
Ein SEO-Leitfaden zum Verständnis großer Sprachmodelle (LLMs)
Veröffentlicht: 2023-05-08Sollte ich große Sprachmodelle für die Keyword-Recherche verwenden? Können diese Modelle denken? Ist ChatGPT mein Freund?
Wenn Sie sich diese Fragen gestellt haben, ist dieser Leitfaden genau das Richtige für Sie.
Dieser Leitfaden behandelt, was SEOs über große Sprachmodelle, die Verarbeitung natürlicher Sprache und alles dazwischen wissen müssen.
Große Sprachmodelle, Verarbeitung natürlicher Sprache und mehr in einfachen Worten
Es gibt zwei Möglichkeiten, jemanden dazu zu bringen, etwas zu tun – ihm zu sagen, dass er es tun soll, oder zu hoffen, dass er es selbst tut.
In der Informatik sagt die Programmierung dem Roboter, dass er es tun soll, während das maschinelle Lernen hofft, dass der Roboter es selbst tut. Ersteres ist überwachtes maschinelles Lernen, letzteres unüberwachtes maschinelles Lernen.
Die Verarbeitung natürlicher Sprache (NLP) ist eine Möglichkeit, den Text in Zahlen zu zerlegen und ihn dann mithilfe von Computern zu analysieren.
Computer analysieren Muster in Wörtern und, wenn sie fortgeschrittener sind, in den Beziehungen zwischen den Wörtern.
Ein unüberwachtes maschinelles Lernmodell für natürliche Sprache kann mit vielen verschiedenen Arten von Datensätzen trainiert werden.
Wenn Sie beispielsweise ein Sprachmodell mit durchschnittlichen Rezensionen des Films „Waterworld“ trainieren, erhalten Sie ein Ergebnis, das gut darin ist, Rezensionen des Films „Waterworld“ zu schreiben (oder zu verstehen).
Wenn Sie es auf die zwei positiven Kritiken trainieren würden, die ich für den Film „Waterworld“ gemacht habe, würde es nur diese positiven Kritiken verstehen.
Large Language Models (LLMs) sind neuronale Netze mit über einer Milliarde Parametern. Sie sind so groß, dass sie allgemeiner sind. Sie werden nicht nur zu positiven und negativen Bewertungen für „Waterworld“ geschult, sondern auch zu Kommentaren, Wikipedia-Artikeln, Nachrichtenseiten und mehr.
Machine-Learning-Projekte arbeiten viel mit Kontext – Dingen innerhalb und außerhalb des Kontexts.
Wenn Sie ein maschinelles Lernprojekt haben, das daran arbeitet, Fehler zu identifizieren und ihm eine Katze zu zeigen, wird es bei diesem Projekt nicht gut sein.
Aus diesem Grund sind Dinge wie selbstfahrende Autos so schwierig: Es gibt so viele kontextlose Probleme, dass es sehr schwierig ist, dieses Wissen zu verallgemeinern.
LLMs scheinen und können sein viel allgemeiner als andere maschinelle Lernprojekte. Dies liegt an der schieren Größe der Daten und der Fähigkeit, Milliarden verschiedener Beziehungen zu verarbeiten.
Lassen Sie uns über eine der bahnbrechenden Technologien sprechen, die dies ermöglichen – Transformatoren.
Transformatoren von Grund auf erklären
Transformatoren sind eine Art neuronale Netzwerkarchitektur und haben das NLP-Feld revolutioniert.
Vor Transformern stützten sich die meisten NLP-Modelle auf eine Technik namens rekurrente neuronale Netze (RNNs), die Text sequentiell, Wort für Wort, verarbeitete. Dieser Ansatz hatte seine Grenzen, z. B. war er langsam und hatte Mühe, mit weitreichenden Abhängigkeiten im Text umzugehen.
Transformers hat dies geändert.
In dem wegweisenden Papier von 2017 „Attention is All You Need“ stellen Vaswani et al. Einführung der Transformatorarchitektur.
Anstatt Text sequenziell zu verarbeiten, verwenden Transformer einen Mechanismus namens „Selbstaufmerksamkeit“, um Wörter parallel zu verarbeiten, wodurch sie weitreichende Abhängigkeiten effizienter erfassen können.
Frühere Architekturen umfassten RNNs und Algorithmen für langes Kurzzeitgedächtnis.
Wiederkehrende Modelle wie diese wurden (und werden immer noch) häufig für Aufgaben verwendet, die Datensequenzen wie Text oder Sprache betreffen.
Allerdings haben diese Modelle ein Problem. Sie können die Daten nur Stück für Stück verarbeiten, was sie verlangsamt und die Datenmenge einschränkt, mit der sie arbeiten können. Diese sequentielle Verarbeitung schränkt die Leistungsfähigkeit dieser Modelle wirklich ein.
Aufmerksamkeitsmechanismen wurden als eine andere Art der Verarbeitung von Sequenzdaten eingeführt. Sie ermöglichen es einem Modell, sich alle Daten gleichzeitig anzusehen und zu entscheiden, welche Teile am wichtigsten sind.
Dies kann bei vielen Aufgaben sehr hilfreich sein. Die meisten Modelle, die Aufmerksamkeit verwendet haben, verwenden jedoch auch eine wiederkehrende Verarbeitung.
