
Apache Spark: Funkelnder Stern am Big-Data-Himmel.
Veröffentlicht: 2015-09-24- Empfehlen Sie Millionen von Produkten an die richtigen Kunden.
- Verfolgung des Suchverlaufs und Angebot von ermäßigten Preisen für Flugreisen.
- Vergleichen Sie die technischen Fähigkeiten der Person und schlagen Sie geeignete Personen vor, mit denen Sie in Ihrem Bereich in Kontakt treten können.
- Muster in Milliarden von mobilen Objekten, Netztürmen und Anruftransaktionen verstehen und Optimierungen von Telekommunikationsnetzen berechnen oder Netzlücken finden.
- Untersuchen von Millionen von Merkmalen von Sensoren und Analysieren von Fehlern in Sensornetzwerken.
Die zugrunde liegenden Daten, die verwendet werden müssen, um die richtigen Ergebnisse für alle oben genannten Aufgaben zu erzielen, sind vergleichsweise sehr groß. Es kann von herkömmlichen Systemen nicht effizient (sowohl räumlich als auch zeitlich) gehandhabt werden.
Das sind alles Big-Data-Szenarien.
Um diese Art von umfangreichen Daten zu sammeln, zu speichern und Berechnungen durchzuführen, benötigen wir ein spezialisiertes Cluster-Computing-System. Apache Hadoop hat dieses Problem für uns gelöst.
Es bietet ein verteiltes Speichersystem (HDFS) und eine Parallel-Computing-Plattform (MapReduce).
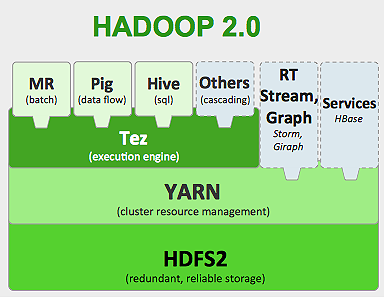
Das Hadoop-Framework funktioniert wie folgt:
- Zerlegt große Datendateien in kleinere Teile, die von einzelnen Computern verarbeitet werden (Verteilen von Speicher).
- Teilt einen längeren Job in kleinere Aufgaben auf, die parallel ausgeführt werden (Parallel Computation).
- Behandelt Fehler automatisch.
Einschränkungen von Hadoop
Hadoop verfügt über spezialisierte Tools in seinem Ökosystem, um verschiedene Aufgaben auszuführen. Wenn Sie also einen End-to-End-Lebenszyklus einer Anwendung ausführen möchten, müssen Sie mit mehreren Tools arbeiten. Für SQL -Abfragen verwenden Sie beispielsweise hive /pig , für Streaming- Quellen müssen Sie mit Hadoop-integriertem Streaming oder Apache Storm (das nicht Teil des Hadoop-Ökosystems ist) oder für maschinelle Lernalgorithmen Mahout verwenden. All diese Systeme zu integrieren, um einen einzigen Anwendungsfall für die Datenpipeline zu erstellen, ist eine ziemliche Aufgabe.
Im MapReduce- Job
- Alle Ausgaben von Zuordnungsaufgaben werden auf lokalen Festplatten (oder HDFS) ausgegeben.
- Hadoop führt alle Spill-Dateien zu einer größeren Datei zusammen, die nach der Anzahl der Reducer sortiert und partitioniert wird.
- Und Reduzieren Sie Aufgaben, müssen Sie sie erneut in den Speicher laden.
Dieser Prozess verlangsamt den Job und verursacht Festplatten-E/A und Netzwerk-E/A. Dies macht Mapreduce auch ungeeignet für die iterative Verarbeitung, bei der Sie Algorithmen des maschinellen Lernens immer wieder auf dieselbe Gruppe von Daten anwenden müssen.
Betreten Sie die Welt von Apache Spark:
Apache Spark wurde 2009 in UC Berkeley AMPLAB entwickelt und wurde 2010 zum Apache Open-Source-Projekt mit dem höchsten Beitrag bis heute.
Apache Spark ist ein allgemeineres System, bei dem Sie sowohl Batch- als auch Streaming-Jobs gleichzeitig ausführen können. Es ersetzt seinen Vorgänger MapReduce in der Geschwindigkeit, indem es Funktionen zur schnelleren Verarbeitung von Daten im Speicher hinzufügt. Es ist auch effizienter auf der Festplatte. Es nutzt die Speicherverarbeitung mit seiner grundlegenden Dateneinheit RDD (Resilient Distributed Dataset). Diese halten so viele Datensätze wie möglich für den gesamten Lebenszyklus des Jobs im Speicher und sparen so Festplatten-I/O. Einige Daten können nach der Speicherobergrenze über die Festplatte verschüttet werden.
Das folgende Diagramm zeigt die Laufzeit in Sekunden von Apache Hadoop und Spark zur Berechnung der logistischen Regression. Hadoop benötigte 110 Sekunden, während Spark dieselbe Aufgabe in nur 0,9 Sekunden erledigte.
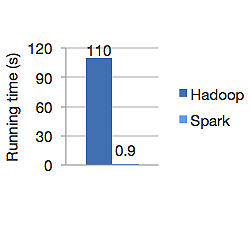
Spark speichert nicht alle Daten im Arbeitsspeicher. Wenn sich Daten jedoch im Speicher befinden, wird der LRU-Cache optimal genutzt, um sie schneller zu verarbeiten. Es ist 100-mal schneller bei der Berechnung von Daten im Speicher und immer noch schneller auf der Festplatte als Hadoop.
