
Können Suchmaschinen KI-Inhalte erkennen?
Veröffentlicht: 2023-08-04Die Explosion der KI-Tools im vergangenen Jahr hatte dramatische Auswirkungen auf digitale Vermarkter, insbesondere im SEO-Bereich.
Da die Erstellung von Inhalten zeitaufwändig und kostspielig ist, haben sich Vermarkter zur Unterstützung an KI gewandt, was zu gemischten Ergebnissen führte
Ungeachtet ethischer Bedenken stellt sich immer wieder die Frage: „Können Suchmaschinen meine KI-Inhalte erkennen?“
Die Frage wird als besonders wichtig erachtet, denn wenn die Antwort „Nein“ lautet, werden viele andere Fragen darüber, ob und wie KI eingesetzt werden sollte, entkräftet.
Eine lange Geschichte maschinell generierter Inhalte
Obwohl die Häufigkeit der maschinell generierten oder unterstützten Inhaltserstellung beispiellos ist, ist sie nicht völlig neu und nicht immer negativ.
Für Nachrichten-Websites ist es unerlässlich, zuerst Geschichten zu veröffentlichen, und sie nutzen seit langem Daten aus verschiedenen Quellen wie Aktienmärkten und Seismometern, um die Erstellung von Inhalten zu beschleunigen.
Es ist beispielsweise sachlich korrekt, einen Roboterartikel zu veröffentlichen, in dem es heißt:
- „Heute Morgen wurde in [Ort, Stadt] um [Uhrzeit]/[Datum] ein Erdbeben [Magnitude] festgestellt, das erste Erdbeben seit [Datum des letzten Ereignisses]. Weitere Neuigkeiten folgen.“
Aktualisierungen wie diese sind auch für den Endleser hilfreich, der diese Informationen so schnell wie möglich erhalten muss.
Am anderen Ende des Spektrums haben wir viele „Blackhat“-Implementierungen maschinengenerierter Inhalte gesehen.
Google verurteilt seit vielen Jahren die Verwendung von Markov-Ketten zur Generierung von Text in Content-Spinning mit geringem Aufwand unter dem Motto „automatisch generierte Seiten, die keinen Mehrwert bieten“.
Was besonders interessant ist und für manche meist ein Punkt der Verwirrung oder eine Grauzone ist, ist die Bedeutung von „kein Mehrwert“.
Wie können LLMs einen Mehrwert schaffen?
Die Beliebtheit von KI-Inhalten stieg aufgrund der Aufmerksamkeit, die GPTx Large Language Models (LLMs) und dem fein abgestimmten KI-Chatbot ChatGPT erregte, der die Konversationsinteraktion verbesserte.
Ohne auf technische Details einzugehen, gibt es bei diesen Tools einige wichtige Punkte zu beachten:
Der generierte Text basiert auf einer Wahrscheinlichkeitsverteilung
- Wenn Sie beispielsweise schreiben: „SEO zu sein macht Spaß, weil…“, schaut sich das LLM alle Token an und versucht, das nächstwahrscheinlichste Wort basierend auf seinem Trainingssatz zu berechnen. Kurz gesagt, Sie können es sich als eine wirklich erweiterte Version der Texterkennung Ihres Telefons vorstellen.
ChatGPT ist eine Art generative künstliche Intelligenz
- Dies bedeutet, dass die Ausgabe nicht vorhersehbar ist. Es gibt ein zufälliges Element, das möglicherweise unterschiedlich auf dieselbe Eingabeaufforderung reagiert.
Wenn man diese beiden Punkte berücksichtigt, wird deutlich, dass Tools wie ChatGPT über kein traditionelles Wissen verfügen oder irgendetwas „wissen“. Dieser Mangel ist die Grundlage für alle Irrtümer oder „Halluzinationen“, wie sie genannt werden.
Zahlreiche dokumentierte Ergebnisse zeigen, wie dieser Ansatz zu falschen Ergebnissen führen und dazu führen kann, dass ChatGPT sich wiederholt widerspricht.
Dies wirft angesichts der Möglichkeit häufiger Halluzinationen ernsthafte Zweifel an der Konsistenz des „Mehrwerts“ mit KI-geschriebenen Texten auf.
Die Hauptursache liegt in der Art und Weise, wie LLMs Text erzeugen, was ohne einen neuen Ansatz nicht einfach zu lösen ist.
