
Wie Google Autoren über EEAT identifizieren und bewerten kann
Veröffentlicht: 2023-04-17Google legt beim Ranking der Suchergebnisse mehr Wert auf die Inhaltsquelle, insbesondere den Autor. Die Einführung von Perspectives, About this result und About this author in den SERPs macht dies deutlich.
In diesem Artikel wird untersucht, wie Google Inhalte anhand der Erfahrung, Expertise, Autorität und Vertrauenswürdigkeit (EEAT) ihrer Autoren potenziell bewerten kann.
EEAT: Googles Qualitätsoffensive
Google hat die Bedeutung des EEAT-Konzepts für die Verbesserung der Qualität der Suchergebnisse und der Benutzererfahrung auf den SERPs hervorgehoben.
On-Page-Faktoren wie die allgemeine Qualität des Inhalts, Link-Signale (dh PageRank und Ankertexte) und Signale auf Entitätsebene spielen alle eine entscheidende Rolle.
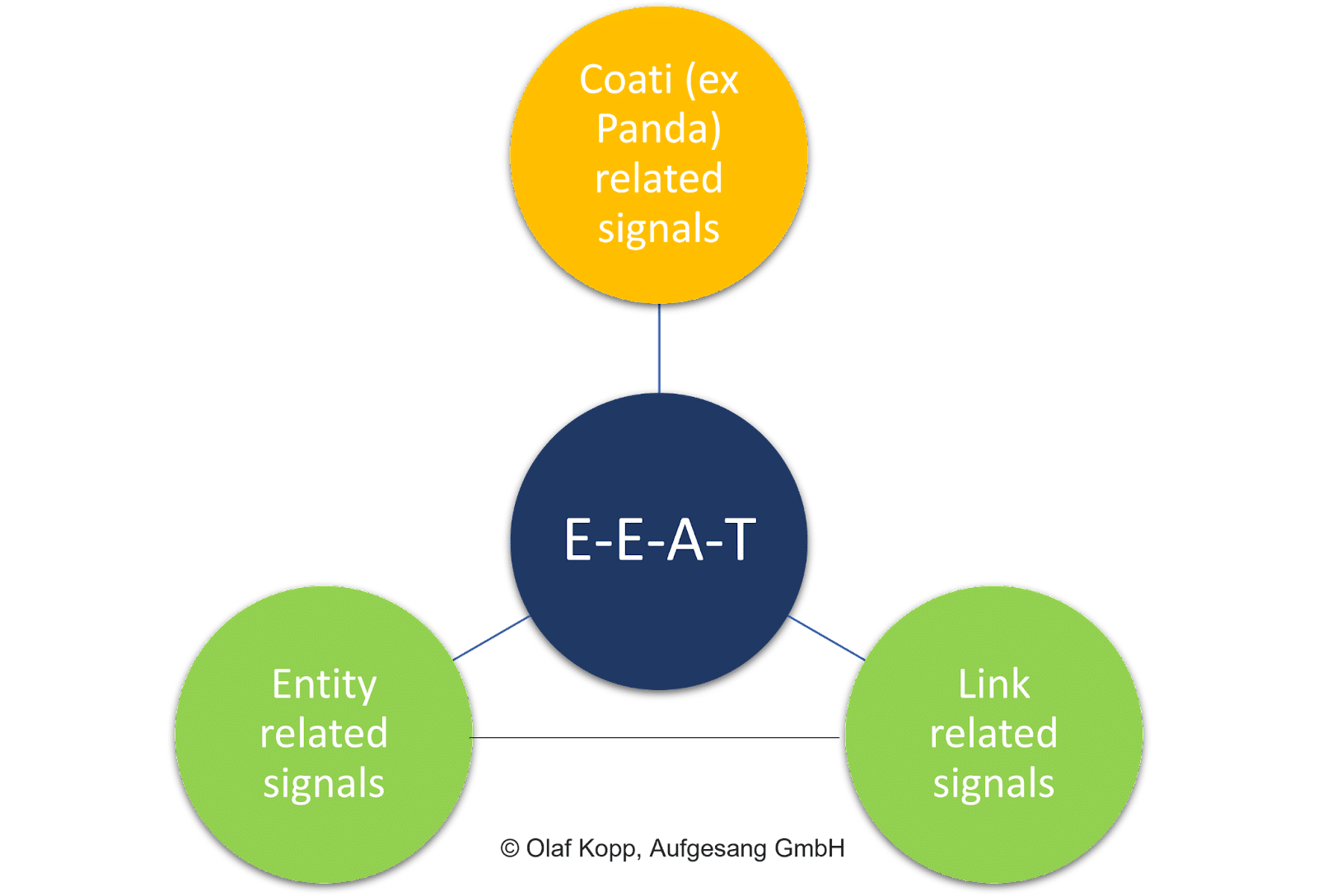
Im Gegensatz zum Dokumenten-Scoring steht bei EEAT nicht die Bewertung einzelner Inhalte im Vordergrund.
Das Konzept hat einen thematischen Bezug zu Domain und Urheber. Sie ist unabhängig von der Suchabsicht und den einzelnen Inhalten selbst.
Letztlich ist der EEAT ein von Suchanfragen unabhängiger Einflussfaktor.
EEAT bezieht sich hauptsächlich auf Themenbereiche und versteht sich als Bewertungsschicht, die Sammlungen von Inhalten und Off-Page-Signalen in Bezug auf Entitäten wie Unternehmen, Organisationen, Personen und deren Domänen bewertet.
