
دراسة حالة على مدار عام لتحسين محركات البحث: ما تحتاج لمعرفته حول Googlebot
نشرت: 2019-08-30ملاحظة المحرر: يقدم الرئيس التنفيذي لشركة JetOctopus crawler Serge Bezborodov نصائح الخبراء حول كيفية جعل موقع الويب الخاص بك جذابًا لبرنامج Googlebot. تستند البيانات الواردة في هذه المقالة إلى بحث استمر لمدة عام و 300 مليون صفحة تم الزحف إليها.
قبل بضع سنوات ، كنت أحاول زيادة حركة المرور على موقع تجميع الوظائف الخاص بنا بـ 5 ملايين صفحة. قررت استخدام خدمات وكالة تحسين محركات البحث (SEO) ، متوقعًا أن تمر حركة المرور عبر السطح. ولكنني كنت مخطئا. بدلاً من المراجعة الشاملة ، حصلت على قراءة بطاقات التارو. لهذا السبب عدت إلى المربع الأول وأنشأت زاحف ويب لتحليل SEO شامل على الصفحة.
لقد كنت أتجسس على Googlebot منذ أكثر من عام ، والآن أنا مستعد لمشاركة رؤى حول سلوكه. أتوقع أن توضح ملاحظاتي على الأقل كيفية عمل برامج زحف الويب ، وستساعدك على الأكثر في إجراء تحسين على الصفحة بكفاءة. لقد جمعت البيانات الأكثر أهمية والمفيدة إما لموقع ويب جديد أو موقع يحتوي على آلاف الصفحات.
هل تظهر صفحاتك في SERPs؟
لمعرفة الصفحات الموجودة في نتائج البحث على وجه اليقين ، يجب عليك التحقق من إمكانية فهرسة موقع الويب بالكامل. ومع ذلك ، فإن تحليل كل عنوان URL على موقع يضم أكثر من 10 ملايين صفحة يكلف ثروة ، مثل سيارة جديدة.
دعنا نستخدم تحليل ملفات السجل بدلاً من ذلك. نحن نعمل مع مواقع الويب بالطريقة التالية: نقوم بالزحف إلى صفحات الويب كما يفعل روبوت البحث ، ثم نقوم بتحليل ملفات السجل التي تم جمعها لمدة نصف العام. توضح السجلات ما إذا كانت برامج الروبوت تزور موقع الويب ، والصفحات التي تم الزحف إليها ومتى وعدد مرات زيارة الروبوتات للصفحات.
الزحف هو عملية قيام روبوتات البحث بزيارة موقع الويب الخاص بك ومعالجة جميع الروابط الموجودة على صفحات الويب ووضع هذه الروابط في طابور للفهرسة. أثناء الزحف ، تقارن برامج الروبوت عناوين URL التي تمت معالجتها للتو بتلك الموجودة بالفعل في الفهرس. وبالتالي ، تقوم الروبوتات بتحديث البيانات وإضافة / حذف بعض عناوين URL من قاعدة بيانات محرك البحث لتقديم النتائج الأكثر صلة وحديثة للمستخدمين.
الآن ، يمكننا بسهولة استخلاص هذه الاستنتاجات:
- ما لم يكن روبوت البحث موجودًا على عنوان URL ، فمن المحتمل ألا يكون عنوان URL هذا في الفهرس.
- إذا قام Googlebot بزيارة عنوان URL عدة مرات في اليوم ، فإن عنوان URL هذا له أولوية عالية وبالتالي يتطلب اهتمامًا خاصًا من جانبك.
إجمالاً ، تكشف هذه المعلومات ما الذي يمنع النمو العضوي وتطوير موقع الويب الخاص بك. الآن ، بدلاً من العمل بشكل أعمى ، يمكن لفريقك تحسين موقع الويب بحكمة.