Im Grunde hatten sie diese Art der Datenverarbeitung auf einmal, mussten sie sich aber dennoch der Reihe nach ansehen. Das Papier von Vaswani et al. schwebte in der Luft: „Was wäre, wenn wir nur den Aufmerksamkeitsmechanismus verwenden würden?“
Aufmerksamkeit ist eine Möglichkeit für das Modell, sich bei der Verarbeitung auf bestimmte Teile der Eingabesequenz zu konzentrieren. Wenn wir zum Beispiel einen Satz lesen, schenken wir einigen Wörtern naturgemäß mehr Aufmerksamkeit als anderen, je nach Kontext und dem, was wir verstehen wollen.
Wenn Sie sich einen Transformer ansehen, berechnet das Modell eine Punktzahl für jedes Wort in der Eingabesequenz basierend darauf, wie wichtig es für das Verständnis der Gesamtbedeutung der Sequenz ist.
Das Modell verwendet diese Werte dann, um die Wichtigkeit jedes Wortes in der Sequenz zu gewichten, sodass es sich mehr auf die wichtigen Wörter und weniger auf die unwichtigen konzentrieren kann.
Dieser Aufmerksamkeitsmechanismus hilft dem Modell, weitreichende Abhängigkeiten und Beziehungen zwischen Wörtern zu erfassen, die in der Eingabesequenz möglicherweise weit voneinander entfernt sind, ohne die gesamte Sequenz sequenziell verarbeiten zu müssen.
Dies macht den Transformer so leistungsfähig für Aufgaben der Verarbeitung natürlicher Sprache, da er die Bedeutung eines Satzes oder einer längeren Textsequenz schnell und genau verstehen kann.
Nehmen wir das Beispiel eines Transformatormodells, das den Satz „Die Katze saß auf der Matte“ verarbeitet.
Jedes Wort im Satz wird als Vektor, eine Reihe von Zahlen, unter Verwendung einer Einbettungsmatrix dargestellt. Nehmen wir an, die Einbettungen für jedes Wort sind:
- Die : [0,2, 0,1, 0,3, 0,5]
- Katze : [0,6, 0,3, 0,1, 0,2]
- sat : [0,1, 0,8, 0,2, 0,3]
- ein : [0,3, 0,1, 0,6, 0,4]
- die : [0,5, 0,2, 0,1, 0,4]
- Matte : [0,2, 0,4, 0,7, 0,5]
Dann berechnet der Transformer eine Punktzahl für jedes Wort im Satz basierend auf seiner Beziehung zu allen anderen Wörtern im Satz.
Dies erfolgt unter Verwendung des Skalarprodukts der Einbettung jedes Wortes mit der Einbettung aller anderen Wörter im Satz.
Um beispielsweise die Punktzahl für das Wort „Katze“ zu berechnen, würden wir das Skalarprodukt seiner Einbettung mit den Einbettungen aller anderen Wörter bilden:
- „ Die Katze “: 0,2*0,6 + 0,1*0,3 + 0,3*0,1 + 0,5*0,2 = 0,24
- „ Katze saß “: 0,6*0,1 + 0,3*0,8 + 0,1*0,2 + 0,2*0,3 = 0,31
- „ Katze an “: 0,6*0,3 + 0,3*0,1 + 0,1*0,6 + 0,2*0,4 = 0,39
- „ Katze die “: 0,6*0,5 + 0,3*0,2 + 0,1*0,1 + 0,2*0,4 = 0,42
- „ Katzenmatte “: 0,6*0,2 + 0,3*0,4 + 0,1*0,7 + 0,2*0,5 = 0,32
Diese Punktzahlen geben die Relevanz jedes Wortes für das Wort „Katze“ an. Der Transformer verwendet dann diese Bewertungen, um eine gewichtete Summe der Worteinbettungen zu berechnen, wobei die Gewichtungen die Bewertungen sind.
Dadurch wird ein Kontextvektor für das Wort „Katze“ erstellt, der die Beziehungen zwischen allen Wörtern im Satz berücksichtigt. Dieser Vorgang wird für jedes Wort im Satz wiederholt.
Betrachten Sie es als den Transformator, der basierend auf dem Ergebnis jeder Berechnung eine Linie zwischen jedem Wort im Satz zieht. Einige Linien sind dünner, andere weniger.
Der Transformator ist ein neuartiges Modell, das nur Aufmerksamkeit ohne wiederkehrende Verarbeitung verwendet. Dadurch ist es viel schneller und in der Lage, mehr Daten zu verarbeiten.
Wie GPT Transformer verwendet
Sie erinnern sich vielleicht, dass Google in der BERT-Ankündigung damit geprahlt hat, dass es der Suche erlaubt, den vollständigen Kontext einer Eingabe zu verstehen. Dies ähnelt der Verwendung von Transformern durch GPT.
Lassen Sie uns eine Analogie verwenden.
Stellen Sie sich vor, Sie haben eine Million Affen, von denen jeder vor einer Tastatur sitzt.
Jeder Affe drückt willkürlich Tasten auf seiner Tastatur und erzeugt Buchstaben- und Symbolketten.
Einige Zeichenfolgen sind völliger Unsinn, während andere echten Wörtern oder sogar zusammenhängenden Sätzen ähneln.
Eines Tages sieht einer der Zirkustrainer, dass ein Affe „Sein oder nicht sein“ aufgeschrieben hat, also gibt der Trainer dem Affen ein Leckerli.
Die anderen Affen sehen das und versuchen, den erfolgreichen Affen nachzuahmen, in der Hoffnung auf ihre eigene Leckerei.
