
Hadoop-Installation mit Ambari
Veröffentlicht: 2015-12-11Alles, was Sie über die Hadoop-Installation mit Ambari wissen möchten
Apache Hadoop hat sich zu einem De-facto-Software-Framework für zuverlässiges, skalierbares, verteiltes und groß angelegtes Computing entwickelt. Im Gegensatz zu anderen Computersystemen bringt es Berechnungen zu Daten, anstatt Daten zur Berechnung zu senden. Hadoop wurde 2006 bei Yahoo von Doug Cutting basierend auf einem von Google veröffentlichten Artikel entwickelt. Mit zunehmender Reife von Hadoop wurden im Laufe der Jahre viele neue Komponenten und Tools zu seinem Ökosystem hinzugefügt, um seine Benutzerfreundlichkeit und Funktionalität zu verbessern. Hadoop HDFS, Hadoop MapReduce, Hive, HCatalog, HBase, ZooKeeper, Oozie, Pig, Sqoop usw., um nur einige zu nennen.
Warum Ambari?
Mit der wachsenden Popularität von Hadoop stürzen sich viele Entwickler auf diese Technologie, um einen Vorgeschmack darauf zu bekommen. Aber wie sie sagen, Hadoop ist nichts für schwache Nerven, viele Entwickler konnten nicht einmal die Hürde überwinden, Hadoop zu installieren. Viele Distributionen bieten eine vorinstallierte Sandbox von VMs an, um Dinge auszuprobieren, aber es gibt Ihnen nicht das Gefühl von verteiltem Computing. Die Installation eines Multi-Nodes ist jedoch keine leichte Aufgabe, und bei einer wachsenden Anzahl von Komponenten ist es sehr schwierig, mit so vielen Konfigurationsparametern umzugehen. Zum Glück kommt Apache Ambari hierher, um uns zu retten!
Was ist Ambari?
Apache Ambari ist ein webbasiertes Tool zum Bereitstellen, Verwalten und Überwachen von Apache Hadoop-Clustern. Ambari bietet ein Dashboard zum Anzeigen des Clusterzustands wie Heatmaps und die Möglichkeit, MapReduce-, Pig- und Hive-Anwendungen visuell anzuzeigen, zusammen mit Funktionen zur benutzerfreundlichen Diagnose ihrer Leistungsmerkmale. Es hat eine sehr einfache und interaktive Benutzeroberfläche, um verschiedene Tools zu installieren und verschiedene Verwaltungs-, Konfigurations- und Überwachungsaufgaben durchzuführen. Im Folgenden führen wir Sie durch verschiedene Schritte zur Installation von Hadoop und seinen verschiedenen Ökosystemkomponenten auf Multi-Node-Clustern.
Die Ambari-Architektur ist unten dargestellt
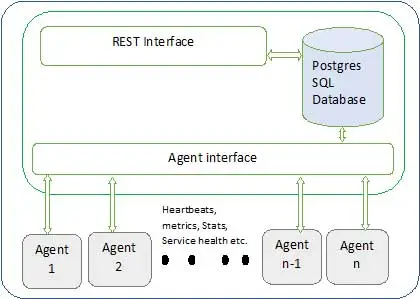
Ambari besteht aus zwei Komponenten
- Ambari-Server – Dies ist der Masterprozess, der mit Ambari-Agenten kommuniziert, die auf jedem am Cluster teilnehmenden Knoten installiert sind. Dies hat eine Postgres-Datenbankinstanz, die verwendet wird, um alle clusterbezogenen Metadaten zu verwalten.
- Ambari Agent – Dies sind Agenten für Ambari auf jedem Knoten. Jeder Agent sendet regelmäßig seinen eigenen Gesundheitszustand zusammen mit verschiedenen Metriken, dem Status der installierten Dienste und vielem mehr. Entsprechend Master entscheidet über die nächste Aktion und übermittelt zurück an den Agenten, um zu handeln.
Wie installiere ich Ambari?
Die Ambari-Installation ist eine einfache Aufgabe mit wenigen Befehlen.
Wir werden die Ambari-Installation und die Cluster-Einrichtung behandeln. Es wird angenommen, dass wir 4 Knoten haben. Knoten1, Knoten2, Knoten3 und Knoten4. Und wir wählen Node1 als unseren Ambari-Server aus.
Dies sind Installationsschritte auf dem RHEL-basierten System, für Debian und andere Systeme werden die Schritte wenig variieren.
- Installation von Ambari: –
Vom Ambari-Serverknoten (Knoten 1, wie wir uns entschieden haben)
ich. Laden Sie das öffentliche Repo von Ambari herunter

