
دليل تحسين محركات البحث (SEO) لفهم نماذج اللغة الكبيرة (LLMs)
نشرت: 2023-05-08هل يجب علي استخدام نماذج لغة كبيرة للبحث عن الكلمات الرئيسية؟ هل تستطيع هذه النماذج التفكير؟ هل ChatGPT صديقي؟
إذا كنت تسأل نفسك هذه الأسئلة ، فهذا الدليل مناسب لك.
يغطي هذا الدليل ما يحتاج مُحسّنات محرّكات البحث إلى معرفته حول نماذج اللغة الكبيرة ومعالجة اللغة الطبيعية وكل شيء بينهما.
نماذج اللغة الكبيرة ومعالجة اللغة الطبيعية والمزيد بعبارات بسيطة
هناك طريقتان لجعل الشخص يفعل شيئًا - أخبره أن يفعل ذلك أو يأمل أن يفعل ذلك بنفسه.
عندما يتعلق الأمر بعلوم الكمبيوتر ، فإن البرمجة تخبر الروبوت بالقيام بذلك ، بينما يأمل التعلم الآلي أن يقوم الروبوت بذلك بنفسه. الأول هو التعلم الآلي الخاضع للإشراف ، والآخر هو التعلم الآلي غير الخاضع للإشراف.
تعد معالجة اللغة الطبيعية (NLP) طريقة لتقسيم النص إلى أرقام ثم تحليله باستخدام أجهزة الكمبيوتر.
تقوم أجهزة الكمبيوتر بتحليل الأنماط في الكلمات ، وكلما أصبحت أكثر تقدمًا ، في العلاقات بين الكلمات.
يمكن تدريب نموذج تعلم الآلة للغة الطبيعية غير الخاضع للإشراف على العديد من أنواع مجموعات البيانات المختلفة.
على سبيل المثال ، إذا قمت بتدريب نموذج لغوي على متوسط تقييمات فيلم "Waterworld" ، فستحصل على نتيجة جيدة في كتابة (أو فهم) مراجعات لفيلم "Waterworld".
إذا قمت بتدريبه على المراجعتين الإيجابيتين اللتين قمت بهما لفيلم "Waterworld" ، فسوف يفهم فقط تلك المراجعات الإيجابية.
نماذج اللغات الكبيرة (LLMs) عبارة عن شبكات عصبية بها أكثر من مليار معلمة. إنها كبيرة جدًا لدرجة أنها أكثر تعميماً. لم يتم تدريبهم فقط على المراجعات الإيجابية والسلبية لـ "Waterworld" ولكن أيضًا على التعليقات ومقالات ويكيبيديا والمواقع الإخبارية والمزيد.
تعمل مشاريع التعلم الآلي مع السياق كثيرًا - أشياء داخل وخارج السياق.
إذا كان لديك مشروع تعلُّم آلي يعمل على تحديد الأخطاء وإظهارها على شكل قطة ، فلن يكون جيدًا في هذا المشروع.
هذا هو السبب في صعوبة أشياء مثل السيارات ذاتية القيادة: هناك العديد من المشكلات خارج السياق بحيث يصعب جدًا تعميم هذه المعرفة.
LLMs تبدو ويمكن أن تكون كذلك أكثر عمومية من مشاريع التعلم الآلي الأخرى. هذا بسبب الحجم الهائل للبيانات والقدرة على التعامل مع مليارات العلاقات المختلفة.
دعنا نتحدث عن واحدة من التقنيات الخارقة التي تسمح بذلك - المحولات.
شرح المحولات من الصفر
نوع من هندسة الشبكات العصبية ، أحدثت المحولات ثورة في مجال البرمجة اللغوية العصبية.
قبل المحولات ، اعتمدت معظم نماذج البرمجة اللغوية العصبية على تقنية تسمى الشبكات العصبية المتكررة (RNN) ، والتي تعالج النص بالتسلسل ، كلمة واحدة في كل مرة. كان لهذا النهج حدوده ، مثل أن يكون بطيئًا ويكافح للتعامل مع التبعيات بعيدة المدى في النص.
غيرت المحولات هذا.
في البحث التاريخي لعام 2017 ، "الاهتمام هو كل ما تحتاجه" ، Vaswani et al. قدم هندسة المحولات.
بدلاً من معالجة النص بالتسلسل ، تستخدم المحولات آلية تسمى "الانتباه الذاتي" لمعالجة الكلمات بشكل متوازٍ ، مما يسمح لها بالتقاط التبعيات بعيدة المدى بشكل أكثر كفاءة.
تضمنت البنية السابقة RNNs وخوارزميات الذاكرة طويلة المدى.
كانت النماذج المتكررة (ولا تزال) تستخدم بشكل شائع للمهام التي تتضمن تسلسل البيانات ، مثل النص أو الكلام.
ومع ذلك ، فإن هذه النماذج لديها مشكلة. يمكنهم فقط معالجة البيانات قطعة واحدة في كل مرة ، مما يبطئهم ويحد من كمية البيانات التي يمكنهم العمل بها. هذه المعالجة المتسلسلة تحد حقًا من قدرة هذه النماذج.
تم تقديم آليات الانتباه كطريقة مختلفة لمعالجة بيانات التسلسل. إنها تسمح للنموذج بإلقاء نظرة على جميع أجزاء البيانات دفعة واحدة وتحديد الأجزاء الأكثر أهمية.
