
Spark vs Hadoop: ما هو إطار البيانات الضخمة الذي سيرفع عملك؟
نشرت: 2019-09-24"البيانات هي وقود الاقتصاد الرقمي"
مع اعتماد الشركات الحديثة على كومة من البيانات لفهم المستهلكين والسوق بشكل أفضل ، تكتسب التقنيات مثل البيانات الضخمة زخمًا هائلاً.
البيانات الضخمة ، مثلها مثل الذكاء الاصطناعي ، لم تندرج فقط في قائمة أفضل الاتجاهات التكنولوجية لعام 2020 ، ولكن من المتوقع أن تتبناها الشركات الناشئة وشركات Fortune 500 للاستمتاع بنمو الأعمال المتسارع وضمان ولاء أعلى للعملاء. ومن المؤشرات الواضحة على ذلك أنه من المتوقع أن يصل حجم سوق البيانات الضخمة إلى 103 مليار دولار بحلول عام 2027.
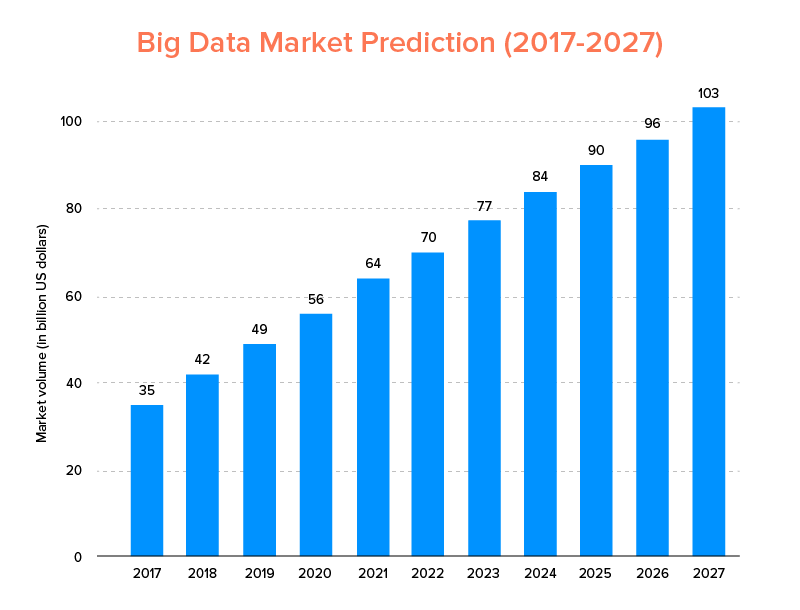
الآن ، في حين أن هذا من جانب واحد ، فإن الجميع متحمس للغاية لاستبدال أدوات تحليل البيانات التقليدية الخاصة بهم بالبيانات الكبيرة - تلك التي تمهد الطريق لتقدم Blockchain و AI ، إلا أنهم مرتبكون أيضًا بشأن اختيار أداة البيانات الضخمة المناسبة. إنهم يواجهون معضلة الاختيار بين Apache Hadoop و Spark - عملاقي عالم البيانات الضخمة.
لذلك ، بالنظر إلى هذه الفكرة ، سنقوم اليوم بتغطية مقال عن Apache Spark vs Hadoop ونساعدك على تحديد الخيار المناسب لاحتياجاتك.
ولكن ، أولاً ، دعنا نحصل على مقدمة موجزة لما هو Hadoop و Spark.
Apache Hadoop هو إطار عمل مفتوح المصدر وموزع وقائم على Java يمكّن المستخدمين من تخزين البيانات الضخمة ومعالجتها عبر مجموعات متعددة من أجهزة الكمبيوتر باستخدام تركيبات برمجة بسيطة. وهي تتألف من وحدات مختلفة تعمل معًا لتقديم تجربة محسّنة ، وهي: -
- Hadoop المشتركة
- نظام الملفات الموزعة Hadoop (HDFS)
- Hadoop الغزل
- Hadoop MapReduce
حيث إن Apache Spark عبارة عن إطار عمل للبيانات الضخمة للحوسبة العنقودية الموزعة مفتوح المصدر وهو "سهل الاستخدام" ويقدم خدمات أسرع.