Dies ist ein wichtiger Gesichtspunkt, insbesondere bei den Themen „Your Money, Your Life“ (YMYL), deren Ungenauigkeiten den Finanzen oder dem Leben von Menschen erheblichen Schaden zufügen können.
Große Publikationen wie Men's Health und CNET wurden in diesem Jahr dabei erwischt, wie sie sachlich falsche, von der KI generierte Informationen veröffentlichten, was die Besorgnis unterstreicht.
Verlage sind mit diesem Problem nicht allein, da Google Schwierigkeiten hatte, seine Search Generative Experience (SGE)-Inhalte mit YMYL-Inhalten einzudämmen.
Obwohl Google angibt, dass man mit den generierten Antworten vorsichtig sein würde und sogar konkret ein Beispiel nennt: „Auf die Frage, ob man einem Kind Tylenol verabreichen kann, weil es im medizinischen Bereich ist, wird keine Antwort angezeigt“, würde die SGE dies nachweislich tun Dies geschieht, indem man ihm einfach die Frage stellt.
Erhalten Sie den täglichen Newsletter, auf den sich Suchmaschinenmarketing verlassen.
Siehe Bedingungen.
Googles SGE und MUM
Es ist klar, dass Google davon überzeugt ist, dass es einen Platz für maschinell generierte Inhalte gibt, um die Fragen der Nutzer zu beantworten. Google hat dies seit Mai 2021 angedeutet, als sie MUM, ihr Multitask Unified Model, ankündigten.
Eine Herausforderung, der sich MUM stellen wollte, basierte auf den Daten, dass Menschen bei komplexen Aufgaben durchschnittlich acht Anfragen stellen.
Bei einer ersten Abfrage erfährt der Suchende einige zusätzliche Informationen, die zu verwandten Suchanfragen führen und neue Webseiten zur Beantwortung dieser Abfragen anzeigen.
Google schlug vor: Was wäre, wenn sie die erste Anfrage beantworten, Folgefragen der Nutzer antizipieren und mithilfe ihres Indexwissens die vollständige Antwort generieren könnten?

Wenn es funktioniert, mag dieser Ansatz zwar fantastisch für den Benutzer sein, er macht aber im Grunde viele „Long-Tail“- oder Zero-Volume-Keyword-Strategien zunichte, auf die sich SEOs verlassen, um in den SERPs Fuß zu fassen.
Vorausgesetzt, Google kann Suchanfragen identifizieren, die für KI-generierte Antworten geeignet sind, könnten viele Fragen als „gelöst“ gelten.
Das wirft die Frage auf …
- Warum sollte Google einem Suchenden Ihre Webseite mit einer vorgenerierten Antwort anzeigen, wenn Google den Nutzer in seinem Suchökosystem behalten und die Antwort selbst generieren kann?
Google hat einen finanziellen Anreiz, Nutzer in seinem Ökosystem zu halten. Wir haben verschiedene Ansätze gesehen, um dies zu erreichen, von Featured Snippets bis hin zur Suche nach Flügen in den SERPs.
Angenommen, Google ist der Ansicht, dass Ihr generierter Text keinen Mehrwert bietet, der über das hinausgeht, was er bereits bieten kann. In diesem Fall ist es für die Suchmaschine einfach eine Frage des Kosten-Nutzen-Verhältnisses.
Können sie langfristig mehr Umsatz generieren, indem sie die Kosten für die Erstellung übernehmen und den Benutzer auf eine Antwort warten lassen, anstatt ihn schnell und kostengünstig auf eine Seite zu schicken, von der sie wissen, dass sie bereits existiert?
KI-Inhalte erkennen
Mit der explosionsartigen Nutzung von ChatGPT kamen Dutzende von „KI-Inhaltsdetektoren“ auf den Markt, die es Ihnen ermöglichen, Textinhalte einzugeben und einen prozentualen Wert auszugeben – und darin liegt das Problem.
Obwohl es bei verschiedenen Detektoren einige Unterschiede in der Bezeichnung dieser prozentualen Bewertung gibt, liefern sie fast ausnahmslos die gleiche Ausgabe: die prozentuale Sicherheit, dass der gesamte bereitgestellte Text von der KI generiert wurde.
Dies führt zu Verwirrung, wenn der Prozentsatz beispielsweise mit „75 % KI / 25 % Mensch“ gekennzeichnet ist.
