
Apache Apex – Eine Einführung
Veröffentlicht: 2015-12-29Apache Hadoop hat sich zu einem De-facto-Software-Framework für zuverlässiges, skalierbares, verteiltes und groß angelegtes Computing entwickelt. Seit seiner Einführung ist Hadoop das Framework der ersten Wahl für die Batch-Verarbeitung. Von großen Banken bis hin zu Online-Einzelhandelsgiganten nutzt jeder Hadoop für die Erstellung regelmäßiger Berichte, Berechnungen und für viele weitere Anwendungsfälle. Typischerweise handelt es sich bei diesen Anwendungsfällen um Batch-orientierte Prozesse und es dauert einige Stunden, bis wir aus den Daten eine Bedeutung gewinnen. Die schnelle Welt von heute erfordert Bedeutung oder Aktionen aus Rohdaten fast zum Zeitpunkt ihrer Generierung. Dies hat zu einem Konzept der Stromverarbeitung geführt. Obwohl Hadoop ursprünglich nicht als geeignet für die Stream-Verarbeitung angesehen wurde, hat die Erfindung von YARN (Hadoop 2.0) es zu einem guten Kandidaten dafür gemacht. Derzeit gibt es mehrere Stream-Processing-Frameworks im Hadoop-Ökosystem, und Apex ist ein brandneues Framework, das in diesen überfüllten Markt eindringt.
Was ist Apache Apex?
Apache Apex ist eine native YARN-basierte Plattform, die Anwendungsentwicklern hilft, Stream-orientierte sowie Batch-orientierte Anwendungen zu schreiben. Es wurde entwickelt, um Daten während der Übertragung auf verteilte, hochleistungsfähige und fehlertolerante Weise zu verarbeiten. Das Sahnehäubchen ist die einfache API, die es Benutzern ermöglicht, ihren Java-Code mit begrenzten Kenntnissen der Stream-Verarbeitung zu schreiben.
Der Apex basiert auf separaten Funktions- und Betriebsspezifikationen, anstatt sie zusammenzusetzen. Dadurch können sich Anwendungsentwickler auf das Schreiben von benutzerdefinierten Funktionen konzentrieren, ohne darüber nachdenken zu müssen, wie sie in einer verteilten Umgebung funktionieren.
Apache Apex verfügt über eine umfangreiche Bibliothek häufig verwendeter Funktionen. Diese werden als Teil der Apache Apex-Malhar-Bibliothek hinzugefügt. Diese Bibliothek verfügt über Operatoren für den Zugriff auf verschiedene Dateisysteme, Datenbanken und Nachrichtenwarteschlangen. Die Community fügt Tag für Tag Operatoren hinzu, die das Leben von Anwendungsentwicklern erleichtern.
Was sind Kernblöcke von Apache Apex?
Die Architektur von Apex ist sehr einfach. Apex verfügt über Malhar, eine Operator-Bibliothek und Kern-Engine, mit der man arbeiten kann. Der Kern von Apex könnte wie folgt dargestellt werden, sie werden oft als Hauptblöcke von Apache Apex bezeichnet.
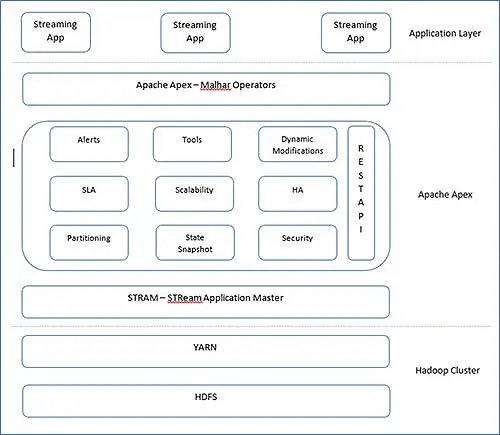
Sie können Ebenen klar trennen und können sich einen Überblick verschaffen, wo es passt. Lassen Sie uns Informationen zu diesen Blöcken sehen.
