
Apache Apex –はじめに
公開: 2015-12-29Apache Hadoopは、信頼性が高く、スケーラブルで、分散型の大規模コンピューティングのための事実上のソフトウェアフレームワークになりました。 創業以来、Hadoopはバッチ処理の第一選択のフレームワークでした。 大手銀行からオンライン小売大手まで、誰もが定期的なレポートの生成、計算、その他多くのユースケースにHadoopを使用しています。 通常、これらのユースケースはバッチ指向のプロセスであり、データから意味を引き出すまでに数時間かかります。 今日の迅速な世界では、生データが生成されるほとんどの時点で、生データから意味やアクションが必要になります。 これは、ストリーム処理の概念につながりました。 Hadoopは元々ストリーム処理に適しているとは考えられていませんが、YARN(Hadoop 2.0)の発明により、Hadoopはその候補になりました。 現在、Hadoopエコシステムには複数のストリーム処理フレームワークがあり、Apexはこの混雑した市場に参入するまったく新しいフレームワークです。
Apache Apexとは何ですか?
Apache ApexはネイティブのYARNベースのプラットフォームであり、アプリケーション開発者がストリーム指向およびバッチ指向のアプリケーションを作成するのに役立ちます。 移動中のデータを、分散型でパフォーマンスが高く、フォールトトレラントな方法で処理するように設計されています。 これをアイシングするのは簡単なAPIであり、ユーザーはストリーム処理の知識が限られていてもJavaコードを記述できます。
Apexは、機能仕様と運用仕様を別々に組み合わせたものではなく、それらを組み合わせたものに基づいています。 これにより、アプリケーション開発者は、分散環境でどのように動作するかを考えることなく、ユーザー定義関数の作成に集中できます。
Apache Apexには、一般的に使用される関数の豊富なライブラリがあります。 これらは、ApacheApex-Malharライブラリの一部として追加されます。 このライブラリには、さまざまなファイルシステム、データベース、メッセージキューにアクセスするための演算子があります。 コミュニティは、アプリケーション開発者の生活をより楽にするために、オペレーターの日々を追加しています。
Apache Apexのコアブロックとは何ですか?
Apexのアーキテクチャは非常にシンプルです。 Apexには、操作するオペレーターライブラリおよびコアエンジンであるMalharがあります。 Apexのコアは、次のように表すことができます。これらは、ApacheApexの主要なブロックと呼ばれることがよくあります。
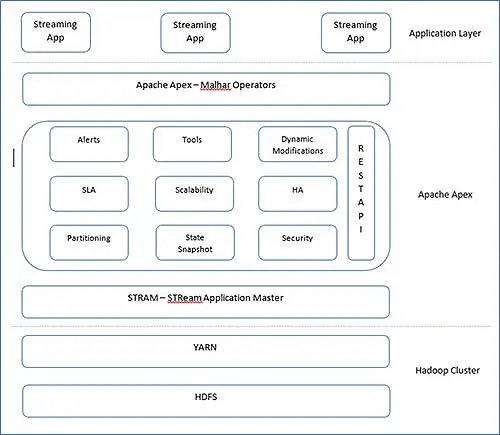
レイヤーを明確に分離し、適切な場所の概要を把握できます。 これらのブロックに関する情報を見てみましょう。
- StrAM( Str eam A pplication M aster)
StrAMはYARNアプリケーションマスターです。 その責任には、ストリームアプリケーションの起動、リソースの割り当て、論理DAGのスケジューリングが含まれます。 これらのYARN操作に加えて、StrAMは演算子、ストリームを初期化します。 StrAMは、その子から統計も収集します。 - 状態スナップショット
ストリーム処理フレームワークは、処理された結果を失う余裕がありませんでした。 さらに、障害から回復した後にレコードを正しく処理するために、処理した量を知る必要があります。 したがって、定期的に、チェックポインティングはストリーム処理で重要です。 Apexでは、StrAMはチェックポインティングを追跡し、オペレーターの境界で、HDFSで定期的にチェックポインティングが実行されます。 - REST API
StrAMはRESTAPIのアクセスポイントです。 外部ツールはこのRESTAPIにアクセスでき、外部アプリケーションと統合できます。 - ツール