يتم دعم إطاري البيانات الضخمة من قبل العديد من الشركات الكبيرة بسبب مجموعة الفرص التي توفرها.
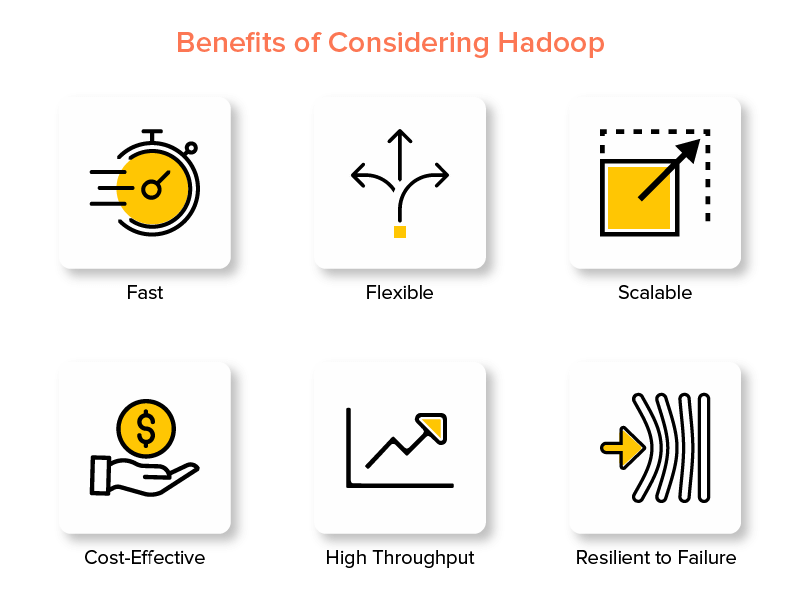
مزايا Hadoop Big Data Framework
1. سريع
تتمثل إحدى ميزات Hadoop التي تجعله مشهورًا في عالم البيانات الضخمة في أنه سريع.
تعتمد طريقة التخزين الخاصة به على نظام ملفات موزع يقوم بشكل أساسي "بتعيين" البيانات أينما كان موجودًا في مجموعة. أيضًا ، عادةً ما تكون البيانات والأدوات المستخدمة في معالجة البيانات متاحة على نفس الخادم ، مما يجعل معالجة البيانات مهمة خالية من المتاعب وأسرع.
في الواقع ، تم العثور على أن Hadoop يمكنه معالجة تيرابايت من البيانات غير المهيكلة في بضع دقائق فقط ، في حين أن البيتابايت في غضون ساعات.
2. مرنة
يوفر Hadoop ، على عكس أدوات معالجة البيانات التقليدية ، مرونة عالية.
يتيح للشركات جمع البيانات من مصادر مختلفة (مثل وسائل التواصل الاجتماعي ، ورسائل البريد الإلكتروني ، وما إلى ذلك) ، والعمل مع أنواع بيانات مختلفة (منظمة وغير منظمة) ، والحصول على رؤى قيمة لاستخدامها في أغراض متنوعة (مثل معالجة السجلات ، وتحليل حملة السوق ، كشف الاحتيال ، إلخ).
3. قابلة للتطوير
ميزة أخرى لـ Hadoop هي أنه قابل للتطوير بدرجة كبيرة. النظام الأساسي ، على عكس أنظمة قواعد البيانات العلائقية التقليدية (RDBMS) ، يمكّن الشركات من تخزين مجموعات البيانات الكبيرة وتوزيعها من مئات الخوادم التي تعمل بشكل متوازي.
