
Verwendet Google ein ChatGPT-ähnliches System zur Erkennung von Spam- und KI-Inhalten und zum Ranking von Websites?
Veröffentlicht: 2023-02-01Die Überschrift ist absichtlich irreführend – aber nur soweit es um die Verwendung des Begriffs „ChatGPT“ geht.
„ChatGPT-like“ lässt Sie, den Leser, sofort wissen, auf welche Art von Technologie ich mich beziehe, anstatt das System als „ein Textgenerierungsmodell wie GPT-2 oder GPT-3“ zu beschreiben. (Außerdem wäre letzteres wirklich nicht so anklickbar …)
Was wir uns in diesem Artikel ansehen werden, ist ein älteres, aber hochrelevantes Google-Papier aus dem Jahr 2020, „Generative Models are Unsupervised Predictors of Page Quality: A Colossal-Scale Study“.
Worum geht es in dem Papier?
Beginnen wir mit der Beschreibung der Autoren. Sie leiten das Thema folgendermaßen ein:
„Viele haben Bedenken hinsichtlich der potenziellen Gefahren neuronaler Textgeneratoren in freier Wildbahn geäußert, was hauptsächlich auf ihre Fähigkeit zurückzuführen ist, menschlich aussehenden Text in großem Maßstab zu produzieren.
Klassifikatoren, die darauf trainiert sind, zwischen menschlichem und maschinell generiertem Text zu unterscheiden, wurden kürzlich eingesetzt, um das Vorhandensein von maschinell generiertem Text im Internet zu überwachen [29]. Es wurde jedoch wenig Arbeit geleistet, um diese Klassifikatoren für andere Zwecke anzuwenden, trotz ihrer attraktiven Eigenschaft, keine Bezeichnungen zu erfordern – nur einen Korpus aus menschlichem Text und ein generatives Modell. In dieser Arbeit zeigen wir durch strenge menschliche Bewertung, dass handelsübliche Diskriminatoren zwischen Mensch und Maschine als leistungsstarke Klassifikatoren für die Seitenqualität dienen . Das heißt, Texte, die maschinell generiert erscheinen, sind tendenziell inkohärent oder unverständlich. Um das Vorhandensein einer niedrigen Seitenqualität in freier Wildbahn zu verstehen, wenden wir die Klassifikatoren auf eine Stichprobe von einer halben Milliarde englischer Webseiten an.“
Was sie im Wesentlichen sagen, ist, dass sie herausgefunden haben, dass dieselben Klassifikatoren, die entwickelt wurden, um KI-basierte Kopien zu erkennen, und dieselben Modelle zu ihrer Generierung verwenden, erfolgreich verwendet werden können, um Inhalte von geringer Qualität zu erkennen.
Das lässt uns natürlich mit einer wichtigen Frage zurück:
Ist dies eine Kausalität (dh nimmt das System es auf, weil es wirklich gut darin ist) oder eine Korrelation (dh wird viel aktueller Spam auf eine Weise erstellt, die mit besseren Tools leicht zu umgehen ist)?
Bevor wir uns damit befassen, werfen wir einen Blick auf einige Arbeiten der Autoren und ihre Erkenntnisse.
Die Einrichtung
Als Referenz verwendeten sie in ihrem Experiment Folgendes:
- Zwei Textgenerierungsmodelle , der RoBERTa-basierte GPT-2-Detektor von OpenAI (ein Detektor, der das RoBERTa-Modell mit GPT-2-Ausgabe verwendet und vorhersagt, ob es wahrscheinlich von der KI generiert wird oder nicht) und das GLTR-Modell, das ebenfalls Zugriff auf top hat GPT-2-Ausgang und funktioniert ähnlich.
