
Crawl-Effizienz: So verbessern Sie die Crawl-Optimierung
Veröffentlicht: 2022-10-27Es ist nicht garantiert, dass der Googlebot jede URL Ihrer Website crawlt, auf die er zugreifen kann. Im Gegenteil, bei der überwiegenden Mehrheit der Websites fehlt ein erheblicher Teil der Seiten.
Die Realität ist, dass Google nicht über die Ressourcen verfügt, um jede gefundene Seite zu crawlen. Alle URLs, die der Googlebot entdeckt, aber noch nicht gecrawlt hat, sowie die URLs, die er erneut crawlen möchte, werden in einer Crawling-Warteschlange priorisiert.
Das bedeutet, dass der Googlebot nur diejenigen durchsucht, denen eine ausreichend hohe Priorität zugewiesen wurde. Und da die Crawling-Warteschlange dynamisch ist, ändert sie sich ständig, wenn Google neue URLs verarbeitet. Und nicht alle URLs kommen ganz hinten in die Warteschlange.
Wie stellen Sie also sicher, dass die URLs Ihrer Website VIPs sind und überspringen?
Crawling ist für SEO von entscheidender Bedeutung

Damit Inhalte sichtbar werden, muss der Googlebot sie zuerst crawlen.
Aber die Vorteile sind nuancierter als das, denn je schneller eine Seite gecrawlt wird, wenn sie:
- Erstellt , desto früher können neue Inhalte bei Google erscheinen. Dies ist besonders wichtig für zeitlich begrenzte oder First-to-Market-Content-Strategien.
- Aktualisiert , desto früher kann sich dieser aktualisierte Inhalt auf die Rankings auswirken. Dies ist besonders wichtig sowohl für Strategien zur Wiederveröffentlichung von Inhalten als auch für technische SEO-Taktiken.
Daher ist das Crawlen für Ihren gesamten organischen Verkehr unerlässlich. Doch zu oft heißt es, Crawl-Optimierung sei nur für große Websites von Vorteil.
Aber es geht nicht um die Größe Ihrer Website, die Häufigkeit, mit der Inhalte aktualisiert werden oder ob Sie in der Google Search Console „Entdeckt – derzeit nicht indiziert“-Ausschlüsse haben.
Die Crawl-Optimierung ist für jede Website von Vorteil. Das Missverständnis seines Wertes scheint von bedeutungslosen Messungen, insbesondere dem Crawl-Budget, zu spornen.
Das Crawl-Budget spielt keine Rolle

Zu oft wird das Crawling anhand des Crawling-Budgets bewertet. Dies ist die Anzahl der URLs, die der Googlebot in einem bestimmten Zeitraum auf einer bestimmten Website crawlt.
Google sagt, es wird durch zwei Faktoren bestimmt:
- Limit der Crawling-Rate (oder was der Googlebot crawlen kann): Die Geschwindigkeit, mit der der Googlebot die Ressourcen der Website abrufen kann, ohne die Leistung der Website zu beeinträchtigen. Im Wesentlichen führt ein reaktionsschneller Server zu einer höheren Crawling-Rate.
- Crawl-Nachfrage (oder was der Googlebot crawlen möchte): Die Anzahl der URLs, die der Googlebot während eines einzelnen Crawls besucht, basierend auf der Nachfrage nach (Neu-)Indexierung, beeinflusst durch die Popularität und Veraltung des Inhalts der Website.
Sobald der Googlebot sein Crawling-Budget „aufgebraucht“ hat, beendet er das Crawlen einer Website.
Google stellt keine Zahl für das Crawl-Budget bereit. Am ehesten kommt es der Anzeige der gesamten Crawling-Anfragen im Crawling-Statistikbericht der Google Search Console.
So viele SEOs, einschließlich mir selbst, haben in der Vergangenheit große Anstrengungen unternommen, um zu versuchen, auf das Crawl-Budget zu schließen.
Die oft vorgestellten Schritte sind in etwa so:
- Bestimmen Sie, wie viele crawlbare Seiten Sie auf Ihrer Website haben, und empfehlen Sie häufig, sich die Anzahl der URLs in Ihrer XML-Sitemap anzusehen oder einen unbegrenzten Crawler auszuführen.
