
So holen Sie mit Regex das Beste aus der Google Search Console API heraus
Veröffentlicht: 2022-11-02Die Google Search Console ist ein erstaunliches Tool, das unschätzbare Suchdaten von echten Benutzern direkt von Google bereitstellt. Während die Diagramme und Tabellen benutzerfreundlich sind, kann auf einen großen Teil der Daten nicht über die Benutzeroberfläche zugegriffen werden.
Die einzige Möglichkeit, an diese versteckten Daten zu gelangen, besteht darin, die API zu verwenden und all die wertvollen Suchdaten zu extrahieren, die Ihnen zur Verfügung stehen – wenn Sie wissen, wie. Dies ist mit regulären Ausdrücken möglich.
So können Sie die API der Google Search Console mithilfe regulärer Ausdrücke maximieren, so Eric Wu, VP of Product Growth bei Honey, einem PayPal-Unternehmen, der auf der SMX Advanced sprach.
Diagnose von SEO-Problemen mit GSC
Arbeiten Sie an einer Website mit stagnierendem oder rückläufigem Wachstum oder einem Core-Update-Ausfall?
Die meisten SEO-Experten wenden sich an die Google Search Console (GSC), um solche Probleme zu diagnostizieren.
(Wenn es die Ressourcen zulassen, können Sie sogar ein kostenpflichtiges Tool wie Ryte verwenden oder Ihre eigene Plattform erstellen.)
Zum Glück für die SEO-Community gibt es keinen Mangel an Looker Studio-Dashboards (ehemals Google Data Studio), die für die GSC-Analyse nützlich sind, darunter:
- Das kostenlose Dashboard von Aleyda Solis, das GSC-Daten verwendet, um potenzielle Ranking-Änderungen in den letzten Tagen durch das Google Core Update leicht zu identifizieren.
- Das Dashboard zur Überwachung des Suchverkehrs von Google, das jetzt Traffic-Daten von Discover und Google News abruft.
- Hannah Butlers Search Console Explorer Studio. (Und wenn Sie GSC-Daten praktisch bearbeiten und schnelle Erkenntnisse gewinnen möchten, können Sie Butlers Search Console Explorer Sheet verwenden.)
Dashboards ermöglichen es SEOs, sich einen Überblick über verschiedene Trends zu verschaffen, anstatt GSC zu verwenden und mehrere Klicks auszuführen, um zu den benötigten Daten zu gelangen.
Aber wenn Sie Unternehmenswebsites analysieren, können Sie auf einige Hindernisse stoßen.
- Sowohl Looker Studio als auch Google Sheets werden langsam geladen, besonders wenn Sie es mit großen Websites zu tun haben.
- Die GSC-Schnittstelle hat ein Exportlimit von 1.000 Zeilen.
- GSC hat ein riesiges Stichprobenproblem. Laut Similar.ai verpassen SEO-Teams von Unternehmen 90 % ihrer GSC-Keywords. Und wenn Sie wissen, wie man die Daten extrahiert, können Sie tatsächlich das 14-fache der Keywords erhalten.
Überwindung des Sampling-Problems von GSC
Explorer for Search ist ein weiteres Tool, das Sie für die GSC-Analyse verwenden können. Von Noah Learner und dem Team von Two Octobers wurde es mit Datenpipelines unter Verwendung der API von GSC erstellt, die dann Daten an BigQuery ausgibt (grundsätzlich Google Sheets umgeht und CSV-Dateien herunterlädt) und dann Informationen mit Data Studio visualisiert.
Auf diese Weise können Sie sicher sein, dass Sie an fast alle Daten gelangen.
Aufgrund des Sampling-Problems von GSC gibt es immer noch einen Vorbehalt, insbesondere bei großen E-Commerce-Websites mit vielen verschiedenen Kategorien. GSC zeigt nicht unbedingt alle Daten an, die aus diesen Verzeichnissen kommen.
Nach der Durchführung verschiedener Tests, um die meisten Daten aus der GSC-API herauszuholen, entdeckte das Similar.ai-Team einen Weg, die GSC-Sampling-Lücke zu schließen.
Sie fanden heraus, dass Sie durch Hinzufügen weiterer Unterverzeichnisse als unterschiedliche Profile in Ihrem GSC-Dashboard noch mehr Daten extrahieren können, da Google Ihnen auf dieser niedrigeren Ebene mehr Informationen liefert.
