
Eine Anleitung zur Diagnose häufiger JavaScript-SEO-Probleme
Veröffentlicht: 2023-07-10Seien wir ehrlich: JavaScript und SEO passen nicht immer gut zusammen. Für einige SEOs kann das Thema wie ein Schleier der Komplexität wirken.
Nun, die gute Nachricht: Wenn man die einzelnen Ebenen durchblättert, kommt es bei vielen JavaScript-basierten SEO-Problemen zunächst auf die Grundlagen der Interaktion von Suchmaschinen-Crawlern mit JavaScript an.
Wenn Sie also diese Grundlagen verstehen, können Sie sich mit Problemen befassen, ihre Auswirkungen verstehen und mit Entwicklern zusammenarbeiten, um die wichtigen Probleme zu beheben.
In diesem Artikel helfen wir bei der Diagnose einiger häufiger Probleme, wenn Websites auf JS-Frameworks erstellt werden. Darüber hinaus werden wir das Grundwissen aufschlüsseln, das jede technische SEO für das Rendering benötigt.
Rendering auf den Punkt gebracht
Bevor wir uns den detaillierteren Dingen zuwenden, lassen Sie uns über das Gesamtbild sprechen.
Damit eine Suchmaschine Inhalte verstehen kann, die auf JavaScript basieren, muss sie die Seite crawlen und rendern.
Das Problem besteht darin, dass Suchmaschinen nur eine begrenzte Menge an Ressourcen zur Verfügung haben und daher selektiv entscheiden müssen, wann es sich lohnt, sie zu nutzen. Es ist nicht selbstverständlich, dass eine Seite gerendert wird, selbst wenn der Crawler sie an die Rendering-Warteschlange sendet.
Wenn die Seite nicht gerendert wird oder der Inhalt nicht richtig gerendert werden kann, liegt möglicherweise ein Problem vor.
Es kommt darauf an, wie das Frontend HTML in der ersten Serverantwort bereitstellt.
Wenn eine URL im Browser erstellt wird, generiert ein Frontend wie React, Vue oder Gatsby den HTML-Code für die Seite. Ein Crawler prüft, ob dieser HTML-Code bereits vom Server verfügbar ist („vorgerenderter“ HTML-Code), bevor er die URL sendet, um auf das Rendern zu warten, damit er sich den resultierenden Inhalt ansehen kann.
Ob vorgerendertes HTML verfügbar ist, hängt von der Konfiguration des Frontends ab. Der HTML-Code wird entweder über den Server oder im Client-Browser generiert.
Serverseitiges Rendering
Der Name ist Programm. In einem SSR-Setup wird dem Crawler eine vollständig gerenderte HTML-Seite zugeführt, ohne dass eine zusätzliche JS-Ausführung und -Renderung erforderlich ist.
Selbst wenn die Seite nicht gerendert wird, kann die Suchmaschine also dennoch jeglichen HTML-Code crawlen, die Seite kontextualisieren (Metadaten, Kopie, Bilder) und ihre Beziehung zu anderen Seiten verstehen (Breadcrumbs, kanonische URL, interne Links).
Clientseitiges Rendering
Bei CSR wird der HTML-Code zusammen mit allen JavaScript-Komponenten im Browser generiert. Das JavaScript muss gerendert werden, bevor der HTML-Code zum Crawlen verfügbar ist.
Wenn der Rendering-Dienst beschließt, eine an die Warteschlange gesendete Seite nicht zu rendern, bleiben Kopien, interne URLs, Bildlinks und sogar Metadaten für Crawler nicht verfügbar.
Infolgedessen haben Suchmaschinen kaum oder gar keinen Kontext, um die Relevanz einer URL für Suchanfragen zu verstehen.
Hinweis : Es kann eine Mischung aus HTML geben, das in der ersten HTML-Antwort bereitgestellt wird, und HTML, das zum Rendern (Erscheinen) die Ausführung von JS erfordert. Dies hängt von mehreren Faktoren ab, zu den häufigsten gehören das Framework, die Art und Weise, wie einzelne Site-Komponenten erstellt werden, und die Serverkonfiguration.
