
Eine E2E-Testreise Teil 1: STUI zu WebdriverIO
Veröffentlicht: 2019-11-21Hinweis: Dies ist ein Beitrag von #frontend@twiliosendgrid. Weitere technische Beiträge finden Sie in der technischen Blogrolle.
Als die Frontend-Architektur von SendGrid über unsere Webanwendungen hinweg auszureifen begann, wollten wir zusätzlich zu unserer üblichen Einheits- und Integrationstestebene eine weitere Testebene hinzufügen. Wir haben versucht, neue Seiten und Funktionen mit E2E-Testabdeckung (End-to-End) mit Browser-Automatisierungstools zu erstellen.
Wir wollten das Testen aus Kundensicht automatisieren und manuelle Regressionstests nach Möglichkeit für große Änderungen vermeiden, die an irgendeinem Teil des Stacks auftreten können. Wir hatten und haben das folgende Ziel: eine Möglichkeit bieten, konsistente, debugfähige, wartbare und wertvolle E2E-Automatisierungstests für unsere Frontend-Anwendungen zu schreiben und mit CICD (Continuous Integration and Continuous Deployment) zu integrieren.
Wir haben mit mehreren technischen Ansätzen experimentiert, bis wir unsere ideale Lösung für E2E-Tests gefunden haben. Auf hohem Niveau fasst dies unsere Reise zusammen:
- Erstellen unserer eigenen benutzerdefinierten internen Ruby Selenium-Lösung, SiteTestUI alias STUI
- Übergang von STUI zu einem knotenbasierten WebdriverIO
- Mit keinem der beiden Setups zufrieden sein und schließlich zu Cypress migrieren
Dieser Blogbeitrag ist einer von zwei Teilen, die unsere Erfahrungen, gewonnenen Erkenntnisse und Kompromisse mit jedem der Ansätze dokumentieren und hervorheben, die auf dem Weg verwendet werden, um Sie und andere Entwickler hoffentlich dabei zu unterstützen, E2E-Tests mit hilfreichen Mustern und Teststrategien zu verbinden.
Teil eins umfasst unsere frühen Kämpfe mit STUI, wie wir zu WebdriverIO migriert sind und dennoch viele ähnliche Abstürze wie STUI erlebt haben. Wir werden besprechen, wie wir Tests mit WebdriverIO geschrieben, die Tests für die Ausführung in einem Container angedockt und schließlich die Tests mit Buildkite, unserem CICD-Anbieter, integriert haben.
Wenn Sie zum heutigen Stand der E2E-Tests übergehen möchten, fahren Sie bitte mit Teil zwei fort, in dem wir unsere endgültige Migration von STUI und WebdriverIO zu Cypress durchlaufen und wie wir sie in verschiedenen Teams einrichten.
TLDR: Wir hatten ähnliche Probleme und Kämpfe mit beiden Selenium-Wrapper-Lösungen, STUI und WebdriverIO, dass wir schließlich begannen, nach Alternativen in Cypress zu suchen. Wir haben eine Reihe aufschlussreicher Lektionen gelernt, um das Schreiben von E2E-Tests und die Integration mit Docker und Buildkite anzugehen.
Inhaltsverzeichnis:
Erster Ausflug ins E2E-Testen: siteTESUI alias STUI
Umstellung von STUI auf WebdriverIO
Schritt 1: Entscheidung über Abhängigkeiten für WebdriverIO
Schritt 2: Umgebungskonfigurationen und Skripte
Schritt 3: Lokale Implementierung von ENE-Tests
Schritt 4: Alle Tests andocken
Schritt 5: Integration mit CICD
Kompromisse mit WebdriverIo
Weiter geht es nach Cypress
Erster Ausflug in das E2E-Testen: SiteTestUI alias STUI
Bei der anfänglichen Suche nach einem Browser-Automatisierungstool machten sich unsere SDETs (Software Development Engineers in Test) daran, unsere eigene benutzerdefinierte Inhouse-Lösung zu entwickeln, die mit Ruby und Selenium, insbesondere Rspec und einem benutzerdefinierten Selenium-Framework namens Gridium, erstellt wurde. Wir schätzten die browserübergreifende Unterstützung, die Möglichkeit, unsere eigenen benutzerdefinierten Integrationen mit TestRail für die Testfälle unserer QA (Quality Assurance)-Ingenieure zu konfigurieren, und den Gedanken, das ideale Repo für alle Frontend-Teams zu erstellen, um E2E-Tests an einem Ort zu schreiben und zu sein laufen nach einem Zeitplan.
Als Frontend-Entwickler, der bestrebt war, zum ersten Mal einige E2E-Tests mit den Tools zu schreiben, die die SDETs für uns erstellt haben, begannen wir mit der Implementierung von Tests für die Seiten, die wir bereits veröffentlicht hatten, und überlegten, wie wir Benutzer und Seed-Daten richtig einrichten, um uns auf Teile davon zu konzentrieren die Funktion, die wir testen wollten. Wir haben auf dem Weg einige großartige Dinge gelernt, wie das Erstellen von Seitenobjekten zum Organisieren von Hilfsfunktionen und Selektoren von Elementen, mit denen wir pro Seite interagieren möchten, und haben begonnen, Spezifikationen zu erstellen, die dieser Struktur folgen:
Wir haben nach und nach umfangreiche Testsuiten in verschiedenen Teams im selben Repo nach ähnlichen Mustern aufgebaut, aber wir erlebten bald viele Frustrationen, die unseren Fortschritt für neue Entwickler und beständige Mitwirkende an STUI immens verlangsamen würden, wie zum Beispiel:
- Das Einrichten und Ausführen erforderte viel Zeit und Mühe , um alle Browsertreiber, Ruby Gem-Abhängigkeiten und korrekten Versionen zu installieren, bevor die Testsuiten überhaupt ausgeführt wurden. Manchmal mussten wir herausfinden, warum die Tests auf dem eigenen Computer im Vergleich zum Computer einer anderen Person ausgeführt wurden und wie sich ihre Setups unterscheiden.
- Testsuiten wurden vermehrt und liefen stundenlang bis zur Fertigstellung. Da alle Teams zum selben Repo beigetragen haben, bedeutete die serielle Ausführung aller Tests, mehrere Stunden auf die Ausführung der gesamten Testsuite zu warten, und mehrere Teams, die neuen Code pushten, führten möglicherweise zu einem weiteren fehlerhaften Test an anderer Stelle.
- Wir waren frustriert von unzuverlässigen CSS-Selektoren und komplizierten XPath-Selektoren . Dieses Bild unten erklärt genug, wie die Verwendung von XPath die Dinge komplizierter machen kann, und dies waren einige der einfacheren.