نحن نعمل في الغالب مع مواقع الويب الكبيرة لأنه إذا كان موقع الويب الخاص بك صغيرًا ، فسيقوم Googlebot بالزحف إلى جميع صفحات الويب الخاصة بك عاجلاً أم آجلاً.
على العكس من ذلك ، تواجه مواقع الويب التي تحتوي على 100 صفحة أوو-بلس مشكلة عندما يزور الزاحف صفحات غير مرئية لمشرفي المواقع. قد يتم إهدار ميزانية الزحف القيمة على هذه الصفحات عديمة الفائدة أو حتى الضارة. في الوقت نفسه ، قد لا يعثر الروبوت أبدًا على صفحاتك المربحة نظرًا لوجود فوضى في بنية موقع الويب.
ميزانية الزحف هي الموارد المحدودة التي يكون Googlebot جاهزًا لإنفاقها على موقع الويب الخاص بك. تم إنشاؤه لتحديد أولويات ما يجب تحليله ومتى. يعتمد حجم ميزانية الزحف على العديد من العوامل ، مثل حجم موقع الويب الخاص بك ، وهيكله ، وحجم وتكرار استفسارات المستخدمين ، وما إلى ذلك.
لاحظ أن روبوت البحث لا يهتم بالزحف إلى موقع الويب الخاص بك تمامًا.
الغرض الرئيسي من روبوت محرك البحث هو تزويد المستخدمين بالإجابات الأكثر صلة مع الحد الأدنى من الخسائر في الموارد.يقوم البوت بالزحف إلى أكبر قدر من البيانات التي يحتاجها للغرض الرئيسي. لذا ، فإن مهمتك هي مساعدة الروبوت في التقاط المحتوى الأكثر فائدة وربحًا.
التجسس على Googlebot
على مدار العام الماضي ، قمنا بمسح أكثر من 300 مليون عنوان URL و 6 مليارات سطر سجل على مواقع الويب الكبيرة. بناءً على هذه البيانات ، قمنا بتتبع سلوك Googlebot للمساعدة في الإجابة عن الأسئلة التالية:
- ما هي أنواع الصفحات التي يتم تجاهلها؟
- الصفحات التي يتم زيارتها بشكل متكرر؟
- ما الذي يستحق الاهتمام للبوت؟
- ما الذي لا قيمة له؟
فيما يلي تحليلنا ونتائجنا ، وليس إعادة كتابة إرشادات مشرفي المواقع من Google. في الواقع ، نحن لا نقدم أي توصيات غير مثبتة وغير مبررة. تستند كل نقطة إلى إحصائيات ورسوم بيانية واقعية من أجل راحتك.
دعنا ننتقل إلى المطاردة ونكتشف:
- ما الذي يهم Googlebot حقًا؟
- ما الذي يحدد ما إذا كان البوت يزور الصفحة أم لا؟
حددنا العوامل التالية:
المسافة من الفهرس
DFI يرمز إلى المسافة من الفهرس وهو مدى بُعد عنوان URL الخاص بك لعنوان URL الرئيسي / الجذر / الفهرس في النقرات. إنه أحد أهم المعايير التي تؤثر على تكرار زيارات Googlebot. هنا شريط فيديو تعليمي لمعرفة المزيد عن DFI .
لاحظ أن DFI ليس عدد الشرط المائلة في دليل URL مثل ، على سبيل المثال:
site.com / shop /iphone/iphoneX.html - DFI - 3
لذلك ، يتم حساب DFI بالضبط بواسطة CLICKS من الصفحة الرئيسية
https://site.com/shop/iphone/iphoneX.html
https://site.com كتالوج iPhones → https://site.com/shop/iphone iPhone X → https://site.com/shop/iphone/iphoneX.html - DFI - 2
يمكنك أدناه معرفة كيف انخفض اهتمام Googlebot بعنوان URL مع DFI الخاص به تدريجيًا خلال الشهر الماضي وعلى مدار الأشهر الستة الماضية.
