
SEO-Fallstudie über ein Jahr: Was Sie über den Googlebot wissen müssen
Veröffentlicht: 2019-08-30Anmerkung des Herausgebers: Serge Bezborodov, CEO des JetOctopus-Crawlers, gibt Expertenratschläge, wie Sie Ihre Website für den Googlebot attraktiv machen können. Die Daten in diesem Artikel basieren auf jahrelanger Forschung und 300 Millionen gecrawlten Seiten.
Vor ein paar Jahren habe ich versucht, den Traffic auf unserer Job-Aggregator-Website mit 5 Millionen Seiten zu erhöhen. Ich entschied mich für die Dienste einer SEO-Agentur, da ich erwartete, dass der Traffic durch die Decke gehen würde. Aber ich habe mich getäuscht. Anstelle einer umfassenden Prüfung ließ ich Tarotkarten lesen. Deshalb habe ich wieder ganz von vorn angefangen und einen Webcrawler für umfassende Onpage-SEO-Analysen erstellt.
Ich spioniere den Googlebot seit mehr als einem Jahr aus und bin jetzt bereit, Einblicke in sein Verhalten zu geben. Ich erwarte, dass meine Beobachtungen zumindest die Funktionsweise von Webcrawlern verdeutlichen und Ihnen höchstens dabei helfen, die Onpage-Optimierung effizient durchzuführen. Ich habe die aussagekräftigsten Daten gesammelt, die entweder für eine neue Website oder eine mit Tausenden von Seiten nützlich sind.
Werden Ihre Seiten in den SERPs angezeigt?
Um sicher zu wissen, welche Seiten in den Suchergebnissen erscheinen, sollten Sie die Indexierbarkeit der gesamten Website überprüfen. Allerdings kostet die Analyse jeder URL auf einer Website mit über 10 Millionen Seiten ein Vermögen, etwa so viel wie ein neues Auto.
Verwenden wir stattdessen die Analyse von Protokolldateien. Wir arbeiten mit Websites auf folgende Weise: Wir crawlen die Webseiten wie der Suchbot und analysieren dann die Protokolldateien, die ein halbes Jahr lang gesammelt wurden. Protokolle zeigen, ob Bots die Website besuchen, welche Seiten gecrawlt wurden und wann und wie oft Bots die Seiten besucht haben.
Crawling ist der Prozess, bei dem Suchbots Ihre Website besuchen, alle Links auf Webseiten verarbeiten und diese Links für die Indexierung in einer Reihe platzieren. Während des Crawlings vergleichen Bots gerade bearbeitete URLs mit bereits im Index befindlichen. Daher aktualisieren Bots die Daten und fügen einige URLs aus der Suchmaschinendatenbank hinzu oder löschen sie, um den Benutzern die relevantesten und aktuellsten Ergebnisse bereitzustellen.
Nun können wir leicht diese Schlussfolgerungen ziehen:
- Wenn der Suchbot nicht auf der URL war, wird diese URL wahrscheinlich nicht im Index sein.
- Wenn der Googlebot die URL mehrmals täglich besucht, hat diese URL hohe Priorität und erfordert daher Ihre besondere Aufmerksamkeit.
Insgesamt zeigen diese Informationen, was das organische Wachstum und die Entwicklung Ihrer Website verhindert. Anstatt blind zu agieren, kann Ihr Team jetzt eine Website mit Bedacht optimieren.
Wir arbeiten hauptsächlich mit großen Websites, denn wenn Ihre Website klein ist, wird der Googlebot früher oder später alle Ihre Webseiten crawlen.
Umgekehrt haben Websites mit mehr als 100.000 Seiten ein Problem, wenn der Crawler Seiten besucht, die für Webmaster unsichtbar sind. Auf diesen nutzlosen oder sogar schädlichen Seiten kann wertvolles Crawl-Budget verschwendet werden. Gleichzeitig findet der Bot Ihre profitablen Seiten möglicherweise nie, weil die Struktur einer Website durcheinander ist.
Das Crawl-Budget ist die begrenzte Menge an Ressourcen, die der Googlebot bereit ist, für Ihre Website auszugeben. Es wurde erstellt, um zu priorisieren, was wann analysiert werden soll. Die Höhe des Crawl-Budgets hängt von vielen Faktoren ab, wie z. B. der Größe Ihrer Website, ihrer Struktur, dem Volumen und der Häufigkeit der Benutzeranfragen usw.
