
Entity SEO: Der definitive Leitfaden
Veröffentlicht: 2023-04-06Dieser Artikel wurde von Andrew Ansley mitverfasst .
Dinge, keine Saiten. Falls Sie dies noch nicht gehört haben, es stammt aus einem berühmten Google-Blogbeitrag, der den Knowledge Graph ankündigte.
Der 11. Jahrestag der Ankündigung ist nur noch einen Monat entfernt, aber viele haben immer noch Schwierigkeiten zu verstehen, was „Dinge, nicht Zeichenketten“ wirklich für SEO bedeutet.
Das Zitat ist ein Versuch zu vermitteln, dass Google die Dinge versteht und kein einfacher Keyword-Erkennungsalgorithmus mehr ist.
Im Mai 2012 könnte man argumentieren, dass Entity SEO geboren wurde. Das maschinelle Lernen von Google, unterstützt durch halbstrukturierte und strukturierte Wissensdatenbanken, könnte die Bedeutung hinter einem Schlüsselwort verstehen.
Die mehrdeutige Natur der Sprache hatte endlich eine langfristige Lösung.
Wenn also Entitäten für Google seit über einem Jahrzehnt wichtig sind, warum sind SEOs immer noch verwirrt über Entitäten?
Gute Frage. Ich sehe vier Gründe:
- Entity SEO als Begriff wurde nicht weit genug verwendet, damit SEOs sich mit seiner Definition anfreunden und ihn daher in ihr Vokabular aufnehmen konnten.
- Die Optimierung für Entitäten überschneidet sich stark mit den alten Keyword-fokussierten Optimierungsmethoden. Infolgedessen werden Entitäten mit Schlüsselwörtern verschmolzen. Darüber hinaus war nicht klar, welche Rolle Entitäten bei der Suchmaschinenoptimierung spielen, und das Wort „Entitäten“ ist manchmal austauschbar mit „Themen“, wenn Google über das Thema spricht.
- Entitäten zu verstehen ist eine langweilige Aufgabe. Wenn Sie tiefgreifende Kenntnisse über Entitäten wünschen, müssen Sie einige Google-Patente lesen und die Grundlagen des maschinellen Lernens kennen. Entity SEO ist ein weitaus wissenschaftlicherer Ansatz für SEO – und Wissenschaft ist einfach nicht jedermanns Sache.
- Während YouTube die Wissensverteilung massiv beeinflusst hat, hat es die Lernerfahrung für viele Fächer abgeflacht. Die YouTuber mit dem größten Erfolg auf der Plattform haben in der Vergangenheit den einfachen Weg gewählt, um ihr Publikum zu informieren. Infolgedessen haben Ersteller von Inhalten bis vor kurzem nicht viel Zeit mit Entitäten verbracht. Aus diesem Grund müssen Sie von NLP-Forschern etwas über Entitäten lernen und dann das Wissen auf SEO anwenden. Patente und Forschungsarbeiten sind der Schlüssel. Dies bekräftigt noch einmal den ersten Punkt oben.
Dieser Artikel ist eine Lösung für alle vier Probleme, die SEOs daran gehindert haben, einen unternehmensbasierten SEO-Ansatz vollständig zu beherrschen.
Wenn Sie dies lesen, erfahren Sie:
- Was eine Entität ist und warum sie wichtig ist.
- Die Geschichte der semantischen Suche.
- Wie man Entitäten im SERP identifiziert und verwendet.
- So verwenden Sie Entitäten zum Ranking von Webinhalten.
Warum sind Entitäten wichtig?
Entity SEO ist die Zukunft, in die Suchmaschinen hinsichtlich der Auswahl der einzustufenden Inhalte und der Bestimmung ihrer Bedeutung gehen.
Kombinieren Sie dies mit wissensbasiertem Vertrauen, und ich glaube, dass Entitäts-SEO die Zukunft dessen sein wird, wie SEO in den nächsten zwei Jahren durchgeführt wird.