Das JavaScript-SEO-Toolkit
Es gibt sicherlich Tools, die dabei helfen, JavaScript-bezogene SEO-Probleme zu erkennen.
Sie können viele Untersuchungen mithilfe von Browser-Tools und der Google Search Console durchführen. Hier ist die Auswahlliste, die ein solides Toolkit ausmacht:
- Quelle anzeigen: Klicken Sie mit der rechten Maustaste auf eine Seite und klicken Sie auf „Quelle anzeigen“, um den vorgerenderten HTML-Code der Seite (die erste Serverantwort) anzuzeigen.
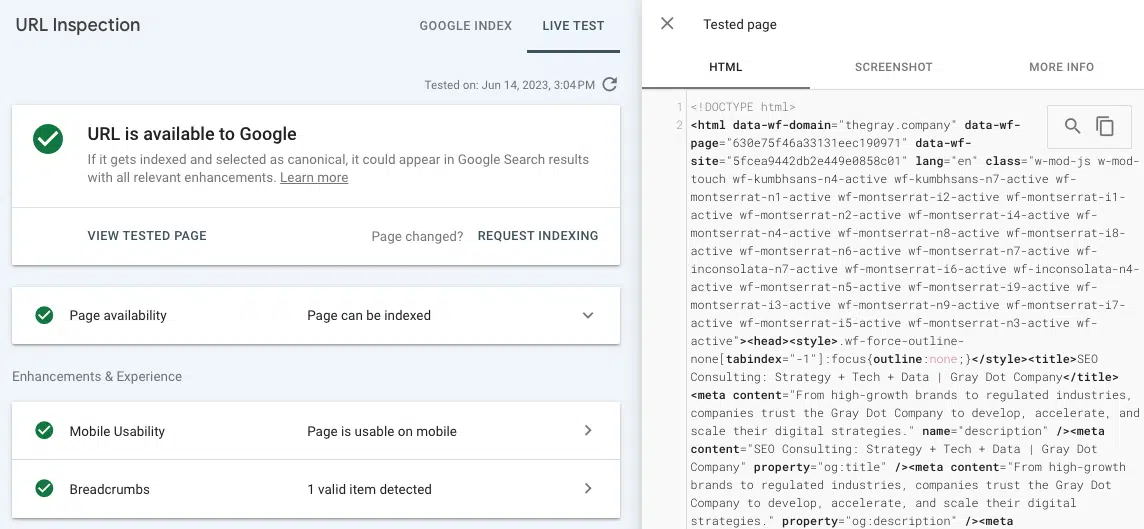
- Live-URL testen (URL-Inspektion): Sehen Sie sich einen Screenshot, HTML und andere wichtige Details einer gerenderten Seite auf der Registerkarte „URL-Inspektion“ der Google Search Console an. (Viele Rendering-Probleme können gefunden werden, indem der vorgerenderte HTML-Code aus „Quelle anzeigen“ mit dem gerenderten HTML-Code aus dem Testen der Live-URL in GSC verglichen wird.)
- Chrome-Entwicklertools: Klicken Sie mit der rechten Maustaste auf eine Seite und wählen Sie „Inspizieren“, um Tools zum Anzeigen von JavaScript-Fehlern und mehr zu öffnen.
- Wappalyzer: Sehen Sie sich den Stack an, auf dem jede Website aufbaut, und erhalten Sie Framework-spezifische Erkenntnisse, indem Sie diese kostenlose Chrome-Erweiterung installieren.
Häufige JavaScript-SEO-Probleme
Problem 1: Vorgerendertes HTML ist allgemein nicht verfügbar
Zusätzlich zu den bereits erwähnten negativen Auswirkungen auf das Crawling und die Kontextualisierung gibt es auch das Problem der Zeit und Ressourcen, die eine Suchmaschine für die Darstellung einer Seite benötigen könnte.