Dieser Befehl fügt das Hortonworks Ambari-Repository zu yum hinzu, einem Standard-Paketmanager für RHEL-Systeme.
ii.Installieren Sie Ambari RPMS

Dies wird einige Zeit in Anspruch nehmen und Ambari auf diesem System installieren.

iii. Konfigurieren des Ambari-Servers
Als nächstes müssen Sie nach der Ambari-Installation Ambari konfigurieren und für die Bereitstellung des Clusters einrichten.
Der folgende Schritt wird sich darum kümmern


iv. Starten Sie den Server und melden Sie sich bei der Web-Benutzeroberfläche an
Starten Sie den Server mit

Jetzt können wir auf die Ambari-Web-UI zugreifen (gehostet auf Port 8080).
Melden Sie sich bei Ambari mit dem Standardbenutzernamen „admin“ und dem Standardkennwort „admin“ an.
Hadoop-Cluster einrichten
1. Zielseite
Klicken Sie auf „Launch Install Wizard“, um die Cluster-Einrichtung zu starten
2. Clustername
Geben Sie Ihrem Cluster einen guten Namen.
Hinweis: Dies ist nur ein einfacher Name für Cluster, er ist nicht so aussagekräftig, also machen Sie sich keine Sorgen und wählen Sie einen beliebigen Namen dafür.
3. Stapelauswahl
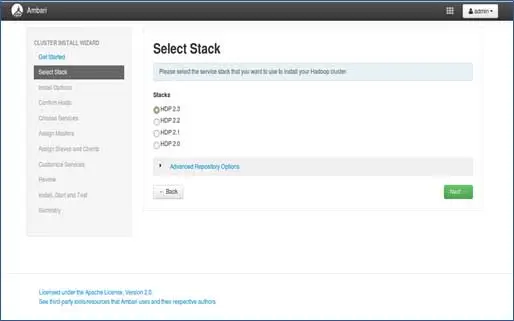
Auf dieser Seite werden Stacks aufgeführt, die zur Installation verfügbar sind. Jeder Stack ist mit einer Hadoop-Ökosystemkomponente vorgepackt. Diese Stapel sind von Hortonworks. (Wir können auch einfaches Hadoop installieren. Das werden wir in späteren Beiträgen behandeln).
4.Hosts-Eintrag und SSH-Schlüsseleintrag

Bevor wir diesen Schritt fortsetzen, sollten wir für alle teilnehmenden Knoten ein passwortloses SSH-Setup haben.
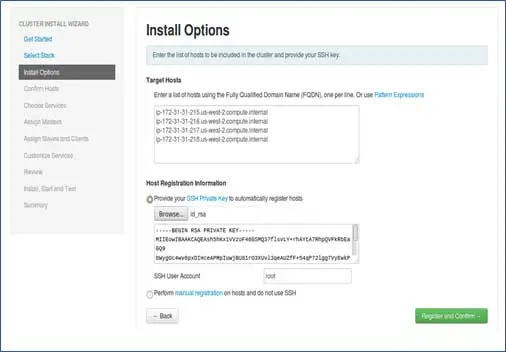
Fügen Sie die Hostnamen der Knoten hinzu, ein Eintrag in jeder Zeile. [FQDN hinzufügen, der mit dem Befehl hostname –f abgerufen werden kann]. Wählen Sie den privaten Schlüssel aus, der beim Einrichten von passwortlosem SSH verwendet wird, und den Benutzernamen, mit dem der private Schlüssel erstellt wurde.
5. Registrierungsstatus des Gastgebers
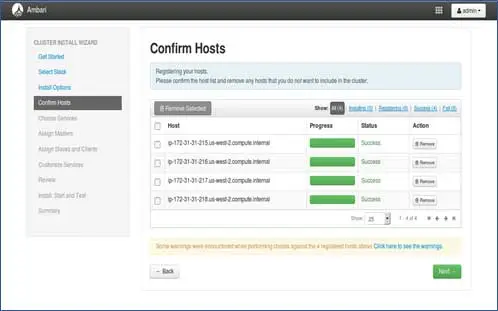
Sie können sehen, wie einige Vorgänge ausgeführt werden. Zu diesen Vorgängen gehören das Festlegen von Ambari-Agent auf jedem Knoten und das Erstellen grundlegender Setups auf jedem Knoten. Sobald wir ALLES GRÜN sehen, können wir weitermachen. Manchmal kann dies einige Zeit dauern, da nur wenige Pakete installiert werden.

