
Was ist generative KI und wie funktioniert sie?
Veröffentlicht: 2023-09-26Generative KI, eine Teilmenge der künstlichen Intelligenz, hat sich zu einer revolutionären Kraft in der Technologiewelt entwickelt. Aber was genau ist das? Und warum erregt es so viel Aufmerksamkeit?
In diesem ausführlichen Leitfaden erfahren Sie, wie generative KI-Modelle funktionieren, was sie können und was nicht und welche Auswirkungen all diese Elemente haben.
Was ist generative KI?
Generative KI oder genAI bezeichnet Systeme, die neue Inhalte generieren können, seien es Texte, Bilder, Musik oder sogar Videos. Traditionell bedeutete KI/ML drei Dinge: überwachtes, unüberwachtes und verstärkendes Lernen. Jedes liefert Erkenntnisse basierend auf der Clustering-Ausgabe.
Nicht generative KI-Modelle führen Berechnungen auf der Grundlage von Eingaben durch (z. B. die Klassifizierung eines Bildes oder die Übersetzung eines Satzes). Im Gegensatz dazu erzeugen generative Modelle „neue“ Ergebnisse wie das Schreiben von Essays, das Komponieren von Musik, das Entwerfen von Grafiken und sogar das Erstellen realistischer menschlicher Gesichter, die es in der realen Welt nicht gibt.
Die Auswirkungen generativer KI
Der Aufstieg der generativen KI hat erhebliche Auswirkungen. Mit der Fähigkeit, Inhalte zu generieren, erleben Branchen wie Unterhaltung, Design und Journalismus einen Paradigmenwechsel.
Beispielsweise können Nachrichtenagenturen mithilfe von KI Berichte verfassen, während Designer KI-gestützte Vorschläge für Grafiken erhalten können. KI kann in Sekundenschnelle Hunderte von Werbeslogans generieren – unabhängig davon, ob diese Optionen gut sind oder nicht oder nicht, ist eine andere Sache.
Generative KI kann maßgeschneiderte Inhalte für einzelne Benutzer erstellen. Stellen Sie sich beispielsweise eine Musik-App vor, die je nach Stimmung ein einzigartiges Lied komponiert, oder eine Nachrichten-App, die Artikel zu Themen verfasst, die Sie interessieren.
Das Problem besteht darin, dass die Frage nach Authentizität, Urheberrecht und dem Wert menschlicher Kreativität immer häufiger wird, da KI eine immer wichtigere Rolle bei der Erstellung von Inhalten spielt.
Wie funktioniert generative KI?
Bei der generativen KI geht es im Kern darum, das nächste Datenelement in einer Sequenz vorherzusagen, sei es das nächste Wort in einem Satz oder das nächste Pixel in einem Bild. Lassen Sie uns aufschlüsseln, wie dies erreicht wird.
Statistische Modelle
Statistische Modelle sind das Rückgrat der meisten KI-Systeme. Sie verwenden mathematische Gleichungen, um die Beziehung zwischen verschiedenen Variablen darzustellen.
Bei der generativen KI werden Modelle darauf trainiert, Muster in Daten zu erkennen und diese Muster dann zur Generierung zu verwenden neue, ähnliche Daten.
Wenn ein Modell auf englische Sätze trainiert wird, lernt es die statistische Wahrscheinlichkeit, dass ein Wort auf das andere folgt, und kann so kohärente Sätze generieren.
Datenerfassung
Sowohl die Qualität als auch die Quantität der Daten sind entscheidend. Generative Modelle werden anhand umfangreicher Datensätze trainiert, um Muster zu verstehen.
Für ein Sprachmodell könnte dies bedeuten, dass Milliarden von Wörtern aus Büchern, Websites und anderen Texten übernommen werden müssen.
Für ein Bildmodell könnte dies bedeuten, Millionen von Bildern zu analysieren. Je vielfältiger und umfassender die Trainingsdaten sind, desto besser wird das Modell vielfältige Ergebnisse generieren.
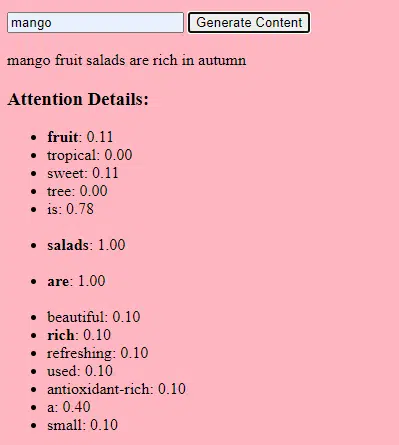
Wie Transformatoren und Aufmerksamkeit funktionieren
Transformatoren sind eine Art neuronaler Netzwerkarchitektur, die 2017 in einem Artikel mit dem Titel „Attention Is All You Need“ von Vaswani et al. vorgestellt wurde. Seitdem sind sie die Grundlage für die meisten hochmodernen Sprachmodelle. ChatGPT würde ohne Transformer nicht funktionieren.
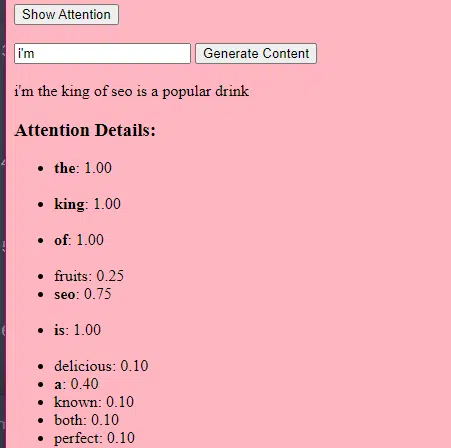
Der „Aufmerksamkeits“-Mechanismus ermöglicht es dem Modell, sich auf verschiedene Teile der Eingabedaten zu konzentrieren, ähnlich wie Menschen beim Verstehen eines Satzes auf bestimmte Wörter achten.