- StrAM ( Str eam Application Master )
StrAM ist ein YARN Application Master. Seine Verantwortung umfasst den Start von Stream-Anwendungen, die Ressourcenzuweisung und die Planung logischer DAGs. Zusammen mit diesen YARN-Operationen initialisiert StrAM Operatoren, Streams. StrAM sammelt auch Statistiken von seinen Kindern. - Zustandsschnappschuss
Stream-Processing-Frameworks konnten es sich nicht leisten, verarbeitete Ergebnisse zu verlieren. Darüber hinaus müssen sie wissen, wie viel sie verarbeitet haben, um Datensätze nach der Wiederherstellung nach einem Ausfall korrekt verarbeiten zu können. Daher ist das regelmäßige Checkpointing bei der Stream-Verarbeitung wichtig. In Apex verfolgt StrAM Checkpointing, und an der Betreibergrenze werden regelmäßige Checkpointings auf HDFS durchgeführt. - REST-API
StrAM ist der Zugangspunkt für die REST-API. Externe Tools können auf diese REST-API zugreifen und sich in jede externe Anwendung integrieren. - Werkzeuge
Apex bietet CLI zum Starten und Überwachen von Apex-Anwendungen. Sogar wir können mit Hilfe von REST-APIs unsere eigenen erstellen. Zusammen mit der CLI kann die Anwendung mit statischen Konfigurationsskripts für den automatischen Start konfiguriert werden. - Partitionierung
- Dynamische Modifikationen
- SLA-Analyse
Apache Apex führt regelmäßig eigene SLA-Analysen durch. Es führt Latenz-, Engpass- und Durchsatzanalysen durch und fügt weitere Ressourcen hinzu, um die konfigurierten SLAs zu erfüllen. - Sicherheit
- Hohe Verfügbarkeit
Apache Apex nutzt die Neustartfunktion von YARN und startet vom letzten Prüfpunktstatus neu. - Malhar
Apache Apex –Malhar ist eine Operatorbibliothek mit zahlreichen Operatoren. Diese Operatoren sind kategorisiert in - Ein-/Ausgabeoperatoren –
Unter dieser Kategorie hat Malhar derzeit Operatoren zum Lesen/Schreiben - Dateisystem
- RDBMS
- NoSQL-Speicher
- Nachrichtenwarteschlangen
- In-Memory-Datenbanken
- Sozialen Medien
- Rechenoperatoren –
- Musterabgleich
- Statistik und Mathe
- Maschinelles Lernen
- Parser
- Sozialen Medien
- Pufferserver
Apex bietet Partitionierung basierend auf Schlüsseln und dynamischen Lastenausgleich. Sogar der Benutzer kann sein eigenes Partitionierungsschema definieren.
Apache Apex hat diese sehr nützliche und einzigartige Funktion. Es unterstützt logische DAG-Änderungen und Änderungen des physischen Ausführungsplans.
Apex unterstützt Kerberos. Auf den zugrunde liegenden gesicherten Hadoop-Cluster kann mit inhärenter Kerberos-Integration zugegriffen werden.
Malhar verfügt über viele Operatoren, die bei der tatsächlichen Implementierung der Geschäftslogik helfen. Diese Bibliothek hat
Pufferserver liegen an jeder Betreibergrenze. Im Falle von Daten können lokale Operator-Pufferserver nach Zeichenfolgen von Operatoren sein. Der Hauptzweck von ihnen besteht darin, Daten an Kanten vorübergehend zu halten, bevor sie an die nächsten weitergeleitet werden. Sie spielen eine wichtige Rolle, wenn der Knoten nach einem Ausfall wiederhergestellt wird. Pufferserver laden Daten aus dem letzten Checkpoint-Zustand zur Wiedergabe

Was ist das Apex-Anwendungsprogrammiermodell?
Dies bietet ein reichhaltiges Framework und eine Malhar-Bibliothek, was bedeutet, dass Anwendungsentwickler nur Operatoren verbinden und die Anwendung starten müssen. Daher ist Ihre Anwendung nichts anderes als eine Folge von Operatoren.
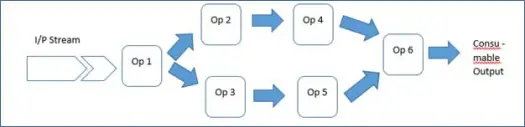
So macht Rich Framework das Leben von Entwicklern einfach. Sehen wir uns also an, wie diese Demoanwendung ausgeführt wird
Apache Apex-Demo
Beginnen wir also mit „ Hello World of Big Data J“, einer kleinen Demo zur Wortzählung mit Apache Apex.
