
ما هو الذكاء الاصطناعي التوليدي وكيف يعمل؟
نشرت: 2023-09-26برز الذكاء الاصطناعي التوليدي، وهو مجموعة فرعية من الذكاء الاصطناعي، كقوة ثورية في عالم التكنولوجيا. ولكن ما هو بالضبط؟ ولماذا تحظى بهذا القدر من الاهتمام؟
سوف يتعمق هذا الدليل المتعمق في كيفية عمل نماذج الذكاء الاصطناعي التوليدية، وما يمكنها فعله وما لا يمكنها فعله، والآثار المترتبة على كل هذه العناصر.
ما هو الذكاء الاصطناعي التوليدي؟
يشير الذكاء الاصطناعي التوليدي، أو genAI، إلى الأنظمة التي يمكنها إنشاء محتوى جديد، سواء كان نصًا أو صورًا أو موسيقى أو حتى مقاطع فيديو. تقليديًا، يعني الذكاء الاصطناعي/التعلم الآلي ثلاثة أشياء: التعلم الخاضع للإشراف، وغير الخاضع للإشراف، والتعلم المعزز. كل منها يعطي رؤى تعتمد على تجميع المخرجات.
تقوم نماذج الذكاء الاصطناعي غير التوليدية بإجراء حسابات بناءً على المدخلات (مثل تصنيف صورة أو ترجمة جملة). في المقابل، تنتج النماذج التوليدية مخرجات "جديدة" مثل كتابة المقالات، وتأليف الموسيقى، وتصميم الرسومات، وحتى إنشاء وجوه بشرية واقعية لا وجود لها في العالم الحقيقي.
الآثار المترتبة على الذكاء الاصطناعي التوليدي
إن صعود الذكاء الاصطناعي التوليدي له آثار كبيرة. ومع القدرة على إنشاء المحتوى، تشهد صناعات مثل الترفيه والتصميم والصحافة تحولًا نموذجيًا.
على سبيل المثال، يمكن لوكالات الأنباء استخدام الذكاء الاصطناعي لصياغة التقارير، بينما يمكن للمصممين الحصول على اقتراحات للرسومات بمساعدة الذكاء الاصطناعي. يمكن للذكاء الاصطناعي إنشاء مئات من الشعارات الإعلانية في ثوانٍ – سواء كانت هذه الخيارات جيدة أم لا أم لا فهذه مسألة أخرى.
يمكن للذكاء الاصطناعي التوليدي إنتاج محتوى مخصص للمستخدمين الفرديين. فكر في شيء مثل تطبيق موسيقى يؤلف أغنية فريدة بناءً على حالتك المزاجية أو تطبيق أخبار يقوم بصياغة مقالات حول الموضوعات التي تهمك.
تكمن المشكلة في أنه نظرًا لأن الذكاء الاصطناعي يلعب دورًا أكثر تكاملاً في إنشاء المحتوى، فإن الأسئلة حول الأصالة وحقوق الطبع والنشر وقيمة الإبداع البشري أصبحت أكثر انتشارًا.
كيف يعمل الذكاء الاصطناعي التوليدي؟
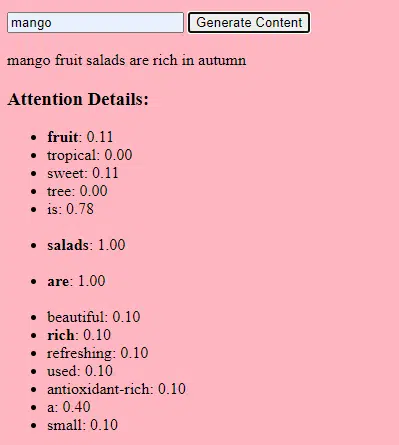
يدور الذكاء الاصطناعي التوليدي، في جوهره، حول التنبؤ بالجزء التالي من البيانات في تسلسل، سواء كانت هذه الكلمة التالية في الجملة أو البكسل التالي في الصورة. دعونا نحلل كيف يتم تحقيق ذلك.
النماذج الإحصائية
النماذج الإحصائية هي العمود الفقري لمعظم أنظمة الذكاء الاصطناعي. ويستخدمون المعادلات الرياضية لتمثيل العلاقة بين المتغيرات المختلفة.
بالنسبة للذكاء الاصطناعي التوليدي، يتم تدريب النماذج على التعرف على الأنماط في البيانات ثم استخدام هذه الأنماط للتوليد بيانات جديدة مماثلة.
إذا تم تدريب النموذج على الجمل الإنجليزية، فإنه يتعلم الاحتمالية الإحصائية لكلمة واحدة تتبع أخرى، مما يسمح له بإنشاء جمل متماسكة.
جمع البيانات
تعد جودة وكمية البيانات أمرًا بالغ الأهمية. يتم تدريب النماذج التوليدية على مجموعات بيانات واسعة لفهم الأنماط.
بالنسبة لنموذج اللغة، قد يعني هذا استيعاب مليارات الكلمات من الكتب والمواقع الإلكترونية والنصوص الأخرى.
بالنسبة لنموذج الصورة، قد يعني ذلك تحليل ملايين الصور. كلما كانت بيانات التدريب أكثر تنوعًا وشمولًا، كلما كان النموذج قادرًا على توليد مخرجات متنوعة بشكل أفضل.
كيف تعمل المحولات والانتباه
المحولات هي نوع من بنية الشبكات العصبية التي تم تقديمها في ورقة بحثية عام 2017 بعنوان "الانتباه هو كل ما تحتاجه" بقلم فاسواني وآخرين. لقد أصبحت منذ ذلك الحين الأساس لمعظم نماذج اللغات الحديثة. لن يعمل ChatGPT بدون المحولات.