Durch diesen Mechanismus kann das Modell entscheiden, welche Teile der Eingabe für eine bestimmte Aufgabe relevant sind, wodurch es äußerst flexibel und leistungsstark wird.
Der folgende Code ist eine grundlegende Aufschlüsselung der Transformatormechanismen und erklärt jeden Teil in einfachem Englisch.
class Transformer: # Convert words to vectors # What this is : turns words into "vector embeddings" –basically numbers that represent the words and their relationships to each other. # Demo : "the pineapple is cool and tasty" -> [0.2, 0.5, 0.3, 0.8, 0.1, 0.9] self.embedding = Embedding(vocab_size, d_model) # Add position information to the vectors # What this is : Since words in a sentence have a specific order, we add information about each word's position in the sentence. # Demo : "the pineapple is cool and tasty" with position -> [0.2+0.01, 0.5+0.02, 0.3+0.03, 0.8+0.04, 0.1+0.05, 0.9+0.06] self.positional_encoding = PositionalEncoding(d_model) # Stack of transformer layers # What this is : Multiple layers of the Transformer model stacked on top of each other to process data in depth. # Why it does it : Each layer captures different patterns and relationships in the data. # Explained like I'm five : Imagine a multi-story building. Each floor (or layer) has people (or mechanisms) doing specific jobs. The more floors, the more jobs get done! self.transformer_layers = [TransformerLayer(d_model, nhead) for _ in range(num_layers)] # Convert the output vectors to word probabilities # What this is : A way to predict the next word in a sequence. # Why it does it : After processing the input, we want to guess what word comes next. # Explained like I'm five : After listening to a story, this tries to guess what happens next. self.output_layer = Linear(d_model, vocab_size) def forward(self, x): # Convert words to vectors, as above x = self.embedding(x) # Add position information, as above x = self.positional_encoding(x) # Pass through each transformer layer # What this is : Sending our data through each floor of our multi-story building. # Why it does it : To deeply process and understand the data. # Explained like I'm five : It's like passing a note in class. Each person (or layer) adds something to the note before passing it on, which can end up with a coherent story – or a mess. for layer in self.transformer_layers: x = layer(x) # Get the output word probabilities # What this is : Our best guess for the next word in the sequence. return self.output_layer(x)Im Code verfügen Sie möglicherweise über eine Transformer-Klasse und eine einzelne TransformerLayer-Klasse. Das ist so, als hätte man einen Bauplan für ein Stockwerk oder für ein ganzes Gebäude.
Dieser TransformerLayer-Code zeigt Ihnen, wie bestimmte Komponenten, wie z. B. Multi-Head-Aufmerksamkeit und spezifische Anordnungen, funktionieren.
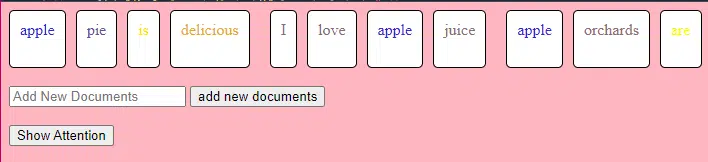
class TransformerLayer: # Multi-head attention mechanism # What this is : A mechanism that lets the model focus on different parts of the input data simultaneously. # Demo : "the pineapple is cool and tasty" might become "this PINEAPPLE is COOL and TASTY" as the model pays more attention to certain words. self.attention = MultiHeadAttention(d_model, nhead) # Simple feed-forward neural network # What this is : A basic neural network that processes the data after the attention mechanism. # Demo : "this PINEAPPLE is COOL and TASTY" -> [0.25, 0.55, 0.35, 0.85, 0.15, 0.95] (slight changes in numbers after processing) self.feed_forward = FeedForward(d_model) def forward(self, x): # Apply attention mechanism # What this is : The step where we focus on different parts of the sentence. # Explained like I'm five : It's like highlighting important parts of a book. attention_output = self.attention(x, x, x) # Pass the output through the feed-forward network # What this is : The step where we process the highlighted information. return self.feed_forward(attention_output)Ein vorwärtsgerichtetes neuronales Netzwerk ist eine der einfachsten Arten künstlicher neuronaler Netzwerke. Es besteht aus einer Eingabeebene, einer oder mehreren verborgenen Ebenen und einer Ausgabeebene.
Die Daten fließen in eine Richtung – von der Eingabeschicht über die verborgenen Schichten bis zur Ausgabeschicht. Es gibt keine Schleifen oder Zyklen im Netzwerk.
Im Kontext der Transformatorarchitektur wird das Feed-Forward-Neuronale Netzwerk nach dem Aufmerksamkeitsmechanismus in jeder Schicht verwendet. Es handelt sich um eine einfache zweischichtige lineare Transformation mit einer ReLU-Aktivierung dazwischen.
