
Wie kann Apache Spark Airline Analytics beflügeln?
Veröffentlicht: 2015-10-30Die globale Luftfahrtindustrie wächst weiterhin schnell, aber eine konsistente und robuste Rentabilität lässt noch auf sich warten. Laut der International Air Transport Association (IATA) hat die Branche ihren Umsatz in den letzten zehn Jahren verdoppelt, von 369 Milliarden US-Dollar im Jahr 2005 auf voraussichtlich 727 Milliarden US-Dollar im Jahr 2015.

In der kommerziellen Luftfahrtbranche macht jeder Akteur in der Wertschöpfungskette – Flughäfen, Flugzeughersteller, Strahltriebwerkshersteller, Reisebüros und Dienstleistungsunternehmen – ordentliche Gewinne.
All diese Akteure erzeugen individuell extrem hohe Datenmengen aufgrund einer höheren Abwanderung von Flugtransaktionen. Das Erkennen und Erfassen der Nachfrage ist hier der Schlüssel, der den Fluggesellschaften viel größere Möglichkeiten bietet, sich zu differenzieren. Daher kann die Luftfahrtindustrie Big-Data-Einblicke nutzen, um ihren Umsatz zu steigern und die Gewinnspanne zu verbessern.
Big Data ist ein Begriff für die Sammlung von Datensätzen, die so groß und komplex sind, dass ihre Berechnung nicht von herkömmlichen Datenverarbeitungssystemen oder verfügbaren DBMS-Tools bewältigt werden kann.
Apache Spark ist ein verteiltes Open-Source-Cluster-Computing-Framework, das speziell für interaktive Abfragen und iterative Algorithmen entwickelt wurde.
Die Spark DataFrame-Abstraktion ist ein tabellarisches Datenobjekt, das dem nativen Datenrahmen von R oder dem Pythons-Pandas-Paket ähnelt, aber in der Clusterumgebung gespeichert ist.
Laut der neuesten Fortunes-Umfrage ist Apache Spark die beliebteste Technologie des Jahres 2015.
Auch der größte Hadoop-Anbieter Cloudera verabschiedet sich von Hadoops MapReduce und Hello to Spark.
Was Spark wirklich den entscheidenden Vorteil gegenüber Hadoop verschafft, ist die Geschwindigkeit . Spark wickelt die meisten seiner Operationen im Arbeitsspeicher ab und kopiert sie aus dem verteilten physischen Speicher in den viel schnelleren logischen RAM-Speicher. Dies reduziert den Zeitaufwand für das Schreiben und Lesen auf und von langsamen, klobigen mechanischen Festplatten, die unter dem Hadoops MapReduce-System durchgeführt werden müssen.
Außerdem enthält Spark Tools (Echtzeitverarbeitung, maschinelles Lernen und interaktives SQL), die gut darauf ausgelegt sind, Geschäftsziele zu erreichen, wie z. B. die Analyse von Echtzeitdaten durch die Kombination historischer Daten von verbundenen Geräten, auch bekannt als das Internet der Dinge .
Lassen Sie uns heute einige Einblicke in Beispielflughafendaten mit Apache Spark gewinnen .
Im vorherigen Blog haben wir gesehen, wie strukturierte und halbstrukturierte Daten in Spark mithilfe der neuen Dataframes-API verarbeitet werden, und wir haben auch behandelt, wie JSON-Daten effizient verarbeitet werden.
In diesem Blog erfahren Sie, wie Sie Daten in DataFrames mit SQL abfragen und die Ausgabe im CSV-Format im Dateisystem speichern.
Verwenden der Databricks-CSV-Analysebibliothek
Dafür werde ich eine CSV-Parsing-Bibliothek verwenden, die von Databricks bereitgestellt wird, einem Unternehmen, das von Creators of Apache Spark gegründet wurde und derzeit Spark-Entwicklung und -Distributionen übernimmt.
Die Spark-Community besteht aus rund 600 Mitwirkenden, die sie in Bezug auf die Anzahl der Mitwirkenden zum aktivsten Projekt in der gesamten Apache Software Foundation machen, einem wichtigen Leitungsgremium für Open-Source-Software.
Die Spark-csv-Bibliothek hilft uns beim Analysieren und Abfragen von CSV-Daten im Spark. Wir können diese Bibliothek sowohl zum Lesen als auch zum Schreiben von CSV-Daten in und aus jedem Hadoop-kompatiblen Dateisystem verwenden.