- Berechnen Sie die durchschnittlichen Crawls pro Tag, indem Sie den Crawl-Statistikbericht der Google Search Console exportieren oder auf Googlebot-Anfragen in Protokolldateien basieren.
- Teilen Sie die Anzahl der Seiten durch die durchschnittlichen Crawls pro Tag. Es wird oft gesagt, wenn das Ergebnis über 10 liegt, konzentrieren Sie sich auf die Optimierung des Crawl-Budgets.
Dieses Verfahren ist jedoch problematisch.
Nicht nur, weil davon ausgegangen wird, dass jede URL einmal gecrawlt wird, während in Wirklichkeit manche mehrfach gecrawlt werden, andere gar nicht.
Nicht nur, weil davon ausgegangen wird, dass ein Crawl einer Seite entspricht. In Wirklichkeit erfordert eine Seite möglicherweise viele URL-Crawls, um die zum Laden erforderlichen Ressourcen (JS, CSS usw.) abzurufen.
Aber am wichtigsten ist, dass das Crawl-Budget, wenn es auf eine berechnete Metrik wie durchschnittliche Crawls pro Tag reduziert wird, nichts anderes als eine Eitelkeitsmetrik ist.
Jede Taktik, die auf „Optimierung des Crawling-Budgets“ abzielt (auch bekannt als das Ziel, die Gesamtmenge an Crawling kontinuierlich zu erhöhen), ist ein Irrweg.
Warum sollte es Sie interessieren, die Gesamtzahl der Crawls zu erhöhen, wenn sie für wertlose URLs oder Seiten verwendet wird, die seit dem letzten Crawl nicht geändert wurden? Solche Crawls werden der SEO-Leistung nicht helfen.
Außerdem weiß jeder, der sich schon einmal Crawling-Statistiken angesehen hat, dass diese von einem Tag zum anderen abhängig von einer Reihe von Faktoren oft ziemlich stark schwanken. Diese Schwankungen können mit einer schnellen (Neu-)Indizierung von SEO-relevanten Seiten korrelieren oder auch nicht.
Ein Anstieg oder Rückgang der gecrawlten URLs ist weder per se gut noch schlecht.
Die Crawl-Effizienz ist ein SEO-KPI

Für die Seite(n), die Sie indexieren möchten, sollte der Fokus nicht darauf liegen, ob sie gecrawlt wurden, sondern wie schnell sie nach der Veröffentlichung oder wesentlichen Änderung gecrawlt wurden.
Im Wesentlichen besteht das Ziel darin, die Zeit zwischen der Erstellung oder Aktualisierung einer SEO-relevanten Seite und dem nächsten Googlebot-Crawling zu minimieren. Ich nenne diese Zeitverzögerung die Crawl-Effizienz.
Der ideale Weg, um die Crawling-Effizienz zu messen, besteht darin, die Differenz zwischen dem Erstellungs- oder Aktualisierungsdatum der Datenbank und dem nächsten Googlebot-Crawling der URL aus den Serverprotokolldateien zu berechnen.
Wenn es schwierig ist, Zugriff auf diese Datenpunkte zu erhalten, können Sie auch das Lastmod-Datum der XML-Sitemap als Proxy verwenden und URLs in der URL-Inspektions-API der Google Search Console nach dem letzten Crawling-Status abfragen (bis zu einer Grenze von 2.000 Abfragen pro Tag).
Außerdem können Sie durch die Verwendung der URL-Inspektions-API nachverfolgen, wenn sich der Indizierungsstatus ändert, um eine Indizierungswirksamkeit für neu erstellte URLs zu berechnen, die den Unterschied zwischen Veröffentlichung und erfolgreicher Indizierung darstellt.
Denn das Crawlen ohne Auswirkung auf den Indexierungsstatus oder das Verarbeiten einer Aktualisierung des Seiteninhalts ist nur eine Verschwendung.