Wenn der Crawler beschließt, eine URL dem Rendering-Prozess zu unterziehen, landet sie in der Rendering-Warteschlange. Dies geschieht, weil ein Crawler möglicherweise eine Diskrepanz zwischen der vorgerenderten und der gerenderten HTML-Struktur erkennt. (Was sehr sinnvoll ist, wenn kein vorgerendertes HTML vorhanden ist!)
Es gibt keine Garantie dafür, wie lange eine URL auf den Web-Rendering-Dienst wartet. Der beste Weg, das WRS zu einer zeitgerechten Wiedergabe zu bewegen, besteht darin, sicherzustellen, dass es auf der Website wichtige Autoritätssignale gibt, die die Wichtigkeit einer URL veranschaulichen (z. B. im oberen Navigationsbereich verlinkt, viele interne Links, die als kanonisch bezeichnet werden). Das wird etwas kompliziert, da auch die Autoritätssignale gecrawlt werden müssen.
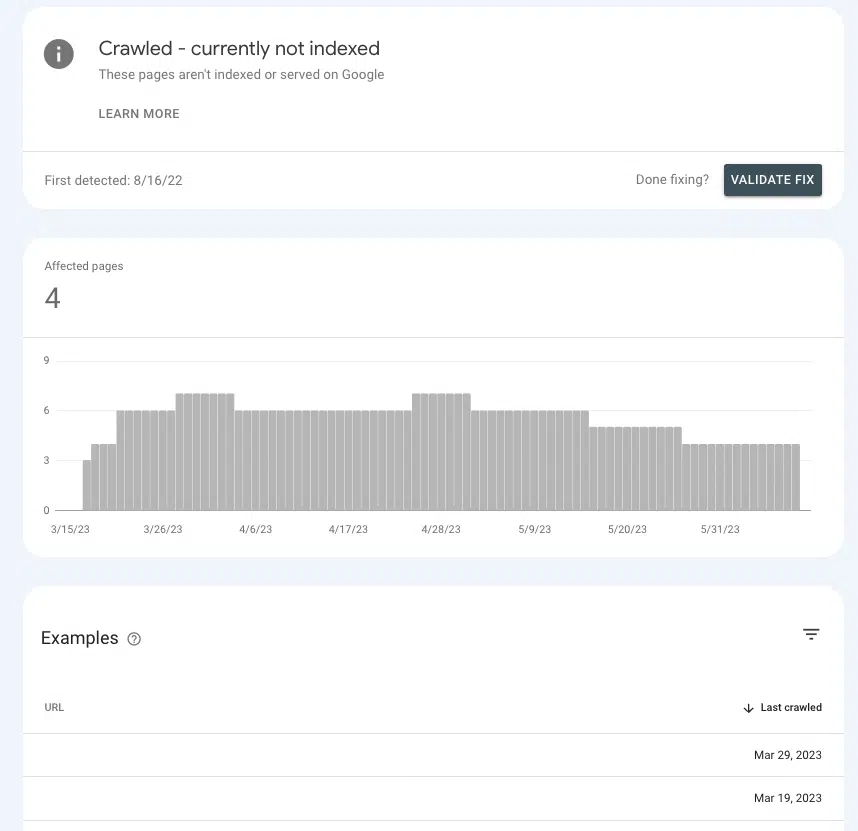
In der Google Search Console können Sie ein Gefühl dafür bekommen, ob Sie die richtigen Autoritätssignale an wichtige Seiten senden oder diese in der Schwebe lassen.
Gehen Sie zu Seiten > Seitenindizierung > Gecrawlt – derzeit nicht indiziert und suchen Sie nach Prioritätsseiten in der Liste.
Wenn sie im Wartezimmer bleiben, liegt das daran, dass Google nicht feststellen kann, ob sie wichtig genug sind, um Ressourcen dafür aufzuwenden.
