
Spark vs. Hadoop: Welches Big-Data-Framework bringt Ihr Unternehmen voran?
Veröffentlicht: 2019-09-24„Daten sind der Treibstoff der digitalen Wirtschaft“
Da sich moderne Unternehmen auf einen Haufen Daten verlassen, um ihre Verbraucher und ihren Markt besser zu verstehen, gewinnen Technologien wie Big Data an Bedeutung.
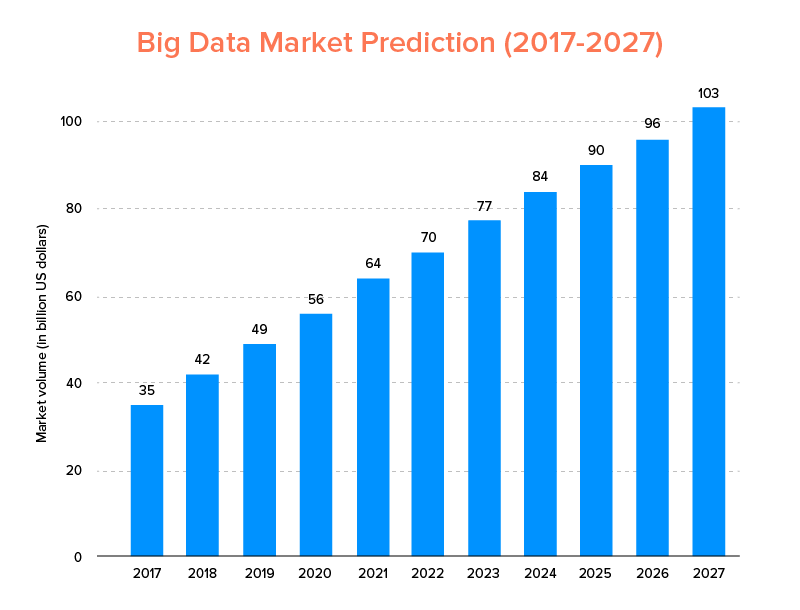
Big Data, genau wie KI, ist nicht nur auf der Liste der Top-Tech-Trends für 2020 gelandet , sondern wird voraussichtlich sowohl von Startups als auch von Fortune-500-Unternehmen angenommen, um ein exponentielles Geschäftswachstum zu erzielen und eine höhere Kundenbindung zu gewährleisten. Ein klarer Hinweis darauf ist, dass der Big-Data-Markt bis 2027 voraussichtlich 103 Milliarden US-Dollar erreichen wird.
Während auf der einen Seite alle hochmotiviert sind, ihre traditionellen Datenanalyse-Tools durch Big Data zu ersetzen – dasjenige, das den Boden für die Weiterentwicklung von Blockchain und KI bereitet –, sind sie auch verwirrt über die Wahl des richtigen Big Data-Tools. Sie stehen vor dem Dilemma, sich zwischen Apache Hadoop und Spark – den beiden Titanen der Big-Data-Welt – zu entscheiden.
In Anbetracht dieses Gedankens werden wir heute einen Artikel über Apache Spark vs. Hadoop behandeln und Ihnen dabei helfen, festzustellen, welche die richtige Option für Ihre Anforderungen ist.
Aber lassen Sie uns zunächst eine kurze Einführung in Hadoop und Spark geben.
Apache Hadoop ist ein Open-Source-, verteiltes und Java-basiertes Framework, mit dem Benutzer große Datenmengen über mehrere Computercluster hinweg mithilfe einfacher Programmierkonstrukte speichern und verarbeiten können. Es besteht aus verschiedenen Modulen, die zusammenarbeiten, um ein verbessertes Erlebnis zu bieten, und zwar:
- Hadoop-Common
- Verteiltes Hadoop-Dateisystem (HDFS)
- Hadoop-GARN
- Hadoop MapReduce
Dagegen ist Apache Spark ein Open-Source-Framework für verteiltes Cluster-Computing mit Big Data, das „benutzerfreundlich“ ist und schnellere Dienste bietet.
Die beiden Big-Data-Frameworks werden aufgrund der vielen Möglichkeiten, die sie bieten, von zahlreichen großen Unternehmen unterstützt.