Wir können ein Beispiel für die Ausgabe dieses Modells auf dem Inhalt sehen, den ich aus dem obigen Papier kopiert habe:
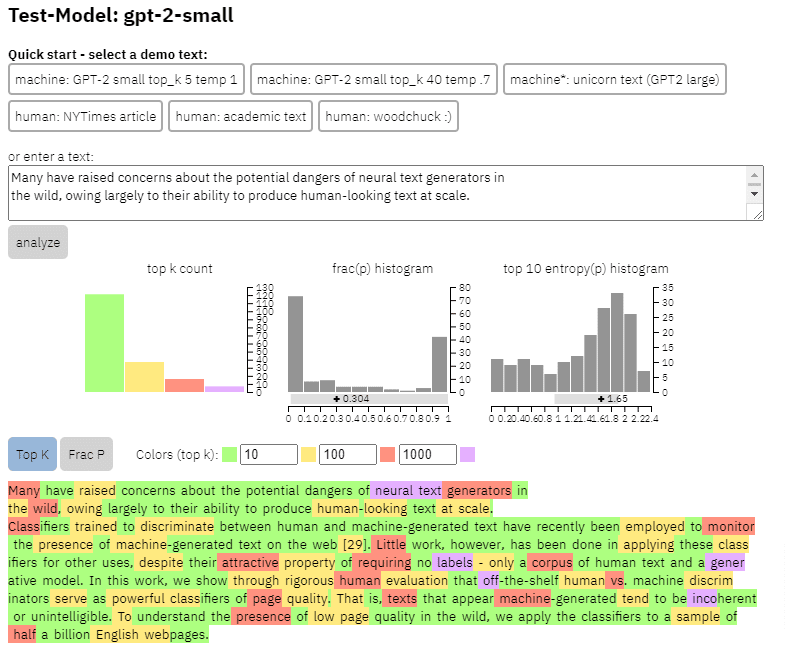
- Drei Datensätze Web500M (eine Zufallsstichprobe von 500 Millionen englischen Webseiten), GPT-2 Output (250.000 GPT-2-Textgenerationen) und Grover-Output (sie generierten intern 1,2 Millionen Artikel unter Verwendung des vortrainierten Grover-Base-Modells, das entworfen wurde um Fake News zu erkennen).
- The Spam Baseline , ein Klassifikator, der auf dem Enron Spam Email Dataset trainiert wurde. Sie verwendeten diesen Klassifikator, um die von ihnen zuzuweisende Sprachqualitätszahl festzulegen. Wenn das Modell also feststellte, dass ein Dokument mit einer Wahrscheinlichkeit von 0,2 kein Spam ist, betrug die zugewiesene Sprachqualitätsbewertung (LQ) 0,2.
Holen Sie sich den täglichen Newsletter, auf den sich Suchmaschinenvermarkter verlassen.
Siehe Bedingungen.