Apexは、Apexアプリケーションを起動および監視するためのCLIを提供します。 私たちでさえ、RESTAPIの助けを借りて独自のものを構築することができます。 CLIに加えて、アプリケーションは自動起動用の静的構成スクリプトを使用して構成できます。 - パーティショニング
- 動的な変更
- SLA分析
Apache Apexは、独自にSLA分析を定期的に実行します。 遅延、ボトルネック、スループットの分析を行い、構成されたSLAを満たすためにリソースを追加します。 - 安全
- 高可用性
Apache Apexは、YARNの再起動機能を利用し、最後のチェックポイント状態から再起動します。 - マルハー
Apache Apex –Malharは、多数の演算子を備えた演算子のライブラリです。 これらの演算子は次のように分類されます - 入出力演算子–
このカテゴリでは、現在、Malharには読み取り/書き込みを行うための演算子があります - ファイルシステム
- RDBMS
- NoSQLストア
- メッセージキュー
- インメモリデータベース
- ソーシャルメディア
- 計算演算子–
- パターンマッチング
- 統計と数学
- 機械学習
- パーサー
- ソーシャルメディア
- バッファサーバー
Apexは、キーと動的な負荷分散に基づいたパーティショニングを提供します。 ユーザーでさえ、独自のパーティションスキームを定義できます。
Apache Apexには、この非常に便利でユニークな機能があります。 論理DAGの変更、物理実行プランの変更をサポートします。
ApexはKerberosをサポートしています。 基盤となるセキュリティで保護されたHadoopクラスターは、固有のKerberos統合でアクセスできます。
Malharには、実際のビジネスロジックの実装を支援する多くの演算子があります。 このライブラリには
バッファーサーバーは、各オペレーターの境界にあります。 データの場合、ローカルオペレーターバッファーサーバーは、オペレーターの文字列の後に置くことができます。 それらの主な目的は、次へ転送する前にエッジでデータを一時的に保持することです。 これらは、ノードが障害から回復するときに重要な役割を果たします。 バッファサーバーは、最後のチェックポイント状態からデータをロードして再生します
Apexアプリケーションプログラミングモデルとは何ですか?
これは、豊富なフレームワークとMalharライブラリを備えているため、アプリケーション開発者はオペレーターを接続してアプリケーションを起動するだけで済みます。 したがって、アプリケーションは一連の演算子にすぎません。

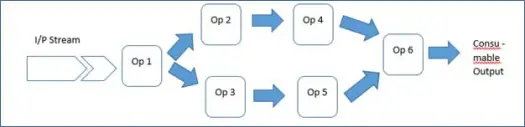
これが、豊富なフレームワークが開発者の生活を楽にする方法です。 では、このデモアプリケーションがどのように実行されるかを見てみましょう
ApacheApexデモ
それでは、 ApacheApexを使用した単語数の小さなデモである「HelloWorldofBigDataJ」から始めましょう。
ApacheApexのセットアップ
このデモを実行するには、Apexを構成する必要があります。 Apache Apexを既存のクラスターにインストールするか、試してみる簡単な方法があります。インストール前のサンドボックスVMをDataTorrentWebサイトからダウンロードできます。 このデモでは、プリインストールされたVMを使用します。
ウォークスルーApexUIコンソール
Apexには、アプリケーションの起動、監視、および管理に使用できる、非常に直感的で美しくデザインされたUIコンソールが付属しています。 これには、デプロイされているさまざまなコンポーネントに関するさまざまな統計が含まれています。