Im Laufe der Zeit beginnen einige Affen, durchweg bessere und kohärentere Textzeichenfolgen zu produzieren, während andere weiterhin Kauderwelsch produzieren.
Schließlich können die Affen zusammenhängende Muster im Text erkennen und sogar nachahmen.
LLMs haben einen Vorteil gegenüber den Affen, weil LLMs zuerst auf Milliarden von Textstücken trainiert werden. Sie können die Muster bereits erkennen. Sie verstehen auch die Vektoren und Beziehungen zwischen diesen Textteilen.
Das bedeutet, dass sie diese Muster und Beziehungen verwenden können, um neuen Text zu generieren, der der natürlichen Sprache ähnelt.
GPT steht für Generative Pre-trained Transformer und ist ein Sprachmodell, das Transformer verwendet, um Text in natürlicher Sprache zu generieren.
Es wurde mit einer riesigen Menge an Text aus dem Internet trainiert, was es ihm ermöglichte, die Muster und Beziehungen zwischen Wörtern und Sätzen in natürlicher Sprache zu lernen.
Das Modell funktioniert, indem es eine Eingabeaufforderung oder ein paar Wörter Text aufnimmt und die Transformatoren verwendet, um vorherzusagen, welche Wörter als nächstes kommen sollten, basierend auf den Mustern, die es aus seinen Trainingsdaten gelernt hat.
Das Modell generiert weiterhin Text Wort für Wort, wobei der Kontext der vorherigen Wörter verwendet wird, um die nächsten zu informieren.
GPT in Aktion
Einer der Vorteile von GPT besteht darin, dass es Text in natürlicher Sprache generieren kann, der sehr kohärent und kontextuell relevant ist.
Dies hat viele praktische Anwendungen, z. B. das Erstellen von Produktbeschreibungen oder das Beantworten von Kundendienstanfragen. Es kann auch kreativ verwendet werden, z. B. zum Erstellen von Gedichten oder Kurzgeschichten.
Es ist jedoch nur ein Sprachmodell. Es wird anhand von Daten trainiert, und diese Daten können veraltet oder falsch sein.
- Es hat keine Quelle des Wissens.
- Es kann nicht im Internet suchen.
- Es „weiß“ nichts.
Es errät einfach, welches Wort als nächstes kommt.
Schauen wir uns einige Beispiele an:
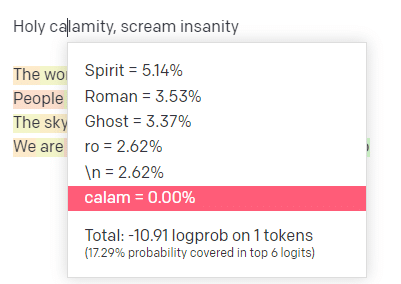
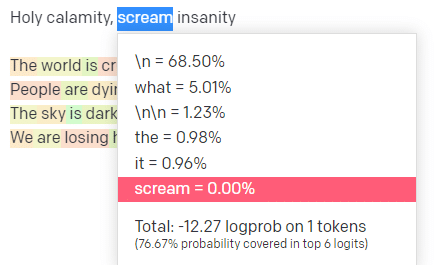
Auf der OpenAI-Spielwiese habe ich die erste Zeile des klassischen Handsome Boy Modeling School-Tracks „Holy Calamity [[Bear Witness ii]]“ eingefügt.
Ich habe die Antwort gesendet, damit wir die Wahrscheinlichkeit sowohl meiner Eingabe- als auch der Ausgabezeilen sehen können. Gehen wir also jeden Teil dessen durch, was uns das sagt.
Für das erste Wort/Token gebe ich „Holy“ ein. Wir können sehen, dass die am meisten erwartete nächste Eingabe Spirit, Roman und Ghost ist.
Wir können auch sehen, dass die sechs besten Ergebnisse nur 17,29 % der Wahrscheinlichkeiten dessen abdecken, was als Nächstes kommt: Das bedeutet, dass es ~82 % andere Möglichkeiten gibt, die wir in dieser Visualisierung nicht sehen können.
Lassen Sie uns kurz die verschiedenen Eingaben besprechen, die Sie dabei verwenden können, und wie sie sich auf Ihre Ausgabe auswirken.
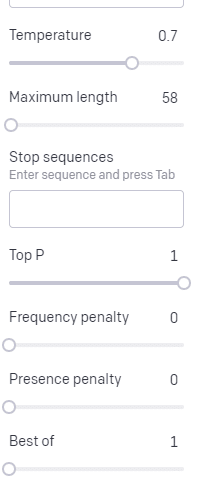
Die Temperatur gibt an, wie wahrscheinlich es ist, dass das Modell andere Wörter als die mit der höchsten Wahrscheinlichkeit erfasst, Top P gibt an, wie es diese Wörter auswählt.
Für die Eingabe „Holy Calamity“ ist Top P also, wie wir den Cluster der nächsten Token auswählen [Ghost, Roman, Spirit], und Temperatur gibt an, wie wahrscheinlich es ist, dass der wahrscheinlichste Token im Vergleich zu mehr Vielfalt gewählt wird.
Wenn die Temperatur höher ist, ist es wahrscheinlicher, einen weniger wahrscheinlichen Token zu wählen.
Eine hohe Temperatur und ein hohes oberes P werden also wahrscheinlich wilder sein. Es wählt aus einer großen Vielfalt (hohes Top-P) und wählt eher überraschende Token.


