
Wikipedia Web Scraping 2023: Extrahieren von Daten zur Analyse
Veröffentlicht: 2023-03-29Online-Scraping ermöglicht es Ihnen, offene Daten von Websites zu Zwecken wie Preisvergleich, Marktforschung, Anzeigenüberprüfung usw. zu sammeln.
In der Regel werden große Mengen der erforderlichen öffentlichen Daten extrahiert, aber wenn Sie auf Blockaden stoßen, kann die Extraktion zu einer Herausforderung werden.
Die Beschränkung kann entweder eine Ratenblockierung oder eine IP-Blockierung sein (die IP-Adresse der Anforderung ist beschränkt, weil sie aus einem verbotenen Bereich, einem verbotenen IP-Typ usw. stammt). (Die IP-Adresse ist blockiert, weil sie mehrere Anfragen gestellt hat).

Nun, wenn Sie bereit sind, nützliches Wissen und Informationen zu kratzen, dann bin ich sicher, dass Sie darüber nachgedacht haben, Wikipedia zu kratzen, die Wissensenzyklopädie, die eine Menge Informationen beherbergt.
Lassen Sie uns ein paar Dinge über Web Scraping Wikipedia verstehen.
Inhaltsverzeichnis
Wikipedia-Web-Scraping
Web Scraping ist eine automatisierte Methode zum Sammeln von Daten aus dem Internet. Ausführliche Informationen zum Thema Web Scraping, ein Vergleich zum Web Crawling und Argumente für Web Scraping finden Sie in diesem Artikel.
Ziel ist es, mit verschiedenen Web-Scraping-Methoden Daten von der Wikipedia-Homepage zu sammeln und sie dann zu parsen.
Sie werden mit verschiedenen Web-Scraping-Methoden, Python-Web-Scraping-Bibliotheken und Verfahren zur Datenextraktion und -verarbeitung vertrauter.
Web Scraping und Python
Web Scraping ist im Wesentlichen der Prozess des Extrahierens strukturierter Daten aus einer großen Datenmenge von einer großen Anzahl von Websites mithilfe von Software, die in einer Programmiersprache erstellt wurde, und Speichern lokal auf unseren Geräten, vorzugsweise in Excel-Tabellen, JSON oder Tabellenkalkulationen.
Dies hilft Programmierern bei der Erstellung von logischem, verständlichem Code für kleine und große Projekte.
Python gilt in erster Linie als die beste Sprache für Web Scraping. Es kann die meisten Aufgaben im Zusammenhang mit dem Web-Crawling effektiv bewältigen und ist eher ein Allrounder.
Wie kratzt man Daten aus Wikipedia?
Daten können auf verschiedene Weise aus Webseiten extrahiert werden.
Beispielsweise können Sie es selbst mit Computersprachen wie Python implementieren. Aber wenn Sie nicht technisch versiert sind, müssen Sie viel lernen, bevor Sie mit diesem Prozess viel anfangen können.
Es ist auch zeitaufwändig und kann so lange dauern wie das manuelle Durchsuchen von Wikipedia-Seiten. Darüber hinaus sind kostenlose Web Scraper online zugänglich. Doch häufig mangelt es ihnen an Verlässlichkeit, und ihre Lieferanten haben womöglich zwielichtige Absichten.
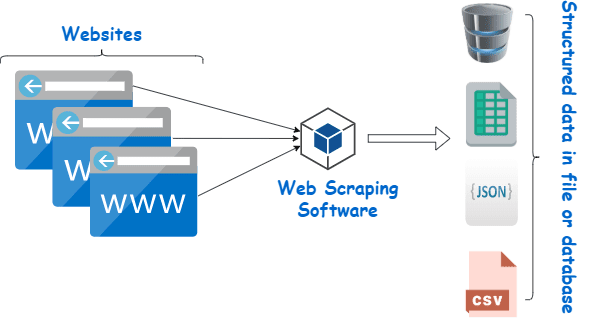
Die Investition in einen anständigen Web Scraper von einem seriösen Anbieter ist die beste Methode, um Wiki-Daten zu sammeln.
Der nächste Schritt ist in der Regel einfach und unkompliziert, da der Anbieter Ihnen eine Anleitung zur Installation und Verwendung des Scrapers anbietet.
Ein Proxy ist ein Tool, das Sie in Verbindung mit Ihrem Wiki-Scraper verwenden können, um Daten effektiver zu scrapen. Python-basierte Frameworks wie Scrapy, Scraping Robot und Beautiful Soup sind nur einige Beispiele dafür, wie einfach es ist, mit dieser Sprache zu schaben.