Die Crawl-Effizienz ist eine umsetzbare Kennzahl, denn je geringer sie ist, desto mehr SEO-kritische Inhalte können Ihrem Publikum über Google angezeigt werden.
Sie können es auch verwenden, um SEO-Probleme zu diagnostizieren. Führen Sie einen Drilldown in URL-Muster durch, um zu verstehen, wie schnell Inhalte aus verschiedenen Bereichen Ihrer Website gecrawlt werden und ob dies die organische Leistung behindert.
Wenn Sie feststellen, dass der Googlebot Stunden oder Tage oder Wochen braucht, um Ihre neu erstellten oder kürzlich aktualisierten Inhalte zu crawlen und somit zu indizieren, was können Sie dagegen tun?
Holen Sie sich den täglichen Newsletter, auf den sich Suchmaschinenvermarkter verlassen.
Siehe Bedingungen.
7 Schritte zur Optimierung des Crawlings
Bei der Crawl-Optimierung geht es darum, den Googlebot dazu zu bringen, wichtige URLs zu crawlen schnell, wenn sie (erneut) veröffentlicht werden. Befolgen Sie die folgenden sieben Schritte.
1. Stellen Sie eine schnelle und fehlerfreie Serverantwort sicher
Ein leistungsstarker Server ist entscheidend. Der Googlebot verlangsamt oder stoppt das Crawlen, wenn:
- Das Crawlen Ihrer Website wirkt sich auf die Leistung aus. Je mehr sie beispielsweise crawlen, desto langsamer ist die Antwortzeit des Servers.
- Der Server antwortet mit einer bemerkenswerten Anzahl von Fehlern oder Verbindungszeitüberschreitungen.
Auf der anderen Seite kann die Verbesserung der Seitenladegeschwindigkeit, die die Bereitstellung von mehr Seiten ermöglicht, dazu führen, dass der Googlebot mehr URLs in der gleichen Zeit crawlt. Dies ist ein zusätzlicher Vorteil neben der Seitengeschwindigkeit, die ein Benutzererlebnis und ein Rankingfaktor ist.
Falls Sie dies noch nicht getan haben, ziehen Sie die Unterstützung von HTTP/2 in Betracht, da es die Möglichkeit bietet, mehr URLs mit einer ähnlichen Last auf Servern anzufordern.
Die Korrelation zwischen Leistung und Crawling-Volumen besteht jedoch nur bis zu einem bestimmten Punkt . Sobald Sie diesen Schwellenwert überschreiten, der von Site zu Site unterschiedlich ist, werden zusätzliche Verbesserungen der Serverleistung wahrscheinlich nicht mit einem Anstieg des Crawlings korrelieren.
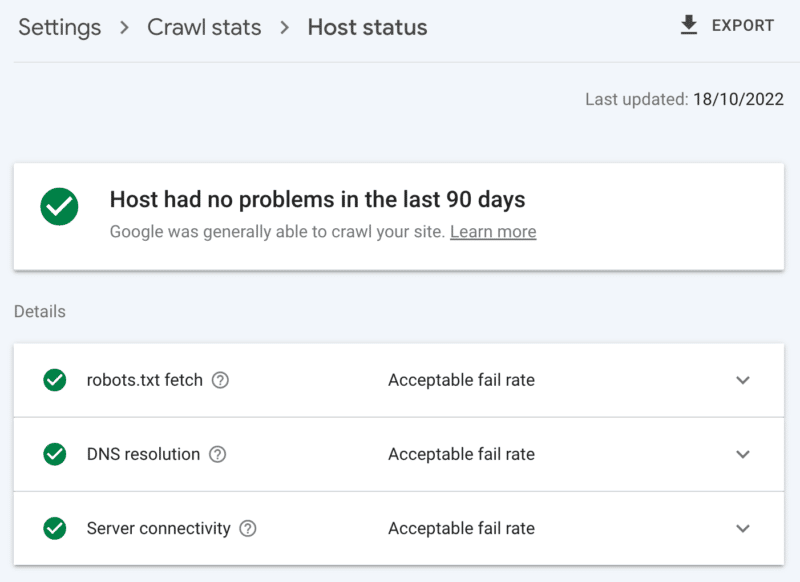
So überprüfen Sie den Serverzustand
Der Crawling-Statistikbericht der Google Search Console:
- Hoststatus: Zeigt grüne Häkchen.