Häufige Ursachen
Standardeinstellungen
Die meisten gängigen Frontends sind standardmäßig auf clientseitiges Rendering eingestellt, sodass die Wahrscheinlichkeit recht hoch ist, dass die Standardeinstellungen der Übeltäter sind.
Wenn Sie sich fragen, warum die meisten Frontends standardmäßig auf CSR setzen, liegt das an den Leistungsvorteilen. Entwickler mögen SSR nicht immer, weil es die Möglichkeiten zur Beschleunigung einer Website und zur Implementierung bestimmter interaktiver Elemente (z. B. einzigartige Übergänge zwischen Seiten) einschränken kann.
Einseitige Bewerbung
Wenn es sich bei einer Website um eine Einzelseitenanwendung handelt, ist sie vollständig in JavaScript eingebettet und generiert alle Komponenten einer Seite im Browser (auch bekannt als „alles“), wird clientseitig gerendert und neue Seiten werden ohne Neuladen bereitgestellt.
Dies hat einige negative Auswirkungen, von denen die vielleicht wichtigste darin besteht, dass Seiten möglicherweise nicht auffindbar sind.
Das soll nicht heißen, dass es unmöglich ist, ein SPA SEO-freundlicher einzurichten. Aber die Chancen stehen gut, dass erhebliche Entwicklungsarbeit erforderlich sein wird, um dies zu erreichen.
Problem 2: Einige Seiteninhalte sind für Crawler nicht zugänglich
Es ist großartig, eine Suchmaschine dazu zu bringen, eine URL zu rendern, solange alle Elemente zum Crawlen verfügbar sind. Was passiert, wenn die Seite zwar gerendert wird, aber Abschnitte auf der Seite vorhanden sind, auf die nicht zugegriffen werden kann?
Ein SEO führt beispielsweise eine interne Linkanalyse durch und findet kaum oder gar keine internen Links für eine URL, die auf mehreren Seiten verlinkt ist.
Wenn der Link im gerenderten HTML-Code des Tools „Live-URL testen“ nicht angezeigt wird, wird er wahrscheinlich in JavaScript-Ressourcen bereitgestellt, auf die Google nicht zugreifen kann.
Um den Übeltäter einzugrenzen, wäre es eine gute Idee, nach Gemeinsamkeiten in Bezug darauf zu suchen, wo sich der fehlende Seiteninhalt oder interne Links auf der Seite über die URLs hinweg befinden.
Wenn es sich beispielsweise um einen FAQ-Link handelt, der im selben Abschnitt jeder Produktseite angezeigt wird, trägt dies wesentlich dazu bei, Entwicklern dabei zu helfen, eine Lösung einzugrenzen.
Häufige Ursachen
JavaScript-Fehler
Beginnen wir hier mit einem Haftungsausschluss. Die meisten JavaScript-Fehler, auf die Sie stoßen, haben für die Suchmaschinenoptimierung keine Bedeutung.
Wenn Sie sich also auf die Suche nach Fehlern begeben, Ihrem Entwickler eine lange Liste vorlegen und das Gespräch mit „Was sind das für Fehler?“ beginnen, wird er es möglicherweise nicht so gut aufnehmen.
Gehen Sie auf das „Warum“ ein, indem Sie das Problem ansprechen, damit sie zum JavaScript-Experten werden können (weil sie es sind!).
Allerdings gibt es Syntaxfehler, die dazu führen können, dass der Rest der Seite nicht geparst werden kann (z. B. „Render-Blockierung“). In diesem Fall kann der Renderer die einzelnen HTML-Elemente nicht aufschlüsseln, den Inhalt im DOM nicht strukturieren oder Beziehungen verstehen.
Im Allgemeinen sind solche Fehler daran erkennbar, dass sie auch in der Browseransicht Auswirkungen haben.
Zusätzlich zur visuellen Bestätigung ist es auch möglich, JavaScript-Fehler anzuzeigen, indem Sie mit der rechten Maustaste auf die Seite klicken, „Inspizieren“ auswählen und zur Registerkarte „Konsole“ navigieren.