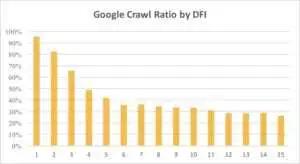
كما ترى ، إذا كان DFI هو 5 t0 6 ، فإن Googlebot يزحف فقط إلى نصف صفحات الويب. وتقل النسبة المئوية للصفحات المعالجة إذا كان DFI أكبر. تم توحيد المؤشرات في الجدول لـ 18 مليون صفحة. لاحظ أن البيانات يمكن أن تختلف حسب مكانة موقع الويب المحدد.
ما يجب القيام به؟
من الواضح أن أفضل استراتيجية في هذه الحالة هي تجنب DFI التي تزيد مدتها عن 5 ، وإنشاء بنية موقع ويب سهلة التنقل ، وإيلاء اهتمام خاص للروابط ، وما إلى ذلك.
الحقيقة هي أن هذه الإجراءات تستغرق وقتًا طويلاً حقًا لمائة موقع ويب يزيد عن 100 صفحة. عادةً ما يكون لمواقع الويب الكبيرة تاريخ طويل من عمليات إعادة التصميم والترحيل. لهذا السبب لا ينبغي لمشرفي المواقع حذف الصفحات التي تحتوي على DFI من 10 أو 12 أو حتى 30. كما أن إدراج رابط واحد من الصفحات التي تتم زيارتها بشكل متكرر لن يحل المشكلة.
الطريقة المثلى للتعامل مع DFI الطويلة هي فحص وتقدير ما إذا كانت عناوين URL هذه ذات صلة ومربحة وما هي المناصب الموجودة في SERPs.
الصفحات ذات DFI الطويلة ولكن المناصب الجيدة في SERPs لديها إمكانات عالية. لزيادة حركة المرور على الصفحات عالية الجودة ، يجب على مشرفي المواقع إدراج روابط من الصفحات التالية. رابط واحد إلى إثنين لا يكفي لإحراز تقدم ملموس.
يمكنك أن ترى من الرسم البياني أدناه أن Googlebot يزور عناوين URL بشكل متكرر إذا كان هناك أكثر من 10 روابط على الصفحة.
الروابط
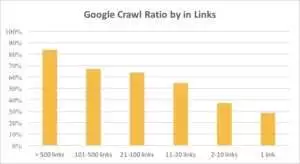

في الواقع ، كلما كان موقع الويب أكبر ، زاد عدد الروابط الموجودة على صفحات الويب أهمية. هذه البيانات في الواقع مأخوذة من أكثر من مليون صفحة من مواقع الويب.
إذا اكتشفت أن هناك أقل من 10 روابط على صفحاتك المربحة ، فلا داعي للذعر. أولاً ، تحقق مما إذا كانت هذه الصفحات عالية الجودة ومربحة. عند القيام بذلك ، أدخل الروابط في صفحات عالية الجودة دون استعجال وبتكرار قصير ، مع تحليل السجلات بعد كل خطوة.
حجم المحتوى
يعد المحتوى أحد الجوانب الأكثر شيوعًا لتحليل تحسين محركات البحث. بالطبع ، كلما كان المحتوى أكثر صلة بموقعك على الويب ، كانت نسبة الزحف أفضل. يمكنك أدناه معرفة مدى انخفاض الاهتمام بـ Googlebot بشكل كبير للصفحات التي تحتوي على أقل من 500 كلمة.
ما يجب القيام به؟
بناءً على تجربتي ، ما يقرب من نصف جميع الصفحات التي تحتوي على أقل من 500 كلمة عبارة عن صفحات مهملة. لقد رأينا حالة احتوى فيها أحد مواقع الويب على 70000 صفحة مع ذكر حجم الملابس فقط ، لذلك كان جزء فقط من هذه الصفحات في الفهرس.