Beispiele für Entitäten
Wie erkennt man also eine Entität?
Das SERP enthält mehrere Beispiele für Entitäten, die Sie wahrscheinlich schon gesehen haben.
Die häufigsten Arten von Entitäten beziehen sich auf Standorte, Personen oder Unternehmen.
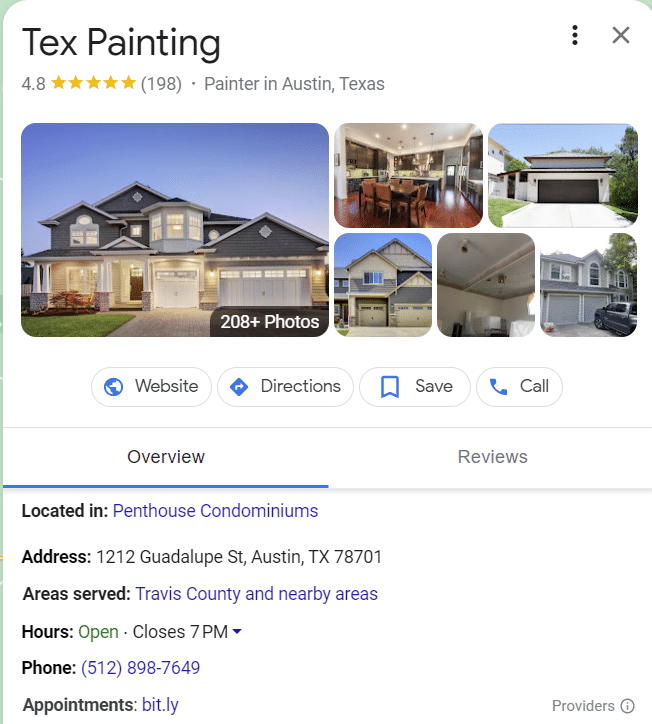
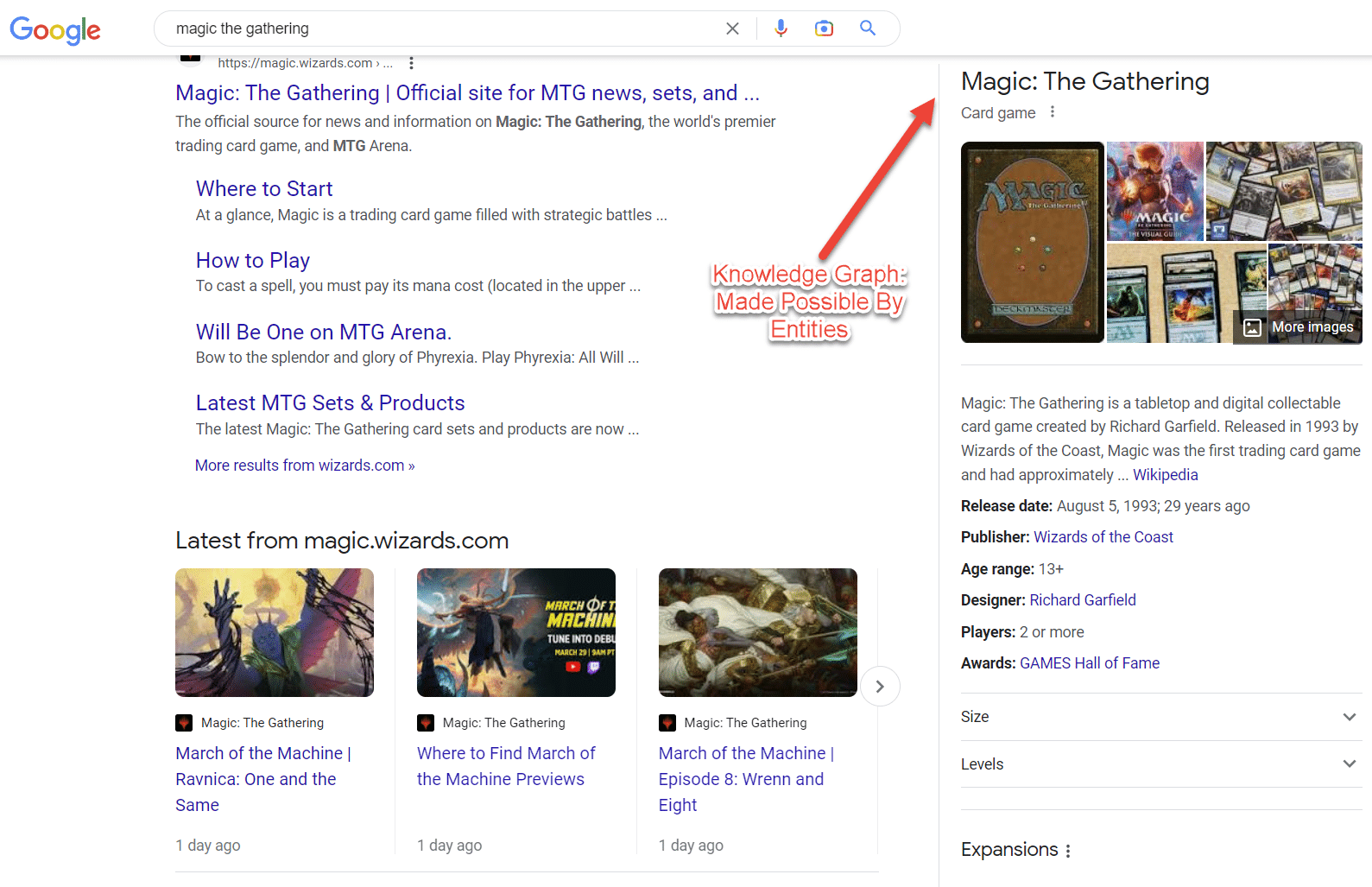
Das vielleicht beste Beispiel für Entitäten im SERP sind Intent-Cluster. Je besser ein Thema verstanden wird, desto mehr tauchen diese Suchmerkmale auf.
Interessanterweise kann eine einzelne SEO-Kampagne das Gesicht der SERP verändern, wenn Sie wissen, wie man unternehmensorientierte SEO-Kampagnen durchführt.
Wikipedia-Einträge sind ein weiteres Beispiel für Entitäten. Wikipedia bietet ein großartiges Beispiel für Informationen, die mit Entitäten verbunden sind.
Wie Sie oben links sehen können, hat die Entität alle möglichen Attribute, die mit „Fisch“ verbunden sind, von ihrer Anatomie bis zu ihrer Bedeutung für den Menschen.
Obwohl Wikipedia viele Datenpunkte zu einem Thema enthält, ist es keineswegs vollständig.
Was ist eine Entität?
Eine Entität ist ein eindeutig identifizierbares Objekt oder eine Sache, die durch Name(n), Typ(en), Attribute und Beziehungen zu anderen Entitäten gekennzeichnet ist. Eine Entität gilt nur dann als vorhanden, wenn sie in einem Entitätskatalog vorhanden ist.
Entitätskataloge weisen jeder Entität eine eindeutige ID zu. Meine Agentur verfügt über programmatische Lösungen, die die eindeutige ID verwenden, die jeder Entität zugeordnet ist (Dienstleistungen, Produkte und Marken sind alle enthalten).
Wenn sich ein Wort oder eine Phrase nicht in einem vorhandenen Katalog befindet, bedeutet dies nicht, dass das Wort oder die Phrase keine Entität ist, aber Sie können normalerweise anhand ihrer Existenz im Katalog erkennen, ob etwas eine Entität ist.
Es ist wichtig anzumerken, dass Wikipedia nicht der entscheidende Faktor dafür ist, ob etwas eine Entität ist, aber das Unternehmen ist am bekanntesten für seine Datenbank mit Entitäten.
Jeder Katalog kann verwendet werden, wenn es um Entitäten geht. Typischerweise ist eine Entität eine Person, ein Ort oder eine Sache, aber Ideen und Konzepte können ebenfalls enthalten sein.
Einige Beispiele für Entitätskataloge sind:
- Wikipedia
- Wikidata
- DBpedia
- Freebase
- Jago

Entitäten helfen dabei, die Kluft zwischen den Welten der unstrukturierten und strukturierten Daten zu überbrücken.
Sie können verwendet werden, um unstrukturierten Text semantisch anzureichern, während Textquellen verwendet werden können, um strukturierte Wissensbasen zu füllen.
Das Erkennen von Erwähnungen von Entitäten im Text und das Zuordnen dieser Erwähnungen zu den entsprechenden Einträgen in einer Wissensdatenbank ist als Aufgabe der Entitätsverknüpfung bekannt.
Entitäten ermöglichen ein besseres Verständnis der Bedeutung von Text, sowohl für Menschen als auch für Maschinen.
Während Menschen die Mehrdeutigkeit von Entitäten basierend auf dem Kontext, in dem sie erwähnt werden, relativ einfach auflösen können, stellt dies viele Schwierigkeiten und Herausforderungen für Maschinen dar.
Der Wissensdatenbankeintrag einer Entität fasst zusammen, was wir über diese Entität wissen.