Die Bedeutung des Autors als Quelle des Inhalts
Lange vor (E-)EAT hat Google versucht, die Bewertung von Inhaltsquellen in Suchrankings einzubeziehen. So verschaffte das Vince-Update von 2009 markenerstellten Inhalten einen Ranking-Vorteil.
Über Projekte wie Knol oder Google+, die längst beendet sind, hat Google versucht, Signale für Autorenbewertungen zu sammeln (also über einen Social Graph und Nutzerbewertungen).
In den letzten 20 Jahren haben mehrere Google-Patente direkt oder indirekt auf Inhaltsplattformen wie Knol und soziale Netzwerke wie Google+ verwiesen.
Die Bewertung der Herkunft oder des Autors eines Inhaltsstücks nach den EEAT-Kriterien ist ein entscheidender Schritt, um die Qualität der Suchergebnisse weiterzuentwickeln.
Bei der Fülle an KI-generierten Inhalten und klassischem Spam macht es für Google keinen Sinn, minderwertige Inhalte in den Suchindex aufzunehmen.
Je mehr Inhalte es indiziert und bei der Informationsbeschaffung verarbeiten muss, desto mehr Rechenleistung wird benötigt.
EEAT kann Google helfen, basierend auf Entität, Domain und Autorenebene auf breiterer Ebene zu ranken, ohne dass jeder Inhalt gecrawlt werden muss.
Auf dieser Makroebene können Inhalte nach der Urheberentität klassifiziert und mit mehr oder weniger Crawl-Budget belegt werden. Google kann mit dieser Methode auch ganze Inhaltsgruppen von der Indexierung ausschließen.
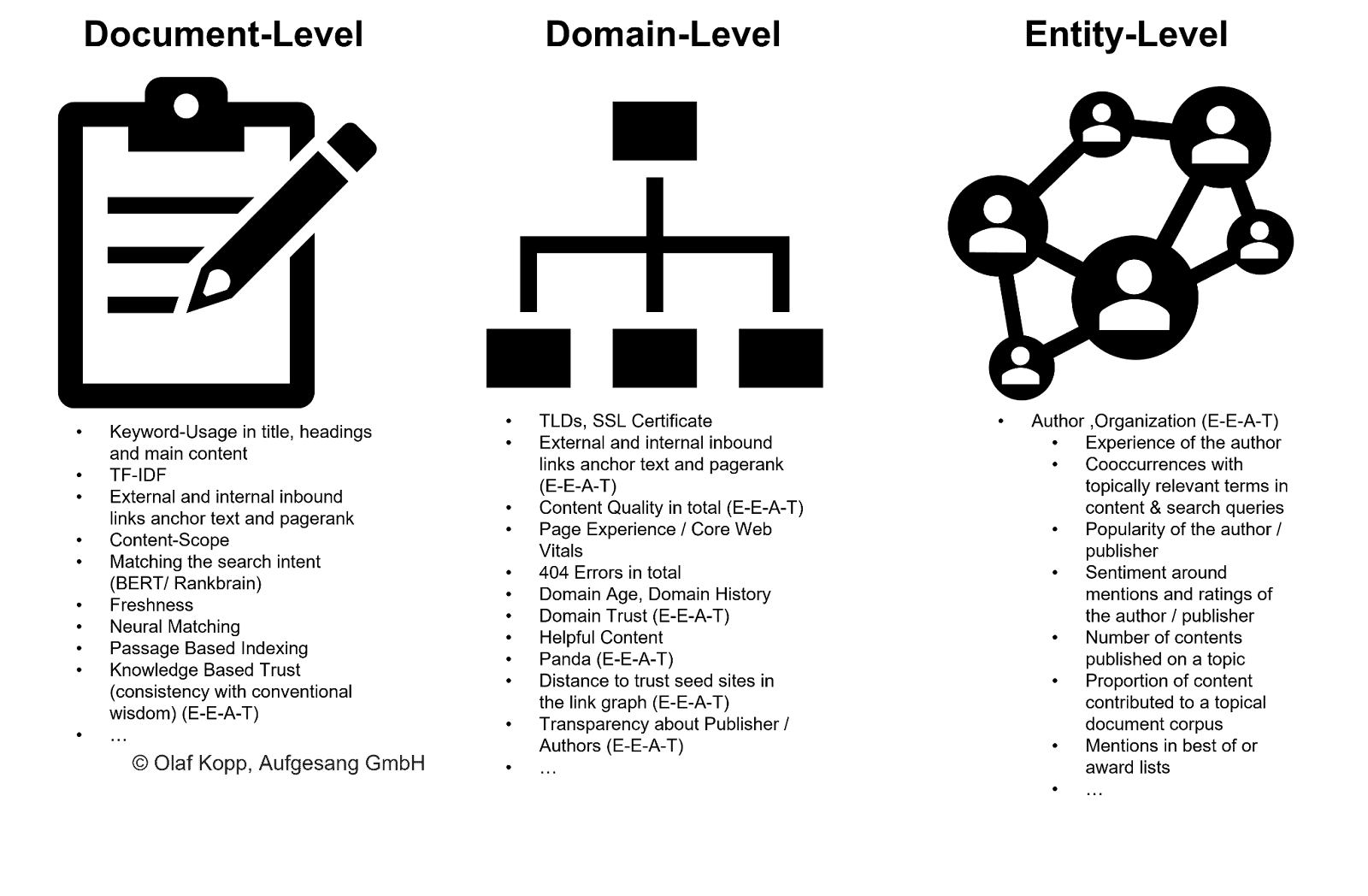
Wie kann Google Autoren identifizieren und Inhalte zuordnen?