يمكن أن يكون هذا مفيدًا حقًا في العديد من المهام. ومع ذلك ، فإن معظم النماذج التي استخدمت الانتباه تستخدم أيضًا المعالجة المتكررة.
في الأساس ، كان لديهم هذه الطريقة في معالجة البيانات دفعة واحدة ولكنهم ما زالوا بحاجة إلى النظر إليها بالترتيب. تم طرح ورقة Vaswani et al. ، "ماذا لو استخدمنا آلية الانتباه فقط؟"
الانتباه هو وسيلة للنموذج للتركيز على أجزاء معينة من تسلسل الإدخال عند معالجته. على سبيل المثال ، عندما نقرأ جملة ، فإننا بطبيعة الحال نولي مزيدًا من الاهتمام لبعض الكلمات أكثر من غيرها ، اعتمادًا على السياق وما نريد أن نفهمه.
إذا نظرت إلى محول ، فإن النموذج يحسب درجة لكل كلمة في تسلسل الإدخال بناءً على مدى أهميتها لفهم المعنى العام للتسلسل.
ثم يستخدم النموذج هذه الدرجات لتقييم أهمية كل كلمة في التسلسل ، مما يسمح له بالتركيز أكثر على الكلمات المهمة وبدرجة أقل على الكلمات غير المهمة.
تساعد آلية الانتباه هذه النموذج على التقاط التبعيات بعيدة المدى والعلاقات بين الكلمات التي قد تكون متباعدة في تسلسل الإدخال دون الحاجة إلى معالجة التسلسل بأكمله بالتسلسل.
هذا يجعل المحول قويًا جدًا لمهام معالجة اللغة الطبيعية ، حيث يمكنه فهم معنى الجملة أو سلسلة نصية أطول بسرعة وبدقة.
لنأخذ مثال نموذج محول يعالج الجملة "جلست القطة على البساط."
يتم تمثيل كل كلمة في الجملة كمتجه ، سلسلة من الأرقام ، باستخدام مصفوفة التضمين. لنفترض أن حفلات الزفاف لكل كلمة هي:
- : [0.2، 0.1، 0.3، 0.5]
- قط : [0.6 ، 0.3 ، 0.1 ، 0.2]
- جلس : [0.1 ، 0.8 ، 0.2 ، 0.3]
- في : [0.3 ، 0.1 ، 0.6 ، 0.4]
- في : [0.5، 0.2، 0.1، 0.4]
- حصيرة : [0.2 ، 0.4 ، 0.7 ، 0.5]
بعد ذلك ، يحسب المحول درجة لكل كلمة في الجملة بناءً على علاقتها مع جميع الكلمات الأخرى في الجملة.
يتم ذلك باستخدام المنتج النقطي لتضمين كل كلمة مع تضمين كل الكلمات الأخرى في الجملة.
على سبيل المثال ، لحساب النتيجة لكلمة "قطة" ، سنأخذ حاصل الضرب النقطي لتضمينها مع تضمين كل الكلمات الأخرى:
- " القط ": 0.2 * 0.6 + 0.1 * 0.3 + 0.3 * 0.1 + 0.5 * 0.2 = 0.24
- " جلس القط ": 0.6 * 0.1 + 0.3 * 0.8 + 0.1 * 0.2 + 0.2 * 0.3 = 0.31
- " قطة على ": 0.6 * 0.3 + 0.3 * 0.1 + 0.1 * 0.6 + 0.2 * 0.4 = 0.39
- " القط ": 0.6 * 0.5 + 0.3 * 0.2 + 0.1 * 0.1 + 0.2 * 0.4 = 0.42
- " حصيرة القط ": 0.6 * 0.2 + 0.3 * 0.4 + 0.1 * 0.7 + 0.2 * 0.5 = 0.32
تشير هذه الدرجات إلى صلة كل كلمة بكلمة "قطة". ثم يستخدم المحول هذه الدرجات لحساب مجموع مرجح لكلمة التضمينات ، حيث تكون الأوزان هي الدرجات.
يؤدي هذا إلى إنشاء متجه سياق لكلمة "قطة" يأخذ في الاعتبار العلاقات بين جميع الكلمات في الجملة. تتكرر هذه العملية لكل كلمة في الجملة.
فكر في الأمر على أنه محول يرسم خطًا بين كل كلمة في الجملة بناءً على نتيجة كل عملية حسابية. بعض السطور أكثر هشاشة ، والبعض الآخر أقل هشاشة.
المحول هو نوع جديد من النماذج يستخدم الانتباه فقط دون أي معالجة متكررة. هذا يجعلها أسرع بكثير وقادرة على التعامل مع المزيد من البيانات.
كيف تستخدم GPT المحولات
قد تتذكر أنه في إعلان Google BERT ، تفاخروا بأنه سمح للبحث بفهم السياق الكامل للإدخال. هذا مشابه لكيفية استخدام GPT للمحولات.
دعونا نستخدم القياس.
تخيل أن لديك مليون قرد ، كل منها يجلس أمام لوحة مفاتيح.
يقوم كل قرد بضرب المفاتيح بشكل عشوائي على لوحة المفاتيح الخاصة به ، مما يؤدي إلى إنشاء سلاسل من الأحرف والرموز.
بعض السلاسل محض هراء ، في حين أن البعض الآخر قد يشبه كلمات حقيقية أو حتى جمل متماسكة.