# Scaled dot-product attention mechanism class ScaledDotProductAttention: def __init__(self, d_model): # Scaling factor helps in stabilizing the gradients # it reduces the variance of the dot product. # What this is: A scaling factor based on the size of our model's embeddings. # What it does : Helps to make sure the dot products don't get too big. # Why it does it : Big dot products can make a model unstable and harder to train. # How it does it : By dividing the dot products by the square root of the embedding size. # It's used when calculating attention scores. # Explained like I'm five : Imagine you shouted something really loud. This scaling factor is like turning the volume down so it's not too loud. self.scaling_factor = d_model ** 0.5 def forward(self, query, key, value): # What this is : The function that calculates how much attention each word should get. # What it does : Determines how relevant each word in a sentence is to every other word. # Why it does it : So we can focus more on important words when trying to understand a sentence. # How it does it : By taking the dot product (the numeric product: a way to measure similarity) of the query and key, then scaling it, and finally using that to weigh our values. # How it fits into the rest of the code : This function is called whenever we want to calculate attention in our model. # Explained like I'm five : Imagine you have a toy and you want to see which of your friends likes it the most. This function is like asking each friend how much they like the toy, and then deciding who gets to play with it based on their answers. # Calculate attention scores by taking the dot product of the query and key. scores = dot_product(query, key) / self.scaling_factor # Convert the raw scores to probabilities using the softmax function. attention_weights = softmax(scores) # Weight the values using the attention probabilities. return dot_product(attention_weights, value) # Feed-forward neural network # This is an extremely basic example of a neural network. class FeedForward: def __init__(self, d_model): # First linear layer increases the dimensionality of the data. self.layer1 = Linear(d_model, d_model * 4) # Second linear layer brings the dimensionality back to d_model. self.layer2 = Linear(d_model * 4, d_model) def forward(self, x): # Pass the input through the first layer, #Pass the input through the first layer: # Input : This refers to the data you feed into the neural network. I # First layer : Neural networks consist of layers, and each layer has neurons. When we say "pass the input through the first layer," we mean that the input data is being processed by the neurons in this layer. Each neuron takes the input, multiplies it by its weights (which are learned during training), and produces an output. # apply ReLU activation to introduce non-linearity, # and then pass through the second layer. #ReLU activation: ReLU stands for Rectified Linear Unit. # It's a type of activation function, which is a mathematical function applied to the output of each neuron. In simpler terms, if the input is positive, it returns the input value; if the input is negative or zero, it returns zero. # Neural networks can model complex relationships in data by introducing non-linearities. # Without non-linear activation functions, no matter how many layers you stack in a neural network, it would behave just like a single-layer perceptron because summing these layers would give you another linear model. # Non-linearities allow the network to capture complex patterns and make better predictions. return self.layer2(relu(self.layer1(x))) # Positional encoding adds information about the position of each word in the sequence. class PositionalEncoding: def __init__(self, d_model): # What this is : A setup to add information about where each word is in a sentence. # What it does : Prepares to add a unique "position" value to each word. # Why it does it : Words in a sentence have an order, and this helps the model remember that order. # How it does it : By creating a special pattern of numbers for each position in a sentence. # How it fits into the rest of the code : Before processing words, we add their position info. # Explained like I'm five : Imagine you're in a line with your friends. This gives everyone a number to remember their place in line. pass def forward(self, x): # What this is : The main function that adds position info to our words. # What it does : Combines the word's original value with its position value. # Why it does it : So the model knows the order of words in a sentence. # How it does it : By adding the position values we prepared earlier to the word values. # How it fits into the rest of the code : This function is called whenever we want to add position info to our words. # Explained like I'm five : It's like giving each of your toys a tag that says if it's the 1st, 2nd, 3rd toy, and so on. return x # Helper functions def dot_product(a, b): # Calculate the dot product of two matrices. # What this is : A mathematical operation to see how similar two lists of numbers are. # What it does : Multiplies matching items in the lists and then adds them up. # Why it does it : To measure similarity or relevance between two sets of data. # How it does it : By multiplying and summing up. # How it fits into the rest of the code : Used in attention to see how relevant words are to each other. # Explained like I'm five : Imagine you and your friend have bags of candies. You both pour them out and match each candy type. Then, you count how many matching pairs you have. return a @ b.transpose(-2, -1) def softmax(x): # Convert raw scores to probabilities ensuring they sum up to 1. # What this is : A way to turn any list of numbers into probabilities. # What it does : Makes the numbers between 0 and 1 and ensures they all add up to 1. # Why it does it : So we can understand the numbers as chances or probabilities. # How it does it : By using exponentiation and division. # How it fits into the rest of the code : Used to convert attention scores into probabilities. # Explained like I'm five : Lets go back to our toys. This makes sure that when you share them, everyone gets a fair share, and no toy is left behind. return exp(x) / sum(exp(x), axis=-1) def relu(x): # Activation function that introduces non-linearity. It sets negative values to 0. # What this is : A simple rule for numbers. # What it does : If a number is negative, it changes it to zero. Otherwise, it leaves it as it is. # Why it does it : To introduce some simplicity and non-linearity in our model's calculations. # How it does it : By checking each number and setting it to zero if it's negative. # How it fits into the rest of the code : Used in neural networks to make them more powerful and flexible. # Explained like I'm five : Imagine you have some stickers, some are shiny (positive numbers) and some are dull (negative numbers). This rule says to replace all dull stickers with blank ones. return max(0, x)Wie generative KI funktioniert – in einfachen Worten
Stellen Sie sich generative KI wie einen gewichteten Würfel vor. Die Trainingsdaten bestimmen die Gewichte (oder Wahrscheinlichkeiten).
Wenn der Würfel das nächste Wort in einem Satz darstellt, hat ein Wort, das in den Trainingsdaten häufig auf das aktuelle Wort folgt, ein höheres Gewicht. „Himmel“ folgt also möglicherweise häufiger auf „Blau“ als auf „Banane“. Wenn die KI „würfelt“, um Inhalte zu generieren, ist es wahrscheinlicher, dass sie basierend auf ihrem Training statistisch wahrscheinlichere Sequenzen auswählt.
Wie können LLMs also Inhalte generieren, die originell „erscheinen“?
Nehmen wir eine gefälschte Liste – die „besten Eid al-Fitr-Geschenke für Content-Vermarkter“ – und gehen wir durch, wie ein LLM etwas generieren kann Erstellen Sie diese Liste, indem Sie Texthinweise aus Dokumenten über Geschenke, Eid und Content-Vermarkter kombinieren.