- 5xx-Fehler: Macht weniger als 1 % aus.
- Diagramm der Serverantwortzeit: Trend unter 300 Millisekunden.
2. Bereinigen Sie Inhalte mit geringem Wert
Wenn eine erhebliche Menge an Website-Inhalten veraltet, doppelt oder von geringer Qualität ist, führt dies zu einem Wettbewerb um Crawling-Aktivitäten, was möglicherweise die Indizierung neuer Inhalte oder die Neuindizierung aktualisierter Inhalte verzögert.

Fügen Sie hinzu, dass die regelmäßige Bereinigung von Inhalten mit geringem Wert auch das Aufblähen des Indexes und die Kannibalisierung von Schlüsselwörtern reduziert und sich positiv auf die Benutzererfahrung auswirkt. Dies ist ein SEO-Kinderspiel.
Führen Sie Inhalte mit einer 301-Weiterleitung zusammen, wenn Sie eine andere Seite haben, die als klarer Ersatz angesehen werden kann; Wenn Sie dies verstehen, kostet Sie das Crawlen für die Verarbeitung das Doppelte, aber es ist ein lohnendes Opfer für die Link-Equity.
Wenn es keinen gleichwertigen Inhalt gibt, führt die Verwendung von 301 nur zu einem weichen 404. Entfernen Sie solche Inhalte mit einem 410 (am besten) oder 404 (nahe an zweiter Stelle) Statuscode, um ein starkes Signal zu geben, die URL nicht erneut zu crawlen.
So suchen Sie nach Inhalten mit geringem Wert
Die Anzahl der URLs auf den Seiten der Google Search Console meldet „gecrawlt – derzeit nicht indexiert“-Ausschlüsse. Wenn dies hoch ist, überprüfen Sie die bereitgestellten Muster auf Ordnermuster oder andere Problemindikatoren.
3. Überprüfen Sie die Indizierungssteuerelemente
Rel=kanonische Links sind ein starker Hinweis zur Vermeidung von Indizierungsproblemen, auf die man sich jedoch oft zu sehr verlässt und die Crawling-Probleme verursachen, da jede kanonisierte URL mindestens zwei Crawlings kostet, einen für sich selbst und einen für ihren Partner.
In ähnlicher Weise sind noindex-Robots-Anweisungen nützlich, um das Aufblähen von Indizes zu reduzieren, aber eine große Anzahl kann das Crawling negativ beeinflussen – verwenden Sie sie also nur, wenn es notwendig ist.
Fragen Sie sich in beiden Fällen:
- Sind diese Indizierungsrichtlinien der optimale Weg, um die SEO-Herausforderung zu bewältigen?
- Können einige URL-Routen in robots.txt konsolidiert, entfernt oder blockiert werden?
Wenn Sie es verwenden, sollten Sie AMP ernsthaft als langfristige technische Lösung in Betracht ziehen.
Da sich das Seitenerlebnis-Update auf die wichtigsten Web-Vitals und die Einbeziehung von Nicht-AMP-Seiten in alle Google-Erlebnisse konzentriert, solange Sie die Anforderungen an die Seitengeschwindigkeit erfüllen, sollten Sie genau prüfen, ob AMP das doppelte Crawlen wert ist.
So überprüfen Sie die übermäßige Abhängigkeit von Indizierungssteuerelementen
Die Anzahl der URLs im Abdeckungsbericht der Google Search Console, die ohne klaren Grund unter den Ausschlüssen kategorisiert wurden:
- Alternative Seite mit passendem Canonical-Tag.
- Ausgeschlossen durch noindex-Tag.
- Duplicate, Google wählte andere Canonicals als der Nutzer.
- Doppelte, übermittelte URL nicht als kanonisch ausgewählt.
