
TW-BERT: End-to-End-Gewichtung von Suchbegriffen und die Zukunft der Google-Suche
Veröffentlicht: 2023-09-14Die Suche ist schwierig, wie Seth Godin 2005 schrieb.
Ich meine, wenn wir glauben, dass SEO schwierig ist (und das ist es auch), stellen Sie sich vor, Sie würden versuchen, eine Suchmaschine in einer Welt zu entwickeln, in der:
- Die Benutzer variieren stark und ändern ihre Vorlieben im Laufe der Zeit.
- Die Technologie, auf die sie bei der Suche zugreifen, entwickelt sich jeden Tag weiter.
- Die Konkurrenz ist Ihnen ständig auf den Fersen.
Darüber hinaus haben Sie es auch mit lästigen SEOs zu tun, die versuchen, Ihren Algorithmus auszutricksen, um Erkenntnisse darüber zu gewinnen, wie Sie Ihre Website am besten für Ihre Besucher optimieren können.
Das wird es viel schwieriger machen.
Stellen Sie sich nun vor, dass die wichtigsten Technologien, auf die Sie sich stützen müssen, um voranzukommen, ihre eigenen Einschränkungen hätten – und, vielleicht noch schlimmer, enorme Kosten hätten.
Nun, wenn Sie einer der Autoren des kürzlich veröffentlichten Artikels „End-to-End Query Term Weighting“ sind, sehen Sie darin eine Chance, zu glänzen.
Was ist End-to-End-Abfragebegriffsgewichtung?
End-to-End-Abfragebegriffsgewichtung bezieht sich auf eine Methode, bei der die Gewichtung jedes Begriffs in einer Abfrage als Teil des Gesamtmodells bestimmt wird, ohne dass man sich auf manuell programmierte oder herkömmliche Begriffsgewichtungsschemata oder andere unabhängige Modelle verlassen muss.
Wie sieht das aus?
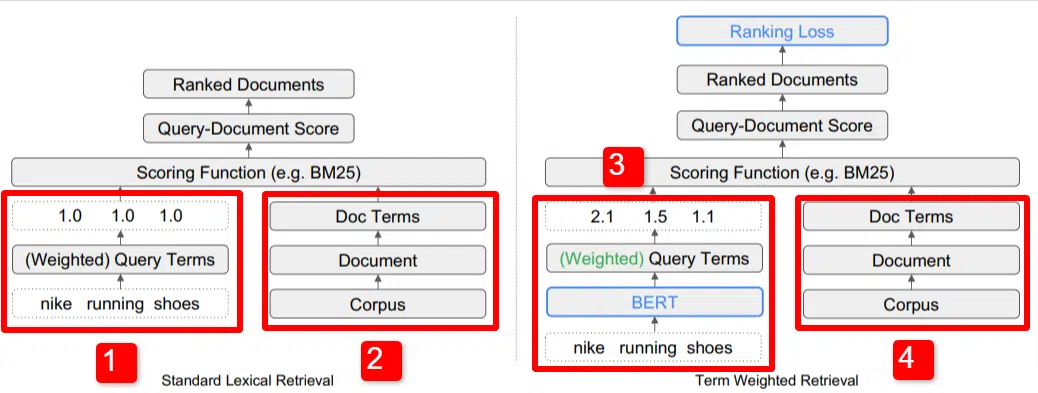
Hier sehen wir eine Darstellung eines der wichtigsten Unterscheidungsmerkmale des im Artikel beschriebenen Modells (insbesondere Abbildung 1).
Auf der rechten Seite des Standardmodells (2) sehen wir dasselbe wie beim vorgeschlagenen Modell (4), nämlich dem Korpus (vollständiger Satz von Dokumenten im Index), der zu den Dokumenten führt und zu den Begriffen führt.
Dies veranschaulicht die tatsächliche Hierarchie im System, aber Sie können es sich auch umgekehrt, von oben nach unten, vorstellen. Wir haben Bedingungen. Wir suchen nach Dokumenten mit diesen Begriffen. Diese Dokumente gehören zum Korpus aller uns bekannten Dokumente.
Unten links (1) in der Standard-IR-Architektur (Information Retrieval) werden Sie feststellen, dass es keine BERT-Schicht gibt. Die in ihrer Abbildung verwendete Abfrage (Nike Laufschuhe) gelangt in das System und die Gewichte werden unabhängig vom Modell berechnet und an dieses übergeben.