Eine Randbemerkung zur Spam-Prävalenz
Ich wollte kurz beiseite nehmen, um einige interessante Erkenntnisse zu diskutieren, über die die Autoren gestolpert sind. Eine ist in der folgenden Abbildung dargestellt (Abbildung 3 aus dem Papier):
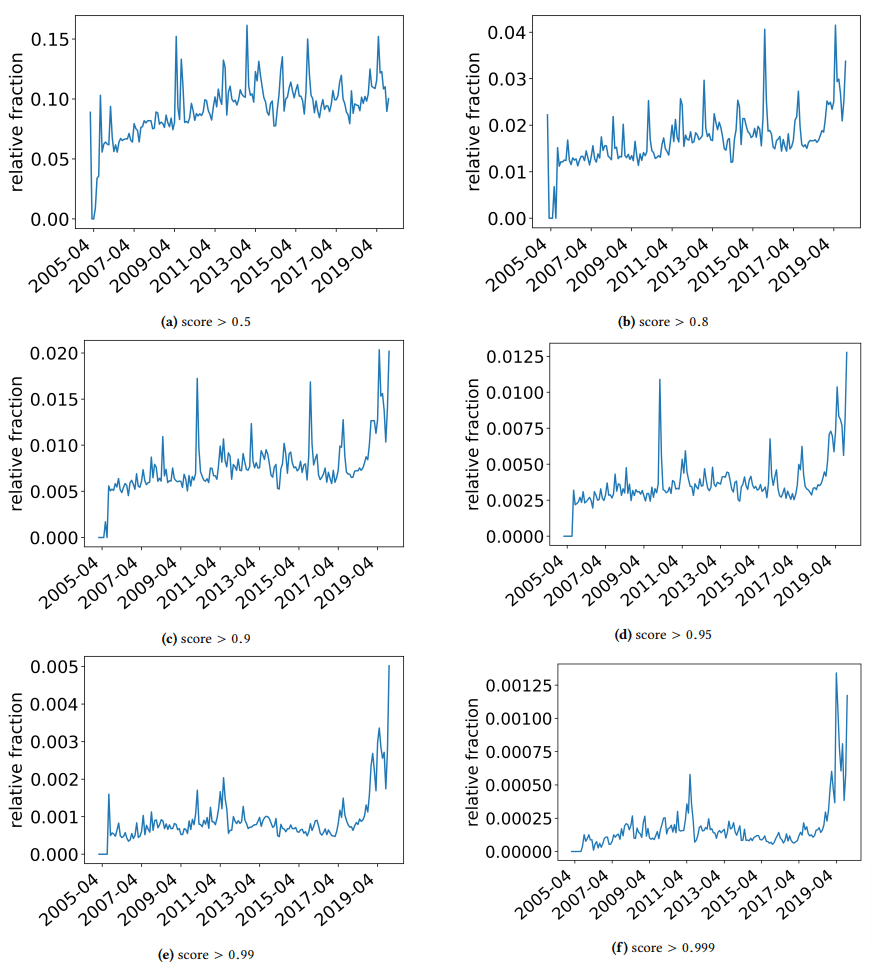
Es ist wichtig, die Punktzahl unter jedem Diagramm zu beachten. Eine Zahl in Richtung 1,0 bewegt sich zu einem Vertrauen, dass der Inhalt Spam ist. Was wir also sehen, ist, dass ab 2017 – und mit einem Anstieg im Jahr 2019 – Dokumente von geringer Qualität weit verbreitet waren.
Darüber hinaus stellten sie fest, dass die Auswirkungen von qualitativ minderwertigen Inhalten in einigen Sektoren stärker waren als in anderen (wobei daran erinnert wurde, dass eine höhere Punktzahl eine höhere Spam-Wahrscheinlichkeit widerspiegelt).
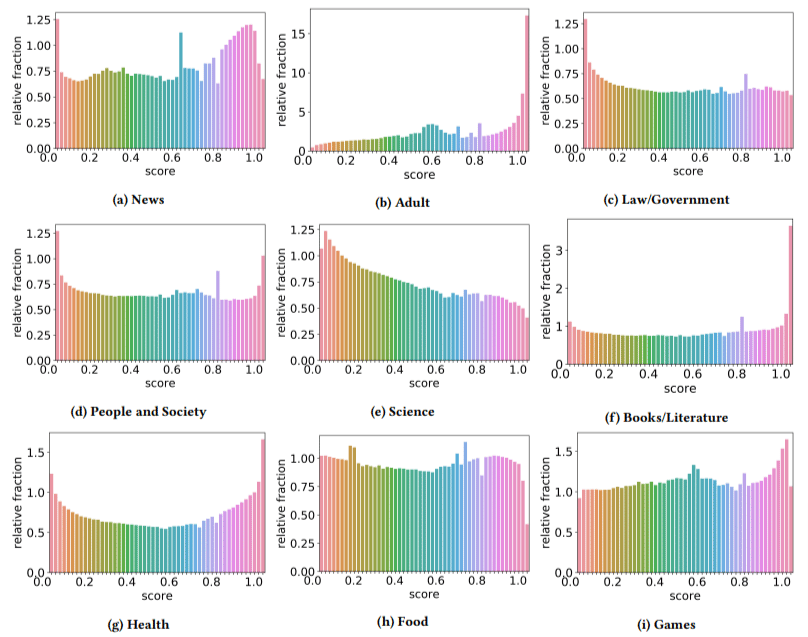
Ich habe mir an ein paar davon den Kopf gekratzt. Erwachsene machten offensichtlich Sinn.
