
Erstellen einer App mit Serverless Framework, AWS und BigQuery
Veröffentlicht: 2021-01-28Serverless bezieht sich auf Anwendungen, bei denen die Verwaltung und Zuweisung von Servern und Ressourcen von einem Cloud-Anbieter verwaltet werden. Das bedeutet, dass der Cloud-Anbieter die Ressourcen dynamisch zuweist. Die App wird in einem zustandslosen Container ausgeführt, der durch ein Ereignis ausgelöst werden kann. Ein solches Beispiel für das Obige, das wir in diesem Artikel verwenden werden, betrifft AWS Lambda .
Kurz gesagt können wir „Serverless Applications“ als Anwendungen bezeichnen, die ereignisgesteuerte Cloud-basierte Systeme sind. Die App ist auf Dienste von Drittanbietern, clientseitige Logik und Remoteaufrufe angewiesen (wobei sie direkt Function as a Service genannt wird).
Serverless Framework installieren und für Amazon AWS konfigurieren

1. Serverloses Framework
Das Serverless Framework ist ein Open-Source-Framework. Es besteht aus einer Befehlszeilenschnittstelle oder CLI und einem gehosteten Dashboard, das uns ein vollständig serverloses Anwendungsverwaltungssystem bietet. Die Verwendung des Frameworks sorgt für weniger Aufwand und Kosten, eine schnelle Entwicklung und Bereitstellung sowie die Sicherung der serverlosen Anwendungen.
Bevor Sie mit der Installation des Serverless-Frameworks fortfahren, müssen Sie zuerst NodeJS einrichten. Dies ist auf den meisten Betriebssystemen sehr einfach – Sie müssen nur die offizielle NodeJS-Website besuchen, um es herunterzuladen und zu installieren. Denken Sie daran, eine Version höher als 6.0.0 zu wählen.
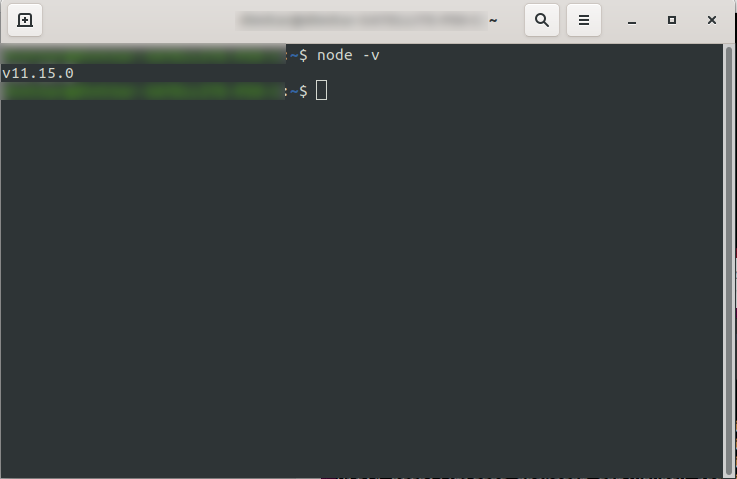
Nach der Installation können Sie bestätigen, dass NodeJS verfügbar ist, indem Sie node -v in der Konsole ausführen. Es sollte die von Ihnen installierte Knotenversion zurückgeben:
Sie können jetzt loslegen, also fahren Sie fort und installieren Sie das Serverless-Framework.
Befolgen Sie dazu die Dokumentation zum Einrichten und Konfigurieren des Frameworks. Wenn Sie möchten, können Sie es nur für ein Projekt installieren, aber bei DevriX installieren wir das Framework normalerweise global: npm install -g serverless
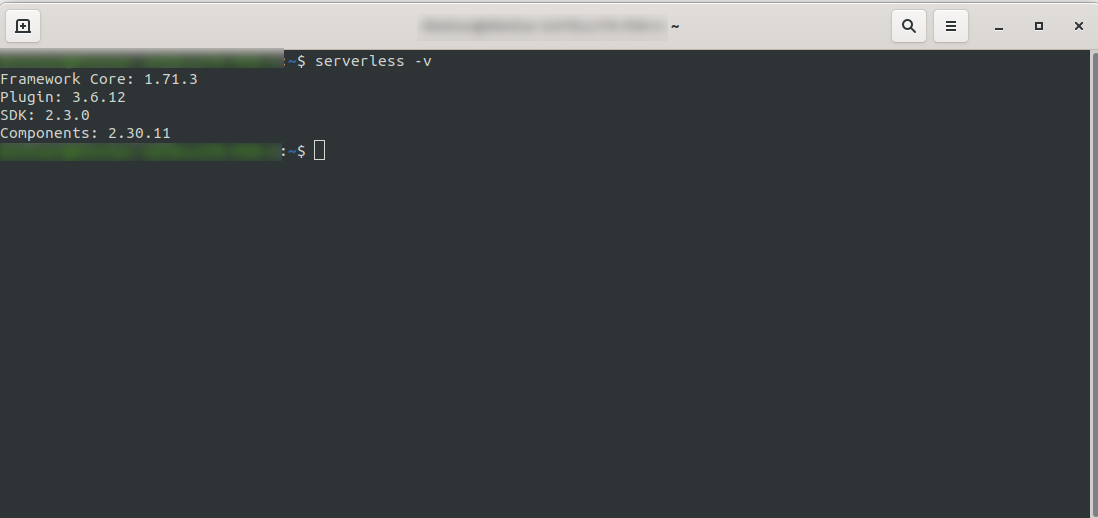
Warten Sie, bis der Vorgang abgeschlossen ist, und stellen Sie sicher, dass Serverless erfolgreich installiert wurde, indem Sie Folgendes ausführen: serverless -v
2. Erstellen Sie ein Amazon AWS-Konto
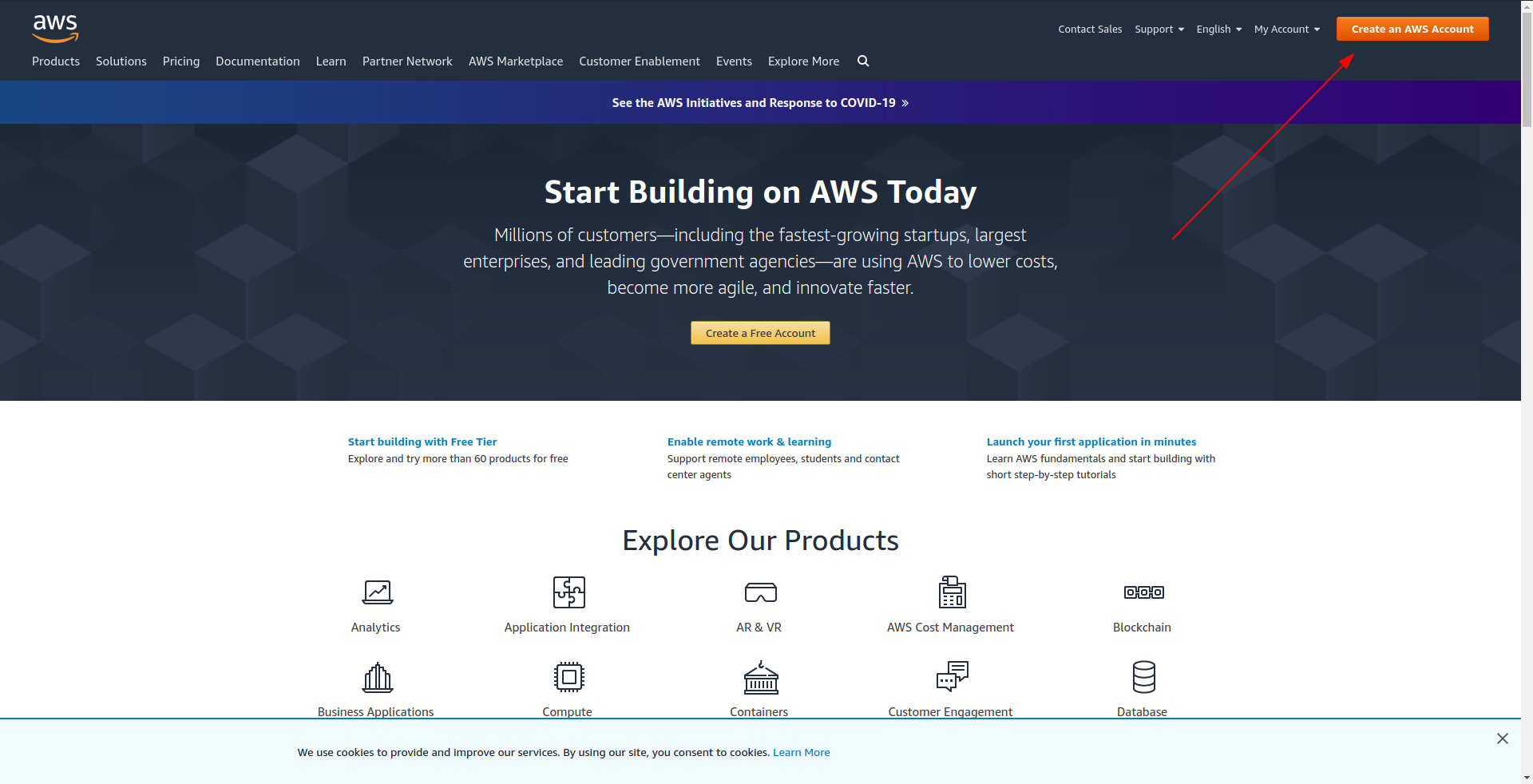
Bevor Sie mit der Erstellung Ihrer Beispielanwendung fortfahren, sollten Sie ein Konto in Amazon AWS erstellen. Wenn Sie noch keins haben, gehen Sie einfach zu Amazon AWS und klicken Sie oben rechts auf „AWS-Konto erstellen“ und befolgen Sie die Schritte zum Erstellen eines Kontos.
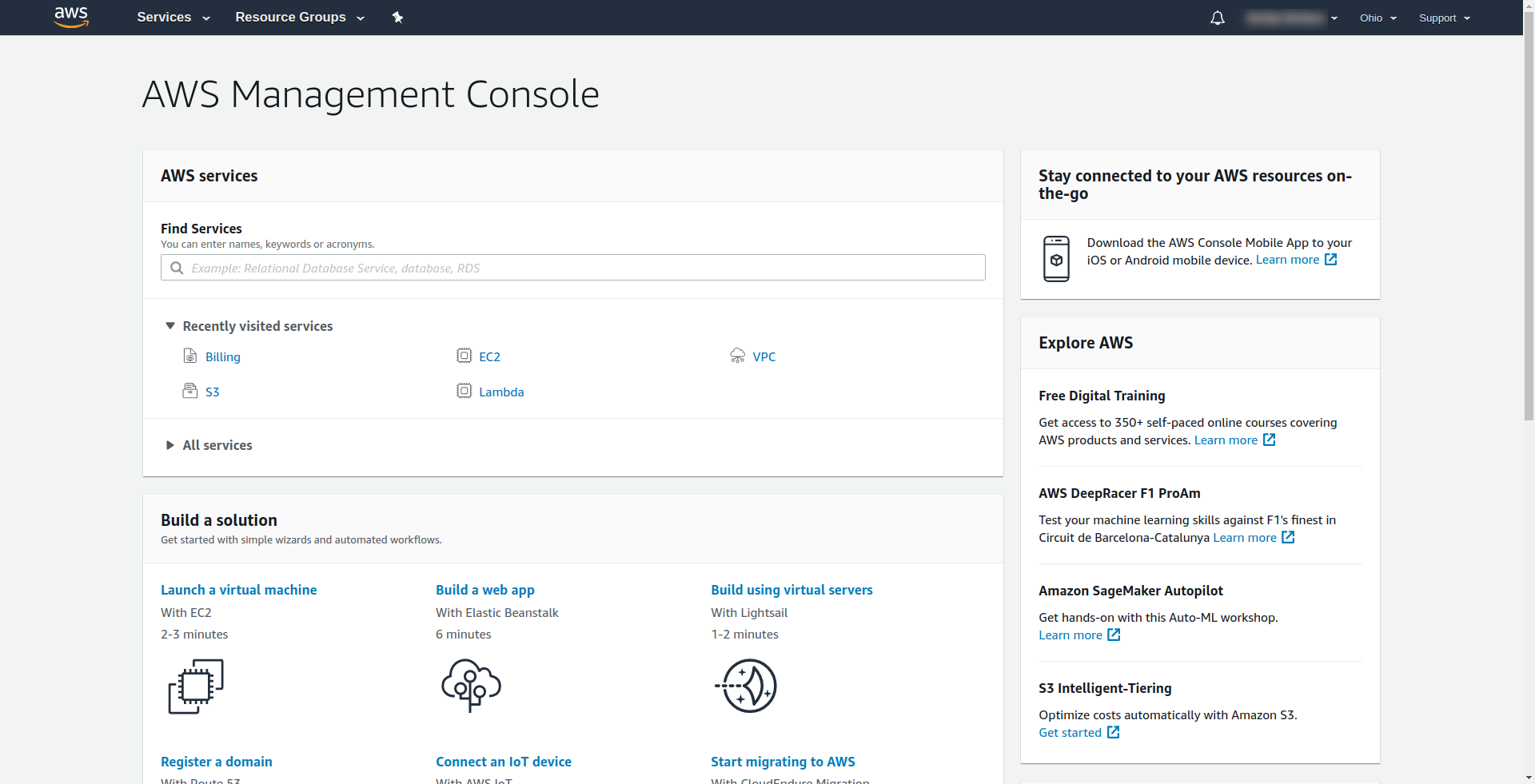
Amazon verlangt, dass Sie eine Kreditkarte eingeben, daher können Sie nicht fortfahren, ohne diese Informationen einzugeben. Nach erfolgreicher Registrierung und Anmeldung sollten Sie die AWS Management Console sehen:
Toll! Lassen Sie uns nun mit der Erstellung Ihrer Anwendung fortfahren.
3. Konfigurieren Sie das Serverless Framework mit AWS Provider und erstellen Sie eine Beispielanwendung
In diesem Schritt müssen wir das Serverless-Framework mit dem AWS-Anbieter konfigurieren. Einige Services wie AWS Lambda erfordern Anmeldeinformationen, wenn Sie darauf zugreifen, um sicherzustellen, dass Sie Berechtigungen für die Ressourcen haben, die diesem Service gehören. AWS empfiehlt die Verwendung von AWS Identity and Access Manager (IAM), um dies zu erreichen.
Das Erste und Wichtigste ist also, einen IAM - Benutzer in AWS zu erstellen, um ihn in unserer Anwendung zu verwenden:
An der AWS-Konsole:
- Geben Sie IAM in das Feld „Dienste suchen“ ein.
- Klicken Sie auf „IAM“ .
- Gehen Sie zu „Benutzer“ .
- Klicken Sie auf „Benutzer hinzufügen“ .
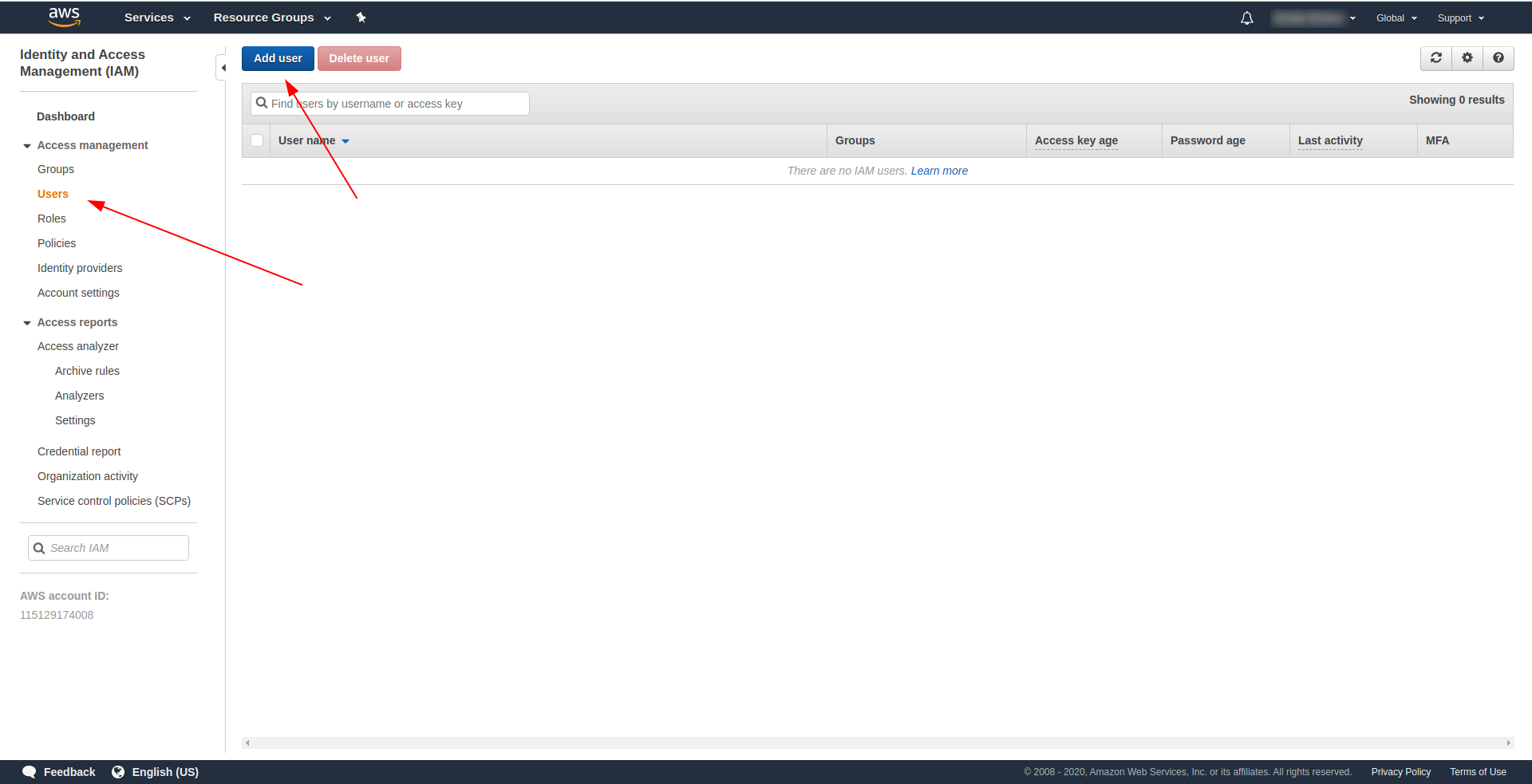
Verwenden Sie für "Benutzername" was Sie wollen. Zum Beispiel verwenden wir serverless-admin. Aktivieren Sie für „ Zugriffstyp“ „Programmatischer Zugriff“ und klicken Sie auf „Weitere Berechtigungen “.