In der Abbildung hier werden die Gewichtungen gleichmäßig auf die drei Wörter in der Abfrage übertragen. Das muss jedoch nicht so sein. Es ist einfach eine Standardvorgabe und eine gute Illustration.
Wichtig zu verstehen ist, dass die Gewichte von außerhalb des Modells zugewiesen und mit der Abfrage eingegeben werden. Wir werden erläutern, warum dies im Moment wichtig ist.
Wenn wir uns die Termgewichtungsversion auf der rechten Seite ansehen, sehen Sie, dass die Abfrage „Nike Laufschuhe“ BERT (Term Weighting BERT oder TW-BERT, um genau zu sein) eingibt, das zur Zuweisung der Gewichtungen verwendet wird würde am besten auf diese Abfrage angewendet werden.
Von da an verläuft der Weg für beide ähnlich: Es wird eine Bewertungsfunktion angewendet und die Dokumente werden in eine Rangfolge gebracht. Aber es gibt noch einen entscheidenden letzten Schritt beim neuen Modell, nämlich den eigentlichen Sinn des Ganzen: die Berechnung des Ranking-Verlusts.
Diese Berechnung, auf die ich mich oben bezog, macht die Gewichtungen, die im Modell ermittelt werden, so wichtig. Um dies am besten zu verstehen, werfen wir einen kurzen Blick auf die Verlustfunktionen. Dies ist wichtig, um wirklich zu verstehen, was hier vor sich geht.
Was ist eine Verlustfunktion?
Beim maschinellen Lernen ist eine Verlustfunktion im Grunde eine Berechnung, wie falsch ein System liegt, wobei das System versucht, zu lernen, so nahe wie möglich an einen Nullverlust heranzukommen.
Nehmen wir als Beispiel ein Modell zur Ermittlung von Immobilienpreisen. Wenn Sie alle Statistiken zu Ihrem Haus eingegeben haben und ein Wert von 250.000 US-Dollar ermittelt wurde, Ihr Haus aber für 260.000 US-Dollar verkauft wurde, würde die Differenz als Verlust betrachtet (was ein absoluter Wert ist).
Anhand zahlreicher Beispiele wird dem Modell beigebracht, den Verlust zu minimieren, indem den vorgegebenen Parametern unterschiedliche Gewichtungen zugewiesen werden, bis das beste Ergebnis erzielt wird. Ein Parameter kann in diesem Fall Dinge wie Quadratmeter, Schlafzimmer, Gartengröße, Nähe zu einer Schule usw. umfassen.
Nun zurück zur Gewichtung des Abfragebegriffs
Wenn wir auf die beiden obigen Beispiele zurückblicken, müssen wir uns auf das Vorhandensein eines BERT-Modells konzentrieren, um die Gewichtung der Begriffe im Down-Funnel der Ranking-Verlustberechnung bereitzustellen.

Anders ausgedrückt: In den traditionellen Modellen erfolgte die Gewichtung der Terme unabhängig vom Modell selbst und konnte daher nicht auf die Leistung des Gesamtmodells reagieren. Es konnte nicht gelernt werden, die Gewichtungen zu verbessern.
Im vorgeschlagenen System ändert sich dies. Die Gewichtung erfolgt innerhalb des Modells selbst. Da das Modell also seine Leistung verbessern und die Verlustfunktion reduzieren möchte, verfügt es über diese zusätzlichen Regler, um die Termgewichtung in die Gleichung einzubeziehen. Buchstäblich.
ngrams
TW-BERT ist nicht darauf ausgelegt, mit Wörtern zu arbeiten, sondern eher mit Ngrammen.
Die Autoren des Papiers veranschaulichen gut, warum sie Ngrams anstelle von Wörtern verwenden, indem sie darauf hinweisen, dass in der Suchanfrage „Nike Running Shoes“ eine Seite mit Erwähnungen der Wörter „Nike“, „Running“ und „Schuhe“, wenn man einfach die Wörter gewichtet, sogar ein gutes Ranking erzielen könnte wenn es um „Nike Laufsocken“ und „Skateschuhe“ geht.
Herkömmliche IR-Methoden verwenden Abfragestatistiken und Dokumentstatistiken und können Seiten mit diesem oder ähnlichen Problemen anzeigen. Frühere Versuche, dieses Problem anzugehen, konzentrierten sich auf das gemeinsame Vorkommen und die Reihenfolge.