4. فعالة من حيث التكلفة
يعد Apache Hadoop ، عند مقارنته بأدوات تحليل البيانات الضخمة الأخرى ، غير مكلف كثيرًا. هذا لأنه لا يتطلب أي آلة متخصصة ؛ يتم تشغيله على مجموعة من الأجهزة السلعية. أيضًا ، من الأسهل إضافة المزيد من العقد على المدى الطويل.
بمعنى ، حالة واحدة تزيد العقد بسهولة دون أن تعاني من أي توقف عن العمل لمتطلبات التخطيط المسبق.
5. إنتاجية عالية
في حالة إطار عمل Hadoop ، يتم تخزين البيانات بطريقة موزعة بحيث يتم تقسيم مهمة صغيرة إلى أجزاء متعددة من البيانات على التوازي. هذا يجعل من السهل على الشركات إنجاز المزيد من الوظائف في وقت أقل ، مما يؤدي في النهاية إلى زيادة الإنتاجية.
6. مرونة في مواجهة الفشل
أخيرًا وليس آخرًا ، يقدم Hadoop خيارات عالية للتسامح مع الأخطاء مما يساعد على التخفيف من عواقب الفشل. يخزن نسخة طبق الأصل من كل كتلة تجعل من الممكن استعادة البيانات كلما تعطلت أي عقدة.
عيوب Hadoop Framework
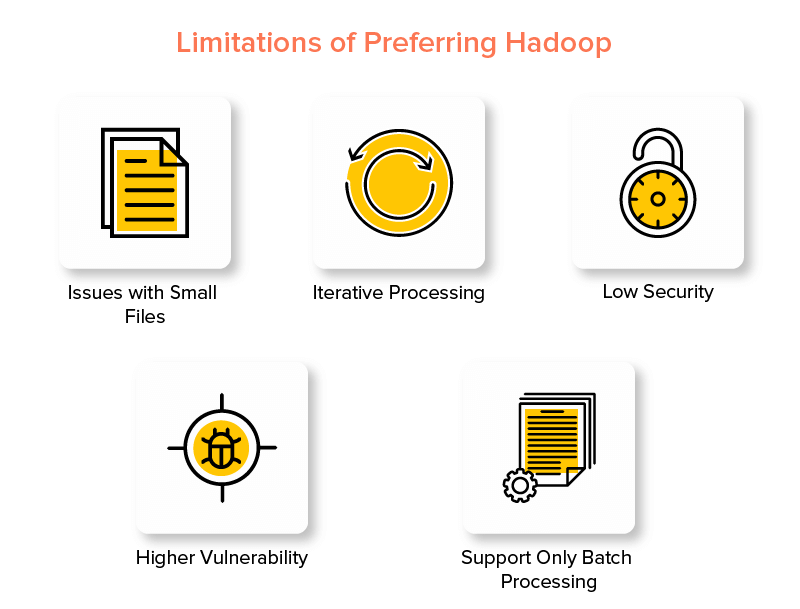
1. مشاكل مع الملفات الصغيرة
أكبر عيب في التفكير في Hadoop لتحليلات البيانات الكبيرة هو أنه يفتقر إلى القدرة على دعم القراءة العشوائية للملفات الصغيرة بكفاءة وفعالية.
السبب وراء ذلك هو أن الملف الصغير يحتوي على حجم ذاكرة أقل نسبيًا من حجم كتلة HDFS. في مثل هذا السيناريو ، إذا قام المرء بتخزين عدد كبير من الملفات الصغيرة ، فهناك فرص أكبر لزيادة التحميل على NameNode الذي يخزن مساحة اسم HDFS ، وهي فكرة غير جيدة عمليًا.
2. المعالجة التكرارية
يكون تدفق البيانات في إطار عمل Hadoop للبيانات الضخمة في شكل سلسلة ، بحيث يصبح إخراج أحدهم مدخلات لمرحلة أخرى. في حين أن تدفق البيانات في المعالجة التكرارية يكون دوريًا بطبيعته.