Vor der Verarbeitung wird der Text in kleinere Teile, sogenannte „Tokens“, zerlegt. Diese Token können nur ein Zeichen oder ein Wort lang sein.
Beispiel: „Eid al-Fitr ist eine Feier“ wird zu [„Eid“, „al-Fitr“, „ist“, „eine“, „Feier“].
Dadurch kann das Modell mit überschaubaren Textblöcken arbeiten und die Struktur von Sätzen verstehen.
Jeder Token wird dann mithilfe von Einbettungen in einen Vektor (eine Liste von Zahlen) umgewandelt. Diese Vektoren erfassen die Bedeutung und den Kontext jedes Wortes.
Die Positionskodierung fügt jedem Wortvektor Informationen über seine Position im Satz hinzu und stellt so sicher, dass das Modell diese Reihenfolgeinformationen nicht verliert.
Dann verwenden wir einen Aufmerksamkeitsmechanismus : Dadurch kann sich das Modell beim Generieren einer Ausgabe auf verschiedene Teile des Eingabetextes konzentrieren. Wenn Sie sich an BERT erinnern, ist das das, was die Google-Mitarbeiter an BERT so begeistert hat.
Wenn unser Modell Texte über „ Geschenke “ gesehen hat und weiß, dass Menschen bei Feierlichkeiten Geschenke machen, und es auch Texte darüber gesehen hat, dass „ Eid al-Fitr “ ein bedeutendes Fest ist, wird es diesen Zusammenhängen „ Aufmerksamkeit “ schenken.
Ebenso kann es, wenn es Texte über „ Content-Vermarkter “ gesehen hat, die bestimmte Tools oder Ressourcen benötigen, die Idee von „ Geschenken “ mit „Content- Vermarktern “ in Verbindung bringen.

Jetzt können wir Kontexte kombinieren: Während das Modell den Eingabetext über mehrere Transformer-Ebenen verarbeitet, kombiniert es die gelernten Kontexte.
Auch wenn in den Originaltexten „Eid al-Fitr-Geschenke für Content-Vermarkter“ nie erwähnt wurden, kann das Modell die Konzepte „Eid al-Fitr“, „Geschenke“ und „Content-Vermarkter“ zusammenführen, um diesen Inhalt zu generieren.
Dies liegt daran, dass es die umfassenderen Zusammenhänge rund um jeden dieser Begriffe kennengelernt hat.
Nach der Verarbeitung der Eingabe durch den Aufmerksamkeitsmechanismus und die Feed-Forward-Netzwerke in jeder Transformer-Schicht erzeugt das Modell eine Wahrscheinlichkeitsverteilung über seinen Wortschatz für das nächste Wort in der Sequenz.
Man könnte denken, dass nach Wörtern wie „am besten“ und „Eid al-Fitr“ mit hoher Wahrscheinlichkeit das Wort „Geschenke“ als nächstes kommt. Ebenso könnten „Geschenke“ mit potenziellen Empfängern wie „Content-Vermarktern“ in Verbindung gebracht werden.
Erhalten Sie den täglichen Newsletter, auf den sich Suchmaschinenmarketing verlassen.
Siehe Bedingungen.
Wie große Sprachmodelle erstellt werden
Der Weg von einem einfachen Transformatormodell zu einem anspruchsvollen Large Language Model (LLM) wie GPT-3 oder BERT erfordert die Skalierung und Verfeinerung verschiedener Komponenten.
Hier ist eine Schritt-für-Schritt-Aufschlüsselung:
LLMs werden auf riesigen Textdatenmengen trainiert. Es ist schwer zu erklären, wie umfangreich diese Daten sind.
Der C4-Datensatz, ein Ausgangspunkt für viele LLMs, umfasst 750 GB Textdaten. Das sind 805.306.368.000 Bytes – eine Menge Informationen. Zu diesen Daten können Bücher, Artikel, Websites, Foren, Kommentarbereiche und andere Quellen gehören.
Je vielfältiger und umfassender die Daten sind, desto besser sind die Verständnis- und Generalisierungsfähigkeiten des Modells.
Während die grundlegende Transformatorarchitektur die Grundlage bleibt, verfügen LLMs über eine deutlich größere Anzahl von Parametern. GPT-3 hat beispielsweise 175 Milliarden Parameter. In diesem Fall beziehen sich Parameter auf die Gewichte und Bias im neuronalen Netzwerk, die während des Trainingsprozesses gelernt werden.
Beim Deep Learning wird ein Modell darauf trainiert, Vorhersagen zu treffen, indem diese Parameter angepasst werden, um den Unterschied zwischen seinen Vorhersagen und den tatsächlichen Ergebnissen zu verringern.
Der Prozess der Anpassung dieser Parameter wird als Optimierung bezeichnet und verwendet Algorithmen wie den Gradientenabstieg.

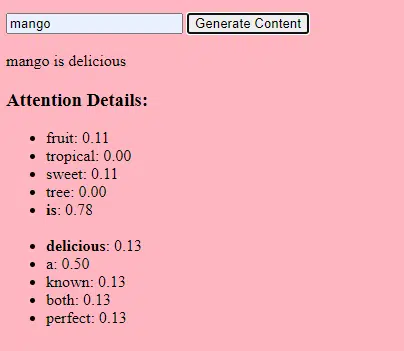
- Gewichte: Dies sind Werte im neuronalen Netzwerk, die Eingabedaten innerhalb der Netzwerkschichten transformieren. Sie werden während des Trainings angepasst, um die Ausgabe des Modells zu optimieren. Jede Verbindung zwischen Neuronen in benachbarten Schichten hat ein zugehöriges Gewicht.