Autoren gehören zum Entitätstyp Person. Es muss zwischen bereits bekannten Entitäten, die im Knowledge Graph erfasst sind, und bisher unbekannten oder nicht validierten Entitäten, die in einem Wissensspeicher wie dem Knowledge Vault erfasst sind, unterschieden werden.
Auch wenn Entitäten noch nicht im Knowledge Graph erfasst sind, kann Google mithilfe von maschinellem Lernen und Sprachmodellen Entitäten aus unstrukturierten Inhalten erkennen und extrahieren. Die Lösung heißt Entity Recognition (NER), eine Teilaufgabe der Verarbeitung natürlicher Sprache.
NER erkennt Entitäten basierend auf sprachlichen Mustern und Entitätstypen werden zugeordnet. Im Allgemeinen sind Substantive (benannte) Entitäten.
Moderne Information-Retrieval-Systeme verwenden dafür Word Embedding (Word2Vec).
Ein Zahlenvektor stellt jedes Wort eines Textes oder Textabsatzes dar, und Entitäten können als Knotenvektoren oder Entitätseinbettungen (Node2Vec/Entity2Vec) dargestellt werden.
Die Zuordnung von Wörtern zu einer grammatikalischen Klasse (Substantiv, Verb, Präpositionen etc.) erfolgt über Part-of-Speech (POS)-Tagging.
Substantive sind normalerweise Entitäten. Subjekte sind die Hauptentitäten und Objekte sind die sekundären Entitäten. Verben und Präpositionen können die Entitäten miteinander in Beziehung setzen.
Im Beispiel unten sind „olaf kopp“, „head of seo“, „cogründer“ und „aufgesang“ die benannten Entitäten. (NN = Substantiv).
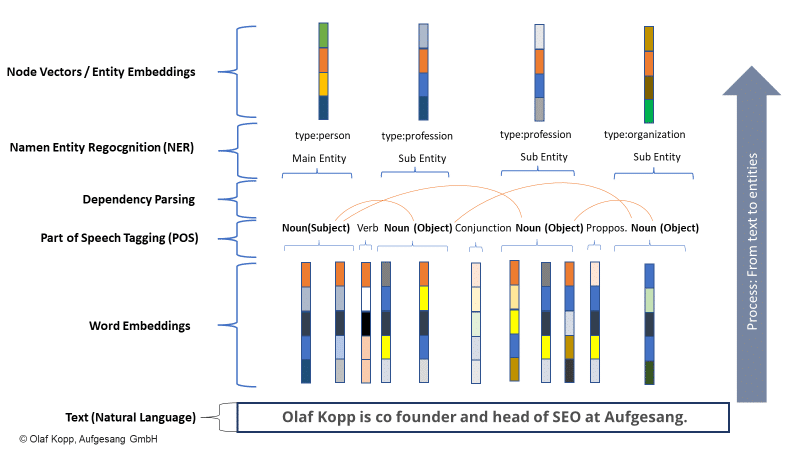
Die Verarbeitung natürlicher Sprache kann Entitäten identifizieren und die Beziehung zwischen ihnen bestimmen.
Dadurch entsteht ein semantischer Raum, der das Konzept einer Entität besser erfasst und versteht.
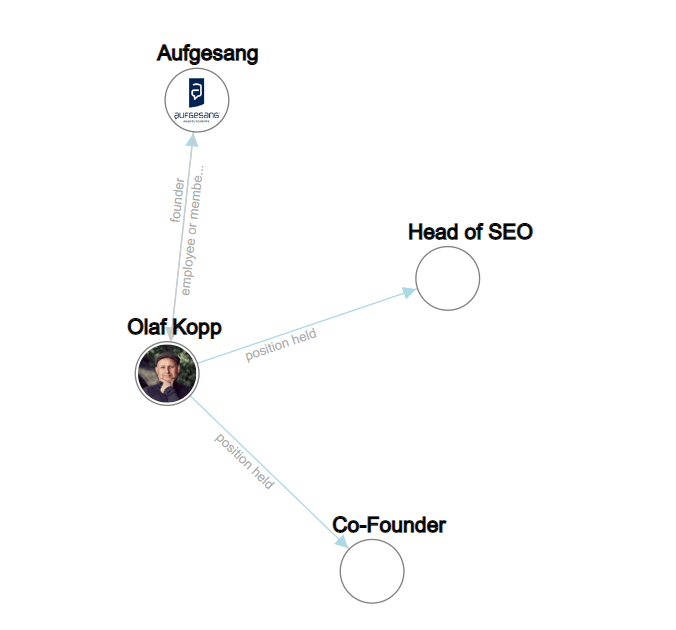
Mehr dazu finden Sie in „Wie Google NLP nutzt, um Suchanfragen und Inhalte besser zu verstehen.“
Das Gegenstück zu Autoreneinbettungen sind Dokumenteneinbettungen. Dokumenteinbettungen werden über eine Vektorraumanalyse mit Autorenvektoren verglichen. (Weitere Informationen finden Sie im Google-Patent „Erstellen von Vektordarstellungen von Dokumenten“.)