Beachten Sie, dass der Suchbot nicht daran interessiert ist, Ihre Website vollständig zu crawlen.
Der Hauptzweck des Suchmaschinen-Bots besteht darin, Benutzern die relevantesten Antworten mit minimalem Ressourcenverlust zu geben.Der Bot crawlt so viele Daten, wie er für den Hauptzweck benötigt. Es ist also IHRE Aufgabe, dem Bot dabei zu helfen, die nützlichsten und profitabelsten Inhalte zu finden.
Googlebot ausspionieren
Im letzten Jahr haben wir mehr als 300 Millionen URLs und 6 Milliarden Protokollzeilen auf großen Websites gescannt. Anhand dieser Daten haben wir das Verhalten des Googlebots nachverfolgt, um die folgenden Fragen zu beantworten:
- Welche Arten von Seiten werden ignoriert?
- Welche Seiten werden häufig besucht?
- Was ist für Bots wichtig?
- Was hat keinen Wert?
Nachfolgend finden Sie unsere Analyse und Ergebnisse und keine Neufassung der Google-Richtlinien für Webmaster. Tatsächlich geben wir keine unbewiesenen und unbegründeten Empfehlungen. Jeder Punkt basiert auf sachlichen Statistiken und Grafiken für Ihre Bequemlichkeit.
Kommen wir zur Sache und finden es heraus:
- Was ist dem Googlebot wirklich wichtig?
- Was bestimmt, ob der Bot die Seite besucht oder nicht?
Folgende Faktoren haben wir identifiziert:
Abstand vom Index
DFI steht für Distance From Index und gibt an, wie weit Ihre URL von der Haupt-/Stamm-/Index-URL in Klicks entfernt ist. Dies ist eines der wichtigsten Kriterien, das sich auf die Häufigkeit der Besuche des Googlebots auswirkt. Hier ist ein Lehrvideo, um mehr über DFI zu erfahren .
Beachten Sie, dass DFI nicht die Anzahl der Schrägstriche im URL-Verzeichnis ist, wie zum Beispiel:
site.com/shop/iphone/iphoneX.html – DFI– 3__ _
DFI wird also genau nach KLICKS von der Hauptseite gezählt
https://site.com/shop/iphone/iphoneX.html
https://site.com iPhones Katalog → https://site.com/shop/iphone iPhone X → https://site.com/shop/iphone/iphoneX.html – DFI – 2
Unten können Sie sehen, wie das Interesse des Googlebots an der URL mit seinem DFI im letzten Monat und in den letzten sechs Monaten allmählich abgenommen hat.
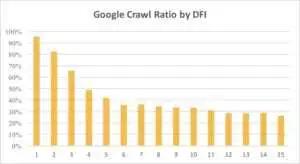
Wie Sie sehen können, crawlt der Googlebot bei einem DFI von 5 bis 6 nur die Hälfte der Webseiten. Und der Prozentsatz der verarbeiteten Seiten verringert sich, wenn DFI größer ist. Die Indikatoren in der Tabelle wurden für 18 Millionen Seiten vereinheitlicht. Beachten Sie, dass die Daten je nach Nische der jeweiligen Website variieren können.
Was zu tun ist?
Es ist offensichtlich, dass die beste Strategie in diesem Fall darin besteht, DFI zu vermeiden, die länger als 5 sind, eine einfach zu navigierende Website-Struktur aufzubauen, besonderes Augenmerk auf Links zu legen usw.
Die Wahrheit ist, dass diese Maßnahmen für Websites mit über 100.000 Seiten wirklich zeitaufwändig sind. Normalerweise haben große Websites eine lange Geschichte von Redesigns und Migrationen. Deshalb sollten Webmaster Seiten mit einem DFI von 10, 12 oder sogar 30 nicht einfach löschen. Auch das Einfügen eines Links von häufig besuchten Seiten wird das Problem nicht lösen.
Der optimale Umgang mit langen DFIs besteht darin, zu prüfen und einzuschätzen, ob diese URLs relevant und profitabel sind und welche Positionen sie in den SERPs einnehmen.
Seiten mit langem DFI, aber guten Positionen in SERPs haben ein hohes Potenzial. Um den Traffic auf qualitativ hochwertigen Seiten zu erhöhen, sollten Webmaster Links von den nächsten Seiten einfügen. Ein bis zwei Links reichen nicht für spürbare Fortschritte.
Aus dem Diagramm unten können Sie ersehen, dass der Googlebot URLs häufiger besucht, wenn mehr als 10 Links auf der Seite vorhanden sind.