تسمح آلية "الانتباه" للنموذج بالتركيز على أجزاء مختلفة من البيانات المدخلة، تمامًا مثل كيفية اهتمام البشر بكلمات معينة عند فهم جملة ما.
تتيح هذه الآلية للنموذج تحديد أجزاء المدخلات ذات الصلة بمهمة معينة، مما يجعلها مرنة وقوية للغاية.
الكود أدناه هو تفصيل أساسي لآليات المحولات، موضحًا كل قطعة باللغة الإنجليزية البسيطة.
class Transformer: # Convert words to vectors # What this is : turns words into "vector embeddings" –basically numbers that represent the words and their relationships to each other. # Demo : "the pineapple is cool and tasty" -> [0.2, 0.5, 0.3, 0.8, 0.1, 0.9] self.embedding = Embedding(vocab_size, d_model) # Add position information to the vectors # What this is : Since words in a sentence have a specific order, we add information about each word's position in the sentence. # Demo : "the pineapple is cool and tasty" with position -> [0.2+0.01, 0.5+0.02, 0.3+0.03, 0.8+0.04, 0.1+0.05, 0.9+0.06] self.positional_encoding = PositionalEncoding(d_model) # Stack of transformer layers # What this is : Multiple layers of the Transformer model stacked on top of each other to process data in depth. # Why it does it : Each layer captures different patterns and relationships in the data. # Explained like I'm five : Imagine a multi-story building. Each floor (or layer) has people (or mechanisms) doing specific jobs. The more floors, the more jobs get done! self.transformer_layers = [TransformerLayer(d_model, nhead) for _ in range(num_layers)] # Convert the output vectors to word probabilities # What this is : A way to predict the next word in a sequence. # Why it does it : After processing the input, we want to guess what word comes next. # Explained like I'm five : After listening to a story, this tries to guess what happens next. self.output_layer = Linear(d_model, vocab_size) def forward(self, x): # Convert words to vectors, as above x = self.embedding(x) # Add position information, as above x = self.positional_encoding(x) # Pass through each transformer layer # What this is : Sending our data through each floor of our multi-story building. # Why it does it : To deeply process and understand the data. # Explained like I'm five : It's like passing a note in class. Each person (or layer) adds something to the note before passing it on, which can end up with a coherent story – or a mess. for layer in self.transformer_layers: x = layer(x) # Get the output word probabilities # What this is : Our best guess for the next word in the sequence. return self.output_layer(x)في التعليمات البرمجية، قد يكون لديك فئة Transformer وفئة TransformerLayer واحدة. وهذا يشبه وجود مخطط لطابق مقابل مبنى بأكمله.
يوضح لك جزء التعليمات البرمجية الخاص بـ TransformerLayer كيفية عمل مكونات محددة، مثل الاهتمام متعدد الرؤوس والترتيبات المحددة.
class TransformerLayer: # Multi-head attention mechanism # What this is : A mechanism that lets the model focus on different parts of the input data simultaneously. # Demo : "the pineapple is cool and tasty" might become "this PINEAPPLE is COOL and TASTY" as the model pays more attention to certain words. self.attention = MultiHeadAttention(d_model, nhead) # Simple feed-forward neural network # What this is : A basic neural network that processes the data after the attention mechanism. # Demo : "this PINEAPPLE is COOL and TASTY" -> [0.25, 0.55, 0.35, 0.85, 0.15, 0.95] (slight changes in numbers after processing) self.feed_forward = FeedForward(d_model) def forward(self, x): # Apply attention mechanism # What this is : The step where we focus on different parts of the sentence. # Explained like I'm five : It's like highlighting important parts of a book. attention_output = self.attention(x, x, x) # Pass the output through the feed-forward network # What this is : The step where we process the highlighted information. return self.feed_forward(attention_output)تعد الشبكة العصبية ذات التغذية الأمامية واحدة من أبسط أنواع الشبكات العصبية الاصطناعية. وتتكون من طبقة الإدخال، وطبقة مخفية واحدة أو أكثر، وطبقة الإخراج.
تتدفق البيانات في اتجاه واحد – من طبقة الإدخال، عبر الطبقات المخفية، إلى طبقة الإخراج. لا توجد حلقات أو دورات في الشبكة.
في سياق بنية المحولات، يتم استخدام الشبكة العصبية ذات التغذية الأمامية بعد آلية الانتباه في كل طبقة. إنه تحويل خطي بسيط من طبقتين مع تنشيط ReLU بينهما.