Alle Arten von Inhalten können als Vektoren dargestellt werden, was Folgendes ermöglicht:
- Zu vergleichende Inhaltsvektoren und Autorenvektoren in Vektorräumen.
- Dokumente, die nach Ähnlichkeit gruppiert werden sollen.
- Zuzuweisende Autoren.
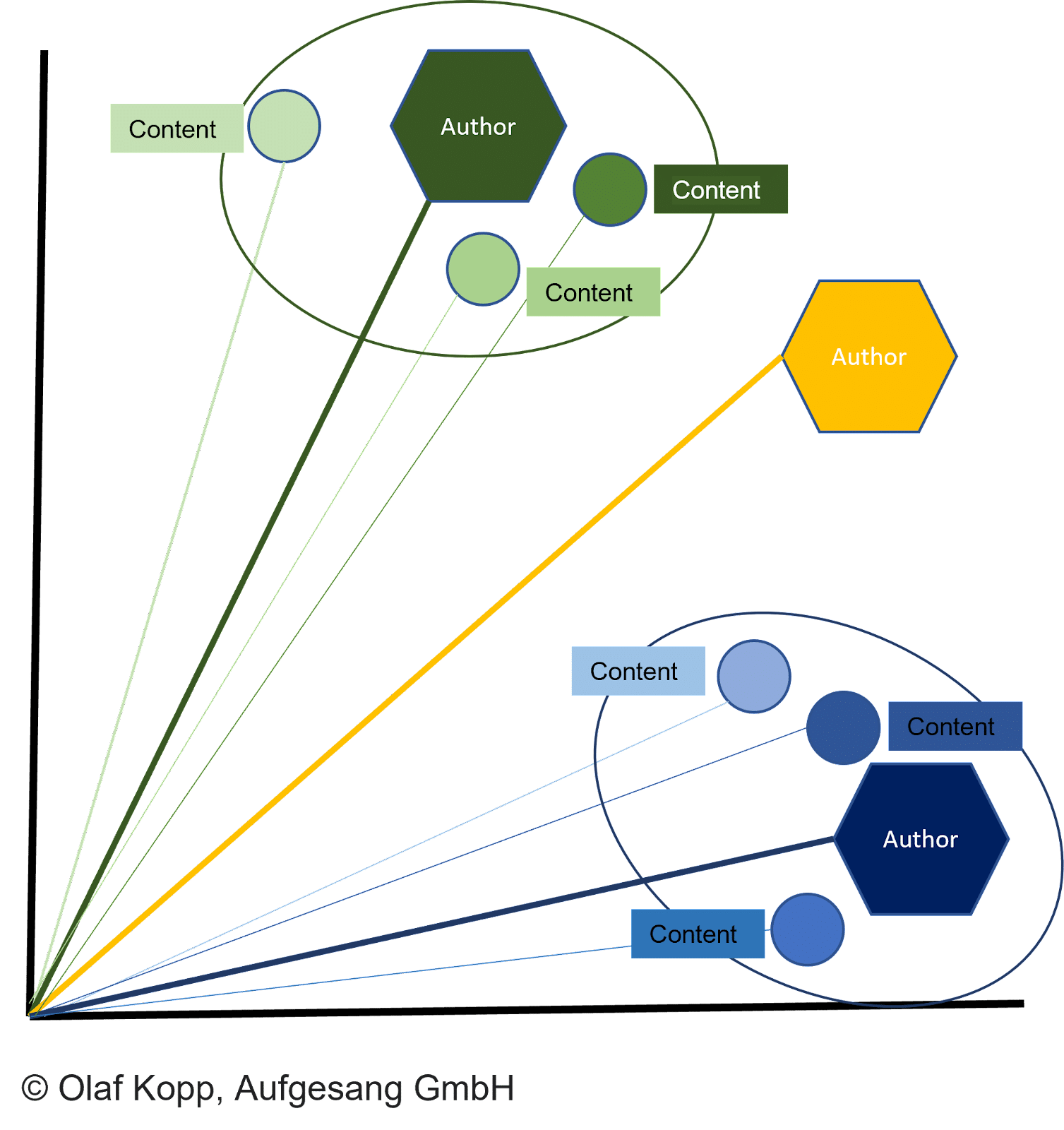
Der Abstand zwischen den Dokumentenvektoren und dem entsprechenden Autorenvektor beschreibt die Wahrscheinlichkeit, dass der Autor die Dokumente erstellt hat.
Das Dokument wird dem Autor zugeschrieben, wenn der Abstand kleiner als andere Vektoren ist und ein bestimmter Schwellenwert erreicht wird.
Dadurch kann auch verhindert werden, dass ein Dokument unter falscher Flagge erstellt wird. Der Autorenvektor kann dann, wie bereits beschrieben, anhand des im Inhalt angegebenen Autorennamens einer Autoreninstanz zugeordnet werden.
Wichtige Informationsquellen zu Autoren sind:
- Wikipedia-Artikel über die Person.
- Autorenprofile.
- Sprecherprofile.
- Social-Media-Profile.
Wenn Sie den Namen einer Person vom Typ Entität googeln, finden Sie in den ersten 20 Suchergebnissen Wikipedia-Einträge, Profile des Autors und URLs von Domains, die direkt mit dem Autor verbunden sind.
In mobilen SERPs können Sie sehen, aus welchen Quellen Google eine direkte Beziehung zur Personenentität herstellt.