- Biases: Hierbei handelt es sich ebenfalls um Werte im neuronalen Netzwerk, die zur Ausgabe der Transformation einer Ebene hinzugefügt werden. Sie verleihen dem Modell einen zusätzlichen Freiheitsgrad, sodass es besser an die Trainingsdaten angepasst werden kann. Jedem Neuron in einer Schicht ist eine Vorspannung zugeordnet.
Durch diese Skalierung kann das Modell komplexere Muster und Beziehungen in den Daten speichern und verarbeiten.
Die große Anzahl an Parametern bedeutet auch, dass das Modell erhebliche Rechenleistung und Speicher für Training und Inferenz benötigt. Aus diesem Grund ist das Training solcher Modelle ressourcenintensiv und verwendet typischerweise spezielle Hardware wie GPUs oder TPUs.
Das Modell ist darauf trainiert, mithilfe leistungsstarker Rechenressourcen das nächste Wort in einer Sequenz vorherzusagen. Es passt seine internen Parameter basierend auf den Fehlern an, die es macht, und verbessert so kontinuierlich seine Vorhersagen.
Aufmerksamkeitsmechanismen wie die, die wir besprochen haben, sind für LLMs von entscheidender Bedeutung. Sie ermöglichen es dem Modell, sich bei der Generierung der Ausgabe auf verschiedene Teile der Eingabe zu konzentrieren.
Durch die Abwägung der Bedeutung verschiedener Wörter in einem Kontext ermöglichen Aufmerksamkeitsmechanismen dem Modell, kohärenten und kontextrelevanten Text zu generieren. Wenn wir dies in diesem riesigen Umfang tun, können die LLMs so arbeiten, wie sie es tun.
Wie sagt ein Transformator Text voraus?
Transformatoren sagen Text voraus, indem sie Eingabetoken über mehrere Schichten verarbeiten, die jeweils mit Aufmerksamkeitsmechanismen und Feed-Forward-Netzwerken ausgestattet sind.
Nach der Verarbeitung erstellt das Modell eine Wahrscheinlichkeitsverteilung über seinen Wortschatz für das nächste Wort in der Sequenz. Typischerweise wird das Wort mit der höchsten Wahrscheinlichkeit als Vorhersage ausgewählt.
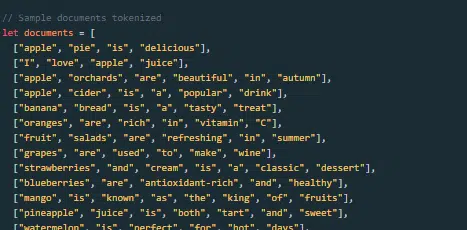
Wie wird ein großes Sprachmodell aufgebaut und trainiert?
Der Aufbau eines LLM umfasst das Sammeln von Daten, deren Bereinigung, das Trainieren des Modells, die Feinabstimmung des Modells und intensive, kontinuierliche Tests.
Das Modell wird zunächst auf einem riesigen Korpus trainiert, um das nächste Wort in einer Sequenz vorherzusagen. In dieser Phase kann das Modell Verbindungen zwischen Wörtern lernen, die Muster in der Grammatik aufgreifen, Beziehungen, die Fakten über die Welt darstellen können, und Verbindungen, die sich wie logisches Denken anfühlen. Diese Verbindungen führen auch dazu, dass in den Trainingsdaten vorhandene Verzerrungen erkannt werden.
Nach dem Vortraining wird das Modell anhand eines engeren Datensatzes verfeinert, häufig unter Befolgung menschlicher Prüfer anhand von Richtlinien.
Die Feinabstimmung ist ein entscheidender Schritt beim Aufbau von LLMs. Dabei wird das vorab trainierte Modell anhand eines spezifischeren Datensatzes oder einer spezifischeren Aufgabe trainiert. Nehmen wir ChatGPT als Beispiel.
Wenn Sie mit GPT-Modellen gespielt haben, wissen Sie, dass Aufforderungen weniger „Schreiben Sie dieses Ding“ als vielmehr Ähnliches bedeuten
- Aufforderung: Es war einmal
- Fortsetzung: Auf der Spitze eines Turms befand sich ein böser Zauberer.
- Fortsetzung: Auf der Spitze eines Turms befand sich ein böser Zauberer.
- Eingabeaufforderung : Warum ist das Huhn einer Band beigetreten?
- Fortsetzung : Weil es die Trommelstöcke hatte!
Um von diesem Punkt an zu ChatGPT zu gelangen, ist eine Menge schlecht bezahlter Arbeit erforderlich. Diese Leute erstellen riesige Korpora, um das Gewicht der GPT-Antworten und erwarteten Verhaltensweisen einzuschätzen. Diese Mitarbeiter erstellen Unmengen von Aufforderungs-/Fortsetzungstexten, die wie folgt aussehen:
- Eingabeaufforderung : Beenden Sie diese Geschichte: „Es war einmal …“
- Fortsetzung : Klar! Es war einmal, in einem weit, weit entfernten Land, ein kleines Dorf, eingebettet zwischen zwei majestätischen Bergen.
- Fortsetzung : Klar! Es war einmal, in einem weit, weit entfernten Land, ein kleines Dorf, eingebettet zwischen zwei majestätischen Bergen.
- Aufforderung : Erzähl mir einen Witz über ein Huhn.
- Fortsetzung : Warum ist das Huhn einer Band beigetreten? Weil es Trommelstöcke hatte!
