
TW-BERT: ترجيح مصطلح الاستعلام الشامل ومستقبل بحث Google
نشرت: 2023-09-14البحث صعب، كما كتب سيث جودين في عام 2005.
أعني، إذا كنا نعتقد أن تحسين محركات البحث (SEO) أمر صعب (وهو كذلك) فتخيل لو كنت تحاول بناء محرك بحث في عالم حيث:
- يختلف المستخدمون بشكل كبير ويغيرون تفضيلاتهم بمرور الوقت.
- التكنولوجيا التي يصلون إليها تتقدم في البحث كل يوم.
- المنافسون يقضمون كعبك باستمرار.
علاوة على ذلك، فأنت تتعامل أيضًا مع مُحسنات محركات البحث المزعجة التي تحاول التلاعب بالخوارزمية للحصول على رؤى حول أفضل السبل لتحسين زوار موقعك.
وهذا سيجعل الأمر أصعب بكثير.
تخيل الآن ما إذا كانت التقنيات الرئيسية التي تحتاج إلى الاعتماد عليها لتحقيق التقدم لها حدودها الخاصة - وربما الأسوأ من ذلك، تكاليفها الهائلة.
حسنًا، إذا كنت أحد مؤلفي الورقة البحثية المنشورة مؤخرًا، "ترجيح مصطلح الاستعلام من النهاية إلى النهاية"، فإنك ترى في ذلك فرصة للتألق.
ما هو ترجيح مصطلح الاستعلام الشامل؟
يشير ترجيح مصطلح الاستعلام من طرف إلى طرف إلى طريقة يتم فيها تحديد وزن كل مصطلح في الاستعلام كجزء من النموذج العام، دون الاعتماد على أنظمة ترجيح المصطلحات المبرمجة يدويًا أو التقليدية أو النماذج المستقلة الأخرى.
كيف يبدو ذلك؟
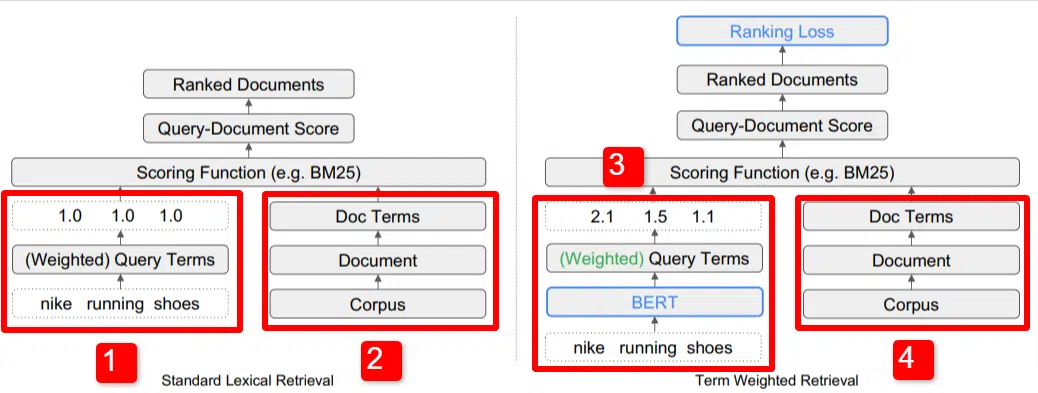
نرى هنا رسمًا توضيحيًا لأحد الفروق الرئيسية للنموذج الموضح في الورقة (الشكل 1، على وجه التحديد).
على الجانب الأيمن من النموذج القياسي (2) نرى نفس ما نفعله مع النموذج المقترح (4)، وهو المتن (مجموعة كاملة من الوثائق في الفهرس)، المؤدي إلى المستندات، المؤدي إلى المصطلحات.
يوضح هذا التسلسل الهرمي الفعلي للنظام، ولكن يمكنك التفكير فيه بشكل عكسي، من الأعلى إلى الأسفل. لدينا شروط. نحن نبحث عن وثائق بهذه الشروط. هذه الوثائق موجودة في مجموعة جميع الوثائق التي نعرفها.
إلى أسفل اليسار (1) في بنية استرجاع المعلومات القياسية (IR)، ستلاحظ عدم وجود طبقة BERT. يدخل الاستعلام المستخدم في الرسم التوضيحي (أحذية الجري Nike) إلى النظام، ويتم حساب الأوزان بشكل مستقل عن النموذج وتمريرها إليه.