Da sich die Welt ständig verändert, tauchen auch neue Fakten auf. Mit diesen Änderungen Schritt zu halten, erfordert kontinuierliche Anstrengungen von Redakteuren und Content-Managern. Dies ist eine anspruchsvolle Aufgabe im Maßstab.
Durch die Analyse der Inhalte von Dokumenten, in denen Entitäten erwähnt werden, kann das Finden neuer oder zu aktualisierender Fakten unterstützt oder sogar vollständig automatisiert werden.
Wissenschaftler bezeichnen dies als das Problem der Wissensbasispopulation, weshalb die Verknüpfung von Entitäten wichtig ist.
Entitäten erleichtern ein semantisches Verständnis des Informationsbedarfs des Benutzers, wie er durch die Schlüsselwortabfrage ausgedrückt wird, und des Inhalts des Dokuments. Entitäten können somit verwendet werden, um Abfrage- und/oder Dokumentdarstellungen zu verbessern.
In der Forschungsarbeit „Extended Named Entity“ identifiziert der Autor rund 160 Entitätstypen. Hier sind zwei von sieben Screenshots aus der Liste.


Bestimmte Kategorien von Entitäten sind einfacher zu definieren, aber es ist wichtig, sich daran zu erinnern, dass Konzepte und Ideen Entitäten sind. Diese beiden Kategorien sind für Google allein sehr schwer zu skalieren.
Sie können Google nicht mit nur einer einzigen Seite beibringen, wenn Sie mit vagen Konzepten arbeiten. Das Verständnis von Entitäten erfordert viele Artikel und viele Referenzen, die im Laufe der Zeit erhalten bleiben.
Googles Verlauf mit Entitäten
Am 16. Juli 2010 kaufte Google Freebase. Dieser Kauf war der erste große Schritt, der zum aktuellen Suchsystem für Entitäten führte.

Nach der Investition in Freebase erkannte Google, dass Wikidata eine bessere Lösung hatte. Google arbeitete dann daran, Freebase mit Wikidata zusammenzuführen, eine Aufgabe, die weitaus schwieriger war als erwartet.
Fünf Google-Wissenschaftler haben ein Papier mit dem Titel „From Freebase to Wikidata: The Great Migration“ geschrieben. Zu den wichtigsten Imbissbuden gehören.
„Freebase basiert auf den Begriffen Objekte, Fakten, Typen und Eigenschaften. Jedes Freebase-Objekt hat eine stabile Kennung namens „Mid“ (für Machine ID).“
„Das Datenmodell von Wikidata beruht auf den Begriffen Item und Statement. Ein Element stellt eine Entität dar, hat eine stabile Kennung namens „qid“ und kann Labels, Beschreibungen und Aliase in mehreren Sprachen haben; weitere Aussagen und Links zu Seiten über die Entität in anderen Wikimedia-Projekten – vor allem Wikipedia. Im Gegensatz zu Freebase zielen Wikidata-Aussagen nicht darauf ab, wahre Tatsachen zu verschlüsseln, sondern Behauptungen aus unterschiedlichen Quellen, die sich auch widersprechen können…“
Entitäten werden in diesen Wissensdatenbanken definiert, aber Google musste sein Entitätswissen für unstrukturierte Daten (z. B. Blogs) noch aufbauen.
Google ist eine Partnerschaft mit Bing und Yahoo eingegangen und hat Schema.org erstellt, um diese Aufgabe zu erfüllen.
Google stellt Schemaanweisungen bereit, sodass Website-Manager über Tools verfügen können, die Google dabei helfen, den Inhalt zu verstehen. Denken Sie daran, Google möchte sich auf Dinge konzentrieren, nicht auf Zeichenfolgen.
In Googles Worten:
„Sie können uns helfen, indem Sie Google explizite Hinweise auf die Bedeutung einer Seite geben, indem Sie strukturierte Daten auf der Seite einfügen. Strukturierte Daten sind ein standardisiertes Format, um Informationen über eine Seite bereitzustellen und den Seiteninhalt zu klassifizieren; zum Beispiel auf einer Rezeptseite, was sind die Zutaten, die Garzeit und -temperatur, die Kalorien und so weiter.“
Google fährt fort mit den Worten:
„Sie müssen alle erforderlichen Eigenschaften angeben, damit ein Objekt in der Google-Suche mit erweiterter Anzeige erscheinen kann. Im Allgemeinen kann die Definition weiterer empfohlener Funktionen die Wahrscheinlichkeit erhöhen, dass Ihre Informationen in den Suchergebnissen mit verbesserter Anzeige erscheinen. Es ist jedoch wichtiger, weniger, aber vollständige und genaue empfohlene Eigenschaften bereitzustellen, als zu versuchen, jede mögliche empfohlene Eigenschaft mit weniger vollständigen, schlecht formatierten oder ungenauen Daten bereitzustellen.“
Über Schema könnte noch mehr gesagt werden, aber es genügt zu sagen, dass Schema ein unglaubliches Werkzeug für SEOs ist, die den Seiteninhalt für Suchmaschinen klar machen wollen.
Das letzte Puzzleteil stammt aus der Blog-Ankündigung von Google mit dem Titel „Improving Search for The Next 20 Years“.
Dokumentenrelevanz und -qualität sind die Hauptgedanken hinter dieser Ankündigung. Die erste Methode, mit der Google den Inhalt einer Seite ermittelte, konzentrierte sich ausschließlich auf Keywords.
Google fügte dann Themenebenen zur Suche hinzu. Diese Schicht wurde durch Knowledge Graphs und durch systematisches Scraping und Strukturieren von Daten im gesamten Web ermöglicht.
Das bringt uns zum aktuellen Suchsystem. Google ist in weniger als 10 Jahren von 570 Millionen Entitäten und 18 Milliarden Fakten auf 800 Milliarden Fakten und 8 Milliarden Entitäten gewachsen. Wenn diese Zahl wächst, verbessert sich die Entitätssuche.
Inwiefern ist das Entitätsmodell eine Verbesserung gegenüber früheren Suchmodellen?
Herkömmliche schlüsselwortbasierte Information Retrieval (IR)-Modelle haben die inhärente Einschränkung, dass sie nicht in der Lage sind, (relevante) Dokumente abzurufen, die keine expliziten Begriffsübereinstimmungen mit der Abfrage haben.
Wenn Sie Strg + F verwenden, um Text auf einer Seite zu finden, verwenden Sie etwas Ähnliches wie das traditionelle schlüsselwortbasierte Informationsabrufmodell.