لذلك ، تحقق أولاً مما إذا كنت تحتاج حقًا إلى تلك الصفحات. إذا كانت عناوين URL هذه مهمة ، فيجب إضافة بعض المحتوى ذي الصلة عليها. إذا لم يكن لديك ما تضيفه ، فما عليك سوى الاسترخاء وترك عناوين URL هذه كما هي. من الأفضل أحيانًا عدم فعل أي شيء بدلاً من نشر محتوى غير مفيد.
عوامل اخرى
يمكن أن تؤثر العوامل التالية بشكل كبير على نسبة الزحف:
وقت التحميل
سرعة صفحة الويب أمر بالغ الأهمية للزحف والترتيب. الروبوت يشبه الإنسان: فهو يكره الانتظار طويلاً حتى يتم تحميل صفحة ويب. إذا كان هناك أكثر من مليون صفحة على موقع الويب الخاص بك ، فمن المحتمل أن يقوم روبوت البحث بتنزيل خمس صفحات بوقت تحميل مدته ثانية واحدة بدلاً من الانتظار حتى يتم تحميل صفحة واحدة في 5 ثوانٍ.
ما يجب القيام به؟
في الواقع ، هذه مهمة فنية ولا يوجد حل "أسلوب واحد يناسب الجميع" ، مثل استخدام خادم أكبر. الفكرة الرئيسية هي إيجاد عنق الزجاجة للمشكلة. يجب أن تفهم سبب بطء تحميل صفحات الويب. فقط بعد الكشف عن السبب ، يمكنك اتخاذ إجراء.
نسبة المحتوى الفريد والقوالب
التوازن بين البيانات الفريدة والقوالب مهم. على سبيل المثال ، لديك موقع ويب به أسماء مختلفة للحيوانات الأليفة. ما مقدار المحتوى الملائم والفريد الذي يمكنك جمعه حقًا حول هذا الموضوع؟
كان لونا أكثر أسماء الكلاب "شهرة" ، تليها ستيلا وجاك وميلو وليو.
لا تحب روبوتات البحث إنفاق مواردها على هذه الأنواع من الصفحات.
ما يجب القيام به؟
حافظ على التوازن. لا يحب المستخدمون والروبوتات زيارة الصفحات ذات القوالب المعقدة ومجموعة من الروابط الصادرة والمحتوى القليل.
الصفحات اليتيمة
الصفحات اليتيمة هي عناوين URL ليست في بنية موقع الويب ولا تعرف شيئًا عن هذه الصفحات ، ولكن يمكن الزحف إلى هذه الصفحات اليتيمة بواسطة برامج الروبوت. لتوضيح الأمر ، انظر إلى دائرة أويلر في الصورة أدناه:

يمكنك أن ترى الوضع الطبيعي لموقع الويب الشاب ، والذي لم يتغير هيكله منذ فترة. هناك 900000 صفحة يمكنك أنت والزاحف تحليلها. تتم معالجة حوالي 500000 صفحة بواسطة الزاحف ولكن Google غير معروفة. إذا جعلت 500000 عنوان URL هذه قابلة للفهرسة ، فستزيد حركة المرور الخاصة بك بالتأكيد.
انتبه: حتى موقع الويب الصغير يحتوي على بعض الصفحات (الجزء الأزرق في الصورة) التي ليست في بنية موقع الويب ولكن يزورها الروبوت بانتظام.
ويمكن أن تحتوي هذه الصفحات على محتوى مهملات ، مثل استعلامات الزوار التي يتم إنشاؤها تلقائيًا والتي لا فائدة منها.
لكن المواقع الكبيرة نادرًا ما تكون دقيقة جدًا. غالبًا ما تبدو مواقع الويب التي لها سجل على هذا النحو:

ها هي المشكلة الأخرى: تعرف Google المزيد عن موقعك على الويب أكثر مما تعرفه أنت. يمكن أن تكون هناك صفحات محذوفة وصفحات على JavaScript أو Ajax وعمليات إعادة توجيه معطلة وما إلى ذلك. بمجرد أن واجهنا موقفًا ظهرت فيه قائمة تضم 500000 رابط معطل في خريطة الموقع بسبب خطأ أحد المبرمجين. بعد ثلاثة أيام ، تم العثور على الخطأ وإصلاحه ، لكن Googlebot كان يزور هذه الروابط المعطلة لمدة نصف عام!