Das verteilte Datenspeichermodell von Spark, Resilient Distributed Datasets (RDD), garantiert Fehlertoleranz, was wiederum Netzwerk-I/O minimiert. Funkenpapier sagt:

„RDDs erreichen Fehlertoleranz durch einen Begriff der Abstammung: Wenn eine Partition eines RDD verloren geht, verfügt das RDD über genügend Informationen darüber, wie es von anderen RDDs abgeleitet wurde, um nur diese Partition neu erstellen zu können.“
Sie müssen also keine Daten replizieren, um Fehlertoleranz zu erreichen.
In Spark MapReduce wird die Ausgabe des Mappers im Puffercache des Betriebssystems gespeichert, und Reducer ziehen sie auf ihre Seite und schreiben sie direkt in ihren Speicher, im Gegensatz zu Hadoop, wo die Ausgabe auf die Festplatte übertragen und erneut gelesen wird.
Der In-Memory-Cache von Spark macht es für maschinelle Lernalgorithmen geeignet, bei denen Sie dieselben Daten immer wieder verwenden müssen. Spark kann komplexe Jobs und mehrstufige Datenpipelines mit Direct Acyclic Graph (DAGs) ausführen.
Spark ist in Scala geschrieben und läuft auf JVM (Java Virtual Machine). Spark bietet Entwicklungs-APIs für die Sprachen Java, Scala, Python und R. Spark läuft auf Hadoop YARN, Apache Mesos und verfügt über einen eigenen eigenständigen Cluster-Manager.
Im Jahr 2014 sicherte es sich den 1. Platz im Weltrekord für das Sortieren von 100 TB Daten (1 Billion Datensätze) in nur 23 Minuten, während der vorherige Rekord von Hadoop von Yahoo bei etwa 72 Minuten lag. Dies beweist, dass Spark Daten dreimal schneller und mit zehnmal weniger Maschinen sortiert. Die gesamte Sortierung erfolgte auf der Festplatte (HDFS), ohne tatsächlich die In-Memory-Cache-Funktion von Spark zu verwenden.
Spark-Ökosystem
Spark ist dafür gedacht, fortschrittliche Analysen in einem Rutsch durchzuführen, um dies zu erreichen, bietet es folgende Komponenten:
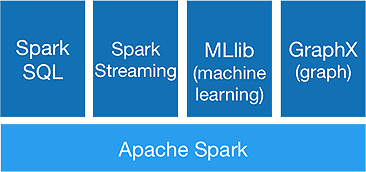
1.Spark-Kern:
Die Spark-Kern-API ist die Basis des Apache Spark-Frameworks, das die Auftragsplanung, Aufgabenverteilung, Speicherverwaltung, E/A-Vorgänge und die Wiederherstellung nach Fehlern übernimmt. Die logische Hauptdateneinheit in Spark heißt RDD (Resilient Distributed Dataset), das Daten verteilt speichert, um später parallel verarbeitet zu werden. Es berechnet träge Operationen. Daher muss der Speicher nicht die ganze Zeit belegt sein, und andere Jobs können ihn verwenden.
2.Spark-SQL:
Es bietet interaktive Abfragemöglichkeiten mit geringer Latenz. Die neue DataFrame -API kann sowohl strukturierte als auch halbstrukturierte Daten enthalten und allen SQL-Operationen und -Funktionen ermöglichen, Berechnungen durchzuführen.
3.Spark-Streaming:
Es bietet Echtzeit-Streaming-APIs , die Daten in Mikrobatches sammeln und verarbeiten.
Es verwendet Dstreams , die nichts anderes als eine kontinuierliche Folge von RDDs sind, um Geschäftslogiken für eingehende Daten zu berechnen und sofort Ergebnisse zu generieren.
4.MLlib :
Es ist die Bibliothek für maschinelles Lernen von Spark (fast 9- mal schneller als Mahout), die sowohl maschinelles Lernen als auch statistische Algorithmen wie Klassifizierung, Regression, kollaborative Filterung usw. bereitstellt.
5.GraphX :
Die GraphX-API bietet Funktionen zur Handhabung von Graphen und zur Durchführung von Graph-parallelen Berechnungen. Es enthält Graphalgorithmen wie PageRank und verschiedene Funktionen zur Analyse von Graphen.
Bedeutet Spark das Ende der Hadoop-Ära?
Spark ist noch ein junges System, nicht so ausgereift wie Hadoop. Es gibt kein Tool für NOSQL wie HBase. In Anbetracht des hohen Speicherbedarfs für eine schnellere Datenverarbeitung kann man nicht wirklich sagen, dass es auf handelsüblicher Hardware läuft. Spark hat kein eigenes Speichersystem. Dafür setzt es auf HDFS.
Daher ist Hadoop MapReduce immer noch gut für bestimmte Batch-Jobs, die nicht viel Daten-Pipelining beinhalten.
„Neue Technologien ersetzen alte niemals vollständig; sie würden beide lieber koexistieren.“
Fazit
In diesem Blog haben wir uns angesehen, warum Sie ein Tool wie Spark benötigen, was es zu einem schnelleren Cluster-Computing-System und seinen Kernkomponenten macht. Im nächsten Teil werden wir uns eingehender mit RDDs, Transformationen und Aktionen der Spark-Kern-API befassen.