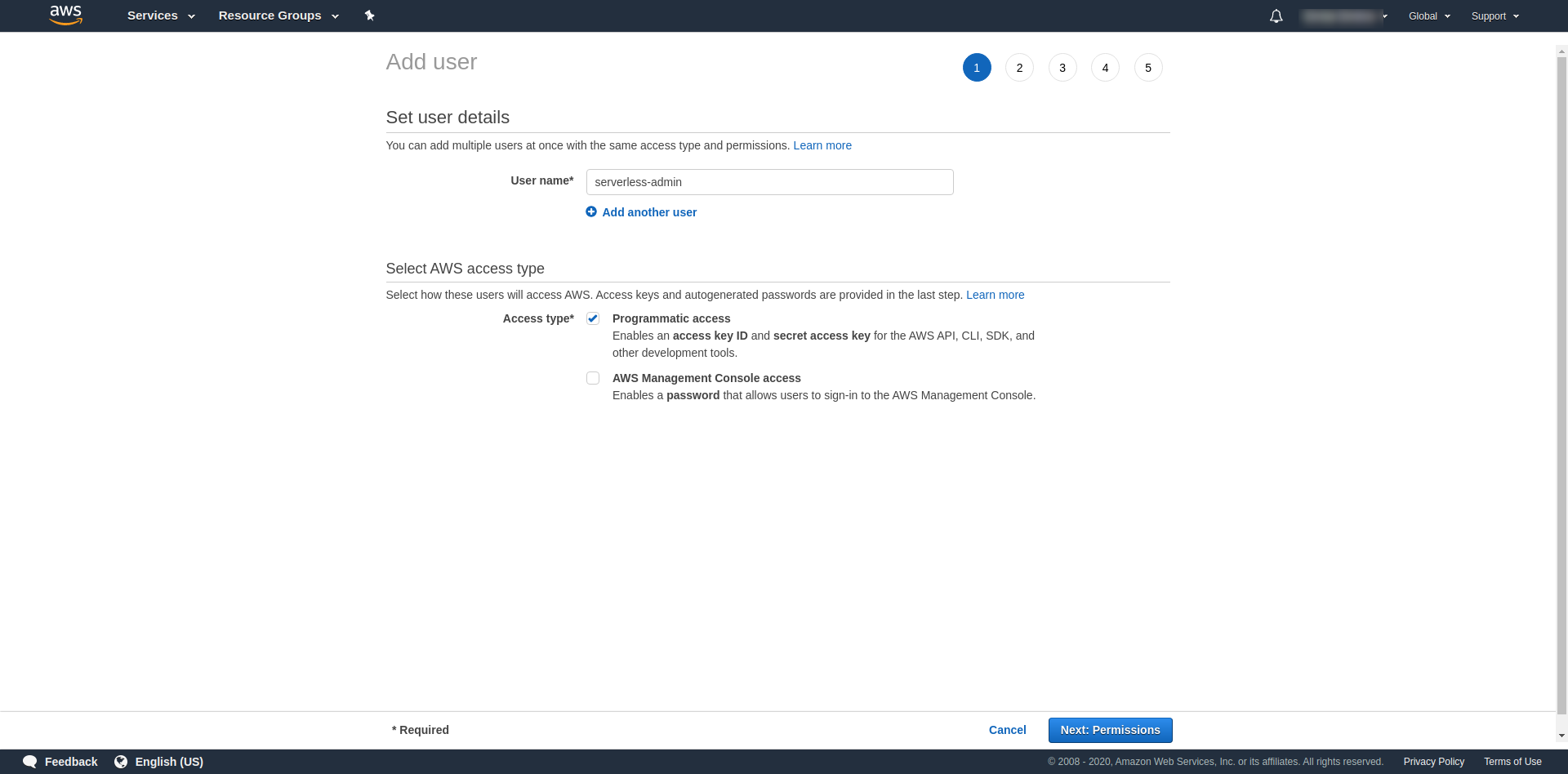
Danach müssen wir Berechtigungen für den Benutzer anhängen, auf „Vorhandene Richtlinien direkt anhängen“ klicken, nach „Administratorzugriff “ suchen und darauf klicken. Fahren Sie fort, indem Sie auf „Nächste Tags“ klicken.
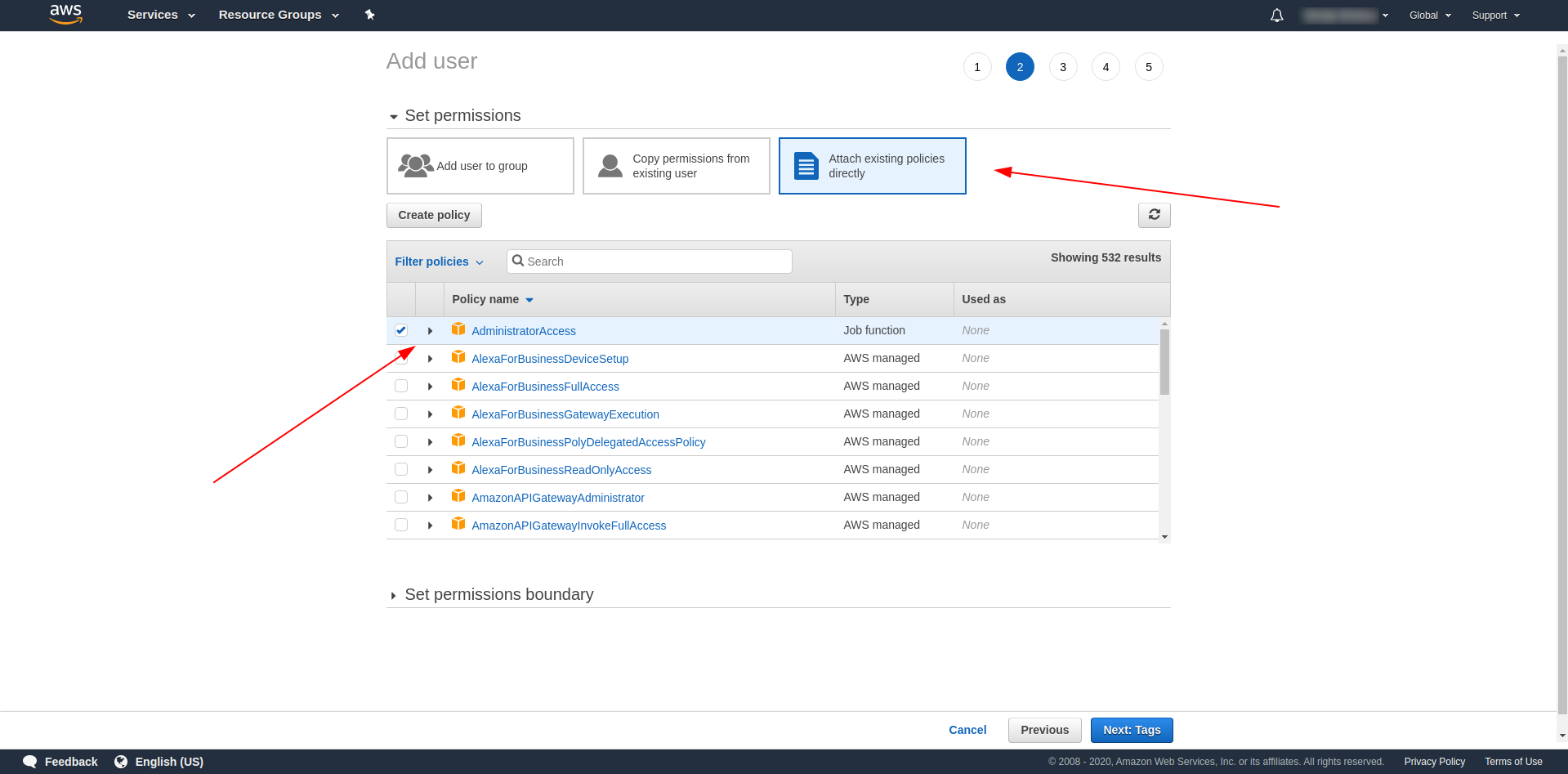
Tags sind optional, Sie können also fortfahren, indem Sie auf „Nächste Bewertung“ und „Benutzer erstellen“ klicken. Sobald dies erledigt und geladen ist, wird auf der Seite eine Erfolgsmeldung mit den erforderlichen Anmeldeinformationen angezeigt.
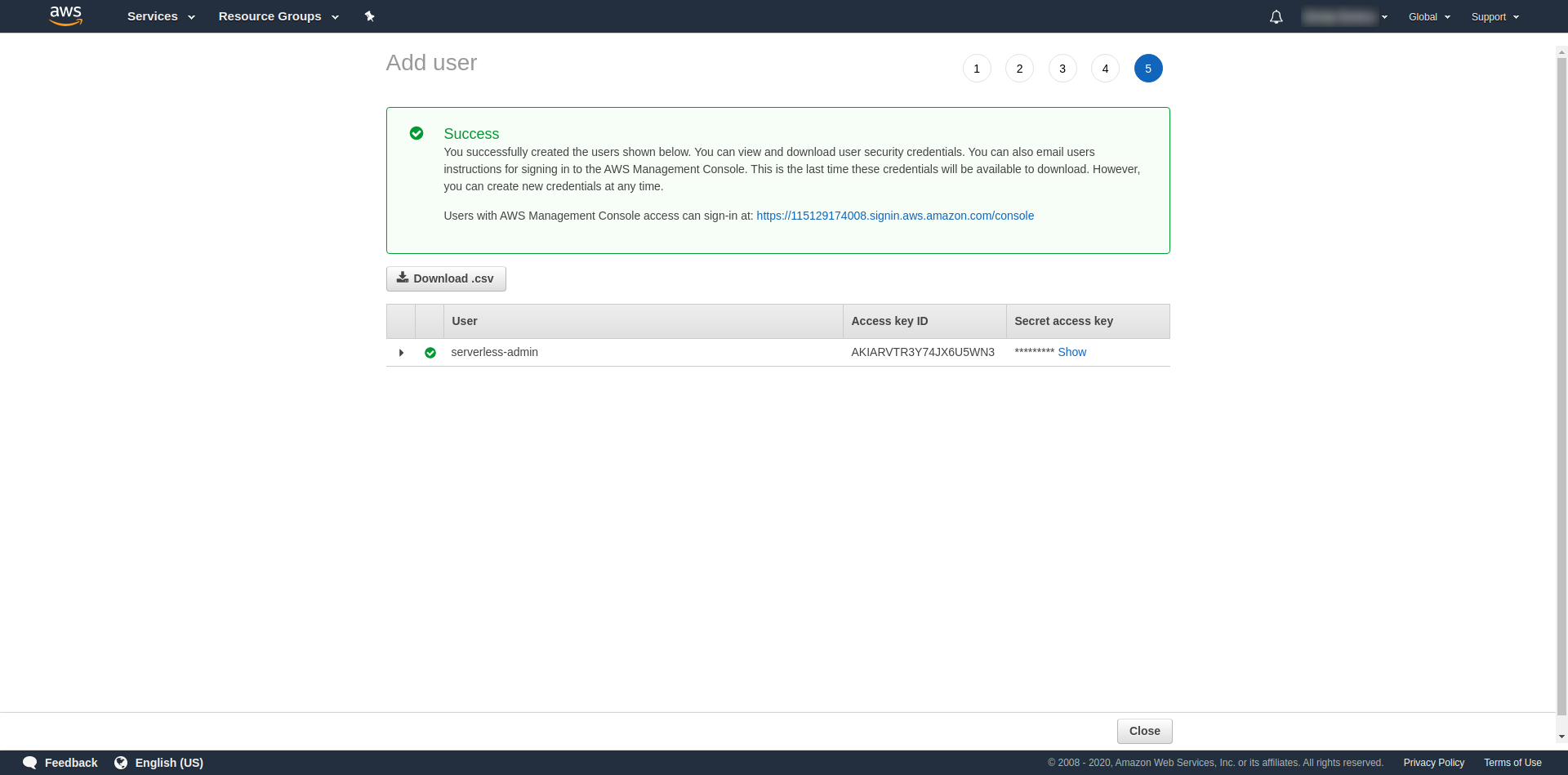
Jetzt müssen wir den folgenden Befehl ausführen:
serverless config credentials --provider aws --key key --secret secret --profile serverless-admin
Ersetzen Sie Schlüssel und Geheimnis durch die oben angegebenen. Ihre AWS-Anmeldeinformationen werden als Profil erstellt. Sie können dies überprüfen, indem Sie die Datei ~/.aws/credentials öffnen . Es sollte aus AWS-Profilen bestehen. Derzeit ist es im folgenden Beispiel nur einer – der, den wir erstellt haben:
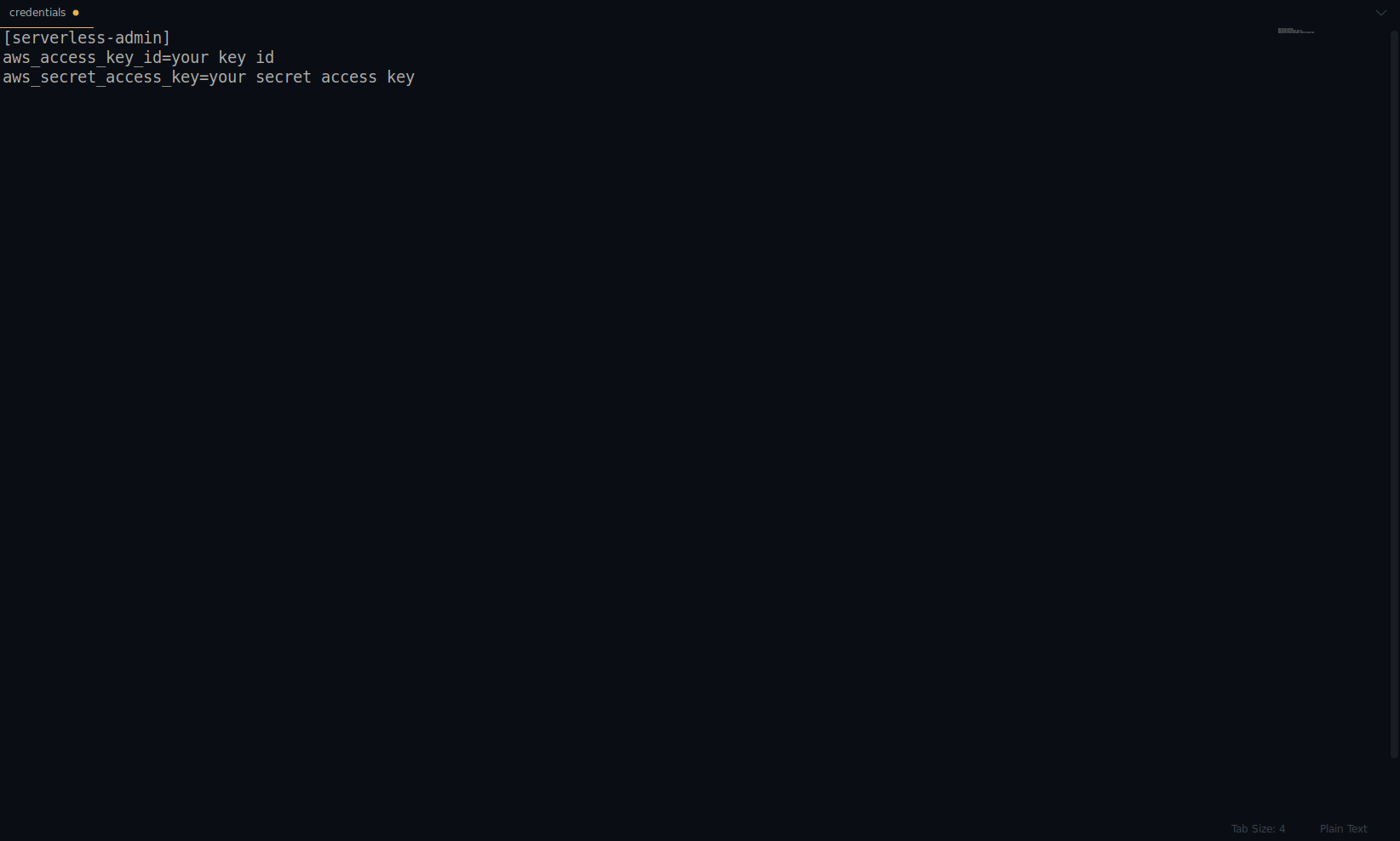
Tolle Arbeit bisher! Sie können fortfahren, indem Sie eine Beispielanwendung mit NodeJS und den integrierten Startvorlagen erstellen.