In diesem Modell werden die ngrams genauso gewichtet wie die Wörter in unserem vorherigen Beispiel, sodass wir am Ende etwa Folgendes erhalten:
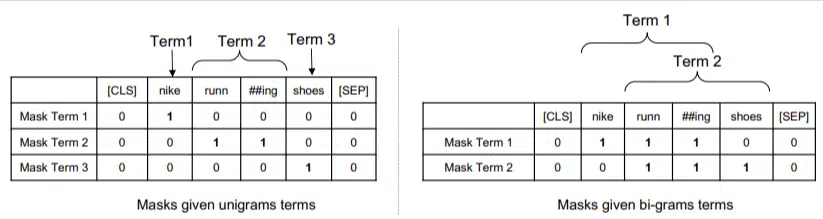
Auf der linken Seite sehen wir, wie die Abfrage als Unigramme (1-Wort-Ngramme) und rechts als Bigramme (2-Wort-Ngramme) gewichtet würde.
Da die Gewichtung in das System integriert ist, kann es alle Permutationen trainieren, um die besten Ngramme und auch die entsprechende Gewichtung für jedes zu ermitteln, anstatt sich nur auf Statistiken wie die Häufigkeit zu verlassen.
Null Schuss
Ein wichtiges Merkmal dieses Modells ist seine Leistung bei Zero-Short-Aufgaben. Die Autoren haben Folgendes getestet:
- MS MARCO-Datensatz – Microsoft-Datensatz für das Ranking von Dokumenten und Passagen
- TREC-COVID-Datensatz – COVID-Artikel und Studien
- Robust04 – Nachrichtenartikel
- Common Core – Bildungsartikel und Blogbeiträge
Sie verfügten nur über eine kleine Anzahl von Auswertungsabfragen und verwendeten keine für die Feinabstimmung, was diesen Test insofern zu einem Zero-Shot-Test machte, als das Modell nicht speziell darauf trainiert war, Dokumente in diesen Domänen einzuordnen. Die Ergebnisse waren:
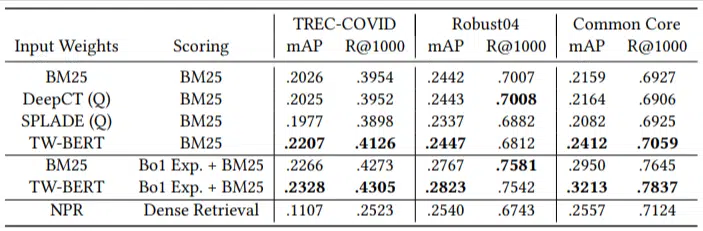
Es schnitt bei den meisten Aufgaben besser ab und schnitt bei kürzeren Abfragen (1 bis 10 Wörter) am besten ab.
Und es ist Plug-and-Play!
OK, das ist vielleicht zu stark vereinfacht, aber die Autoren schreiben:
„Durch die Abstimmung von TW-BERT mit Suchmaschinen-Scorern werden die Änderungen minimiert, die für die Integration in bestehende Produktionsanwendungen erforderlich sind , wohingegen bestehende Deep-Learning-basierte Suchmethoden eine weitere Optimierung der Infrastruktur und Hardwareanforderungen erfordern würden. Die erlernten Gewichte können problemlos von standardmäßigen lexikalischen Retrievern und anderen Retrieval-Techniken wie der Abfrageerweiterung genutzt werden.“
Da TW-BERT für die Integration in das aktuelle System konzipiert ist, ist die Integration weitaus einfacher und kostengünstiger als bei anderen Optionen.
Was das alles für Sie bedeutet
Bei Modellen für maschinelles Lernen ist es beispielsweise schwierig vorherzusagen, was Sie als SEO dagegen tun können (abgesehen von sichtbaren Bereitstellungen wie Bard oder ChatGPT).
Aufgrund seiner Verbesserungen und der einfachen Implementierung (vorausgesetzt, die Aussagen sind korrekt) wird zweifellos eine Abwandlung dieses Modells zum Einsatz kommen.
Allerdings handelt es sich dabei um eine Verbesserung der Lebensqualität bei Google, die bei geringen Kosten zu besseren Rankings und Zero-Shot-Ergebnissen führt.
Wir können uns nur darauf verlassen, dass bei der Umsetzung zuverlässiger bessere Ergebnisse erzielt werden. Und das sind gute Nachrichten für SEO-Profis.
Die in diesem Artikel geäußerten Meinungen sind die des Gastautors und nicht unbedingt die von Search Engine Land. Die Autoren unserer Mitarbeiter sind hier aufgelistet.