Proxy zum Scrapen von Daten aus Wikipedia
Sie benötigen Proxys, die extrem schnell und sicher zu verwenden sind und garantiert nicht untergehen, wenn Sie sie brauchen, um Daten effektiv zu kratzen. Solche Proxys sind bei Rayobyte zu angemessenen Preisen erhältlich.
Wir bemühen uns, eine Vielzahl von Proxys anzubieten, da wir uns bewusst sind, dass jeder Benutzer andere Vorlieben und Anwendungsfälle hat.
Rotierende Proxys für Web Scraping Wikipedia
Eine Instanz eines Proxys ist eine, die ihre IP-Adresse regelmäßig wechselt. Um Unterbrechungen zu vermeiden, wird die IP-Adresse außerdem sofort geändert, wenn ein Verbot auftritt. Dies macht diesen speziellen Proxy zu einer großartigen Wahl für das Site-Scraping.
Statische Proxys haben im Vergleich dazu nur eine IP-Adresse. Wenn Ihr ISP keinen automatischen Austausch ermöglicht, werden Sie auf eine Mauer stoßen, wenn Sie nur Zugriff auf eine IP-Adresse haben und diese blockiert wird. Aus diesem Grund sind statische Proxys nicht die beste Option für Web Scraping.
Residente Proxys für Web-Scraping-Wiki-Daten
Residential Proxys sind Proxy-IP-Adressen, die Internetdienstanbieter (ISPs) verteilen und bestimmten Haushalten zugeordnet sind. Da sie von echten Menschen stammen, ist es ziemlich schwierig, sie zu bekommen. Dadurch sind sie knapp und relativ teuer.


Wenn Sie private Proxys zum Scrapen von Daten verwenden, scheinen Sie ein alltäglicher Benutzer zu sein, da sie mit den Adressen echter Personen verknüpft sind.
Die Verwendung von Residential Proxys verringert also Ihre Chance, entdeckt und blockiert zu werden, erheblich. Sie sind daher hervorragende Kandidaten für das Data Scraping.
Rotierende Residential Proxys zum Sammeln von Wiki-Daten
Ein rotierender privater Proxy, der die beiden Typen kombiniert, über die wir gerade gesprochen haben, ist der beste Proxy für das Web-Scraping von Wikipedia.
Sie können auf eine große Anzahl von Heim-IPs zugreifen, indem Sie einen Proxy verwenden, der sie häufig rotiert.
Dies ist von entscheidender Bedeutung, da trotz der Schwierigkeit, Residential Proxys zu identifizieren, die Menge der von ihnen generierten Anfragen schließlich die Aufmerksamkeit der zu kratzenden Website auf sich ziehen wird.
Die Rotation stellt sicher, dass das Projekt fortgesetzt werden kann, selbst wenn die IP-Adresse unvermeidlich auf die schwarze Liste gesetzt wird.
Wir haben daher das, was Sie brauchen, egal ob Sie sich für mehrere Rechenzentrums-Proxys entscheiden oder lieber in ein paar Heim-Proxys investieren möchten.
Sie werden das beste Web-Scraping-Erlebnis mit Proxys mit einer Geschwindigkeit von 1 GBS, unbegrenzter Bandbreite und Kundendienst rund um die Uhr genießen.
Sie können auch lesen
- Beste Web-Scraping-Techniken: Ein praktischer Leitfaden
- Octoparse Review Ist es wirklich ein gutes Web-Scraping-Tool?
- Beste Web-Scraping-Tools
- Was ist Web Scraping? - Wie wird es verwendet? Wie Ihr Unternehmen davon profitieren kann
Warum sollten Sie Wikipedia schaben?
Wikipedia ist derzeit einer der vertrauenswürdigsten und informationsreichsten Dienste in der Online-Welt. Auf dieser Plattform finden Sie Antworten und Informationen zu fast allen Themen, die Ihnen einfallen.
Daher ist Wikipedia natürlich eine großartige Quelle, um Daten zu kratzen. Lassen Sie uns die Hauptgründe besprechen, warum Sie Wikipedia kratzen sollten.
Web Scraping für die akademische Forschung
Das Sammeln von Daten ist eine der schmerzhaftesten Aktivitäten in der Forschung. Wie bereits erwähnt, machen Web Scraper diesen Vorgang schneller und einfacher und sparen Ihnen außerdem eine Menge Zeit und Energie.
Mit einem Web Scraper können Sie schnell zahlreiche Wiki-Seiten durchsuchen und alle benötigten Daten organisiert sammeln.
Gehen Sie für einen Moment davon aus, dass Ihr Ziel darin besteht, festzustellen, ob Depressionen und Sonneneinstrahlung von Land zu Land unterschiedlich sind.