Hinweis: Darüber hinaus verwenden wir in dem Artikel den Befehl sls , der die Abkürzung für serverless ist.
Erstellen Sie ein leeres Verzeichnis und geben Sie es ein. Führen Sie den Befehl aus
ls create --template aws-nodejs
Geben Sie mit dem Befehl create –template eine der verfügbaren Vorlagen an, in diesem Fall aws-nodejs, bei der es sich um eine NodeJS „Hello world“-Vorlagenanwendung handelt.
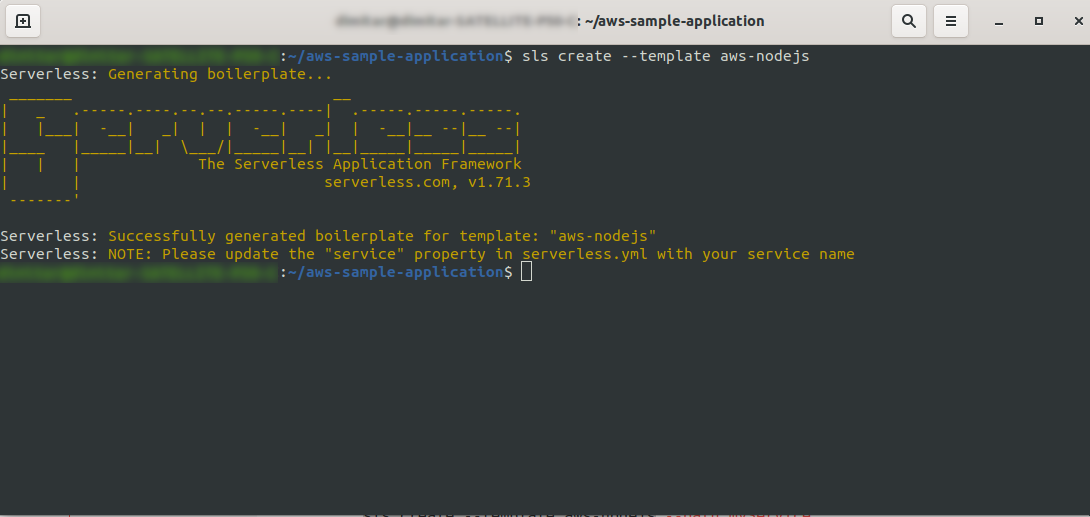
Sobald Sie fertig sind, sollte Ihr Verzeichnis aus Folgendem bestehen und so aussehen:
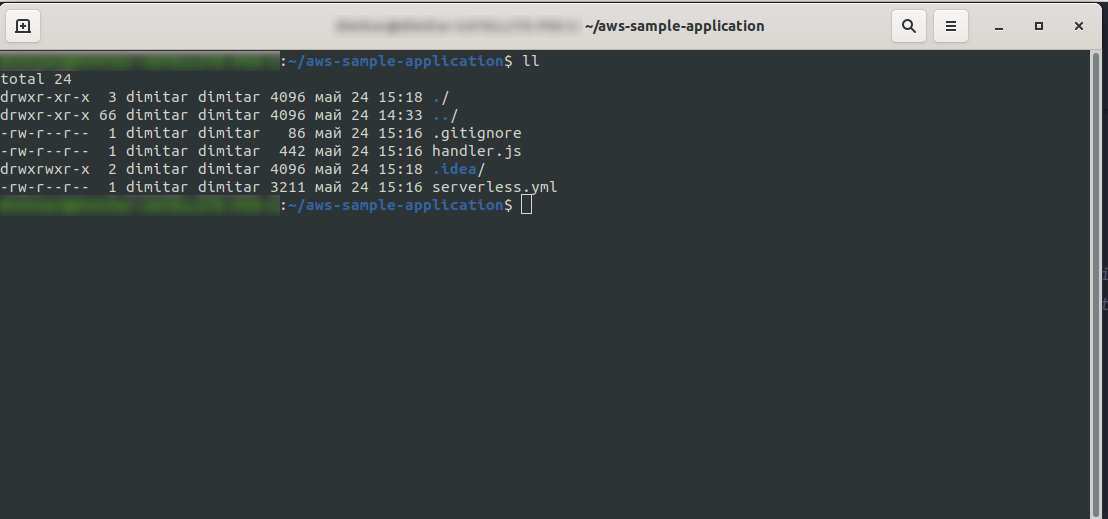
Wir haben die neuen Dateien handler.js und serverless.yml erstellt.
Die Datei handler.js speichert Ihre Funktion(en) und serverless.yml speichert die Konfigurationseigenschaften, die Sie später ändern werden. Wenn Sie sich fragen, was die .yml -Datei ist, kurz gesagt, es ist eine menschenlesbare Datenserialisierungssprache . Es ist gut, damit vertraut zu sein, da es beim Einfügen von Konfigurationsparametern verwendet wird. Aber werfen wir einen Blick darauf, was wir jetzt in der serverless.yml -Datei haben:
service: aws-beispielapplikation
Anbieter:
Name: aws
Laufzeit: nodejs12.x
Funktionen:
Hallo:
Handler: Handler.Hallo
- service: – Unser Servicename.
- Anbieter: – Ein Objekt, das Anbietereigenschaften enthält, und wie wir hier sehen, ist unser Anbieter AWS, und wir verwenden die NodeJS-Laufzeit.
- Funktionen: – Es ist ein Objekt, das alle Funktionen enthält, die für Lambda bereitgestellt werden können. In diesem Beispiel haben wir nur eine Funktion namens hello , die auf die hallo-Funktion von handler.j verweist.
Sie müssen hier eine entscheidende Sache tun, bevor Sie mit der Bereitstellung der Anwendung fortfahren. Zuvor haben wir die Anmeldeinformationen für AWS mit einem Profil festgelegt (wir nannten es serverless-admin ). Jetzt müssen Sie der serverlosen Konfiguration nur noch mitteilen, dass sie dieses Profil und Ihre Region verwenden soll. Öffnen Sie serverless.yml und geben Sie unter der Eigenschaft provider rechts unterhalb der Laufzeit Folgendes ein:
Profil: Serverless-Admin region: us-ost-2
Am Ende sollten wir das haben:
Anbieter: Name: aws Laufzeit: nodejs12.x Profil: Serverless-Admin region: us-ost-2
Hinweis: Um die Region abzurufen, können Sie einfach nach der URL suchen, wenn Sie sich bei der Konsole angemeldet haben: Beispiel:
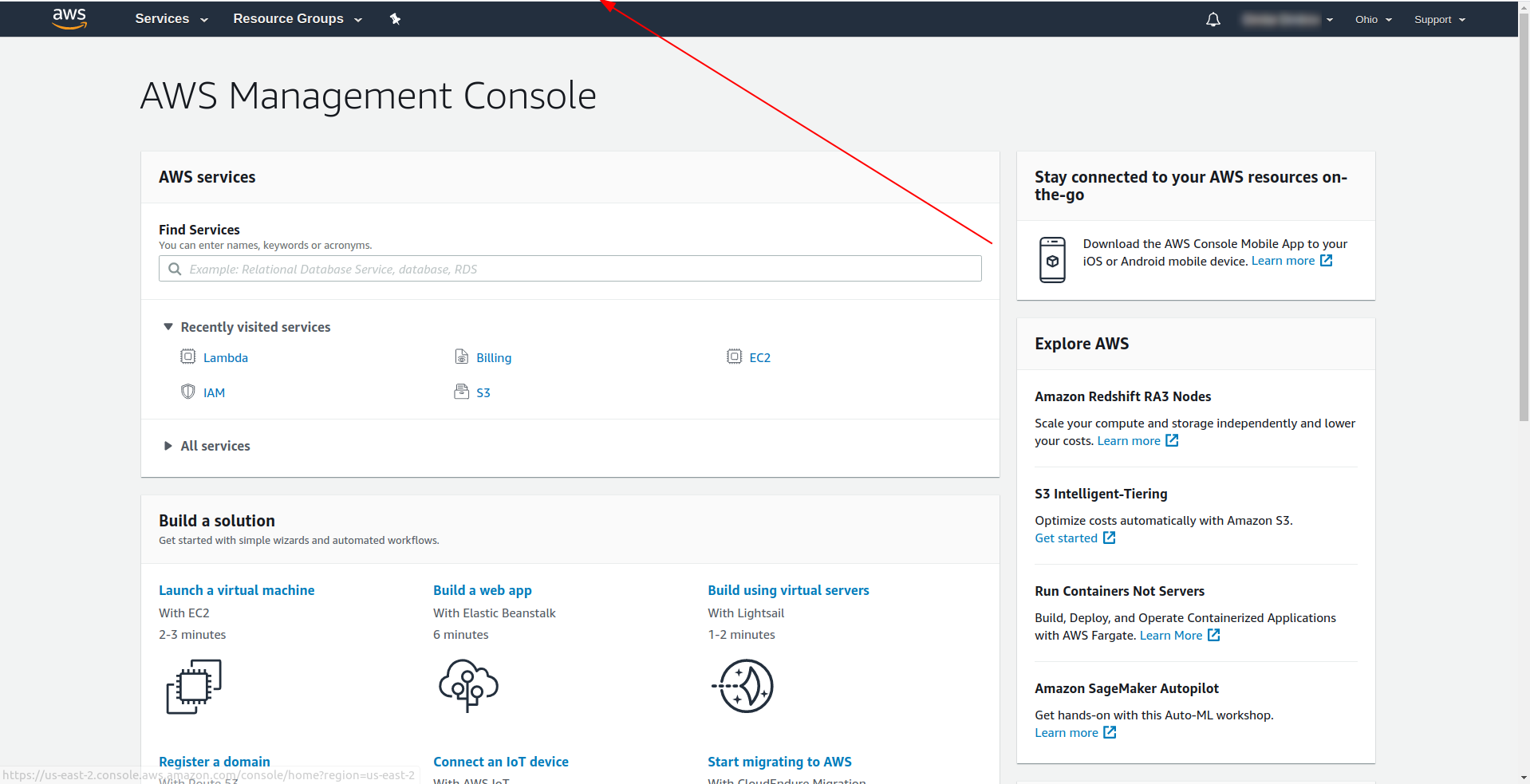
Jetzt haben wir die notwendigen Informationen über unsere generierte Vorlage. Sehen wir uns an, wie wir die Funktion lokal aufrufen und in AWS Lambda bereitstellen können.
Wir können die Anwendung sofort testen, indem wir die Funktion lokal aufrufen:
sls invoke local -f hello
Es ruft die Funktion auf (aber nur lokal!) und gibt die Ausgabe an die Konsole zurück:
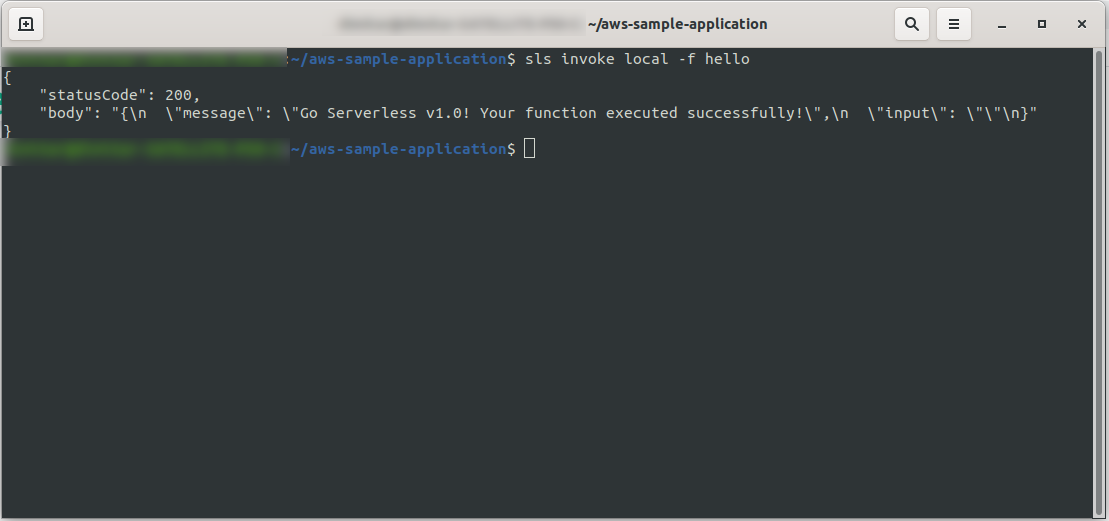
Wenn nun alles in Ordnung war, können Sie versuchen, Ihre Funktion für AWS Lambda bereitzustellen .
Also war das kompliziert? Nein, war es nicht! Dank des Serverless Frameworks ist es nur ein einzeiliger Code:
sls deploy -v
Warten Sie, bis alles fertig ist, es kann ein paar Minuten dauern, wenn alles in Ordnung ist, sollten Sie mit so etwas enden:
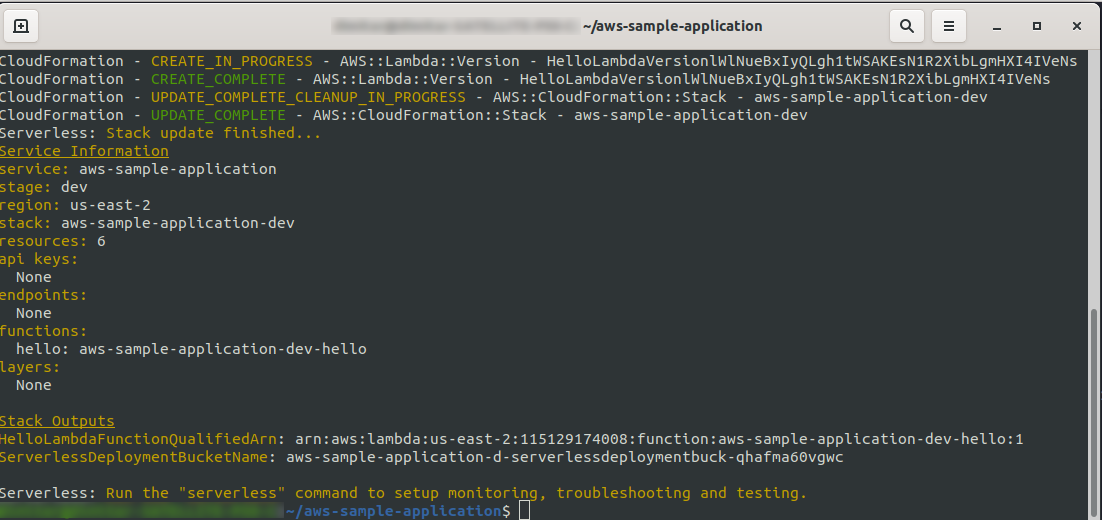
Lassen Sie uns nun überprüfen, was in AWS passiert ist. Gehen Sie zu Lambda (in „ Find Services “ geben Sie Lambda ein), und Sie sollten sehen, dass Ihre Lambda -Funktion erstellt wurde.
