
Schätzung von Zeit, Kosten und Ergebnissen eines ML-App-Projekts
Veröffentlicht: 2019-11-20Stellen Sie sich vor, Sie würden in einem Geschäft eine personalisierte Brieftasche kaufen.
Sie wissen zwar, welche Art von Brieftasche Sie benötigen, kennen aber nicht die Kosten oder die Zeit, die erforderlich sind, um die angepasste Version zu erhalten.
Das Gleiche gilt für Machine-Learning-Projekte. Und um Ihnen aus diesem Dilemma zu helfen, haben wir detaillierte Informationen für Sie bereitgestellt, damit Sie ein erfolgreiches Projekt haben.
Maschinelles Lernen ist wie eine Münze, die zwei Seiten hat .
Einerseits hilft es, Unsicherheiten aus Prozessen zu beseitigen. Aber auf der anderen Seite ist seine Entwicklung voller Unsicherheiten.
Während das Endergebnis fast jedes Machine Learning (ML) -Projekts eine Lösung ist, die Unternehmen besser und Prozesse rationalisiert; Der Entwicklungsteil davon hat eine ganz andere Geschichte zu erzählen.
Obwohl ML eine massive Rolle bei der Veränderung der Gewinngeschichte und des Geschäftsmodells mehrerer etablierter Marken für mobile Apps gespielt hat, befindet es sich noch in der Entstehungsphase. Diese Neuheit wiederum macht es für Entwickler mobiler Anwendungen umso schwieriger , einen ML-Projektplan zu handhaben und ihn produktionsreif zu machen, wobei Zeit- und Kostenbeschränkungen im Auge zu behalten sind.
Eine Lösung ( wahrscheinlich die einzige Lösung ) für dieses Problem ist eine Schwarz-Weiß-App-Projektschätzung für maschinelles Lernen in Bezug auf Zeit, Kosten und Ergebnisse.
Aber bevor wir uns diesen Abschnitten zuwenden, lassen Sie uns zunächst untersuchen, warum sich die Schwierigkeit und das Brennen der Nachtkerzen lohnen.
Warum benötigt Ihre App ein Framework für maschinelles Lernen?
Sie denken vielleicht, warum wir inmitten von Zeit-, Kosten- und Ergebnisschätzungen über Frameworks sprechen.
Aber der wahre Grund für die Zeit und die Kosten liegt hier, was uns über unser Motiv hinter der App-Entwicklung informiert. Ob Sie maschinelles Lernen benötigen für:
Für das Angebot personalisierter Erfahrungen
Zur Einbindung der Erweiterten Suche m
Zur Vorhersage des Benutzerverhaltens
Für mehr Sicherheit
Für intensives Benutzerengagement
Aus diesen Gründen hängen Zeit, Kosten und Lieferfähigkeit entsprechend ab.
Arten von Modellen für maschinelles Lernen
Welche Art von Modell würden Sie in Betracht ziehen, um Zeit und Kosten anzupassen? Wenn Sie es nicht wissen, haben wir Informationen für Sie bereitgestellt, damit Sie die Modelle je nach Ihren Anforderungen und Ihrem Budget verstehen und auswählen können.
Maschinelles Lernen kann in seinen verschiedenen Anwendungsfällen in drei Modelltypen eingeteilt werden, die eine Rolle dabei spielen, rudimentäre Apps in intelligente mobile Apps umzuwandeln – überwacht, nicht überwacht und verstärkt. Das Wissen darüber, wofür diese Modelle für maschinelles Lernen stehen, hilft bei der Definition der Entwicklung einer ML-fähigen App.
Überwachtes Lernen
Es ist der Prozess, bei dem das System mit Daten versorgt wird, bei denen die Eingaben des Algorithmus und ihre Ausgaben korrekt gekennzeichnet sind. Da die Eingabe- und Ausgabeinformationen gekennzeichnet sind, wird das System darauf trainiert, die Muster in den Daten innerhalb des Algorithmus zu erkennen.
Es ist umso vorteilhafter, als es verwendet wird, um das Ergebnis auf der Grundlage zukünftiger Eingabedaten vorherzusagen. Ein Beispiel dafür ist, wenn soziale Medien das Gesicht einer Person erkennen, wenn sie auf einem Foto markiert ist.
Unbeaufsichtigtes Lernen
Beim unüberwachten Lernen werden die Daten in das System eingespeist, aber seine Ausgaben werden nicht wie beim überwachten Modell gekennzeichnet. Es ermöglicht dem System , Daten zu identifizieren und Muster aus den Informationen zu bestimmen. Sobald die Muster gespeichert sind, werden alle zukünftigen Eingaben dem Muster zugewiesen, um eine Ausgabe zu erzeugen.