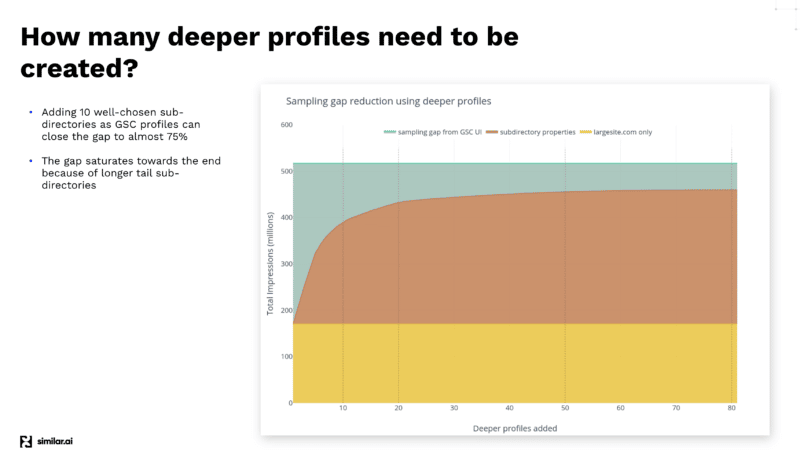
Wenn Sie beispielsweise example.com/televisions aufrufen und Ihrem GSC-Profil „televisions“ als Unterverzeichnis hinzufügen, gibt Google Ihnen nur die Keywords und die Klickinformationen für dieses Unterverzeichnis und darunter.
Und indem Sie viele dieser verschiedenen Unterverzeichnisse hinzufügen, können Sie viel mehr Informationen extrahieren.
Das löst das Stichprobenproblem, aber Sie können noch mehr Daten erhalten, indem Sie reguläre Ausdrücke verwenden.
Mehr GSC-Daten mit regulären Ausdrücken erhalten
Reguläre Ausdrücke oder Regex sind ein leistungsstarkes Werkzeug, um Ihre Daten zu verstehen.
Im April 2021 fügte Google der GSC Regex-Unterstützung hinzu – was SEOs mehr Möglichkeiten gibt, organische Suchdaten zu zerlegen.
Oft sind Daten nur dann nützlich, wenn Sie sie verstehen können. Und Regex hilft dabei, umsetzbare Erkenntnisse aus den umfangreichen Daten von GSC zu extrahieren.
Aber so leistungsfähig Regex auch sein mag, es kann schwierig sein, es zu lernen.
Der beste Ort, um reguläre Ausdrücke zu verstehen und tief in sie einzutauchen, ist die offizielle Dokumentation von Google auf GitHub. (Google verwendet RE2 in seinen Produkten, was eine Variante des regulären Ausdrucks ist.)
Während Regex in allen möglichen Programmiersprachen verfügbar ist, finden Sie es fast überall, sogar für diejenigen, die .htaccess-Dateien ändern.
In den nächsten Abschnitten finden Sie Anwendungsfälle für die Nutzung von Regex für GSC.
Regex-Informationsabfragen
Wenn Sie sich aktuelle Informationssuchanfragen in GSC ansehen, möchten Sie normalerweise Folgendes verstehen:
- Wie kommen die Leute eigentlich auf Ihre Website?
- Welche Fragen extrahieren sie?
Diese Dinge von einem einmaligen Standpunkt innerhalb des GSC zu betrachten, kann schwierig sein.
Du suchst immer nach den Wörtern „was“, „wie“, „warum“ und dann „wann“.
Es gibt ein paar Möglichkeiten, das Extrahieren von Informationsabfragen mit Regex weniger mühsam zu gestalten.
Daniel K. Cheung hat einen Regex-String geteilt, der Ihnen alle Abfragen zeigt, die „was“, „wie“, „warum“ und „wann“ enthalten und entweder einen Klick oder eine Impression erzielt haben:
-
"what|how|why|when"
Und dieser von Steve Toth geteilte Regex-String bringt das vorherige Beispiel noch eine Stufe höher:
-
^(who|what|where|when|why|how)[" "]
Sie können diese Zeichenfolge verwenden, wenn Sie fragenbasierte Abfragen erfassen möchten, die entweder mit „wer“, „was“, „wo“, „wann“, „warum“ und „wie“ beginnen und dann von einem Leerzeichen gefolgt werden.