Laden der Daten in Spark DataFrames
Lassen Sie uns unsere Eingabedateien mithilfe der Spark-CSV-Analysebibliothek von Databricks in einen Spark-DataFrame laden.
Sie können diese Bibliothek in der Spark-Shell verwenden, indem Sie –packages com.databricks: spark-csv_2.10:1.0.3 angeben
Beim Starten der Shell wie unten gezeigt:
$ bin/spark-shell –packages com.databricks:spark-csv_2.10:1.0.3
Denken Sie daran, dass Sie mit dem Internet verbunden sein sollten, da das spark-csv-Paket automatisch heruntergeladen wird, wenn Sie diesen Befehl eingeben. Ich verwende die Spark-Version 1.4.0
Lassen Sie uns sqlContext mit dem bereits erstellten SparkContext(sc)-Objekt erstellen
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
import sqlContext.implicits._
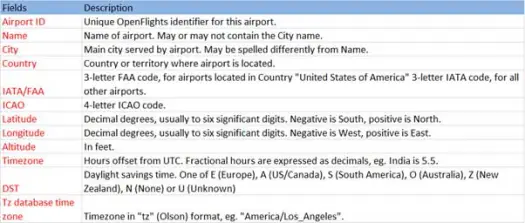
Lassen Sie uns nun unsere CSV-Daten aus der Datei airports.csv (Flughafen-CSV-Github) laden, deren Schema wie folgt ist
scala> val airportDF = sqlContext.load("com.databricks.spark.csv", Map("path" -> "/home /poonam/airports.csv", "header" -> "true"))Der Ladevorgang analysiert die *.csv-Datei mithilfe der Databricks Spark-CSV-Bibliothek und gibt einen Datenrahmen mit Spaltennamen zurück, die mit denen in der ersten Kopfzeile in der Datei identisch sind.
Im Folgenden sind die Parameter aufgeführt, die an die Lademethode übergeben werden.
- Quelle : "com.databricks.spark.csv" teilt Spark mit, dass wir als CSV-Datei laden möchten.
- Optionen:
- Pfad – Pfad der Datei, wo sie sich befindet.
- Header : "header" -> "true" weist Spark an, die erste Zeile der Datei den Spaltennamen für den resultierenden Datenrahmen zuzuordnen.
Mal sehen, was das Schema unseres Datenrahmens ist
Sehen Sie sich Beispieldaten in unserem Datenrahmen an
scala> airportDF.show


CSV-Daten mit temporären Tabellen abfragen:
Um eine Abfrage für eine Tabelle auszuführen, rufen wir die Methode sql() für den SQLContext auf.
Wir haben einen DataFrame für Flughäfen erstellt und CSV-Daten geladen. Um diese DF-Daten abzufragen, müssen wir sie als temporäre Tabelle namens Flughäfen registrieren.
>
scala> airportDF.registerTempTable("airports")
Lassen Sie uns herausfinden, wie viele Flughäfen es in unserem Datensatz im Südosten gibt
scala> sqlContext.sql("select AirportID, Name, Latitude, Longitude from airports where Latitude<0 and Longitude>0").collect.foreach(println)
[1,Goroka,-6.081689,145.391881]
[2,Madang,-5.207083,145.7887]
[3,Mount Hagen,-5.826789,144.295861
]
[4,Nadzab,-6.569828,146.726242]
[5,Port Moresby Jacksons Intl,-9.443383,147.22005]
[6,Wewak Intl,-3.583828,143.669186]
Wir können Aggregationen in SQL-Abfragen auf Spark durchführen
Wir werden herausfinden, wie viele einzigartige Städte in jedem Land Flughäfen haben
scala> sqlContext.sql("select Country, count(distinct(City)) from airports group by Country").collect.foreach(println)
[Iceland,10]
[Greenland,4]
[Canada,131]
[Papua New Guinea,6]
Was ist die durchschnittliche Höhe (in Fuß) der Flughäfen in jedem Land?
scala> sqlContext.sql("select Country , avg(Altitude) from airports group by Country").collect
res6: Array[org.apache.spark.sql.Row] =Array(
[Iceland,72.8],
[Greenland,202.75],
[Canada,852.6666666666666],
[Papua New Guinea,1849.0])
Um jetzt herauszufinden, wie viele Flughäfen in jeder Zeitzone in Betrieb sind?