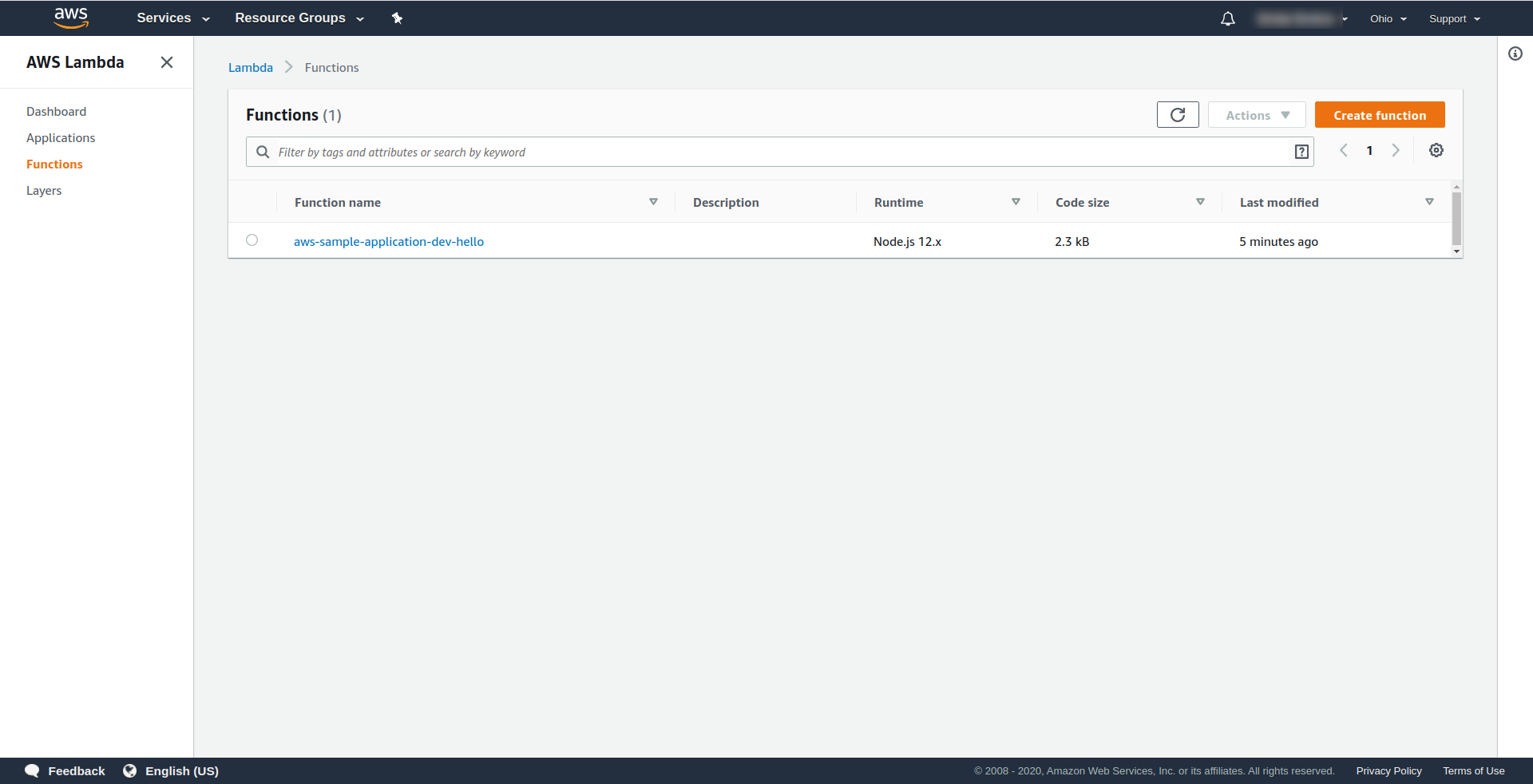
Jetzt können Sie versuchen, Ihre Funktion von AWS Lambda aus aufzurufen. Im Terminaltyp
sls invoke -f hello
Es sollte dieselbe Ausgabe wie zuvor zurückgeben (wenn wir lokal testen):
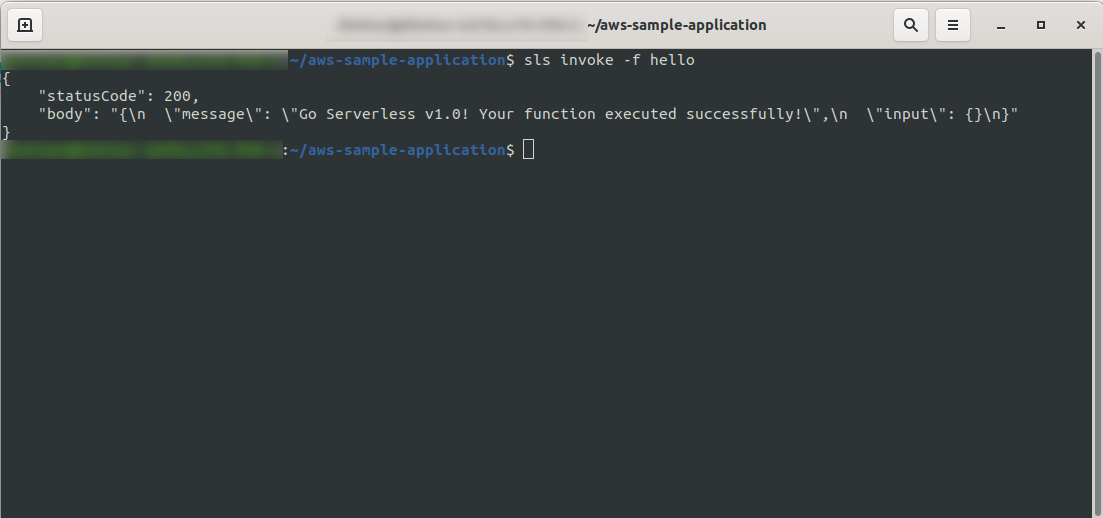
Sie können überprüfen, ob Sie die AWS-Funktion ausgelöst haben, indem Sie die Funktion in AWS Lambda öffnen und zur Registerkarte „ Überwachung “ gehen und auf „ Protokolle in CloudWatch anzeigen“ klicken. “.
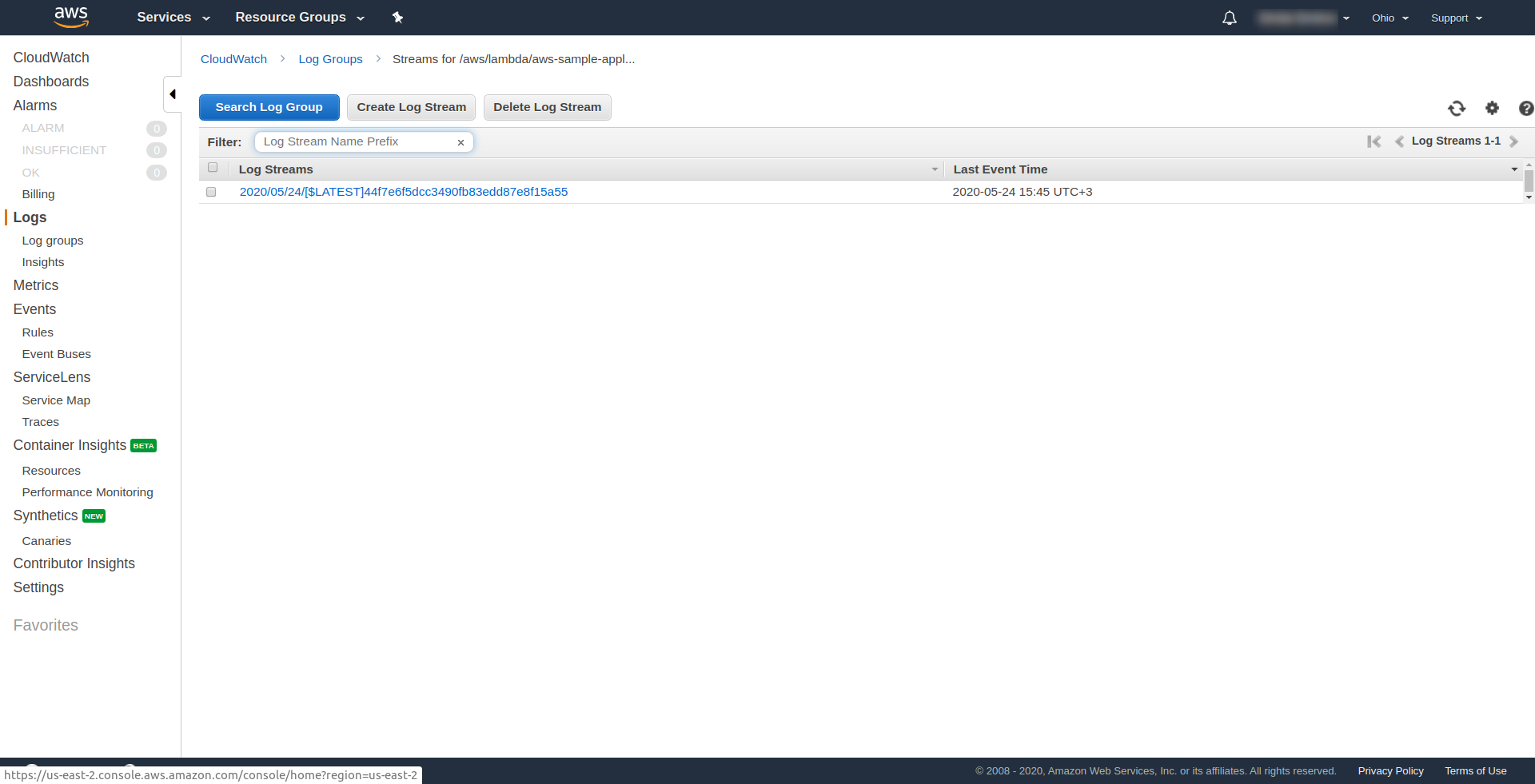
Sie sollten dort ein Protokoll haben.
Nun, eine Sache fehlt noch in Ihrer Bewerbung, aber was ist das …? Nun, Sie haben keinen Endpunkt, auf den Sie für Ihre App zugreifen können, also erstellen wir diesen mit AWS API Gateway.
Sie müssen zuerst die serverless.yml -Datei öffnen und die Kommentare löschen. Sie müssen unserer Funktion und unter ihrer http -Eigenschaft eine events -Eigenschaft hinzufügen. Dadurch wird das Serverless-Framework angewiesen , ein API-Gateway zu erstellen und es bei der Bereitstellung der App an unsere Lambda-Funktion anzuhängen. Unsere Konfigurationsdatei sollte folgendermaßen enden:
service: aws-beispielapplikation
Anbieter:
Name: aws
Laufzeit: nodejs12.x
Profil: Serverless-Admin
region: us-ost-2
Funktionen:
Hallo:
Handler: Handler.Hallo
Veranstaltungen:
- http:
Pfad: /Hallo
Methode: erhalten
In http geben wir den Pfad und die HTTP-Methode an.
Stellen wir unsere App erneut bereit, indem sls deploy -v
Sobald es fertig ist, sollte eine neue Sache im Ausgabeterminal erscheinen, und das ist der Endpunkt, der erstellt wurde:
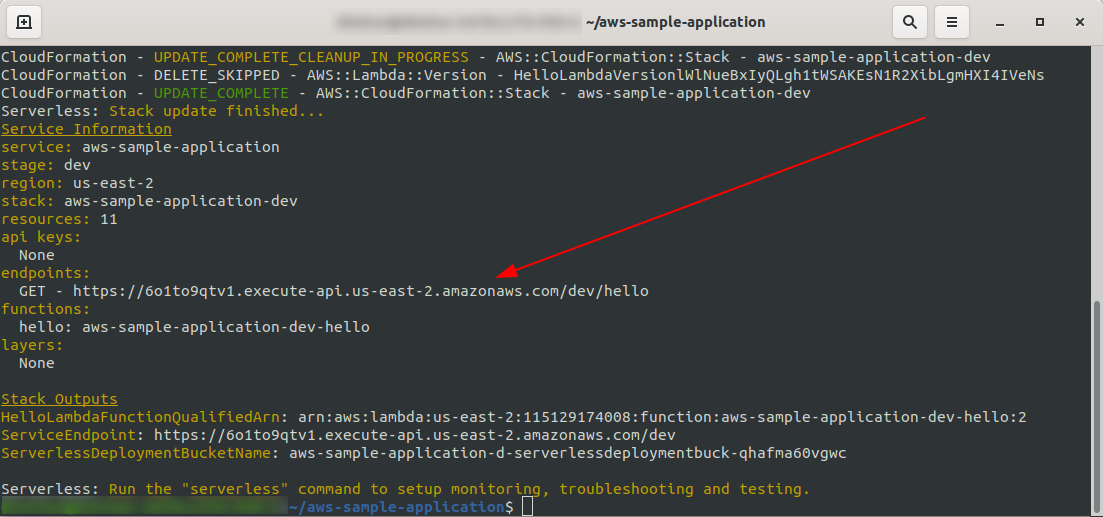
Öffnen wir den Endpunkt:
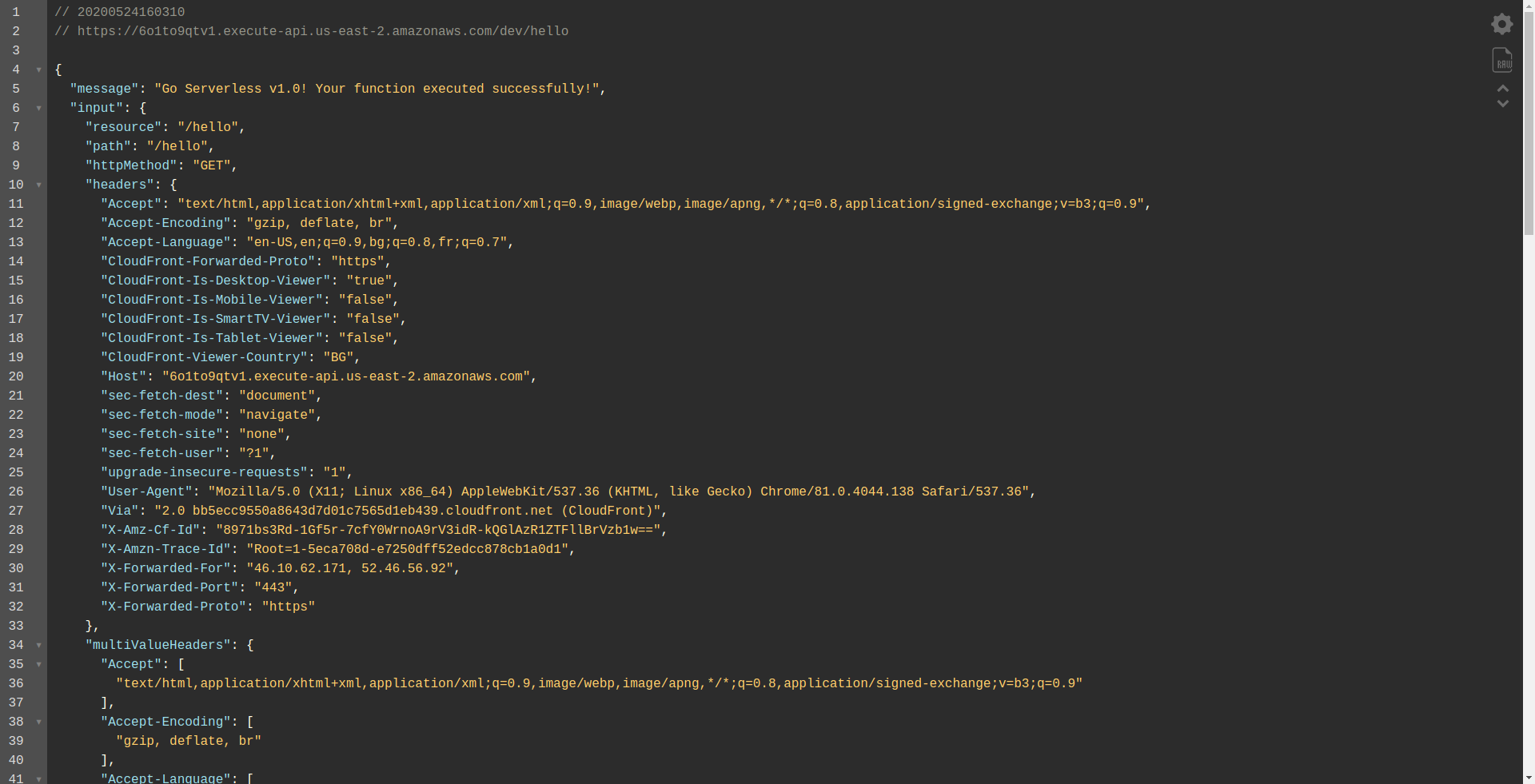
Sie sollten sehen, dass Ihre Funktion ausgeführt wird, eine Ausgabe und einige Informationen über die Anforderung zurückgibt. Sehen wir uns an, was sich in unserer Lambda-Funktion ändert.
Öffnen Sie AWS Lambda und klicken Sie auf Ihre Funktion.
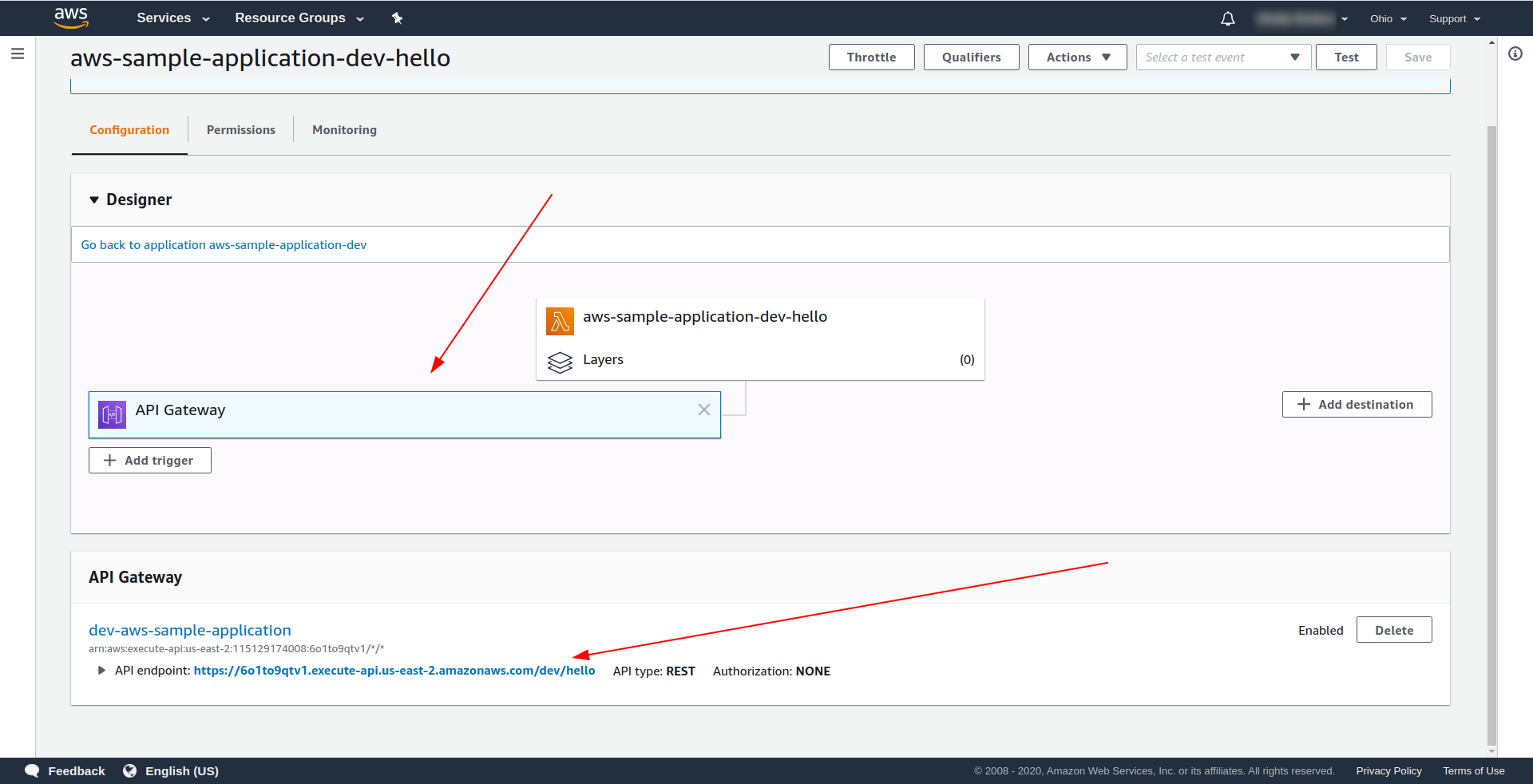
Wir sehen auf der Registerkarte „ Designer “, dass wir API Gateway an unser Lambda und den API-Endpunkt angehängt haben.