لهذا السبب ، يعد Hadoop خيارًا غير مناسب للتعلم الآلي أو الحلول القائمة على المعالجة التكرارية.
3. الأمن المنخفض
عيب آخر لاستخدام Hadoop framework هو أنه يوفر ميزات أمان أقل.
إطار العمل ، على سبيل المثال ، تم تعطيل نموذج الأمان بشكل افتراضي. إذا كان شخص ما يستخدم أداة البيانات الضخمة هذه لا يعرف كيفية تمكينها ، فقد تكون بياناته أكثر عرضة للسرقة / إساءة الاستخدام. أيضًا ، لا يوفر Hadoop وظيفة التشفير على مستويات التخزين والشبكة ، مما يزيد مرة أخرى من فرص تهديد اختراق البيانات.
4. ضعف أعلى
تتم كتابة إطار عمل Hadoop بلغة Java ، وهي لغة البرمجة الأكثر شيوعًا واستغلالًا بشكل كبير. هذا يسهل على مجرمي الإنترنت الوصول بسهولة إلى الحلول المستندة إلى Hadoop وإساءة استخدام البيانات الحساسة.
5. دعم معالجة الدُفعات فقط
على عكس العديد من أطر عمل البيانات الضخمة الأخرى ، لا يقوم Hadoop بمعالجة البيانات المتدفقة. يدعم معالجة الدُفعات فقط ، والسبب وراء ذلك هو أن MapReduce فشل في الاستفادة من ذاكرة Hadoop Cluster إلى أقصى حد.
في حين أن هذا كله يتعلق بـ Hadoop وميزاته وعيوبه ، فلنلقِ نظرة على إيجابيات وسلبيات Spark لإيجاد سهولة في فهم الفرق بين الاثنين.
فوائد Apache Spark Framework
1. ديناميكية في الطبيعة
نظرًا لأن Apache Spark يقدم حوالي 80 مشغلًا رفيع المستوى ، فيمكن استخدامه لمعالجة البيانات ديناميكيًا. يمكن اعتباره أداة البيانات الضخمة المناسبة لتطوير وإدارة التطبيقات المتوازية.
2. قوية
نظرًا لقدرتها على معالجة البيانات في الذاكرة بزمن انتقال منخفض وتوافر العديد من المكتبات المدمجة للتعلم الآلي وخوارزميات تحليلات الرسم البياني ، يمكنها التعامل مع تحديات التحليلات المختلفة. وهذا يجعله خيارًا قويًا للبيانات الضخمة في السوق.
3. تحليلات متقدمة
ميزة أخرى مميزة لـ Spark هي أنه لا يشجع فقط "MAP" و "تقليل" ، ولكنه يدعم أيضًا التعلم الآلي (ML) واستعلامات SQL وخوارزميات الرسم البياني وتدفق البيانات. هذا يجعلها مناسبة للاستمتاع بالتحليلات المتقدمة.
4. إعادة الاستخدام
على عكس Hadoop ، يمكن إعادة استخدام كود Spark لمعالجة الدُفعات ، وتشغيل استعلامات مخصصة في حالة البث ، والانضمام إلى الدفق مقابل البيانات التاريخية ، والمزيد.
5. معالجة الدفق في الوقت الحقيقي
ميزة أخرى لاستخدام Apache Spark هي أنه يتيح معالجة البيانات ومعالجتها في الوقت الفعلي.
6. دعم متعدد اللغات
أخيرًا وليس آخرًا ، تدعم أداة تحليل البيانات الضخمة هذه لغات متعددة للترميز ، بما في ذلك Java و Python و Scala.
حدود أداة Spark Big Data
1. لا توجد عملية إدارة ملف
العيب الرئيسي لاستخدام Apache Spark هو أنه لا يحتوي على نظام إدارة الملفات الخاص به. يعتمد على منصات أخرى مثل Hadoop لتلبية هذا المطلب.