Verknüpfungen
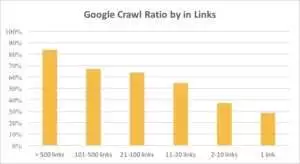
Je größer eine Website ist, desto bedeutender ist die Anzahl der Links auf den Webseiten. Diese Daten stammen tatsächlich von Websites mit über 1 Million Seiten.

Wenn Sie feststellen, dass Ihre profitablen Seiten weniger als 10 Links enthalten, geraten Sie nicht in Panik. Prüfen Sie zunächst, ob diese Seiten qualitativ hochwertig und profitabel sind. Wenn Sie dies tun, fügen Sie Links auf qualitativ hochwertigen Seiten ohne Eile und mit kurzen Iterationen ein und analysieren Sie die Protokolle nach jedem Schritt.
Inhaltsgröße
Content ist einer der beliebtesten Aspekte der SEO-Analyse. Je relevanter der Inhalt auf Ihrer Website ist, desto besser ist natürlich Ihre Crawl Ratio. Unten sehen Sie, wie dramatisch das Interesse des Googlebots für Seiten mit weniger als 500 Wörtern abnimmt.
Was zu tun ist?
Nach meiner Erfahrung sind fast die Hälfte aller Seiten mit weniger als 500 Wörtern Trash-Seiten. Wir haben einen Fall gesehen, in dem eine Website 70.000 Seiten enthielt, auf denen nur die Kleidergröße aufgeführt war, sodass nur ein Teil dieser Seiten im Index enthalten war.
Prüfen Sie daher zunächst, ob Sie diese Seiten wirklich benötigen. Wenn diese URLs wichtig sind, sollten Sie ihnen relevante Inhalte hinzufügen. Wenn Sie nichts hinzuzufügen haben, entspannen Sie sich einfach und lassen Sie diese URLs so, wie sie sind. Manchmal ist es besser, nichts zu tun, anstatt nutzlose Inhalte zu veröffentlichen.
Andere Faktoren
Die folgenden Faktoren können das Crawl-Verhältnis erheblich beeinflussen:
Ladezeit
Die Geschwindigkeit von Webseiten ist entscheidend für das Crawling und Ranking. Bot ist wie ein Mensch: Er hasst es, zu lange auf das Laden einer Webseite zu warten. Wenn Ihre Website mehr als 1 Million Seiten enthält, lädt der Suchbot wahrscheinlich fünf Seiten mit einer Ladezeit von 1 Sekunde herunter, anstatt auf eine Seite zu warten, die in 5 Sekunden geladen wird.
Was zu tun ist?
Tatsächlich ist dies eine technische Aufgabe und es gibt keine „one-method-fits-all“-Lösung, wie z. B. die Verwendung eines größeren Servers. Die Hauptidee besteht darin, den Engpass des Problems zu finden. Sie sollten verstehen, warum Webseiten langsam geladen werden. Erst nachdem der Grund bekannt ist, können Sie Maßnahmen ergreifen.
Verhältnis von einzigartigem und vorlagenbasiertem Inhalt
Das Gleichgewicht zwischen eindeutigen und Vorlagendaten ist wichtig. Zum Beispiel haben Sie eine Website mit Variationen von Tiernamen. Wie viele relevante und einzigartige Inhalte können Sie wirklich zu diesem Thema sammeln?
Luna war der beliebteste „Promi“-Hundename, gefolgt von Stella, Jack, Milo und Leo.
Such-Bots geben ihre Ressourcen nicht gerne für diese Art von Seiten aus.
Was zu tun ist?
Halten Sie das Gleichgewicht. Benutzer und Bots mögen es nicht, Seiten mit komplizierten Vorlagen, vielen ausgehenden Links und wenig Inhalt zu besuchen.
Verwaiste Seiten
Verwaiste Seiten sind URLs, die nicht in der Website-Struktur enthalten sind und von denen Sie nichts wissen, aber diese verwaisten Seiten könnten von Bots gecrawlt werden. Schauen Sie sich zur Verdeutlichung den Euler-Kreis im Bild unten an:

Sie sehen den Normalzustand für die junge Website, deren Struktur schon seit einiger Zeit unverändert ist. Es gibt 900.000 Seiten, die Sie und der Crawler analysieren können. Etwa 500.000 Seiten werden von Crawlern verarbeitet, sind aber Google unbekannt. Wenn Sie diese 500.000 URLs indexierbar machen, wird Ihr Traffic mit Sicherheit steigen.
