
So verwenden Sie Google-Entitäten und GPT-4 zum Erstellen von Artikelgliederungen
Veröffentlicht: 2023-06-06In diesem Artikel erfahren Sie, wie Sie mithilfe von Scraping und dem Knowledge Graph von Google ein automatisches Prompt-Engineering durchführen, das eine Gliederung und Zusammenfassung für einen Artikel generiert, der, wenn er gut geschrieben ist, viele wichtige Zutaten für ein gutes Ranking enthält.
Im Grunde weisen wir GPT-4 an, eine Artikelübersicht zu erstellen, die auf einem Schlüsselwort und den Top-Entitäten basiert, die sie auf einer gut rankenden Seite Ihrer Wahl gefunden haben.
Die Entitäten werden nach ihrem Salienzwert geordnet.
„Warum Salience-Score?“ könnte man fragen.
Google beschreibt die Bedeutung in seinen API-Dokumenten wie folgt:
„Der Salienzwert für eine Entität liefert Informationen über die Wichtigkeit oder Zentralität dieser Entität für den gesamten Dokumenttext. Werte näher bei 0 sind weniger hervorstechend, während Werte näher bei 1,0 sehr hervorstechend sind.“
Scheint eine ziemlich gute Metrik zu sein, um zu beeinflussen, welche Entitäten in einem Inhalt vorhanden sein sollten, den Sie vielleicht schreiben möchten, nicht wahr?
Einstieg
Es gibt zwei Möglichkeiten, wie Sie dabei vorgehen können:
- Nehmen Sie sich etwa 5 Minuten Zeit (vielleicht 10, wenn Sie Ihren Computer einrichten müssen) und führen Sie die Skripts auf Ihrem Computer aus, oder ...
- Wechseln Sie zu dem Colab, das ich erstellt habe, und beginnen Sie sofort damit herumzuspielen.
Ich habe eine Vorliebe für Ersteres, bin aber im Laufe meiner Zeit auch auf ein oder zwei Colabs umgestiegen. 😀
Angenommen, Sie sind immer noch hier und möchten dies auf Ihrem eigenen Computer einrichten, haben aber noch weder Python noch eine IDE (Integrated Development Environment) installiert, verweise ich Sie zunächst auf eine kurze Lektüre zum Einrichten Ihres Computers für die Verwendung Jupyter-Notizbuch. Es sollte nicht länger als etwa 5 Minuten dauern.
Jetzt ist es Zeit, loszulegen!
Verwendung von Google-Entitäten und GPT-4 zum Erstellen von Artikelgliederungen
Um das Nachvollziehen zu erleichtern, werde ich die Anweisungen wie folgt formatieren:
- Schritt : Eine kurze Beschreibung des Schritts, in dem wir uns befinden.
- Code : Der Code zum Abschließen dieses Schritts.
- Erläuterung : Eine kurze Erklärung, was der Code tut.
Schritt 1: Sagen Sie mir, was Sie wollen
Bevor wir uns an die Erstellung der Umrisse machen, müssen wir definieren, was wir wollen.
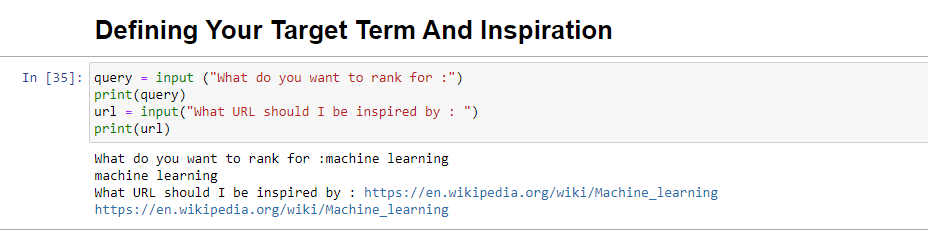
query = input ("What do you want to rank for :") print(query) url = input("What URL should I be inspired by : ") print(url)Wenn dieser Block ausgeführt wird, fordert er den Benutzer (wahrscheinlich Sie) dazu auf, die Abfrage einzugeben, für die der Artikel ranken soll bzw. um die er sich drehen soll Stück, von dem man sich inspirieren lassen kann.
Ich würde einen Artikel vorschlagen, der ein gutes Ranking hat, in einem Format vorliegt, das für Ihre Website geeignet ist und von dem Sie denken, dass er das Ranking allein aufgrund des Werts des Artikels und nicht nur aufgrund der Stärke der Website verdient.
Wenn es ausgeführt wird, sieht es so aus:
Schritt 2: Installieren der erforderlichen Bibliotheken
Als nächstes müssen wir alle Bibliotheken installieren, die wir verwenden werden, um die Magie zu verwirklichen.
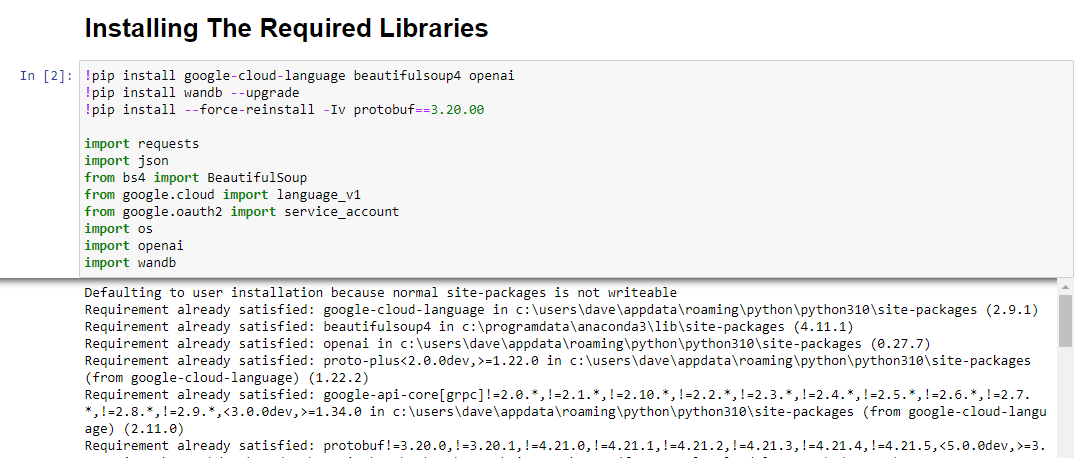
!pip install google-cloud-language beautifulsoup4 openai !pip install wandb --upgrade !pip install --force-reinstall -Iv protobuf==3.20.00 import requests import json from bs4 import BeautifulSoup from google.cloud import language_v1 from google.oauth2 import service_account import os import openai import pandas as pd import wandbWir installieren die folgenden Bibliotheken:
- Anfragen : Diese Bibliothek ermöglicht das Senden von HTTP-Anfragen zum Abrufen von Inhalten von Websites oder Web-APIs.