# Scaled dot-product attention mechanism class ScaledDotProductAttention: def __init__(self, d_model): # Scaling factor helps in stabilizing the gradients # it reduces the variance of the dot product. # What this is: A scaling factor based on the size of our model's embeddings. # What it does : Helps to make sure the dot products don't get too big. # Why it does it : Big dot products can make a model unstable and harder to train. # How it does it : By dividing the dot products by the square root of the embedding size. # It's used when calculating attention scores. # Explained like I'm five : Imagine you shouted something really loud. This scaling factor is like turning the volume down so it's not too loud. self.scaling_factor = d_model ** 0.5 def forward(self, query, key, value): # What this is : The function that calculates how much attention each word should get. # What it does : Determines how relevant each word in a sentence is to every other word. # Why it does it : So we can focus more on important words when trying to understand a sentence. # How it does it : By taking the dot product (the numeric product: a way to measure similarity) of the query and key, then scaling it, and finally using that to weigh our values. # How it fits into the rest of the code : This function is called whenever we want to calculate attention in our model. # Explained like I'm five : Imagine you have a toy and you want to see which of your friends likes it the most. This function is like asking each friend how much they like the toy, and then deciding who gets to play with it based on their answers. # Calculate attention scores by taking the dot product of the query and key. scores = dot_product(query, key) / self.scaling_factor # Convert the raw scores to probabilities using the softmax function. attention_weights = softmax(scores) # Weight the values using the attention probabilities. return dot_product(attention_weights, value) # Feed-forward neural network # This is an extremely basic example of a neural network. class FeedForward: def __init__(self, d_model): # First linear layer increases the dimensionality of the data. self.layer1 = Linear(d_model, d_model * 4) # Second linear layer brings the dimensionality back to d_model. self.layer2 = Linear(d_model * 4, d_model) def forward(self, x): # Pass the input through the first layer, #Pass the input through the first layer: # Input : This refers to the data you feed into the neural network. I # First layer : Neural networks consist of layers, and each layer has neurons. When we say "pass the input through the first layer," we mean that the input data is being processed by the neurons in this layer. Each neuron takes the input, multiplies it by its weights (which are learned during training), and produces an output. # apply ReLU activation to introduce non-linearity, # and then pass through the second layer. #ReLU activation: ReLU stands for Rectified Linear Unit. # It's a type of activation function, which is a mathematical function applied to the output of each neuron. In simpler terms, if the input is positive, it returns the input value; if the input is negative or zero, it returns zero. # Neural networks can model complex relationships in data by introducing non-linearities. # Without non-linear activation functions, no matter how many layers you stack in a neural network, it would behave just like a single-layer perceptron because summing these layers would give you another linear model. # Non-linearities allow the network to capture complex patterns and make better predictions. return self.layer2(relu(self.layer1(x))) # Positional encoding adds information about the position of each word in the sequence. class PositionalEncoding: def __init__(self, d_model): # What this is : A setup to add information about where each word is in a sentence. # What it does : Prepares to add a unique "position" value to each word. # Why it does it : Words in a sentence have an order, and this helps the model remember that order. # How it does it : By creating a special pattern of numbers for each position in a sentence. # How it fits into the rest of the code : Before processing words, we add their position info. # Explained like I'm five : Imagine you're in a line with your friends. This gives everyone a number to remember their place in line. pass def forward(self, x): # What this is : The main function that adds position info to our words. # What it does : Combines the word's original value with its position value. # Why it does it : So the model knows the order of words in a sentence. # How it does it : By adding the position values we prepared earlier to the word values. # How it fits into the rest of the code : This function is called whenever we want to add position info to our words. # Explained like I'm five : It's like giving each of your toys a tag that says if it's the 1st, 2nd, 3rd toy, and so on. return x # Helper functions def dot_product(a, b): # Calculate the dot product of two matrices. # What this is : A mathematical operation to see how similar two lists of numbers are. # What it does : Multiplies matching items in the lists and then adds them up. # Why it does it : To measure similarity or relevance between two sets of data. # How it does it : By multiplying and summing up. # How it fits into the rest of the code : Used in attention to see how relevant words are to each other. # Explained like I'm five : Imagine you and your friend have bags of candies. You both pour them out and match each candy type. Then, you count how many matching pairs you have. return a @ b.transpose(-2, -1) def softmax(x): # Convert raw scores to probabilities ensuring they sum up to 1. # What this is : A way to turn any list of numbers into probabilities. # What it does : Makes the numbers between 0 and 1 and ensures they all add up to 1. # Why it does it : So we can understand the numbers as chances or probabilities. # How it does it : By using exponentiation and division. # How it fits into the rest of the code : Used to convert attention scores into probabilities. # Explained like I'm five : Lets go back to our toys. This makes sure that when you share them, everyone gets a fair share, and no toy is left behind. return exp(x) / sum(exp(x), axis=-1) def relu(x): # Activation function that introduces non-linearity. It sets negative values to 0. # What this is : A simple rule for numbers. # What it does : If a number is negative, it changes it to zero. Otherwise, it leaves it as it is. # Why it does it : To introduce some simplicity and non-linearity in our model's calculations. # How it does it : By checking each number and setting it to zero if it's negative. # How it fits into the rest of the code : Used in neural networks to make them more powerful and flexible. # Explained like I'm five : Imagine you have some stickers, some are shiny (positive numbers) and some are dull (negative numbers). This rule says to replace all dull stickers with blank ones. return max(0, x)كيف يعمل الذكاء الاصطناعي التوليدي – بعبارات بسيطة
فكر في الذكاء الاصطناعي التوليدي باعتباره رمي نرد مرجح. تحدد بيانات التدريب الأوزان (أو الاحتمالات).
إذا كان النرد يمثل الكلمة التالية في جملة، فإن الكلمة التي غالبًا ما تتبع الكلمة الحالية في بيانات التدريب سيكون لها وزن أكبر. لذلك، قد تأتي كلمة "السماء" بعد كلمة "الأزرق" في كثير من الأحيان أكثر من كلمة "الموزة". عندما يقوم الذكاء الاصطناعي "برمي النرد" لإنشاء المحتوى، فمن المرجح أن يختار تسلسلات أكثر احتمالاً إحصائيًا بناءً على تدريبه.
إذًا، كيف يمكن لحاملي شهادة LLM إنشاء محتوى "يبدو" أصليًا؟
دعونا نلقي نظرة على قائمة مزيفة - "أفضل هدايا عيد الفطر لمسوقي المحتوى" - ونتعرف على كيفية إنشاء ماجستير إدارة الأعمال (LLM) هذه القائمة من خلال الجمع بين الإشارات النصية من المستندات المتعلقة بالهدايا والعيد ومسوقي المحتوى.
قبل المعالجة، يتم تقسيم النص إلى أجزاء أصغر تسمى "الرموز المميزة". يمكن أن تكون هذه الرموز قصيرة مثل حرف واحد أو طويلة مثل كلمة واحدة.