Jeden Tag werden wahnsinnig viele Daten im Internet veröffentlicht.
Es ist Google einfach nicht möglich, die Bedeutung jedes Wortes, jedes Absatzes, jedes Artikels und jeder Website zu verstehen.
Stattdessen stellen Entitäten eine Struktur bereit, anhand derer Google die Rechenlast minimieren und gleichzeitig das Verständnis verbessern kann.
„Konzeptbasierte Retrievalmethoden versuchen, diese Herausforderung anzugehen, indem sie sich auf Hilfsstrukturen stützen, um semantische Repräsentationen von Abfragen und Dokumenten in einem übergeordneten Konzeptraum zu erhalten. Solche Strukturen umfassen kontrollierte Vokabulare (Wörterbücher und Thesauri), Ontologien und Entitäten aus einem Wissensspeicher.“
– Entitätsorientierte Suche , Kapitel 8.3
Krisztian Balog, der das maßgebliche Buch über Entitäten geschrieben hat, identifiziert drei mögliche Lösungen für das traditionelle Modell des Informationsabrufs.
- Erweiterungsbasiert : Verwendet Entitäten als Quelle zum Erweitern der Abfrage um verschiedene Begriffe.
- Projektionsbasiert : Die Relevanz zwischen einer Abfrage und einem Dokument wird verstanden, indem sie auf einen latenten Raum von Entitäten projiziert werden
- Entitätsbasiert : Explizite semantische Darstellungen von Abfragen und Dokumenten werden im Entitätsraum erhalten, um die begriffsbasierten Darstellungen zu erweitern.
Das Ziel dieser drei Ansätze besteht darin, eine reichhaltigere Darstellung der vom Benutzer benötigten Informationen zu erhalten, indem Entitäten identifiziert werden, die in starkem Zusammenhang mit der Abfrage stehen.
Balog identifiziert dann sechs Algorithmen, die mit projektionsbasierten Methoden der Entitätsabbildung verbunden sind (Projektionsmethoden beziehen sich auf die Umwandlung von Entitäten in den dreidimensionalen Raum und die Messung von Vektoren unter Verwendung von Geometrie).
- Explizite semantische Analyse (ESA) : Die Semantik eines bestimmten Wortes wird durch einen Vektor beschrieben, der die Assoziationsstärken des Wortes zu von Wikipedia abgeleiteten Konzepten speichert.
- Latent Entity Space Model (LES) : Basierend auf einem generativen probabilistischen Rahmen. Der Abrufwert des Dokuments wird als lineare Kombination des Latent-Entity-Space-Werts und des ursprünglichen Abfragewahrscheinlichkeitswerts angenommen.
- EsdRank: EsdRank dient zum Ranking von Dokumenten unter Verwendung einer Kombination aus Abfrageentitäts- und Entitätsdokumentfunktionen. Diese entsprechen den Begriffen der Abfrageprojektions- bzw. Dokumentprojektionskomponenten von LES von zuvor. Über ein diskriminierendes Lernframework lassen sich auch zusätzliche Signale wie Entity Popularity oder Document Quality einfach einbinden
- Explizites semantisches Ranking (ESR): Das explizite semantische Ranking-Modell enthält Beziehungsinformationen aus einem Wissensgraphen, um ein „weiches Matching“ im Entitätsraum zu ermöglichen.
- Word-Entity Duet Framework: Dies beinhaltet raumübergreifende Interaktionen zwischen begriffsbasierten und entitätsbasierten Darstellungen, was zu vier Arten von Übereinstimmungen führt: Abfragebegriffe zu Dokumentbegriffen, Abfrageentitäten zu Dokumentbegriffen, Abfragebegriffe zu Dokumententitäten und Abfrageentitäten Entitäten zu dokumentieren.
- Aufmerksamkeitsbasiertes Ranking-Modell : Dies ist bei weitem am kompliziertesten zu beschreiben.
Hier ist, was Balog schreibt:
„Insgesamt werden vier Aufmerksamkeitsmerkmale entworfen, die für jede Abfrageentität extrahiert werden. Entitätsmehrdeutigkeitsmerkmale sollen das mit einer Entitätsanmerkung verbundene Risiko charakterisieren. Diese sind: (1) die Entropie der Wahrscheinlichkeit, dass die Oberflächenform mit verschiedenen Entitäten verknüpft ist (z. B. in Wikipedia), (2) ob die annotierte Entität die populärste Bedeutung der Oberflächenform ist (dh die höchste Gemeinsamkeit hat). Score, und (3) die Differenz der Gemeinsamkeitsscores zwischen den wahrscheinlichsten und zweitwahrscheinlichsten Kandidaten für die gegebene Oberflächenform.Das vierte Merkmal ist die Nähe, die als Kosinus-Ähnlichkeit zwischen der Abfrageentitätund der Abfrage in einem Einbettungsraum definiert ist Insbesondere wird eine gemeinsame Einbettung von Entitätsbegriffen mithilfe des Skip-Gram-Modells auf einem Korpus trainiert, wobei Entitätserwähnungen durch die entsprechenden Entitätskennungen ersetzt werden. Die Einbettung der Abfrage wird als Schwerpunkt der Einbettungen der Abfragebegriffe angesehen.“

Im Moment ist es wichtig, sich mit diesen sechs entitätszentrierten Algorithmen auf Oberflächenebene vertraut zu machen.
Die wichtigste Erkenntnis ist, dass es zwei Ansätze gibt: das Projizieren von Dokumenten auf eine latente Entitätsschicht und explizite Entitätsanmerkungen von Dokumenten.