Ein Beispiel für dieses Modell ist in Fällen zu sehen, in denen soziale Medien Freunden Vorschläge auf der Grundlage mehrerer bekannter Daten wie Demografie, Bildungshintergrund usw. machen.
Verstärkungslernen
Wie beim unüberwachten Lernen werden auch beim Reinforcement Learning die Daten, die dem System gegeben werden, nicht gelabelt. Beide Arten des maschinellen Lernens unterscheiden sich darin, dass dem System bei korrekter Ausgabe mitgeteilt wird, dass die Ausgabe richtig ist. Diese Lernart ermöglicht es dem System, aus der Umgebung und den Erfahrungen zu lernen.
Ein Beispiel dafür ist bei Spotify zu sehen. Die Spotify-App macht eine Empfehlung für Songs , die die Nutzer dann entweder mit einem Daumen hoch oder einem Daumen runter bewerten müssen . Anhand der Auswahl lernt die Spotify-App den Musikgeschmack der Nutzer.
Lebenszyklus eines maschinellen Lernprojekts
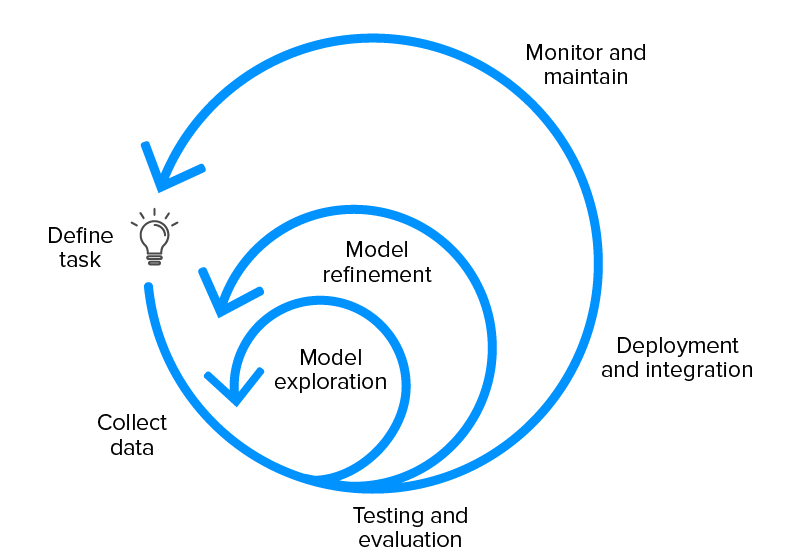
Der Lebenszyklus der Arbeitsergebnisse eines Machine-Learning -Projekts sieht normalerweise so aus:
Einrichtung des ML-Projektplans
- Definieren Sie die Aufgabe und die Anforderungen
- Identifizieren Sie die Machbarkeit des Projekts
- Diskutieren Sie die allgemeinen Modellkompromisse
- Erstellen Sie eine Projektcodebasis
Erfassung und Kennzeichnung von Daten
- Erstellen Sie die Kennzeichnungsdokumentation
- Erstellen Sie die Datenerfassungspipeline
- Validierung der Datenqualität
Modellerkundung
- Legen Sie die Basislinie für die Modellleistung fest
- Erstellen Sie ein einfaches Modell mit anfänglicher Datenpipeline
- Probieren Sie in den frühen Phasen parallele Ideen aus
- Finden Sie das SoTA-Modell für die Problemdomäne, falls vorhanden, und reproduzieren Sie die Ergebnisse.
Verfeinerung des Modells
- Führen Sie modellzentrierte Optimierungen durch
- Debuggen Sie Modelle, wenn die Komplexität zunimmt
- Führen Sie eine Fehleranalyse durch, um Fehlermodi aufzudecken.
Testen und auswerten
- Bewerten Sie das Modell für die Testverteilung
- Überprüfen Sie die Modellbewertungsmetrik erneut und stellen Sie sicher, dass sie das gewünschte Benutzerverhalten fördert
- Schreiben Sie Tests für – Modellschlussfunktion, Eingabedatenpipeline, explizite Szenarien, die in der Produktion erwartet werden.
Bereitstellung des Modells
- Stellen Sie das Modell über die REST-API bereit
- Stellen Sie das neue Modell für eine Untergruppe von Benutzern bereit, um sicherzustellen, dass vor der endgültigen Einführung alles glatt läuft.