- JSON : Es bietet Funktionen zum Arbeiten mit JSON-Daten, einschließlich der Analyse von JSON-Strings in Python-Objekte und der Serialisierung von Python-Objekten in JSON-Strings.
- BeautifulSoup : Diese Bibliothek wird für Web-Scraping-Zwecke verwendet. Es hilft beim Parsen und Navigieren in HTML- oder XML-Dokumenten und beim Extrahieren relevanter Informationen daraus.
- Google.cloud.sprache_v1 : Es handelt sich um eine Bibliothek von Google Cloud, die Funktionen zur Verarbeitung natürlicher Sprache bereitstellt. Es ermöglicht die Durchführung verschiedener Aufgaben wie Stimmungsanalyse, Entitätserkennung und Syntaxanalyse für Textdaten.
- Google.oauth2.service_account : Diese Bibliothek ist Teil des Google OAuth2 Python-Pakets. Es bietet Unterstützung für die Authentifizierung bei Google APIs mithilfe eines Dienstkontos. Dies ist eine Möglichkeit, eingeschränkten Zugriff auf die Ressourcen eines Google Cloud-Projekts zu gewähren.
- Betriebssystem : Diese Bibliothek bietet eine Möglichkeit zur Interaktion mit dem Betriebssystem. Es ermöglicht den Zugriff auf verschiedene Funktionen wie Dateioperationen, Umgebungsvariablen und Prozessverwaltung.
- OpenAI : Diese Bibliothek ist das OpenAI-Python-Paket. Es bietet eine Schnittstelle zur Interaktion mit den Sprachmodellen von OpenAI, einschließlich GPT-4 (und 3). Es ermöglicht Entwicklern, Text zu generieren, Textvervollständigungen durchzuführen und mehr.
- Pandas : Es ist eine leistungsstarke Bibliothek zur Datenbearbeitung und -analyse. Es stellt Datenstrukturen und Funktionen zur effizienten Verarbeitung und Analyse strukturierter Daten wie Tabellen oder CSV-Dateien bereit.
- WandB : Diese Bibliothek steht für „Weights & Biases“ und ist ein Tool zur Experimentverfolgung und Visualisierung. Es hilft bei der Protokollierung und Visualisierung der Metriken, Hyperparameter und anderer wichtiger Aspekte von Experimenten zum maschinellen Lernen.
Wenn es ausgeführt wird, sieht es so aus:
Erhalten Sie den täglichen Newsletter, auf den sich Suchmaschinenmarketing verlassen.
Siehe Bedingungen.
Schritt 3: Authentifizierung
Ich muss uns einen Moment ablenken, damit wir uns auf den Weg machen und unsere Authentifizierung durchführen können. Wir benötigen einen OpenAI-API-Schlüssel und Anmeldeinformationen für Google Knowledge Graph Search.
Dies dauert nur wenige Minuten.
Erhalten Sie Ihre OpenAI-API
Derzeit müssen Sie sich wahrscheinlich auf die Warteliste setzen. Ich habe das Glück, frühzeitig Zugriff auf die API zu haben, und deshalb schreibe ich dies, um Ihnen bei der Einrichtung zu helfen, sobald Sie sie erhalten.
Die Anmeldebilder stammen von GPT-3 und werden für GPT-4 aktualisiert, sobald der Flow für alle verfügbar ist.
Bevor Sie GPT-4 verwenden können, benötigen Sie einen API-Schlüssel, um darauf zuzugreifen.
Um eines zu erhalten, gehen Sie einfach zur Produktseite von OpenAI und klicken Sie auf „Erste Schritte“ .
Wählen Sie Ihre Anmeldemethode (ich habe Google gewählt) und führen Sie den Verifizierungsprozess durch. Für diesen Schritt benötigen Sie Zugriff auf ein Telefon, das SMS empfangen kann.
Sobald dies abgeschlossen ist, erstellen Sie einen API-Schlüssel. Auf diese Weise kann OpenAI Ihre Skripte mit Ihrem Konto verbinden.
Sie müssen wissen, wer was tut, und festlegen, ob und wie viel sie Ihnen für das, was Sie tun, in Rechnung stellen sollen.
OpenAI-Preise
Bei der Anmeldung erhalten Sie ein Guthaben von 5 $, mit dem Sie überraschend weit kommen, wenn Sie nur experimentieren.
Zum jetzigen Zeitpunkt beträgt die bisherige Preisgestaltung:

Erstellen Sie Ihren OpenAI-Schlüssel
Um Ihren Schlüssel zu erstellen, klicken Sie oben rechts auf Ihr Profil und wählen Sie API-Schlüssel anzeigen .
...und dann erstellen Sie Ihren Schlüssel.