في الرسم التوضيحي هنا، يتم تمرير الأوزان بالتساوي بين الكلمات الثلاث في الاستعلام. ومع ذلك، فإنه ليس من الضروري أن يكون بهذه الطريقة. إنه مجرد توضيح افتراضي وجيد.
المهم أن نفهم أنه يتم تعيين الأوزان من خارج النموذج وإدخالها مع الاستعلام. سنغطي سبب أهمية ذلك للحظات.
إذا نظرنا إلى إصدار مصطلح الوزن على الجانب الأيمن، سترى أن الاستعلام "أحذية الجري nike" يدخل BERT (مصطلح الوزن BERT، أو TW-BERT، على وجه التحديد) والذي يستخدم لتعيين الأوزان التي سيكون من الأفضل تطبيقه على هذا الاستعلام.
ومن هناك تتبع الأمور مسارًا مشابهًا لكليهما، ويتم تطبيق وظيفة التسجيل ويتم ترتيب المستندات. ولكن هناك خطوة نهائية رئيسية في النموذج الجديد، وهي في الحقيقة المغزى من كل ذلك، ألا وهو حساب خسارة التصنيف.
هذا الحساب، الذي أشرت إليه أعلاه، يجعل تحديد الأوزان داخل النموذج في غاية الأهمية. لفهم هذا بشكل أفضل، دعونا نأخذ جانبًا سريعًا لمناقشة وظائف الخسارة، وهو أمر مهم لفهم ما يحدث هنا حقًا.
ما هي وظيفة الخسارة؟
في التعلم الآلي، تعد دالة الخسارة في الأساس حسابًا لمدى خطأ النظام في محاولة النظام المذكور تعلم الاقتراب من الخسارة الصفرية قدر الإمكان.
لنأخذ على سبيل المثال نموذجًا مصممًا لتحديد أسعار المنازل. إذا قمت بإدخال جميع إحصائيات منزلك وتوصلت إلى قيمة 250 ألف دولار، ولكن منزلك تم بيعه بمبلغ 260 ألف دولار، فسيعتبر الفرق خسارة (وهي قيمة مطلقة).
من خلال عدد كبير من الأمثلة، يتم تدريس النموذج لتقليل الخسارة عن طريق تعيين أوزان مختلفة للمعلمات المعطاة له حتى يحصل على أفضل نتيجة. قد تتضمن المعلمة، في هذه الحالة، أشياء مثل الأقدام المربعة، وغرف النوم، وحجم الفناء، والقرب من المدرسة، وما إلى ذلك.
الآن، نعود إلى ترجيح مصطلح الاستعلام
إذا نظرنا إلى المثالين أعلاه، فإن ما نحتاج إلى التركيز عليه هو وجود نموذج BERT لتوفير الترجيح للمصطلحات السفلية لحساب خسارة التصنيف.
وبعبارة أخرى، في النماذج التقليدية، تم ترجيح المصطلحات بشكل مستقل عن النموذج نفسه، وبالتالي، لا يمكن الاستجابة لكيفية أداء النموذج العام. ولم يتمكن من تعلم كيفية تحسين الترجيح.

وفي النظام المقترح يتغير هذا. يتم إجراء الترجيح من داخل النموذج نفسه، وبالتالي، بينما يسعى النموذج إلى تحسين أدائه وتقليل وظيفة الخسارة، فإنه يحتوي على هذه الأقراص الإضافية لتحويل ترجيح المصطلح إلى المعادلة. حرفياً.
ngrams
لم يتم تصميم TW-BERT للعمل فيما يتعلق بالكلمات، بل بالأحرى ngrams.
يوضح مؤلفو البحث جيدًا سبب استخدامهم لـ ngrams بدلاً من الكلمات عندما يشيرون إلى أنه في الاستعلام "أحذية الجري Nike" إذا قمت ببساطة بوزن الكلمات، فإن الصفحة التي تحتوي على إشارات للكلمات Nike و Running و Shoes يمكن أن تحصل على تصنيف جيد حتى إذا كان الأمر يتعلق بـ "جوارب الجري Nike" و"أحذية التزلج".
تستخدم أساليب IR التقليدية إحصائيات الاستعلام وإحصائيات المستندات، وقد تظهر صفحات بها هذه المشكلة أو مشكلات مشابهة. ركزت المحاولات السابقة لمعالجة هذا الأمر على التواجد المشترك والنظام.