- Haben Sie die Möglichkeit, die Modelle auf ihre vorherige Version zurückzusetzen
- Überwachen Sie die Live-Daten.
Modellpflege
- Trainieren Sie das Modell neu, um ein Veralten des Modells zu verhindern
- Informieren Sie das Team, wenn es eine Übertragung des Eigentums am Modell gibt
Wie schätzt man den Umfang eines maschinellen Lernprojekts ab?
Das Appinventiv Machine Learning-Team definiert nach Durchsicht des Machine Learning-Typs und des Entwicklungslebenszyklus die Machine Learning-App-Projektschätzung des Projekts nach diesen Phasen:
Phase 1 – Entdeckung (7 bis 14 Tage)
Die ML-Projektplan-Roadmap beginnt mit der Definition eines Problems. Es untersucht die Probleme und betrieblichen Ineffizienzen, die angegangen werden sollten.
Das Ziel hier ist es, die Anforderungen zu identifizieren und zu sehen, ob Machine Learning die Geschäftsziele erfüllt . In dieser Phase müssen sich unsere Ingenieure mit den Geschäftsleuten auf der Kundenseite treffen, um ihre Vision in Bezug auf die zu lösenden Probleme zu verstehen.
Zweitens sollte das Entwicklungsteam ermitteln, über welche Art von Daten es verfügt und ob es diese von einem externen Dienst abrufen müsste.
Als nächstes müssen Entwickler abschätzen, ob sie in der Lage sind, Algorithmen zu überwachen – ob sie bei jeder Vorhersage die richtige Antwort zurückgeben.
Ergebnis – Eine Problemstellung, die definiert, ob ein Projekt trivial oder komplex ist .
Phase 2 – Erkundung (6 bis 8 Wochen)
Das Ziel dieser Phase ist es, auf einem Proof of Concept aufzubauen, das dann als API installiert werden kann. Sobald ein Basismodell trainiert ist, schätzt unser Team von ML-Experten die Leistung der produktionsreifen Lösung.
Diese Phase gibt uns Klarheit darüber, welche Leistung mit den in der Discovery-Phase geplanten Metriken zu erwarten ist.
Lieferbar – Ein Proof of Concept
Phase 3 – Entwicklung (4+ Monate)
Dies ist die Phase, in der das Team iterativ arbeitet, bis es eine produktionsreife Antwort erreicht. Da bis zu diesem Zeitpunkt des Projekts weitaus weniger Unsicherheiten bestehen, wird die Schätzung sehr genau.
Falls sich das Ergebnis jedoch nicht verbessert, müssten die Entwickler ein anderes Modell anwenden oder die Daten überarbeiten oder bei Bedarf sogar die Methode ändern.
In dieser Phase arbeiten unsere Entwickler in Sprints und entscheiden, was nach jeder einzelnen Iteration zu tun ist. Die Ergebnisse jedes Sprints können effektiv vorhergesagt werden.

Während das Sprint-Ergebnis gut vorhergesagt werden kann, kann die Planung von Sprints im Voraus beim maschinellen Lernen ein Fehler sein, da Sie sich auf Neuland bewegen.
Lieferbar – Eine produktionsreife ML-Lösung
Phase 4 – Verbesserung (fortlaufend)
Einmal bereitgestellt, haben Entscheidungsträger es fast immer eilig, das Projekt zu beenden, um Kosten zu sparen. Während die Formel in 80 % der Projekte funktioniert, gilt dies nicht für Apps für maschinelles Lernen.
Was passiert, ist, dass sich die Daten während der Zeitachse des Machine Learning-Projekts ändern. Aus diesem Grund muss ein KI-Modell ständig überwacht und überprüft werden – um es vor dem Verfall zu bewahren und eine sichere KI bereitzustellen, die die Entwicklung mobiler Apps ermöglicht .
Die auf maschinelles Lernen ausgerichteten Projekte benötigen Zeit, um zufriedenstellende Ergebnisse zu erzielen. Selbst wenn Sie feststellen, dass Ihre Algorithmen die Benchmarks von Anfang an schlagen, besteht die Möglichkeit, dass sie ein Treffer sind und das Programm verloren geht, wenn es auf einem anderen Datensatz verwendet wird.
Faktoren, die die Gesamtkosten beeinflussen
Die Art und Weise, ein maschinelles Lernsystem zu entwickeln, weist einige Unterscheidungsmerkmale auf, wie z. B. datenbezogene Probleme und leistungsbezogene Faktoren, die über die letzten Ausgaben entscheiden.