Apache Apex einrichten
Um diese Demo auszuführen, müssen wir Apex konfigurieren. Sie können Apache Apex auf Ihrem vorhandenen Cluster installieren oder es gibt eine einfache Möglichkeit zum Ausprobieren. Sie können die vorinstallierte Sandbox-VM hier von der DataTorrent-Website herunterladen. Für diese Demo verwenden wir eine vorinstallierte VM.
Exemplarische Vorgehensweise Apex-UI-Konsole
Apex wird mit einer sehr intuitiv und schön gestalteten UI-Konsole geliefert, die Sie zum Starten, Überwachen und Verwalten von Anwendungen verwenden können. Es enthält verschiedene Statistiken zu verschiedenen Komponenten, die bereitgestellt werden.
Danach haben Sie die Sandbox-VM heruntergeladen, enttarnen und in Ihren bevorzugten VM-Player laden (ich verwende den VMWare VM-Player). Alle Software und Tools, die zum Ausführen von Apex erforderlich sind, sind bereits in dieser VM konfiguriert, und alle Startskripts sind so konfiguriert, dass sie beim Booten des Betriebssystems ausgeführt werden. Wenn Ihre VM also hochgefahren ist, haben Sie eine laufende Instanz von Apache Apex. Um jetzt die Konsole anzuzeigen, klicken Sie einfach auf http://locahost:9090 in Ihrem bevorzugten Webbrowser und melden Sie sich bei der Konsole an. Standardbenutzername: Das Passwort für die Sandbox-VM lautet dtadmin: dtadmin. Sie werden die Konsole wie unten sehen
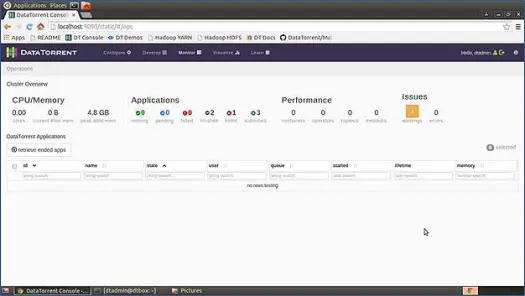
Diese Seite gibt uns einen vollständigen Überblick über alle Systeme wie CPU- und Speicherauslastung, Anwendungen, Leistung, Probleme usw.
Um eine Anwendung bereitzustellen, gehen Sie oben auf der Seite auf die Registerkarte Entwickeln.
Hier können Sie Ihre Anwendungspakete bereitstellen und die Tupelschemas für die Daten in Apex verwalten.
Apex stellt Ihnen eine Reihe von Anwendungen zur Verfügung, die Sie unten aufgelistet sehen können:
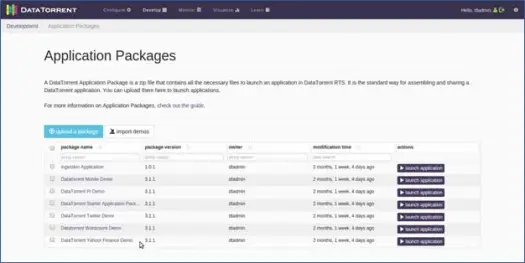
WordCount-Demo
Lassen Sie uns nun die Wordcount-Anwendung starten. Sie können dies tun, indem Sie neben DataTorrent Wordcount Demo auf die Option zum Starten der Anwendung klicken. Als nächstes können Sie eine andere Anwendung angeben und Konfigurationsdetails ändern, falls erforderlich (Wir werden dies nicht tun, da die meisten Standardeinstellungen gut funktionieren, ändern wir einfach den App-Namen in „MyWordCountDemo“). Sie sehen eine Meldung, die besagt, dass die Anwendung erfolgreich bereitgestellt wurde, mit einem Link zur Anwendung. Klicken Sie auf diesen Link.