- Debugging-Tests waren schmerzhaft . Wir hatten Probleme, vage Fehlerausgaben zu debuggen, und wir hatten normalerweise keine Ahnung, wo und wie etwas fehlgeschlagen ist. Wir konnten die Tests nur wiederholt ausführen und den Browser beobachten, um abzuleiten, wo er möglicherweise versagt hat und welcher Code dafür verantwortlich ist. Wenn ein Test in einer Docker-Umgebung in CICD fehlschlug, ohne dass man sich etwas anderes als die Konsolenausgaben ansehen musste, hatten wir Mühe, das Problem lokal zu reproduzieren und das Problem zu lösen.
- Wir sind auf Selenium-Bugs und Langsamkeit gestoßen. Die Tests liefen langsam, da alle Anfragen vom Server an den Browser gesendet wurden, und manchmal stürzten unsere Tests vollständig ab, wenn versucht wurde, viele Elemente auf der Seite auszuwählen, oder aus unbekannten Gründen während der Testläufe.
- Es wurde mehr Zeit damit verbracht, Tests zu reparieren und zu überspringen, und fehlerhafte geplante Build-Testläufe wurden ignoriert. Die Tests lieferten keinen Wert, indem sie tatsächlich wahre Fehler im System anzeigten.
- Unsere Frontend-Teams fühlten sich von den E2E-Tests getrennt, da sie in einem separaten Repo von den jeweiligen Webanwendungs-Repos existierten . Wir mussten oft beide Repos gleichzeitig geöffnet haben und weiterhin zwischen den Codebasen hin und her schauen, zusätzlich zu den Browser-Tabs, wenn die Tests liefen.
- Frontend-Teams mochten den Kontextwechsel vom täglichen Schreiben von Code in JavaScript oder TypeScript zu Ruby nicht und mussten das Schreiben von Tests neu lernen, wenn sie zu STUI beitrugen.
- Da dies für viele von uns ein erster Schritt war, als sie zum Test beitrugen, sind wir auf viele Antimuster gestoßen, wie z zu folgen, was einen großartigen Test ausmacht.
Trotz unserer Fortschritte beim Schreiben einer beträchtlichen Anzahl von E2E-Tests für viele verschiedene Teams in einem Repository und dem Erlernen einiger hilfreicher Muster, die wir mitnehmen können, hatten wir Kopfschmerzen mit der allgemeinen Entwicklererfahrung, mehreren Fehlerquellen und dem Mangel an wertvollen, stabilen Tests um unseren gesamten Stapel zu überprüfen.
Wir schätzten eine Möglichkeit, andere Frontend-Entwickler und QAs in die Lage zu versetzen, ihre eigenen stabilen E2E-Testsuiten mit JavaScript zu erstellen, die sich in ihrem eigenen Anwendungscode befinden, um die Wiederverwendung, Nähe und Eigentümerschaft der Tests zu fördern. Dies veranlasste uns, WebdriverIO, ein JavaScript-basiertes Selenium-Framework für Browserautomatisierungstests, als unseren ersten Ersatz für STUI, die benutzerdefinierte Ruby Selenium-Inhouse-Lösung, zu untersuchen.
Später erlebten wir seine Stürze und wechselten schließlich zu Cypress (schneller Vorlauf zu Teil 2 hier, falls Ihnen WebdriverIO-Zeug nicht zusagt), aber wir sammelten unschätzbare Erfahrungen mit der Einrichtung einer standardisierten Infrastruktur in den Repos jedes Teams und der Integration von E2E-Tests in CICD für unser Frontend Teams und die Einführung technischer Muster, die es wert sind, auf unserer Reise dokumentiert zu werden, und damit andere erfahren, wer möglicherweise in WebdriverIO oder eine andere E2E-Testlösung einsteigen wird.
Umstellung von STUI auf WebdriverIO

Als wir mit WebdriverIO begannen, um hoffentlich die Frustrationen zu lindern, die wir erlebten, experimentierten wir damit, dass jedes Frontend-Team seine vorhandenen Automatisierungstests, die mit dem Ruby Selenium-Ansatz geschrieben wurden, in WebdriverIO-Tests in JavaScript oder TypeScript umwandeln und Stabilität, Geschwindigkeit, Entwicklererfahrung und allgemeine Wartung vergleichen sollten Die Tests.
Um unseren idealen Aufbau zu erreichen, bei dem E2E-Tests in den Anwendungsrepositorys der Frontend-Teams gespeichert sind und sowohl in CICD- als auch in geplanten Pipelines ausgeführt werden, haben wir die folgenden Schritte zusammengefasst, die im Allgemeinen für jedes Team gelten, das ein E2E-Testframework mit ähnlichen Zielen integrieren möchte :
- Installieren und Auswählen von Abhängigkeiten zum Verbinden mit dem Testframework
- Einrichten von Umgebungskonfigurationen und Skriptbefehlen
- Implementieren von E2E-Tests, die lokal gegen verschiedene Umgebungen bestehen
- Dockerisieren der Tests
- Integrieren von Dockerized-Tests mit dem CICD-Anbieter
Schritt 1: Entscheidung über Abhängigkeiten für WebdriverIO
WebdriverIO bietet Entwicklern die Flexibilität, aus vielen Frameworks, Reportern und Diensten auszuwählen, um den Test Runner zu starten. Dies erforderte viel Bastelei und Recherche für die Teams, um sich für bestimmte Bibliotheken zu entscheiden, um loszulegen.
Da WebdriverIO nicht vorschreibt, was zu verwenden ist, öffnete es Frontend-Teams die Tür zu unterschiedlichen Bibliotheken und Konfigurationen, obwohl die allgemeinen Kerntests bei der Verwendung der WebdriverIO-API konsistent wären.
Wir entschieden uns dafür, jedes der Frontend-Teams basierend auf seinen Präferenzen anpassen zu lassen, und landeten in der Regel bei der Verwendung von Mocha als Testframework, Mochawesome als Reporter, dem Selenium Standalone-Dienst und Typescript-Unterstützung. Wir entschieden uns für Mocha und Mochawesome aufgrund der Vertrautheit und früheren Erfahrung unserer Teams mit Mocha, aber andere Teams entschieden sich auch für andere Alternativen.
Schritt 2: Umgebungskonfigurationen und Skripte
Nachdem wir uns für die WebdriverIO-Infrastruktur entschieden hatten, brauchten wir eine Möglichkeit, unsere WebdriverIO-Tests mit unterschiedlichen Einstellungen für jede Umgebung auszuführen. Hier ist eine Liste, die die meisten Anwendungsfälle veranschaulicht, wie wir diese Tests ausführen wollten und warum wir sie unterstützen wollten:
- Gegen einen Webpack-Entwicklungsserver, der auf localhost läuft (z. B. http://localhost:8000), und dieser Entwicklungsserver würde auf eine bestimmte Umgebungs-API wie Testen oder Staging verweisen (z. B. https://testing.api.com oder https:// staging.api.com).