Toll! Sie haben eine supereinfache serverlose Anwendung erstellt, sie in AWS Lambda bereitgestellt und ihre Funktionalität getestet. Außerdem haben wir einen Endpunkt mit dem AWS API Gateway hinzugefügt.
4. So führen Sie die Anwendung offline aus
Bisher wissen wir, dass wir Funktionen lokal aufrufen können, aber wir können unsere gesamte Anwendung auch offline mit dem Serverless-Offline-Plugin ausführen.
Das Plugin emuliert AWS Lambda und API Gateway auf Ihrem lokalen/Entwicklungscomputer. Es startet einen HTTP-Server, der die Anforderungen verarbeitet und Ihre Handler aufruft.
Um das Plugin zu installieren, führen Sie den folgenden Befehl im App-Verzeichnis aus
npm install serverless-offline --save-dev
Öffnen Sie dann in der serverless.yml des Projekts die Datei und fügen Sie die Eigenschaft plugins hinzu:
Plugins: - Serverlos-offline
Die Konfig sollte so aussehen:
service: aws-beispielapplikation
Anbieter:
Name: aws
Laufzeit: nodejs12.x
Profil: Serverless-Admin
region: us-ost-2
Funktionen:
Hallo:
Handler: Handler.Hallo
Veranstaltungen:
- http:
Pfad: /Hallo
Methode: erhalten
Plugins:
- Serverlos-offline
Um zu überprüfen, ob wir das Plugin erfolgreich installiert und konfiguriert haben, führen Sie es aus
sls --verbose
Sie sollten dies sehen:
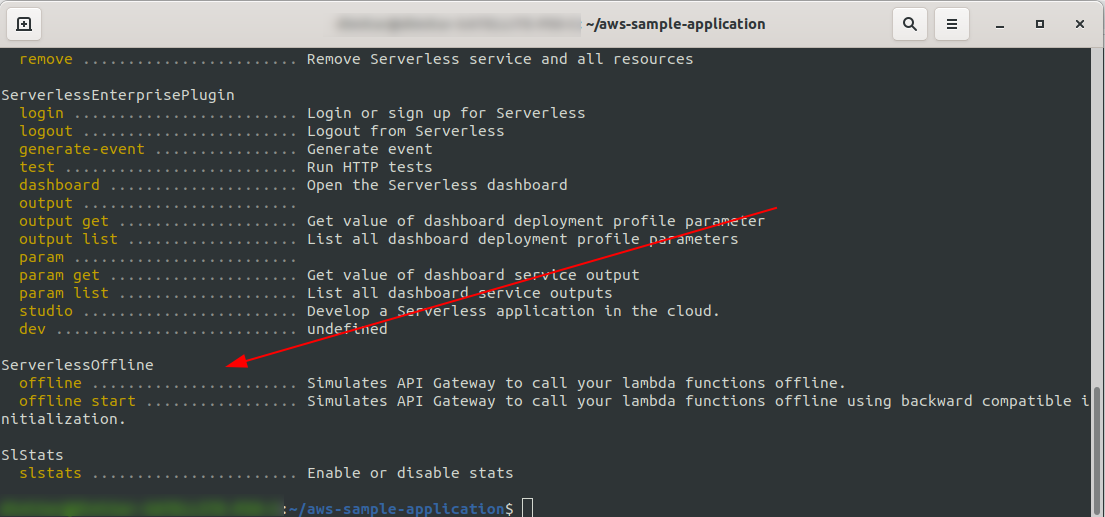
Führen Sie nun im Stammverzeichnis Ihres Projekts den Befehl aus
sls offline
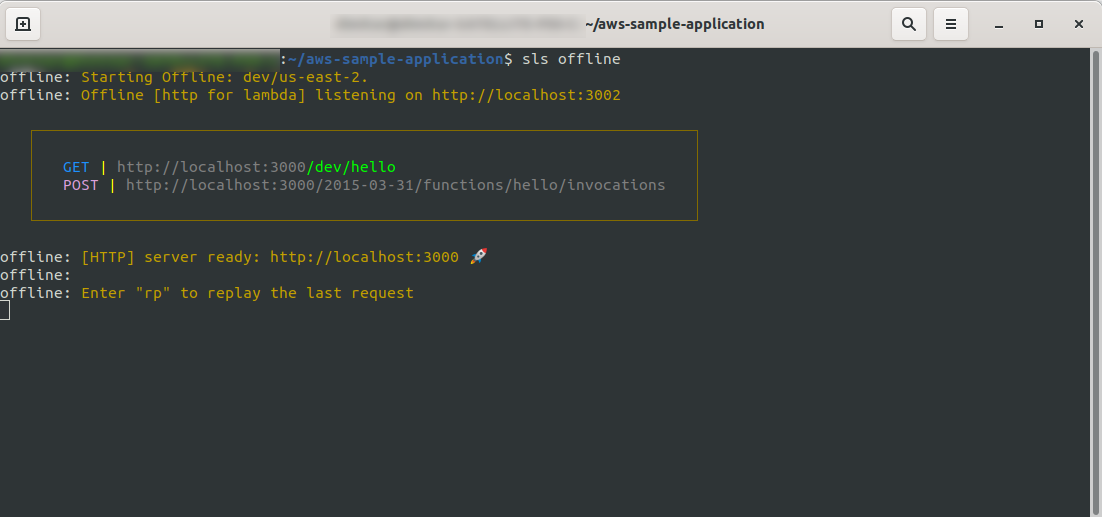
Wie Sie sehen können, lauscht ein HTTP -Server auf Port 3000, und Sie können auf Ihre Funktionen zugreifen, hier haben wir beispielsweise http://localhost:3000/dev/hello für unsere Hallo-Funktion. Wenn wir das öffnen, haben wir die gleiche Antwort wie vom API Gateway , das wir zuvor erstellt haben.
Fügen Sie die Google BigQuery-Integration hinzu

Ihr habt bisher einen tollen Job gemacht! Sie haben eine voll funktionsfähige Anwendung mit Serverless. Lassen Sie uns unsere App erweitern und ihr die BigQuery- Integration hinzufügen, um zu sehen, wie sie funktioniert und wie die Integration erfolgt.
BigQuery ist eine serverlose Software as a Service (SaaS), also ein kostengünstiges und schnelles Data Warehouse, das Abfragen unterstützt. Bevor wir mit der Integration in unsere NodeJS-App fortfahren, müssen wir ein Konto erstellen, also machen wir weiter.

1. Richten Sie die Google Cloud Console ein
Gehen Sie zu https://cloud.google.com und melden Sie sich mit Ihrem Konto an, falls Sie dies noch nicht getan haben – erstellen Sie ein Konto und fahren Sie fort.
Wenn Sie sich bei Google Cloud Console anmelden, müssen Sie ein neues Projekt erstellen. Klicken Sie auf die drei Punkte neben dem Logo und es öffnet sich ein modales Fenster, in dem Sie „ Neues Projekt“ auswählen. ”
Geben Sie einen Namen für Ihr Projekt ein. Wir werden bigquery-example verwenden. Nachdem Sie das Projekt erstellt haben, navigieren Sie mithilfe der Schublade zu BigQuery :
Wenn BigQuery geladen wird, sehen Sie auf der linken Seite die Daten des Projekts, auf die Sie Zugriff haben, sowie die öffentlichen Datasets. Wir verwenden für dieses Beispiel einen öffentlichen Datensatz. Es heißt covid19_ecdc :
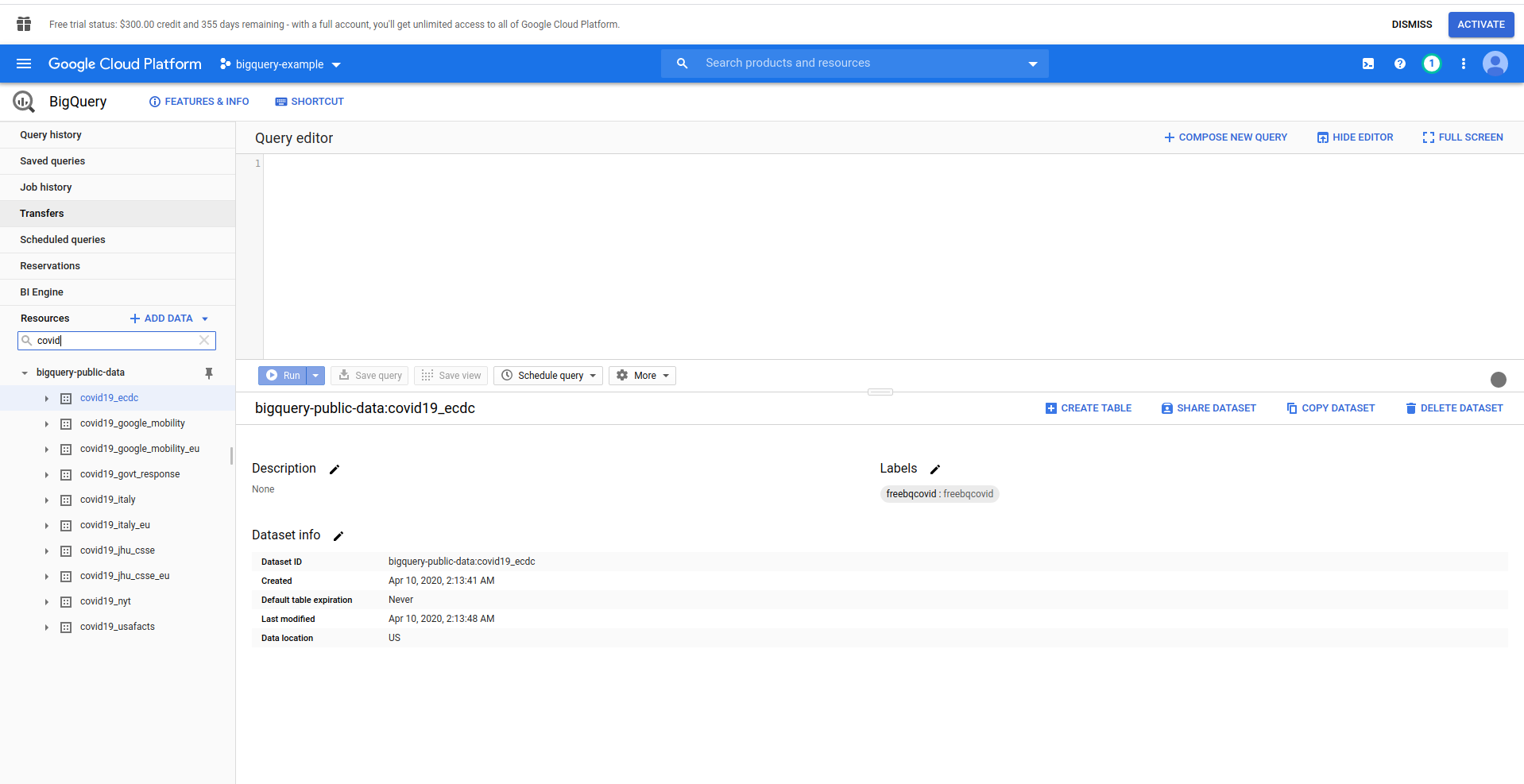
Spielen Sie mit dem Datensatz und den verfügbaren Tabellen herum. Vorschau der darin enthaltenen Daten. Das ist ein öffentlicher Datensatz, der stündlich aktualisiert wird und Informationen über weltweite COVID-19- Daten enthält.
Wir müssen einen IAM-Benutzer -> Dienstkonto erstellen, um auf die Daten zugreifen zu können. Klicken Sie also im Menü auf „IAM & Verwaltung“ und dann auf „Dienstkonten“.
Klicken Sie auf die Schaltfläche „Dienstkonto erstellen“ , geben Sie den Namen des Dienstkontos ein und klicken Sie auf „Erstellen“. Gehen Sie als Nächstes zu „Dienstkontoberechtigungen “ , suchen Sie nach „BigQuery-Administrator“ und wählen Sie es aus.
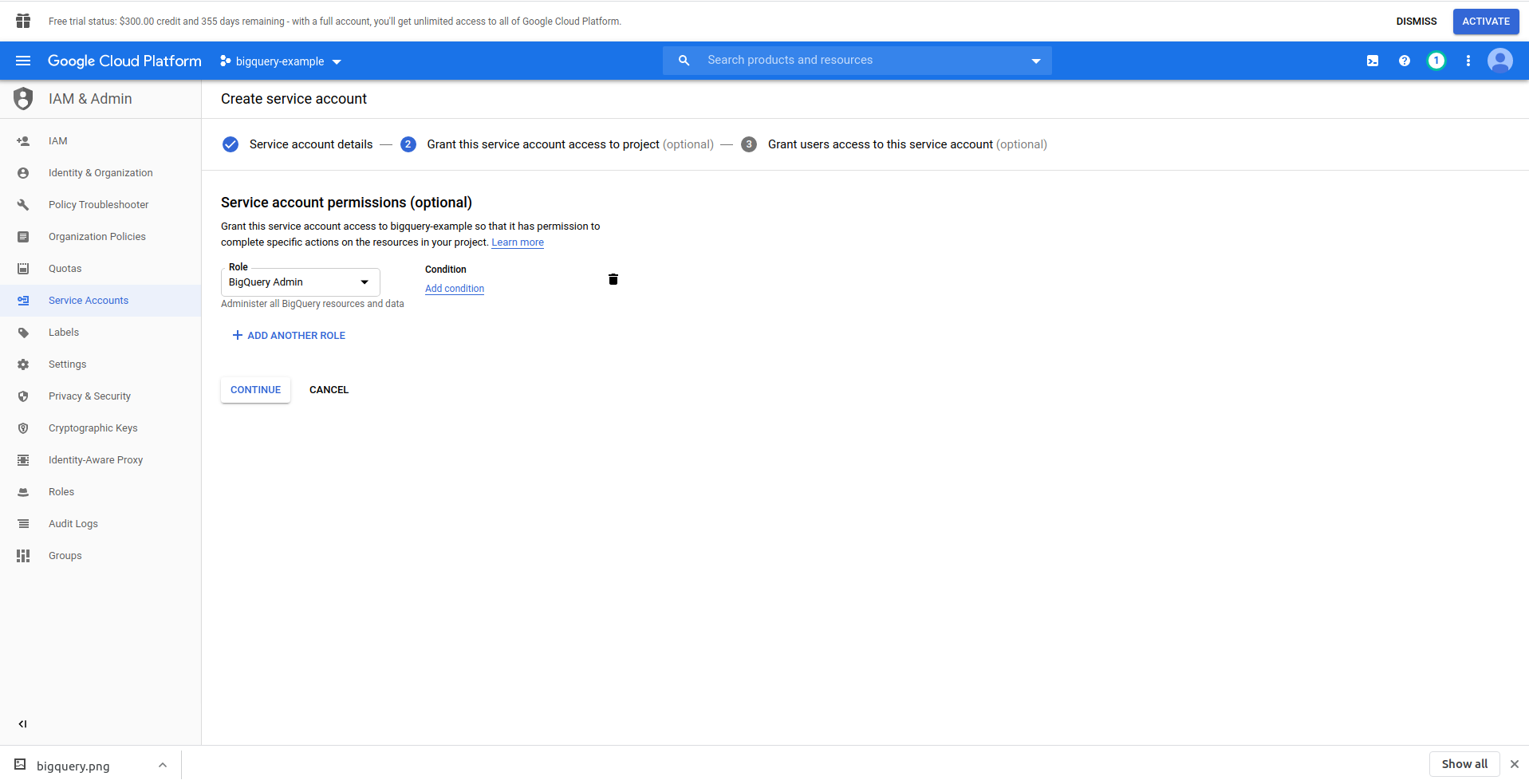
Klicken Sie auf „ Weiter “, dies ist der letzte Schritt, hier benötigen Sie Ihre Schlüssel, also klicken Sie auf die Erstellungsschaltfläche unter „ Schlüssel “ und exportieren Sie sie als JSON . Bewahren Sie diese an einem sicheren Ort auf, wir brauchen sie später. Klicken Sie auf Fertig , um die Erstellung des Dienstkontos abzuschließen.