في هذا النموذج، يتم وزن ngrams بنفس وزن الكلمات في مثالنا السابق، لذلك ننتهي بشيء مثل:
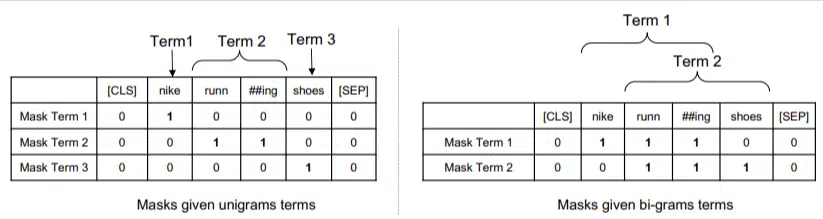
على اليسار نرى كيف سيتم ترجيح الاستعلام على أنه uni-grams (ngrams من كلمة واحدة) وعلى اليمين، bi-grams (ngrams من كلمتين).
يمكن للنظام، نظرًا لأن الترجيح مدمج فيه، أن يتدرب على جميع التباديل لتحديد أفضل ngrams وأيضًا الوزن المناسب لكل منها، بدلاً من الاعتماد فقط على الإحصائيات مثل التردد.
طلقة صفر
من السمات المهمة لهذا النموذج هو أدائه في المهام القصيرة الصفرية. اختبر المؤلفون على:
- مجموعة بيانات MS MARCO – مجموعة بيانات Microsoft لتصنيف المستندات والمقطع
- مجموعة بيانات TREC-COVID – مقالات ودراسات حول فيروس كورونا
- Robust04 – مقالات إخبارية
- Core Common – المقالات التعليمية ومنشورات المدونات
لم يكن لديهم سوى عدد قليل من استعلامات التقييم ولم يستخدموا أيًا منها للضبط الدقيق، مما يجعل هذا اختبارًا صفريًا حيث لم يتم تدريب النموذج على ترتيب المستندات في هذه المجالات على وجه التحديد. وكانت النتائج:
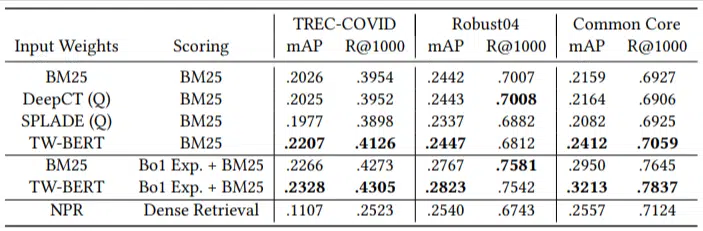
لقد تفوق في الأداء في معظم المهام وكان أداؤه أفضل في الاستعلامات الأقصر (من كلمة واحدة إلى 10 كلمات).
وهو التوصيل والتشغيل!
حسنًا، قد يكون هذا تبسيطًا مبالغًا فيه، لكن المؤلفين كتبوا:
"تؤدي مواءمة TW-BERT مع نتائج محركات البحث إلى تقليل التغييرات اللازمة لدمجها في تطبيقات الإنتاج الحالية ، في حين أن أساليب البحث القائمة على التعلم العميق الحالية تتطلب المزيد من تحسين البنية التحتية ومتطلبات الأجهزة. يمكن استخدام الأوزان التي تم تعلمها بسهولة بواسطة المستردات المعجمية القياسية وبواسطة تقنيات الاسترجاع الأخرى مثل توسيع الاستعلام.
ونظرًا لأن TW-BERT مصمم للاندماج في النظام الحالي، فإن التكامل أبسط بكثير وأرخص من الخيارات الأخرى.
ماذا يعني كل هذا بالنسبة لك
باستخدام نماذج التعلم الآلي، من الصعب التنبؤ بما يمكنك فعله بصفتك أحد كبار المسئولين الاقتصاديين (بصرف النظر عن عمليات النشر المرئية مثل Bard أو ChatGPT).
مما لا شك فيه أنه سيتم نشر تبديل لهذا النموذج بسبب تحسيناته وسهولة نشره (بافتراض دقة البيانات).
ومع ذلك، يعد هذا تحسينًا لجودة الحياة في Google، والذي سيؤدي إلى تحسين التصنيفات والنتائج الصفرية بتكلفة منخفضة.
كل ما يمكننا الاعتماد عليه حقًا هو أنه إذا تم تنفيذه، فسوف تظهر نتائج أفضل بشكل أكثر موثوقية. وهذه أخبار جيدة لمحترفي تحسين محركات البحث (SEO).
الآراء الواردة في هذه المقالة هي آراء المؤلف الضيف وليست بالضرورة Search Engine Land. يتم سرد المؤلفين الموظفين هنا.