Warum? Manchmal müssen wir Änderungen an unserer lokalen Web-App vornehmen, z. B. das Hinzufügen spezifischerer Selektoren für unsere Tests, um robuster mit den Elementen zu interagieren, oder wir waren gerade dabei, eine neue Funktion zu entwickeln, und mussten die vorhandenen Automatisierungstests anpassen und validieren würde lokal gegen unsere neuen Codeänderungen passieren. Wann immer sich der Anwendungscode geändert hat und wir noch nicht in die bereitgestellte Umgebung hochgeladen haben, haben wir diesen Befehl verwendet, um unsere Tests für unsere lokale Web-App auszuführen. - Gegen eine bereitgestellte App für eine bestimmte Umgebung (z. B. https://testing.app.com oder https://staging.app.com) wie Testen oder Staging
Warum? In anderen Fällen ändert sich der Anwendungscode nicht, aber wir müssen möglicherweise unseren Testcode ändern, um einige Unregelmäßigkeiten zu beheben, oder wir fühlen uns sicher genug, um Tests hinzuzufügen oder zu löschen, ohne Frontend-Änderungen vorzunehmen. Wir haben diesen Befehl stark genutzt, um Tests lokal für die bereitgestellte App zu aktualisieren oder zu debuggen, um genauer zu simulieren, wie unsere Tests in CICD-Pipelines ausgeführt werden. - Ausführung in einem Docker-Container gegen eine bereitgestellte App für eine bestimmte Umgebung wie Testen oder Staging
Warum? Dies ist für CICD-Pipelines gedacht, damit wir E2E-Tests auslösen können, die in einem Docker-Container beispielsweise gegen die bereitgestellte Staging-App ausgeführt werden, und sicherstellen, dass sie bestanden werden, bevor Code in der Produktion oder in geplanten Testläufen in einer dedizierten Pipeline bereitgestellt wird. Bei der anfänglichen Einrichtung dieser Befehle haben wir viele Versuche und Irrtümer durchgeführt, um Docker-Container mit unterschiedlichen Umgebungsvariablenwerten hochzufahren und zu testen, ob die richtigen Tests erfolgreich ausgeführt wurden, bevor wir sie mit unserem CICD-Anbieter Buildkite verbunden haben.
Um dies zu erreichen, richten wir eine allgemeine Basis-Konfigurationsdatei mit gemeinsam genutzten Eigenschaften und vielen umgebungsspezifischen Dateien ein, sodass jede Umgebungs-Konfigurationsdatei mit der Basisdatei zusammengeführt wird und je nach Bedarf Eigenschaften überschreibt oder hinzufügt. Wir hätten eine Datei für jede Umgebung haben können, ohne dass eine Basisdatei erforderlich wäre, aber das würde zu vielen Duplizierungen in gemeinsamen Einstellungen führen. Wir haben uns entschieden, eine Bibliothek wie deepmerge zu verwenden, um dies für uns zu handhaben, aber es ist wichtig zu beachten, dass das Zusammenführen mit verschachtelten Objekten oder Arrays nicht immer perfekt ist. Überprüfen Sie die resultierenden Ausgabekonfigurationen immer doppelt, da dies zu undefiniertem Verhalten führen kann, wenn doppelte Eigenschaften vorhanden sind, die nicht korrekt zusammengeführt wurden.
Wir haben eine gemeinsame Basiskonfigurationsdatei , wdio.conf.js , wie folgt erstellt:
Um unseren ersten großen Anwendungsfall der Ausführung von E2E-Tests auf einem lokalen Webpack-Entwicklungsserver, der auf eine Umgebungs-API verweist, anzupassen, haben wir die localhost-Konfigurationsdatei wdio.localhost.conf.js folgt generiert:
Beachten Sie, dass wir die Basisdatei zusammengeführt und der Datei die localhost-spezifischen Eigenschaften hinzugefügt haben, um sie kompakter und einfacher zu warten. Wir verwenden auch den Selenium Standalone-Dienst, um verschiedene Arten von Browsern, auch bekannt als Funktionen, zu entwickeln.
Für den zweiten Anwendungsfall des Ausführens von E2E-Tests für eine bereitgestellte Web-App richten wir die Konfigurationsdateien der Test- und Staging-App `wdio.testing.conf.js` und wdio.staging.conf.js ähnlich wie folgt ein:
Hier haben wir den Konfigurationsdateien einige zusätzliche Umgebungsvariablen hinzugefügt, z. B. Anmeldeinformationen für dedizierte Benutzer beim Staging, und die „baseUrl“ aktualisiert, sodass sie auf die URL der bereitgestellten Staging-App verweist.
Für den dritten Anwendungsfall der Ausführung von E2E-Tests in einem Docker-Container gegen eine bereitgestellte Webanwendung im Bereich unseres CICD-Anbieters richten wir die CICD-Konfigurationsdateien wdio.cicd.testing.conf.js und wdio.cicd.staging.conf.js , etwa so:
Beachten Sie, dass wir den Selenium Standalone-Dienst nicht mehr verwenden, da wir später Selenium Chrome, Selenium Hub und den Anwendungscode in separaten Diensten in einer Docker Compose-Datei installieren werden. Diese Konfiguration weist auch dieselben Umgebungsvariablen wie die Staging-Konfiguration auf, z. B. die Anmeldeinformationen und „baseUrl“, da wir davon ausgehen, dass unsere Tests mit der bereitgestellten Staging-App ausgeführt werden, und der einzige Unterschied darin besteht, dass diese Tests in einem Docker-Container ausgeführt werden sollen .
Nachdem diese Umgebungskonfigurationsdateien eingerichtet waren, skizzierten wir die Skriptbefehle „ package.json “, die als Grundlage für unsere Tests dienen würden. Für dieses Beispiel haben wir den Befehlen „uitest“ vorangestellt, um UI-Tests mit WebdriverIO zu bezeichnen und weil wir auch Testdateien mit *.uitest.js . Hier sind einige Beispielbefehle für die Staging-Umgebung:
Schritt 3: E2E-Tests lokal implementieren
Mit allen verfügbaren Testbefehlen haben wir Tests in unserem STUI-Repo ausgearbeitet, damit wir sie in WebdriverIO-Tests umwandeln können. Wir konzentrierten uns auf kleine bis mittelgroße Seitentests und begannen, das Seitenobjektmuster anzuwenden, um die gesamte Benutzeroberfläche für jede Seite auf organisierte Weise zu kapseln.
Wir könnten strukturierte Dateien mit einer Reihe von Hilfsfunktionen oder Objektliteralen oder jeder anderen Strategie haben, aber der Schlüssel war, einen konsistenten Weg zu haben, um schnell wartbare Tests bereitzustellen und dabei zu bleiben. Wenn sich der UI-Flow oder die DOM-Elemente für eine bestimmte Seite geändert haben, mussten wir nur das damit verbundene Seitenobjekt und möglicherweise den Testcode umgestalten, damit die Tests wieder bestanden werden.