مثال: "عيد الفطر احتفال" يصبح ["عيد"، "الفطر"، "هو"، "أ"، "احتفال"].
يتيح ذلك للنموذج العمل مع أجزاء من النص يمكن التحكم فيها وفهم بنية الجمل.
يتم بعد ذلك تحويل كل رمز مميز إلى متجه (قائمة أرقام) باستخدام التضمينات. تلتقط هذه المتجهات معنى وسياق كل كلمة.
يضيف التشفير الموضعي معلومات إلى كل متجه كلمة حول موضعه في الجملة، مما يضمن عدم فقدان النموذج لمعلومات الترتيب هذه.
ثم نستخدم آلية الانتباه : وهذا يسمح للنموذج بالتركيز على أجزاء مختلفة من نص الإدخال عند إنشاء مخرجات. إذا كنت تتذكر بيرت، فهذا هو ما كان مثيرًا جدًا لموظفي Google بشأن بيرت.
إذا كان نموذجنا قد رأى نصوصًا عن " الهدايا " ويعرف أن الناس يقدمون الهدايا أثناء الاحتفالات ، وشاهد أيضًا نصوصًا عن كون " عيد الفطر " احتفالًا مهمًا، فسوف " ينتبه " إلى هذه الارتباطات.
وبالمثل، إذا شاهدت نصوصًا حول احتياج " مسوقي المحتوى " إلى أدوات أو موارد محددة، فيمكنها ربط فكرة " الهدايا " بـ " مسوقي المحتوى".

يمكننا الآن دمج السياقات: بينما يقوم النموذج بمعالجة نص الإدخال من خلال طبقات محولات متعددة، فإنه يجمع السياقات التي تعلمها.
لذلك، حتى لو لم تذكر النصوص الأصلية مطلقًا "هدايا عيد الفطر لمسوقي المحتوى"، فإن النموذج يمكن أن يجمع مفاهيم "عيد الفطر" و"الهدايا" و"مسوقي المحتوى" معًا لتوليد هذا المحتوى.
وذلك لأنها تعلمت السياقات الأوسع حول كل مصطلح من هذه المصطلحات.
بعد معالجة المدخلات من خلال آلية الانتباه وشبكات التغذية الأمامية في كل طبقة محولات، ينتج النموذج توزيعًا احتماليًا على مفرداته للكلمة التالية في التسلسل.
قد يعتقد أنه بعد كلمات مثل "أفضل" و"عيد الفطر"، فإن كلمة "الهدايا" لديها احتمال كبير أن تأتي بعد ذلك. وبالمثل، قد تربط "الهدايا" بالمستلمين المحتملين مثل "مسوقي المحتوى".
احصل على النشرة الإخبارية اليومية التي يعتمد عليها مسوقو البحث.
انظر الشروط.
كيف يتم بناء نماذج اللغة الكبيرة
تتضمن الرحلة من نموذج المحولات الأساسي إلى نموذج اللغة الكبير المتطور (LLM) مثل GPT-3 أو BERT توسيع نطاق المكونات المختلفة وتحسينها.
وفيما يلي تفصيل خطوة بخطوة:
يتم تدريب LLMs على كميات هائلة من البيانات النصية. من الصعب شرح مدى ضخامة هذه البيانات.
مجموعة بيانات C4، وهي نقطة البداية للعديد من حاملي شهادات LLM، هي 750 جيجابايت من البيانات النصية. هذا يعني 805,306,368,000 بايت – الكثير من المعلومات. يمكن أن تشمل هذه البيانات الكتب والمقالات ومواقع الويب والمنتديات وأقسام التعليقات والمصادر الأخرى.
كلما كانت البيانات أكثر تنوعًا وشمولًا، كانت قدرة النموذج على الفهم والتعميم أفضل.
في حين أن بنية المحولات الأساسية تظل هي الأساس، إلا أن LLMs لديها عدد أكبر بكثير من المعلمات. على سبيل المثال، يحتوي GPT-3 على 175 مليار معلمة. في هذه الحالة، تشير المعلمات إلى الأوزان والتحيزات في الشبكة العصبية التي يتم تعلمها أثناء عملية التدريب.
في التعلم العميق، يتم تدريب النموذج على عمل تنبؤات عن طريق ضبط هذه المعلمات لتقليل الفرق بين تنبؤاته والنتائج الفعلية.
تسمى عملية ضبط هذه المعلمات بالتحسين، والتي تستخدم خوارزميات مثل نزول التدرج.
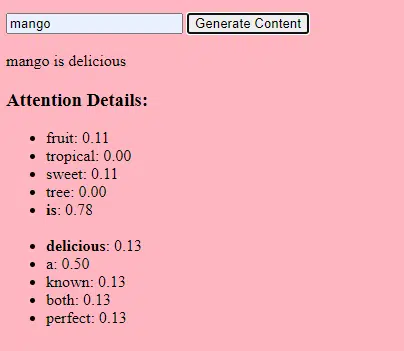
- الأوزان: هذه هي القيم الموجودة في الشبكة العصبية والتي تعمل على تحويل بيانات الإدخال داخل طبقات الشبكة. ويتم تعديلها أثناء التدريب لتحسين مخرجات النموذج. كل اتصال بين الخلايا العصبية في الطبقات المجاورة له وزن مرتبط.
- التحيزات: هذه أيضًا قيم في الشبكة العصبية تضاف إلى مخرجات تحويل الطبقة. إنها توفر درجة إضافية من الحرية للنموذج، مما يسمح له بملاءمة بيانات التدريب بشكل أفضل. كل خلية عصبية في الطبقة لها انحياز مرتبط بها.