Google hat alle Ergebnisse oberhalb der Icons für die Social-Media-Profile als Quellen mit direktem Bezug zur Entität erkannt.

Dieser Screenshot der Suchanfrage nach „olaf kopp“ zeigt, dass Entitäten mit Quellen verknüpft sind.
Es zeigt auch eine neue Variante eines Knowledge Panels. Anscheinend bin ich hier Teil eines Beta-Tests geworden.
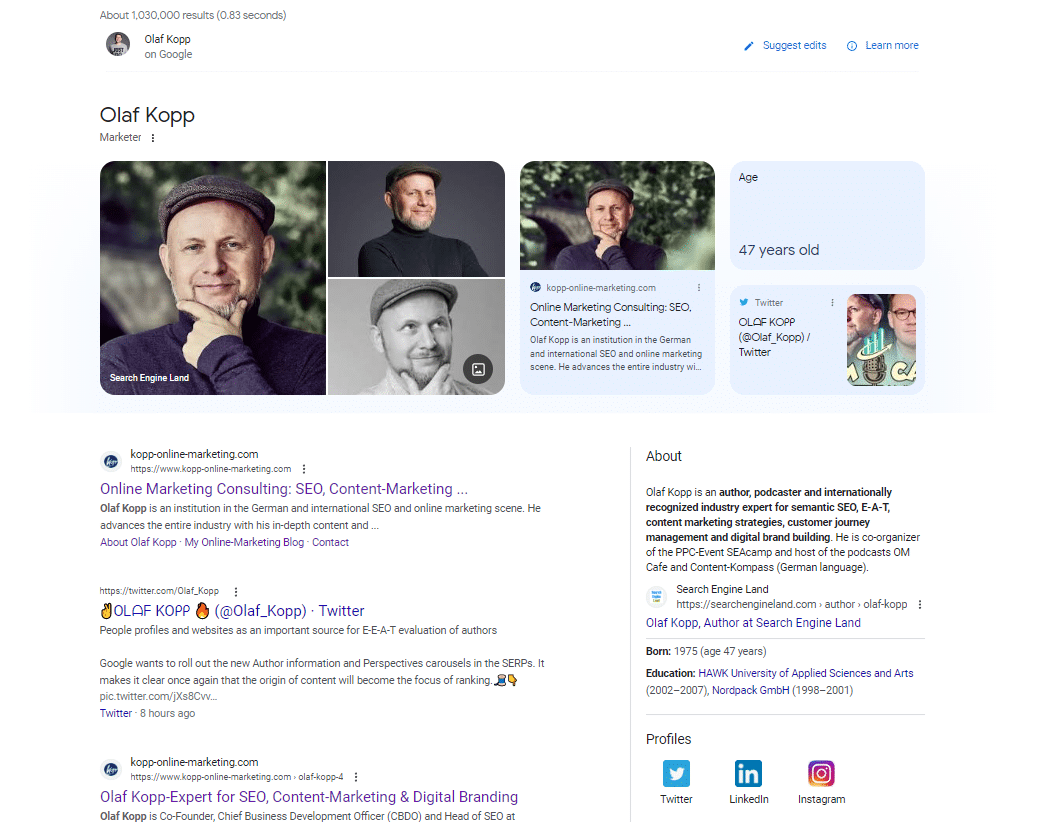
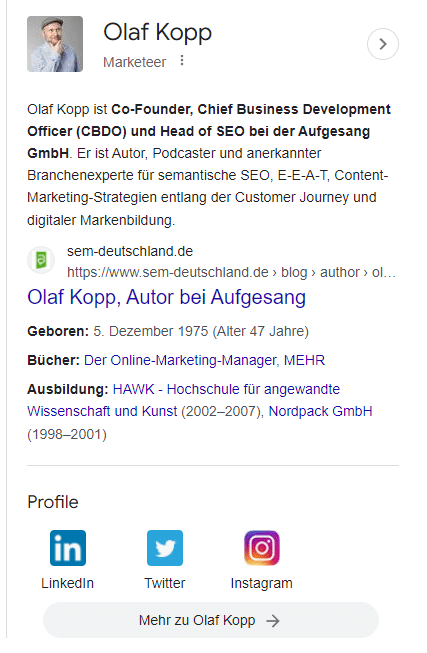
In diesem Screenshot sehen Sie, dass Google neben Bildern und Attributen (Alter) meine Domain und mein Social-Media-Profil direkt mit meiner Entität verknüpft und im Knowledge Panel ausliefert.
Da es keinen Wikipedia-Artikel über mich gibt, wird die About-Beschreibung aus dem Autorenprofil bei Search Engine Land in den USA und dem Autorenprofil der Agentur-Website in Deutschland geliefert.
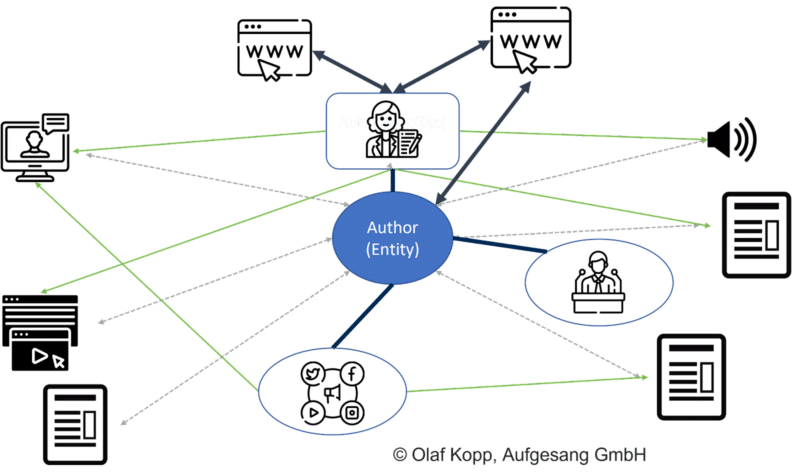
Persönliche Profile im Web helfen Google dabei, Autoren zu kontextualisieren und Social-Media-Profile und Domänen zu identifizieren, die einem Autor zugeordnet sind.