Dieser Feinabstimmungsprozess ist aus mehreren Gründen unerlässlich:
- Spezifität: Während das Vortraining dem Modell ein umfassendes Sprachverständnis verleiht, schränkt die Feinabstimmung sein Wissen und Verhalten ein, um es besser an bestimmte Aufgaben oder Domänen anzupassen. Beispielsweise kann ein auf medizinische Daten abgestimmtes Modell medizinische Fragen besser beantworten.
- Kontrolle: Durch die Feinabstimmung haben Entwickler mehr Kontrolle über die Ausgaben des Modells. Entwickler können einen kuratierten Datensatz verwenden, um das Modell so zu steuern, dass es gewünschte Reaktionen hervorruft und unerwünschte Verhaltensweisen vermeidet.
- Sicherheit: Es hilft bei der Reduzierung schädlicher oder voreingenommener Ausgaben. Durch die Verwendung von Richtlinien während des Feinabstimmungsprozesses können menschliche Prüfer sicherstellen, dass das Modell keine unangemessenen Inhalte produziert.
- Leistung: Durch Feinabstimmung kann die Leistung des Modells bei bestimmten Aufgaben erheblich verbessert werden. Beispielsweise ist ein Modell, das speziell für den Kundensupport optimiert wurde, wesentlich besser darin als ein generisches Modell.
Man merkt, dass ChatGPT in mancher Hinsicht besonders verfeinert wurde.
Beispielsweise ist „logisches Denken“ etwas, mit dem LLM-Studenten oft zu kämpfen haben. Das beste Modell für logisches Denken von ChatGPT – GPT-4 – wurde intensiv trainiert, um Muster in Zahlen explizit zu erkennen.
Statt so etwas:
- Eingabeaufforderung : Was ist 2+2?
- Prozess : Oftmals in Mathematiklehrbüchern für Kinder 2+2 =4. Gelegentlich gibt es Verweise auf „2+2=5“, aber wenn das der Fall ist, gibt es normalerweise mehr Kontext, der mit George Orwell oder Star Trek zu tun hat. Wenn dies in diesem Zusammenhang wäre, würde die Gewichtung eher zu Gunsten von 2+2=5 ausfallen. Da dieser Kontext jedoch nicht existiert, ist das nächste Token in diesem Fall wahrscheinlich 4.
- Antwort : 2+2=4
Das Training läuft in etwa so ab:
- Ausbildung: 2+2=4
- Training: 4/2=2
- Training: Die Hälfte von 4 ist 2
- Training: 2 von 2 ist vier
…und so weiter.
Für diese „logischeren“ Modelle bedeutet das, dass der Trainingsprozess strenger ist und sich darauf konzentriert, sicherzustellen, dass das Modell logische und mathematische Prinzipien versteht und korrekt anwendet.
Das Modell wird verschiedenen mathematischen Problemen und deren Lösungen ausgesetzt, um sicherzustellen, dass es diese Prinzipien verallgemeinern und auf neue, unbekannte Probleme anwenden kann.
Die Bedeutung dieses Feinabstimmungsprozesses, insbesondere für das logische Denken, kann nicht genug betont werden. Ohne sie könnte das Modell falsche oder unsinnige Antworten auf einfache logische oder mathematische Fragen liefern.
Bildmodelle vs. Sprachmodelle
Während sowohl Bild- als auch Sprachmodelle ähnliche Architekturen wie Transformatoren verwenden können, unterscheiden sich die von ihnen verarbeiteten Daten grundlegend:
Bildmodelle
Diese Modelle arbeiten mit Pixeln und arbeiten oft hierarchisch, indem sie zuerst kleine Muster (wie Kanten) analysieren und sie dann kombinieren, um größere Strukturen (wie Formen) zu erkennen, und so weiter, bis sie das gesamte Bild verstehen.
Sprachmodelle
Diese Modelle verarbeiten Wort- oder Zeichenfolgen. Sie müssen den Kontext, die Grammatik und die Semantik verstehen, um kohärenten und kontextrelevanten Text zu erstellen.
Wie prominente generative KI-Schnittstellen funktionieren
Dall-E + Midjourney
Dall-E ist eine für die Bilderzeugung angepasste Variante des GPT-3-Modells. Es wird anhand eines riesigen Datensatzes von Text-Bild-Paaren trainiert. Midjourney ist eine weitere Bildgenerierungssoftware, die auf einem proprietären Modell basiert.
- Eingabe: Sie geben eine Textbeschreibung ein, z. B. „ein zweiköpfiger Flamingo“.
- Verarbeitung: Diese Modelle kodieren diesen Text in eine Reihe von Zahlen und dekodieren dann diese Vektoren, indem sie Beziehungen zu Pixeln finden, um ein Bild zu erzeugen. Das Modell hat die Beziehungen zwischen Textbeschreibungen und visuellen Darstellungen aus seinen Trainingsdaten gelernt.
- Ausgabe: Ein Bild, das mit der angegebenen Beschreibung übereinstimmt oder sich darauf bezieht.
Finger, Muster, Probleme
Warum können diese Tools nicht durchweg Hände erzeugen, die normal aussehen? Diese Tools funktionieren, indem sie Pixel nebeneinander betrachten.
Sie können sehen, wie das funktioniert, wenn Sie frühere oder primitivere generierte Bilder mit neueren vergleichen: Frühere Modelle sehen sehr unscharf aus. Im Gegensatz dazu sind neuere Modelle viel knackiger.
Diese Modelle erzeugen Bilder, indem sie das nächste Pixel basierend auf den bereits generierten Pixeln vorhersagen. Dieser Vorgang wird millionenfach wiederholt, um ein vollständiges Bild zu erzeugen.
Hände, insbesondere Finger, sind komplex und weisen viele Details auf, die genau erfasst werden müssen.
Die Positionierung, Länge und Ausrichtung jedes Fingers kann in verschiedenen Bildern stark variieren.
