
Hadoop-Ökosystem und seine Komponenten
Veröffentlicht: 2015-04-23Big Data ist das Schlagwort, das seit 2008 in der IT-Branche kursiert. Die Menge an Daten, die von sozialen Netzwerken, Fertigung, Einzelhandel, Aktien, Telekommunikation, Versicherungen, Banken und dem Gesundheitswesen generiert wird, übersteigt unsere Vorstellungskraft bei weitem.
Vor dem Aufkommen von Hadoop war die Speicherung und Verarbeitung von Big Data eine große Herausforderung. Aber jetzt, da Hadoop verfügbar ist, haben Unternehmen die geschäftlichen Auswirkungen von Big Data erkannt und wissen, wie das Verständnis dieser Daten das Wachstum vorantreiben wird. Zum Beispiel:
• Bankensektoren haben eine bessere Chance, treue Kunden, Kreditsäumige und betrügerische Transaktionen zu verstehen.
• Einzelhandelssektoren verfügen jetzt über genügend Daten, um die Nachfrage zu prognostizieren.
• Fertigungssektoren müssen sich nicht auf kostspielige Mechanismen zur Qualitätsprüfung verlassen. Das Erfassen und Analysieren von Sensordaten würde viele Muster aufdecken.
• E-Commerce, soziale Netzwerke können die Seiten basierend auf Kundeninteressen personalisieren.
• Aktienmärkte erzeugen riesige Mengen an Daten, die von Zeit zu Zeit Korrelationen liefern, um schöne Erkenntnisse zu gewinnen.
Big Data hat viele nützliche und aufschlussreiche Anwendungen.
Hadoop ist die direkte Antwort auf die Verarbeitung von Big Data. Das Hadoop-Ökosystem ist eine Kombination von Technologien, die einen kompetenten Vorteil bei der Lösung von Geschäftsproblemen haben.
Lassen Sie uns die Komponenten im Hadoop Ecosystem verstehen, um die richtigen Lösungen für ein bestimmtes Geschäftsproblem zu entwickeln.
Hadoop-Ökosystem:
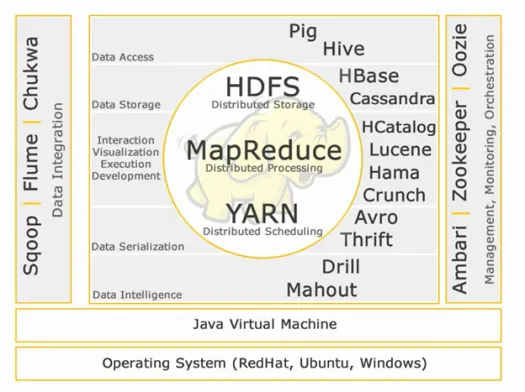

Kern-Hadoop:
HDFS:
HDFS steht für Hadoop Distributed File System zur Verwaltung großer Datensätze mit hohem Volumen, Geschwindigkeit und Vielfalt. HDFS implementiert eine Master-Slave-Architektur. Master ist Namensknoten und Slave ist Datenknoten.
Merkmale:
• Skalierbar
• Zuverlässig
• Commodity-Hardware
HDFS ist der bekannteste Speicher für Big Data.
Karte verkleinern:
Map Reduce ist ein Programmiermodell, das für die Verarbeitung großer Mengen verteilter Daten entwickelt wurde. Die Plattform wurde mit Java für eine bessere Ausnahmebehandlung erstellt. Map Reduce enthält zwei Dämonen, den Job-Tracker und den Task-Tracker.
Merkmale:
• Funktionale Programmierung.
• Funktioniert sehr gut mit Big Data.
• Kann große Datensätze verarbeiten.
Map Reduce ist die Hauptkomponente, die für die Verarbeitung von Big Data bekannt ist.
GARN:
YARN steht für Yet Another Resource Negotiator. Es wird auch als MapReduce 2 (MRv2) bezeichnet. Die beiden Hauptfunktionalitäten von Job Tracker in MRv1, Ressourcenverwaltung und Jobplanung/-überwachung, sind in separate Daemons aufgeteilt, nämlich ResourceManager, NodeManager und ApplicationMaster.
Merkmale:
• Besseres Ressourcenmanagement.
• Skalierbarkeit
• Dynamische Zuweisung von Cluster-Ressourcen.
Datenzugriff:
Schwein:
Apache Pig ist eine Hochsprache, die auf MapReduce aufbaut, um große Datensätze mit einfachen Ad-hoc-Datenanalyseprogrammen zu analysieren. Pig ist auch als Datenflusssprache bekannt. Es ist sehr gut in Python integriert. Es wurde ursprünglich von Yahoo entwickelt.
Hauptmerkmale des Schweins:
• Einfache Programmierung
• Optimierungsmöglichkeiten
• Erweiterbarkeit.
Pig-Skripte werden intern in Map-Reduce-Programme konvertiert.