Dies ist eine großartige Liste, die Sie verwenden können, wenn Sie nach Wörtern suchen, die eine Frage einleiten würden:
- sind, können, können nicht, konnten, konnten nicht, taten, taten nicht, tun, tut, tut nicht, wie, wenn, ist, ist nicht, sollte, sollte nicht, war, war nicht, waren, waren nicht, was, wann, wo, wer, wen, wessen, warum, wird, wird nicht, würde, würde nicht
All dies in Regex-Form zu bringen, würde ungefähr so aussehen:
-
^(are|can|can't|could|couldn't|did|didn't|do|does|doesn't|how|if|is|isn't|should|shouldn't|was|wasn't|were|weren't|what|when|where|who|whom|whose|why|will|won't|would|wouldn't)\s
In dieser 178 Zeichen langen Zeichenfolge:
- Sie haben das Caretzeichen (
^), das Ihnen sagt, dass die Abfrage mit diesem Wort beginnen muss: - Die Wörter werden mit senkrechten Strichen (
|) anstelle von Kommas getrennt. - Alle Wörter sind in Klammern eingeschlossen.
- Es gibt einen Backslash und das „s“ (
\s), das ein Leerzeichen nach dem Wort bezeichnet.
Das ist gut, kann aber auch mühsam werden.
Unten hat Wu die vorherige Liste von Wörtern vereinfacht, um Regex-freundlicher und kürzer zu sein, was ideal zum Kopieren und Einfügen ist. Die Pflege auf diese Weise trägt auch zur Effizienz bei.
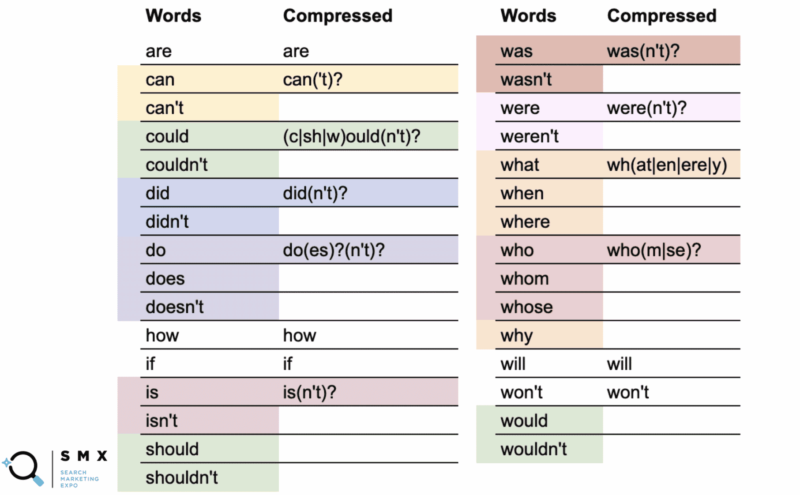
In der ersten Spalte stehen die normalen Wörter und in der zweiten Spalte die komprimierte Regex.
Zum Beispiel verwendet das Wort „can“ die komprimierte Version can('t)? .
Das Fragezeichen zeigt an, dass alles innerhalb der Klammern optional ist. Die komprimierte Syntax ermöglicht es Ihnen, sowohl das Wort „kann“ als auch „kann nicht“ abzudecken.
Interessanterweise können Sie dies mit could/couldn't, should/shouldn't und would/wouldn't tun, wobei der -ould- Teil der Wörter die gemeinsame Basis ist, wie (c|sh|w)ould(n't)? . Diese kurze Zeichenfolge deckt alle sechs dieser Fälle ab.
Während die Vereinfachung dieser langen Liste von Wörtern die Zeichenfolge weniger lesbar machte, ist das Tolle, dass sie besser in das Regex-Feld passt und Ihnen das Kopieren und Einfügen erleichtert.
-
^(are|can('t)?|(c|sh|w)ould(n't)?|did(n't)?|do(es)?(n't)?|how|if|is(n't)?|was(n't)?|were(n't)?|wh(at|en|ere|y)who(m|se)?|will|won't)\s
Wenn Sie noch einen Schritt weiter gehen, können Sie es noch mehr komprimieren. In diesem Fall reduzierte Wu die Zeichenanzahl von 135 auf 113 Zeichen.
-
^(are|can('t)?|how|if|wh(at|en|ere|y)|who(m|se)?|will|won't|((c|sh|w)ould|did(n't)?|do(es)?|was|is|were)(n't)?)\s
Reguläre Ausdrücke können sehr kompliziert werden. Wenn Sie einen Regex-String von jemand anderem erhalten und eindeutig machen möchten, was was tut, können Sie Regexper verwenden, um ihn zu visualisieren.