Erhalten Sie den täglichen Newsletter, auf den sich Suchmaschinenmarketing verlassen.
Siehe Bedingungen.

Inhalte erfordern eine Benutzerinteraktion
Eines der wichtigsten Dinge, die Sie beim Rendern beachten sollten, ist, dass Google keine Inhalte rendern kann, die eine Interaktion der Nutzer mit der Seite erfordern. Oder einfacher ausgedrückt: Es kann keine Dinge „klicken“.
Warum spielt das eine Rolle? Denken Sie an unseren alten, treuen Freund, das Akkordeon-Dropdown, und daran, wie viele Websites es zum Organisieren von Inhalten wie Produktdetails und FAQs verwenden.
Je nachdem, wie das Akkordeon codiert ist, kann Google den Inhalt im Dropdown-Menü möglicherweise nicht rendern, wenn es erst bei der Ausführung von JS ausgefüllt wird.
Um dies zu überprüfen, können Sie eine Seite „untersuchen“ und sehen, ob sich der „versteckte“ Inhalt (der angezeigt wird, wenn Sie auf ein Akkordeon klicken) im HTML befindet.
Ist dies nicht der Fall, bedeutet das, dass Googlebot und andere Crawler diesen Inhalt in der gerenderten Version der Seite nicht sehen.
Problem 3: Abschnitte einer Website werden nicht gecrawlt
Google rendert Ihre Seite möglicherweise nicht, wenn es sie crawlt und an die Warteschlange sendet. Wenn die Seite nicht gecrawlt wird, ist selbst diese Chance vom Tisch.
Um zu verstehen, ob Google Seiten crawlt, kann der Bericht „Crawling-Statistiken“ hilfreich sein : Einstellungen > Crawl-Statistiken .
Wählen Sie Crawl-Anfragen: OK (200), um alle Crawl-Instanzen von 200 Statusseiten in den letzten drei Monaten anzuzeigen. Verwenden Sie dann die Filterung, um nach einzelnen URLs oder ganzen Verzeichnissen zu suchen.
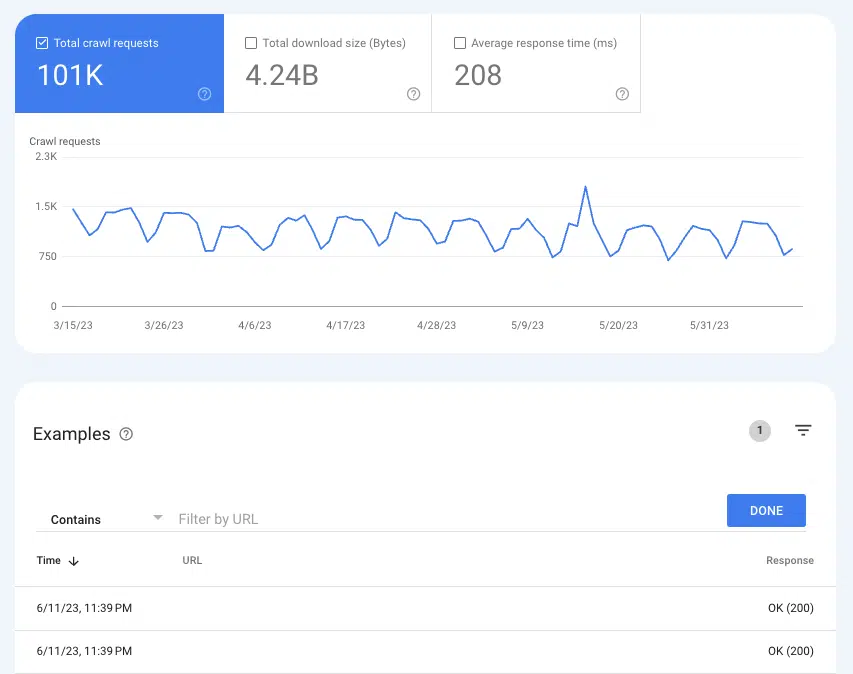
Wenn die URLs nicht in den Crawling-Protokollen angezeigt werden, besteht eine gute Chance, dass Google die Seiten nicht erkennen und crawlen kann (oder es handelt sich nicht um 200 Seiten, was ein ganz anderes Problem ist).