Wir haben das Seitenobjektmuster implementiert, indem wir ein Basisseitenobjekt mit gemeinsam genutzter Funktionalität haben, von dem alle anderen Seitenobjekte ausgehen würden. Wir hatten Funktionen wie open, um eine konsistente API für alle unsere Seitenobjekte bereitzustellen, um die URL einer Seite im Browser zu „öffnen“ oder zu besuchen. Es sah ungefähr so aus:
Die Implementierung der spezifischen Seitenobjekte folgte dem gleichen Muster der Erweiterung von der Basisklasse Page und dem Hinzufügen der Selektoren zu bestimmten Elementen, mit denen wir interagieren oder die wir bestätigen wollten, und Hilfsfunktionen, um Aktionen auf der Seite auszuführen.
Beachten Sie, wie wir die Basisklasse open über super.open(...) mit der spezifischen Route der Seite verwendet haben, damit wir die Seite mit diesem Aufruf SomePage.open() besuchen können. Wir haben auch die bereits initialisierte Klasse exportiert, damit wir auf die Elemente wie SomePage.submitButton oder SomePage.tableRows und mit WebdriverIO-Befehlen mit diesen Elementen interagieren oder sie bestätigen können. Wenn das Seitenobjekt geteilt und mit eigenen Elementeigenschaften in einem Konstruktor initialisiert werden sollte, könnten wir die Klasse auch direkt exportieren und das Seitenobjekt in den Testdateien mit new SomePage(...constructorArgs) instanziieren.
Nachdem wir die Seitenobjekte mit Selektoren und einigen Hilfsfunktionen ausgestattet hatten, schrieben wir die E2E-Tests und modellierten gemeinsam diese Testformel:
- Richten Sie über die API ein oder aus, was erforderlich ist, um die Testbedingungen auf den erwarteten Ausgangspunkt zurückzusetzen, bevor Sie die eigentlichen Tests ausführen.
- Melden Sie sich für den Test bei einem dedizierten Benutzer an, sodass wir bei jedem direkten Besuch von Seiten angemeldet bleiben und nicht durch die Benutzeroberfläche gehen mussten. Wir haben eine einfache
login-Hilfsfunktion erstellt, die einen Benutzernamen und ein Passwort aufnimmt, die den gleichen API-Aufruf machen, den wir für unsere Login-Seite verwenden, und die schließlich unser Authentifizierungstoken zurückgibt, das benötigt wird, um eingeloggt zu bleiben und die Header von geschützten API-Anforderungen weiterzugeben. Andere Unternehmen verfügen möglicherweise über noch mehr benutzerdefinierte interne Endpunkte oder Tools, um schnell brandneue Benutzer mit Startdaten und Konfigurationen zu erstellen, aber wir hatten leider keinen ausreichend ausgearbeiteten. Wir würden es auf die altmodische Weise tun und dedizierte Testbenutzer in unseren Umgebungen mit unterschiedlichen Konfigurationen über die Benutzeroberfläche erstellen und oft Tests für Seiten mit unterschiedlichen Benutzern aufteilen, um Konflikte zwischen Ressourcen zu vermeiden und isoliert zu bleiben, wenn Tests parallel liefen. Wir mussten sicherstellen, dass die dedizierten Testbenutzer nicht von anderen berührt wurden, da sonst die Tests fehlschlagen würden, wenn jemand unwissentlich an einem von ihnen herumbastelte. - Automatisieren Sie die Schritte so, als ob ein Endbenutzer mit der Funktion/Seite interagieren würde. Normalerweise würden wir die Seite besuchen, die unseren Feature-Flow enthält, und beginnen, den allgemeinen Schritten zu folgen, die ein Endbenutzer tun würde, wie z ein Ergebnis der Aktion. Durch die Verwendung unserer praktischen Seitenobjekte und Selektoren haben wir jeden Schritt schnell implementiert und während der Plausibilitätsprüfungen festgestellt, was der Benutzer während des Funktionsablaufs auf der Seite sehen oder nicht sehen sollte, um sicherzustellen, dass sich bestimmte Dinge wie erwartet verhalten vor und nach jedem Schritt. Wir haben uns auch bewusst für hochwertige Happy-Path-Tests und manchmal leicht reproduzierbare häufige Fehlerzustände entschieden und den Rest der Tests auf niedrigerer Ebene auf Unit- und Integrationstests verschoben.
Hier ist ein grobes Beispiel für das allgemeine Layout unserer E2E-Tests (diese Strategie galt auch für andere Test-Frameworks, die wir ausprobiert haben):

Nebenbei bemerkt, wir haben uns entschieden, nicht alle Tipps und Fallstricke für WebdriverIO und E2E Best Practices in dieser Blog-Post-Reihe zu behandeln, aber wir werden über diese Themen in einem zukünftigen Blog-Post sprechen, also bleiben Sie dran!
Schritt 4: Alle Tests andocken
Beim Ausführen jedes Buildkite-Pipelineschritts auf einer neuen AWS-Maschine in der Cloud konnten wir nicht einfach „npm run uitests:staging“ aufrufen, da diese Maschinen keinen Knoten, Browser, unseren Anwendungscode oder andere Abhängigkeiten haben, um die Tests tatsächlich auszuführen .
Um dies zu lösen, haben wir alle Abhängigkeiten wie Node, Selenium, Chrome und den Anwendungscode in einem Docker-Container gebündelt, damit die WebdriverIO-Tests erfolgreich ausgeführt werden können. Wir nutzten Docker und Docker Compose, um alle für die Inbetriebnahme erforderlichen Dienste zusammenzustellen, die in Dockerfiles und docker-compose.yml Dateien übersetzt wurden, und viel experimentiert, um Docker-Container lokal hochzufahren, um die Dinge zum Laufen zu bringen.
Um mehr Kontext zu bieten, wir waren keine Experten in Docker, daher hat es eine beträchtliche Anlaufzeit gedauert, um zu verstehen, wie man die Dinge zusammenfügt. Es gibt mehrere Möglichkeiten, WebdriverIO-Tests zu dockerisieren, und wir fanden es schwierig, viele verschiedene Dienste zusammen zu orchestrieren und verschiedene Docker-Images, Compose-Versionen und Tutorials zu sichten, bis die Dinge funktionierten.
Wir werden größtenteils ausgearbeitete Dateien demonstrieren, die mit einer der Konfigurationen unseres Teams übereinstimmen, und wir hoffen, dass dies Ihnen oder allen, die sich mit dem allgemeinen Problem der Dockerisierung von Selenium-basierten Tests befassen, Einblicke verschafft.