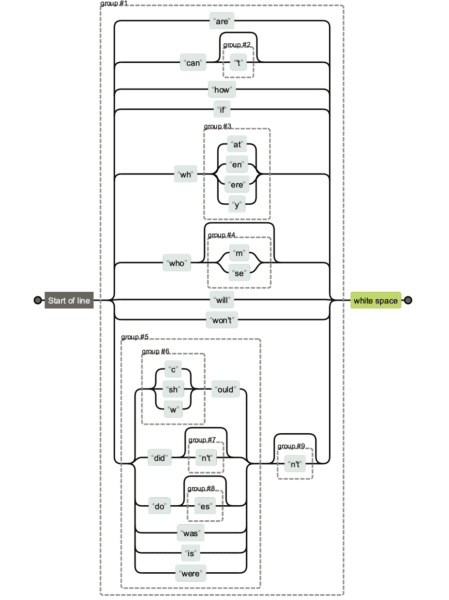
Unten sehen Sie einen Vergleich der verschiedenen Regex-String-Versionen. Es ist einfacher, die erste zu pflegen, und offensichtlich schwieriger, die letzte zu pflegen und zu lesen.

Aber manchmal spielt die Anzahl der Zeichen wirklich eine Rolle, besonders wenn Sie längere reguläre Ausdrücke haben.
Regex-Filterlimits für GSC sind laut Google Search Advocate Daniel Waisberg 4.096 Zeichen.
Das scheint ziemlich viel zu sein. Wenn Sie jedoch eine E-Commerce-Website haben und Domainnamen, Subdomains oder längere Verzeichnisse hinzufügen müssen, werden Sie höchstwahrscheinlich diese Grenze erreichen.
Regex-gebrandete Abfragen
Ein weiterer Fall, in dem Sie möglicherweise anfangen, die Regex-Zeichenbegrenzung in GSC zu erreichen, ist, wenn Sie es für Markenabfragen verwenden.
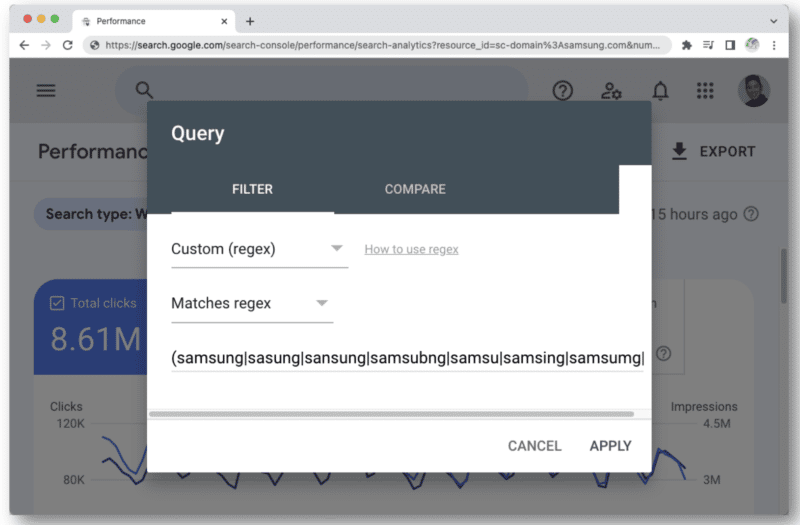
Wenn Sie an all die verschiedenen Arten von Rechtschreibfehlern eines Markennamens denken, die eine Person eingeben könnte, werden Sie schnell auf diese 4.096 Zeichen stoßen. Zum Beispiel:
- aamaung, damsung, mamsang, sam gesungen, samaung, samdung, samesung, sameung, samgsung, samgung, samsang, samsaung, samsgu, samshgg, samshng, samsing, samsnug, samssung, samsu, samsuag, samsubg, samsubng, samsug, samsumg, samsumng , samsun g, samsunb, samsund, samsund, samsunh, samsunt …
Hier hilft das Verständnis von Regex. Mit dieser Zeichenfolge können Sie den Markennamen „Samsung“ zusammen mit Rechtschreibfehlern erfassen:
-
(s+|a|d|z)[az\s]{1,4}m?[az\s]{1,6}(m|u|n|g|t|h|b|v)
Oft werden die Mittelteile des Wortes falsch geschrieben. Aber im Allgemeinen erhalten sie das richtige Format und die richtige Länge, und Sie können Ihre Syntax auf diese Weise angehen.
Berücksichtigen Sie bei Rechtschreibfehlern bei Markenabfragen Folgendes:

- Hauptbuchstaben , aus denen sich die Markenabfrage zusammensetzt.
- Konsonanten .
- Buchstaben, die harte Konsonanten umgeben .

Rot sind die harten Konsonanten, die Menschen normalerweise nicht übersehen, wenn sie einen Markennamen eingeben. Dies sind die Hauptbuchstaben, die diese bestimmte Marke ausmachen. Für „Samsung“ das „s“ am Anfang, das „m“ in der Mitte und dann „n“ und „g“ am Ende.