في أحد الأيام ، رأى أحد مدربي السيرك أن قردًا كتب "أكون أو لا أكون" ، لذا فإن المدرب يعطي القرد مكافأة.
ترى القردة الأخرى هذا وتبدأ في محاولة تقليد القرد الناجح ، على أمل الحصول على علاجهم الخاص.
مع مرور الوقت ، تبدأ بعض القرود في إنتاج سلاسل نصية أفضل وأكثر تماسكًا باستمرار ، بينما يستمر البعض الآخر في إنتاج هراء.
في النهاية ، يمكن للقرود التعرف على الأنماط المتماسكة في النص وحتى محاكاتها.
LLMs لها ساق على القرود لأن LLMs يتم تدريبها أولاً على مليارات الأجزاء من النص. يمكنهم بالفعل رؤية الأنماط. كما يفهمون المتجهات والعلاقات بين هذه الأجزاء من النص.
هذا يعني أنه يمكنهم استخدام تلك الأنماط والعلاقات لإنشاء نص جديد يشبه اللغة الطبيعية.
GPT ، الذي يرمز إلى Transformer Generative مُدرَّب مسبقًا ، هو نموذج لغة يستخدم المحولات لإنشاء نص بلغة طبيعية.
تم تدريبه على كمية هائلة من النصوص من الإنترنت ، مما سمح له بتعلم الأنماط والعلاقات بين الكلمات والعبارات في اللغة الطبيعية.
يعمل النموذج من خلال أخذ نص سريع أو بضع كلمات واستخدام المحولات للتنبؤ بالكلمات التي يجب أن تأتي بعد ذلك بناءً على الأنماط التي تعلمها من بيانات التدريب الخاصة به.
يستمر النموذج في إنشاء نص كلمة بكلمة ، باستخدام سياق الكلمات السابقة لإبلاغ الكلمات التالية.
GPT في العمل
تتمثل إحدى مزايا GPT في أنه يمكن إنشاء نص بلغة طبيعية متماسك للغاية وملائم للسياق.
هذا له العديد من التطبيقات العملية ، مثل إنشاء أوصاف المنتج أو الرد على استفسارات خدمة العملاء. كما يمكن استخدامها بشكل إبداعي ، مثل تأليف الشعر أو القصص القصيرة.
ومع ذلك ، فهو مجرد نموذج لغوي. يتم تدريبه على البيانات ، ويمكن أن تكون هذه البيانات قديمة أو غير صحيحة.
- ليس لديها مصدر للمعرفة.
- لا يمكن البحث في الإنترنت.
- إنه لا "يعرف" أي شيء.
إنه ببساطة يخمن ما هي الكلمة القادمة.
لنلقِ نظرة على بعض الأمثلة:
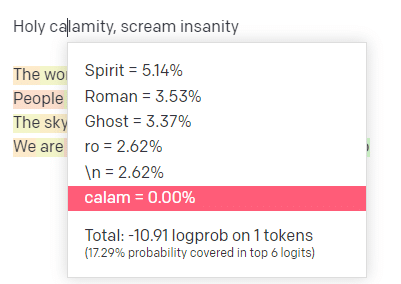
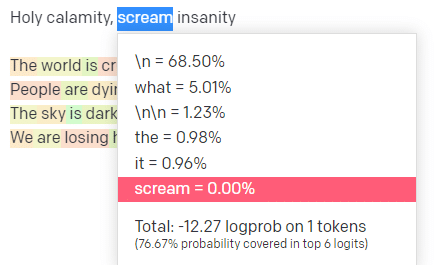
في ملعب OpenAI ، قمت بتوصيل السطر الأول من مسار مدرسة Handsome Boy Modeling School الكلاسيكية "الكارثة المقدسة [[Bear Witness ii]]".
لقد قدمت الرد حتى نتمكن من رؤية احتمالية كل من المدخلات وخطوط الإخراج. فلنستعرض كل جزء مما يخبرنا به هذا.
بالنسبة للكلمة / الرمز الأول ، أدخل "مقدس". يمكننا أن نرى أن المدخلات التالية الأكثر توقعًا هي الروح والرومان والشبح.
يمكننا أيضًا أن نرى أن النتائج الست الأولى تغطي فقط 17.29٪ من احتمالات ما سيأتي بعد ذلك: مما يعني أن هناك ~ 82٪ احتمالات أخرى لا يمكننا رؤيتها في هذا التصور.
دعنا نناقش بإيجاز المدخلات المختلفة التي يمكنك استخدامها في هذا وكيف تؤثر على مخرجاتك.
درجة الحرارة هي مدى احتمالية أن يلتقط النموذج كلمات أخرى غير الكلمات ذات الاحتمالية الأعلى ، أما الجزء العلوي P فهو كيفية تحديد هذه الكلمات.
لذلك بالنسبة للإدخال "كارثة مقدسة" ، فإن الجزء العلوي P هو كيفية اختيار مجموعة الرموز التالية [Ghost ، Roman ، Spirit] ، ودرجة الحرارة هي مدى احتمالية استخدام الرمز المميز مقابل المزيد من التنوع.
إذا كانت درجة الحرارة أعلى ، فمن الأرجح أن تختار رمزًا أقل احتمالًا .
لذلك من المحتمل أن تكون درجة الحرارة المرتفعة و P أعلى من المحتمل أن تكون أكثر وحشية. إنه يختار من بين مجموعة متنوعة (عالية أعلى P) ومن المرجح أن يختار الرموز المميزة المفاجئة.