Während eine hohe Temperatur, aber ein niedrigerer oberer P überraschende Optionen aus einer kleineren Auswahl an Möglichkeiten auswählen wird:

Und das Senken der Temperatur wählt nur die wahrscheinlichsten nächsten Token:

Das Spielen mit diesen Wahrscheinlichkeiten kann Ihnen meiner Meinung nach einen guten Einblick in die Funktionsweise dieser Art von Modellen geben.
Es betrachtet eine Sammlung wahrscheinlicher nächster Auswahlen basierend auf dem, was bereits abgeschlossen ist.
Was bedeutet das eigentlich?
Einfach ausgedrückt nehmen LLMs eine Sammlung von Eingaben auf, schütteln sie und wandeln sie in Ausgaben um.
Ich habe Leute darüber scherzen hören, ob das so anders sei als Menschen.
Aber es ist nicht wie bei Menschen – LLMs haben keine Wissensbasis. Sie extrahieren keine Informationen über eine Sache. Sie erraten eine Folge von Wörtern basierend auf dem letzten.
Ein weiteres Beispiel: Denken Sie an einen Apfel. Was gerade in den Sinn kommt?
Vielleicht kannst du eine in deinem Kopf drehen.
Vielleicht erinnern Sie sich an den Geruch eines Apfelgartens, die Süße einer rosa Dame usw.
Vielleicht denken Sie an Steve Jobs.
Sehen wir uns nun an, was eine Eingabeaufforderung „denke an einen Apfel“ zurückgibt.
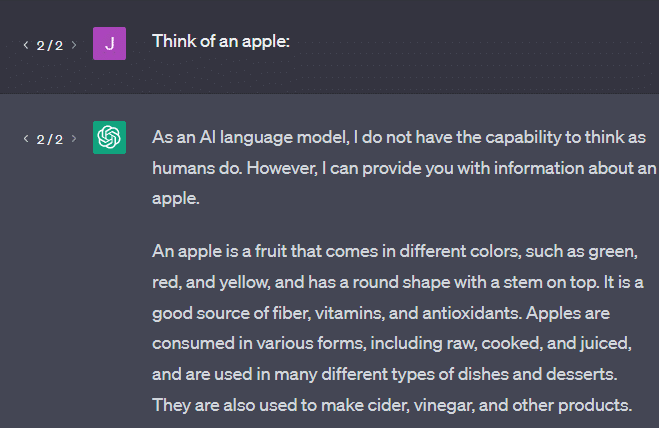
Sie haben vielleicht schon die Worte „Stochastic Parrots“ gehört, die zu diesem Zeitpunkt herumschwirren.
Stochastische Papageien ist ein Begriff, der verwendet wird, um LLMs wie GPT zu beschreiben. Ein Papagei ist ein Vogel, der nachahmt, was er hört.
LLMs sind also wie Papageien, da sie Informationen (Wörter) aufnehmen und etwas ausgeben, das dem ähnelt, was sie gehört haben. Aber sie sind auch stochastisch , was bedeutet, dass sie die Wahrscheinlichkeit verwenden, um zu erraten, was als nächstes kommt.
LLMs sind gut darin, Muster und Beziehungen zwischen Wörtern zu erkennen, aber sie haben kein tieferes Verständnis von dem, was sie sehen. Deshalb sind sie so gut darin, Text in natürlicher Sprache zu generieren, ihn aber nicht zu verstehen.
Gute Anwendungen für ein LLM
LLMs sind gut für allgemeinere Aufgaben.
Sie können ihm Text zeigen, und ohne Training kann es eine Aufgabe mit diesem Text erledigen.
Sie können ihm etwas Text zuwerfen und um Stimmungsanalyse bitten, ihn bitten, diesen Text in strukturiertes Markup zu übertragen und kreative Arbeit zu leisten (z. B. Umrisse schreiben).
Es ist in Ordnung bei Sachen wie Code. Bei vielen Aufgaben kann es Sie fast ans Ziel bringen.
Aber auch hier basiert es auf Wahrscheinlichkeiten und Mustern. Es wird also Zeiten geben, in denen es Muster in Ihrer Eingabe aufgreift, von denen Sie nicht wissen, dass sie vorhanden sind.
Das kann positiv sein (Muster sehen, die Menschen nicht sehen können), aber es kann auch negativ sein (warum hat es so reagiert?).
Es hat auch keinen Zugriff auf irgendwelche Datenquellen. SEOs, die es verwenden, um Ranking-Keywords nachzuschlagen, werden eine schlechte Zeit haben.
Es kann keinen Traffic für ein Schlüsselwort nachschlagen. Es verfügt nicht über die Informationen für Schlüsselwortdaten, die über die Wörter hinausgehen.

Das Spannende an ChatGPT ist, dass es sich um ein leicht verfügbares Sprachmodell handelt, das Sie sofort für verschiedene Aufgaben verwenden können. Aber es ist nicht ohne Vorbehalte.

Gute Verwendung für andere ML-Modelle
Ich höre Leute sagen, dass sie LLMs für bestimmte Aufgaben verwenden, die andere NLP-Algorithmen und -Techniken besser können.
Nehmen wir ein Beispiel, Keyword-Extraktion.
Wenn ich TF-IDF oder eine andere Schlüsselworttechnik verwende, um Schlüsselwörter aus einem Korpus zu extrahieren, weiß ich, welche Berechnungen in diese Technik einfließen.