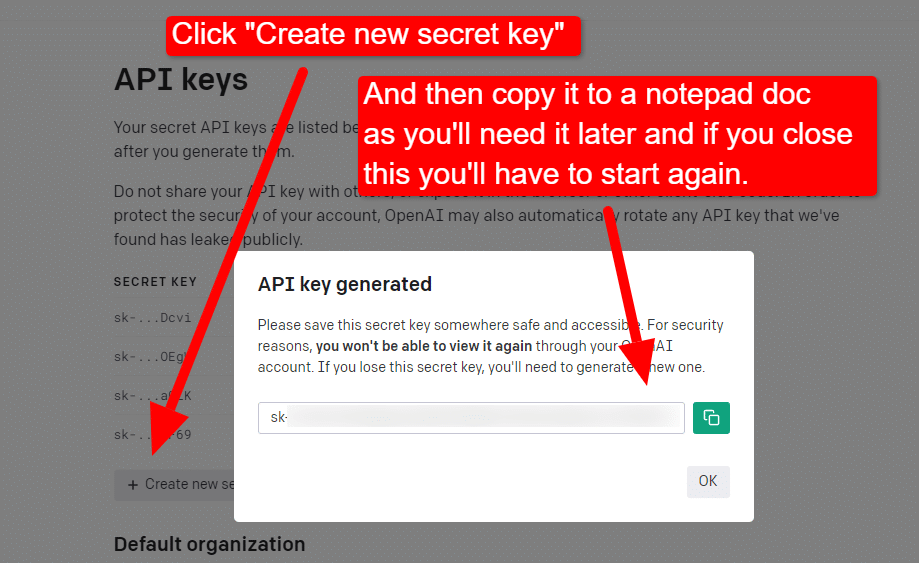
Sobald Sie die Lightbox schließen, können Sie Ihren Schlüssel nicht mehr sehen und müssen ihn neu erstellen. Kopieren Sie ihn daher für dieses Projekt einfach in ein Notepad-Dokument, um ihn in Kürze zu verwenden.
Hinweis: Speichern Sie Ihren Schlüssel nicht (ein Notepad-Dokument auf Ihrem Desktop ist nicht besonders sicher). Wenn Sie es kurzzeitig verwendet haben, schließen Sie das Notepad-Dokument, ohne es zu speichern.
Erhalten Sie Ihre Google Cloud-Authentifizierung
Zunächst müssen Sie sich bei Ihrem Google-Konto anmelden. (Sie sind auf einer SEO-Seite, also gehe ich davon aus, dass Sie eine haben. 🙂)
Sobald Sie dies getan haben, können Sie bei Bedarf die Knowledge Graph-API-Informationen überprüfen oder direkt zur API-Konsole springen und loslegen.
Sobald Sie an der Konsole sind:
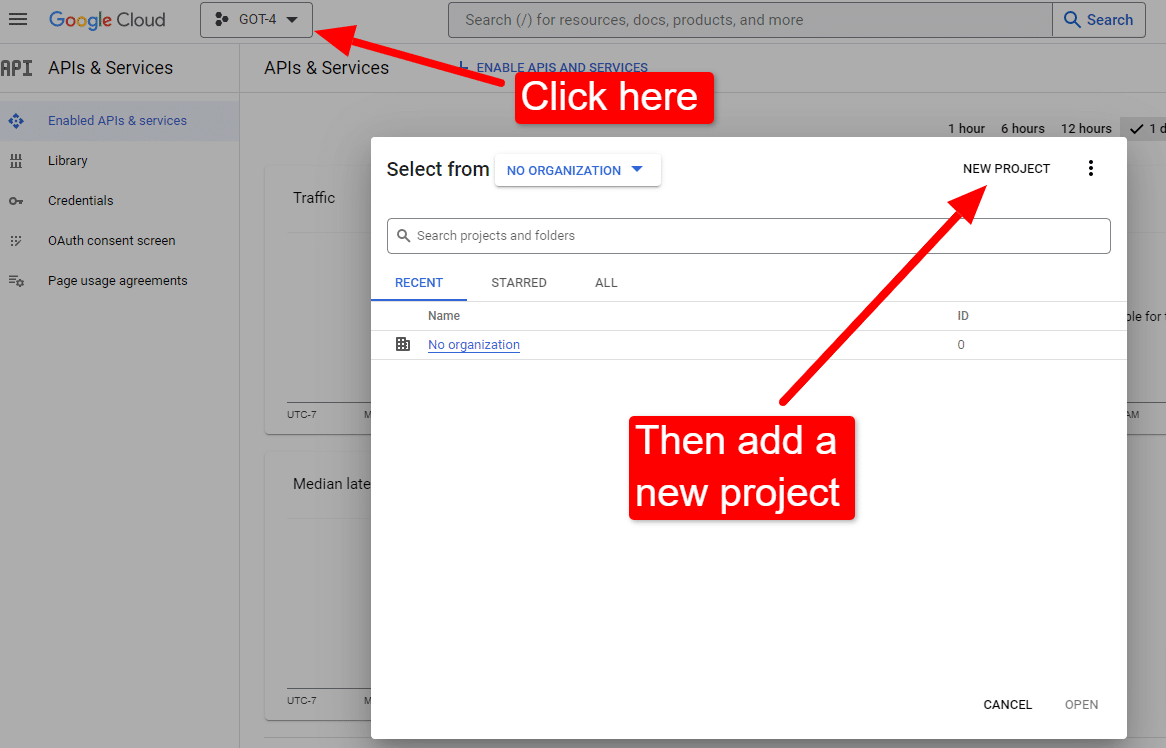
Nennen Sie es etwa „Dave's Awesome Articles“. Weißt du ... leicht zu merken.
Als Nächstes aktivieren Sie die API, indem Sie auf APIs und Dienste aktivieren klicken.