Häufige Ursachen
Interne Links sind nicht crawlbar
Links sind die Verkehrszeichen, denen Crawler folgen, um zu neuen Seiten zu gelangen. Das ist einer der Gründe, warum verwaiste Seiten ein so großes Problem darstellen.
Wenn Sie über eine gut verlinkte Website verfügen und bei Ihren Website-Prüfungen verwaiste Seiten auftauchen, besteht eine gute Chance, dass die Links im vorgerenderten HTML-Code nicht verfügbar sind.
Eine einfache Möglichkeit zur Überprüfung besteht darin, eine URL aufzurufen, die auf die gemeldete verwaiste Seite verweist. Klicken Sie mit der rechten Maustaste auf die Seite und klicken Sie auf „Quelle anzeigen“.
Verwenden Sie dann CMD + f, um nach der URL der verwaisten Seite zu suchen. Wenn es nicht im vorgerenderten HTML-Code erscheint, aber beim Rendern im Browser auf der Seite erscheint, fahren Sie mit Punkt vier fort.
XML-Sitemap nicht aktualisiert
Die XML-Sitemap ist entscheidend, um Google dabei zu helfen, neue Seiten zu entdecken und zu verstehen, welche URLs bei einem Crawl priorisiert werden sollen.
Ohne die XML-Sitemap ist die Seitenerkennung nur über das Folgen von Links möglich.
Bei Websites ohne vorgerenderten HTML-Code bedeutet eine veraltete oder fehlende Sitemap also, dass man darauf warten muss, dass Google Seiten rendert, internen Links zu anderen Seiten folgt, sie in die Warteschlange stellt, rendert, ihren Links folgt und so weiter.
Abhängig vom verwendeten Frontend haben Sie möglicherweise Zugriff auf Plugins, die dynamische XML-Sitemaps erstellen können.
Da sie oft angepasst werden müssen, ist es wichtig, dass SEOs sorgfältig alle URLs dokumentieren, die nicht in der Sitemap enthalten sein sollten, und die Logik dafür angeben, warum das so ist.
Dies sollte relativ einfach zu überprüfen sein, indem Sie die Sitemap mit Ihrem bevorzugten SEO-Tool ausführen.
Problem 4: Interne Links fehlen
Die Nichtverfügbarkeit interner Links für Crawler ist nicht nur ein potenzielles Entdeckungsproblem, sondern auch ein Eigenkapitalproblem. Da Links SEO-Equity von der Referenz-URL an die Ziel-URL weitergeben, sind sie ein wichtiger Faktor für die Steigerung der Seiten- und Domain-Autorität.
Ein gutes Beispiel sind Links von der Homepage. Es handelt sich im Allgemeinen um die Seite mit der höchsten Autorität auf einer Website, daher hat ein Link zu einer anderen Seite von der Homepage eine große Bedeutung.
Wenn diese Links nicht gecrawlt werden können, ist es ein bisschen so, als hätte man ein kaputtes Lichtschwert. Eines Ihrer mächtigsten Werkzeuge wird nutzlos gemacht (Wortspiel beabsichtigt).
Häufige Ursachen
Benutzerinteraktion erforderlich, um zum Link zu gelangen
Das Akkordeon-Beispiel, das wir zuvor verwendet haben, ist nur ein Fall, in dem Inhalte hinter einer Benutzerinteraktion verborgen sind. Eine weitere Möglichkeit, die weitreichende Auswirkungen haben kann, ist die unendliche Scroll-Paginierung – insbesondere für E-Commerce-Websites mit umfangreichen Produktkatalogen.