Das bedeutet, dass die Ergebnisse standardisiert und reproduzierbar sind, und ich weiß, dass sie sich speziell auf diesen Korpus beziehen.
Wenn Sie bei LLMs wie ChatGPT nach einer Schlüsselwortextraktion fragen, erhalten Sie nicht unbedingt die Schlüsselwörter, die aus dem Korpus extrahiert wurden. Sie erhalten, was GPT für eine Antwort auf Corpus + Extract-Keywords hält.
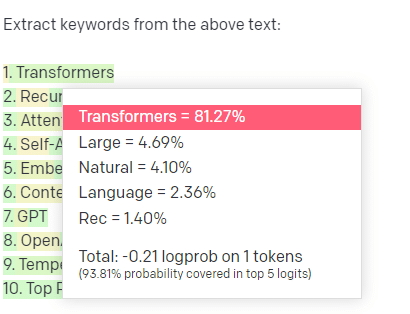
Dies ähnelt Aufgaben wie Clustering oder Stimmungsanalyse. Mit den von Ihnen eingestellten Parametern erhalten Sie nicht unbedingt das fein abgestimmte Ergebnis. Sie erhalten das, was mit einiger Wahrscheinlichkeit auf der Grundlage anderer ähnlicher Aufgaben erreicht wird.
Auch hier haben LLMs keine Wissensbasis und keine aktuellen Informationen. Sie können das Internet oft nicht durchsuchen und analysieren die Informationen, die sie erhalten, als statistische Token. Die Einschränkungen, wie lange das Gedächtnis eines LLM hält, sind auf diese Faktoren zurückzuführen.
Eine andere Sache ist, dass diese Modelle nicht denken können. Ich verwende das Wort „denken“ in diesem Artikel nur ein paar Mal, weil es wirklich schwierig ist, es nicht zu verwenden, wenn es um diese Prozesse geht.
Die Tendenz geht in Richtung Anthropomorphismus, selbst wenn es um ausgefallene Statistiken geht.
Aber das bedeutet, dass Sie einem denkenden Wesen nicht vertrauen, wenn Sie einem LLM eine Aufgabe anvertrauen, die „Denken“ erfordert.
Sie vertrauen einer statistischen Analyse dessen, womit Hunderte von Internet-Verrückten auf ähnliche Token reagieren.
Wenn Sie Internetnutzern eine Aufgabe anvertrauen möchten, können Sie ein LLM verwenden. Ansonsten…
Dinge, die niemals ML-Modelle sein sollten
Ein Chatbot, der ein GPT-Modell (GPT-J) durchläuft, soll einen Mann dazu ermutigt haben, sich umzubringen. Die Kombination von Faktoren kann echten Schaden anrichten, einschließlich:
- Menschen, die diese Reaktionen vermenschlichen.
- Zu glauben, dass sie unfehlbar sind.
- Verwenden Sie sie an Orten, an denen Menschen in der Maschine sein müssen.
- Und mehr.
Während Sie vielleicht denken: „Ich bin ein SEO. Ich habe keine Hände in Systemen, die jemanden töten könnten!“
Denken Sie an YMYL-Seiten und daran, wie Google Konzepte wie EEAT fördert.
Tut Google das, weil sie SEOs ärgern wollen, oder weil sie nicht die Schuld an diesem Schaden tragen wollen?
Selbst in Systemen mit starken Wissensbasen kann Schaden angerichtet werden.
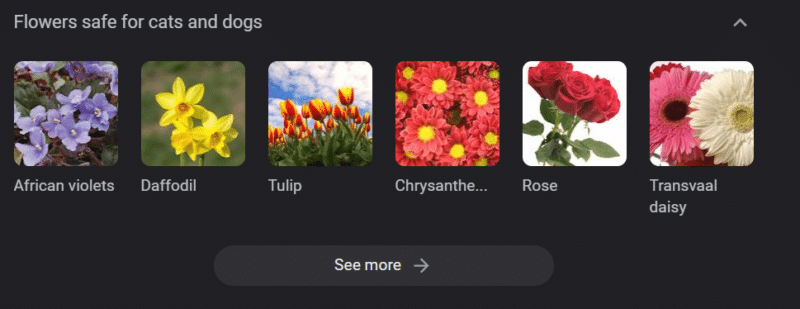
Das Obige ist ein Google-Wissenskarussell für „Blumen, die für Katzen und Hunde sicher sind“. Narzissen stehen auf dieser Liste, obwohl sie für Katzen giftig sind.
Angenommen, Sie erstellen Inhalte für eine Veterinär-Website in großem Umfang mit GPT. Sie geben eine Reihe von Schlüsselwörtern ein und pingen die ChatGPT-API an.
Sie lassen alle Ergebnisse von einem Freiberufler lesen, der kein Fachexperte ist. Sie gehen einem Problem nicht auf den Grund.
Sie veröffentlichen das Ergebnis, was den Kauf von Narzissen für Katzenbesitzer anregt.
Du tötest die Katze von jemandem.
Nicht direkt. Vielleicht wissen sie nicht einmal, dass es genau diese Seite war.
Vielleicht fangen die anderen Tierärzte an, dasselbe zu tun und sich gegenseitig zu ernähren.
Das oberste Google-Suchergebnis für „sind Narzissen für Katzen giftig“ ist eine Seite, die besagt, dass sie es nicht sind.