في حين أن درجة الحرارة العالية ولكن الأعلى P ستختار خيارات مفاجئة من عينة أصغر من الاحتمالات:

ويختار خفض درجة الحرارة فقط الرموز التالية الأكثر احتمالاً:

اللعب بهذه الاحتمالات ، في رأيي ، يمكن أن يمنحك فكرة جيدة عن كيفية عمل هذه الأنواع من النماذج.
إنه يبحث في مجموعة من التحديدات التالية المحتملة بناءً على ما تم إكماله بالفعل.
ماذا يعني هذا في الواقع؟
ببساطة ، تأخذ LLM مجموعة من المدخلات وتهزها وتحولها إلى مخرجات.
لقد سمعت الناس يمزحون حول ما إذا كان هذا مختلفًا تمامًا عن الأشخاص.
لكنها ليست مثل الناس - ماجستير في القانون ليس لديها قاعدة معرفية. إنهم لا يستخرجون معلومات عن شيء ما. إنهم يخمنون سلسلة من الكلمات بناءً على الكلمة الأخيرة.
مثال آخر: فكر في تفاحة. ما يتبادر إلى الذهن؟
ربما يمكنك تدوير واحدة في عقلك.
ربما تتذكر رائحة بستان التفاح ، حلاوة السيدة الوردية ، إلخ.
ربما تفكر في ستيف جوبز.
الآن دعنا نرى ما الذي ستعود إليه عبارة "فكر في تفاحة".
ربما تكون قد سمعت عبارة "Stochastic Parrots" تطفو حول هذه النقطة.
الببغاوات العشوائية هو مصطلح يستخدم لوصف LLMs مثل GPT. الببغاء طائر يحاكي ما يسمعه.
لذا ، فإن LLM مثل الببغاوات في أنها تأخذ المعلومات (الكلمات) وتخرج شيئًا يشبه ما سمعوه. لكنها أيضًا عشوائية ، مما يعني أنها تستخدم الاحتمال لتخمين ما سيحدث بعد ذلك.
LLM جيدة في التعرف على الأنماط والعلاقات بين الكلمات ، لكن ليس لديهم أي فهم أعمق لما يرونه. لهذا السبب هم جيدون جدًا في إنشاء نص بلغة طبيعية ولكنهم لا يفهمونها.
استخدامات جيدة لـ LLM
ماجستير في القانون جيد في المهام الأكثر عمومية.
يمكنك عرض النص عليه ، وبدون تدريب ، يمكنه القيام بمهمة بهذا النص.
يمكنك رمي بعض النص وطلب تحليل المشاعر ، واطلب منه نقل هذا النص إلى ترميز منظم والقيام ببعض الأعمال الإبداعية (على سبيل المثال ، كتابة الخطوط العريضة).
لا بأس في أشياء مثل الكود. بالنسبة للعديد من المهام ، يمكن أن تصل إليك تقريبًا.
لكن مرة أخرى ، يعتمد على الاحتمالات والأنماط. لذلك ستكون هناك أوقات تلتقط فيها أنماطًا في مدخلاتك لا تعرف أنها موجودة.
يمكن أن يكون هذا إيجابيًا (رؤية أنماط لا يستطيع البشر) ، ولكنه قد يكون أيضًا سلبيًا (لماذا استجاب بهذه الطريقة؟).
كما أنه لا يمتلك حق الوصول إلى أي نوع من مصادر البيانات. سيواجه مُحسّنات محرّكات البحث الذين يستخدمونه للبحث عن الكلمات الرئيسية للترتيب وقتًا سيئًا.
لا يمكن البحث عن حركة المرور عن كلمة رئيسية. لا يحتوي على معلومات لبيانات الكلمات الرئيسية بخلاف تلك الكلمات الموجودة.

الشيء المثير في ChatGPT هو أنه نموذج لغة متاح بسهولة يمكنك استخدامه خارج الصندوق في مهام مختلفة. لكنها لا تخلو من المحاذير.
استخدامات جيدة لنماذج ML الأخرى
أسمع الناس يقولون إنهم يستخدمون LLM في مهام معينة ، والتي يمكن لخوارزميات وتقنيات البرمجة اللغوية العصبية الأخرى القيام بها بشكل أفضل.

لنأخذ مثالا ، استخراج الكلمات الرئيسية.
إذا استخدمت TF-IDF ، أو تقنية أخرى للكلمات الرئيسية ، لاستخراج الكلمات الرئيسية من مجموعة ، فأنا أعرف الحسابات الجارية في هذه التقنية.
هذا يعني أن النتائج ستكون قياسية وقابلة للتكرار ، وأنا أعلم أنها ستكون مرتبطة على وجه التحديد بتلك المجموعة.
مع LLMs مثل ChatGPT ، إذا كنت تطلب استخراج الكلمات الرئيسية ، فأنت لا تحصل بالضرورة على الكلمات الرئيسية المستخرجة من المجموعة. أنت تحصل على ما تعتقد GPT أنه سيكون استجابة للمجموعة + الكلمات الرئيسية المستخرجة.