Autorenboxen oder Autorensammlungen in Autorenprofilen helfen Google bei der Zuordnung von Inhalten zu Autoren. Der Name des Autors ist als Identifikator nicht ausreichend, da Mehrdeutigkeiten auftreten können.
Sie sollten auf die Autorenbeschreibungen aller achten, um Konsistenz zu gewährleisten. Google kann sie verwenden, um die Gültigkeit der Entitäten im Vergleich zueinander zu überprüfen.
Holen Sie sich den täglichen Newsletter, auf den sich Suchmaschinenvermarkter verlassen.
Siehe Bedingungen.
Interessante Google-Patente für die EEAT-Bewertung von Autoren
Die folgenden Patente geben einen Einblick in mögliche Methoden, wie Google Autoren identifiziert, ihnen Inhalte zuordnet und sie im Hinblick auf EEAT bewertet.
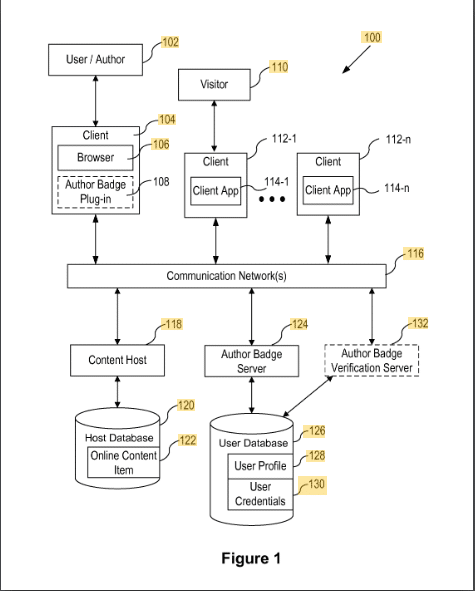
Abzeichen für Inhaltsautoren
Dieses Patent beschreibt die Zuordnung von Inhalten zu Autoren über ein Badge.
Die Zuordnung der Inhalte zu einem Autoren-Badge erfolgt über eine ID wie die E-Mail-Adresse oder den Namen des Autors. Die Überprüfung erfolgt über ein Addon im Browser des Autors.
Generieren von Autorenvektoren
Google hat dieses Patent 2016 unterzeichnet, mit einer Laufzeit bis 2036. Allerdings gab es bisher nur Patentanmeldungen für die USA, was darauf hindeutet, dass es weltweit noch nicht in Google-Suchen verwendet wird.

Das Patent beschreibt, wie Autoren basierend auf Trainingsdaten als Vektoren dargestellt werden.
Ein Vektor wird zu eindeutigen Parametern, die auf der Grundlage des typischen Schreibstils und der Wortwahl des Autors identifiziert werden.
Auf diese Weise können dem Autor bisher nicht zugeordnete Inhalte zugeordnet oder ähnliche Autoren zu Clustern zusammengefasst werden.
Das Content-Ranking kann dann für einen oder mehrere Autoren basierend auf dem Nutzerverhalten des Nutzers in der Vergangenheit bei der Suche (z. B. auf Discover) angepasst werden.
So würden Inhalte von bereits entdeckten Autoren und von ähnlichen Autoren besser ranken.
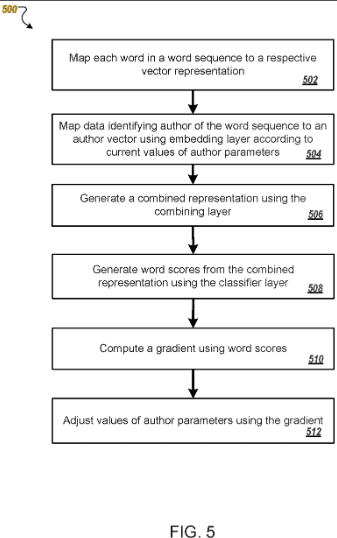
Dieses Patent basiert auf sogenannten Embeddings, wie etwa Autoren- und Word-Embeddings.
Embeddings sind heute der technologische Standard im Deep Learning und in der Verarbeitung natürlicher Sprache.
Daher liegt es auf der Hand, dass Google solche Verfahren auch zur Autorenerkennung und -zuordnung einsetzen wird.
Reputationsbewertung eines Autors
Dieses Patent wurde erstmals 2008 von Google unterzeichnet und hat eine Mindestlaufzeit von 2029. Dieses Patent bezieht sich ursprünglich auf das lange geschlossene Google Knol-Projekt.
Umso spannender ist es, warum Google ihn 2017 erneut unter dem neuen Titel Monetarisierung von Online-Inhalten zeichnete. Knol wurde 2012 von Google geschlossen.
Bei dem Patent geht es um die Ermittlung eines Reputations-Scores. Dabei können folgende Faktoren berücksichtigt werden:
- Rahmenebene des Autors.