Bei einem Infinite-Scroll-Setup werden unzählige Produkte auf einer Produktlistenseite (Kategorieseite) nicht geladen, es sei denn, ein Benutzer scrollt über einen bestimmten Punkt hinaus (Lazy Loading) oder tippt auf die Schaltfläche „Mehr anzeigen“.
Selbst wenn das JavaScript gerendert wird, kann ein Crawler nicht auf die internen Links für Produkte zugreifen, die noch geladen werden müssen. Das Laden aller dieser Produkte auf einer Seite würde sich jedoch aufgrund der schlechten Seitenleistung negativ auf die Benutzererfahrung auswirken.
Aus diesem Grund bevorzugen SEOs im Allgemeinen eine echte Paginierung, bei der jede Ergebnisseite eine eindeutige, crawlbare URL hat.
Zwar gibt es Möglichkeiten für eine Website, Lazy Loading zu optimieren und alle Produkte zum vorgerenderten HTML hinzuzufügen, dies würde jedoch zu Unterschieden zwischen dem gerenderten HTML und dem vorgerenderten HTML führen.
Dies schafft effektiv einen Grund, mehr Seiten an die Render-Warteschlange zu senden und Crawler mehr arbeiten zu lassen als nötig – und wir wissen, dass das nicht gut für SEO ist.
Befolgen Sie mindestens die Empfehlungen von Google zur Optimierung des unendlichen Scrollens.
Links nicht richtig codiert
Wenn Google eine Website crawlt oder eine URL in der Warteschlange rendert, lädt es eine zustandslose Version einer Seite herunter. Das ist einer der Gründe, warum es so wichtig ist, die richtigen href-Tags und Anker zu verwenden (die Linkstruktur, die Sie am häufigsten sehen). Ein Crawler kann Linkformaten wie Router, Span oder OnClick nicht folgen.
Kann folgen:
- <a href="https://example.com">
- <a href="/relative/path/file">
Kann nicht folgen:
- <a routerLink="some/path">
- <span href="https://example.com">
- <a>
Für Entwickler sind dies alles gültige Methoden zum Codieren von Links. SEO-Auswirkungen sind eine zusätzliche Kontextebene, und es ist nicht ihre Aufgabe, das zu wissen – es ist die der SEO.
Ein großer Teil der Arbeit einer guten SEO besteht darin, Entwicklern diesen Kontext durch Dokumentation bereitzustellen.
Problem 5: Metadaten fehlen
In einer HTML-Seite sind Metadaten wie Titel, Beschreibung, kanonische URL und Meta-Robots-Tag alle im Kopf verschachtelt.
Aus offensichtlichen Gründen sind fehlende Metadaten schädlich für SEO, vor allem aber für SPAs. Elemente wie eine selbstreferenzierende kanonische URL sind entscheidend, um die Chancen einer JS-Seite zu verbessern, die Rendering-Warteschlange erfolgreich zu durchlaufen.
Von allen Elementen, die im vorgerenderten HTML vorhanden sein sollten, ist der Kopf für die Indexierung am wichtigsten.
Glücklicherweise ist dieses Problem ziemlich leicht zu erkennen, da es in jedem SEO-Tool, das eine Website für Hygieneberichte verwendet, eine Fülle von Fehlern aufgrund fehlender Metadaten auslöst. Anschließend können Sie dies bestätigen, indem Sie im Quellcode nach dem Kopf suchen.
Häufige Ursachen
Fehlende oder falsch konfigurierte Metadaten des Fahrzeugs
In einem JS-Framework erstellt ein Plugin den Kopf und fügt die Metadaten in den Kopf ein. (Das beliebteste Beispiel ist React Helmet.) Auch wenn ein Plugin bereits installiert ist, muss es normalerweise richtig konfiguriert werden.
Auch hier ist es ein Bereich, in dem SEOs lediglich das Problem dem Entwickler vortragen, das Warum erklären und eng auf gut dokumentierte Akzeptanzkriterien hinarbeiten können.