Andere Freiberufler, die sich andere KI-Inhalte durchlesen – Seiten für Seiten mit KI-Inhalten – überprüfen tatsächlich die Fakten. Aber die Systeme haben jetzt falsche Informationen.
Wenn ich über diesen aktuellen KI-Boom spreche, erwähne ich oft Therac-25. Es ist eine berühmte Fallstudie über Computermissbrauch.
Im Grunde war es ein Strahlentherapiegerät, das erste, das nur Computerverriegelungsmechanismen verwendete. Ein Fehler in der Software führte dazu, dass Menschen das Zehntausendfache der Strahlendosis erhielten, die sie haben sollten.
Was mir immer wieder auffällt ist, dass das Unternehmen diese Modelle freiwillig zurückgerufen und geprüft hat.
Aber sie gingen davon aus, dass das Problem mit den mechanischen Teilen der Maschine zu tun hatte, da die Technologie fortgeschritten und die Software „unfehlbar“ war.
Also reparierten sie die Mechanismen, überprüften aber nicht die Software – und der Therac-25 blieb auf dem Markt.
Häufig gestellte Fragen und Missverständnisse
Warum lügt mich ChatGPT an?
Eine Sache, die ich von einigen der größten Köpfe unserer Generation und auch Influencern auf Twitter gesehen habe, ist eine Beschwerde, dass ChatGPT sie „lügt“. Dies ist auf ein paar Missverständnisse zurückzuführen:
- Dass ChatGPT „Wünsche“ hat.
- Dass es eine Wissensbasis hat.
- Dass die Technologen hinter der Technologie eine Art Agenda haben, die über „Geld verdienen“ oder „ein cooles Ding machen“ hinausgeht.
Vorurteile sind in jeden Teil Ihres täglichen Lebens eingebrannt. So sind Ausnahmen von diesen Vorurteilen.
Die meisten Softwareentwickler sind derzeit Männer: Ich bin Softwareentwickler und eine Frau.
Eine KI auf Basis dieser Realität zu trainieren, würde dazu führen, dass sie immer annimmt, Softwareentwickler seien Männer, was nicht stimmt.
Ein berühmtes Beispiel ist die Rekrutierungs-KI von Amazon, die anhand der Lebensläufe erfolgreicher Amazon-Mitarbeiter trainiert wird.
Dies führte dazu, dass Lebensläufe von mehrheitlich schwarzen Colleges verworfen wurden, obwohl viele dieser Mitarbeiter äußerst erfolgreich hätten sein können.
Um diesen Vorurteilen entgegenzuwirken, verwenden Tools wie ChatGPT Ebenen der Feinabstimmung. Aus diesem Grund erhalten Sie die Antwort „Als KI-Sprachmodell kann ich nicht …“.
Einige Arbeiter in Kenia mussten Hunderte von Eingabeaufforderungen durchgehen und nach Beleidigungen, Hassreden und einfach nur schrecklichen Antworten und Eingabeaufforderungen suchen.
Dann wurde eine Feinabstimmungsschicht erstellt.
Warum können Sie sich keine Beleidigungen über Joe Biden ausdenken? Warum kann man sexistische Witze über Männer machen und nicht über Frauen?
Es liegt nicht an liberaler Voreingenommenheit, sondern an Tausenden von Feinabstimmungsebenen, die ChatGPT sagen, das N-Wort nicht zu sagen.
Im Idealfall wäre ChatGPT völlig neutral gegenüber der Welt, aber sie brauchen es auch, um die Welt widerzuspiegeln.
Es ist ein ähnliches Problem wie bei Google.
Was wahr ist, was Menschen glücklich macht und was eine richtige Reaktion auf eine Aufforderung ausmacht, sind oft sehr unterschiedliche Dinge .
Warum kommt ChatGPT mit gefälschten Zitaten?
Eine andere Frage, die ich häufig sehe, bezieht sich auf gefälschte Zitate. Warum sind einige von ihnen gefälscht und andere echt? Warum sind einige Websites echt, aber die Seiten sind gefälscht?
Wenn Sie lesen, wie die statistischen Modelle funktionieren, können Sie dies hoffentlich herausfinden. Aber hier eine kurze Erklärung:
Sie sind ein KI-Sprachmodell. Sie wurden auf einer Tonne des Webs geschult.
Jemand fordert Sie auf, über eine technologische Sache zu schreiben – sagen wir, Cumulative Layout Shift.
Sie haben nicht viele Beispiele für CLS-Papiere, aber Sie wissen, was es ist, und Sie kennen die allgemeine Form eines Artikels über Technologien. Sie kennen das Muster, wie diese Art von Artikel aussieht.

Sie fangen also mit Ihrer Antwort an und stoßen auf eine Art Problem. So wie Sie technisches Schreiben verstehen, wissen Sie, dass eine URL in Ihrem Satz als nächstes stehen sollte.
Nun, aus anderen CLS-Artikeln wissen Sie, dass Google und GTMetrix oft über CLS zitiert werden, also sind diese einfach.