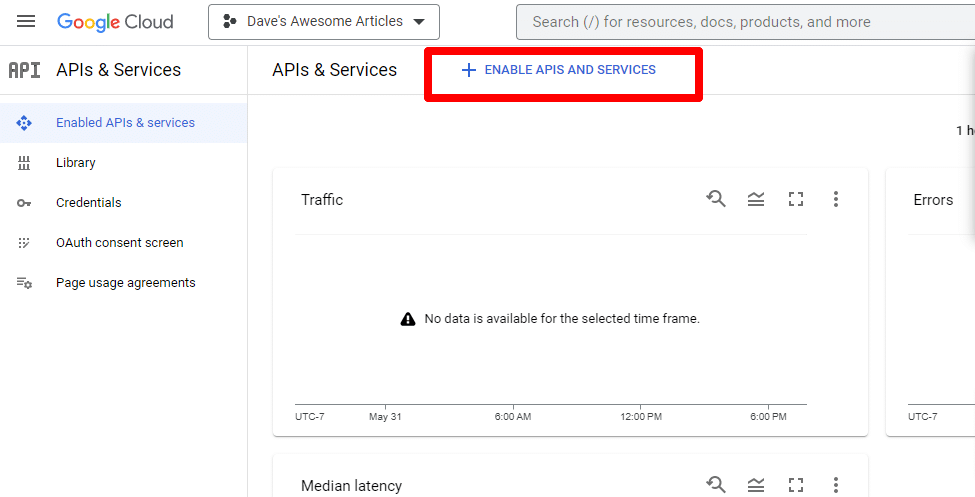
Suchen Sie die Knowledge Graph Search API und aktivieren Sie sie.
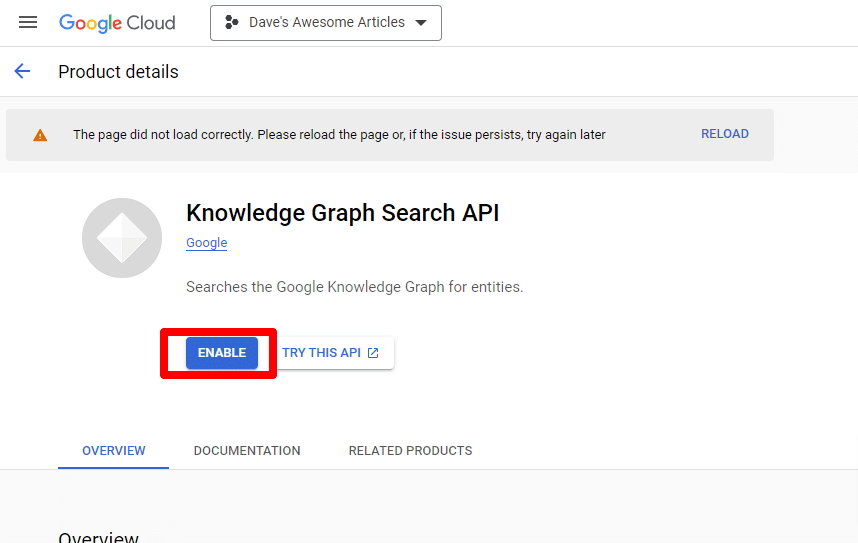
Sie werden dann zur Haupt-API-Seite zurückgeleitet, wo Sie Anmeldeinformationen erstellen können:
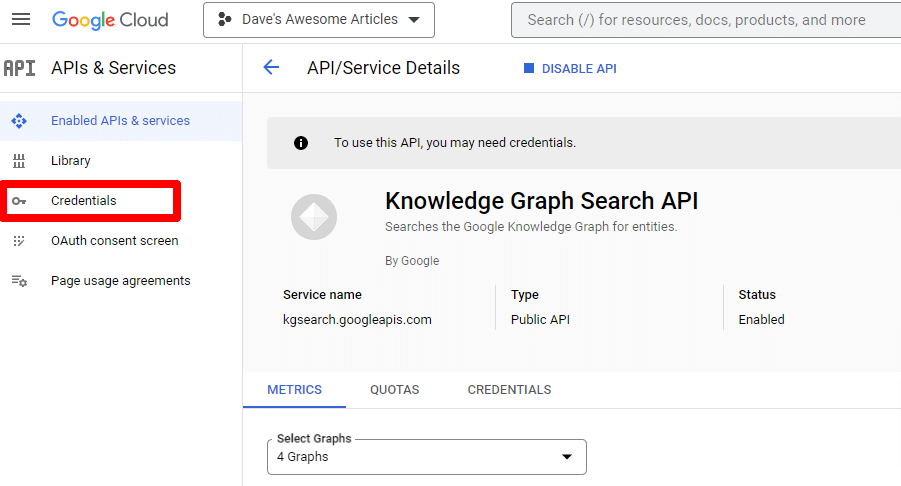
Und wir werden ein Dienstkonto erstellen.