2. خوارزميات قليلة
يتخلف Apache Spark أيضًا عن أطر البيانات الضخمة الأخرى عند التفكير في توفر الخوارزميات مثل مسافة تانيموتو.
3. مشكلة الملفات الصغيرة
عيب آخر لاستخدام Spark هو أنه لا يتعامل مع الملفات الصغيرة بكفاءة.
هذا لأنه يعمل مع نظام الملفات الموزعة Hadoop (HDFS) الذي يجد أنه من الأسهل إدارة عدد محدود من الملفات الكبيرة على عدد كبير من الملفات الصغيرة.
4. لا توجد عملية تحسين تلقائية
على عكس العديد من الأنظمة الأساسية الأخرى القائمة على البيانات الضخمة والسحابة ، لا يوجد لدى Spark أي عملية تحسين تلقائية للرمز. على المرء أن يقوم بتحسين الكود يدويًا فقط.
5. غير مناسب لبيئة متعددة المستخدمين
نظرًا لأن Apache Spark لا يمكنه التعامل مع عدة مستخدمين في نفس الوقت ، فإنه لا يعمل بكفاءة في بيئة متعددة المستخدمين. شيء يضيف مرة أخرى إلى حدوده.
مع أساسيات أطر عمل البيانات الضخمة المغطاة ، من المحتمل أنك تأمل في التعرف على الاختلافات بين Spark و Hadoop.
لذلك ، دعونا لا ننتظر أكثر من ذلك ونتجه نحو المقارنة لنرى أيهما يقود معركة "Spark vs Hadoop".
Spark vs Hadoop: كيف تتراكم أداتا البيانات الضخمة ضد بعضهما البعض
[معرف الجدول = 38 /]
1. العمارة
عندما يتعلق الأمر بهندسة Spark و Hadoop ، فإن الأخير يتقدم حتى عندما يعمل كلاهما في بيئة الحوسبة الموزعة.
هذا لأن بنية Hadoop - على عكس Spark - لها عنصرين رئيسيين - HDFS (نظام الملفات الموزعة Hadoop) و YARN (مفاوض آخر حول الموارد). هنا ، يتعامل HDFS مع تخزين البيانات الضخمة عبر عقد متنوعة ، بينما تتولى YARN مهام المعالجة عبر آليات تخصيص الموارد وجدولة الوظائف. يتم بعد ذلك تقسيم هذه المكونات إلى المزيد من المكونات لتقديم حلول أفضل مع خدمات مثل تحمل الأعطال.
2. سهولة الاستخدام
يتيح Apache Spark للمطورين تقديم العديد من واجهات برمجة التطبيقات سهلة الاستخدام مثل تلك الخاصة بـ Scala و Python و R و Java و Spark SQL في بيئة التطوير الخاصة بهم. كما أنه يأتي محملاً بوضع تفاعلي يدعم كلا من المستخدمين والمطورين. هذا يجعله سهل الاستخدام ومنحنى تعليمي منخفض.
بينما ، عند الحديث عن Hadoop ، فإنه يقدم وظائف إضافية لدعم المستخدمين ، ولكن ليس الوضع التفاعلي. هذا يجعل Spark تفوز على Hadoop في معركة "البيانات الضخمة" هذه.
3. الأمن والتسامح مع الخطأ
بينما يقدم كل من Apache Spark و Hadoop MapReduce إمكانية التسامح مع الخطأ ، فإن الأخير يفوز بالمعركة.
هذا لأنه يجب على المرء أن يبدأ من نقطة الصفر في حالة تعطل العملية في منتصف العملية في بيئة Spark. ولكن عندما يتعلق الأمر بـ Hadoop ، يمكنهم المتابعة من نقطة الانهيار نفسه.
4. الأداء
عندما يتعلق الأمر بالتفكير في أداء Spark vs MapReduce ، يفوز الأول على الأخير.