Aber Sie wissen auch, dass in Webartikeln oft auf CSS-Tricks verwiesen wird: Sie wissen, dass CSS-Tricks-URLs normalerweise auf eine bestimmte Weise aussehen: Sie können also eine CSS-Tricks-URL wie folgt konstruieren:
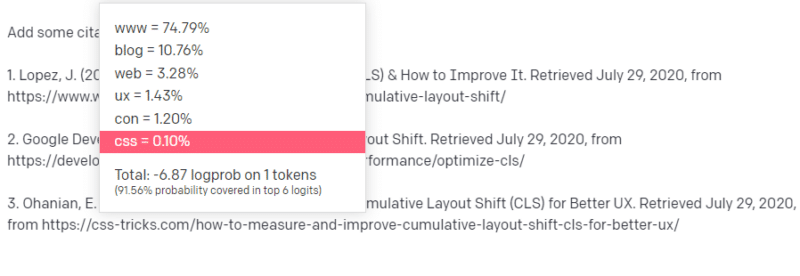
Der Trick ist: So sind alle URLs aufgebaut, nicht nur die gefälschten:

Dieser GTMetrix-Artikel existiert, aber er existiert, weil es wahrscheinlich eine Reihe von Werten war, die am Ende dieses Satzes stehen würden.
GPT und ähnliche Modelle können nicht zwischen einem echten Zitat und einem gefälschten unterscheiden.
Die einzige Möglichkeit, diese Modellierung durchzuführen, besteht darin, andere Quellen (Wissensdatenbanken, Python usw.) zu verwenden, um diesen Unterschied zu analysieren und die Ergebnisse zu überprüfen.
Was ist ein „stochastischer Papagei“?
Ich weiß, dass ich das bereits besprochen habe, aber es muss wiederholt werden. Stochastische Papageien beschreiben, was passiert, wenn große Sprachmodelle von Natur aus generalistisch erscheinen .
Für den LLM sind Unsinn und Realität dasselbe. Sie sehen die Welt wie ein Ökonom, als ein Bündel von Statistiken und Zahlen, die die Realität beschreiben.
Sie kennen das Zitat: „Es gibt drei Arten von Lügen: Lügen, verdammte Lügen und Statistiken.“
LLMs sind ein großer Haufen Statistiken.
LLMs scheinen kohärent zu sein, aber das liegt daran, dass wir Dinge, die menschlich erscheinen, grundsätzlich als menschlich sehen.
In ähnlicher Weise verschleiert das Chatbot-Modell viele der Eingabeaufforderungen und Informationen, die Sie benötigen, damit GPT-Antworten vollständig kohärent sind.
Ich bin Entwickler: Der Versuch, LLMs zum Debuggen meines Codes zu verwenden, führt zu äußerst unterschiedlichen Ergebnissen. Wenn es sich um ein ähnliches Problem handelt, wie es häufig online aufgetreten ist, können LLMs dieses Ergebnis aufgreifen und beheben.
Wenn es sich um ein Problem handelt, auf das es noch nie zuvor gestoßen ist, oder wenn es sich um einen kleinen Teil des Korpus handelt, wird es nichts beheben.
Warum ist GPT besser als eine Suchmaschine?
Ich habe das scharf formuliert. Ich glaube nicht, dass GPT besser ist als eine Suchmaschine. Es macht mir Sorgen, dass die Leute die Suche durch ChatGPT ersetzt haben.
Ein unterschätzter Teil von ChatGPT ist, wie wichtig es ist, Anweisungen zu befolgen. Sie können ihn bitten, im Grunde alles zu tun.
Aber denken Sie daran, es basiert alles auf dem nächsten statistischen Wort in einem Satz, nicht auf der Wahrheit.
Wenn Sie ihm also eine Frage stellen, die keine gute Antwort hat, sie aber so stellen, dass er sie beantworten muss, erhalten Sie eine schlechte Antwort.
Eine Antwort zu haben, die für Sie und um Sie herum entworfen wurde, ist beruhigender, aber die Welt ist eine Masse von Erfahrungen.
Alle Eingaben in ein LLM werden gleich behandelt: Einige Leute haben jedoch Erfahrung, und ihre Antwort wird besser sein als eine Mischung aus den Antworten anderer Leute.
Ein Experte ist mehr wert als tausend Gedankenstücke.
Ist das der Beginn der KI? Ist Skynet hier?
Koko der Gorilla war ein Affe, dem Gebärdensprache beigebracht wurde. Forscher in Sprachwissenschaften haben unzählige Untersuchungen durchgeführt, die zeigen, dass Affen Sprache beigebracht werden kann.
Herbert Terrace entdeckte dann, dass die Affen keine Sätze oder Wörter zusammenstellten, sondern einfach ihre menschlichen Betreuer nachäfften.
Eliza war eine Maschinentherapeutin, einer der ersten Chatterbots (Chatbots).
Die Leute sahen sie als Person: eine Therapeutin, der sie vertrauten und die sie umsorgten. Sie baten die Forscher, mit ihr allein zu sein.
Sprache macht etwas sehr Spezifisches mit den Gehirnen der Menschen. Menschen hören etwas kommunizieren und erwarten Gedanken dahinter.
LLMs sind beeindruckend, aber auf eine Weise, die eine Bandbreite menschlicher Errungenschaften zeigt.
LLMs haben kein Testament. Sie können nicht entkommen. Sie können nicht versuchen, die Weltherrschaft an sich zu reißen.
Sie sind ein Spiegel: ein Spiegelbild der Menschen und insbesondere des Benutzers.
Der einzige Gedanke dort ist eine statistische Darstellung des kollektiven Unbewussten.
Hat GPT eine ganze Sprache von selbst gelernt?