Aber Bücher und Literatur waren eine kleine Überraschung. Und so war die Gesundheit – bis die Autoren Viagra und andere Websites mit „Gesundheitsprodukten für Erwachsene“ als „Gesundheit“ und Aufsatzfarmen als „Literatur“ bezeichneten – das heißt.
Ihre Erkenntnisse
Abgesehen von dem, was wir über Sektoren und den Anstieg im Jahr 2019 besprochen haben, fanden die Autoren auch eine Reihe interessanter Dinge, von denen SEOs lernen können und die sie im Hinterkopf behalten müssen, insbesondere wenn wir uns auf Tools wie ChatGPT stützen.
- Inhalte von geringer Qualität sind tendenziell kürzer (maximal 3.000 Zeichen).
- Erkennungssysteme, die darauf trainiert sind, festzustellen, ob Text von einer Maschine geschrieben wurde oder nicht, sind auch gut darin, Inhalte auf niedriger und hoher Ebene zu klassifizieren.
- Sie nennen unsere Inhalte, die für Rankings entwickelt wurden, einen bestimmten Schuldigen, obwohl ich vermute, dass sie sich auf den Müll beziehen, von dem wir alle wissen, dass er dort nicht sein sollte.
Die Autoren behaupten nicht, dass dies eine End-all-be-all-Lösung ist, sondern eher ein Ausgangspunkt, und ich bin sicher, dass sie in den letzten Jahren die Messlatte nach vorne verschoben haben.
Ein Hinweis zu KI-generierten Inhalten
Sprachmodelle haben sich ebenfalls über die Jahre entwickelt. Während GPT-3 existierte, als dieses Papier geschrieben wurde, basierten die verwendeten Detektoren auf GPT-2, das ein deutlich minderwertiges Modell ist.
GPT-4 steht wahrscheinlich gleich um die Ecke und Googles Sparrow soll später in diesem Jahr erscheinen. Das bedeutet, dass nicht nur die Technik auf beiden Seiten des Schlachtfelds (Inhaltsgeneratoren vs. Suchmaschinen) besser wird, sondern es wird auch einfacher, Kombinationen ins Spiel zu bringen.
Kann Google Inhalte erkennen, die entweder von Sparrow oder GPT-4 erstellt wurden? Vielleicht.
Aber wie wäre es, wenn es mit Sparrow generiert und dann mit einem Rewrite-Prompt an GPT-4 gesendet würde?
Ein weiterer Faktor, der nicht vergessen werden muss, ist, dass die in diesem Papier verwendeten Techniken auf autoregressiven Modellen basieren. Einfach ausgedrückt sagen sie eine Punktzahl für ein Wort voraus, basierend auf dem, was sie vorhersagen würden, dass dieses Wort denen gegeben wird, die ihm vorangegangen sind.
Wenn Modelle einen höheren Grad an Raffinesse entwickeln und beginnen, vollständige Ideen auf einmal zu entwickeln, anstatt ein Wort dem anderen zu folgen, kann die KI-Erkennung versagen.
Auf der anderen Seite sollte die Erkennung von einfach beschissenem Inhalt eskalieren – was bedeuten könnte, dass der einzige „minderwertige“ Inhalt, der gewinnen wird, KI-generiert ist.
Die in diesem Artikel geäußerten Meinungen sind die des Gastautors und nicht unbedingt Search Engine Land. Mitarbeiter Autoren sind hier aufgelistet.