Problem 6: Ressourcen werden nicht gecrawlt
Skriptdateien und Bilder sind wesentliche Bausteine im Rendering-Prozess.
Da sie auch über eigene URLs verfügen, gelten auch für sie die Gesetze der Crawlbarkeit. Wenn das Crawlen der Dateien blockiert ist, kann Google die Seite nicht analysieren, um sie darzustellen.
Um zu sehen, ob URLs gecrawlt werden, können Sie frühere Anfragen in den GSC-Crawling-Statistiken anzeigen.
- Bilder: Gehen Sie zu Einstellungen > Crawl-Statistiken > Crawl-Anfragen: Bild
- JavaScript: Gehen Sie zu Einstellungen > Crawl-Statistiken > Crawl-Anfragen: Bild
Häufige Ursachen
Verzeichnis durch robots.txt blockiert
Sowohl Skript- als auch Bild-URLs sind im Allgemeinen in ihrer eigenen dedizierten Subdomäne oder ihrem eigenen Unterordner verschachtelt, sodass ein Disallow-Ausdruck in der robots.txt das Crawlen verhindert.
Einige SEO-Tools sagen Ihnen, ob Skript- oder Bilddateien blockiert sind. Das Problem lässt sich jedoch recht leicht erkennen, wenn Sie wissen, wo Ihre Bilder und Skriptdateien verschachtelt sind. Sie können in der robots.txt nach diesen URL-Strukturen suchen.
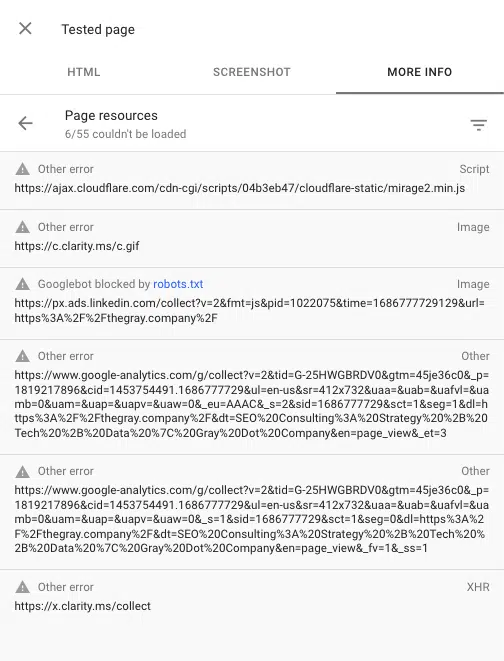
Sie können auch alle beim Rendern einer Seite blockierten Skripte sehen, indem Sie das URL-Inspektionstool in der Google Search Console verwenden. „Live-URL testen“ und dann zu „ Getestete Seite anzeigen“ > „Weitere Informationen“ > „Seitenressourcen“ gehen.
Hier sehen Sie alle Skripte, die während des Rendervorgangs nicht geladen werden können. Wenn eine Datei von robots.txt blockiert wird, wird sie als solche markiert.
Freunde dich mit JavaScript an
Ja, JavaScript kann einige SEO-Probleme mit sich bringen. Aber mit der Weiterentwicklung von SEO werden Best Practices zum Synonym für ein großartiges Benutzererlebnis.
Eine großartige Benutzererfahrung hängt oft von JavaScript ab. Auch wenn die Aufgabe eines SEOs nicht darin besteht, JavaScript zu programmieren, müssen wir wissen, wie Suchmaschinen damit interagieren, es rendern und verwenden.
Mit einem soliden Verständnis des Rendering-Prozesses und einiger häufiger SEO-Probleme in JS-Frameworks sind Sie auf dem besten Weg, die Probleme zu identifizieren und Ihren Entwicklern ein starker Verbündeter zu sein.
Die in diesem Artikel geäußerten Meinungen sind die des Gastautors und nicht unbedingt die von Search Engine Land. Die Autoren unserer Mitarbeiter sind hier aufgelistet.