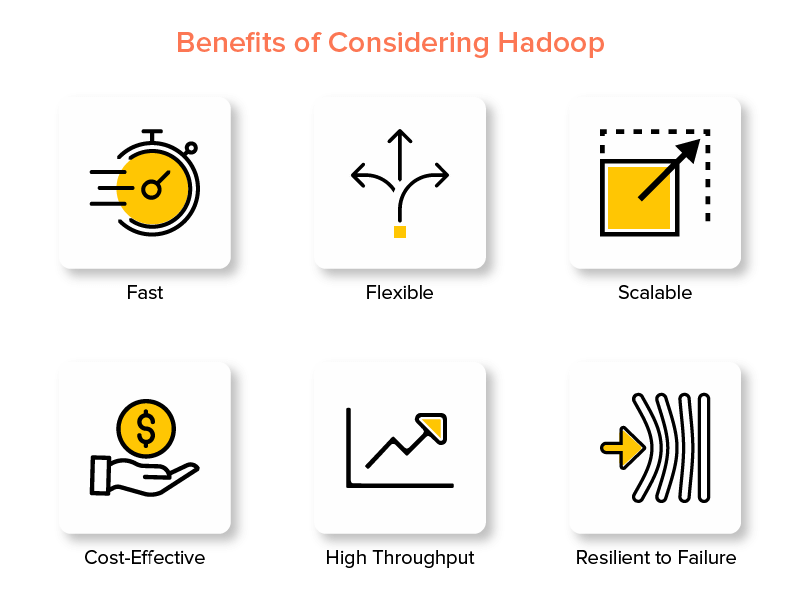
Vorteile von Hadoop Big Data Framework
1. Schnell
Eines der Merkmale von Hadoop, das es in der Big-Data-Welt beliebt macht, ist seine Schnelligkeit.
Seine Speichermethode basiert auf einem verteilten Dateisystem, das Daten in erster Linie dort abbildet, wo sie sich auf einem Cluster befinden. Außerdem sind Daten und Tools, die für die Datenverarbeitung verwendet werden, normalerweise auf demselben Server verfügbar, was die Datenverarbeitung zu einer problemlosen und schnelleren Aufgabe macht.
Tatsächlich wurde festgestellt, dass Hadoop Terabytes an unstrukturierten Daten in nur wenigen Minuten verarbeiten kann, während Petabytes in Stunden.
2. Flexibel
Hadoop bietet im Gegensatz zu herkömmlichen Datenverarbeitungstools High-End-Flexibilität.
Es ermöglicht Unternehmen, Daten aus verschiedenen Quellen (wie soziale Medien, E-Mails usw.) zu sammeln, mit verschiedenen Datentypen (sowohl strukturiert als auch unstrukturiert) zu arbeiten und wertvolle Erkenntnisse zur weiteren Verwendung für verschiedene Zwecke zu erhalten (wie Protokollverarbeitung, Marktkampagnenanalyse, Betrugserkennung usw.).
3. Skalierbar
Ein weiterer Vorteil von Hadoop ist die hohe Skalierbarkeit. Im Gegensatz zu herkömmlichen relationalen Datenbanksystemen (RDBMS) ermöglicht die Plattform Unternehmen das Speichern und Verteilen großer Datensätze von Hunderten von Servern, die parallel betrieben werden.
4. Kostengünstig
Apache Hadoop ist im Vergleich zu anderen Big-Data-Analysetools sehr kostengünstig. Dies liegt daran, dass keine spezielle Maschine erforderlich ist. es läuft auf einer Gruppe von Commodity-Hardware. Außerdem ist es auf lange Sicht einfacher, weitere Knoten hinzuzufügen.
Das heißt, in einem Fall können die Knoten problemlos erhöht werden, ohne dass Ausfallzeiten aufgrund von Vorplanungsanforderungen auftreten.
5. Hoher Durchsatz
Im Fall des Hadoop-Frameworks werden Daten verteilt gespeichert, sodass ein kleiner Auftrag parallel in mehrere Datenblöcke aufgeteilt wird. Dies erleichtert es Unternehmen, mehr Jobs in kürzerer Zeit zu erledigen, was letztendlich zu einem höheren Durchsatz führt.
6. Ausfallsicher
Last but not least bietet Hadoop Optionen mit hoher Fehlertoleranz, die dazu beitragen, die Folgen eines Ausfalls zu mindern. Es speichert eine Kopie jedes Blocks, die es ermöglicht, Daten wiederherzustellen, wenn ein Knoten ausfällt.