Bei der Generierung eines Bildes aus einer Textbeschreibung muss das Modell viele Annahmen über die genaue Haltung und Struktur der Hand treffen, was zu Anomalien führen kann.
ChatGPT
ChatGPT basiert auf der GPT-3.5-Architektur, einem transformatorbasierten Modell, das für Aufgaben der Verarbeitung natürlicher Sprache entwickelt wurde.
- Eingabe: Eine Eingabeaufforderung oder eine Reihe von Nachrichten, um ein Gespräch zu simulieren.
- Verarbeitung: ChatGPT nutzt sein umfangreiches Wissen aus diversen Internettexten, um Antworten zu generieren. Es berücksichtigt den Kontext des Gesprächs und versucht, die relevanteste und kohärenteste Antwort zu finden.
- Ausgabe: Eine Textantwort, die das Gespräch fortsetzt oder beantwortet.
Spezialität
Die Stärke von ChatGPT liegt in seiner Fähigkeit, verschiedene Themen zu behandeln und menschenähnliche Gespräche zu simulieren, was es ideal für Chatbots und virtuelle Assistenten macht.
Bard + Search Generative Experience (SGE)
Während bestimmte Details möglicherweise proprietär sind, basiert Bard auf transformatorischen KI-Techniken, ähnlich wie andere hochmoderne Sprachmodelle. SGE basiert auf ähnlichen Modellen, integriert jedoch andere ML-Algorithmen, die Google verwendet.
SGE generiert Inhalte wahrscheinlich mithilfe eines transformatorbasierten generativen Modells und extrahiert dann Fuzzy-Antworten aus Ranking-Seiten in der Suche. (Das stimmt möglicherweise nicht. Nur eine Vermutung, basierend darauf, wie es beim Spielen damit zu funktionieren scheint. Bitte verklagen Sie mich nicht!)
- Eingabe: Eine Eingabeaufforderung/ein Befehl/eine Suche
- Verarbeitung: Bard verarbeitet die Eingaben und arbeitet wie andere LLMs. SGE verwendet eine ähnliche Architektur, fügt jedoch eine Ebene hinzu, in der es sein internes Wissen (aus Trainingsdaten gewonnen) durchsucht, um eine geeignete Antwort zu generieren. Es berücksichtigt die Struktur, den Kontext und die Absicht der Eingabeaufforderung, relevante Inhalte zu produzieren.
- Ausgabe: Generierter Inhalt, der eine Geschichte, eine Antwort oder eine andere Art von Text sein kann.
Anwendungen generativer KI (und ihre Kontroversen)
Kunst und Design
Generative KI kann jetzt Kunstwerke, Musik und sogar Produktdesigns erstellen. Dies hat neue Wege für Kreativität und Innovation eröffnet.
Kontroverse
Der Aufstieg der KI in der Kunst hat Debatten über Arbeitsplatzverluste in kreativen Bereichen entfacht.
Darüber hinaus gibt es Bedenken hinsichtlich:
- Arbeitsverstöße, insbesondere wenn KI-generierte Inhalte ohne ordnungsgemäße Nennung oder Entschädigung verwendet werden.
- Führungskräfte, die Schriftstellern damit drohen, sie durch KI zu ersetzen, sind eines der Themen, die den Schriftstellerstreik auslösten.
Verarbeitung natürlicher Sprache (NLP)
KI-Modelle werden mittlerweile häufig für Chatbots, Sprachübersetzungen und andere NLP-Aufgaben verwendet.
Außerhalb des Traums der künstlichen allgemeinen Intelligenz (AGI) ist dies die beste Verwendung für LLMs, da sie einem „generalistischen“ NLP-Modell nahe kommen.
Kontroverse
Viele Nutzer empfinden Chatbots als unpersönlich und manchmal nervig.
Darüber hinaus hat KI zwar erhebliche Fortschritte bei der Sprachübersetzung gemacht, ihr fehlen jedoch häufig die Nuancen und das kulturelle Verständnis, die menschliche Übersetzer mitbringen, was zu beeindruckenden und fehlerhaften Übersetzungen führt.
Medizin und Arzneimittelentwicklung
KI kann große Mengen medizinischer Daten schnell analysieren und potenzielle Arzneimittelwirkstoffe generieren, wodurch der Arzneimittelentwicklungsprozess beschleunigt wird. Viele Ärzte nutzen LLMs bereits zum Verfassen von Notizen und Patientenkommunikationen
Kontroverse
Es kann problematisch sein, sich für medizinische Zwecke auf LLMs zu verlassen. Medizin erfordert Präzision und Fehler oder Versäumnisse der KI können schwerwiegende Folgen haben.
Auch in der Medizin gibt es bereits Vorurteile, die durch die Verwendung von LLMs nur noch verstärkt werden. Es gibt auch ähnliche Probleme, wie weiter unten erörtert, in Bezug auf Datenschutz, Wirksamkeit und Ethik.
Spielen
Viele KI-Enthusiasten freuen sich über den Einsatz von KI im Gaming: Sie sagen, dass KI realistische Spielumgebungen, Charaktere und sogar ganze Spielhandlungen erzeugen und so das Spielerlebnis verbessern kann. Der NPC-Dialog kann durch die Verwendung dieser Tools verbessert werden.
Kontroverse
Es gibt eine Debatte über die Intentionalität im Spieldesign.
Während KI große Mengen an Inhalten generieren kann, argumentieren einige, dass ihr das bewusste Design und die erzählerische Kohärenz fehlen, die menschliche Designer mitbringen.
In Watchdogs 2 gab es programmatische NPCs, die wenig zum erzählerischen Zusammenhalt des Spiels als Ganzes beitrugen.