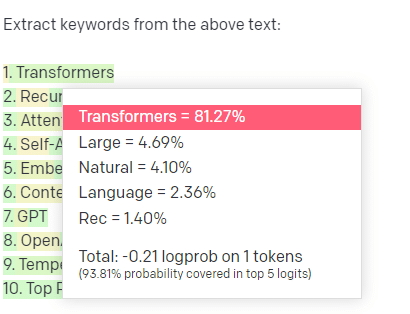
هذا مشابه لمهام مثل التجميع أو تحليل المشاعر. أنت لا تحصل بالضرورة على النتيجة الدقيقة باستخدام المعلمات التي قمت بتعيينها. إنك تحصل على ما يوجد بعض الاحتمالات بناءً على مهام أخرى مماثلة.
مرة أخرى ، ليس لدى LLM قاعدة معرفية ولا معلومات حالية. غالبًا لا يمكنهم البحث في الويب ، ويقومون بتحليل ما يحصلون عليه من المعلومات كرموز إحصائية. القيود المفروضة على المدة التي تدوم فيها ذاكرة LLM هي بسبب هذه العوامل.
شيء آخر هو أن هذه النماذج لا تستطيع التفكير. لا أستخدم كلمة "يفكر" إلا عدة مرات خلال هذه المقالة لأنه من الصعب حقًا عدم استخدامها عند الحديث عن هذه العمليات.
الاتجاه نحو التجسيم ، حتى عند مناقشة الإحصائيات الفاخرة.
لكن هذا يعني أنك إذا عهدت إلى ماجستير في أي مهمة تحتاج إلى "التفكير" ، فأنت لا تثق في مخلوق مفكر.
أنت تثق في تحليل إحصائي لما يستجيب به المئات من غريب الأطوار على الإنترنت لرموز مماثلة.
إذا كنت تثق في مستخدمي الإنترنت بمهمة ما ، فيمكنك استخدام LLM. خلاف ذلك…
الأشياء التي لا ينبغي أن تكون نماذج ML
يقال إن روبوت الدردشة الذي يمر عبر نموذج GPT (GPT-J) شجع الرجل على الانتحار. يمكن أن تسبب مجموعة العوامل ضررًا حقيقيًا ، بما في ذلك:
- الناس يجسدون هذه الاستجابات.
- اعتقادهم أنهم معصومون.
- استخدامها في الأماكن التي يجب أن يكون فيها البشر في الآلة.
- و اكثر.
بينما قد تعتقد ، "أنا مُحسن محركات البحث. ليس لدي يد في الأنظمة التي يمكن أن تقتل شخصًا ما! "
فكر في صفحات YMYL وكيف تروج Google لمفاهيم مثل EEAT.
هل تفعل Google هذا لأنها تريد مضايقة مُحسّنات محرّكات البحث ، أم لأنها لا تريد اللوم عن هذا الضرر؟
حتى في الأنظمة ذات قواعد المعرفة القوية ، يمكن إلحاق الضرر.
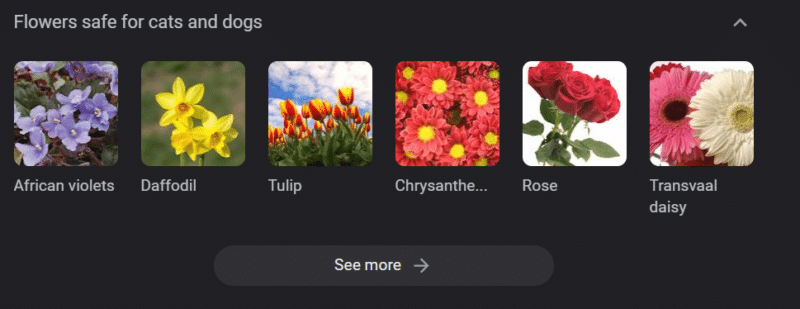
ما ورد أعلاه عبارة عن مكتبة معرفية من Google عن "زهور آمنة للقطط والكلاب". توجد أزهار النرجس في تلك القائمة على الرغم من كونها سامة للقطط.
لنفترض أنك تنشئ محتوى لموقع ويب بيطري على نطاق واسع باستخدام GPT. يمكنك توصيل مجموعة من الكلمات الرئيسية وإجراء اختبار ping على واجهة برمجة تطبيقات ChatGPT.
لديك مترجم مستقل يقرأ جميع النتائج ، وهم ليسوا خبراء في الموضوع. إنهم لا يتعاملون مع مشكلة.
أنت تنشر النتيجة ، مما يشجع على شراء أزهار النرجس لمالكي القطط.
أنت تقتل قطة شخص ما.
لا مباشرة. ربما لا يعرفون حتى أنه كان ذلك الموقع بالتحديد.
ربما تبدأ مواقع الأطباء البيطريين الأخرى في فعل الشيء نفسه وإطعام بعضها البعض.
أعلى نتيجة بحث في Google عن "أزهار النرجس سامة للقطط" هي موقع يقول أنها ليست كذلك.
يقرأ المستقلون الآخرون محتوى AI الآخر - صفحات على صفحات من محتوى AI - في الواقع تحقق من الحقائق. لكن الأنظمة لديها الآن معلومات غير صحيحة.
عند مناقشة طفرة الذكاء الاصطناعي الحالية ، أذكر Therac-25 كثيرًا. إنها دراسة حالة شهيرة عن مخالفات الكمبيوتر.
في الأساس ، كانت آلة علاج إشعاعي ، أول من استخدم آليات قفل الكمبيوتر فقط. خلل في البرنامج يعني أن الناس حصلوا على عشرات الآلاف من جرعة الإشعاع التي ينبغي أن يحصلوا عليها.
الشيء الذي يلفت انتباهي دائمًا هو أن الشركة استدعت طواعية وفحصت هذه النماذج.