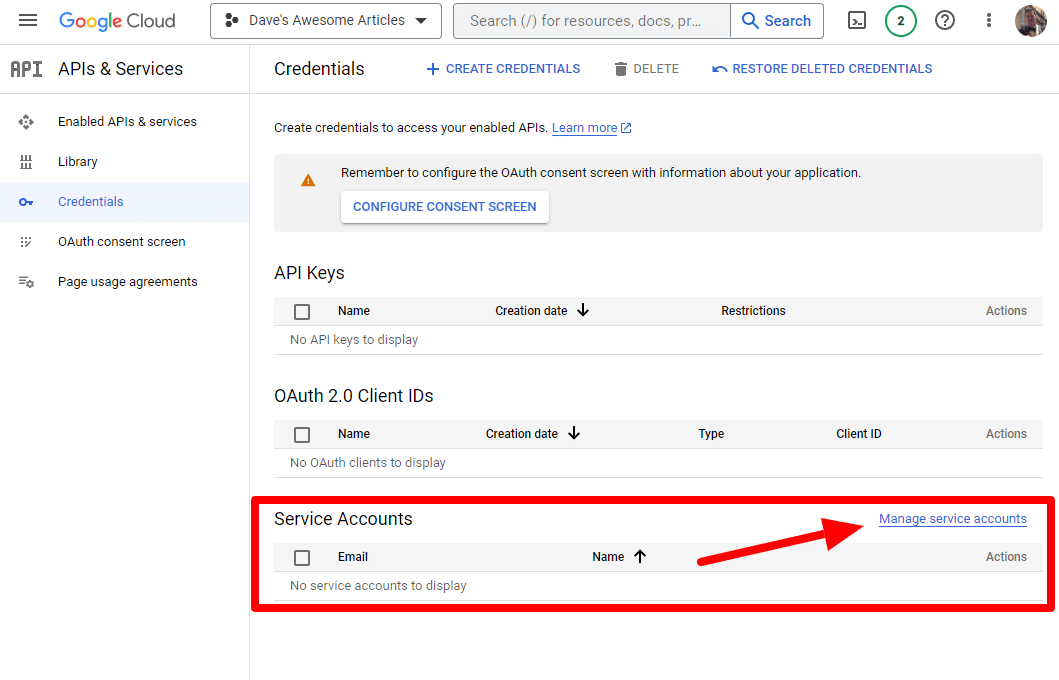
Erstellen Sie einfach ein Dienstkonto:
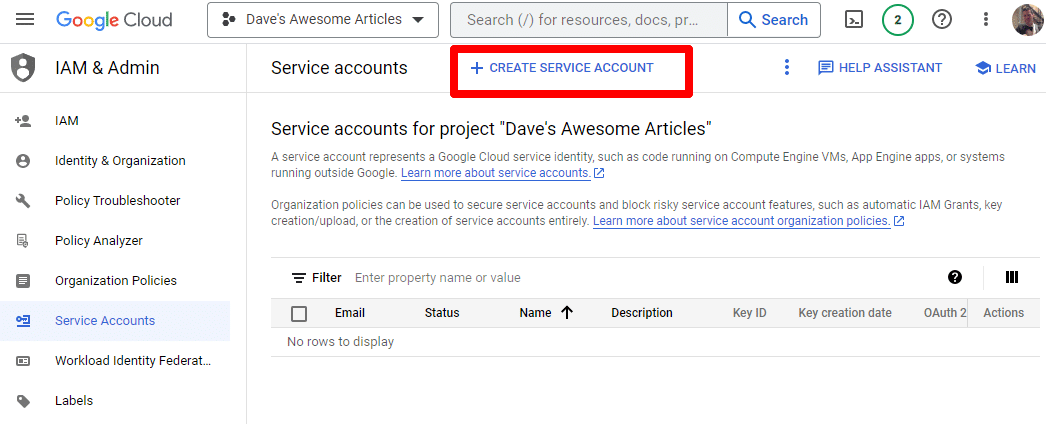
Geben Sie die erforderlichen Informationen ein:
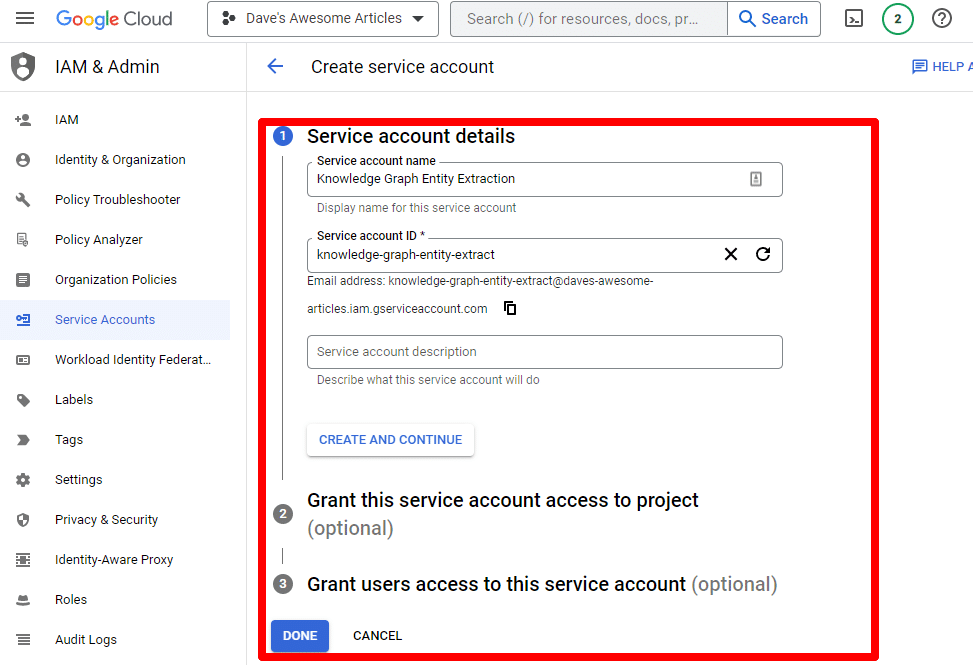
(Sie müssen ihm einen Namen geben und ihm Besitzerrechte gewähren.)
Jetzt haben wir unser Servicekonto. Jetzt müssen wir nur noch unseren Schlüssel erstellen.
Klicken Sie unter „Aktionen“ auf die drei Punkte und dann auf „Schlüssel verwalten“ .