يسمح هذا القياس للنموذج بتخزين ومعالجة الأنماط والعلاقات الأكثر تعقيدًا في البيانات.
ويعني العدد الكبير من المعلمات أيضًا أن النموذج يتطلب قوة حسابية وذاكرة كبيرة للتدريب والاستدلال. وهذا هو السبب في أن تدريب مثل هذه النماذج يستهلك الكثير من الموارد ويستخدم عادةً أجهزة متخصصة مثل وحدات معالجة الرسومات أو وحدات معالجة الرسومات.
يتم تدريب النموذج على التنبؤ بالكلمة التالية في تسلسل باستخدام موارد حسابية قوية. يقوم بضبط معلماته الداخلية بناءً على الأخطاء التي يرتكبها، مما يؤدي إلى تحسين تنبؤاته بشكل مستمر.

تعتبر آليات الاهتمام مثل تلك التي ناقشناها أمرًا محوريًا بالنسبة إلى LLMs. إنها تسمح للنموذج بالتركيز على أجزاء مختلفة من المدخلات عند توليد المخرجات.
من خلال وزن أهمية الكلمات المختلفة في السياق، تمكن آليات الانتباه النموذج من إنشاء نص متماسك وذو صلة بالسياق. إن القيام بذلك على هذا النطاق الهائل يمكّن طلاب LLM من العمل بالطريقة التي يعملون بها.
كيف يتنبأ المحول بالنص؟
تتنبأ المحولات بالنص عن طريق معالجة رموز الإدخال من خلال طبقات متعددة، كل منها مجهز بآليات الانتباه وشبكات التغذية الأمامية.
بعد المعالجة، ينتج النموذج توزيعًا احتماليًا على مفرداته للكلمة التالية في التسلسل. عادةً ما يتم تحديد الكلمة ذات الاحتمالية الأعلى كتنبؤ.
كيف يتم بناء نموذج لغة كبير وتدريبه؟
يتضمن بناء LLM جمع البيانات، وتنظيفها، وتدريب النموذج، وضبط النموذج، والاختبار القوي والمستمر.
يتم تدريب النموذج في البداية على مجموعة كبيرة للتنبؤ بالكلمة التالية في التسلسل. تسمح هذه المرحلة للنموذج بتعلم الروابط بين الكلمات التي تلتقط الأنماط في القواعد، والعلاقات التي يمكن أن تمثل حقائق حول العالم، والروابط التي تبدو وكأنها تفكير منطقي. هذه الروابط أيضًا تجعلها تلتقط التحيزات الموجودة في بيانات التدريب.
بعد التدريب المسبق، يتم تنقيح النموذج على مجموعة بيانات أضيق، وغالبًا ما يتبع المراجعون البشريون الإرشادات.
يعد الضبط الدقيق خطوة حاسمة في بناء LLMs. يتضمن تدريب النموذج المُدرب مسبقًا على مجموعة بيانات أو مهمة أكثر تحديدًا. لنأخذ ChatGPT كمثال.
إذا كنت قد لعبت مع نماذج GPT، فأنت تعلم أن المطالبة أقل من "اكتب هذا الشيء" وأكثر شبهًا
- عاجل: ذات مرة
- تتمة: كان هناك ساحر شرير في أعلى البرج.
- تتمة: كان هناك ساحر شرير في أعلى البرج.
- المستعجل : لماذا انضمت الدجاجة إلى الفرقة؟
- استمرار : لأنه كان لديه أفخاذ!
يتطلب الوصول إلى ChatGPT من تلك النقطة الكثير من العمالة منخفضة الأجر. يقوم هؤلاء الأشخاص بإنشاء مجموعات ضخمة لوضع إصبعهم على وزن استجابات GPT والسلوكيات المتوقعة. يقوم هؤلاء العمال بإنشاء الكثير من النصوص السريعة/المستمرة التي تشبه:
- عاجل : أكمل هذه القصة: "كان يا ما كان.."
- استمرار : بالتأكيد! ذات مرة، في أرض بعيدة جدًا، كانت هناك قرية صغيرة تقع بين جبلين مهيبين.
- استمرار : بالتأكيد! ذات مرة، في أرض بعيدة جدًا، كانت هناك قرية صغيرة تقع بين جبلين مهيبين.
- مستعجل : أخبرني نكتة عن الدجاجة.
- متابعة : لماذا انضمت الدجاجة إلى الفرقة؟ لأنه كان لديه أفخاذ!
تعد عملية الضبط الدقيق هذه ضرورية لعدة أسباب:
- الخصوصية: في حين أن التدريب المسبق يمنح النموذج فهمًا واسعًا للغة، فإن الضبط الدقيق يضيق معرفته وسلوكه للتوافق بشكل أكبر مع مهام أو مجالات محددة. على سبيل المثال، النموذج المضبوط بدقة على البيانات الطبية سوف يجيب بشكل أفضل على الأسئلة الطبية.
- التحكم: يمنح الضبط الدقيق للمطورين مزيدًا من التحكم في مخرجات النموذج. يمكن للمطورين استخدام مجموعة بيانات منسقة لتوجيه النموذج لإنتاج الاستجابات المطلوبة وتجنب السلوكيات غير المرغوب فيها.
- السلامة: يساعد في تقليل المخرجات الضارة أو المتحيزة. ومن خلال استخدام الإرشادات أثناء عملية الضبط الدقيق، يمكن للمراجعين البشريين التأكد من أن النموذج لا ينتج محتوى غير مناسب.
- الأداء: يمكن أن يؤدي الضبط الدقيق إلى تحسين أداء النموذج بشكل كبير في مهام محددة. على سبيل المثال، النموذج الذي تم ضبطه لدعم العملاء سيكون أفضل بكثير من النموذج العام.