その後、サンドボックスVMをダウンロードし、UnTarして、お気に入りのVMプレーヤーにロードします(私はVMWare VMプレーヤーを使用しています)。 Apexの実行に必要なすべてのソフトウェアとツールは、このVMですでに構成されており、すべての起動スクリプトはOSの起動時に実行されるように構成されています。 したがって、VMが起動すると、ApacheApexのインスタンスが実行されます。 ここで、コンソールを表示するには、お気に入りのWebブラウザーでhttp:// locahost:9090を押して、コンソールにログインします。 デフォルトのユーザー名:サンドボックスVMのパスワードはdtadmin:dtadminです。 以下のようなコンソールが表示されます
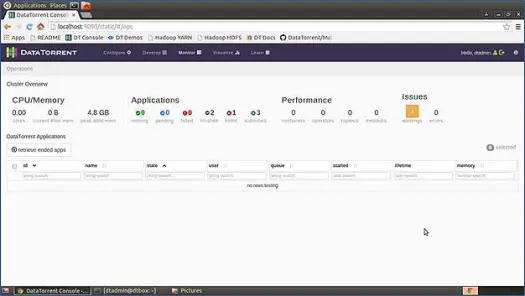
このページでは、CPUとメモリの使用量、アプリケーション、パフォーマンス、問題など、すべてのシステムの完全な概要を説明します。
アプリケーションをデプロイするには、ページ上部の[開発]タブに移動します。
ここでは、アプリケーションパッケージをデプロイし、Apex内のデータのタプルスキーマを管理できます。
Apexは、すぐに使用できる多数のアプリケーションを提供します。これらのアプリケーションを以下に示します。
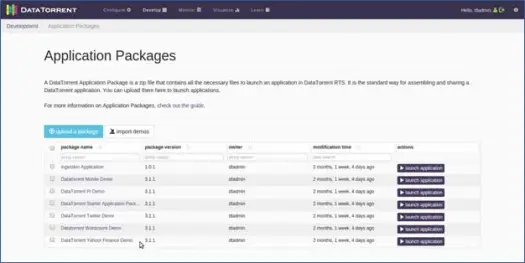
WordCountデモ
それでは、単語数アプリケーションを起動しましょう。 これを行うには、DataTorrentWordcountDemoの横にあるアプリケーションの起動オプションをクリックします。 次に、アプリケーションに別のものを提供し、必要に応じて構成の詳細を変更できます(ほとんどのデフォルトは正常に機能するため、これは行いません。アプリ名を「MyWordCountDemo」に変更してみましょう)。 アプリケーションへのリンクとともに、アプリケーションが正常にデプロイされたことを示すメッセージが表示されます。 そのリンクをクリックしてください。

これにより、新しいページが開きます。 アプリケーションのステータスがAcceptedからRunningに変わるまで数秒待ちます。 これで、さまざまな統計と情報が満載のページが表示されます。 次の2つのスクリーンショットはそれらを示しています。
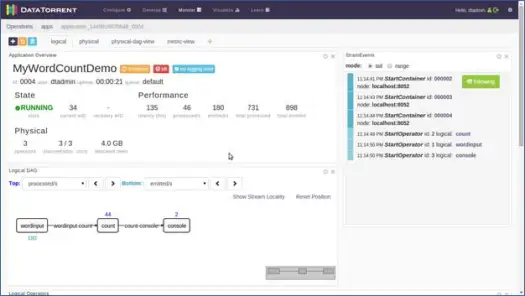
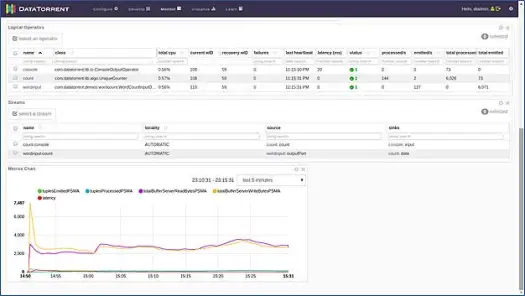
このページには、アプリケーションの論理ビュー、物理ビュー、メトリックビューなどのさまざまな情報と、アプリケーションによって毎秒処理されるさまざまなタプル/レコードの統計が表示されます。 放出されるタプルやレイテンシーなどをグラフィカルに表示します。
論理演算子のいずれかをクリックして、そのレコードを調べ、サンプルを記録することもできます。 コンソールオペレータのためにそれをやってみましょう。 コンソール演算子をクリックすると、以下のように演算子に関する詳細情報が表示されます。
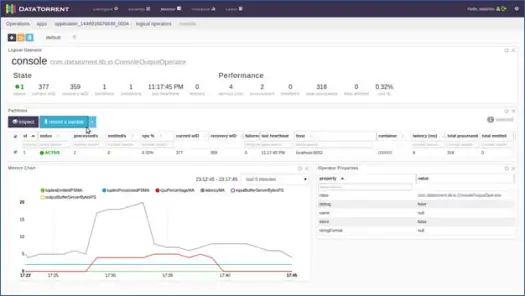
次に、パーティションの1つを選択し、[サンプルの記録]をクリックします。
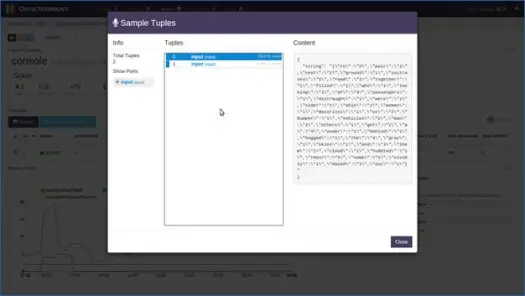
数秒後、タプルが入力されていることがわかります。タプルをクリックしてコンテンツを表示します。 コンテンツからわかるように、アプリケーションはウィンドウに基づいてデータに対して単語数を実行し、このウィンドウの0番目の入力タプルに2つの「to」、4つの「the」、4つの「a」などがありました。 これで、アプリケーションのメインページで[シャットダウン]または[強制終了]をクリックして、アプリケーションを停止できます。
これで、単語数アプリケーションの展開と実行に成功しました。
結論
これが、新しいストリーミングツールであるApache Apexの紹介であり、ApacheApexでのアプリケーションの実行に成功しました。 Apache Apexには多くの顕著な機能があり、以降の投稿で取り上げる他の既存のフレームワークよりも優れています。