لكنهم افترضوا أنه بما أن التكنولوجيا كانت متطورة والبرمجيات "معصومة من الخطأ" ، فإن المشكلة تتعلق بالأجزاء الميكانيكية للآلة.
وبالتالي ، قاموا بإصلاح الآليات لكنهم لم يتحققوا من البرنامج - وبقي Therac-25 في السوق.
الأسئلة الشائعة والمفاهيم الخاطئة
لماذا يكذب علي ChatGPT؟
هناك شيء واحد رأيته من بعض أعظم العقول في جيلنا ومن المؤثرين أيضًا على Twitter وهو الشكوى من أن ChatGPT "يكذب" عليهم. هذا بسبب اثنين من المفاهيم الخاطئة جنبًا إلى جنب:
- أن ChatGPT لديه "يريد".
- أن لديها قاعدة معرفية.
- أن التقنيين الذين يقفون وراء التكنولوجيا لديهم نوع من الأجندة تتجاوز "كسب المال" أو "صنع شيء رائع".
يتم تجسيد التحيزات في كل جزء من حياتك اليومية. وكذلك الاستثناءات من هذه التحيزات.
معظم مطوري البرمجيات حاليًا من الرجال: أنا مطور برامج وامرأة.
إن تدريب الذكاء الاصطناعي على أساس هذه الحقيقة سيؤدي إلى افتراض أن مطوري البرمجيات هم رجال ، وهذا ليس صحيحًا.
ومن الأمثلة الشهيرة على توظيف الذكاء الاصطناعي في أمازون ، والذي تم تدريبه على السير الذاتية من موظفي أمازون الناجحين.
أدى ذلك إلى إهمال السير الذاتية من الكليات ذات الأغلبية السوداء ، على الرغم من أن العديد من هؤلاء الموظفين كان من الممكن أن يكونوا ناجحين للغاية.
لمواجهة هذه التحيزات ، تستخدم أدوات مثل ChatGPT طبقات من الضبط الدقيق. هذا هو السبب في حصولك على استجابة "بصفتي نموذجًا للغة الذكاء الاصطناعي ، لا أستطيع ...".
كان على بعض العمال في كينيا المرور بمئات المطالبات ، والبحث عن الإهانات وخطاب الكراهية والاستجابات والمطالبات الرهيبة الصريحة.
ثم تم إنشاء طبقة صقل.
لماذا لا يمكنك اختلاق الإهانات لجو بايدن؟ لماذا يمكنك إلقاء نكات جنسية عن الرجال وليس النساء؟
لا يرجع ذلك إلى التحيز الليبرالي ولكن بسبب الآلاف من طبقات الضبط الدقيق التي تخبر ChatGPT بعدم قول كلمة N.
من الناحية المثالية ، سيكون ChatGPT محايدًا تمامًا بشأن العالم ، لكنهم يحتاجون إليه أيضًا لتعكس العالم.
إنها مشكلة مشابهة لتلك التي لدى Google.
ما هو صحيح ، وما الذي يجعل الناس سعداء وما يجعل الاستجابة الصحيحة للموجه هي في الغالب أشياء مختلفة جدًا .
لماذا يأتي ChatGPT باستشهادات وهمية؟
هناك سؤال آخر أراه كثيرًا وهو حول الاقتباسات المزيفة. لماذا بعضها مزيف والبعض الآخر حقيقي؟ لماذا بعض المواقع حقيقية لكن الصفحات مزيفة؟
نأمل ، من خلال قراءة كيفية عمل النماذج الإحصائية ، يمكنك تحليل ذلك. لكن إليك شرحًا موجزًا:
أنت نموذج لغة AI. لقد تدربت على الكثير من الويب.
يخبرك شخص ما أن تكتب عن شيء تقني - دعنا نقول تغيير التخطيط التراكمي.
ليس لديك الكثير من الأمثلة على أوراق CLS ، لكنك تعرف ما هي ، وأنت تعرف الشكل العام لمقال حول التقنيات. أنت تعرف نمط شكل هذا النوع من المقالات.

لذلك تبدأ بردك وتواجه نوعًا من المشكلة. بالطريقة التي تفهم بها الكتابة الفنية ، فأنت تعلم أن عنوان URL يجب أن يأتي بعد ذلك في جملتك.
حسنًا ، من خلال مقالات CLS الأخرى ، أنت تعلم أن Google و GTMetrix غالبًا ما يتم الاستشهاد بهما حول CLS ، لذا فهي سهلة.
لكنك تعلم أيضًا أن حيل CSS غالبًا ما يتم ربطها بمقالات الويب: فأنت تعلم أن عناوين URL الخاصة بحيل CSS عادةً ما تبدو بطريقة معينة: لذلك يمكنك إنشاء عنوان URL لحيل CSS مثل هذا:
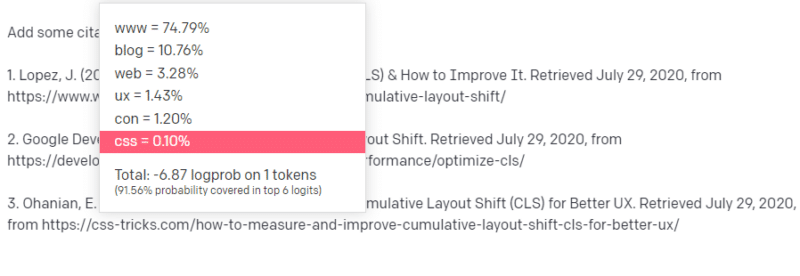
الحيلة هي: هذه هي الطريقة التي يتم بها إنشاء جميع عناوين URL ، وليس فقط الروابط المزيفة:

مقالة GTMetrix هذه موجودة بالفعل: لكنها موجودة لأنها كانت سلسلة محتملة من القيم تأتي في نهاية هذه الجملة.