Nachteile des Hadoop-Frameworks
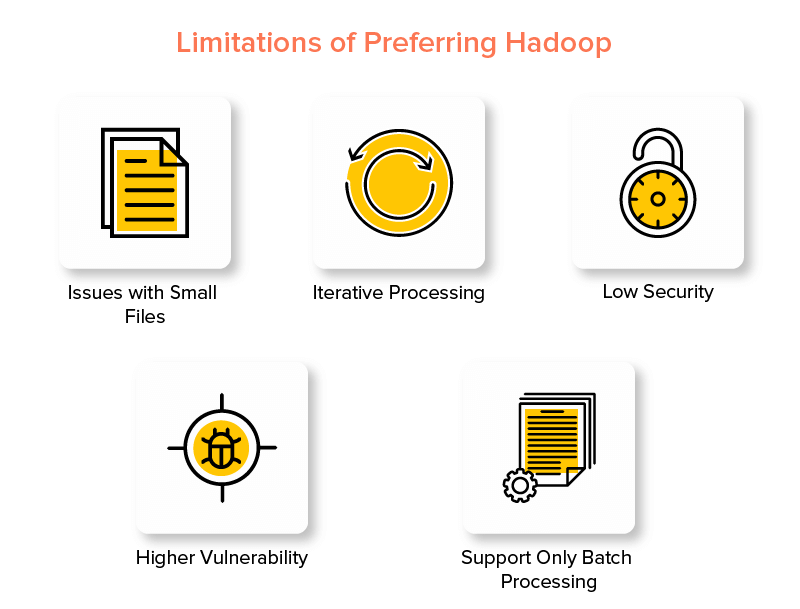
1. Probleme mit kleinen Dateien
Der größte Nachteil bei der Betrachtung von Hadoop für Big-Data-Analysen besteht darin, dass es nicht das Potenzial hat, das zufällige Lesen kleiner Dateien effizient und effektiv zu unterstützen.
Der Grund dafür ist, dass eine kleine Datei eine vergleichsweise geringere Speichergröße als die HDFS-Blockgröße hat. Wenn in einem solchen Szenario eine große Anzahl kleiner Dateien gespeichert wird, besteht eine höhere Wahrscheinlichkeit, dass NameNode überlastet wird, das den Namespace von HDFS speichert, was praktisch keine gute Idee ist.
2. Iterative Verarbeitung
Der Datenfluss im Big-Data-Hadoop-Framework hat die Form einer Kette, sodass die Ausgabe einer Stufe zur Eingabe einer anderen Stufe wird. Dagegen ist der Datenfluss bei der iterativen Verarbeitung zyklischer Natur.
Aus diesem Grund ist Hadoop eine ungeeignete Wahl für maschinelles Lernen oder iterative verarbeitungsbasierte Lösungen.
3. Geringe Sicherheit
Ein weiterer Nachteil des Hadoop-Frameworks besteht darin, dass es geringere Sicherheitsfunktionen bietet.
Das Framework hat beispielsweise das Sicherheitsmodell standardmäßig deaktiviert. Wenn jemand, der dieses Big-Data-Tool verwendet, nicht weiß, wie er es aktivieren soll, könnten seine Daten einem höheren Risiko ausgesetzt sein, gestohlen/missbraucht zu werden. Außerdem bietet Hadoop nicht die Funktionalität der Verschlüsselung auf Speicher- und Netzwerkebene, was wiederum die Wahrscheinlichkeit einer Bedrohung durch Datenschutzverletzungen erhöht.
4. Höhere Anfälligkeit
Das Hadoop-Framework ist in Java geschrieben, der beliebtesten, aber am stärksten genutzten Programmiersprache. Dies erleichtert Cyberkriminellen den einfachen Zugriff auf Hadoop-basierte Lösungen und den Missbrauch der sensiblen Daten.
5. Unterstützung nur für Stapelverarbeitung
Im Gegensatz zu verschiedenen anderen Big-Data-Frameworks verarbeitet Hadoop keine gestreamten Daten. Es unterstützt nur die Stapelverarbeitung , und der Grund dafür ist, dass MapReduce den Speicher des Hadoop-Clusters nicht maximal ausnutzt.
Während sich hier alles um Hadoop, seine Funktionen und Nachteile dreht, werfen wir einen Blick auf die Vor- und Nachteile von Spark, um den Unterschied zwischen den beiden zu verstehen.
Vorteile des Apache Spark-Frameworks
1. Dynamisch in der Natur
Da Apache Spark rund 80 High-Level-Operatoren bietet, kann es für die dynamische Verarbeitung von Daten verwendet werden. Es kann als das richtige Big-Data-Tool angesehen werden, um parallele Apps zu entwickeln und zu verwalten.