- Veröffentlichungen in renommierten Medien.
- Anzahl der Veröffentlichungen.
- Alter der letzten Veröffentlichungen.
- Wie lange der Autor offiziell als Autor tätig ist.
- Anzahl der durch den Inhalt des Autors generierten Links.
Ein Autor kann mehrere Reputationswerte pro Thema und mehrere Aliase pro Fachgebiet haben.
Viele der im Patent genannten Punkte beziehen sich auf eine geschlossene Plattform wie Knol. Daher sollte dieses Patent an dieser Stelle genügen.
Agentenrang
Dieses Google-Patent wurde erstmals 2005 unterzeichnet und hat eine Mindestlaufzeit bis 2026.
Neben den USA wurde es auch in Spanien, Kanada und weltweit registriert, was es wahrscheinlich macht, dass es in der Google-Suche verwendet wird.
Das Patent beschreibt, wie digitale Inhalte einem Agenten (Herausgeber und/oder Autor) zugeordnet werden. Diese Inhalte werden unter anderem basierend auf einem Agentenrang eingestuft.
Der Agentenrang ist unabhängig von der Suchabsicht der Suchanfrage und wird anhand der dem Agenten zugeordneten Dokumente und deren Backlinks ermittelt.
Der Agent Rank bezieht sich ausschließlich auf eine Suchanfrage, Suchanfragen-Cluster oder ganze Themenbereiche.
„Die Agentenränge können optional auch relativ zu Suchbegriffen oder Kategorien von Suchbegriffen berechnet werden. Beispielsweise können Suchbegriffe (oder strukturierte Sammlungen von Suchbegriffen, dh Suchanfragen) in Themen klassifiziert werden, z. B. Sport oder medizinische Fachgebiete, und ein Agent kann in Bezug auf jedes Thema einen anderen Rang haben.“
Glaubwürdigkeit eines Autors von Online-Inhalten
Dieses Google-Patent wurde erstmals 2008 unterzeichnet und hat eine Mindestlaufzeit von 2029 und wurde bisher nur in den USA registriert.
Justin Lawyer hat ihn auf die gleiche Weise wie den Patent Reputation Score eines Autors entwickelt und steht in direktem Zusammenhang mit der Verwendung bei Recherchen.
In dem Patent findet man ähnliche Punkte wie in dem oben erwähnten Patent.
Für mich ist es das spannendste Patent, um Autoren hinsichtlich Vertrauen und Autorität zu bewerten.
Dieses Patent bezieht sich auf verschiedene Faktoren, die verwendet werden können, um die Glaubwürdigkeit eines Autors algorithmisch zu bestimmen.
Es beschreibt, wie eine Suchmaschine Dokumente unter dem Einfluss des Glaubwürdigkeitsfaktors und der Reputationsbewertung eines Autors bewerten kann.
Ein Autor kann mehrere Reputationswerte haben, je nachdem, zu wie vielen verschiedenen Themen er Inhalte veröffentlicht.
Die Reputationsbewertung eines Autors ist unabhängig vom Verlag.
Auch in diesem Patent gibt es einen Hinweis auf Links als möglichen Faktor in einer EEAT-Bewertung. Die Anzahl der Links zu veröffentlichten Inhalten kann die Reputationsbewertung eines Autors beeinflussen.
Folgende mögliche Signale für einen Reputations-Score werden genannt:
- Wie lange der Autor Inhalte in einem Fachgebiet produziert.
- Bekanntheitsgrad des Autors.
- Bewertungen von veröffentlichten Inhalten durch Benutzer.
- Wenn ein anderer Verlag die Inhalte des Autors mit überdurchschnittlichen Bewertungen veröffentlicht.
- Die Menge der vom Autor veröffentlichten Inhalte.
- Wie lange ist es her, dass der Autor zuletzt veröffentlicht hat.
- Bewertungen früherer Veröffentlichungen zu einem ähnlichen Thema durch den Autor.
Weitere interessante Informationen zum Reputations-Score aus dem Patent:
- Ein Autor kann mehrere Reputationswerte haben, je nachdem, zu wie vielen verschiedenen Themen er Inhalte veröffentlicht.
- Die Reputationsbewertung eines Autors ist unabhängig vom Verlag.
- Der Reputationswert kann herabgestuft werden, wenn duplizierte Inhalte oder Auszüge mehrfach veröffentlicht werden.
- Die Anzahl der Links zu den veröffentlichten Inhalten kann den Reputationswert beeinflussen.
Darüber hinaus spricht das Patent einen Glaubwürdigkeitsfaktor für Autoren an. Folgende Einflussfaktoren werden genannt:
- Geprüfte Angaben zum Beruf oder zur Rolle des Autors in einem Unternehmen. Es berücksichtigt auch die Glaubwürdigkeit des Unternehmens.
- Bezug der Tätigkeit zu den Themen der veröffentlichten Inhalte.
- Bildungs- und Ausbildungsstand des Autors.
- Die Erfahrung des Autors basiert auf der Zeit. Je länger ein Autor zu einem Thema publiziert, desto glaubwürdiger ist er. Die Erfahrung des Autors/Herausgebers kann für Google über das Datum der Erstveröffentlichung in einem Fachgebiet algorithmisch ermittelt werden.