Bienenstock:
Apache Hive ist eine weitere High-Level-Abfragesprache und Data-Warehouse-Infrastruktur, die auf Hadoop aufbaut, um Datenzusammenfassung, -abfrage und -analyse bereitzustellen. Es wurde ursprünglich von Yahoo entwickelt und Open Source gemacht.
Herausragende Merkmale des Bienenstocks:
• SQL-ähnliche Abfragesprache namens HQL.
• Partitionierung und Bucketing für schnellere Datenverarbeitung.
• Integration mit Visualisierungstools wie Tableau.
Hive-Abfragen werden intern in Map-Reduce-Programme umgewandelt.
Wenn Sie ein Big-Data-Analyst werden möchten, müssen Sie diese beiden Hochsprachen kennen!

Datenspeicher:
Basis:
Apache HBase ist eine NoSQL-Datenbank, die zum Hosten großer Tabellen mit Milliarden von Zeilen und Millionen von Spalten auf Hadoop-Standardhardwaremaschinen entwickelt wurde. Verwenden Sie Apache Hbase, wenn Sie zufälligen Echtzeit-Lese-/Schreibzugriff auf Ihre Big Data benötigen.
Merkmale:
• Streng konsistente Lese- und Schreibvorgänge. Bei Speicheroperationen.
• Benutzerfreundliche Java-API für den Client-Zugriff.
• Gut integriert mit Pig, Hive und Sqoop.
• Ist ein konsistentes und partitionstolerantes System im CAP-Theorem.

Kassandra:
Cassandra ist eine NoSQL-Datenbank, die auf lineare Skalierbarkeit und Hochverfügbarkeit ausgelegt ist. Cassandra basiert auf dem Schlüsselwertmodell. Von Facebook entwickelt und bekannt für schnellere Antworten auf Anfragen.
Merkmale:
• Spaltenindizes
• Unterstützung für Denormalisierung
• Materialisierte Ansichten
• Leistungsstarkes integriertes Caching.

Interaktion -Visualisierung- Ausführung-Entwicklung:
Katalog:

HCatalog ist eine Tabellenverwaltungsschicht, die die Integration von Hive-Metadaten für andere Hadoop-Anwendungen ermöglicht. Es ermöglicht Benutzern mit verschiedenen Datenverarbeitungstools wie Apache Pig, Apache MapReduce und Apache Hive, Daten einfacher zu lesen und zu schreiben.
Merkmale:
• Tabellarische Ansicht für verschiedene Formate.
• Benachrichtigungen über Datenverfügbarkeit.
• REST-APIs für externe Systeme zum Zugriff auf Metadaten.
Lucene:
Apache LuceneTM ist eine hochleistungsfähige Textsuchmaschinenbibliothek mit vollem Funktionsumfang, die vollständig in Java geschrieben wurde. Es ist eine Technologie, die für nahezu jede Anwendung geeignet ist, die eine Volltextsuche erfordert, insbesondere plattformübergreifend.
Merkmale:
• Skalierbare, leistungsstarke Indizierung.
• Leistungsstarke, genaue und effiziente Suchalgorithmen.
• Plattformübergreifende Lösung.
Hama:
Apache Hama ist ein verteiltes Framework, das auf Bulk Synchronous Parallel (BSP) Computing basiert. Leistungsfähig und bekannt für massive wissenschaftliche Berechnungen wie Matrix-, Graphen- und Netzwerkalgorithmen.
Merkmale:
• Einfaches Programmiermodell
• Gut geeignet für iterative Algorithmen
• YARN unterstützt
• Kollaboratives Filtern von unbeaufsichtigtem maschinellem Lernen.
• K-Means-Clustering.
Knirschen:
Apache Crunch wurde für das Pipelining von MapReduce-Programmen entwickelt, die einfach und effizient sind. Dieses Framework wird zum Schreiben, Testen und Ausführen von MapReduce-Pipelines verwendet.
Merkmale:
• Entwicklerorientiert.
• Minimale Abstraktionen
• Flexibles Datenmodell.
Datenserialisierung:
Avro:
Apache Avro ist ein sprachneutrales Framework zur Datenserialisierung. Entwickelt für Sprachübertragbarkeit, sodass Daten möglicherweise die Sprache überleben, um sie zu lesen und zu schreiben.