2. Leistungsstark
Aufgrund seiner In-Memory-Datenverarbeitungsfähigkeit mit geringer Latenz und der Verfügbarkeit verschiedener integrierter Bibliotheken für maschinelles Lernen und Graphanalysealgorithmen kann es verschiedene Analyseherausforderungen bewältigen. Dies macht es zu einer leistungsstarken Big-Data-Option auf dem Markt.
3. Erweiterte Analysen
Eine weitere Besonderheit von Spark ist, dass es nicht nur „MAP“ und „Reduzieren“ fördert, sondern auch maschinelles Lernen (ML), SQL-Abfragen, Graph-Algorithmen und Streaming-Daten unterstützt. Dies macht es geeignet, um erweiterte Analysen zu genießen.
4. Wiederverwendbarkeit
Im Gegensatz zu Hadoop kann Spark-Code für die Stapelverarbeitung wiederverwendet werden, Ad-hoc-Abfragen zum Stream-Status ausführen, Streams mit historischen Daten verbinden und vieles mehr.
5. Echtzeit-Stream-Verarbeitung
Ein weiterer Vorteil von Apache Spark besteht darin, dass es die Verarbeitung und Verarbeitung von Daten in Echtzeit ermöglicht.
6. Mehrsprachige Unterstützung
Nicht zuletzt unterstützt dieses Big-Data-Analysetool mehrere Programmiersprachen, darunter Java, Python und Scala.
Einschränkungen des Big-Data-Tools von Spark

1. Kein Dateiverwaltungsprozess
Der Hauptnachteil von Apache Spark ist, dass es kein eigenes Dateiverwaltungssystem hat. Es ist auf andere Plattformen wie Hadoop angewiesen, um diese Anforderung zu erfüllen.
2. Wenige Algorithmen
Apache Spark hinkt auch anderen Big-Data-Frameworks hinterher, wenn man die Verfügbarkeit von Algorithmen wie Tanimoto Distance berücksichtigt.
3. Problem mit kleinen Dateien
Ein weiterer Nachteil der Verwendung von Spark besteht darin, dass kleine Dateien nicht effizient verarbeitet werden.
Dies liegt daran, dass es mit dem Hadoop Distributed File System (HDFS) arbeitet, das es einfacher findet, eine begrenzte Anzahl großer Dateien über eine Vielzahl kleiner Dateien zu verwalten.
4. Kein automatischer Optimierungsprozess
Im Gegensatz zu vielen anderen Big-Data- und Cloud-basierten Plattformen verfügt Spark über keinen automatischen Code-Optimierungsprozess. Man muss Code nur manuell optimieren.
5. Nicht geeignet für Umgebungen mit mehreren Benutzern
Da Apache Spark nicht mit mehreren Benutzern gleichzeitig umgehen kann, arbeitet es in einer Mehrbenutzerumgebung nicht effizient. Etwas, das wiederum zu seinen Einschränkungen beiträgt.
Nachdem Sie die Grundlagen beider Big-Data-Frameworks behandelt haben, hoffen Sie wahrscheinlich, sich mit den Unterschieden zwischen Spark und Hadoop vertraut zu machen.
Warten wir also nicht länger und gehen wir zu ihrem Vergleich, um zu sehen, wer den Kampf „Spark vs. Hadoop“ anführt.
Spark vs Hadoop: Wie sich die beiden Big-Data-Tools gegeneinander behaupten
[Tabellen-ID=38 /]
1. Architektur
Wenn es um die Spark- und Hadoop-Architektur geht, ist letztere führend, selbst wenn beide in einer verteilten Computerumgebung arbeiten.
Dies liegt daran, dass die Architektur von Hadoop – im Gegensatz zu Spark – zwei Hauptelemente hat – HDFS (Hadoop Distributed File System) und YARN (Yet Another Resource Negotiator). Hier übernimmt HDFS die Speicherung großer Datenmengen über verschiedene Knoten hinweg, während YARN die Verarbeitungsaufgaben über Ressourcenzuweisungs- und Jobplanungsmechanismen übernimmt. Diese Komponenten werden dann weiter in weitere Komponenten unterteilt, um bessere Lösungen mit Diensten wie Fehlertoleranz bereitzustellen.
