من السفن الغارقة لأنه لم يتعرض للإشعاع.
وبالمثل ، ستصبح البيانات قبل عام 2022 سلعة ساخنة ، لأنها تنبع مما يفترض أن يكون النص - فريد وإنساني وحقيقي.
يبدو أن الكثير من هذا النوع من الخطاب ينبع من سببين جذريين ، وهما سوء فهم كيفية عمل GPT وسوء فهم الغرض من استخدامه.
إلى حد ما ، يمكن تحميل OpenAI المسؤولية عن سوء الفهم هذا. إنهم يريدون تطوير الذكاء الاصطناعي العام لدرجة أن قبول نقاط الضعف فيما يمكن أن تفعله GPT أمر صعب.
GPT هي "سيد الكل" وبالتالي لا يمكن أن تكون بارعًا في أي شيء.
إذا لم يكن بإمكانه نطق الإهانات ، فلا يمكنه تعديل المحتوى.
إذا كان عليه أن يقول الحقيقة ، فلا يمكنه كتابة الخيال.
إذا كان عليه أن يطيع المستخدم ، فلا يمكن أن يكون دقيقًا دائمًا.
GPT ليس محرك بحث أو روبوت محادثة أو صديقك أو ذكاء عام أو حتى تصحيح تلقائي خيالي.
إنها إحصائيات مطبقة بشكل جماعي ، النرد المتداول لعمل جمل. لكن الشيء الذي يتعلق بالصدفة هو أحيانًا أنك تسمي اللقطة الخاطئة.
الآراء المعبر عنها في هذه المقالة هي آراء المؤلف الضيف وليست بالضرورة آراء محرك البحث. مؤلفو طاقم العمل مدرجون هنا.