scala> sqlContext.sql("select Tz , count(Tz) from airports group by Tz").collect.foreach(println)
[America/Dawson_Creek,1]
[America/Coral_Harbour,3]
[America/Halifax,9]
[America/Toronto,48]
[America/Vancouver,19]
[America/Godthab,3]
[Pacific/Port_Moresby,6]
[Atlantic/Reykjavik,10]
[America/Thule,1]
[America/St_Johns,4]
[America/Winnipeg,14]
[America/Edmonton,27]
[America/Regina,10]
Wir können auch den durchschnittlichen Breiten- und Längengrad für diese Flughäfen in jedem Land berechnen
scala> sqlContext.sql("select Country, avg(Latitude), avg(Longitude) from airports group by Country").collect.foreach(println)
[Iceland,65.0477736,-19.5969224]
[Greenland,67.22490275,-54.124131999999996]
[Canada,53.94868565185185,-93.950036237037]
[Papua New Guinea,-6.118766666666666,145.51532]
Lassen Sie uns zählen, wie viele verschiedene DSTs es gibt
scala> sqlContext.sql("select count(distinct(DST)) from airports").collect.foreach(println)
[4]
Speichern von Daten im CSV-Format
Bisher haben wir CSV-Daten geladen und abgefragt. Jetzt werden wir sehen, wie Ergebnisse im CSV-Format wieder im Dateisystem gespeichert werden.
Angenommen, wir möchten dem Kunden einen Bericht über alle Flughäfen im Nordwesten aller Länder senden.
Rechnen wir das erstmal aus.
scala> val NorthWestAirportsDF=sqlContext.sql("select AirportID, Name, Latitude, Longitude from airports where Latitude>0 and Longitude<0")
NorthWestAirportsDF: org.apache.spark.sql.DataFrame = [AirportID: string, Name: string, Latitude: string, Longitude: string]
Und speichern Sie es in einer CSV-Datei
scala> NorthWestAirportsDF.save("com.databricks.spark.csv", org.apache.spark.sql.SaveMode.ErrorIfExists, Map("path" -> "/home/poonam/NorthWestAirports.csv","header"->"true"))
Im Folgenden sind die Parameter aufgeführt, die an die save-Methode übergeben werden.
- Quelle : Es ist dasselbe wie die Lademethode com.databricks.spark.csv , die Spark anweist, Daten als CSV zu speichern.
- SaveMode : Damit kann der Benutzer im Voraus angeben, was getan werden muss, wenn der angegebene Ausgabepfad bereits vorhanden ist. Damit vorhandene Daten nicht versehentlich verloren gehen/überschrieben werden. Sie können Fehler werfen, anhängen oder überschreiben. Hier haben wir einen Fehler ErrorIfExists ausgelöst , da wir keine vorhandene Datei überschreiben möchten.
- Optionen : Diese Optionen sind die gleichen wie die, die wir an die Lademethode übergeben haben. Optionen:
- Pfad – Pfad der Datei, wo sie gespeichert werden soll.
- Header : "header" -> "true" weist Spark an, die Spaltennamen des Datenrahmens der ersten Zeile der resultierenden Ausgabedatei zuzuordnen.
Konvertieren anderer Datenformate in CSV
Mit dieser Bibliothek können wir auch jedes andere Datenformat wie JSON, Parquet, Text in CSV konvertieren.
Im vorherigen Blog hatten wir json-Daten erstellt. Sie können es auf github finden
scala> val employeeDF = sqlContext.read.json("/home/poonam/employee.json")
Speichern wir es einfach als CSV.
scala> employeeDF.save("com.databricks.spark.csv", org.apache.spark.sql.SaveMode.ErrorIfExists, Map("path" -> "/home/poonam/employee.csv", "header"->"true"))
Fazit:
In diesem Beitrag haben wir einige Einblicke in Flughafendaten mithilfe von interaktiven SparkSQL- Abfragen gesammelt
und erkundete die CSV-Parsing-Bibliothek von Spark
Im nächsten Blog werden wir uns mit einer sehr wichtigen Komponente von Spark befassen, dh Spark Streaming.
Spark Streaming ermöglicht es Benutzern, Echtzeitdaten in Spark zu sammeln und sie während des Vorgangs zu verarbeiten, und liefert sofort Ergebnisse.