4. Sagen Sie Suchmaschinen-Spidern, was sie wann crawlen sollen
Ein wesentliches Tool, das dem Googlebot hilft, wichtige Website-URLs zu priorisieren und zu kommunizieren, wenn solche Seiten aktualisiert werden, ist eine XML-Sitemap.
Achten Sie für eine effektive Raupenführung auf Folgendes:
- Schließen Sie nur URLs ein, die sowohl indexierbar als auch für SEO wertvoll sind – im Allgemeinen 200-Statuscode, kanonische Originalinhaltsseiten mit einem „Index, Follow“-Roboter-Tag, für die Sie sich um ihre Sichtbarkeit in den SERPs kümmern.
- Fügen Sie den einzelnen URLs und der Sitemap selbst genaue <lastmod>-Zeitstempel-Tags so zeitnah wie möglich hinzu.
Google überprüft eine Sitemap nicht jedes Mal, wenn eine Website gecrawlt wird. Wenn es also aktualisiert wird, ist es am besten, Google darauf aufmerksam zu machen. Senden Sie dazu einen GET-Request in Ihrem Browser oder über die Kommandozeile an:
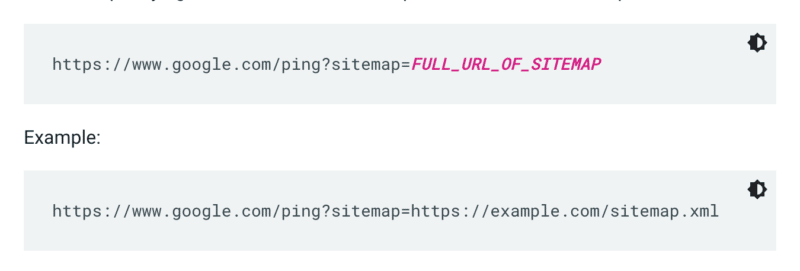
Geben Sie außerdem die Pfade zur Sitemap in der robots.txt-Datei an und übermitteln Sie sie mithilfe des Sitemaps-Berichts an die Google Search Console.
In der Regel wird Google URLs in Sitemaps häufiger crawlen als andere. Aber selbst wenn ein kleiner Prozentsatz der URLs in Ihrer Sitemap von geringer Qualität ist, kann dies den Googlebot davon abhalten, sie zum Crawlen von Vorschlägen zu verwenden.
XML-Sitemaps und -Links fügen URLs zur regulären Crawl-Warteschlange hinzu. Es gibt auch eine Prioritäts-Crawl-Warteschlange, für die es zwei Eingabemethoden gibt.
Erstens können Sie für diejenigen mit Stellenausschreibungen oder Live-Videos URLs an die Indexierungs-API von Google senden.
Oder wenn Sie die Aufmerksamkeit von Microsoft Bing oder Yandex auf sich ziehen möchten, können Sie die IndexNow-API für jede URL verwenden. In meinen eigenen Tests hatte es jedoch einen begrenzten Einfluss auf das Crawlen von URLs. Wenn Sie also IndexNow verwenden, achten Sie darauf, die Crawling-Effizienz für Bingbot zu überwachen.
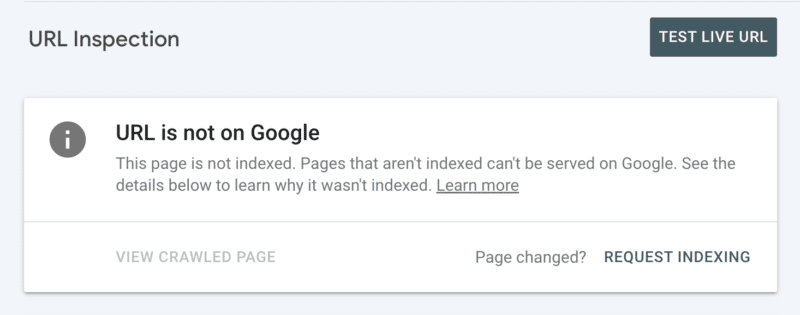
Zweitens können Sie die Indizierung manuell anfordern, nachdem Sie die URL in der Search Console überprüft haben. Beachten Sie jedoch, dass es ein tägliches Kontingent von 10 URLs gibt und das Crawlen dennoch einige Stunden dauern kann. Es ist am besten, dies als temporären Patch zu sehen, während Sie nach der Wurzel Ihres Crawling-Problems suchen.