Drei Arten von Datenstrukturen
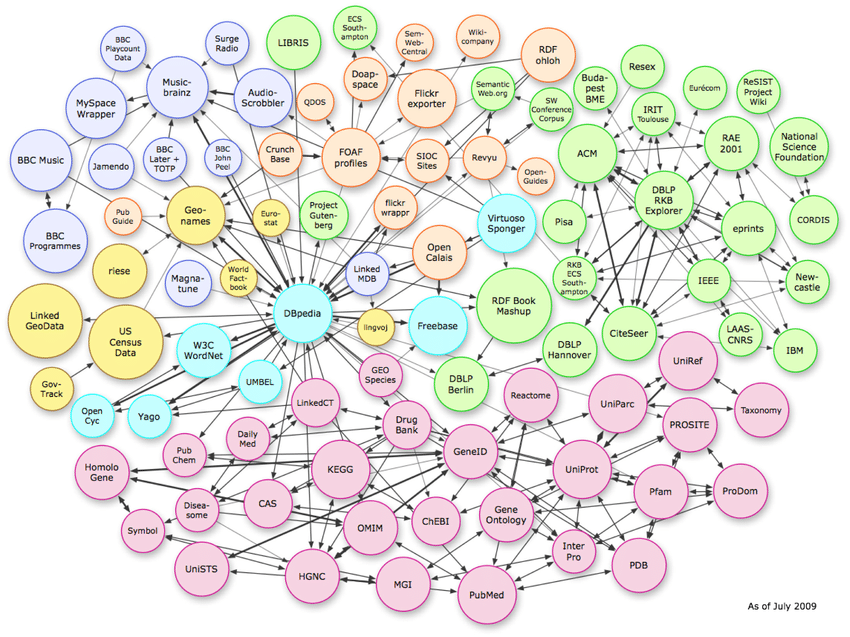
Das obige Bild zeigt die komplexen Beziehungen, die im Vektorraum bestehen. Während das Beispiel Knowledge-Graph-Verbindungen zeigt, kann das gleiche Muster auf einer Seite-für-Seite-Schemaebene repliziert werden.
Um Entitäten zu verstehen, ist es wichtig, die drei Arten von Datenstrukturen zu kennen, die Algorithmen verwenden.
- Anhand von unstrukturierten Entitätsbeschreibungen müssen Verweise auf andere Entitäten erkannt und eindeutig gemacht werden. Gerichtete Kanten (Hyperlinks) werden von jeder Entität zu allen anderen in ihrer Beschreibung erwähnten Entitäten hinzugefügt.
- In einer halbstrukturierten Umgebung (z. B. Wikipedia) können Links zu anderen Entitäten explizit bereitgestellt werden.
- Beim Arbeiten mit strukturierten Daten definieren RDF-Tripel einen Graphen (dh den Wissensgraphen). Insbesondere sind Subjekt- und Objektressourcen (URIs) Knoten und Prädikate Kanten.
Das Problem mit einem halbstrukturierten und ablenkenden Kontext für die IR-Bewertung besteht darin, dass, wenn ein Dokument nicht für ein einzelnes Thema konfiguriert ist, die IR-Bewertung durch die beiden unterschiedlichen Kontexte verwässert werden kann, was dazu führt, dass ein relativer Rang gegenüber einem anderen Textdokument verloren geht.
Die Verdünnung des IR-Scores beinhaltet schlecht strukturierte lexikalische Beziehungen und schlechte Wortnähe.
Die relevanten Wörter, die einander ergänzen, sollten eng innerhalb eines Absatzes oder Abschnitts des Dokuments verwendet werden, um den Kontext klarer zu signalisieren und den IR-Score zu erhöhen.
Die Verwendung von Entitätsattributen und -beziehungen führt zu relativen Verbesserungen im Bereich von 5–20 %. Die Nutzung von Entitätsinformationen ist sogar noch lohnender, mit relativen Verbesserungen, die von 25 % bis über 100 % reichen.
Das Kommentieren von Dokumenten mit Entitäten kann unstrukturierten Dokumenten Struktur verleihen, was dazu beitragen kann, Wissensdatenbanken mit neuen Informationen über Entitäten zu füllen.
Verwendung von Wikipedia als Ihr SEO-Framework für Entitäten
Aufbau von Wikipedia-Seiten
- Titel (I.)
- Lead-Sektion (II.)
- Begriffsklärungslinks (II.a)
- Infobox (II.b)
- Einführungstext (II.c)
- Inhaltsverzeichnis (III.)
- Körperinhalt (IV.)
- Anhänge und Fußzeile (V.)
- Referenzen und Notizen (Va)
- Externe Links (Vb)
- Kategorien (Vc)
Die meisten Wikipedia-Artikel enthalten einen einleitenden Text, den „Lead“, eine kurze Zusammenfassung des Artikels – normalerweise nicht länger als vier Absätze. Dieser sollte so geschrieben sein, dass Interesse an dem Artikel geweckt wird.
Dem ersten Satz und dem einleitenden Absatz kommt besondere Bedeutung zu. Der erste Satz „kann als Definition der im Artikel beschriebenen Entität angesehen werden.“ Der erste Absatz bietet eine ausführlichere Definition ohne zu viele Details.
Der Wert von Links geht über Navigationszwecke hinaus; sie erfassen semantische Beziehungen zwischen Artikeln. Darüber hinaus sind Ankertexte eine reichhaltige Quelle für Entitätsnamensvarianten. Wikipedia-Links können unter anderem verwendet werden, um zu helfen, Erwähnungen von Entitäten im Text zu identifizieren und eindeutig zu machen.
- Fassen Sie die wichtigsten Fakten über die Entität zusammen (Infobox).
- Kurze Einleitung.
- Interne Links. Eine Schlüsselregel für Redakteure besteht darin, nur auf das erste Auftreten einer Entität oder eines Konzepts zu verlinken.
- Schließen Sie alle gängigen Synonyme für eine Entität ein.
- Bezeichnung der Kategorieseite.
- Navigationsvorlage.
- Verweise.
- Spezielle Parsing-Tools zum Verständnis von Wiki-Seiten.
- Mehrere Medientypen.
So optimieren Sie für Entitäten
Im Folgenden finden Sie wichtige Überlegungen zur Optimierung von Entitäten für die Suche:
- Die Aufnahme von semantisch verwandten Wörtern auf einer Seite.
- Häufigkeit von Wörtern und Phrasen auf einer Seite.
- Die Organisation von Konzepten auf einer Seite.
- Einschließlich unstrukturierter Daten, halbstrukturierter Daten und strukturierter Daten auf einer Seite.
- Subjekt-Prädikat-Objekt-Paare (SPO).
- Webdokumente auf einer Website, die als Seiten eines Buches fungieren.
- Organisation von Webdokumenten auf einer Website.
- Fügen Sie Konzepte in ein Webdokument ein, die bekannte Merkmale von Entitäten sind.
Wichtiger Hinweis: Wenn die Betonung auf den Beziehungen zwischen Entitäten liegt, wird eine Wissensbasis oft als Wissensgraph bezeichnet.
Da die Absicht in Verbindung mit Benutzersuchprotokollen und anderen Kontextteilen analysiert wird, könnte derselbe Suchausdruck von Person 1 ein anderes Ergebnis als Person 2 erzeugen. Die Person könnte eine andere Absicht mit genau derselben Anfrage haben.