Die blauen Buchstaben, die diese Hauptkonsonanten auf der Tastatur umgeben, sind diejenigen, die sich normalerweise vertippen. Im Beispiel sehen Sie um das „s“ herum das „a“, „d“ und „z“. (Während das Layout für internationale Tastaturen unterschiedlich ist, ist das Konzept immer noch dasselbe.)
Die obige Regex-Zeichenfolge erfasst alle möglichen Varianten von „Samsung“.
Der andere große Trick hier ist in [az\s]{1,4} .
In Regex-Form bedeutet dies im Grunde: „Ich möchte jeden Buchstaben „a“ mit „z“ oder ein Leerzeichen ein- bis viermal abgleichen.“
Dies erfasst all die seltsamen Rechtschreibfehler, die mitten in einer Markenabfrage passieren können – wo eine Person möglicherweise mehrmals dieselbe Taste drückt oder versehentlich die Leertaste drückt.
Außerdem hat der Markenname eine bestimmte Länge („Samsung“ hat sieben Zeichen). Die Leute werden wahrscheinlich keine 20–50 Zeichen eingeben.
In diesem regulären Ausdruck vermuten wir also, dass sich zwischen „s“ und „m“ in „samsung“ jemand 1–4 Zeichen vertippen wird. Und dann von „m“ bis „g“ am Ende werden sie 1–6 Zeichen falsch schreiben, einschließlich Leerzeichen.
Wenn Sie all dies hinzufügen, können Sie die vielen Variationen einer Markenabfrage umfassend erfassen.
Beachten Sie außerdem, dass der Markenname in verschiedenen Teilen der Abfrage erscheinen kann.

Wir müssen also sicherstellen, dass der Markenname selbst erfasst wird. Es sollte entweder sein:
- Zu Beginn der Abfrage.
- In der Mitte der Abfrage (also von Leerzeichen umgeben).
- Oder am Ende der Abfrage.
Der reguläre Ausdruck dafür lautet wie folgt:
-
(^|\s)(s+|a|d|z)[az\s]{1,4}m?[az\s]{1,6}(m|u|n|g|t|h|b|v)(\s|$)
Damit werden alle Suchanfragen erfasst, bei denen der Markenname „Samsung“ entweder am Anfang, in der Mitte oder am Ende steht.
- Stringanfang =
^ - Umgeben von Leerzeichen =
\s - Ende der Zeichenfolge =
$
Der Beitrag von JC Chouinard, Reguläre Ausdrücke (RegEx) in der Google Search Console, taucht noch tiefer in Regex-Beispiele ein.
Regex und die GSC-API in Aktion
Reguläre Ausdrücke erwiesen sich als nützlich für Wu und sein Team, als sie mit einem Client arbeiteten, der nach einem Core-Update auf Traffic-Einbrüche stieß.
Nachdem sie sich die verschiedenen Probleme der E-Commerce-Website angesehen hatten, stellten sie fest, dass das Problem auf einigen Produktdetailseiten lag.
Sie mussten Seitentypen für die Analyse in GSC segmentieren. Aufgrund der unterschiedlichen URL-Strukturen für US-amerikanische und internationale Produkte war dies jedoch eine komplexe Aufgabe.

Die internationalen Produkt-URLs der Website enthielten Sprach- und Ländercodes, die US-Produkt-URLs dagegen nicht.
Sogar die Verwendung der Regex-Syntax war schwierig, da Buchstaben und Bindestriche im Produkt-Slug, in den Kategorien und Unterkategorien vorhanden sind. Außerdem mussten sie die internationalen Produkt-URLs herausfiltern, um nur US-Seiten zu erfassen.
Um alle Landing- und Detailseiten für US-Produkte ( nicht i18n-Seiten) zu erhalten, haben sie die folgenden Regex-Strings entwickelt:
Einschließen: /([^/]+/){1,2}p?
Ausschließen: /[a-zA-Z]{2}|[a-zA-Z]{2}-[a-zA-Z]{2}/
Hier ist eine Aufschlüsselung:

Das Team wollte die Kategorie, die Unterkategorie und alle Produkte abgleichen, also enthielten sie:
- Jedes Zeichen, das kein Schrägstrich ist =
[^/]+ - 1 oder 2 Verzeichnisse =
/){1,2} - Manchmal gefolgt von einem Produkt-Slug =
p?
Ein Caretzeichen ( ^ ) bedeutet normalerweise den Anfang der Zeichenfolge. Aber wenn es innerhalb von Klammern steht (wie in [^/] ), zeigt es eine Negation an (dh „nichts in dieser Box“).