So prüfen Sie, ob Googlebot Crawling-Anleitungen für den Googlebot benötigt
In der Google Search Console zeigt Ihre XML-Sitemap den Status „Erfolg“ und wurde kürzlich gelesen.
5. Sagen Sie Suchmaschinen-Spidern, was sie nicht crawlen sollen
Einige Seiten können für Benutzer oder Websitefunktionen wichtig sein, aber Sie möchten nicht, dass sie in den Suchergebnissen erscheinen. Verhindern Sie, dass solche URL-Routen Crawler ablenken, indem Sie die robots.txt-Datei nicht zulassen. Dies könnte beinhalten:
- APIs und CDNs . Wenn Sie beispielsweise ein Kunde von Cloudflare sind, stellen Sie sicher, dass Sie den Ordner /cdn-cgi/ nicht zulassen, der Ihrer Website hinzugefügt wird.
- Unwichtige Bilder, Skripte oder Stildateien , wenn die ohne diese Ressourcen geladenen Seiten nicht wesentlich von dem Verlust betroffen sind.
- Funktionale Seite , z. B. ein Einkaufswagen.
- Unendliche Leerzeichen , wie sie beispielsweise durch Kalenderseiten entstehen.
- Parameterseiten . Besonders solche aus der Facettennavigation, die filtern (z. B. ?Preisspanne=20-50), neu ordnen (z. B. ?sort=) oder suchen (z. B. ?q=), da jede einzelne Kombination von Crawlern als separate Seite gezählt wird.
Achten Sie darauf, den Paginierungsparameter nicht vollständig zu blockieren. Eine Crawling-Paginierung bis zu einem bestimmten Punkt ist für den Googlebot oft unerlässlich, um Inhalte zu entdecken und den internen Linkwert zu verarbeiten. (Sehen Sie sich dieses Semrush-Webinar zum Thema Paginierung an, um mehr über das Warum zu erfahren.)
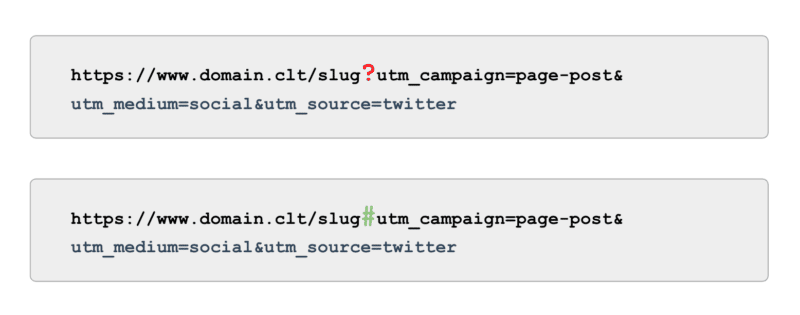
Und wenn es um das Tracking geht, verwenden Sie statt UTM-Tags, die von Parametern (auch bekannt als „?“) unterstützt werden, Anker (auch bekannt als „#“). Es bietet die gleichen Berichtsvorteile in Google Analytics, ohne dass es gecrawlt werden kann.
So prüfen Sie, ob der Googlebot keine Anleitung zum Crawlen enthält
Sehen Sie sich das Beispiel für „Indexierte, nicht in Sitemap eingereichte“ URLs in der Google Search Console an. Abgesehen von den ersten Seiten der Paginierung, welche anderen Pfade finden Sie? Sollen sie in eine XML-Sitemap aufgenommen, für das Crawlen gesperrt oder gelassen werden?
Überprüfen Sie auch die Liste „Entdeckt – derzeit nicht indexiert“ – Blockieren Sie in robots.txt alle URL-Pfade, die für Google keinen oder nur einen geringen Wert bieten.
Um dies auf die nächste Stufe zu heben, überprüfen Sie alle Googlebot-Smartphone-Crawls in den Serverprotokolldateien auf wertlose Pfade.