Auf hohem Niveau forderten unsere Tests Folgendes:
- Selenium , um Befehle gegen einen Browser auszuführen und mit ihm zu kommunizieren. Wir haben Selenium Hub verwendet, um nach Belieben mehrere Instanzen hochzufahren, und das Image „selenium/hub“ für den
selenium-hubDienst in der Docker-Compose-Datei heruntergeladen. - Ein Browser , gegen den man laufen kann. Wir haben Selenium Chrome-Instanzen aufgerufen und das Image „selenium/node-chrome-debug“ für den
selenium-chromeDienst in derdocker-compose.yml file. - Anwendungscode zum Ausführen unserer Testdateien mit allen anderen installierten Node-Modulen. Wir haben eine neue
Dockerfile-Datei erstellt, um eine Umgebung mit Node bereitzustellen, um npm-Pakete zu installieren undpackage.jsonSkripts auszuführen, den Testcode zu kopieren und einen Dienst für die Ausführung der Testdateien mit dem Namenuitestsin der Dateidocker-compose.yml.
Um einen Dienst mit all unserem Anwendungs- und Testcode aufzurufen, der zum Ausführen der WebdriverIO-Tests erforderlich ist, haben wir eine Dockerfile namens Dockerfile.uitests , alle node_modules installiert und den Code in das Arbeitsverzeichnis des Images in einer Node-Umgebung kopiert. Dies würde von unserem uitests Docker Compose-Dienst verwendet werden, und wir haben das Dockerfile Setup auf folgende Weise erreicht:
Um den Selenium Hub, den Chrome-Browser und den Anwendungstestcode für die Ausführung der WebdriverIO-Tests zusammenzubringen, haben wir die Dienste selenium selenium-hub , selenium-chrom e und uitest in der Datei docker-compose.uitests.yml :
Wir haben die Selenium-Hub- und Chrome-Images über Umgebungsvariablen, depends_on und das Verfügbarmachen von Ports für Dienste verbunden. Unser Testanwendungscode-Image würde schließlich hochgeladen und aus einer von uns verwalteten privaten Docker-Registrierung abgerufen.
Wir würden das Docker-Image für den Testcode während CICD mit bestimmten Umgebungsvariablen wie VERSION und PIPELINE_SUFFIX , um die Images durch ein Tag und einen spezifischeren Namen zu referenzieren. Wir würden dann die Selenium-Dienste starten und Befehle über den uitests -Dienst ausführen, um die WebdriverIO-Tests auszuführen.
Beim Erstellen unserer Docker Compose-Dateien haben wir die hilfreichen Befehle wie docker-compose up und docker-compose down mit dem auf unseren Computern installierten Mac Docker genutzt, um lokal zu testen, ob unsere Images die richtigen Konfigurationen hatten und reibungslos liefen, bevor sie in Buildkite integriert wurden. Wir haben alle Befehle dokumentiert, die erforderlich sind, um die markierten Images zu erstellen, sie in die Registrierung hochzuladen, herunterzuziehen und die Tests gemäß den Werten der Umgebungsvariablen auszuführen.
Schritt 5: Integration mit CICD
Nachdem wir funktionierende Docker-Befehle etabliert hatten und unsere Tests erfolgreich in einem Docker-Container in verschiedenen Umgebungen liefen, begannen wir mit der Integration mit Buildkite, unserem CICD-Anbieter.
Buildkite bot Möglichkeiten zum Ausführen von Schritten in einer .yml -Datei auf unseren AWS-Maschinen mit Bash-Skripten und Umgebungsvariablen, die entweder über den Code oder die Buildkite-Benutzeroberfläche mit Einstellungen für die Pipeline unseres Repositorys festgelegt wurden.
Buildkite ermöglichte es uns auch, diese Testpipeline von unserer Hauptbereitstellungspipeline mit exportierten Umgebungsvariablen auszulösen, und wir würden diese Testschritte für andere isolierte Testpipelines wiederverwenden, die nach einem Zeitplan ausgeführt würden, den unsere QAs überwachen und prüfen würden.
Auf hoher Ebene teilten unsere Test-Buildkite-Pipelines für WebdriverIO und spätere Cypress-Pipelines die folgenden ähnlichen Schritte:
- Richten Sie die Docker-Images ein . Erstellen, taggen und pushen Sie die für die Tests erforderlichen Docker-Images in die Registrierung, damit wir sie in einem späteren Schritt herunterziehen können.
- Führen Sie die Tests basierend auf Umgebungsvariablenkonfigurationen aus . Ziehen Sie die markierten Docker-Images für den spezifischen Build herunter und führen Sie die richtigen Befehle für eine bereitgestellte Umgebung aus, um ausgewählte Testsuiten aus den festgelegten Umgebungsvariablen auszuführen.
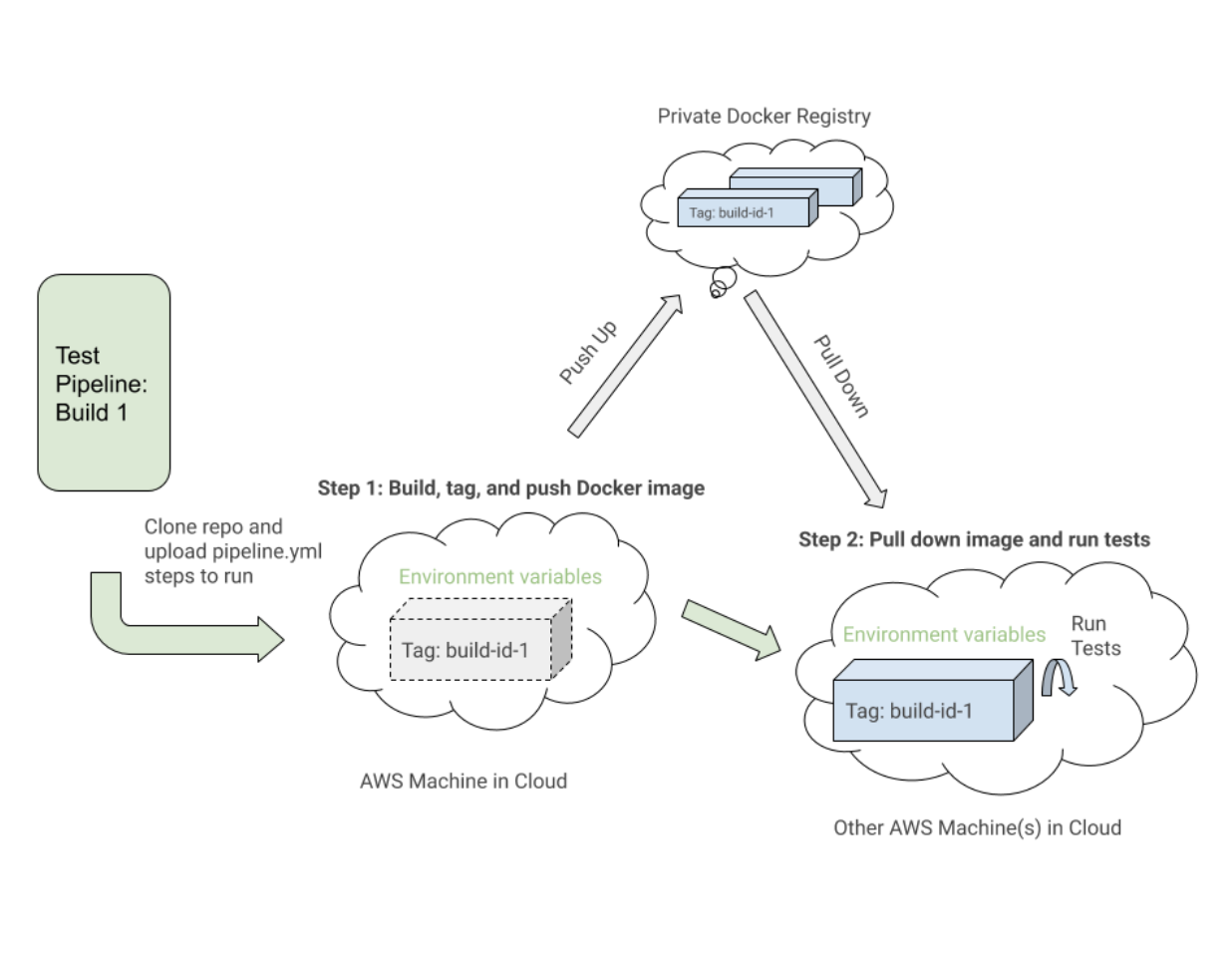
Hier ist ein enges Beispiel einer pipeline.uitests.yml -Datei, die das Einrichten der Docker-Images im Schritt „Build UITests Docker Image“ und das Ausführen der Tests im Schritt „Run Webdriver tests against Chrome“ demonstriert:
Beachtenswert ist der erste Schritt „Build UITests Docker Image“ und wie er die Docker-Images für den Test einrichtet. Es verwendete den Docker Compose- build -Befehl, um den uitests -Dienst mit dem gesamten Anwendungstestcode zu erstellen, und markierte ihn mit der latest und ${VERSION} -Umgebungsvariablen, damit wir dasselbe Image in Zukunft mit dem richtigen Tag für diesen Build abrufen können Schritt.