Datenbezogene Probleme
Die Entwicklung zuverlässigen maschinellen Lernens hängt nicht nur von einer phänomenalen Codierung ab, sondern auch die Qualität und Quantität der Trainingsinformationen spielt eine entscheidende Rolle.
- Mangel an geeigneten Daten
- Komplexe Prozeduren zum Extrahieren, Transformieren und Laden
- Unstrukturierte Datenverarbeitung
Leistungsbezogene Probleme
Die angemessene Algorithmus-Performance ist ein weiterer wichtiger Kostenfaktor, da ein qualitativ hochwertiger Algorithmus mehrere Tuning-Runden erfordert.
- Die Genauigkeitsrate variiert
- Leistung von Verarbeitungsalgorithmen
Wie schätzen wir die Kosten eines maschinellen Lernprojekts ein?
Wenn wir über die Schätzung der Kosten eines maschinellen Lernprojekts sprechen, ist es wichtig, zunächst zu identifizieren, über welchen Projekttyp gesprochen wird.
Es gibt im Wesentlichen drei Arten von Machine-Learning-Projekten , die bei der Beantwortung der Frage Wie viel kostet Machine Learning eine Rolle spielen:
Erstens – Dieser Typ hat bereits eine Lösung – beide: Modellarchitektur und Datensatz sind bereits vorhanden. Diese Art von Projekten ist praktisch kostenlos, daher werden wir nicht darüber sprechen.
Zweitens – Diese Projekte erfordern Grundlagenforschung – Anwendung von ML in einem völlig neuen Bereich oder auf anderen Datenstrukturen im Vergleich zu Mainstream-Modellen. Die Kosten für diese Projekttypen sind in der Regel solche, die sich die Mehrheit der Startups nicht leisten kann.
Drittens – Auf diese werden wir uns bei unserer Kostenschätzung konzentrieren. Hier nehmen Sie bereits vorhandene Modellarchitekturen und Algorithmen und passen diese an die Daten an, an denen Sie arbeiten.
Kommen wir nun zu dem Teil, in dem wir die Kosten des ML-Projekts schätzen.
Die Daten kosten
Daten sind die Hauptwährung eines Machine-Learning-Projekts. Das Maximum der Lösungen und Forschung konzentriert sich auf die Variationen des überwachten Lernmodells. Es ist eine bekannte Tatsache, dass je tiefer das überwachte Lernen geht, desto größer der Bedarf an kommentierten Daten und desto höher die Entwicklungskosten für Machine Learning-Apps .
Während Dienste wie Scale und Mechanical Turk von Amazon Ihnen beim Sammeln und Kommentieren von Daten helfen können, was ist mit der Qualität?
Es kann sehr zeitaufwändig sein, die Datenbeispiele zu überprüfen und dann zu korrigieren. Die Lösung des Problems ist zweiseitig – entweder die Datenerfassung auslagern oder intern verfeinern.
Sie sollten den Großteil der Datenvalidierungs- und Verfeinerungsarbeiten auslagern und dann ein oder zwei Personen intern ernennen, die die Datenproben bereinigen und beschriften.
Die Forschungskosten
Der Forschungsteil des Projekts befasst sich, wie oben erwähnt, mit der Machbarkeitsstudie auf Einstiegsebene, der Algorithmussuche und der Experimentierphase. Die Informationen, die normalerweise aus einem Product Delivery Workshop hervorgehen . Grundsätzlich ist die Erkundungsphase diejenige, die jedes Projekt vor seiner Produktion durchläuft.
Das Abschließen der Phase mit ihrer äußersten Perfektion ist ein Prozess, der mit einer angehängten Zahl in den Kosten für die Implementierung der ML-Diskussion einhergeht.
Die Produktionskosten
Der Produktionsteil der Projektkosten für maschinelles Lernen setzt sich aus Infrastrukturkosten, Integrationskosten und Wartungskosten zusammen. Von diesen Kosten müssen Sie mit der Cloud-Berechnung die geringsten Ausgaben machen. Aber auch das wird von der Komplexität eines Algorithmus zum anderen variieren.
Die Integrationskosten variieren von einem Anwendungsfall zum anderen. Normalerweise reicht es aus, einen API-Endpunkt in die Cloud zu stellen und ihn zu dokumentieren, um dann vom Rest des Systems verwendet zu werden.
Ein Schlüsselfaktor, der bei der Entwicklung eines maschinellen Lernprojekts häufig übersehen wird, ist die Notwendigkeit, während des gesamten Lebenszyklus des Projekts kontinuierlichen Support zu leisten. Die von APIs eingehenden Daten müssen ordnungsgemäß bereinigt und kommentiert werden. Dann müssen die Modelle mit neuen Daten trainiert und getestet und eingesetzt werden.