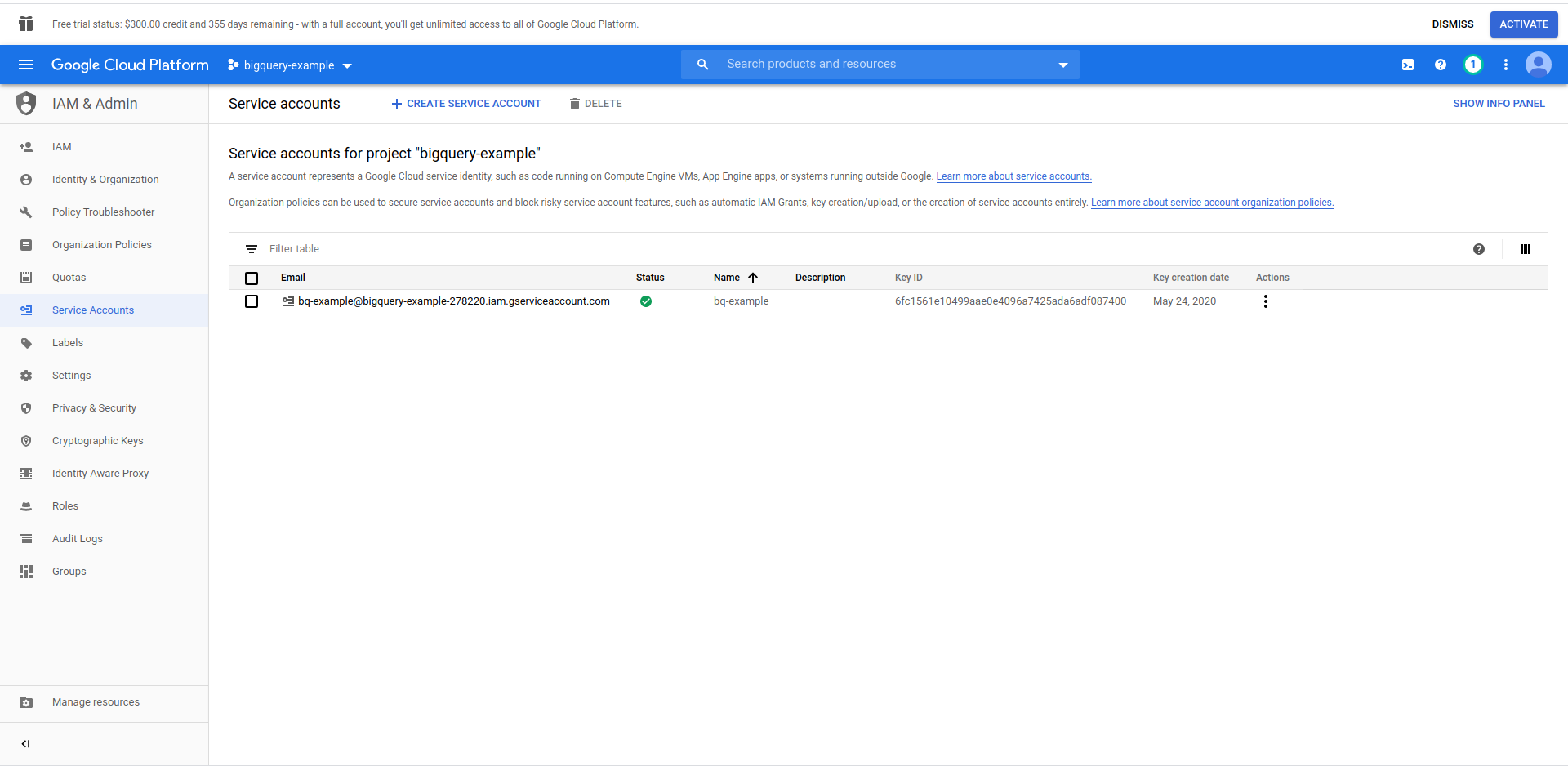
Jetzt verwenden wir die hier generierten Anmeldeinformationen, um die NodeJS BigQuery-Bibliothek zu verbinden.
2. Installieren Sie die NodeJS BigQuery-Bibliothek
Sie müssen die BigQuery NodeJS-Bibliothek installieren, um sie in dem gerade erstellten Projekt zu verwenden. Führen Sie die folgenden Befehle im App-Verzeichnis aus:
Initialisieren Sie zunächst npm, indem Sie npm init
Füllen Sie alle Fragen aus und fahren Sie mit der Installation der BigQuery- Bibliothek fort:
npm install @google-cloud/bigquery
Bevor wir unseren Funktionshandler weiter ändern, müssen wir den privaten Schlüssel aus der zuvor erstellten JSON-Datei mitnehmen. Wir werden dazu serverlose Umgebungsvariablen verwenden. Weitere Informationen erhalten Sie hier.
Öffnen Sie serverless.yml und fügen Sie in der Anbietereigenschaft die Umgebungseigenschaft wie folgt hinzu:
Umgebung:
PROJECT_ID: ${file(./config/bigquery-config.json):project_id}
CLIENT_EMAIL: ${file(./config/bigquery-config.json):client_email}
PRIVATE_KEY: ${file(./config/bigquery-config.json):private_key}
Erstellen Sie die Umgebungsvariablen PROJECT_ID, PRIVATE_KEY und CLIENT_EMAIL , die dieselben Eigenschaften (Kleinbuchstaben) aus der von uns generierten JSON-Datei übernehmen. Wir haben es im Ordner config abgelegt und es bigquery-config.json genannt .
Im Moment sollte die serverless.yml-Datei so aussehen:
service: aws-beispielapplikation
Anbieter:
Name: aws
Laufzeit: nodejs12.x
Profil: Serverless-Admin
region: us-ost-2
Umgebung:
PROJECT_ID: ${file(./config/bigquery-config.json):project_id}
CLIENT_EMAIL: ${file(./config/bigquery-config.json):client_email}
PRIVATE_KEY: ${file(./config/bigquery-config.json):private_key}
Funktionen:
Hallo:
Handler: Handler.Hallo
Veranstaltungen:
- http:
Pfad: /Hallo
Methode: erhalten
Plugins:
- Serverlos-offline
Öffnen Sie nun handler.js und lassen Sie die BigQuery-Bibliothek importieren. Fügen Sie oben in der Datei unter „use strict“ die folgende Zeile hinzu:
const {BigQuery} = require('@google-cloud/bigquery');
Jetzt müssen wir der BigQuery-Bibliothek die Anmeldedaten mitteilen. Erstellen Sie zu diesem Zweck eine neue Konstante, die BigQuery mit den Anmeldeinformationen instanziiert:
const bigQueryClient = new BigQuery({
Projekt-ID: process.env.PROJECT_ID,
Referenzen: {
client_email: process.env.CLIENT_EMAIL,
private_key: process.env.PRIVATE_KEY
}
});
Als Nächstes erstellen wir unsere BigQuery-SQL-Abfrage. Wir möchten die neuesten Informationen zu COVID-19- Fällen für Bulgarien abrufen. Wir verwenden den BigQuery-Abfrageeditor, um ihn zu testen, bevor wir fortfahren, also haben wir eine benutzerdefinierte Abfrage erstellt:
SELECT * FROM `bigquery-public-data.covid19_ecdc.covid_19_geographic_distribution_worldwide` WHERE geo_ ORDER BY Datum DESC LIMIT 1
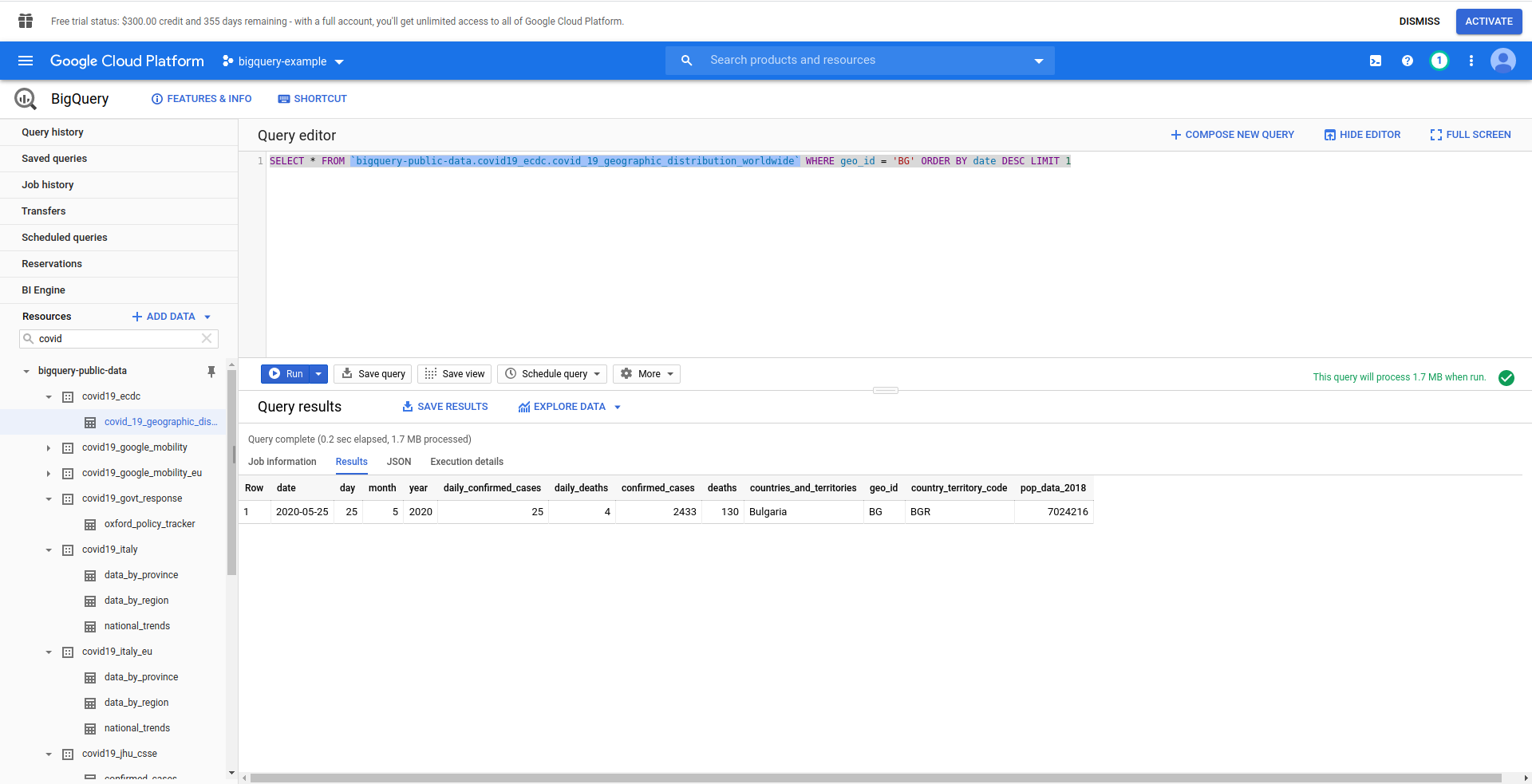
Gut! Lassen Sie uns das jetzt in unserer NodeJS-App implementieren.
Öffnen Sie handler.js und fügen Sie den folgenden Code ein
const query = 'SELECT * FROM `bigquery-public-data.covid19_ecdc.covid_19_geographic_distribution_worldwide` WHERE geo_id = \'BG\' ORDER BY date DESC LIMIT 1';
Konstante Optionen = {
Abfrage: Abfrage
}
const [Job] = warte auf bigQueryClient.createQueryJob (Optionen);
const [rows] = warte auf job.getQueryResults();
Wir haben Abfrage- und Optionskonstanten erstellt. Dann fahren wir damit fort, die Abfrage als Job auszuführen und die Ergebnisse daraus abzurufen.
Lassen Sie uns auch unseren Rückgabehandler ändern, um die generierten Zeilen aus der Abfrage zurückzugeben:
Rückkehr {
statusCode: 200,
Körper: JSON.stringify(
{
Reihen
},
Null,
2
),
};
Sehen wir uns die vollständige handler.js an :
'streng verwenden';
const {BigQuery} = require('@google-cloud/bigquery');
const bigQueryClient = new BigQuery({
Projekt-ID: process.env.PROJECT_ID,
Referenzen: {
client_email: process.env.CLIENT_EMAIL,
private_key: process.env.PRIVATE_KEY
}
});
module.exports.hello = asynchrones Ereignis => {
const query = 'SELECT * FROM `bigquery-public-data.covid19_ecdc.covid_19_geographic_distribution_worldwide` WHERE geo_id = \'BG\' ORDER BY date DESC LIMIT 1';
Konstante Optionen = {
Abfrage: Abfrage
}
const [Job] = warte auf bigQueryClient.createQueryJob (Optionen);