2. Benutzerfreundlichkeit
Apache Spark ermöglicht es Entwicklern, verschiedene benutzerfreundliche APIs wie die für Scala, Python, R, Java und Spark SQL in ihre Entwicklungsumgebung einzuführen. Außerdem ist es mit einem interaktiven Modus ausgestattet, der sowohl Benutzer als auch Entwickler unterstützt. Dies macht es einfach zu bedienen und mit geringer Lernkurve.
Wohingegen, wenn es um Hadoop geht, Add-Ons zur Unterstützung der Benutzer angeboten werden, aber kein interaktiver Modus. Dadurch gewinnt Spark in diesem „Big Data“-Kampf über Hadoop.
3. Fehlertoleranz und Sicherheit
Während sowohl Apache Spark als auch Hadoop MapReduce eine Fehlertoleranzfunktion bieten, gewinnt letzteres die Schlacht.
Dies liegt daran, dass man bei Null anfangen muss, falls ein Prozess mitten im Betrieb in der Spark-Umgebung abstürzt. Aber wenn es um Hadoop geht, können sie am Punkt des Absturzes selbst weitermachen.
4. Leistung
Wenn es darum geht, die Leistung von Spark im Vergleich zu MapReduce zu betrachten, gewinnt ersteres über letzteres.
Das Spark-Framework kann auf der Festplatte 10-mal schneller und im Arbeitsspeicher 100-mal schneller ausgeführt werden. Dadurch ist es möglich, 100 TB Daten dreimal schneller zu verwalten als mit Hadoop MapReduce.
5. Datenverarbeitung
Ein weiterer Faktor, der beim Vergleich zwischen Apache Spark und Hadoop zu berücksichtigen ist, ist die Datenverarbeitung.
Während Apache Hadoop nur eine Möglichkeit zur Stapelverarbeitung bietet, ermöglicht das andere Big-Data-Framework das Arbeiten mit interaktiver, iterativer, Stream-, Diagramm- und Stapelverarbeitung. Etwas, das beweist, dass Spark eine bessere Option ist, um bessere Datenverarbeitungsdienste zu genießen.
6. Kompatibilität
Die Kompatibilität von Spark und Hadoop MapReduce ist in etwa gleich.
Obwohl beide Big-Data-Frameworks manchmal als eigenständige Anwendungen fungieren, können sie auch zusammenarbeiten. Spark kann effizient auf Hadoop YARN ausgeführt werden, während Hadoop problemlos in Sqoop und Flume integriert werden kann. Aus diesem Grund unterstützen beide die Datenquellen und Dateiformate des jeweils anderen.
7. Sicherheit
Die Spark-Umgebung ist mit verschiedenen Sicherheitsfunktionen wie Ereignisprotokollierung und Verwendung von Javax-Servlet-Filtern zum Schutz von Web-UIs ausgestattet. Außerdem fördert es die Authentifizierung über Shared Secret und kann das Potenzial von HDFS-Dateiberechtigungen, Verschlüsselung zwischen den Modi und Kerberos nutzen, wenn es in YARN und HDFS integriert ist.
Dagegen unterstützt Hadoop Kerberos -Authentifizierung, Drittanbieter-Authentifizierung, herkömmliche Dateiberechtigungen und Zugriffskontrolllisten und mehr, was letztendlich bessere Sicherheitsergebnisse bietet.
Wenn man also den Vergleich zwischen Spark und Hadoop in Bezug auf die Sicherheit betrachtet, führt letzteres.
8. Wirtschaftlichkeit
Beim Vergleich von Hadoop und Spark benötigt ersteres mehr Speicher auf der Festplatte, während letzteres mehr RAM benötigt. Da Spark im Vergleich zu Apache Hadoop recht neu ist, arbeiten Entwickler seltener mit Spark.
Das macht die Arbeit mit Spark zu einer teuren Angelegenheit. Das heißt, Hadoop bietet kostengünstige Lösungen, wenn man sich auf die Kosten von Hadoop vs. Spark konzentriert.