يمكنك معرفة أن ChatGPT قد تم ضبطه بشكل خاص في بعض النواحي.
على سبيل المثال، "الاستدلال المنطقي" هو شيء يميل طلاب ماجستير إدارة الأعمال إلى النضال معه. لقد تم تدريب أفضل نموذج للاستدلال المنطقي في ChatGPT – GPT-4 – بشكل مكثف للتعرف على الأنماط في الأرقام بشكل واضح.
بدلا من شيء مثل هذا:
- مستعجل : ما هو 2+2؟
- العملية : في كثير من الأحيان في كتب الرياضيات للأطفال 2 + 2 = 4. في بعض الأحيان توجد إشارات إلى "2+2=5" ولكن عادةً ما يكون هناك سياق أكثر للقيام به مع جورج أورويل أو ستار تريك عندما يكون هذا هو الحال. لو كان هذا في هذا السياق لكان الترجيح أكثر لصالح 2+2=5. لكن هذا السياق غير موجود، لذا في هذه الحالة، من المحتمل أن يكون الرمز المميز التالي هو 4.
- الرد : 2+2=4
التدريب يفعل شيئا مثل هذا:
- التدريب: 2+2=4
- التدريب: 4/2=2
- التدريب: نصف 4 هو 2
- التدريب: 2 من 2 هو أربعة
…وما إلى ذلك وهلم جرا.
وهذا يعني أنه بالنسبة لتلك النماذج الأكثر "منطقية"، تكون عملية التدريب أكثر صرامة وتركز على ضمان فهم النموذج للمبادئ المنطقية والرياضية وتطبيقها بشكل صحيح.
يتعرض النموذج لمختلف المشاكل الرياضية وحلولها، مما يضمن قدرته على تعميم وتطبيق هذه المبادئ على مشاكل جديدة غير مرئية.
لا يمكن المبالغة في أهمية عملية الضبط هذه، خاصة بالنسبة للتفكير المنطقي. وبدون ذلك، قد يقدم النموذج إجابات غير صحيحة أو لا معنى لها على الأسئلة المنطقية أو الرياضية المباشرة.
نماذج الصور مقابل نماذج اللغة
في حين أن كلا من نماذج الصور واللغة قد تستخدم بنيات مماثلة مثل المحولات، فإن البيانات التي تعالجها مختلفة بشكل أساسي:
نماذج الصور
تتعامل هذه النماذج مع وحدات البكسل وغالبًا ما تعمل بطريقة هرمية، حيث تحلل الأنماط الصغيرة (مثل الحواف) أولاً، ثم تجمعها للتعرف على الهياكل الأكبر (مثل الأشكال)، وهكذا حتى تفهم الصورة بأكملها.
نماذج اللغة
تقوم هذه النماذج بمعالجة تسلسل الكلمات أو الأحرف. إنهم بحاجة إلى فهم السياق والقواعد والدلالات لإنشاء نص متماسك وذو صلة بالسياق.
كيف تعمل واجهات الذكاء الاصطناعي التوليدية البارزة
Dall-E + رحلة منتصف الليل
يعد Dall-E أحد أشكال نموذج GPT-3 المكيف لتوليد الصور. لقد تم تدريبه على مجموعة بيانات واسعة من أزواج الصور النصية. Midjourney هو برنامج آخر لتوليد الصور يعتمد على نموذج خاص.
- الإدخال: يمكنك تقديم وصف نصي، مثل "طائر النحام ذي الرأسين".
- المعالجة: تقوم هذه النماذج بتشفير هذا النص إلى سلسلة من الأرقام ثم فك تشفير هذه المتجهات، وإيجاد العلاقات مع وحدات البكسل، لإنتاج صورة. لقد تعلم النموذج العلاقات بين الأوصاف النصية والتمثيلات المرئية من بيانات التدريب الخاصة به.
- الإخراج: صورة تتطابق مع الوصف المحدد أو تتعلق به.
الأصابع والأنماط والمشاكل
لماذا لا تتمكن هذه الأدوات من توليد أيدي تبدو طبيعية باستمرار؟ تعمل هذه الأدوات من خلال النظر إلى وحدات البكسل المجاورة لبعضها البعض.
يمكنك أن ترى كيف يعمل هذا عند مقارنة الصور التي تم إنشاؤها سابقًا أو أكثر بدائية مع الصور الأحدث: تبدو النماذج السابقة غامضة للغاية. وفي المقابل، فإن النماذج الأحدث أكثر هشاشة بكثير.
تقوم هذه النماذج بإنشاء صور من خلال التنبؤ بالبكسل التالي بناءً على وحدات البكسل التي أنشأتها بالفعل. يتم تكرار هذه العملية ملايين المرات للحصول على صورة كاملة.
الأيدي، وخاصة الأصابع، معقدة وتحتوي على الكثير من التفاصيل التي يجب التقاطها بدقة.
يمكن أن يختلف موضع كل إصبع وطوله واتجاهه بشكل كبير في الصور المختلفة.
عند إنشاء صورة من وصف نصي، يجب على النموذج أن يضع العديد من الافتراضات حول الوضع الدقيق وبنية اليد، مما قد يؤدي إلى حدوث حالات شاذة.
ChatGPT
يعتمد ChatGPT على بنية GPT-3.5، وهو نموذج قائم على المحولات مصمم لمهام معالجة اللغة الطبيعية.
- الإدخال: مطالبة أو سلسلة من الرسائل لمحاكاة محادثة.
- المعالجة: يستخدم ChatGPT معرفته الواسعة من نصوص الإنترنت المتنوعة لتوليد الردود. يأخذ في الاعتبار السياق المقدم في المحادثة ويحاول تقديم الرد الأكثر صلة وتماسكًا.