Vermarktung und Werbung
KI kann das Verbraucherverhalten analysieren und personalisierte Werbung und Werbeinhalte generieren, wodurch Marketingkampagnen effektiver werden.
LLMs enthalten Kontext aus den Texten anderer Leute, was sie für die Generierung von User Stories oder differenzierteren programmatischen Ideen nützlich macht. Anstatt jemandem, der gerade einen Fernseher gekauft hat, einen Fernseher zu empfehlen, können LLMs Zubehör empfehlen, das jemand stattdessen haben möchte.
Controversy
The use of AI in marketing raises privacy concerns. There's also a debate about the ethical implications of using AI to influence consumer behavior.
Dig deeper: How to scale the use of large language models in marketing
Continuing issues with LLMS
Contextual understanding and comprehension of human speech
- Limitation: AI models, including GPT, often struggle with nuanced human interactions, such as detecting sarcasm, humor, or lies.
- Example: In stories where a character is lying to other characters, the AI might not always grasp the underlying deceit and might interpret statements at face value.
Pattern matching
- Limitation: AI models, especially those like GPT, are fundamentally pattern matchers. They excel at recognizing and generating content based on patterns they've seen in their training data. However, their performance can degrade when faced with novel situations or deviations from established patterns.
- Example: If a new slang term or cultural reference emerges after the model's last training update, it might not recognize or understand it.
Lack of common sense understanding
- Limitation: While AI models can store vast amounts of information, they often lack a "common sense" understanding of the world, leading to outputs that might be technically correct but contextually nonsensical.
Potential to reinforce biases
- Ethical consideration: AI models learn from data, and if that data contains biases, the model will likely reproduce and even amplify those biases. This can lead to outputs that are sexist, racist, or otherwise prejudiced.
Challenges in generating unique ideas
- Limitation: AI models generate content based on patterns they've seen. While they can combine these patterns in novel ways, they don't "invent" like humans do. Their "creativity" is a recombination of existing ideas.
Data Privacy, Intellectual Property, and Quality Control Issues:
- Ethical consideration : Using AI models in applications that handle sensitive data raises concerns about data privacy. When AI generates content, questions arise about who owns the intellectual property rights. Ensuring the quality and accuracy of AI-generated content is also a significant challenge.
Bad code
- AI models might generate syntactically correct code when used for coding tasks but functionally flawed or insecure. I have had to correct the code people have added to sites they generated using LLMs. It looked right, but was not. Even when it does work, LLMs have out-of-date expectations for code, using functions like “document.write” that are no longer considered best practice.
Hot takes from an MLOps engineer and technical SEO
This section covers some hot takes I have about LLMs and generative AI. Feel free to fight with me.
Prompt engineering isn't real (for generative text interfaces)
Generative models, especially large language models (LLMs) like GPT-3 and its successors, have been touted for their ability to generate coherent and contextually relevant text based on prompts.
Because of this, and since these models have become the new “gold rush," people have started to monetize “prompt engineering” as a skill. This can be either $1,400 courses or prompt engineering jobs.
However, there are some critical considerations:
LLMs change rapidly
As technology evolves and new model versions are released, how they respond to prompts can change. What worked for GPT-3 might not work the same way for GPT-4 or even a newer version of GPT-3.
This constant evolution means prompt engineering can become a moving target, making it challenging to maintain consistency. Prompts that work in January may not work in March.
Uncontrollable outcomes
While you can guide LLMs with prompts, there's no guarantee they'll always produce the desired output. For instance, asking an LLM to generate a 500-word essay might result in outputs of varying lengths because LLMs don't know what numbers are.
Similarly, while you can ask for factual information, the model might produce inaccuracies because it cannot tell the difference between accurate and inaccurate information by itself.
Using LLMs in non-language-based applications is a bad idea
LLMs are primarily designed for language tasks. While they can be adapted for other purposes, there are inherent limitations:
Struggle with novel ideas
LLMs are trained on existing data, which means they're essentially regurgitating and recombining what they've seen before. They don't "invent" in the truest sense of the word.
Tasks that require genuine innovation or out-of-the-box thinking should not use LLMs.
You can see an issue with this when it comes to people using GPT models for news content – if something novel comes along, it's hard for LLMs to deal with it.

For example, a site that seems to be generating content with LLMs published a possibly libelous article about Megan Crosby. Crosby was caught elbowing opponents in real life.
Without that context, the LLM created a completely different, evidence-free story about a “controversial comment.”
Text-focused
At their core, LLMs are designed for text. While they can be adapted for tasks like image generation or music composition, they might not be as proficient as models specifically designed for those tasks.
LLMs don't know what the truth is
They generate outputs based on patterns encountered in their training data. This means they can't verify facts or discern true and false information.
If they've been exposed to misinformation or biased data during training, or they don't have context for something, they might propagate those inaccuracies in their outputs.
This is especially problematic in applications like news generation or academic research, where accuracy and truth are paramount.
Think about it like this: if an LLM has never come across the name “Jimmy Scrambles” before but knows it's a name, prompts to write about it will only come up with related vectors.
Designers are always better than AI-generated Art
AI has made significant strides in art, from generating paintings to composing music. However, there's a fundamental difference between human-made art and AI-generated art:
Intent, feeling, vibe
Art is not just about the final product but the intent and emotion behind it.
A human artist brings their experiences, emotions, and perspectives to their work, giving it depth and nuance that's challenging for AI to replicate.
A “bad” piece of art from a person has more depth than a beautiful piece of art from a prompt.
Die in diesem Artikel geäußerten Meinungen sind die des Gastautors und nicht unbedingt die von Search Engine Land. Die Autoren unserer Mitarbeiter sind hier aufgelistet.