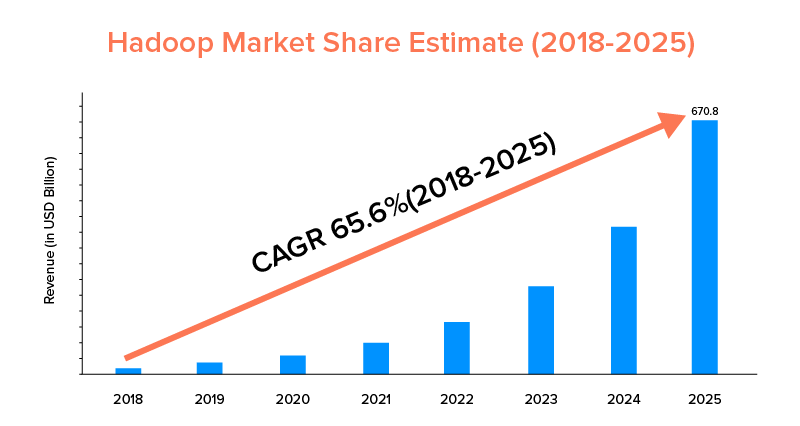
9. Marktumfang
Während sowohl Apache Spark als auch Hadoop von großen Unternehmen unterstützt und für unterschiedliche Zwecke eingesetzt wurden, ist letzteres in Bezug auf den Marktumfang führend.
Laut Marktstatistik wird der Apache Hadoop-Markt im Zeitraum von 2018 bis 2025 voraussichtlich mit einer CAGR von 65,6 % wachsen, verglichen mit Spark mit einer CAGR von nur 33,9 %.
Diese Faktoren helfen zwar bei der Bestimmung des richtigen Big-Data-Tools für Ihr Unternehmen, es lohnt sich jedoch, sich mit deren Anwendungsfällen vertraut zu machen. Lassen Sie uns also hier abdecken.
Anwendungsfälle des Apache Spark Framework
Dieses Big-Data-Tool wird von Unternehmen genutzt, wenn sie Folgendes wünschen:
- Streamen und analysieren Sie Daten in Echtzeit.
- Genießen Sie die Kraft des maschinellen Lernens.
- Arbeiten Sie mit interaktiven Analysen.
- Führen Sie Fog und Edge Computing in ihr Geschäftsmodell ein.
Anwendungsfälle von Apache Hadoop Framework
Hadoop wird von Startups und Unternehmen bevorzugt, wenn sie:-
- Archivdaten analysieren.
- Profitieren Sie von besseren Finanzhandels- und Prognoseoptionen.
- Ausführen von Operationen, die Commodity-Hardware umfassen.
- Betrachten Sie die lineare Datenverarbeitung.
Damit hoffen wir, dass Sie sich entschieden haben, wer in Bezug auf Ihr Unternehmen der Gewinner des Kampfes „Spark vs. Hadoop“ ist. Wenn nicht, können Sie sich gerne mit unseren Big Data-Experten in Verbindung setzen, um alle Zweifel auszuräumen und vorbildliche Dienstleistungen mit einer höheren Erfolgsquote zu erhalten.
HÄUFIG GESTELLTE FRAGEN
1. Welches Big-Data-Framework wählen?
Die Wahl hängt ganz von Ihren geschäftlichen Anforderungen ab. Wenn Sie sich auf Leistung, Datenkompatibilität und Benutzerfreundlichkeit konzentrieren, ist Spark besser als Hadoop. Dagegen ist das Hadoop-Big-Data-Framework besser, wenn Sie sich auf Architektur, Sicherheit und Kosteneffizienz konzentrieren.
2. Was ist der Unterschied zwischen Hadoop und Spark?
Es gibt verschiedene Unterschiede zwischen Spark und Hadoop. Beispielsweise:-
- Spark ist 100-mal so groß wie Hadoop MapReduce.
- Während Hadoop für die Batch-Verarbeitung eingesetzt wird, ist Spark für Batch-, Graphen-, maschinelles Lernen und iterative Verarbeitung gedacht.
- Spark ist kompakt und einfacher als das Big-Data-Framework Hadoop.
- Im Gegensatz zu Spark unterstützt Hadoop kein Caching von Daten.
3. Ist Spark besser als Hadoop?
Spark ist besser als Hadoop, wenn Ihr Hauptaugenmerk auf Geschwindigkeit und Sicherheit liegt. In anderen Fällen bleibt dieses Big-Data-Analysetool jedoch hinter Apache Hadoop zurück.
4. Warum ist Spark schneller als Hadoop?
Spark ist aufgrund der geringeren Anzahl von Lese-/Schreibzyklen auf der Festplatte und der Speicherung von Zwischendaten im Arbeitsspeicher schneller als Hadoop.
5. Wofür wird Apache Spark verwendet?
Apache Spark wird zur Datenanalyse verwendet, wenn man
- Analysieren Sie Daten in Echtzeit.
- Führen Sie ML und Fog Computing in Ihr Geschäftsmodell ein.
- Arbeiten Sie mit Interactive Analytics.