Wenn Ihre Seite beide Arten von Absichten abdeckt, ist Ihre Seite ein besserer Kandidat für das Web-Ranking. Sie können die Struktur von Wissensdatenbanken verwenden, um Ihre Abfrageabsichtsvorlagen zu leiten (wie in einem vorherigen Abschnitt erwähnt).
„Personen fragen auch“, „Personen suchen nach“ und „Autovervollständigung“ sind semantisch mit der übermittelten Suchanfrage verbunden und tauchen entweder tiefer in die aktuelle Suchrichtung ein oder wechseln zu einem anderen Aspekt der Suchaufgabe.
Wir wissen das, also wie können wir es optimieren?
Ihre Dokumente sollten so viele Variationen der Suchabsicht wie möglich enthalten. Ihre Website sollte alle Variationen der Suchabsicht für Ihren Cluster enthalten. Clustering basiert auf drei Arten von Ähnlichkeit:
- Lexikalische Ähnlichkeit.
- Semantische Ähnlichkeit.
- Klicken Sie auf Ähnlichkeit.
Themenabdeckung
Was ist das –> Attributliste –> Abschnitt, der jedem Attribut gewidmet ist –> Jeder Abschnitt verlinkt auf einen Artikel, der vollständig diesem Thema gewidmet ist –> Die Zielgruppe sollte angegeben werden und Definitionen für den Unterabschnitt sollten angegeben werden –> Was sollte berücksichtigt werden ? –> Was sind die Vorteile? –> Modifikatorvorteile –> Was ist ___ –> Was macht es? –> Wie bekommt man es –> Wie man es macht –> Wer kann es machen –> Link zurück zu allen Kategorien

Google bietet ein Tool an, das einen Hervorhebungswert liefert (ähnlich wie wir das Wort „Stärke“ oder „Vertrauen“ verwenden), der Ihnen sagt, wie Google den Inhalt sieht.

Das obige Beispiel stammt aus einem Search Engine Land-Artikel über Entitäten aus dem Jahr 2018.
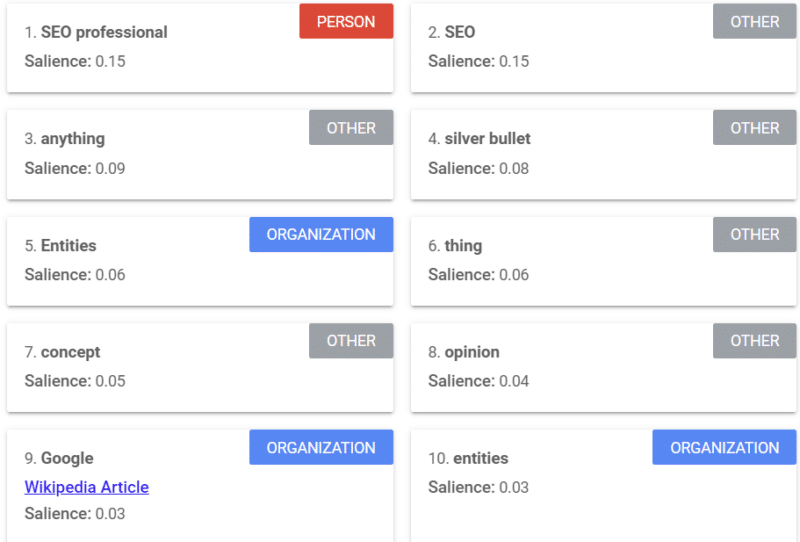
Sie können Personen, andere und Organisationen aus dem Beispiel sehen. Das Tool ist die Natural Language API von Google Cloud.
Jedes Wort, jeder Satz und jeder Absatz ist wichtig, wenn es um eine Entität geht. Wie Sie Ihre Gedanken organisieren, kann Googles Verständnis Ihrer Inhalte verändern.
Sie können ein Schlüsselwort zu SEO hinzufügen, aber versteht Google dieses Schlüsselwort so, wie Sie es verstehen möchten?
Versuchen Sie, ein oder zwei Absätze in das Tool zu platzieren und das Beispiel neu zu organisieren und zu ändern, um zu sehen, wie es die Hervorhebung erhöht oder verringert.
Diese als „Begriffsklärung“ bezeichnete Übung ist für Entitäten unglaublich wichtig. Sprache ist mehrdeutig, also müssen wir unsere Worte für Google weniger zweideutig machen.
Moderne Disambiguierungsansätze berücksichtigen drei Arten von Beweisen:
Priorität von Entitäten und Erwähnungen.
Kontextuelle Ähnlichkeit zwischen dem die Erwähnung umgebenden Text und der Kandidatenentität und Kohärenz zwischen allen Entitätsverknüpfungsentscheidungen im Dokument.
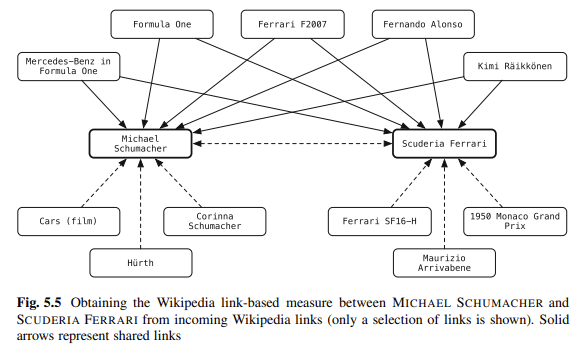
Schema ist eine meiner Lieblingsmethoden, um Inhalte zu disambiguieren. Sie verknüpfen Entitäten in Ihrem Blog mit Wissensspeichern. Balog sagt:
„Das [Verknüpfen] von Entitäten in unstrukturiertem Text mit einem strukturierten Wissensspeicher kann Benutzer bei ihren Informationsnutzungsaktivitäten erheblich stärken.“
Beispielsweise können Leser eines Dokuments mit einem einzigen Klick Kontext- oder Hintergrundinformationen abrufen und einfachen Zugriff auf verwandte Entitäten erhalten.
Entitätsanmerkungen können auch in der nachgelagerten Verarbeitung verwendet werden, um die Abrufleistung zu verbessern oder eine bessere Benutzerinteraktion mit Suchergebnissen zu ermöglichen.