Zusätzlich zu den oben genannten Punkten gibt es zwei weitere Faktoren, die bei der Schätzung der Kosten für die Entwicklung einer KI-App/ML-App von Bedeutung sind .
Herausforderungen bei der Entwicklung von Apps für maschinelles Lernen

Normalerweise werden bei der Erstellung einer Projektschätzung für eine App für maschinelles Lernen auch die damit verbundenen Entwicklungsherausforderungen berücksichtigt. Aber es kann Fälle geben, in denen die Herausforderungen mitten im Entwicklungsprozess von ML-gestützten Apps liegen. In solchen Fällen erhöht sich automatisch die Gesamtzeit- und Kostenschätzung.
Die Herausforderungen für Machine-Learning-Projekte können reichen von:
- Entscheiden, welche Funktionen zu maschinellen Lernfunktionen werden sollen
- Talentdefizit im Bereich KI und maschinelles Lernen
- Die Beschaffung von Datensätzen ist teuer
- Es braucht Zeit, um zufriedenstellende Ergebnisse zu erzielen
Fazit
Die Abschätzung des Arbeits- und Zeitaufwands für die Fertigstellung eines Softwareprojekts ist relativ einfach, wenn es auf der Grundlage eines modularen Designs entwickelt und von einem erfahrenen Team nach einem agilen Ansatz bearbeitet wird . Das Gleiche wird jedoch umso schwieriger, wenn Sie daran arbeiten, eine zeit- und arbeitsintensive Projektschätzung für Machine Learning-Apps zu erstellen.
Auch wenn die Ziele gut definiert sein mögen, gibt es keine Garantie dafür, ob ein Modell das gewünschte Ergebnis erzielen würde oder nicht. Es ist in der Regel nicht möglich, den Umfang zu verringern und das Projekt dann in Zeitfenstern bis zu einem vordefinierten Liefertermin durchzuführen.
Es ist von größter Bedeutung, dass Sie erkennen, dass es Unsicherheiten geben wird. Ein Ansatz, der dazu beitragen kann, Verzögerungen zu verringern, besteht darin, sicherzustellen, dass die Eingabedaten das richtige Format für maschinelles Lernen haben.
Aber egal welchen Ansatz Sie verfolgen möchten, er wird letztendlich nur dann als erfolgreich angesehen, wenn Sie mit einer Entwicklungsagentur für maschinelles Lernen zusammenarbeiten, die weiß, wie man die Komplexität in ihrer einfachsten Form entwickelt und bereitstellt.
Häufig gestellte Fragen zur Schätzung des App-Projekts für maschinelles Lernen
F. Warum maschinelles Lernen bei der Entwicklung einer App verwenden?
Es gibt eine Reihe von Vorteilen, die Unternehmen durch die Integration von maschinellem Lernen in ihre mobilen Apps nutzen können. Einige der am weitesten verbreiteten sind im Bereich App-Marketing –
- Bietet personalisierte Erfahrung
- Erweiterte Suche
- Vorhersage des Benutzerverhaltens
- Tieferes Benutzerengagement
F. Wie kann maschinelles Lernen Ihrem Unternehmen helfen?
Die Vorteile des maschinellen Lernens für Unternehmen gehen über die Kennzeichnung als disruptive Marke hinaus. Dies führt dazu, dass ihre Angebote personalisierter und in Echtzeit werden.
Maschinelles Lernen kann die Geheimformel sein, die Unternehmen ihren Kunden näher bringt, genau so, wie sie angesprochen werden möchten.
F. Wie schätzt man den ROI bei der Entwicklung eines maschinellen Lernprojekts?
Während der Artikel Ihnen bei der Erstellung der Projektschätzung für Machine Learning-Apps geholfen hätte, ist die Berechnung des ROI ein anderes Spiel. Sie müssen auch die Opportunitätskosten in der Mischung berücksichtigen. Darüber hinaus müssen Sie sich mit den Erwartungen befassen, die Ihr Unternehmen von dem Projekt hat.
F. Welche Plattform ist besser für ein ML-Projekt?
Ihre Wahl, ob Sie sich mit einem Android-App-Entwicklungsunternehmen oder mit iOS-Entwicklern in Verbindung setzen, hängt vollständig von Ihrer Benutzerbasis und der Absicht ab – ob es sich um Gewinn oder Wert handelt.