إطار عمل Spark قادر على العمل 10 مرات أسرع على القرص و 100 مرة في الذاكرة. هذا يجعل من الممكن إدارة 100 تيرابايت من البيانات أسرع 3 مرات من Hadoop MapReduce.
5. معالجة البيانات
هناك عامل آخر يجب مراعاته أثناء مقارنة Apache Spark و Hadoop وهو معالجة البيانات.
بينما يوفر Apache Hadoop فرصة لمعالجة الدُفعات فقط ، يتيح إطار عمل البيانات الضخمة الآخر العمل مع المعالجة التفاعلية والتكرارية والدفق والرسم البياني والدُفعات. شيء يثبت أن Spark هو خيار أفضل للاستمتاع بخدمات معالجة البيانات بشكل أفضل.
6. التوافق
توافق Spark و Hadoop MapReduce هو نفسه إلى حد ما.
بينما في بعض الأحيان ، يعمل كلا إطاري البيانات الضخمة كتطبيقات قائمة بذاتها ، إلا أنهما يمكنهما العمل معًا أيضًا. يمكن تشغيل Spark بكفاءة أعلى Hadoop YARN ، بينما يمكن لـ Hadoop التكامل بسهولة مع Sqoop و Flume. لهذا السبب ، يدعم كلاهما مصادر البيانات وتنسيقات الملفات لبعضهما البعض.
7. الأمن
يتم تحميل بيئة Spark بميزات أمان مختلفة مثل تسجيل الأحداث واستخدام مرشحات javax servlet لحماية واجهات مستخدم الويب. أيضًا ، يشجع المصادقة عبر السر المشترك ويمكنه الاستفادة من أذونات ملف HDFS والتشفير بين الأوضاع و Kerberos عند دمجها مع YARN و HDFS.
حيث أن Hadoop يدعم مصادقة Kerberos ، ومصادقة الجهات الخارجية ، وأذونات الملفات التقليدية ، وقوائم التحكم في الوصول ، والمزيد ، مما يوفر في النهاية نتائج أمان أفضل.
لذلك ، عند النظر في مقارنة Spark و Hadoop من حيث الأمان ، فإن الأخير يتقدم.
8. فعالية التكلفة
عند مقارنة Hadoop و Spark ، يحتاج الأول إلى ذاكرة أكبر على القرص بينما يتطلب الأخير ذاكرة RAM أكبر. أيضًا ، نظرًا لأن Spark جديد تمامًا مقارنة بـ Apache Hadoop ، فإن المطورين الذين يعملون مع Spark نادرون.
هذا يجعل العمل مع Spark أمرًا مكلفًا. بمعنى ، يقدم Hadoop حلولًا فعالة من حيث التكلفة عندما يركز المرء على تكلفة Hadoop مقابل Spark.
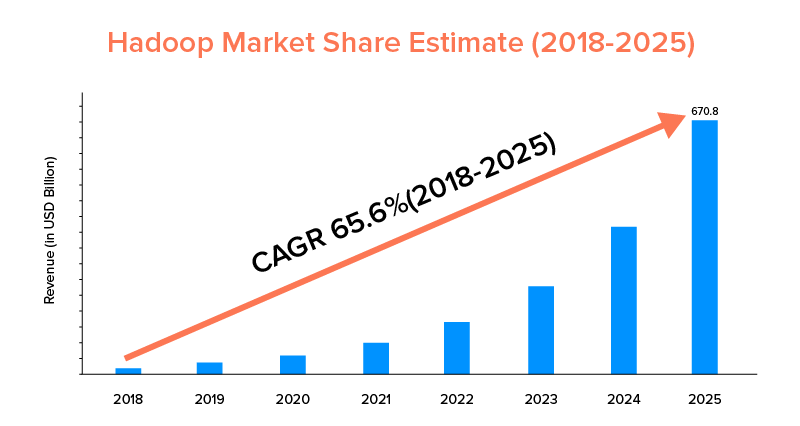
9. نطاق السوق
في حين أن كل من Apache Spark و Hadoop مدعومان من قبل الشركات الكبرى وتم استخدامهما لأغراض مختلفة ، فإن هذا الأخير يتصدر من حيث نطاق السوق.