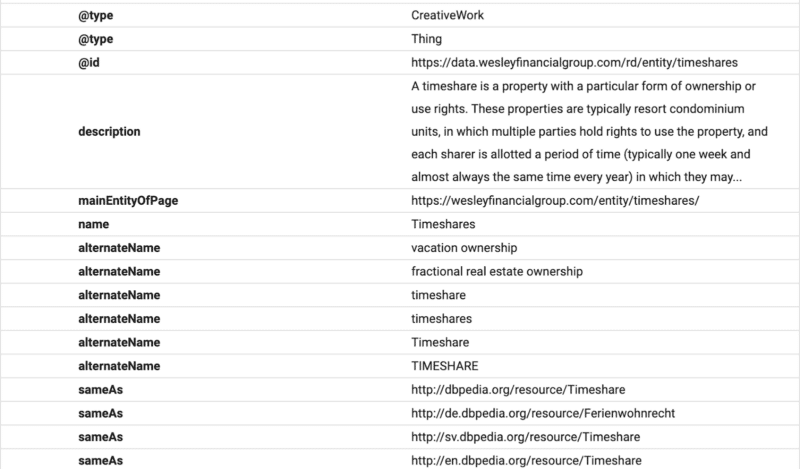
Hier sehen Sie, dass der FAQ-Inhalt für Google mithilfe des FAQ-Schemas strukturiert ist.
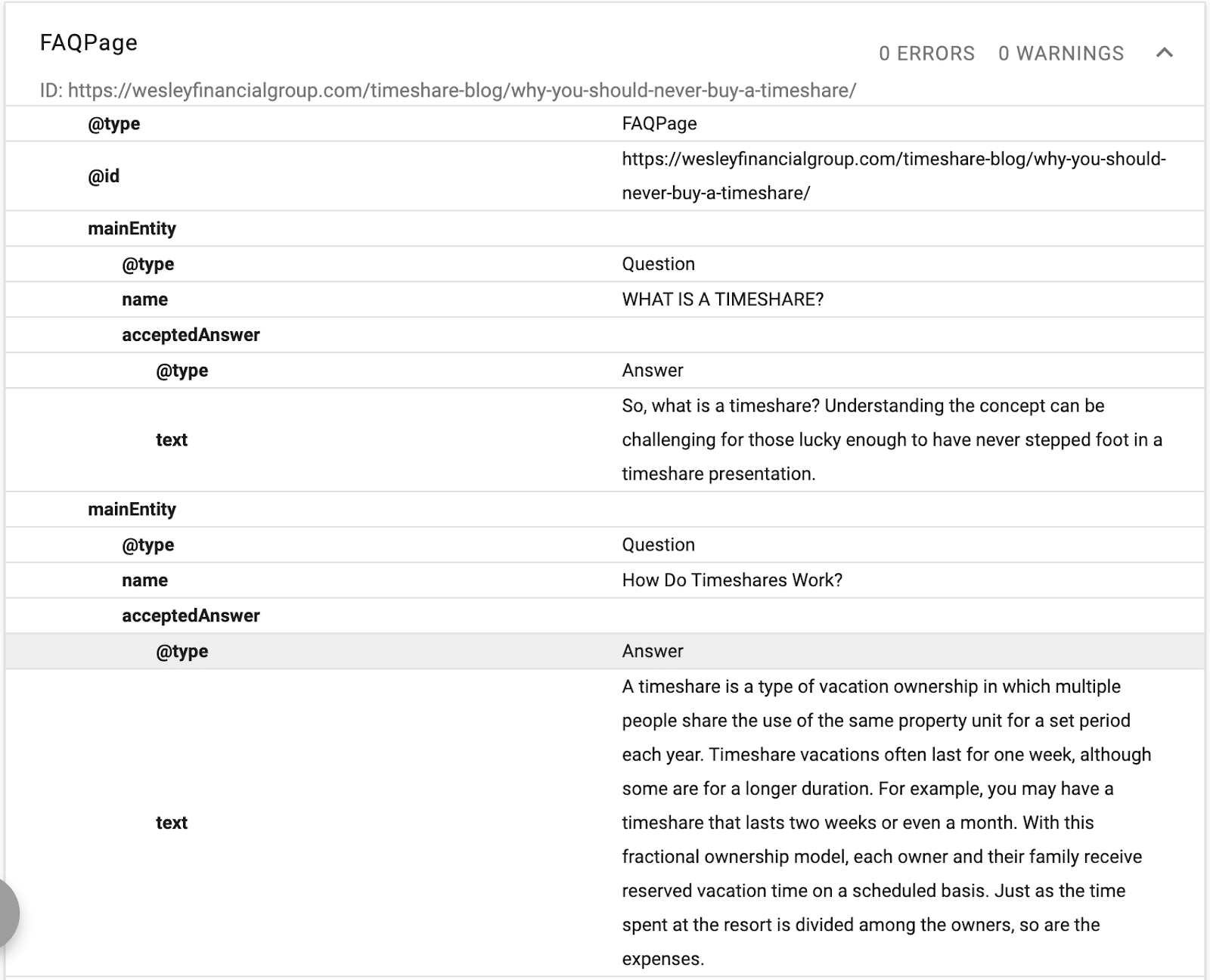
In diesem Beispiel sehen Sie ein Schema, das eine Beschreibung des Textes, eine ID und eine Deklaration der Hauptentität der Seite bereitstellt.
(Denken Sie daran, Google möchte die Hierarchie des Inhalts verstehen, weshalb H1–H6 wichtig ist.)
Sie sehen alternative Namen und dasselbe wie Deklarationen. Wenn Google nun den Inhalt liest, weiß es, welche strukturierte Datenbank es mit dem Text verknüpfen soll, und es werden Synonyme und alternative Versionen eines Wortes mit der Entität verknüpft.
Wenn Sie mit Schema optimieren, optimieren Sie für NER (Named Entity Recognition), auch bekannt als Entity Identification, Entity Extraction und Entity Chunking.
Die Idee ist, sich mit Named Entity Disambiguation > Wikiification > Entity Linking zu beschäftigen.