Diese Zeichenfolge /([^/]+/){1,2}p? bedeutet „Ich möchte eine beliebige Anzahl von Zeichen, die kein Schrägstrich sind, die zu einem Schrägstrich führen (der das Verzeichnis bezeichnet), und manchmal gefolgt von dem Buchstaben ‚p‘ (dem Präfix für Produkt-Slugs).“
Gleichzeitig wollte das Team die Länder- und Sprachkombination, die auch Buchstaben und Bindestriche enthielt, nicht abgleichen, also schlossen sie Folgendes aus:
- Beliebiges 2-Buchstaben-Verzeichnis =
[a-zA-Z]{2} - Kombination aus 2 Buchstaben + 2 Buchstaben Sprache-Land =
[a-zA-Z]{2}-[a-zA-Z]{2}
Das Erstellen eines regulären Ausdrucks, der alle Sprach- und Ländercodes allein abgleicht, wäre aufgrund aller möglichen Kombinationen mühsam, sodass sie dies nicht so angehen konnten wie für Informationsabfragen (wo jede einzelne Art von Kombination ausgeschlossen wurde).
Aber selbst nachdem sie diese Regex-Strings erstellt hatten, hatten sie ein Problem.
In der Google Search Console gibt es nur ein Feld zum Einfügen einer Regex-Zeichenfolge. Sie müssen entweder Übereinstimmung mit regulärem Ausdruck oder Übereinstimmung mit regulärem Ausdruck wählen – Sie können nicht beide gleichzeitig verwenden.
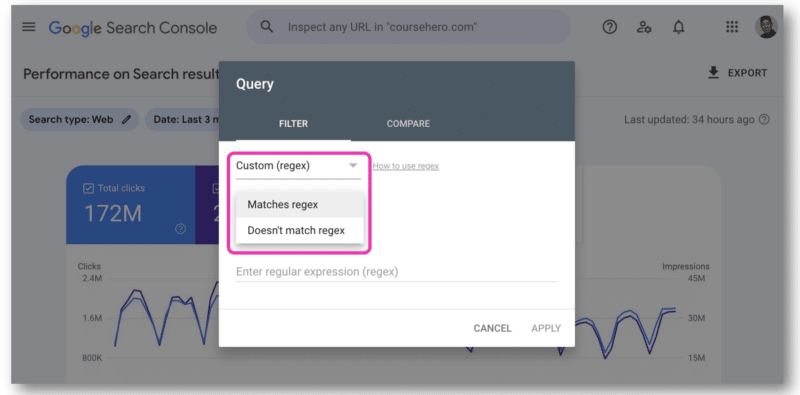
Hier hat sich die GSC-API als nützlich erwiesen, da sie das Verbinden von Regex-Strings ermöglicht.
In der API-Dokumentation der Google Search Console gibt es einen Link Jetzt ausprobieren.
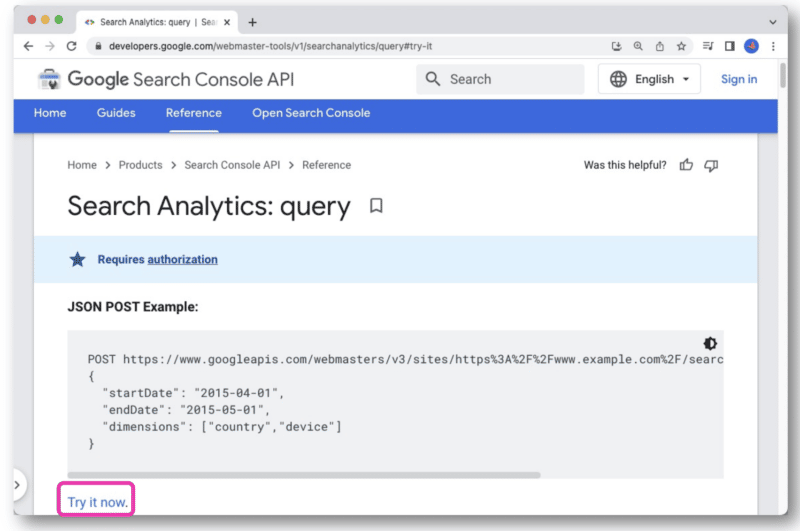
Nach dem Anklicken öffnet sich eine Konsole, mit der Sie eine Site auswählen und Ihre API-Anfrage über die Webansicht stellen können.