Jeder Schritt kann irgendwo auf einer anderen Maschine in der AWS-Cloud ausgeführt werden, sodass die Tags das Image für die spezifische Buildkite-Ausführung eindeutig identifizieren. Nach dem Taggen des Images haben wir das neueste Image mit Versions-Tags zur Wiederverwendung in unsere private Docker-Registrierung hochgeladen.
Im Schritt „Webdriver-Tests gegen Chrome ausführen“ ziehen wir das Image herunter, das wir im ersten Schritt erstellt, getaggt und gepusht haben, und starten den Selenium Hub, Chrome und die Testdienste. Basierend auf Umgebungsvariablen wie $UITESTENV und $UITESTSUITE würden wir den auszuführenden Befehlstyp wie npm run uitest: und die Testsuiten auswählen, die für diesen bestimmten Buildkite-Build ausgeführt werden sollen, wie z. B. --suite $UITESTSUITE .
Diese Umgebungsvariablen würden über die Buildkite-Pipelineeinstellungen festgelegt oder dynamisch von einem Bash-Skript ausgelöst, das ein Buildkite-Auswahlfeld analysiert, um zu bestimmen, welche Testsuiten in welcher Umgebung ausgeführt werden sollen.
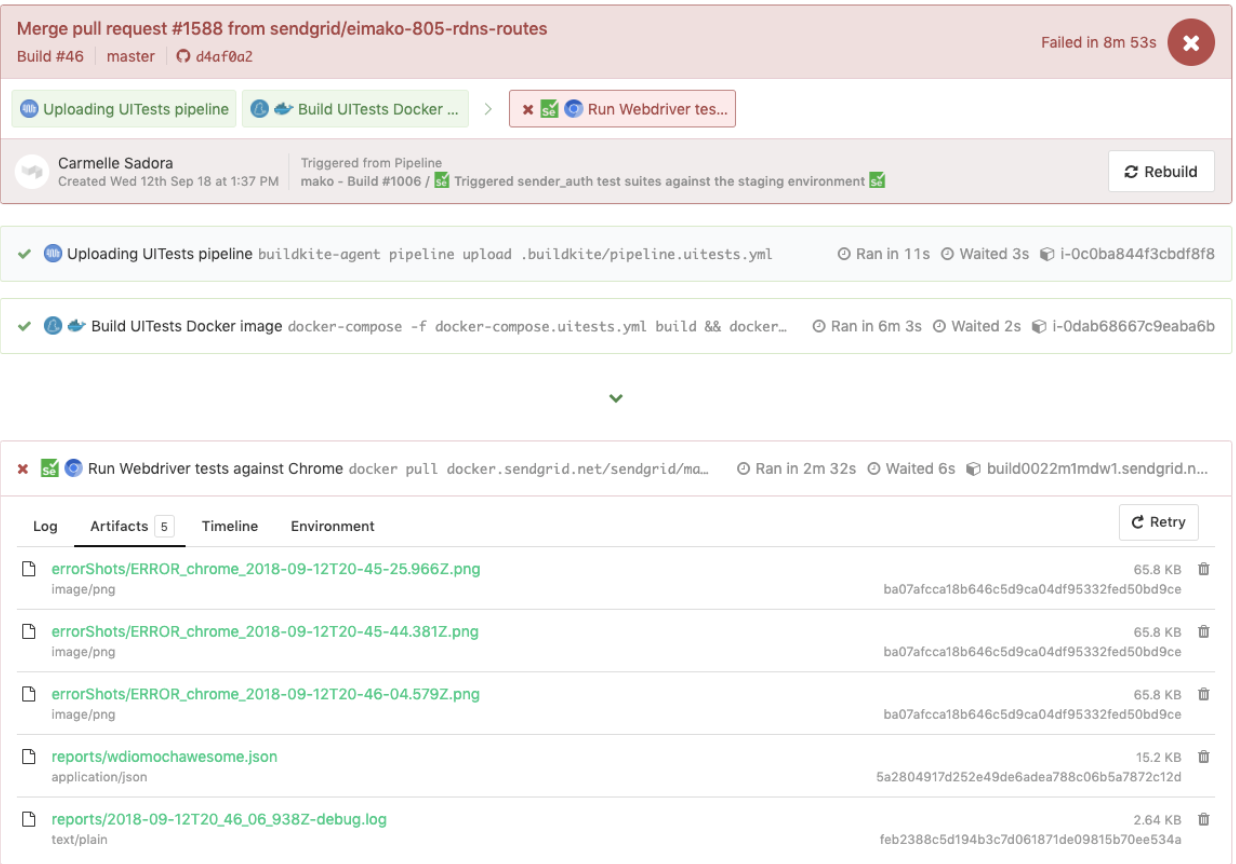
Hier ist ein Beispiel für WebdriverIO-Tests, die in einer dedizierten Testpipeline ausgelöst wurden, die ebenfalls dieselbe pipeline.uitests.yml -Datei wiederverwendete, jedoch mit Umgebungsvariablen, die dort eingestellt waren, wo die Pipeline ausgelöst wurde. Dieser Build ist fehlgeschlagen und es gab Fehler-Screenshots, die wir uns auf der Registerkarte „ Artifacts “ und der Konsolenausgabe auf der Registerkarte „ Logs “ ansehen konnten. Erinnern Sie sich an die artifact_paths in der pipeline.uitests.yml (https://gist.github.com/alfredlucero/71032a82f3a72cb2128361c08edbcff2#file-pipeline-uitests-yml-L38), Screenshots-Einstellungen für `mochawesome` in der `wdio.conf.js `-Datei (https://gist.github.com/alfredlucero/4ee280be0e0674048974520b79dc993a#file-wdio-conf-js-L39) und Mounten der Volumes im `uitests`-Dienst in der `docker-compose.uitests.yml` (https://gist.github.com/alfredlucero/d2df4533a4a49d5b2f2c4a0eb5590ff8#file-docker-compose-yml-L32)?