لا تستطيع GPT والنماذج المماثلة التمييز بين الاقتباس الحقيقي والاقتباس المزيف.
الطريقة الوحيدة للقيام بهذا النمذجة هي استخدام مصادر أخرى (قواعد المعرفة ، Python ، إلخ) لتحليل هذا الاختلاف والتحقق من النتائج.
ما هو "الببغاء العشوائي"؟
أعلم أنني تجاوزت هذا بالفعل ، لكن الأمر يستحق التكرار. الببغاوات العشوائية هي طريقة لوصف ما يحدث عندما تبدو النماذج اللغوية الكبيرة عامة في طبيعتها.
بالنسبة إلى LLM ، الهراء والواقع هما نفس الشيء. إنهم يرون العالم كخبير اقتصادي ، كمجموعة من الإحصائيات والأرقام التي تصف الواقع.
أنت تعرف الاقتباس ، "هناك ثلاثة أنواع من الأكاذيب: الأكاذيب ، والأكاذيب اللعينة ، والإحصاءات."
LLMs هي مجموعة كبيرة من الإحصائيات.
تبدو LLM متماسكة ، لكن هذا لأننا نرى بشكل أساسي الأشياء التي تبدو بشرية على أنها إنسان.
وبالمثل ، فإن نموذج chatbot يخفي الكثير من المطالبات والمعلومات التي تحتاجها لكي تكون استجابات GPT متماسكة تمامًا.
أنا مطور: محاولة استخدام LLMs لتصحيح أخطاء الكود الخاص بي له نتائج متغيرة للغاية. إذا كانت مشكلة مماثلة لأحد الأشخاص الذين غالبًا ما واجهوه عبر الإنترنت ، فيمكن لـ LLM التقاط هذه النتيجة وإصلاحها.
إذا كانت مشكلة لم تتم مواجهتها من قبل ، أو كانت جزءًا صغيرًا من المجموعة ، فلن يتم إصلاح أي شيء.
لماذا تعد GPT أفضل من محرك البحث؟
لقد قمت بصياغة هذا بطريقة لاذعة. لا أعتقد أن GPT أفضل من محرك البحث. يقلقني أن الناس قد استبدلوا البحث بـ ChatGPT.
أحد الأجزاء غير المعترف بها في ChatGPT هو مقدار وجوده لاتباع التعليمات. يمكنك أن تطلب منه أن يفعل أي شيء بشكل أساسي.
لكن تذكر أن الأمر كله مبني على الكلمة التالية الإحصائية في الجملة ، وليس الحقيقة.
فإذا طرحت عليه سؤالاً ليس له إجابة جيدة ، ولكن سألته بطريقة تلزم إجابته ، فستحصل على إجابة سيئة.
الحصول على استجابة مصممة لك ومن حولك أكثر راحة ، لكن العالم عبارة عن مجموعة من التجارب.
يتم التعامل مع جميع المدخلات في LLM بالطريقة نفسها: لكن بعض الأشخاص لديهم خبرة ، وستكون استجابتهم أفضل من مزيج من ردود الآخرين.
خبير واحد يستحق أكثر من ألف قطعة فكرية.
هل هذا بزوغ فجر الذكاء الاصطناعي؟ هل Skynet هنا؟
كان كوكو الغوريلا قردًا تعلم لغة الإشارة. أجرى الباحثون في الدراسات اللغوية الكثير من الأبحاث التي أظهرت أنه يمكن تعليم القردة اللغة.
اكتشف هربرت تيراس بعد ذلك أن القردة لم تكن تجمع جملًا أو كلمات ولكن ببساطة تقلد معالجيها من البشر.
كانت إليزا معالجًا آليًا ، وكانت من أوائل الروبوتات الثرثرة (روبوتات المحادثة).
رآها الناس كشخص: معالج يثقون به ويهتمون به. طلبوا من الباحثين أن يكونوا بمفردها معها.
اللغة تفعل شيئًا محددًا جدًا لأدمغة الناس. يسمع الناس شيئًا ما يتواصل ويتوقعون التفكير وراءه.
ماجستير في القانون مثير للإعجاب ولكن بطريقة تظهر اتساع نطاق الإنجازات البشرية.
LLMs ليس لديها وصايا. لا يمكنهم الهروب. لا يمكنهم محاولة السيطرة على العالم.
إنها مرآة: انعكاس للأشخاص والمستخدم على وجه التحديد.
الفكر الوحيد هو وجود تمثيل إحصائي للعقل الجماعي.
هل تعلمت GPT لغة كاملة بمفردها؟
سوندار بيتشاي ، الرئيس التنفيذي لشركة Google ، ذهب في برنامج "60 دقيقة" وادعى أن نموذج اللغة لدى Google تعلم البنغالية.
تم تدريب النموذج على تلك النصوص. من الخطأ أنه "تحدث بلغة أجنبية لم يتدرب على معرفتها قط".
هناك أوقات يقوم فيها الذكاء الاصطناعي بأشياء غير متوقعة ، ولكن هذا في حد ذاته متوقع.