Viele Menschen werden dies falsch verstehen und sagen: „Der Text wurde zu 75 % von einer KI und zu 25 % von einem Menschen geschrieben“, während es bedeutet: „Ich bin zu 75 % sicher, dass eine KI 100 % dieses Textes geschrieben hat.“
Dieses Missverständnis hat einige dazu veranlasst, Ratschläge zu geben, wie man die Texteingabe so optimieren kann, dass sie einen KI-Detektor „passiert“.
Beispielsweise ist die Verwendung eines doppelten Ausrufezeichens (!!) eine sehr menschliche Eigenschaft. Das Hinzufügen dieses Zeichens zu einem KI-generierten Text führt dazu, dass ein KI-Detektor die Bewertung „99 %+ menschlich“ ergibt.
Dies wird dann fälschlicherweise dahingehend interpretiert, dass Sie den Detektor „getäuscht“ haben.
Aber es ist ein Beispiel dafür, dass der Detektor perfekt funktioniert, da der bereitgestellte Durchgang nicht mehr zu 100 % von der KI generiert wird.
Leider wird diese irreführende Schlussfolgerung, KI-Detektoren „täuschen“ zu können, auch häufig damit in Verbindung gebracht, dass Suchmaschinen wie Google keine KI-Inhalte erkennen, was den Website-Besitzern ein falsches Sicherheitsgefühl vermittelt.
Google-Richtlinien und -Aktionen für KI-Inhalte
Googles Aussagen zu KI-Inhalten waren in der Vergangenheit so vage, dass sie bei der Durchsetzung Spielraum hatten.
Dieses Jahr wurde jedoch in Google Search Central ein aktualisierter Leitfaden veröffentlicht, in dem es ausdrücklich heißt:
„Unser Fokus liegt auf der Qualität der Inhalte und nicht darauf, wie Inhalte produziert werden.“
Schon zuvor äußerte sich Danny Sullivan, Verbindungsmann der Google-Suche, zu Twitter-Vorbehalten und bestätigte, dass sie „nicht gesagt haben, dass KI-Inhalte schlecht sind“.
Google listet konkrete Beispiele dafür auf, wie KI hilfreiche Inhalte generieren kann, etwa Sportergebnisse, Wettervorhersagen und Transkripte.
Es ist klar, dass es Google viel mehr um die Ausgabe geht als um die Art und Weise, wie man dorthin gelangt, und dass es einen Verstoß gegen unsere Spam-Richtlinien darstellt, „Inhalte zu generieren, deren Hauptzweck darin besteht, das Ranking in den Suchergebnissen zu manipulieren“.
Im Kampf gegen SERP-Manipulation verfügt Google über langjährige Erfahrung und behauptet, dass Fortschritte in seinen Systemen wie SpamBrain 99 % der Suchanfragen „Spam-frei“ gemacht haben, was UGC-Spam, Scraping, Cloaking und alle anderen Formen von Inhalten einschließt Generation.
Viele Leute haben Tests durchgeführt, um zu sehen, wie Google auf KI-Inhalte reagiert und wo sie die Grenze bei der Qualität ziehen.
Vor dem Start von ChatGPT habe ich eine Website mit 10.000 Inhaltsseiten erstellt, die hauptsächlich von einem unbeaufsichtigten GPT3-Modell generiert wurden, und beantwortete Fragen zu Videospielen.
Mit minimalen Links wurde die Website schnell indiziert und wuchs stetig, sodass sie jeden Monat Tausende Besucher anzog.
Bei zwei Google-Systemaktualisierungen im Jahr 2022, dem „Hilfreiche Inhalte“-Update und dem späteren „Spam“-Update, hat Google die Seite plötzlich und fast vollständig unterdrückt.