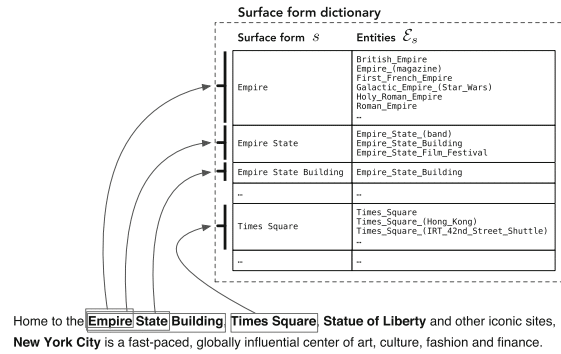
„Das Aufkommen von Wikipedia hat die Erkennung und Begriffsklärung von Entitäten im großen Maßstab erleichtert, indem ein umfassender Katalog von Entitäten zusammen mit anderen unschätzbaren Ressourcen (insbesondere Hyperlinks, Kategorien und Weiterleitungs- und Begriffsklärungsseiten) bereitgestellt wurde.“
– Entitätsorientierte Suche
Wie man gehen Sie über die Vorschläge für SEO-Tools hinaus
Die meisten SEOs verwenden ein On-Page-Tool zur Optimierung ihrer Inhalte. Jedes Tool ist in seiner Fähigkeit, einzigartige Inhaltsmöglichkeiten und Vorschläge zur Inhaltstiefe zu identifizieren, begrenzt.
In den meisten Fällen aggregieren On-Page-Tools nur die besten SERP-Ergebnisse und erstellen einen Durchschnitt, den Sie nachahmen können.
SEOs müssen bedenken, dass Google nicht nach denselben aufbereiteten Informationen sucht. Sie können kopieren, was andere tun, aber eindeutige Informationen sind der Schlüssel, um eine Seed-Site/Autoritäts-Site zu werden.
Hier ist eine vereinfachte Beschreibung, wie Google mit neuen Inhalten umgeht:
Sobald ein Dokument gefunden wurde, das eine gegebene Entität erwähnt, kann dieses Dokument überprüft werden, um möglicherweise neue Tatsachen zu entdecken, mit denen der Wissensdatenbankeintrag dieser Entität aktualisiert werden kann.
Balog schreibt:
„Wir möchten Redakteuren dabei helfen, über Änderungen auf dem Laufenden zu bleiben, indem wir Inhalte (Nachrichtenartikel, Blogbeiträge usw.) automatisch identifizieren, die Änderungen an den KB-Einträgen einer bestimmten Gruppe von interessierenden Entitäten (d. h. Entitäten, die ein bestimmter Redakteur ist) implizieren können verantwortlich für)."
Jeder, der Wissensdatenbanken, die Erkennung von Entitäten und die Crawlbarkeit von Informationen verbessert, wird von Google geliebt.
Im Wissensspeicher vorgenommene Änderungen können auf das Dokument als Originalquelle zurückgeführt werden.
Wenn Sie Inhalte bereitstellen, die das Thema abdecken, und eine seltene oder neue Tiefe hinzufügen, kann Google feststellen, ob Ihr Dokument diese einzigartigen Informationen hinzugefügt hat.
Letztendlich könnten diese neuen Informationen, die über einen längeren Zeitraum erhalten bleiben, dazu führen, dass Ihre Website zu einer Autorität wird.
Dies ist keine Autorität basierend auf der Domain-Bewertung, sondern eine thematische Berichterstattung, die meiner Meinung nach weitaus wertvoller ist.
Mit dem Entity-Ansatz für SEO sind Sie nicht darauf beschränkt, Keywords mit Suchvolumen anzusprechen.
Alles, was Sie tun müssen, ist, den Kopfbegriff zu validieren (z. B. „Fliegenfischruten“), und dann können Sie sich darauf konzentrieren, auf Variationen der Suchabsicht zu zielen, die auf dem guten alten menschlichen Denken basieren.
Wir beginnen mit Wikipedia. Am Beispiel des Fliegenfischens können wir sehen, dass mindestens die folgenden Konzepte auf einer Angel-Website behandelt werden sollten:
- Fischarten, Geschichte, Ursprünge, Entwicklung, technologische Verbesserungen, Expansion, Methoden des Fliegenfischens, Werfen, Spinnfischen, Fliegenfischen auf Forelle, Techniken des Fliegenfischens, Kaltwasserfischen, Trockenfliegenfischen auf Forelle, Nymphen auf Forelle, Stillwasser Forellenangeln, Forellen spielen, Forellen freisetzen, Salzwasserfliegenfischen, Tackle, künstliche Fliegen und Knoten.
Die obigen Themen stammen von der Wikipedia-Seite zum Fliegenfischen. Während diese Seite einen großartigen Überblick über Themen bietet, füge ich gerne zusätzliche Themenideen hinzu, die aus semantisch verwandten Themen stammen.
Für das Thema „Fisch“ können wir mehrere zusätzliche Themen hinzufügen, darunter Etymologie, Evolution, Anatomie und Physiologie, Fischkommunikation, Fischkrankheiten, Erhaltung und Bedeutung für den Menschen.
Hat jemand die Anatomie der Forelle mit der Wirksamkeit bestimmter Fangtechniken in Verbindung gebracht?
Hat eine einzige Angel-Website alle Fischarten abgedeckt und gleichzeitig die Arten von Angeltechniken, Ruten und Ködern mit jedem Fisch verknüpft?
Inzwischen sollten Sie sehen können, wie die Themenerweiterung wachsen kann. Denken Sie daran, wenn Sie eine Content-Kampagne planen.
Nicht nur aufwärmen. Mehrwert. Einzigartig sein. Verwenden Sie die in diesem Artikel erwähnten Algorithmen als Leitfaden.
Abschluss
Dieser Artikel ist Teil einer Reihe von Artikeln, die sich auf Entitäten konzentrieren. Im nächsten Artikel werde ich tiefer in die Optimierungsbemühungen rund um Entitäten und einige auf Entitäten fokussierte Tools auf dem Markt eintauchen.
Ich möchte diesen Artikel beenden, indem ich zwei Leuten einen Gruß ausspreche, die mir viele dieser Konzepte erklärt haben.
Bill Slawski von SEO by the Sea und Koray Tugbert von Holistic SEO. Obwohl Slawski nicht mehr bei uns ist, wirken sich seine Beiträge weiterhin in der SEO-Branche aus.
Ich verlasse mich stark auf die folgenden Quellen für den Inhalt des Artikels, da diese Quellen die besten Ressourcen sind, die es zu diesem Thema gibt:
- Extended Named Entity Hierarchy von Satoshi Ketine, Kiyoshi Sudo und Chikashi Nobata
- Entity-Oriented Search von Krisztian Balog , Information Retrieval Series (INRE, Band 39)
- Umschreiben von Abfragen mit Entitätserkennung , Google-Patent
- Suchabfragen verfeinern , Google Patent
- Assoziieren einer Entität mit einer Suchanfrage , Google Patent
Die in diesem Artikel geäußerten Meinungen sind die des Gastautors und nicht unbedingt Search Engine Land. Mitarbeiter Autoren sind hier aufgelistet.