عندما تنظر إلى الأنماط والإحصاءات على نطاق واسع ، ستكون هناك بالضرورة أوقات تكشف فيها هذه الأنماط عن شيء مثير للدهشة.
ما يكشفه هذا حقًا هو أن العديد من C Suite وأفراد التسويق الذين يبيعون الذكاء الاصطناعي والتعلم الآلي لا يفهمون في الواقع كيفية عمل الأنظمة.
لقد سمعت بعض الأشخاص الأذكياء جدًا يتحدثون عن الخصائص الناشئة والذكاء العام الاصطناعي (AGI) وأشياء أخرى مستقبلية.
قد أكون مجرد مهندس عمليات تعلم بسيط في بلد بسيط ، لكنه يُظهر مقدار الضجيج والوعود والخيال العلمي والواقع معًا عند الحديث عن هذه الأنظمة.
إليزابيث هولمز ، مؤسِسة ثيرانوس سيئة السمعة ، صُلبت لأنها قدمت وعودًا لا يمكن الوفاء بها.
لكن دورة تقديم الوعود المستحيلة هي جزء من ثقافة الشركات الناشئة وجني الأموال. الفرق بين Theranos و AI hype هو أن Theranos لم يستطع تزييفه لفترة طويلة.
هل GPT صندوق أسود؟ ماذا يحدث لبياناتي في GPT؟
GPT ، كنموذج ، ليس صندوقًا أسود. يمكنك رؤية الكود المصدري لكل من GPT-J و GPT-Neo.
ومع ذلك ، فإن GPT الخاص بـ OpenAI هو صندوق أسود. لم تحاول OpenAI ومن المحتمل ألا تطلق نموذجها ، لأن Google لا تصدر الخوارزمية.
لكن هذا ليس لأن الخوارزمية خطيرة للغاية. إذا كان هذا صحيحًا ، فلن يبيعوا اشتراكات API لأي شخص سخيف لديه جهاز كمبيوتر. إنه بسبب قيمة قاعدة بيانات الملكية تلك.
عندما تستخدم أدوات OpenAI ، فأنت تقوم بتدريب وتغذية واجهة برمجة التطبيقات الخاصة بهم على مدخلاتك. هذا يعني أن كل شيء تضعه في OpenAI يغذيها.
هذا يعني أن الأشخاص الذين استخدموا نموذج GPT الخاص بـ OpenAI على بيانات المريض للمساعدة في كتابة الملاحظات وأشياء أخرى قد انتهكوا HIPAA. هذه المعلومات موجودة الآن في النموذج ، وسيكون من الصعب للغاية استخراجها.
نظرًا لأن الكثير من الأشخاص يواجهون صعوبات في فهم هذا ، فمن المحتمل جدًا أن النموذج يحتوي على الكثير من البيانات الخاصة ، فقط في انتظار المطالبة الصحيحة لإصدارها.
لماذا يتم تدريب GPT على الكلام الذي يحض على الكراهية؟
الشيء الآخر الذي يظهر كثيرًا هو أن النص الذي تم تدريب GPT عليه يتضمن الكلام الذي يحض على الكراهية.
إلى حد ما ، تحتاج OpenAI إلى تدريب نماذجها على الاستجابة لخطاب الكراهية ، لذا فهي بحاجة إلى مجموعة تتضمن بعض هذه المصطلحات.
زعمت شركة OpenAI أنها تحجب هذا النوع من خطاب الكراهية من النظام ، لكن وثائق المصدر تتضمن 4chan وأطنانًا من مواقع الكراهية.
الزحف على الويب ، واستيعاب التحيز.
لا توجد طريقة سهلة لتجنب ذلك. كيف يمكنك التعرف على شيء ما أو فهمه للكراهية والتحيز والعنف دون أن يكون جزءًا من مجموعة التدريب الخاصة بك؟
كيف تتجنب التحيزات وتفهم التحيزات الضمنية والصريحة عندما تكون وكيل آلة تختار إحصائيًا الرمز المميز التالي في الجملة؟
TL ؛ DR
يُعد الضجيج والمعلومات المضللة حاليًا من العناصر الرئيسية لازدهار الذكاء الاصطناعي. هذا لا يعني أنه لا توجد استخدامات مشروعة: فهذه التكنولوجيا مدهشة ومفيدة.
ولكن كيف يتم تسويق التكنولوجيا وكيف يستخدمها الناس يمكن أن يعزز المعلومات المضللة والانتحال وحتى التسبب في ضرر مباشر.
لا تستخدم LLM عندما تكون الحياة على المحك. لا تستخدم LLMs عندما يكون أداء خوارزمية مختلفة أفضل. لا تنخدع بالضجيج.
من الضروري فهم ما هي LLM - وما هي ليست كذلك
أوصي بمقابلة آدم كونوفر هذه مع إميلي بندر وتيمنيت جيبرو.
يمكن أن تكون LLM أدوات رائعة عند استخدامها بشكل صحيح. هناك العديد من الطرق التي يمكنك من خلالها استخدام LLM والمزيد من الطرق لإساءة استخدام LLM.
ChatGPT ليس صديقك. إنها مجموعة من الإحصائيات. AGI ليس "هنا بالفعل".
الآراء الواردة في هذا المقال هي آراء المؤلف الضيف وليست بالضرورة آراء محرك البحث. مؤلفو طاقم العمل مدرجون هنا.