Sie können einen Wiki-Scraper verwenden, um Informationen wie die Verbreitung von Depressionen in verschiedenen Nationen und ihre Sonnenstunden zu finden, anstatt zahlreiche Wikipedia-Einträge zu durchsuchen.
Reputationsmanagement
Das Erstellen einer Wikipedia-Seite ist in der heutigen Zeit zu einer unverzichtbaren Marketingstrategie für viele verschiedene Arten von Unternehmen geworden, da Wikipedia-Beiträge häufig auf der ersten Seite von Google erscheinen.
Aber eine Seite auf Wikipedia zu haben, sollte nicht das Ende Ihrer Marketingbemühungen sein. Wikipedia ist eine Crowdsourcing-Plattform, daher kommt Vandalismus ziemlich häufig vor.
Infolgedessen könnte jemand der Seite Ihres Unternehmens ungünstige Informationen hinzufügen und Ihrem Ruf schaden. Alternativ könnten sie Ihr Unternehmen in einem relevanten Wiki-Artikel diffamieren.
Aus diesem Grund müssen Sie Ihre Wiki-Seite sowie andere Seiten, die Ihr Unternehmen erwähnen, im Auge behalten, sobald es erstellt wurde. Das geht ganz einfach mit Hilfe eines Wiki-Scrapers.
Sie können Wikipedia-Seiten regelmäßig nach Hinweisen auf Ihr Unternehmen durchsuchen und dort auf Fälle von Vandalismus hinweisen.
Steigern Sie SEO
Sie können Wikipedia verwenden, um den Verkehr auf Ihrer Website zu erhöhen.
Erstellen Sie eine Liste von Artikeln, die Sie ändern möchten, indem Sie mit einem Wiki-Daten-Scraper Seiten finden, die für Ihr Unternehmen und Ihre Zielgruppe relevant sind.
Lesen Sie zunächst die Artikel und nehmen Sie einige hilfreiche Anpassungen vor, um als Mitwirkender an der Website Glaubwürdigkeit zu gewinnen.
Sobald Sie eine gewisse Glaubwürdigkeit hergestellt haben, können Sie Verbindungen zu Ihrer Website an Stellen hinzufügen, an denen fehlerhafte Links vorhanden sind oder Zitate erforderlich sind.
Schnelle Links
- Beste französische Proxys
- Top Bester Spotify-Proxy
- Beste Nike Proxys
Python-Bibliotheken, die für Web Scraping verwendet werden
Python ist, wie bereits gesagt, die beliebteste und renommierteste Programmiersprache und das Web-Scraping-Tool der Welt. Schauen wir uns nun die Python-Web-Scraping-Bibliotheken an, die derzeit verfügbar sind.
Requests (HTTP für Menschen) Bibliothek für Web Scraping
Es wird verwendet, um verschiedene HTTP-Anforderungen wie GET und POST zu senden. Unter allen Bibliotheken ist sie die grundlegendste, aber auch die wichtigste.
lxml-Bibliothek für Web Scraping
Sehr schnelles und performantes Parsen von HTML- und XML-Text von Webseiten bietet das Paket lxml. Dies ist die richtige Wahl, wenn Sie große Datenbanken durchsuchen möchten.
Schöne Suppenbibliothek für Web Scraping
Seine Arbeit besteht darin, einen Parse-Baum für das Parsen von Inhalten aufzubauen. Ein großartiger Ausgangspunkt für Anfänger und sehr benutzerfreundlich.
Selenbibliothek für Web Scraping
Diese Bibliothek löst das Problem, das alle oben genannten Bibliotheken haben, nämlich das Scrapen von Inhalten von dynamisch gefüllten Webseiten.
Es wurde ursprünglich für das automatisierte Testen von Webanwendungen entwickelt. Aus diesem Grund ist es langsamer und für Aufgaben auf industrieller Ebene ungeeignet.
Scrapy für Web Scraping
Ein vollständiges Web-Scraping-Framework, das asynchrone Nutzung verwendet, ist der BOSS aller Pakete. Das steigert die Effizienz und macht es blitzschnell.
Abschluss
Das war also so ziemlich der wichtigste Aspekt, den Sie über Wikipedia Web Scraping wissen müssen. Bleiben Sie mit uns auf dem Laufenden für weitere solche informativen Posts über Web Scraping und vieles mehr!
Schnelle Links
- Beste Proxys für die Aggregation von Reisepreisen
- Beste französische Proxys
- Die besten Tripadvisor-Proxys
- Beste Etsy-Proxys
- IPRoyal Gutscheincode
- Beste TikTok-Proxys