Achtung: Auch eine junge Website enthält einige Seiten (der blaue Teil im Bild), die nicht in der Website-Struktur enthalten sind, aber regelmäßig von Bots besucht werden.
Und diese Seiten könnten Müllinhalte enthalten, wie z. B. nutzlose automatisch generierte Besucheranfragen.
Aber große Websites sind selten so genau. Sehr oft sehen Webseiten mit Historie so aus:

Hier ist das andere Problem: Google weiß mehr über Ihre Website als Sie. Es können gelöschte Seiten, Seiten auf JavaScript oder Ajax, defekte Weiterleitungen und so weiter und so weiter sein. Einmal standen wir vor einer Situation, in der aufgrund eines Programmierfehlers eine Liste mit 500.000 defekten Links in der Sitemap auftauchte. Nach drei Tagen war der Fehler gefunden und behoben, aber der Googlebot besuchte diese defekten Links schon seit einem halben Jahr!
So oft wird Ihr Crawl-Budget häufig auf diesen verwaisten Seiten verschwendet.
Was zu tun ist?
Es gibt zwei Möglichkeiten, dieses potenzielle Problem zu beheben: Die erste ist kanonisch: das Durcheinander aufräumen. Organisieren Sie die Struktur der Website, fügen Sie interne Links korrekt ein, fügen Sie verwaiste Seiten zum DFI hinzu, indem Sie Links von indizierten Seiten hinzufügen, stellen Sie die Aufgabe für Programmierer ein und warten Sie auf den nächsten Googlebot-Besuch.
Der zweite Weg ist prompt: Sammeln Sie die Liste der verwaisten Seiten und prüfen Sie, ob sie relevant sind. Wenn die Antwort „Ja“ lautet, erstellen Sie die Sitemap mit diesen URLs und senden Sie sie an Google. Dieser Weg ist einfacher und schneller, aber nur die Hälfte der verwaisten Seiten wird im Index sein.
Das nächste Level
Die Algorithmen von Suchmaschinen haben sich seit zwei Jahrzehnten verbessert, und es ist naiv zu glauben, dass das Crawlen der Suche mit ein paar Grafiken erklärt werden könnte.
Wir sammeln mehr als 200 verschiedene Parameter für jede Seite, und wir gehen davon aus, dass diese Zahl bis Ende des Jahres steigen wird. Stellen Sie sich vor, Ihre Website ist die Tabelle mit 1 Million Zeilen (Seiten) und multiplizieren Sie diese Zeilen mit 200 Spalten, die einfache Stichprobe reicht für eine umfassende, technische Prüfung nicht aus. Sind Sie einverstanden?
Wir entschieden uns, tiefer einzutauchen und nutzten maschinelles Lernen, um herauszufinden, was das Crawling von Googlebots jeweils beeinflusst.

Zum einen sind Website-Links entscheidend, zum anderen der Inhalt.
Der Hauptpunkt dieser Aufgabe bestand darin, einfache Antworten aus komplizierten und massiven Daten zu erhalten: Was auf Ihrer Website beeinflusst die Indexierung am meisten? Welche URL-Cluster sind mit denselben Faktoren verbunden? Damit Sie umfassend damit arbeiten können.
Vor dem Herunterladen und Analysieren von Protokollen auf unserer HotWork-Aggregator-Website erschien mir die Geschichte über verwaiste Seiten, die für Bots sichtbar sind, aber nicht für uns, unrealistisch. Aber die tatsächliche Situation überraschte mich noch mehr: Crawl zeigte 500 Seiten mit 301-Weiterleitung, aber Yandex fand 700.000 Seiten mit demselben Statuscode.
Üblicherweise speichern Technikfreaks keine Logfiles, da diese Daten die Festplatten „überlasten“. Aber objektiv betrachtet funktioniert auf den meisten Webseiten mit bis zu 10 Millionen Visits im Monat die Grundeinstellung der Logspeicherung einwandfrei.
Apropos Protokollvolumen: Die beste Lösung besteht darin, ein Archiv zu erstellen und es auf Amazon S3-Glacier herunterzuladen (Sie können 250 GB Daten für nur 1 US-Dollar speichern). Für Systemadministratoren ist diese Aufgabe so einfach wie eine Tasse Kaffee zu kochen. Historische Protokolle werden in Zukunft dabei helfen, technische Fehler aufzudecken und den Einfluss der Google-Updates auf Ihre Website abzuschätzen.