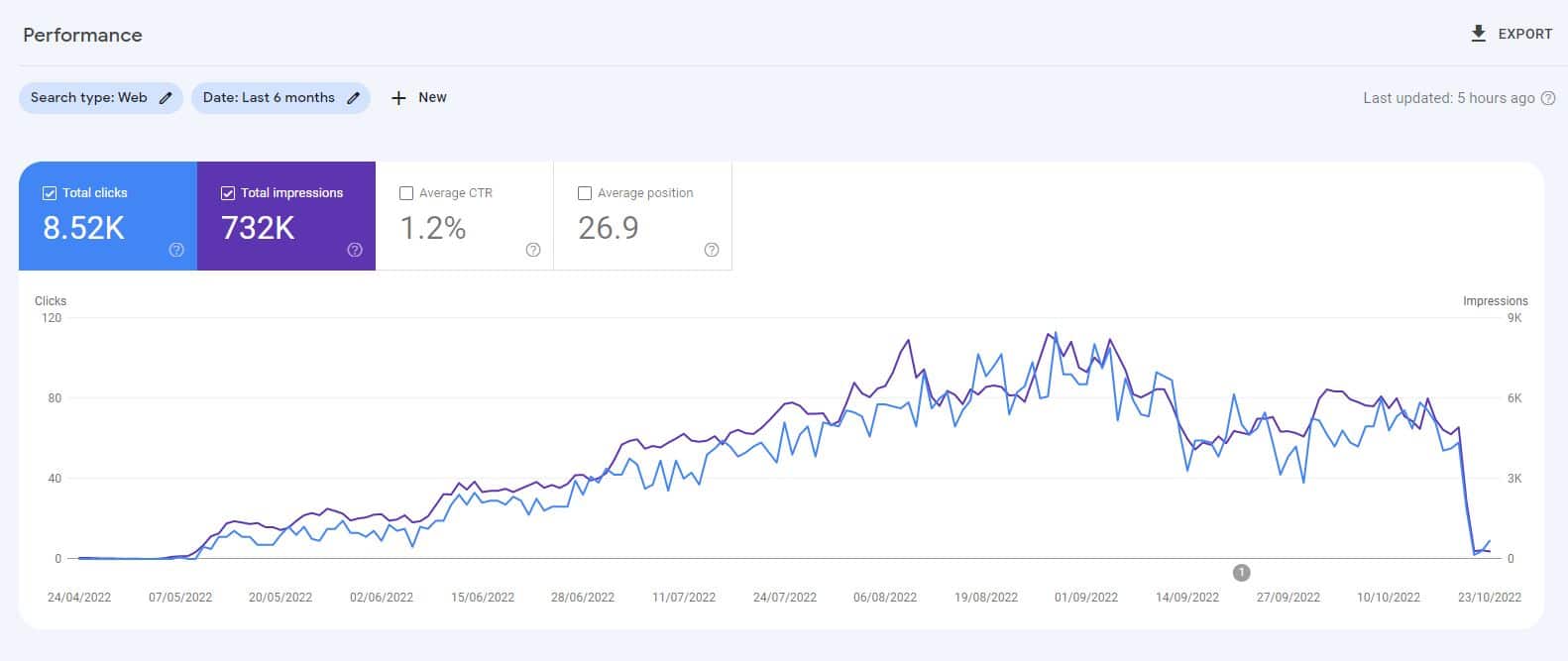
Es wäre falsch, aus einem solchen Experiment den Schluss zu ziehen, dass „KI-Inhalte nicht funktionieren“.
Dies zeigte mir jedoch, dass Google zu diesem Zeitpunkt:
- Unbeaufsichtigte GPT-3-Inhalte wurden nicht als „Qualität“ eingestuft.
- Könnte solche Ergebnisse mit einer Reihe anderer Signale erkennen und entfernen.
Um die ultimative Antwort zu erhalten, benötigen Sie eine bessere Frage
Basierend auf den Richtlinien von Google, was wir über Suchmaschinen, SEO-Experimente und den gesunden Menschenverstand wissen: „Können Suchmaschinen KI-Inhalte erkennen?“ ist wahrscheinlich die falsche Frage.
Im besten Fall handelt es sich um eine sehr kurzfristige Sichtweise.
Bei den meisten Themen fällt es LLMs schwer, konsistent „hochwertige“ Inhalte im Hinblick auf sachliche Genauigkeit und die Erfüllung der EEAT-Kriterien von Google zu produzieren, obwohl sie über Live-Webzugriff auf Informationen verfügen, die über ihre Trainingsdaten hinausgehen.
KI macht erhebliche Fortschritte bei der Generierung von Antworten auf bisher inhaltsarme Fragen. Doch da Google mit SGE höhere langfristige Ziele anstrebt, könnte dieser Trend nachlassen.
Es wird erwartet, dass der Schwerpunkt wieder auf längeren Experteninhalten liegt, wobei die Wissenssysteme von Google Antworten für viele Longtail-Anfragen liefern, anstatt Benutzer auf zahlreiche kleine Websites zu leiten.
Die in diesem Artikel geäußerten Meinungen sind die des Gastautors und nicht unbedingt die von Search Engine Land. Die Autoren unserer Mitarbeiter sind hier aufgelistet.