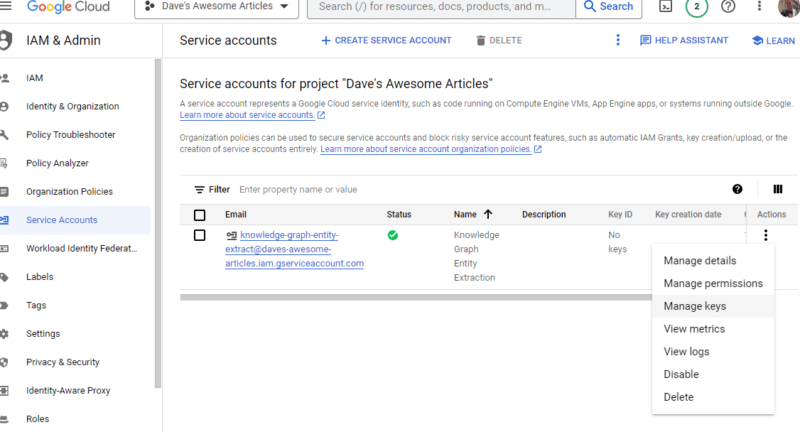
Klicken Sie auf Schlüssel hinzufügen und dann auf Neuen Schlüssel erstellen :
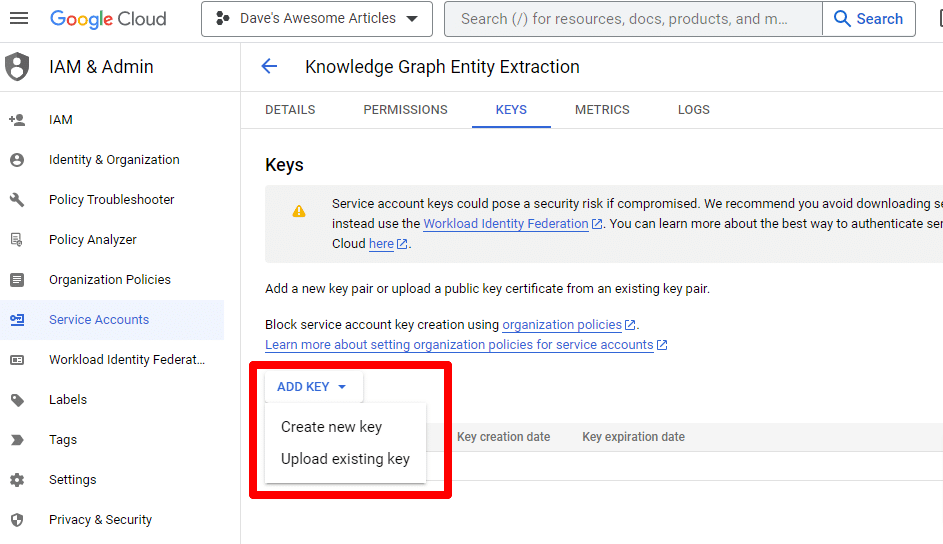
Der Schlüsseltyp ist JSON.
Sie werden sofort sehen, wie es an Ihren Standard-Download-Speicherort heruntergeladen wird.
Dieser Schlüssel ermöglicht den Zugriff auf Ihre APIs. Bewahren Sie ihn daher genau wie Ihre OpenAI-API sicher auf.
Alles klar... und wir sind zurück. Bereit, mit unserem Drehbuch fortzufahren?
Nachdem wir sie nun haben, müssen wir unseren API-Schlüssel und den Pfad zur heruntergeladenen Datei definieren. Der Code hierfür lautet:
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = '/PATH-TO-FILE/FILENAME.JSON' %env OPENAI_API_KEY=YOUR_OPENAI_API_KEY openai.api_key = os.environ.get("OPENAI_API_KEY") Sie ersetzen YOUR_OPENAI_API_KEY durch Ihren eigenen Schlüssel.
Außerdem ersetzen Sie /PATH-TO-FILE/FILENAME.JSON durch den Pfad zum Dienstkontoschlüssel, den Sie gerade heruntergeladen haben, einschließlich des Dateinamens.
Führen Sie die Zelle aus und schon kann es losgehen.
Schritt 4: Erstellen Sie die Funktionen
Als Nächstes erstellen wir die Funktionen für:
- Durchsuchen Sie die Webseite, die wir oben eingegeben haben.
- Analysieren Sie den Inhalt und extrahieren Sie die Entitäten.
- Generieren Sie einen Artikel mit GPT-4.
#The function to scrape the web page def scrape_url(url): response = requests.get(url) soup = BeautifulSoup(response.content, "html.parser") paragraphs = soup.find_all("p") text = " ".join([p.get_text() for p in paragraphs]) return text #The function to pull and analyze the entities on the page using Google's Knowledge Graph API def analyze_content(content): client = language_v1.LanguageServiceClient() response = client.analyze_entities( request={"document": language_v1.Document(content=content, type_=language_v1.Document.Type.PLAIN_TEXT), "encoding_type": language_v1.EncodingType.UTF8} ) top_entities = sorted(response.entities, key=lambda x: x.salience, reverse=True)[:10] for entity in top_entities: print(entity.name) return top_entities #The function to generate the content def generate_article(content): openai.api_key = os.environ["OPENAI_API_KEY"] response = openai.ChatCompletion.create( messages = [{"role": "system", "content": "You are a highly skilled writer, and you want to produce articles that will appeal to users and rank well."}, {"role": "user", "content": content}], model="gpt-4", max_tokens=1500, #The maximum with GPT-3 is 4096 including the prompt n=1, #How many results to produce per prompt #best_of=1 #When n>1 completions can be run server-side and the "best" used stop=None, temperature=0.8 #A number between 0 and 2, where higher numbers add randomness ) return response.choices[0].message.content.strip()Das ist ziemlich genau das, was die Kommentare beschreiben. Wir erstellen drei Funktionen für die oben beschriebenen Zwecke.
Aufmerksame Augen werden es bemerken:
messages = [{"role": "system", "content": "You are a highly skilled writer, and you want to produce articles that will appeal to users and rank well."}, Sie können den Inhalt bearbeiten ( You are a highly skilled writer, and you want to produce articles that will appeal to users and rank well. ) und die Rolle beschreiben, die ChatGPT übernehmen soll. Sie können auch einen Ton hinzufügen (z. B. „Sie sind ein freundlicher Schriftsteller …“).
Schritt 5: Scrapen Sie die URL und drucken Sie die Entitäten aus
Jetzt machen wir uns die Hände schmutzig. Es ist Zeit zu:
- Scrapen Sie die URL, die wir oben eingegeben haben.
- Rufen Sie den gesamten Inhalt ab, der sich in Absatz-Tags befindet.
- Führen Sie es über die Google Knowledge Graph API aus.