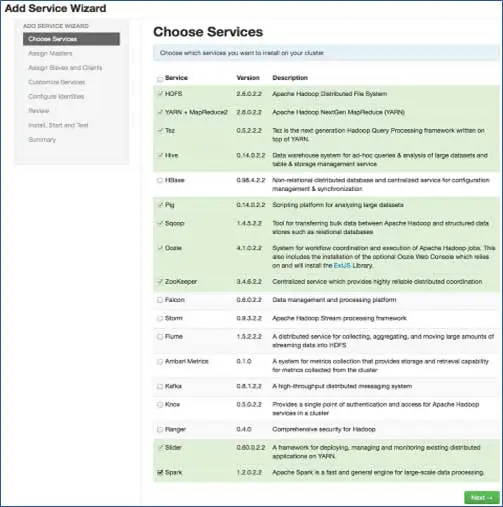
6. Wählen Sie die Dienste aus, die Sie installieren möchten
Gemäß den ausgewählten Stapeln in Schritt 3 haben wir die Anzahl der Dienste, die wir im Cluster installieren können. Sie können die gewünschte auswählen. Ambari wählt auf intelligente Weise abhängige Dienste aus, wenn Sie sie nicht ausgewählt haben. Wenn Sie beispielsweise HBase, aber nicht Zookeeper ausgewählt haben, wird dasselbe angezeigt und Zookeeper auch zum Cluster hinzugefügt.
7. Master-Services-Mapping mit Nodes
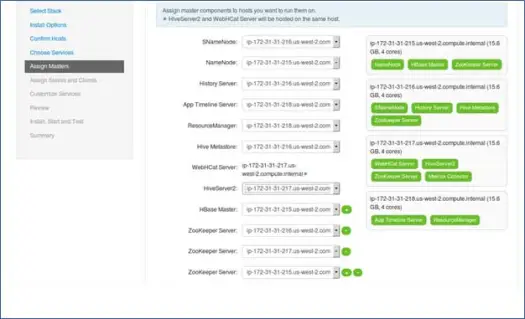
Wie Sie wissen, verfügt das Hadoop-Ökosystem über Tools, die auf einer Master-Slave-Architektur basieren. In diesem Schritt werden wir dem Knoten Master-Prozesse zuordnen. Stellen Sie hier sicher, dass Sie Ihren Cluster richtig ausbalancieren. Denken Sie auch daran, dass sich primäre und sekundäre Dienste wie Namenode und sekundärer Namenode nicht auf demselben Computer befinden.