Wir konnten die Screenshots so verknüpfen, dass sie über die Buildkite-Benutzeroberfläche zugänglich sind, damit wir sie direkt herunterladen und sofort sehen können, um bei den Debugging-Tests zu helfen, wie unten gezeigt.
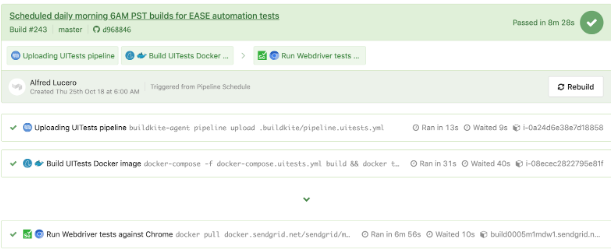
Ein weiteres Beispiel für WebdriverIO-Tests, die in einer separaten Pipeline nach einem Zeitplan für eine bestimmte Seite unter Verwendung der Datei pipeline.uitests.yml ausgeführt werden, außer mit Umgebungsvariablen, die bereits in den Buildkite-Pipelineeinstellungen konfiguriert sind, wird darunter angezeigt.
Es ist wichtig zu beachten, dass jeder CICD-Anbieter unterschiedliche Funktionen und Möglichkeiten zum Integrieren von Schritten in eine Art Bereitstellungsprozess beim Zusammenführen in neuem Code hat, sei es durch .yml Dateien mit spezifischer Syntax, GUI-Einstellungen, Bash-Skripts oder andere Mittel.
Als wir von Jenkins auf Buildkite umgestiegen sind, haben wir die Möglichkeiten für Teams drastisch verbessert, ihre eigenen Pipelines innerhalb ihrer jeweiligen Codebasis zu definieren, Schritte bei Bedarf über Skalierungsmaschinen hinweg zu parallelisieren und leichter lesbare Befehle zu verwenden.
Unabhängig davon, welchen CICD-Anbieter Sie möglicherweise verwenden, sind die Strategien zum Integrieren der Tests beim Einrichten der Docker-Images und beim Ausführen der Tests basierend auf Umgebungsvariablen für Portabilität und Flexibilität ähnlich.
Kompromisse mit WebdriverIO
Nachdem wir eine beträchtliche Anzahl der benutzerdefinierten Ruby Selenium-Lösungstests auf WebdriverIO-Tests umgestellt und in Docker und Buildkite integriert hatten, verbesserten wir uns in einigen Bereichen, hatten aber immer noch ähnliche Probleme wie das alte System, was uns letztendlich zu unserem nächsten und letzten Stopp bei Cypress führte unsere E2E-Testlösung.
Hier ist eine Liste einiger der Vorteile, die wir aus unseren Erfahrungen mit WebdriverIO im Vergleich zur benutzerdefinierten Ruby Selenium-Lösung gefunden haben:
- Tests wurden ausschließlich in JavaScript oder TypeScript und nicht in Ruby geschrieben . Dies bedeutete weniger Kontextwechsel zwischen Sprachen und weniger Zeitaufwand für das Neulernen von Ruby jedes Mal, wenn wir E2E-Tests schrieben.
- Wir haben Tests zusammen mit dem Anwendungscode angeordnet und nicht in einem gemeinsam genutzten Ruby-Repo. Wir fühlten uns nicht länger davon abhängig, dass die Tests anderer Teams fehlschlagen, und übernahmen die E2E-Tests für unsere Funktionen in unseren Repos direkter.
- Wir haben die Möglichkeit des browserübergreifenden Testens sehr geschätzt . Mit WebdriverIO konnten wir Tests mit verschiedenen Funktionen oder Browsern wie Chrome, Firefox und IE durchführen, obwohl wir uns hauptsächlich darauf konzentrierten, unsere Tests mit Chrome durchzuführen, da über 80 % unserer Benutzer unsere App über Chrome besuchten.
- Wir haben die Möglichkeit der Integration mit Diensten von Drittanbietern erwogen . Die WebdriverIO-Dokumentation erläuterte die Integration mit Diensten von Drittanbietern wie BrowserStack und SauceLabs, um unsere App auf allen Geräten und Browsern abzudecken.
- Wir hatten die Flexibilität, unseren eigenen Test Runner, Reporter und Services auszuwählen . WebdriverIO war nicht vorgeschrieben, was zu verwenden war, also nahm sich jedes Team die Freiheit zu entscheiden, ob Dinge wie Mocha und Chai oder Jest und andere Dienste verwendet werden sollten oder nicht. Dies könnte auch als Betrug interpretiert werden, da die Teams anfingen, sich von den Einstellungen des anderen zu entfernen, und es viel Zeit in Anspruch nahm, mit jeder der Optionen zu experimentieren, die wir auswählen konnten.
- Die WebdriverIO-API, -CLI und -Dokumentation waren brauchbar genug, um Tests zu schreiben und in Docker und CIC D zu integrieren . Wir konnten viele verschiedene Konfigurationsdateien haben, Spezifikationen gruppieren, Tests über die Befehlszeile ausführen und Tests nach dem Seitenobjektmuster schreiben. Die Dokumentation könnte jedoch klarer sein und wir mussten uns mit vielen seltsamen Fehlern befassen. Trotzdem konnten wir unsere Tests von der Ruby Selenium Lösung umstellen.
Wir haben in vielen Bereichen Fortschritte gemacht, die uns in der vorherigen Ruby Selenium-Lösung gefehlt haben, aber wir sind auf viele Showstopper gestoßen, die uns daran gehindert haben, mit WebdriverIO All-in zu gehen, wie zum Beispiel die folgenden:
- Da WebdriverIO noch Selenium-basiert war, erlebten wir viele seltsame Zeitüberschreitungen, Abstürze und Fehler, die uns an negative Flashbacks mit unserer alten Ruby-Selenium-Lösung erinnerten. Manchmal stürzten unsere Tests vollständig ab, wenn wir viele Elemente auf der Seite auswählten, und die Tests liefen langsamer als wir wollten. Wir mussten Problemumgehungen durch viele Github-Probleme finden oder bestimmte Methoden beim Schreiben von Tests vermeiden.