const [rows] = warte auf job.getQueryResults();
Rückkehr {
statusCode: 200,
Körper: JSON.stringify(
{
Reihen
},
Null,
2
),
};
};
In Ordnung! Lassen Sie uns unsere Funktion lokal testen:
sls invoke local -f hello
Wir sollten die Ausgabe sehen:
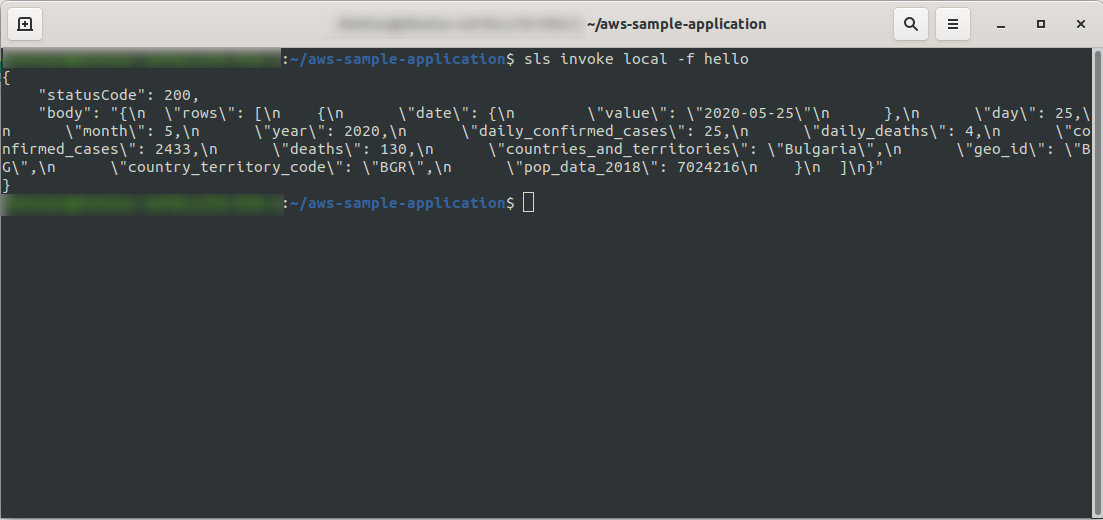
Fahren Sie mit der Bereitstellung der Anwendung fort, um sie über HTTP-Endpunkte zu testen, also führen sls deploy -v
Warten Sie, bis es fertig ist, und öffnen Sie den Endpunkt. Hier sind die Ergebnisse:
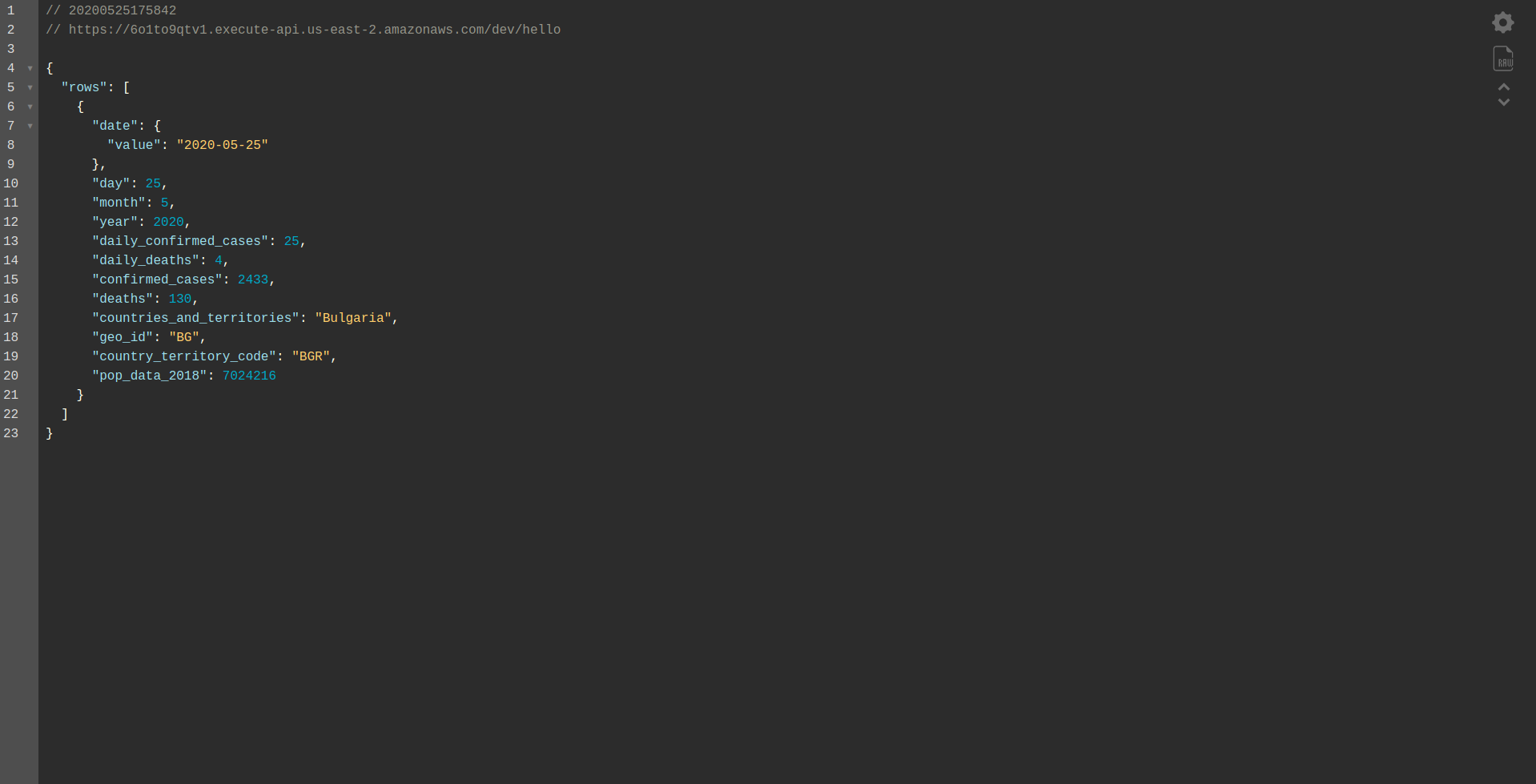
Gut gemacht! Wir haben jetzt eine Anwendung, um Daten aus BigQuery abzurufen und eine Antwort zurückzugeben! Lassen Sie uns endlich überprüfen, ob es offline funktioniert. Führen sls offline
Und laden Sie den lokalen Endpunkt:
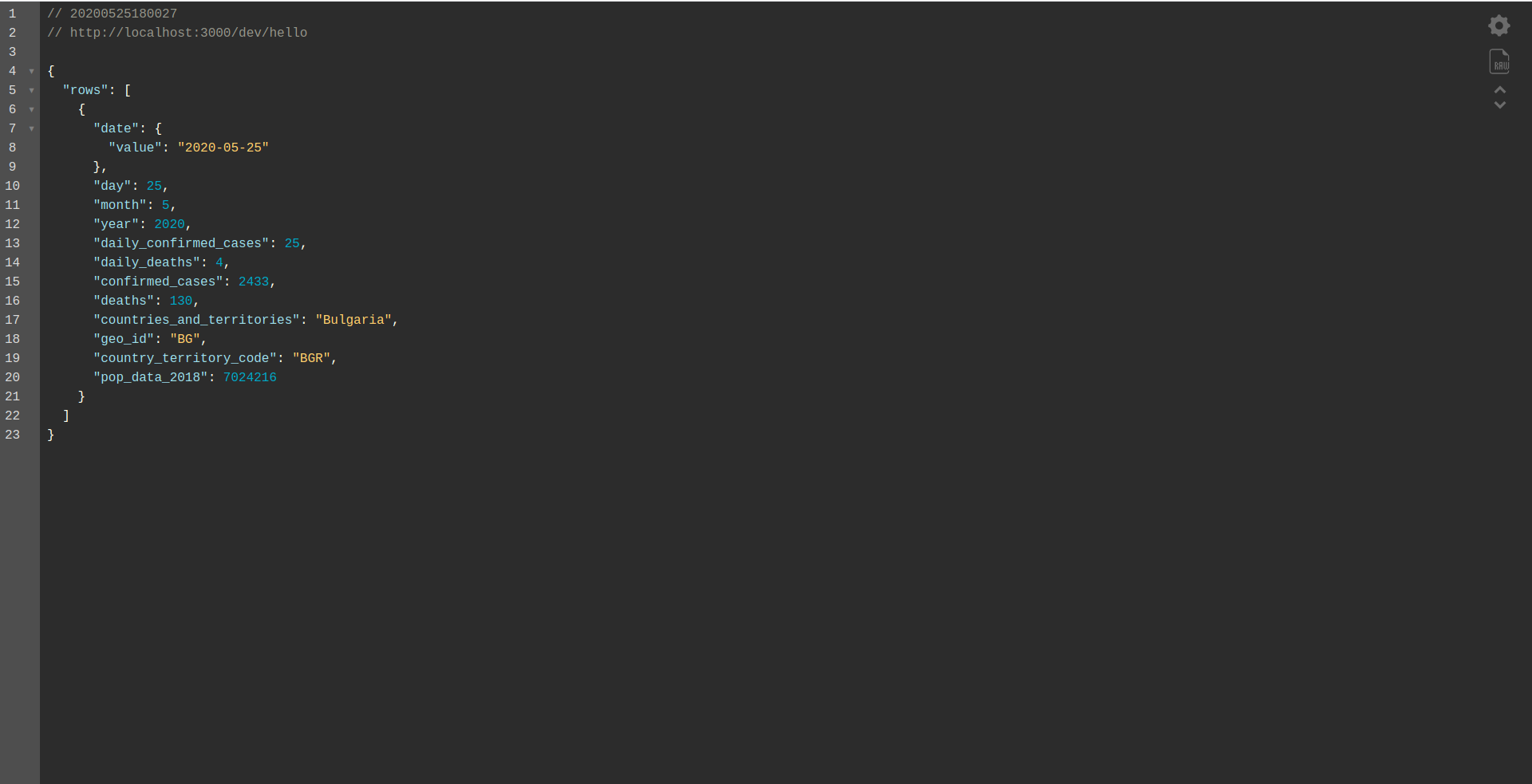
Gut gemachte Arbeit. Wir sind fast am Ende des Prozesses. Der letzte Schritt besteht darin, die App und das Verhalten geringfügig zu ändern. Anstelle von AWS API Gateway wollen wir den Application Load Balancer verwenden. Sehen wir uns im nächsten Kapitel an, wie Sie das erreichen.
ALB – Application Load Balancer in AWS
Wir haben unsere Anwendung mit dem AWS API Gateway erstellt. In diesem Kapitel behandeln wir, wie das API-Gateway durch Application Load Balancer (ALB) ersetzt wird.
Lassen Sie uns zunächst sehen, wie der Application Load Balancer im Vergleich zum API Gateway funktioniert:
Im Application Load Balancer ordnen wir einen oder mehrere bestimmte Pfade (z. B. /hello/ ) einer Zielgruppe zu – einer Gruppe von Ressourcen, in unserem Fall der Lambda -Funktion.
Einer Zielgruppe kann nur eine Lambda-Funktion zugeordnet sein. Wann immer die Zielgruppe antworten muss, sendet der Application Load Balancer eine Anfrage an Lambda und die Funktion muss mit einem Response-Objekt antworten. Wie das API-Gateway verarbeitet der ALB alle HTTP(s)-Anforderungen.
Es gibt einige Unterschiede zwischen dem ALB und dem API Gateway . Ein Hauptunterschied besteht darin, dass das API Gateway nur HTTPS (SSL) unterstützt, während das ALB sowohl HTTP als auch HTTPS unterstützt.
Aber sehen wir uns einige Vor- und Nachteile des API-Gateways an:
API-Gateway:
Vorteile:
- Hervorragende Sicherheit.
- Es ist einfach zu implementieren.
- Es lässt sich schnell bereitstellen und ist in einer Minute betriebsbereit.
- Skalierbarkeit und Verfügbarkeit.
Nachteile:
- Bei hohem Verkehrsaufkommen kann es recht teuer werden.
- Es erfordert etwas mehr Orchestrierung, was den Schwierigkeitsgrad für Entwickler erhöht.
- Leistungseinbußen aufgrund der API-Szenarien können sich auf die Geschwindigkeit und Zuverlässigkeit der Anwendung auswirken.
Fahren wir mit dem Erstellen einer ALB fort und wechseln zu ihr, anstatt das API Gateway zu verwenden:
1. Was ist ALB?
Der Application Load Balancer ermöglicht es dem Entwickler, den eingehenden Datenverkehr zu konfigurieren und weiterzuleiten. Es ist eine Funktion von „ Elastic Load Balancing“. Es dient als zentrale Anlaufstelle für Clients und verteilt den eingehenden Anwendungsdatenverkehr auf mehrere Ziele, z. B. EC2-Instanzen in mehreren Zonen.
2. Erstellen Sie mithilfe der AWS-Benutzeroberfläche einen Application Load Balancer
Lassen Sie uns unseren Application Load Balancer (ALB) über die Benutzeroberfläche in Amazon AWS erstellen. Melden Sie sich bei der AWS-Konsole unter „ Find services“ an. “ Geben Sie „ EC2 “ ein und suchen Sie nach „ Load Balancers. ”
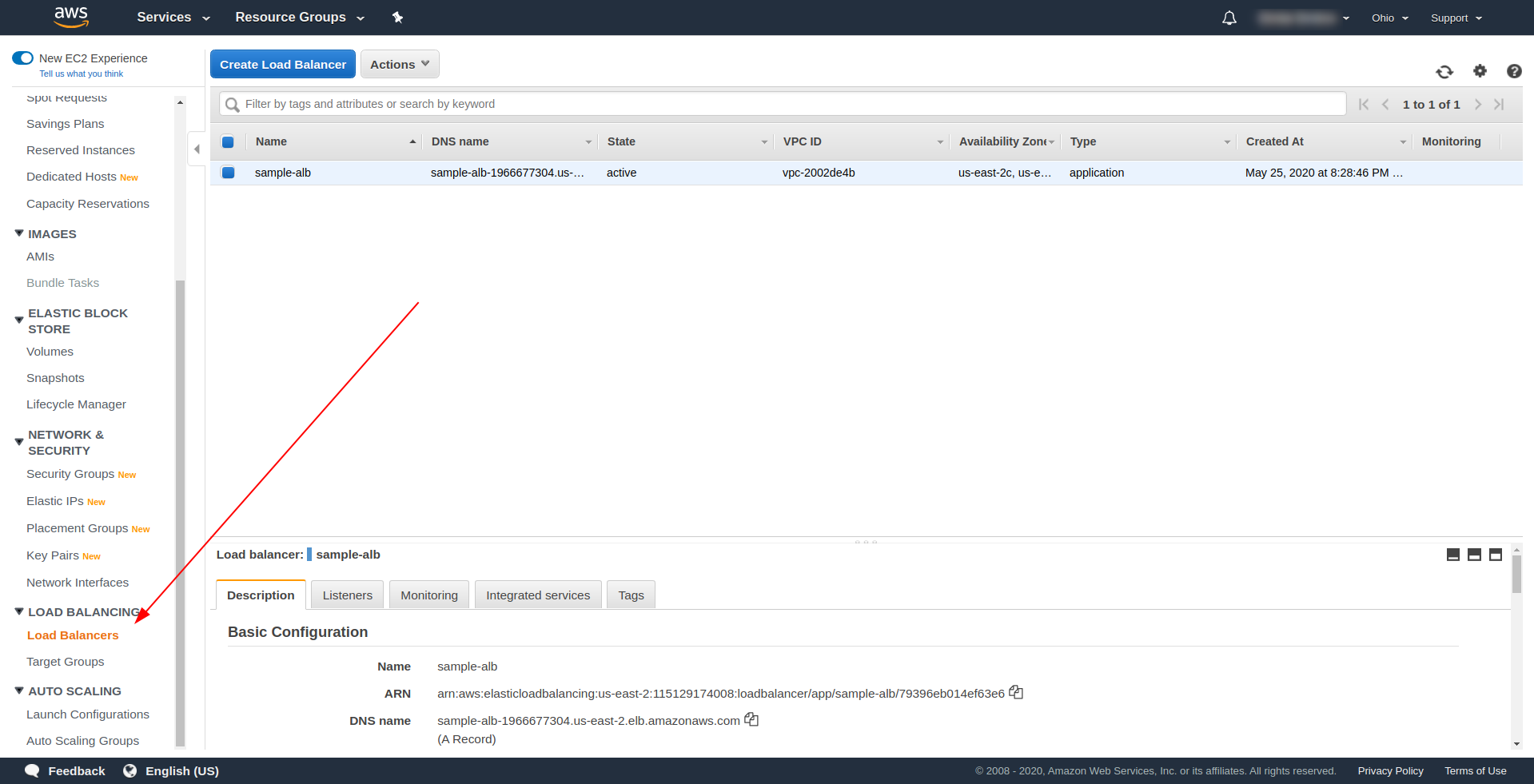
Klicken Sie auf „ Create Load Balancer “ und wählen Sie unter „ Application Load Balancer “ die Option „ Create “. Geben Sie als Namen Ihre Wahl ein, wir haben „ Beispiel-Alb“ verwendet, wählen Sie Schema „ Internet-Facing “, IP-Adresstyp IPv4.
Belassen Sie es unter „ Listener “ so wie es ist – HTTP und Port 80. Es kann für HTTPS konfiguriert werden, obwohl Sie eine Domain haben und diese bestätigen müssen, bevor Sie HTTPS verwenden können.
Verfügbarkeitszonen – Wählen Sie für VPC diejenige , die Sie haben, aus der Dropdown-Liste aus und markieren Sie alle „ Verfügbarkeitszonen“ :
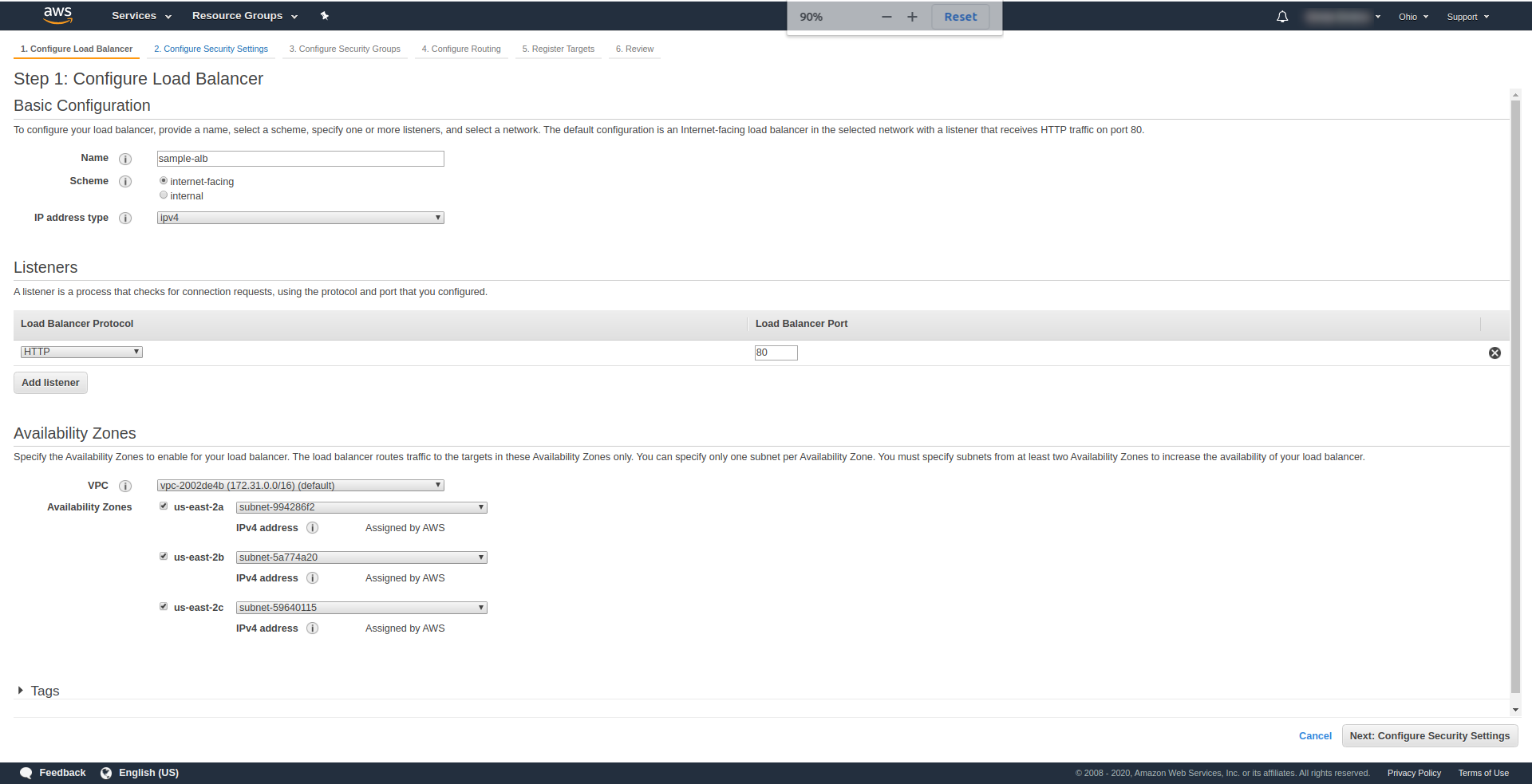
Klicken Sie auf „ Weiter Sicherheitseinstellungen konfigurieren “, um Sie aufzufordern, die Sicherheit Ihres Load Balancers zu verbessern. Weiter klicken.