6. Kuratieren Sie relevante Links
Backlinks zu einer Seite sind für viele Aspekte der SEO wertvoll, und Crawling ist da keine Ausnahme. Es kann jedoch für bestimmte Seitentypen schwierig sein, externe Links zu erhalten. Zum Beispiel tiefe Seiten wie Produkte, Kategorien auf den unteren Ebenen in der Seitenarchitektur oder sogar Artikel.
Andererseits sind relevante interne Links:
- Technisch skalierbar.
- Leistungsstarke Signale an den Googlebot, um eine Seite für das Crawlen zu priorisieren.
- Besonders wirkungsvoll beim Deep-Page-Crawling.
Breadcrumbs, verwandte Inhaltsblöcke, schnelle Filter und die Verwendung gut kuratierter Tags sind alle von erheblichem Nutzen für die Crawling-Effizienz. Da es sich um SEO-kritische Inhalte handelt, stellen Sie sicher, dass solche internen Links nicht von JavaScript abhängig sind, sondern verwenden Sie stattdessen einen standardmäßigen, crawlbaren <a>-Link.
Bedenkt man, dass solche internen Links auch einen tatsächlichen Mehrwert für den Benutzer haben sollten.
Wie Sie nach relevanten Links suchen
Führen Sie einen manuellen Crawl Ihrer gesamten Website mit einem Tool wie der SEO-Spinne von ScreamingFrog durch und suchen Sie nach:
- Verwaiste URLs.
- Interne Links durch robots.txt blockiert.
- Interne Links zu allen Statuscodes, die nicht 200 sind.
- Der Prozentsatz intern verlinkter nicht indexierbarer URLs.
7. Prüfen Sie verbleibende Crawling-Probleme
Wenn alle oben genannten Optimierungen abgeschlossen sind und Ihre Crawling-Effizienz suboptimal bleibt, führen Sie ein Deep-Dive-Audit durch.
Überprüfen Sie zunächst die Beispiele aller verbleibenden Google Search Console-Ausschlüsse, um Crawling-Probleme zu identifizieren.
Sobald diese behoben sind, gehen Sie tiefer, indem Sie ein manuelles Crawling-Tool verwenden, um alle Seiten in der Websitestruktur zu crawlen, wie es der Googlebot tun würde. Vergleichen Sie dies mit den auf Googlebot-IPs eingegrenzten Protokolldateien, um zu verstehen, welche dieser Seiten gecrawlt werden und welche nicht.
Beginnen Sie schließlich mit der Protokolldateianalyse, die sich auf die Googlebot-IP für Daten von mindestens vier Wochen, idealerweise mehr, beschränkt.
Wenn Sie mit dem Format von Protokolldateien nicht vertraut sind, nutzen Sie ein Protokollanalysetool. Letztendlich ist dies die beste Quelle, um zu verstehen, wie Google Ihre Website crawlt.
Sobald Ihr Audit abgeschlossen ist und Sie über eine Liste der identifizierten Crawling-Probleme verfügen, ordnen Sie jedes Problem nach dem erwarteten Aufwand und der Auswirkung auf die Leistung.
Hinweis : Andere SEO-Experten haben erwähnt, dass Klicks von den SERPs das Crawlen der Zielseiten-URL erhöhen. Allerdings konnte ich dies noch nicht durch Tests bestätigen.
Priorisieren Sie die Crawling-Effizienz gegenüber dem Crawling-Budget
Das Ziel des Crawlings besteht nicht darin, die größtmögliche Menge an Crawling zu erzielen oder jede Seite einer Website wiederholt zu crawlen, sondern ein Crawling von SEO-relevanten Inhalten so nah wie möglich an der Erstellung oder Aktualisierung einer Seite zu verleiten.
Insgesamt spielt das Budget keine Rolle. Es zählt, was Sie investieren.
Die in diesem Artikel geäußerten Meinungen sind die des Gastautors und nicht unbedingt Search Engine Land. Mitarbeiter Autoren sind hier aufgelistet.