- Die Anzahl der zu einem Thema veröffentlichten Inhalte. Wenn ein Autor viele Artikel zu einem Thema veröffentlicht, ist davon auszugehen, dass er ein Experte ist und eine gewisse Glaubwürdigkeit besitzt.
- Verstrichene Zeit bis zur letzten Veröffentlichung. Je länger es her ist, dass ein Autor zuletzt zu einem Thema veröffentlicht hat, desto mehr sinkt ein möglicher Reputationswert für dieses Thema. Je aktueller der Inhalt ist, desto höher ist er.
- Erwähnung des Autors/Herausgebers in Award- und Best-of-Listen.
Systeme und Verfahren zum Neuranken von geordneten Suchergebnissen
Dieses Google-Patent wurde erstmals 2013 unterzeichnet und hat eine Mindestlaufzeit bis 2033. Es wurde in den USA und weltweit registriert, was eine Nutzung durch Google wahrscheinlich macht.
Zu den Erfindern des Patents gehört Chung Tin Kwok, der an mehreren EEAT-relevanten Google-Patenten beteiligt war.
Das Patent beschreibt, wie Suchmaschinen neben den Verweisen auf die Inhalte des Autors auch den Anteil berücksichtigen können, den er zu einem thematischen Dokumentenkorpus bei einem Autoren-Scoring beitragen kann.
„In einigen Ausführungsformen umfasst das Bestimmen der ursprünglichen Autorenbewertung für die jeweilige Entität: Identifizieren einer Vielzahl von Inhaltsabschnitten in dem Index bekannter Inhalte, die als mit der jeweiligen Entität assoziiert identifiziert wurden, wobei jeder Abschnitt in der Vielzahl von Abschnitten eine vorbestimmte Menge darstellt von Daten im Index bekannter Inhalte; und Berechnen eines Prozentsatzes der Vielzahl der Abschnitte, die erste Instanzen der Inhaltsabschnitte im Index bekannter Inhalte sind.
Es beschreibt eine Neuklassifizierung von Suchergebnissen basierend auf der Autorenbewertung, einschließlich der Bewertung von Zitaten. Die Bewertung der Zitate basiert auf der Anzahl der Verweise auf die Dokumente eines Autors.
Ein weiteres Kriterium für die Autorenbewertung ist der Anteil an Inhalten, die ein Autor zu einem Korpus themenbezogener Dokumente beigetragen hat.
„[W]hier umfasst das Bestimmen der Autorenbewertung für eine jeweilige Entität: Bestimmen einer Zitationsbewertung für die jeweilige Entität, wobei die Zitationsbewertung einer Häufigkeit entspricht, mit der Inhalt, der mit der jeweiligen Entität verbunden ist, zitiert wird; Bestimmen einer ursprünglichen Autorenbewertung für die jeweiligen Entität, wobei die ursprüngliche Autorenbewertung einem Prozentsatz des Inhalts entspricht, der der jeweiligen Entität zugeordnet ist, die eine erste Instanz des Inhalts in einem Index bekannter Inhalte ist, und Kombinieren der Zitierbewertung und der ursprünglichen Autorenbewertung unter Verwendung einer vorbestimmten Funktion zur Erzeugung die Autorenpartitur."
Das Patent dient der Identifizierung von „Nachahmern“ und deren Herabstufung in den Rankings, kann aber auch zur allgemeinen Bewertung von Autoren herangezogen werden.
Schlüsselfaktoren für die Bewertung eines Autors
Zusätzlich zu den in den obigen Patenten aufgeführten möglichen Faktoren für eine Autorenbewertung sind hier noch ein paar weitere zu berücksichtigen (einige davon habe ich bereits in meinem Artikel „14 Wege, wie Google EAT bewerten kann“ erwähnt).
- Gesamtqualität des Inhalts zu einem Thema: Die Qualität, die ein Autor über seinen Inhalt zu einem Thema als Ganzes liefert, unabhängig von Domäne und Format, kann ein Faktor für EEAT sein. Signale hierfür können Nutzersignale, Links und andere Qualitätssignale auf inhaltlicher Ebene sein.
- PageRank oder Verweise auf die Inhalte des Autors.
- Kovorkommen des Autors in Inhalten (Podcasts, Videos, Websites, PDFs, Bücher) mit relevanten Themen oder Begriffen.
- Kovorkommen des Autors in Suchanfragen mit relevanten Themen oder Begriffen.
Anwenden von EEAT auf Autorenentitäten
Verfahren des maschinellen Lernens ermöglichen es, semantische Strukturen aus unstrukturierten Inhalten in großem Maßstab zu erkennen und abzubilden.
Dadurch kann Google viel mehr Entitäten erkennen und verstehen als bisher im Knowledge Graph dargestellt.
Dadurch spielt die Quelle der Inhalte eine immer wichtigere Rolle. EEAT kann algorithmisch über Dokumente, Inhalte und Domänen hinaus angewendet werden.
Das Konzept kann auch die Autoreneinheiten von Inhalten umfassen (dh die Autoren und Organisationen, die für die Inhalte verantwortlich sind).
Ich denke, wir werden in den nächsten Jahren einen noch bedeutenderen Einfluss von EEAT auf die Google-Suche sehen. Dieser Faktor kann für das Ranking sogar ebenso wichtig sein wie die Relevanzoptimierung einzelner Inhalte.
Die in diesem Artikel geäußerten Meinungen sind die des Gastautors und nicht unbedingt Search Engine Land. Mitarbeiter Autoren sind hier aufgelistet.