Dies öffnet eine neue Seite. Warten Sie einige Sekunden, bis sich der Anwendungsstatus von „Angenommen“ in „Wird ausgeführt“ ändert. Sie sehen nun eine Seite, die mit verschiedenen Statistiken und Informationen gefüllt ist. Die nächsten beiden Screenshots zeigen sie.
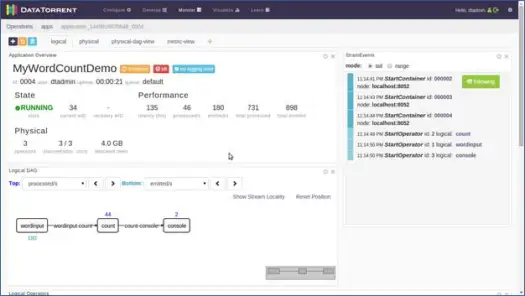
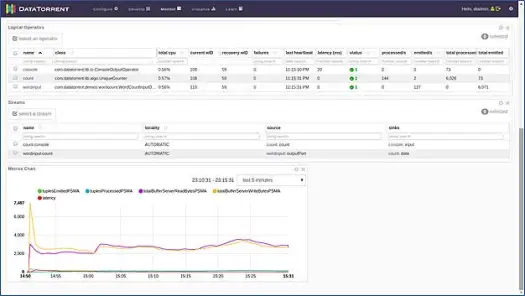
Diese Seiten zeigen uns verschiedene Informationen wie logische, physische und metrische Ansichten der Anwendung sowie Statistiken verschiedener Tupel/Datensätze, die von der Anwendung jede Sekunde verarbeitet werden. Es zeigt eine grafische Darstellung der ausgegebenen Tupel und der Latenzen usw.
Sie können auf einen der logischen Operatoren klicken, seine Aufzeichnungen überprüfen und sogar eine Probe aufzeichnen. Lassen Sie uns das für den Konsolenoperator tun. Klicken Sie auf Konsolenbetreiber und Sie erhalten detaillierte Informationen zum Betreiber wie folgt:
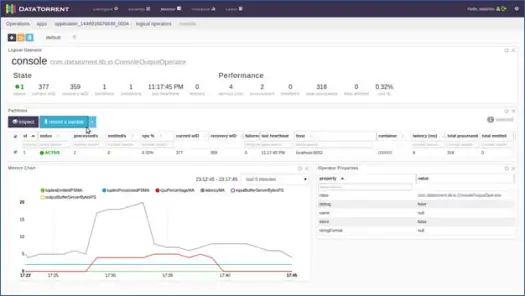
Wählen Sie als Nächstes eine der Partitionen aus und klicken Sie auf Sample aufnehmen.
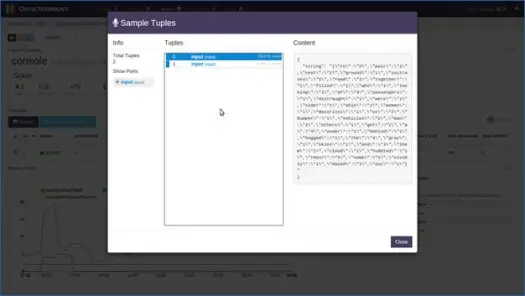
Nach ein paar Sekunden sehen Sie, dass Tupel gefüllt sind, klicken Sie auf Tupel, um seinen Inhalt anzuzeigen. Wie Sie aus dem Inhalt sehen können, hat die Anwendung eine Wortzählung auf Daten basierend auf Fenstern durchgeführt, und es gab 2 „to“, 4 „the“, 4 „a“ usw. im 0. Eingabetupel für dieses Fenster. Sie können die Anwendung jetzt beenden, indem Sie auf der Hauptseite der Anwendung auf „Herunterfahren“ oder „Kill“ klicken.
Das war's, wir haben die Wordcount-Anwendung erfolgreich bereitgestellt und ausgeführt.
Fazit
Das war also die Einführung in ein neues Streaming-Tool – Apache Apex und das erfolgreiche Ausführen einer Anwendung in Apache Apex. Apache Apex hat viele hervorstechende Merkmale, die ihm einen Vorteil gegenüber anderen bestehenden Frameworks verschaffen, die ich in späteren Beiträgen behandeln werde.