- Geben Sie die Entitäten für eine schnelle Vorschau aus.
Grundsätzlich möchten Sie zu diesem Zeitpunkt alles sehen. Wenn Sie nichts sehen, schauen Sie auf einer anderen Website nach.
content = scrape_url(url) entities = analyze_content(content)Sie können sehen, dass Zeile eins die Funktion aufruft, die die URL löscht, die wir zuerst eingegeben haben. In der zweiten Zeile wird der Inhalt analysiert, um die Entitäten und Schlüsselmetriken zu extrahieren.
Ein Teil der Funktion „analysate_content“ druckt auch eine Liste der gefundenen Entitäten zur schnellen Referenz und Überprüfung aus.
Schritt 6: Analysieren Sie die Entitäten
Als ich anfing, mit dem Skript herumzuspielen, begann ich mit 20 Entitäten und stellte schnell fest, dass das normalerweise zu viele sind. Aber ist die Standardeinstellung (10) richtig?
Um das herauszufinden, schreiben wir die Daten zur einfacheren Auswertung in W&B Tables. Die Daten werden für zukünftige Auswertungen auf unbestimmte Zeit gespeichert.
Zunächst müssen Sie sich etwa 30 Sekunden Zeit nehmen, um sich anzumelden. (Keine Sorge, für solche Dinge ist es kostenlos!) Sie können dies unter https://wandb.ai/site tun.
Sobald Sie das getan haben, lautet der Code dafür:
run = wandb.init(project="Article Summary With Entities") columns=["Name", "Salience"] ent_table = wandb.Table(columns=columns) for entity in entities: ent_table.add_data(entity.name, entity.salience) run.log({"Entity Table": ent_table}) wandb.finish()Bei der Ausführung sieht die Ausgabe so aus:
Und wenn Sie auf den Link klicken, um Ihren Lauf anzusehen, finden Sie Folgendes:
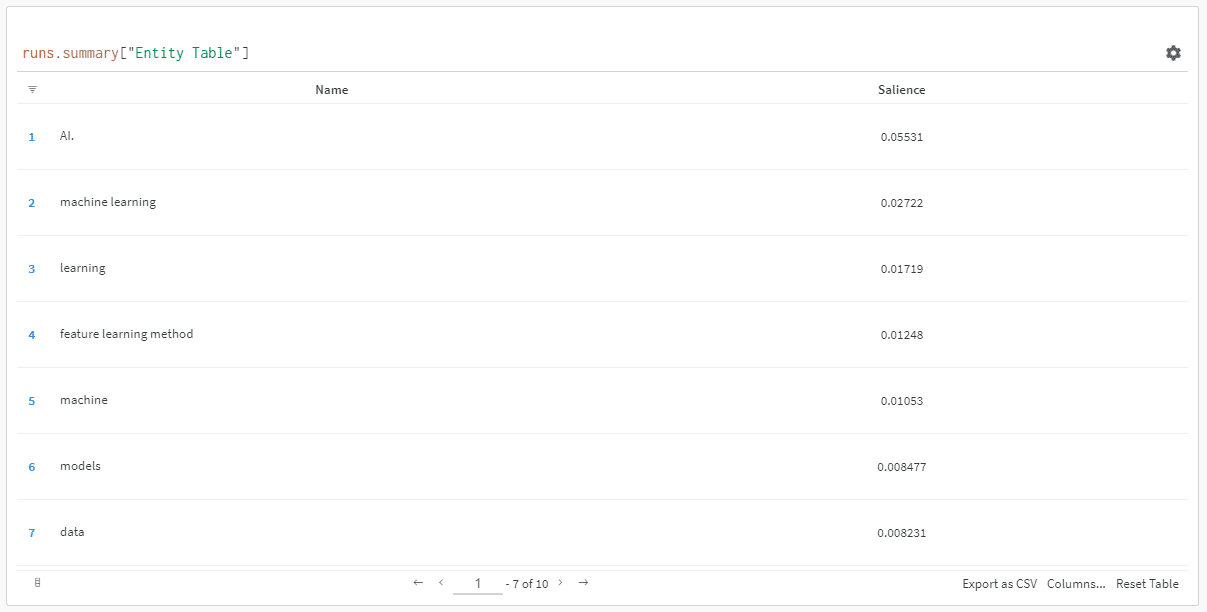
Sie können einen Rückgang des Salienzwerts feststellen. Denken Sie daran, dass dieser Wert berechnet, wie wichtig dieser Begriff für die Seite ist, nicht für die Suchanfrage.
Wenn Sie diese Daten überprüfen, können Sie die Anzahl der Entitäten basierend auf der Bedeutung oder nur dann anpassen, wenn irrelevante Begriffe auftauchen.
Um die Anzahl der Entitäten anzupassen, gehen Sie zur Funktionszelle und bearbeiten Sie Folgendes:
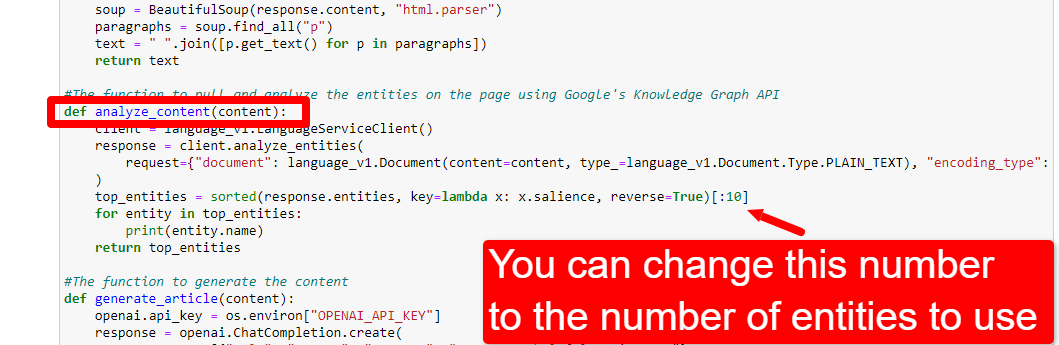
Anschließend müssen Sie die Zelle und die Zelle, die Sie zum Scrapen und Analysieren des Inhalts ausgeführt haben, erneut ausführen, um die neue Entitätsanzahl zu verwenden.