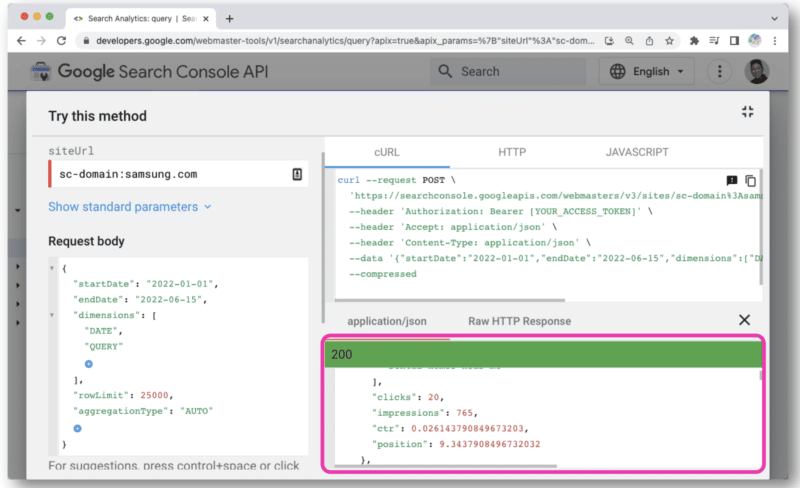
Aber um API-Abfragen besser zu verwalten, empfiehlt Wu die Verwendung von Postman auf dem Desktop oder Paw (das für Mac nativ ist).
Mit Postman können Sie Abfragen erstellen und für später speichern. Und wenn Sie Zugriff auf andere Websites haben, müssen Sie nicht jedes Mal eine neue Abfrage erstellen. Sie ändern einfach den Site-Namen durch eine Variable und stellen dann mehrere Anfragen.
Paw hingegen ist viel einfacher zu durchsuchen und zu verwenden.
Um auf die API zuzugreifen, müssen Sie Ihre API-Schlüssel abrufen. (Hier ist ein hilfreiches Tutorial von Chouinard.)
Sobald Sie diese Informationen erhalten haben, verfügen Sie über Ihre Client-ID und Client-Geheimnisse, die Sie Ihrer OAuth 2.0-Authentifizierung entweder in Postman oder Paw hinzufügen.
Von dort aus können Sie sich mit Ihrem normalen Konto anmelden.
Wu stellte hauptsächlich GSC-API-Anfragen unter Verwendung der Regex-Strings in Paw. Die Abfrage wird in der Mitte der Oberfläche eingegeben.
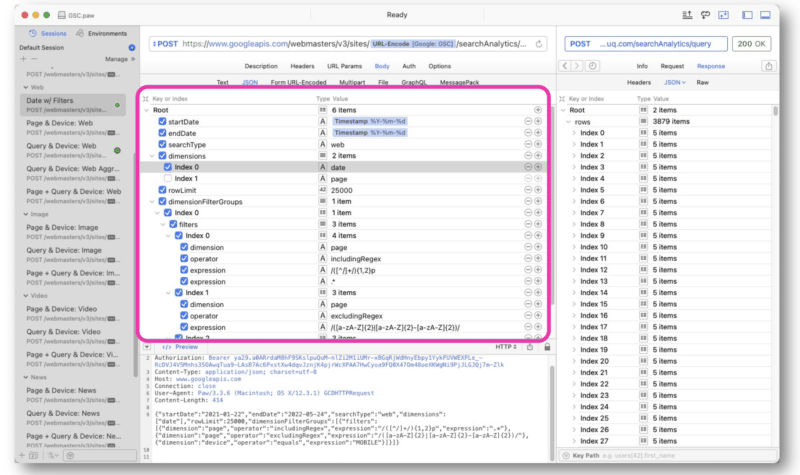
Die Antwort von Google ähnelt der der GSC-API-Webansicht. Die Daten können dann zur Weiterverarbeitung exportiert werden.
Da die Daten in JSON vorliegen, können die Informationen chaotisch und schwer lesbar sein.

Zu diesem Zweck können Sie einen kostenlosen und Open-Source-Befehlszeilen-JSON-Prozessor namens JQ verwenden, um die Informationen schön auszudrucken.

Die Daten sind nicht so nützlich, bis Sie sie in eine Tabelle übertragen. Leiten Sie die Datei ein, die Sie von Paw nach JQ exportiert haben. Öffnen Sie es und durchlaufen Sie dann jede Zeile – speichern Sie jedes Element, damit Sie es in eine CSV-Datei ausgeben können.