في كثير من الأحيان ، يتم إهدار ميزانية الزحف بشكل متكرر في هذه الصفحات المعزولة.
ما يجب القيام به؟
هناك طريقتان لإصلاح هذه المشكلة المحتملة: الأول أساسي: تنظيف الفوضى. تنظيم هيكل الموقع ، وإدراج الروابط الداخلية بشكل صحيح ، وإضافة الصفحات اليتيمة إلى DFI عن طريق إضافة روابط من الصفحات المفهرسة ، وتعيين المهمة للمبرمجين وانتظر زيارة Googlebot التالية.
الطريقة الثانية هي سريعة: اجمع قائمة الصفحات اليتيمة وتحقق مما إذا كانت ذات صلة. إذا كانت الإجابة "نعم" ، فقم بإنشاء خريطة الموقع باستخدام عناوين URL هذه وأرسلها إلى Google. هذه الطريقة أسهل وأسرع ، لكن نصف الصفحات اليتيمة فقط ستكون في الفهرس.
المستوى التالي
لقد تحسنت خوارزميات محرك البحث على مدار عقدين من الزمن ، ومن السذاجة التفكير في إمكانية تفسير زحف البحث ببعض الرسوم البيانية.
نجمع أكثر من 200 معلمة مختلفة لكل صفحة ، ونتوقع أن يزداد هذا الرقم بحلول نهاية العام. تخيل أن موقع الويب الخاص بك هو الجدول الذي يحتوي على مليون سطر (صفحة) وضرب هذه السطور في 200 عمود ، فإن العينة البسيطة لا تكفي لإجراء تدقيق فني شامل. هل توافق؟
قررنا التعمق أكثر في استخدام التعلم الآلي لمعرفة ما يؤثر على زحف Googlebots في كل حالة.

من ناحية ، تعتبر روابط موقع الويب مهمة بينما المحتوى هو العامل الرئيسي للآخر.
كانت النقطة الأساسية من هذه المهمة هي الحصول على إجابات سهلة من البيانات المعقدة والضخمة: ما الذي يؤثر على موقع الويب الخاص بك في الفهرسة أكثر من غيره؟ ما هي مجموعات عناوين URL المرتبطة بنفس العوامل؟ حتى يمكنك العمل معهم بشكل شامل.
قبل تنزيل السجلات وتحليلها على موقع مجمّع HotWork الخاص بنا ، بدت قصة الصفحات اليتيمة المرئية للروبوتات ولكن ليس لنا غير واقعية بالنسبة لي. لكن الموقف الحقيقي فاجأني أكثر: أظهر الزحف 500 صفحة مع إعادة توجيه 301 ، لكن Yandex وجد 700000 صفحة بنفس رمز الحالة هذا.
عادة ، لا يحب المهوسون الفنيون تخزين ملفات السجل لأن هذه البيانات "تفرط في التحميل" على الأقراص. ولكن من الناحية الموضوعية ، في معظم مواقع الويب مع ما يصل إلى 10 ملايين زيارة شهريًا ، يعمل الإعداد الأساسي لتخزين السجلات بشكل مثالي.
عند الحديث عن حجم السجلات ، فإن أفضل حل هو إنشاء أرشيف وتنزيله على Amazon S3-Glacier (يمكنك تخزين 250 جيجابايت من البيانات مقابل دولار واحد فقط). بالنسبة لمسؤولي النظام ، فإن هذه المهمة سهلة مثل صنع فنجان من القهوة. في المستقبل ، ستساعد السجلات التاريخية في الكشف عن الأخطاء التقنية وتقدير تأثير تحديثات Google على موقع الويب الخاص بك.