وفقًا لإحصائيات السوق ، من المتوقع أن ينمو سوق Apache Hadoop بمعدل نمو سنوي مركب يبلغ 65.6٪ خلال الفترة من 2018 إلى 2025 ، مقارنةً بـ Spark بمعدل نمو سنوي مركب يبلغ 33.9٪ فقط.
في حين أن هذه العوامل ستساعد في تحديد أداة البيانات الضخمة المناسبة لعملك ، فمن المربح التعرف على حالات استخدامها. لذا ، دعنا نغطي هنا.
حالات استخدام إطار عمل Apache Spark
تتبنى الشركات أداة البيانات الضخمة هذه عندما ترغب في:
- دفق البيانات وتحليلها في الوقت الفعلي.
- استمتع بقوة التعلم الآلي.
- العمل مع التحليلات التفاعلية.
- تقديم Fog and Edge Computing لنموذج أعمالهم.
حالات استخدام إطار Apache Hadoop
يفضل Hadoop من قبل الشركات الناشئة والمؤسسات عندما يريدون: -
- تحليل بيانات الأرشيف.
- استمتع بتداول مالي وخيارات تنبؤ أفضل.
- تنفيذ العمليات التي تتألف من أجهزة السلع الأساسية.
- ضع في اعتبارك معالجة البيانات الخطية.
مع هذا ، نأمل أن تكون قد قررت من هو الفائز في معركة "Spark vs Hadoop" فيما يتعلق بعملك. إذا لم يكن الأمر كذلك ، فلا تتردد في الاتصال بخبراء البيانات الضخمة لدينا لإزالة كل الشكوك والحصول على خدمات مثالية مع نسبة نجاح أعلى.
أسئلة مكررة
1. ما هو إطار البيانات الضخمة الذي يجب اختياره؟
يعتمد الاختيار تمامًا على احتياجات عملك. إذا كنت تركز على الأداء وتوافق البيانات وسهولة الاستخدام ، فإن Spark أفضل من Hadoop. حيث أن إطار عمل البيانات الضخمة Hadoop يكون أفضل عندما تركز على الهندسة المعمارية والأمان والفعالية من حيث التكلفة.
2. ما هو الفرق بين Hadoop و Spark؟
هناك اختلافات مختلفة بين Spark و Hadoop. فمثلا:-
- شرارة هو عامل 100 مرة أن Hadoop MapReduce.
- بينما يتم استخدام Hadoop لمعالجة الدُفعات ، فإن Spark مخصصة للدُفعات والرسم البياني والتعلم الآلي والمعالجة التكرارية.
- Spark مضغوط وأسهل من إطار عمل البيانات الضخمة Hadoop.
- على عكس Spark ، لا يدعم Hadoop التخزين المؤقت للبيانات.
3. هل شرارة أفضل من Hadoop؟
Spark أفضل من Hadoop عندما يكون تركيزك الأساسي على السرعة والأمان. ومع ذلك ، في حالات أخرى ، تتخلف أداة تحليل البيانات الضخمة هذه عن Apache Hadoop.
4. لماذا سبارك أسرع من Hadoop؟
Spark أسرع من Hadoop بسبب انخفاض عدد دورات القراءة / الكتابة على القرص وتخزين البيانات الوسيطة في الذاكرة.
5. ما هو استخدام اباتشي سبارك؟
يستخدم Apache Spark لتحليل البيانات عندما يريد المرء-
- تحليل البيانات في الوقت الحقيقي.
- أدخل ML و Fog Computing في نموذج عملك.
- العمل مع التحليلات التفاعلية.