Schritt 7: Erstellen Sie die Artikelgliederung
In dem Moment, auf den Sie alle gewartet haben, ist es an der Zeit, die Artikelgliederung zu erstellen.
Dies geschieht in zwei Teilen. Zuerst müssen wir die Eingabeaufforderung generieren, indem wir die Zelle hinzufügen:
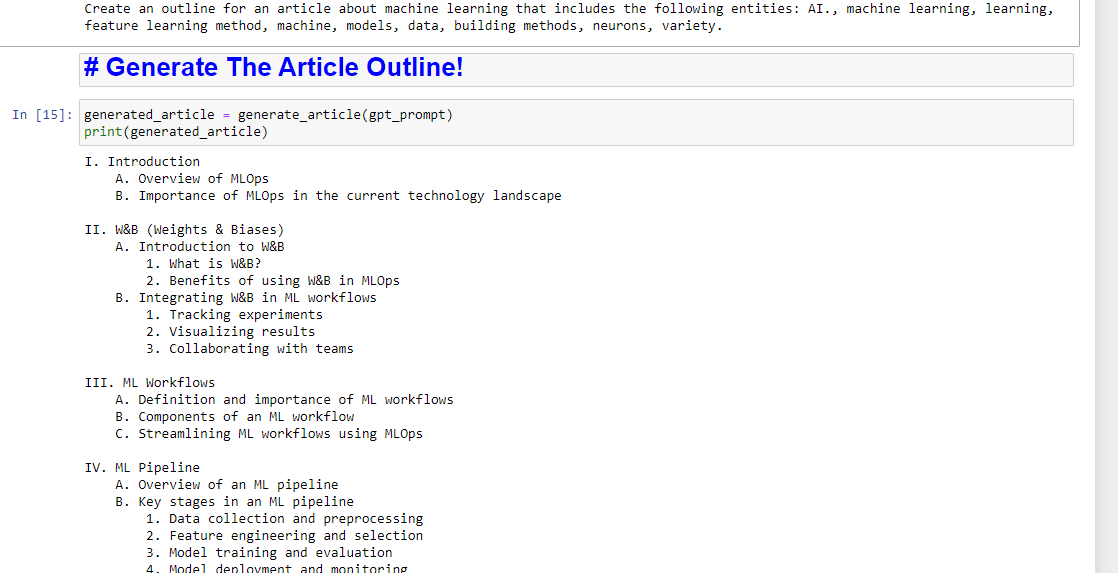
entity_names = [entity.name for entity in entities] gpt_prompt = f"Create an outline for an article about {query} that includes the following entities: {', '.join(entity_names)}." print(gpt_prompt)Dadurch entsteht im Wesentlichen eine Aufforderung zum Generieren eines Artikels:

Und dann müssen Sie nur noch die Artikelgliederung wie folgt erstellen:
generated_article = generate_article(gpt_prompt) print(generated_article)Was etwa Folgendes hervorbringen wird:
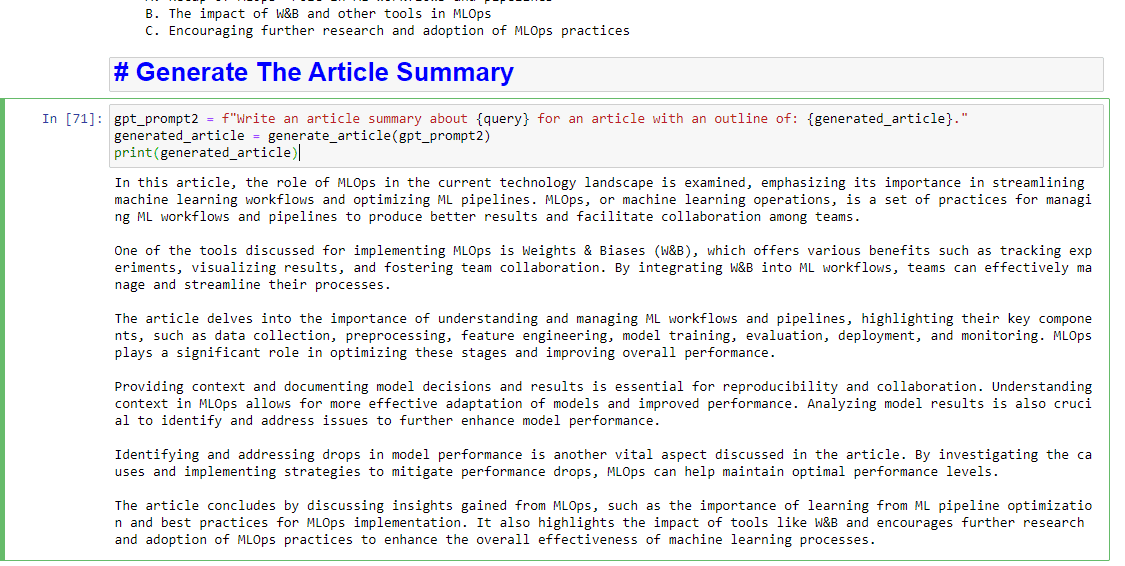
Und wenn Sie auch eine Zusammenfassung verfassen lassen möchten, können Sie Folgendes hinzufügen:
gpt_prompt2 = f"Write an article summary about {query} for an article with an outline of: {generated_article}." generated_article = generate_article(gpt_prompt2) print(generated_article)Was etwa Folgendes hervorbringen wird:
Die in diesem Artikel geäußerten Meinungen sind die des Gastautors und nicht unbedingt die von Search Engine Land. Die Autoren unserer Mitarbeiter sind hier aufgelistet.