- Die allgemeine Entwicklererfahrung war suboptimal . Die Dokumentation bot einen groben Überblick über die Befehle, aber nicht genügend Beispiele, um alle Verwendungsmöglichkeiten zu erklären. Wir haben es vermieden, E2E-Tests mit Ruby zu schreiben und konnten schließlich Tests in JavaScript oder TypeScript schreiben, aber die WebdriverIO-API war etwas verwirrend im Umgang. Einige gängige Beispiele waren die Verwendung von
$vs.$$für Singular- vs. Plural-Elemente,$('...').waitForVisible(9000, true)für das Warten darauf, dass ein Element nicht sichtbar ist, und andere nicht intuitive Befehle. Wir haben viele unzuverlässige Selektoren erlebt und mussten für alles explizit$(...).waitForVisible(). - Debugging-Tests waren für Entwickler und QAs äußerst schmerzhaft und mühsam . Whenever tests failed, we only had screenshots, which would often be blank or not capturing the right moment for us to deduce what went wrong, and vague console error messages that did not point us in the right direction of how to solve the problem and even where the issue occurred. We often had to re-run the tests many times and stare closely at the Chrome browser running the tests to hopefully put things together as to where in the code our tests failed. We used things like
browser.debug()but it often did not work or did not provide enough information. We gradually gathered a bunch of console error messages and mapped them to possible solutions over time but it took lots of pain and headache to get there. - WebdriverIO tests were tough to set up with Docker . We struggled with trying to incorporate it into Docker as there were many tutorials and ways to do things in articles online, but it was hard to figure out a way that worked in general. Hooking up 2 to 3 services together with all these configurations led to long trial and error experiments and the documentation did not guide us enough in how to do that.
- Choosing the test runner, reporter, assertions, and services demanded lots of research time upfront . Since WebdriverIO was flexible enough to allow other options, many teams had to spend plenty of time to even have a solid WebdriverIO infrastructure after experimenting with a lot of different choices and each team can have a completely different setup that doesn't transfer over well for shared knowledge and reuse.
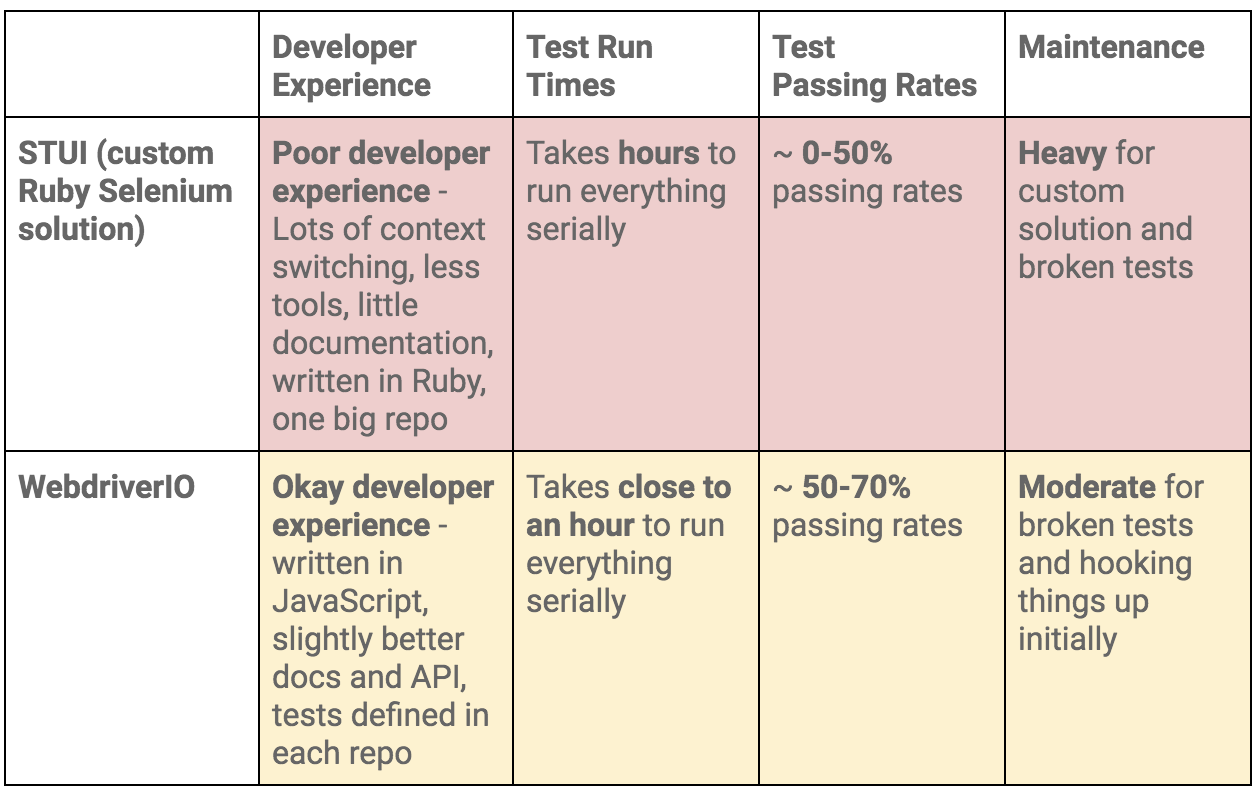
To summarize our WebdriverIO and STUI comparison, we analyzed the overall developer experience (related to tools, writing tests, debugging, API, documentation, etc.), test run times, test passing rates, and maintenance as displayed in this table:
Moving On to Cypress
At the end of the day, our WebdriverIO tests were still flaky and tough to maintain. More time was still spent debugging tests in dealing with weird Selenium issues, vague console errors, and somewhat useful screenshots than actually reaping the benefits of seeing tests fail for when the backend or frontend encountered issues.
We appreciated cross-browser testing and implementing tests in JavaScript, but if our tests could not pass consistently without much headache for even Chrome, then it became no longer worth it and we would then simply have a STUI 2.0.
With WebdriverIO we still strayed from the crucial aspect of providing a way to write consistent, debuggable, maintainable, and valuable E2E automation tests for our frontend applications in our original goal. Overall, we learned a lot about integrating with Buildkite and Docker, using page objects, and outlining tests in a structured way that will transfer over to our final solution with Cypress.
If we felt it was necessary to run our tests in multiple browsers and against various third-party services, we could always circle back to having some tests written with WebdriverIO, or if we needed something fully custom, we would revisit the STUI solution.
Ultimately, neither solution met our main goal for E2E tests, so follow us on our journey in how we migrated from STUI and WebdriverIO to Cypress in part 2 of the blog post series.