- الإخراج: رد نصي يستمر في المحادثة أو يجيب عليها.
تخصص
تكمن قوة ChatGPT في قدرته على التعامل مع مواضيع مختلفة ومحاكاة المحادثات الشبيهة بالإنسان، مما يجعله مثاليًا لروبوتات الدردشة والمساعدين الافتراضيين.
بارد + تجربة البحث التوليدية (SGE)
على الرغم من أن بعض التفاصيل المحددة قد تكون مملوكة، إلا أن Bard يعتمد على تقنيات الذكاء الاصطناعي للمحولات، على غرار نماذج اللغات الحديثة الأخرى. يعتمد SGE على نماذج مماثلة ولكنه ينسج في خوارزميات ML الأخرى التي تستخدمها Google.
من المحتمل أن تقوم SGE بإنشاء محتوى باستخدام نموذج توليدي قائم على المحولات ثم تقوم باستخراج الإجابات بشكل غامض من صفحات التصنيف في البحث. (قد لا يكون هذا صحيحًا. مجرد تخمين يعتمد على كيفية عمل اللعبة من خلال اللعب بها. من فضلك لا تقاضيني!)
- الإدخال: موجه/أمر/بحث
- المعالجة: يقوم Bard بمعالجة المدخلات ويعمل بالطريقة التي يعمل بها LLMs الآخرون. تستخدم SGE بنية مشابهة ولكنها تضيف طبقة تبحث فيها عن معرفتها الداخلية (المكتسبة من بيانات التدريب) لتوليد استجابة مناسبة. فهو يأخذ في الاعتبار بنية الموجه وسياقه والقصد من إنتاج محتوى ذي صلة.
- الإخراج: المحتوى المُنشأ الذي يمكن أن يكون قصة أو إجابة أو أي نوع آخر من النصوص.
تطبيقات الذكاء الاصطناعي التوليدي (وخلافاتها)
فن و تصميم
يمكن الآن للذكاء الاصطناعي التوليدي إنشاء أعمال فنية وموسيقى وحتى تصميمات المنتجات. وقد فتح هذا آفاقا جديدة للإبداع والابتكار.
الجدل
أثار صعود الذكاء الاصطناعي في الفن جدلاً حول فقدان الوظائف في المجالات الإبداعية.
بالإضافة إلى ذلك، هناك مخاوف بشأن:
- انتهاكات العمل، خاصة عند استخدام المحتوى الناتج عن الذكاء الاصطناعي دون الإسناد أو التعويض المناسب.
- ويعد تهديد المديرين التنفيذيين للكتاب باستبدالهم بالذكاء الاصطناعي إحدى القضايا التي أدت إلى إضراب الكتاب.
معالجة اللغة الطبيعية (NLP)
تُستخدم نماذج الذكاء الاصطناعي الآن على نطاق واسع في برامج الدردشة الآلية وترجمة اللغات ومهام البرمجة اللغوية العصبية الأخرى.
بعيدًا عن حلم الذكاء العام الاصطناعي (AGI)، يعد هذا أفضل استخدام لمادة LLM نظرًا لأنها قريبة من نموذج البرمجة اللغوية العصبية "العامة".
الجدل
يجد العديد من المستخدمين أن برامج الدردشة الآلية غير شخصية ومزعجة في بعض الأحيان.
علاوة على ذلك، في حين حقق الذكاء الاصطناعي خطوات كبيرة في ترجمة اللغات، فإنه غالبا ما يفتقر إلى الفروق الدقيقة والفهم الثقافي الذي يجلبه المترجمون البشريون، مما يؤدي إلى ترجمات مثيرة للإعجاب ومعيبة.
اكتشاف الطب والعقاقير
يستطيع الذكاء الاصطناعي تحليل كميات هائلة من البيانات الطبية بسرعة وتوليد مركبات دوائية محتملة، مما يؤدي إلى تسريع عملية اكتشاف الأدوية. يستخدم العديد من الأطباء بالفعل LLMs لكتابة الملاحظات واتصالات المرضى
الجدل
الاعتماد على LLMs للأغراض الطبية يمكن أن يكون مشكلة. يتطلب الطب الدقة، وأي أخطاء أو سهو من جانب الذكاء الاصطناعي يمكن أن يكون له عواقب وخيمة.
الطب أيضًا لديه بالفعل تحيزات لا تؤدي إلا إلى المزيد من النضج في استخدام LLMs. هناك أيضًا مشكلات مماثلة، كما هو موضح أدناه، فيما يتعلق بالخصوصية والفعالية والأخلاق.
الألعاب
العديد من المتحمسين للذكاء الاصطناعي متحمسون لاستخدام الذكاء الاصطناعي في الألعاب: يقولون إن الذكاء الاصطناعي يمكنه إنشاء بيئات ألعاب واقعية وشخصيات وحتى حبكات لعبة كاملة، مما يعزز تجربة الألعاب. يمكن تعزيز حوار الشخصيات غير القابلة للعب من خلال استخدام هذه الأدوات.
الجدل
هناك جدل حول القصد في تصميم اللعبة.
في حين أن الذكاء الاصطناعي يمكنه توليد كميات هائلة من المحتوى، يرى البعض أنه يفتقر إلى التصميم المتعمد والتماسك السردي الذي يجلبه المصممون البشريون.
كان لدى Watchdogs 2 شخصيات غير قابلة للعب (NPCs) برمجية، والتي لم تفعل الكثير لتضيف إلى التماسك السردي للعبة ككل.