Wählen Sie bei „ Schritt 3. Sicherheitsgruppen konfigurieren “ unter Sicherheitsgruppe zuweisen „Neue Sicherheitsgruppe erstellen“ aus. Fahren Sie mit einem Klick auf „ Weiter: Routing konfigurieren“ fort. “. Konfigurieren Sie es in Schritt 4 wie im obigen Screenshot gezeigt:
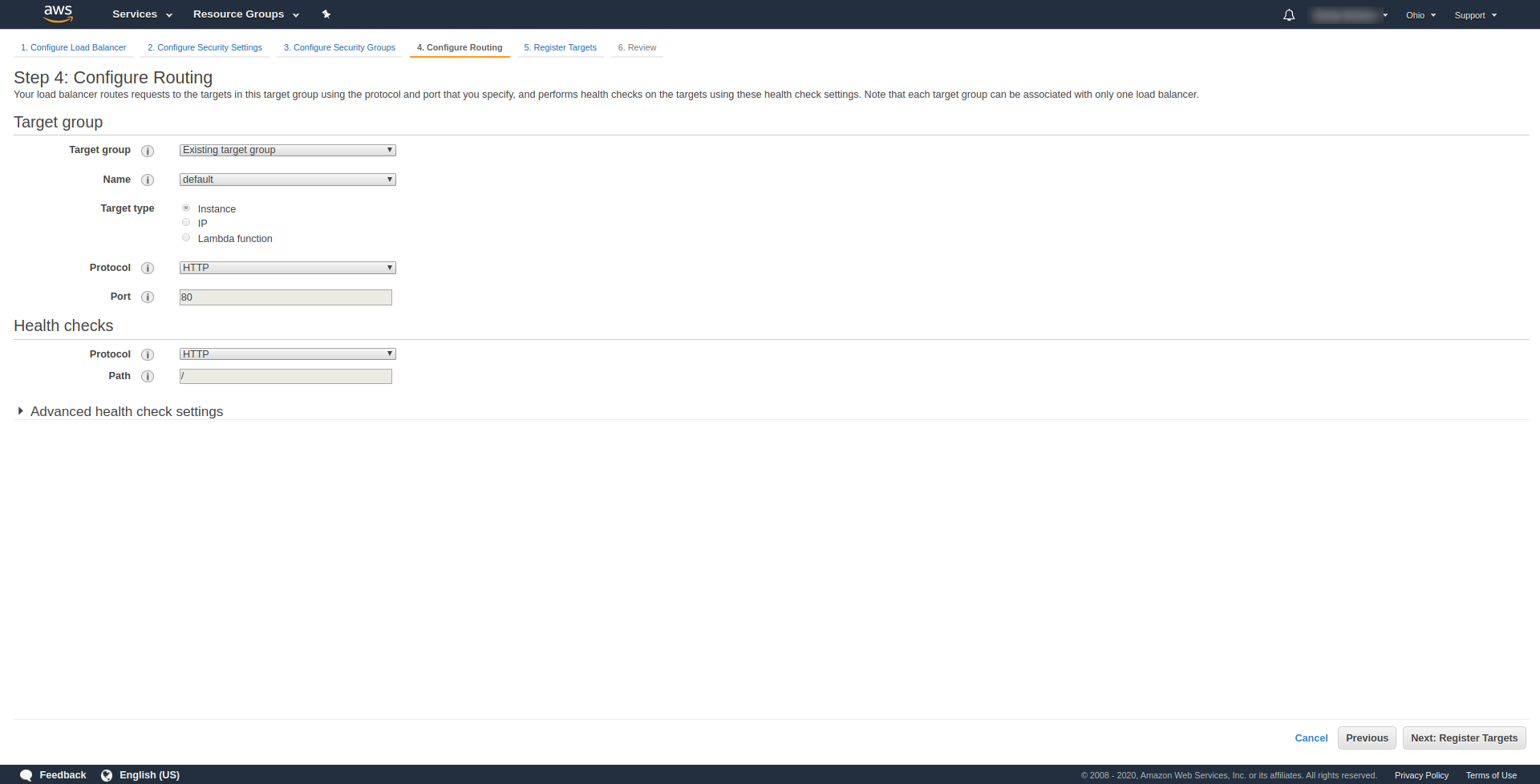
Klicken Sie auf Weiter , Weiter und Erstellen .
Kehren Sie zu den Load Balancern zurück und kopieren Sie den ARN wie im Screenshot gezeigt:
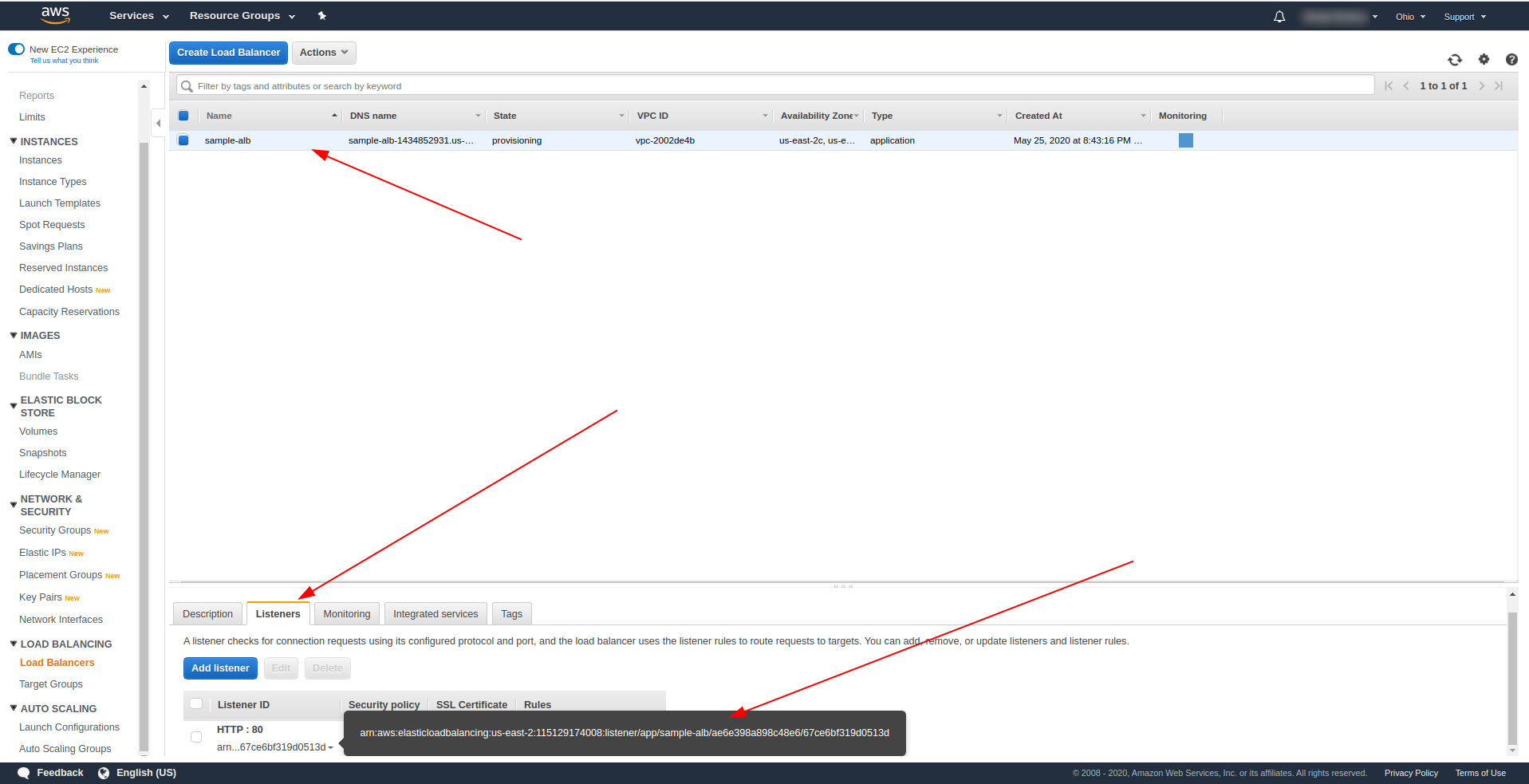
Jetzt müssen wir unsere serverless.yml ändern und die HTTP-Eigenschaft des API-Gateways entfernen. Entfernen Sie unter der Eigenschaft events die Eigenschaft http und fügen Sie eine Eigenschaft alb hinzu. Das Funktionsobjekt sollte folgendermaßen enden:
Hallo:
Handler: Handler.Hallo
Veranstaltungen:
- alb:
listenerArn: arn:aws:elasticloadbalancing:us-east-2:115129174008:listener/app/sample-alb/ae6e398a898c48e6/67ce6bf319d0513d
Priorität: 1
Bedingungen:
Pfad: /Hallo
Speichern Sie die Datei und führen Sie den Befehl zum Bereitstellen der Anwendung aus
sls deploy -v
Kehren Sie nach erfolgreicher Bereitstellung zu AWS Load Balancers zurück und suchen Sie Ihren DNS-Namen, wie auf dem Screenshot gezeigt:
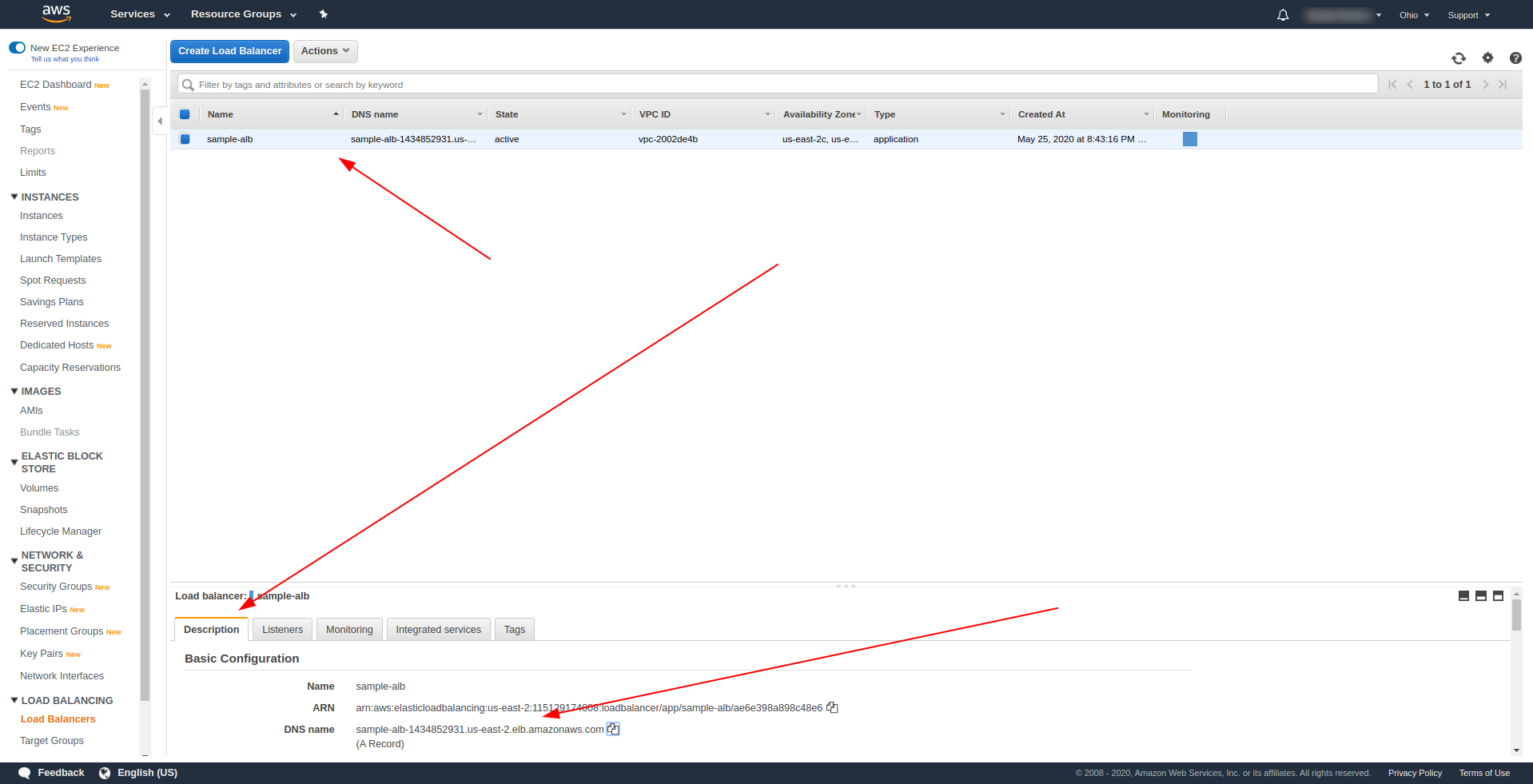
Kopieren Sie den DNS-Namen und geben Sie den Pfad /hello ein.
Es sollte funktionieren und Ihnen schließlich die Möglichkeit bieten, Inhalte herunterzuladen :). Bisher funktioniert der Application Load Balancer wunderbar, aber die Anwendung muss eine angemessene Antwort für unsere Endbenutzer zurückgeben. Öffnen Sie dazu handler.js und ersetzen Sie die return-Anweisung durch die folgende:
Rückkehr {
statusCode: 200,
statusDescription: "200 OK",
Überschriften: {
"Inhaltstyp": "application/json"
},
isBase64Encoded: falsch,
Körper: JSON.stringify (Zeilen)
}
Der Unterschied von ALB besteht darin, dass die Antwort container statusDescription, Header und isBase64Encoded enthalten muss. Bitte speichern Sie die Datei und stellen Sie sie erneut bereit, aber diesmal nicht die gesamte Anwendung, sondern nur die von uns geänderte Funktion. Führen Sie den folgenden Befehl aus:
sls deploy -f hello
Auf diese Weise definieren wir nur die zu implementierende Funktion hallo . Besuchen Sie nach erfolgreicher Bereitstellung erneut den DNS-Namen mit dem Pfad, und Sie sollten eine ordnungsgemäße Antwort erhalten!
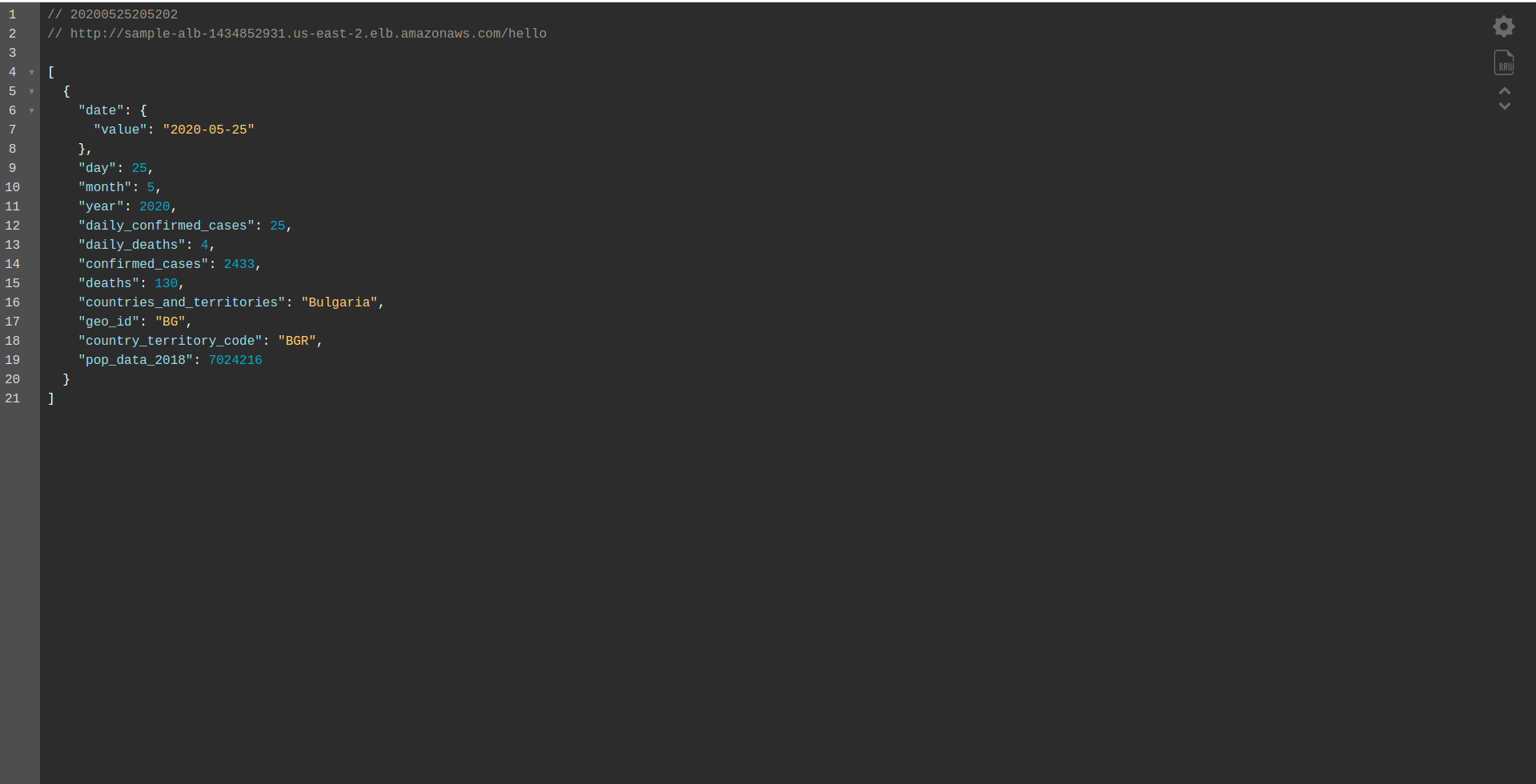
Toll! Jetzt haben wir das API Gateway durch Application Load Balancer ersetzt. Der Anwendungs-Load-Balancer ist billiger als das API-Gateway, und wir können unsere Anwendung jetzt erweitern, um unsere Anforderungen zu erfüllen, insbesondere wenn wir mit höherem Datenverkehr rechnen.
Letzte Worte
Wir haben eine einfache Anwendung mit dem Serverless Framework, AWS und BigQuery erstellt und ihre primäre Verwendung abgedeckt. Serverless ist die Zukunft, und es ist mühelos, eine Anwendung damit zu handhaben. Lernen Sie weiter und tauchen Sie in das Serverless-Framework ein, um alle seine Funktionen und Geheimnisse zu erkunden. Es ist auch ein ziemlich einfaches und praktisches Werkzeug.