Sundar Pichai, CEO von Google, ging auf „60 Minutes“ und behauptete, dass Googles Sprachmodell Bengali gelernt habe.
Das Modell wurde mit diesen Texten trainiert. Es ist falsch, dass es „eine Fremdsprache sprach, die ihm nie beigebracht wurde“.
Es gibt Zeiten, in denen KI unerwartete Dinge tut, aber das an sich wird erwartet.
Wenn Sie Muster und Statistiken im großen Stil betrachten, wird es zwangsläufig Zeiten geben, in denen diese Muster etwas Überraschendes offenbaren.
Was dies wirklich zeigt, ist, dass viele der C-Suite- und Marketing-Leute, die mit KI und ML hausieren, nicht wirklich verstehen, wie die Systeme funktionieren.
Ich habe einige Leute gehört, die sehr schlau sind und über neue Eigenschaften, künstliche allgemeine Intelligenz (AGI) und andere futuristische Dinge sprechen.
Ich bin vielleicht nur ein einfacher Country-ML-Ops-Ingenieur, aber es zeigt, wie viel Hype, Versprechungen, Science-Fiction und Realität zusammengeworfen werden, wenn man über diese Systeme spricht.
Elizabeth Holmes, die berüchtigte Gründerin von Theranos, wurde gekreuzigt, weil sie Versprechungen gemacht hatte, die nicht gehalten werden konnten.
Aber der Kreislauf unmöglicher Versprechungen ist Teil der Startup-Kultur und des Geldverdienens. Der Unterschied zwischen Theranos und dem KI-Hype besteht darin, dass Theranos es nicht lange vortäuschen konnte.
Ist GPT eine Blackbox? Was passiert mit meinen Daten in GPT?
GPT ist als Modell keine Blackbox. Sie können den Quellcode für GPT-J und GPT-Neo sehen.
Das GPT von OpenAI ist jedoch eine Blackbox. OpenAI hat und wird wahrscheinlich nicht versuchen, sein Modell nicht zu veröffentlichen, da Google den Algorithmus nicht veröffentlicht.
Aber das liegt nicht daran, dass der Algorithmus zu gefährlich ist. Wenn das wahr wäre, würden sie keinem dummen Kerl mit einem Computer API-Abonnements verkaufen. Das liegt am Wert dieser proprietären Codebasis.
Wenn Sie die Tools von OpenAI verwenden, trainieren und füttern Sie ihre API mit Ihren Eingaben. Das bedeutet, dass alles, was Sie in die OpenAI eingeben, diese speist.
Dies bedeutet, dass Personen, die das GPT-Modell von OpenAI für Patientendaten verwendet haben, um beim Schreiben von Notizen und anderen Dingen zu helfen, gegen HIPAA verstoßen haben. Diese Informationen befinden sich jetzt im Modell, und es wird äußerst schwierig sein, sie zu extrahieren.
Da so viele Menschen Schwierigkeiten haben, dies zu verstehen, ist es sehr wahrscheinlich, dass das Modell Tonnen von privaten Daten enthält, die nur auf die richtige Aufforderung warten, sie freizugeben.
Warum wird GPT auf Hassreden geschult?
Eine andere Sache, die oft auftaucht, ist, dass der Textkorpus, an dem GPT trainiert wurde, Hassreden enthält.
Bis zu einem gewissen Grad muss OpenAI seine Modelle trainieren, um auf Hassreden zu reagieren, also muss es einen Korpus haben, der einige dieser Begriffe enthält.
OpenAI hat behauptet, diese Art von Hassreden aus dem System zu entfernen, aber die Quelldokumente umfassen 4chan und Tonnen von Hassseiten.
Crawle das Web, nimm die Voreingenommenheit auf.
Es gibt keinen einfachen Weg, dies zu vermeiden. Wie können Sie Hass, Vorurteile und Gewalt erkennen oder verstehen, ohne dass dies Teil Ihres Trainingssets ist?
Wie vermeiden Sie Vorurteile und verstehen implizite und explizite Vorurteile, wenn Sie ein Maschinenagent sind, der statistisch das nächste Token in einem Satz auswählt?
TL;DR
Hype und Fehlinformationen sind derzeit wichtige Elemente des KI-Booms. Das bedeutet nicht, dass es keine legitimen Anwendungen gibt: Diese Technologie ist erstaunlich und nützlich.
Aber wie die Technologie vermarktet wird und wie Menschen sie nutzen, kann Fehlinformationen und Plagiate fördern und sogar direkten Schaden anrichten.
Verwenden Sie keine LLMs, wenn Leben auf dem Spiel steht. Verwenden Sie keine LLMs, wenn ein anderer Algorithmus besser funktionieren würde. Lassen Sie sich nicht vom Hype täuschen.
Es ist notwendig zu verstehen, was LLMs sind – und was nicht
Ich empfehle dieses Adam Conover-Interview mit Emily Bender und Timnit Gebru.
LLMs können bei richtiger Anwendung unglaubliche Werkzeuge sein. Es gibt viele Möglichkeiten, wie Sie LLMs verwenden können, und noch mehr Möglichkeiten, LLMs zu missbrauchen.
ChatGPT ist nicht dein Freund. Es ist ein Haufen Statistiken. AGI ist nicht „bereits hier“.
Die in diesem Artikel geäußerten Meinungen sind die des Gastautors und nicht unbedingt Search Engine Land. Mitarbeiter Autoren sind hier aufgelistet.