التسويق والإعلان
يمكن للذكاء الاصطناعي تحليل سلوك المستهلك وإنشاء إعلانات مخصصة ومحتوى ترويجي، مما يجعل الحملات التسويقية أكثر فعالية.
تمتلك LLM سياقًا من كتابات الآخرين، مما يجعلها مفيدة لإنشاء قصص المستخدم أو أفكار برمجية أكثر دقة. بدلاً من التوصية بأجهزة تلفزيون لشخص اشترى جهاز تلفزيون للتو، يمكن لـ LLMs التوصية بالملحقات التي قد يرغب فيها شخص ما بدلاً من ذلك.
الجدل
The use of AI in marketing raises privacy concerns. There's also a debate about the ethical implications of using AI to influence consumer behavior.
Dig deeper: How to scale the use of large language models in marketing
Continuing issues with LLMS
Contextual understanding and comprehension of human speech
- Limitation: AI models, including GPT, often struggle with nuanced human interactions, such as detecting sarcasm, humor, or lies.
- Example: In stories where a character is lying to other characters, the AI might not always grasp the underlying deceit and might interpret statements at face value.
Pattern matching
- Limitation: AI models, especially those like GPT, are fundamentally pattern matchers. They excel at recognizing and generating content based on patterns they've seen in their training data. However, their performance can degrade when faced with novel situations or deviations from established patterns.
- Example: If a new slang term or cultural reference emerges after the model's last training update, it might not recognize or understand it.
Lack of common sense understanding
- Limitation: While AI models can store vast amounts of information, they often lack a "common sense" understanding of the world, leading to outputs that might be technically correct but contextually nonsensical.
Potential to reinforce biases
- Ethical consideration: AI models learn from data, and if that data contains biases, the model will likely reproduce and even amplify those biases. This can lead to outputs that are sexist, racist, or otherwise prejudiced.
Challenges in generating unique ideas
- Limitation: AI models generate content based on patterns they've seen. While they can combine these patterns in novel ways, they don't "invent" like humans do. Their "creativity" is a recombination of existing ideas.
Data Privacy, Intellectual Property, and Quality Control Issues:
- Ethical consideration : Using AI models in applications that handle sensitive data raises concerns about data privacy. When AI generates content, questions arise about who owns the intellectual property rights. Ensuring the quality and accuracy of AI-generated content is also a significant challenge.
Bad code
- AI models might generate syntactically correct code when used for coding tasks but functionally flawed or insecure. I have had to correct the code people have added to sites they generated using LLMs. It looked right, but was not. Even when it does work, LLMs have out-of-date expectations for code, using functions like “document.write” that are no longer considered best practice.
Hot takes from an MLOps engineer and technical SEO
This section covers some hot takes I have about LLMs and generative AI. Feel free to fight with me.
Prompt engineering isn't real (for generative text interfaces)
Generative models, especially large language models (LLMs) like GPT-3 and its successors, have been touted for their ability to generate coherent and contextually relevant text based on prompts.
Because of this, and since these models have become the new “gold rush," people have started to monetize “prompt engineering” as a skill. This can be either $1,400 courses or prompt engineering jobs.
However, there are some critical considerations:
LLMs change rapidly
As technology evolves and new model versions are released, how they respond to prompts can change. What worked for GPT-3 might not work the same way for GPT-4 or even a newer version of GPT-3.
This constant evolution means prompt engineering can become a moving target, making it challenging to maintain consistency. Prompts that work in January may not work in March.
Uncontrollable outcomes
While you can guide LLMs with prompts, there's no guarantee they'll always produce the desired output. For instance, asking an LLM to generate a 500-word essay might result in outputs of varying lengths because LLMs don't know what numbers are.
Similarly, while you can ask for factual information, the model might produce inaccuracies because it cannot tell the difference between accurate and inaccurate information by itself.
Using LLMs in non-language-based applications is a bad idea
LLMs are primarily designed for language tasks. While they can be adapted for other purposes, there are inherent limitations:
Struggle with novel ideas
LLMs are trained on existing data, which means they're essentially regurgitating and recombining what they've seen before. They don't "invent" in the truest sense of the word.
Tasks that require genuine innovation or out-of-the-box thinking should not use LLMs.
You can see an issue with this when it comes to people using GPT models for news content – if something novel comes along, it's hard for LLMs to deal with it.

For example, a site that seems to be generating content with LLMs published a possibly libelous article about Megan Crosby. Crosby was caught elbowing opponents in real life.
Without that context, the LLM created a completely different, evidence-free story about a “controversial comment.”
Text-focused
At their core, LLMs are designed for text. While they can be adapted for tasks like image generation or music composition, they might not be as proficient as models specifically designed for those tasks.
LLMs don't know what the truth is
They generate outputs based on patterns encountered in their training data. This means they can't verify facts or discern true and false information.
If they've been exposed to misinformation or biased data during training, or they don't have context for something, they might propagate those inaccuracies in their outputs.
This is especially problematic in applications like news generation or academic research, where accuracy and truth are paramount.
Think about it like this: if an LLM has never come across the name “Jimmy Scrambles” before but knows it's a name, prompts to write about it will only come up with related vectors.
Designers are always better than AI-generated Art
AI has made significant strides in art, from generating paintings to composing music. However, there's a fundamental difference between human-made art and AI-generated art:
Intent, feeling, vibe
Art is not just about the final product but the intent and emotion behind it.
A human artist brings their experiences, emotions, and perspectives to their work, giving it depth and nuance that's challenging for AI to replicate.
A “bad” piece of art from a person has more depth than a beautiful piece of art from a prompt.
الآراء الواردة في هذه المقالة هي آراء المؤلف الضيف وليست بالضرورة Search Engine Land. يتم سرد المؤلفين الموظفين هنا.