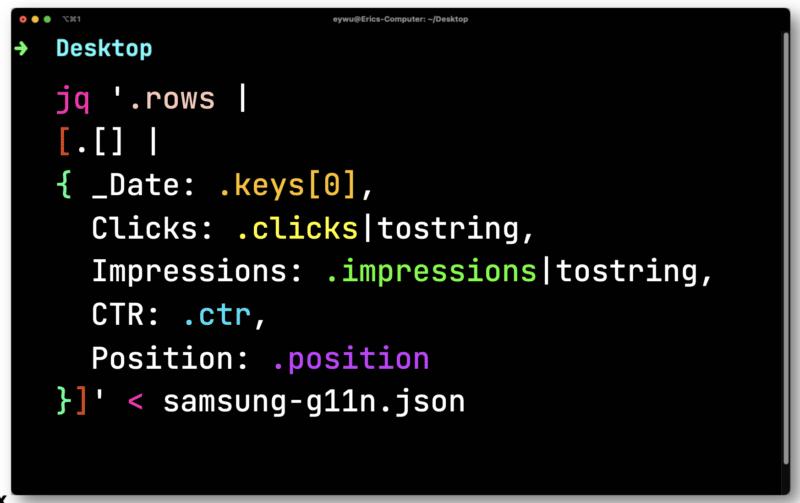
Hier müssen Sie Klicks und Impressionen konvertieren, die Floats sind (eine Zahl mit einer Dezimalstelle). Beide müssen in CSV-kompatible Zeichenfolgen konvertiert werden.
JQ gibt dann das folgende viel einfachere Format aus.
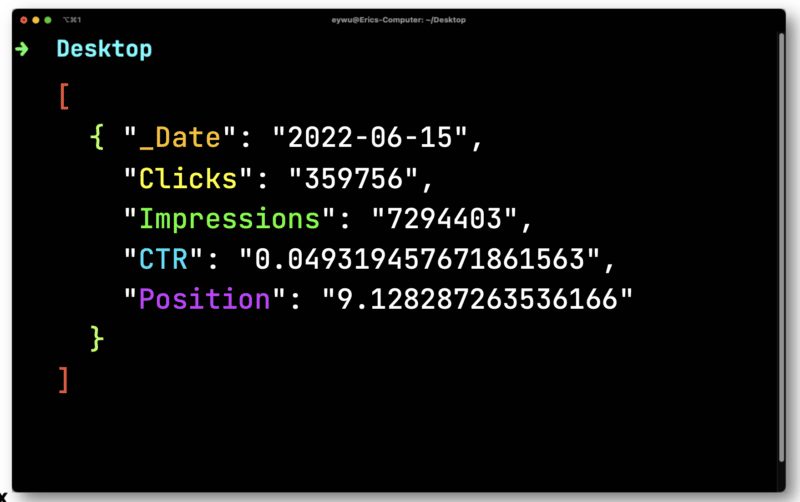
Als Nächstes verwenden Sie Dasel, um dieses Format zu übernehmen und es dann in eine CSV-Datei umzuwandeln.
Und hier ist das Endergebnis.
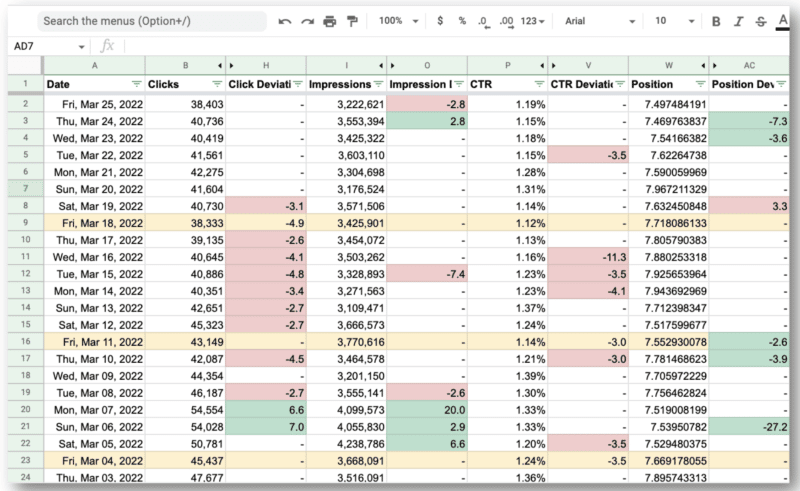
Das Erstaunliche für Wus Team ist, dass sie die Google Search Console API und reguläre Ausdrücke verwenden konnten, um:
- Filtern Sie alle internationalen Suchanfragen heraus und schauen Sie sich nur die USA an, wo sie die Hauptprobleme hatten.
- Identifizieren Sie die Tage, an denen die Website Probleme hatte.
Ansehen: Das Beste aus der Google Search Console API herausholen
Nachfolgend finden Sie das vollständige Video von Wus SMX Advanced-Präsentation.