8. Slaves-Mapping mit Nodes
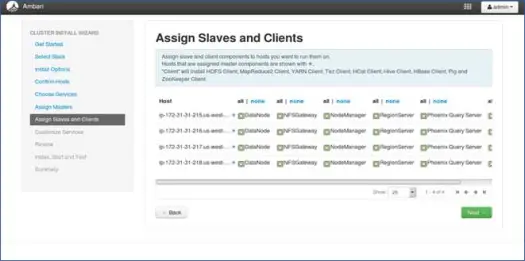
Ordnen Sie ähnlich wie bei Mastern Slave-Dienste auf den Knoten zu. Im Allgemeinen haben alle Knoten einen Slave-Prozess, der zumindest für Datenknoten und Knotenmanager läuft.
9. Passen Sie Dienste an
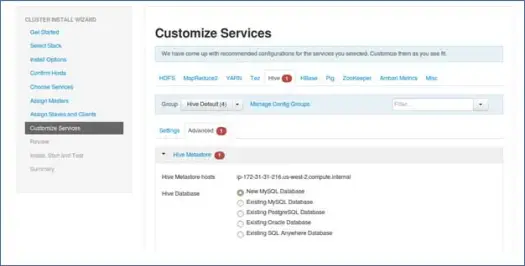
Dies ist eine sehr wichtige Seite für Administratoren.
Hier können Sie Eigenschaften für Ihren Cluster konfigurieren, um ihn für Ihre Anwendungsfälle am besten geeignet zu machen.
Außerdem verfügt es über einige erforderliche Eigenschaften wie Hive-Metastore-Passwort (wenn Hive ausgewählt ist) usw. Diese werden mit roten Fehlersymbolen angezeigt.
10. Überprüfen und starten Sie die Bereitstellung
Stellen Sie sicher, dass Sie die Clusterkonfiguration vor dem Start überprüfen, da dies verhindert, dass unwissentlich falsche Konfigurationen festgelegt werden.
11. Starten Sie und bleiben Sie zurück, bis der Status GRÜN wird.
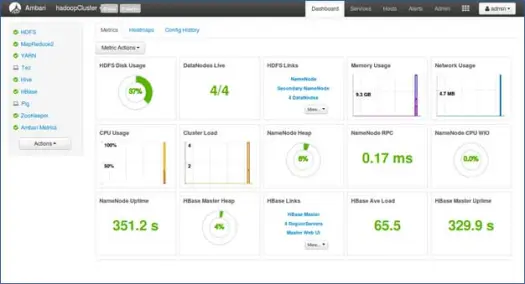
Nächste Schritte
Jaaa! Wir haben Hadoop und alle Komponenten erfolgreich auf allen Knoten des Clusters installiert. Jetzt können wir anfangen, mit Hadoop zu spielen.
Ambari führt einen MapReduce-Wordcount-Job aus, um zu überprüfen, ob alles einwandfrei läuft. Sehen wir uns das Protokoll an, das der Job vom ambari-qa-Benutzer ausgeführt hat.
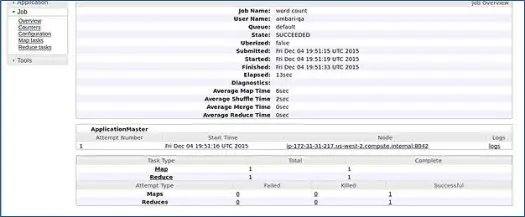
Wie Sie im obigen Screenshot sehen können, wurde der WordCount-Job erfolgreich abgeschlossen. Dies bestätigt, dass unser Cluster gut funktioniert.
Fazit
Das war's, wir haben jetzt gelernt, wie man Hadoop und seine Komponenten mit einem einfachen webbasierten Tool namens Apache Ambari auf dem Multi-Node-Cluster installiert. Apache Ambari bietet uns eine einfachere Schnittstelle und erspart uns viel Aufwand bei der Installation, Überwachung und Verwaltung, die bei so vielen Komponenten und ihren verschiedenen Installationsschritten und Überwachungssteuerungen sehr mühsam gewesen wären.
Lassen Sie mich Sie mit einem Hack verlassen

Das Ambari-Installationsprogramm überprüft /etc/lsb-release, um Betriebssystemdetails abzurufen. In Linux Mint befindet sich dieselbe Datei für die Ubuntu-Version unter /etc/upstream-release/lsb-release. Um das Installationsprogramm zu täuschen, ersetzen Sie einfach ersteres durch letzteres (Sie sollten zuerst die Datei sichern).

Irgendwann nach Abschluss der Installation können Sie das Original wiederherstellen mit:

PS Dies ist ein Hack ohne Garantien, er hat bei mir funktioniert, also dachte ich, ihn mit Ihnen zu teilen.
Sie sind Entwickler/Dev-Ops und müssen Hadoop schnell installieren. Wir haben eine gute Nachricht für Sie, Ambari bietet eine Möglichkeit, den gesamten Assistentenprozess und den abgeschlossenen Installationsprozess mit einem einzigen Skript zu überspringen, und ich werde es im nächsten Beitrag einbringen, also bleiben Sie dran und bis dahin Happy Hadooping!