Sparsamkeit:
Thrift ist eine Sprache, die entwickelt wurde, um Schnittstellen für die Interaktion mit Technologien zu erstellen, die auf Hadoop basieren. Es wird verwendet, um Dienste für zahlreiche Sprachen zu definieren und zu erstellen.
Datenintelligenz:
Bohren:
Apache Drill ist eine SQL-Abfrage-Engine mit geringer Latenz für Hadoop und NoSQL.
Merkmale:
• Agilität
• Flexibilität
• Vertrautheit.

Mahout:
Apache Mahout ist eine skalierbare Bibliothek für maschinelles Lernen, die für die Erstellung von Vorhersageanalysen auf Big Data entwickelt wurde. Mahout hat jetzt Implementierungen von Apache Spark für eine schnellere Speicherberechnung.
Merkmale:
• Kollaboratives Filtern.
• Klassifizierung
• Clusterbildung
• Dimensionsreduktion

Datenintegration:
Apache Sqoop:

Apache Sqoop ist ein Tool, das für Massendatenübertragungen zwischen relationalen Datenbanken und Hadoop entwickelt wurde.
Merkmale:
• Import und Export zu und von HDFS.
• Import und Export nach und von Hive.
• Import und Export nach HBase.
Apache Flume:
Flume ist ein verteilter, zuverlässiger und verfügbarer Dienst zum effizienten Sammeln, Aggregieren und Verschieben großer Mengen von Protokolldaten.
Merkmale:
• Robust
• Fehlertoleranz
• Einfache und flexible Architektur basierend auf Streaming-Datenflüssen.

Apache Chukwa:
Skalierbarer Protokollsammler zur Überwachung großer verteilter Dateisysteme.
Merkmale:
• Skalierung auf Tausende von Knoten.
• Zuverlässige Lieferung.
• Sollte in der Lage sein, Daten auf unbestimmte Zeit zu speichern.

Management, Überwachung und Orchestrierung:
Apache Ambari:
Ambari wurde entwickelt, um die Hadoop-Verwaltung zu vereinfachen, indem es eine Schnittstelle für die Bereitstellung, Verwaltung und Überwachung von Apache Hadoop-Clustern bereitstellt.
Merkmale:
• Bereitstellen eines Hadoop-Clusters.
• Verwalten eines Hadoop-Clusters.
• Überwachen eines Hadoop-Clusters.

Apache Zookeeper:
Zookeeper ist ein zentralisierter Dienst, der für die Verwaltung von Konfigurationsinformationen, die Benennung, die Bereitstellung einer verteilten Synchronisierung und die Bereitstellung von Gruppendiensten entwickelt wurde.
Merkmale:
• Serialisierung
• Atomizität
• Verlässlichkeit
• Einfache API

Apache Oozie:
Oozie ist ein Workflow-Scheduler-System zur Verwaltung von Apache Hadoop-Jobs.
Merkmale:
• Skalierbares, zuverlässiges und erweiterbares System.
• Unterstützt mehrere Arten von Hadoop-Jobs wie Map-Reduce, Hive, Pig und Sqoop.
• Einfach und leicht zu bedienen.

Wir werden in den kommenden Artikeln detailliert auf die Komponenten eingehen. Bleib dran.