
Apache Spark:ビッグデータの大空に輝くスター。
公開: 2015-09-24- 適切な顧客に何百万もの製品を推奨します。
- 検索履歴を追跡し、フライトの旅の割引価格を提供します。
- 人の技術的スキルを比較し、あなたの分野でつながる人を適切に提案します。
- 数十億のモバイルオブジェクト、ネットワークタワー、通話トランザクションのパターンを理解し、通信ネットワークの最適化を計算したり、ネットワークの抜け穴を見つけたりします。
- センサーの何百万もの機能を研究し、センサーネットワークの障害を分析します。
上記のすべてのタスクで正しい結果を得るために使用する必要のある基礎となるデータは、比較的非常に大きいものです。 従来のシステムでは(空間と時間の両方の観点から)効率的に処理することはできません。
これらはすべてビッグデータのシナリオです。
この種の膨大なデータを収集、保存、計算するには、専用のクラスターコンピューティングシステムが必要です。 Apache Hadoopは、この問題を解決してくれました。
分散ストレージシステム(HDFS)と並列コンピューティングプラットフォーム(MapReduce)を提供します。
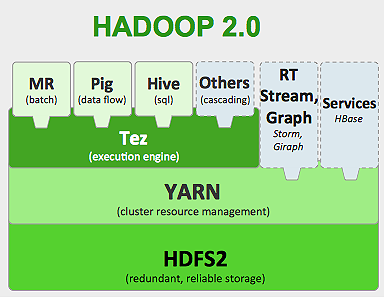
Hadoopフレームワークは次のように機能します。
- 大きなデータファイルを小さなチャンクに分割して、個々のマシンで処理します(ストレージの分散)。
- 長いジョブを小さなタスクに分割して、並列実行します(並列計算)。
- 障害を自動的に処理します。
Hadoopの制限
Hadoopのエコシステムには、さまざまなタスクを実行するための専用ツールがあります。 したがって、アプリケーションのエンドツーエンドのライフサイクルを実行する場合は、複数のツールを使用する必要があります。 たとえば、 SQLクエリの場合はhive / pigを使用し、ストリーミングソースの場合はHadoop組み込みストリーミングまたはApache Storm (Hadoopエコシステムの一部ではありません)を使用する必要があり、機械学習アルゴリズムの場合はMahoutを使用する必要があります。 これらすべてのシステムを統合して単一のデータパイプラインのユースケースを構築することは、かなりの作業です。
MapReduceジョブでは、
- すべてのマップタスクの出力は、ローカルディスク(またはHDFS)にダンプされます。
- Hadoopは、すべてのスピルファイルをより大きなファイルにマージします。このファイルは、レデューサーの数に従って並べ替えられ、パーティション化されます。
- そして、reduceタスクはそれをメモリに再度ロードする必要があります。
このプロセスにより、ジョブが遅くなり、ディスクI/OとネットワークI/Oが発生します。 これにより、Mapreduceは、同じグループのデータに機械学習アルゴリズムを何度も適用する必要がある反復処理には適していません。
Apache Sparkの世界に入る:
Apache Sparkは、2009年にカリフォルニア大学バークレー校のAMPLABで開発され、2010年には、これまでApacheのトップ貢献のオープンソースプロジェクトになりました。
Apache Sparkはより一般化されたシステムであり、バッチジョブとストリーミングジョブの両方を一度に実行できます。 これは、メモリ内のデータをより高速に処理する機能を追加することにより、以前のMapReduceの速度に取って代わります。 また、ディスク上でより効率的です。 基本データユニットRDD(Resilient Distributed Dataset)を使用してメモリ処理を活用します。 これらは、ジョブの完全なライフサイクルのために可能な限り多くのデータセットをメモリに保持するため、ディスクI/Oを節約できます。 一部のデータは、メモリの上限を超えるとディスクに流出する可能性があります。
以下のグラフは、ロジスティック回帰を計算するためのApacheHadoopとSparkの両方の実行時間を秒単位で示しています。 Hadoopは110秒かかりましたが、sparkはわずか0.9秒で同じジョブを終了しました。
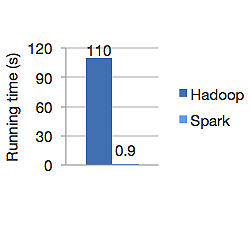
Sparkはすべてのデータをメモリに保存するわけではありません。 ただし、データがメモリ内にある場合は、LRUキャッシュを最大限に活用してデータをより高速に処理します。 メモリ内のデータを計算している間は100倍高速であり、ディスク上ではHadoopよりも高速です。
Sparkの分散データストレージモデルである復元力のある分散データセット(RDD)は、フォールトトレランスを保証し、ネットワークI/Oを最小限に抑えます。 スパークペーパーは言う:

「RDDは系統の概念を通じてフォールトトレランスを実現します。RDDのパーティションが失われた場合、RDDには、そのパーティションだけを再構築できるように、他のRDDからどのように派生したかに関する十分な情報があります。」
したがって、フォールトトレランスを実現するためにデータを複製する必要はありません。
Spark MapReduceでは、出力がディスクにスピルされて再度読み取られるHadoopとは異なり、マッパーの出力はOSバッファーキャッシュに保持され、レデューサーはそれをサイドにプルしてメモリに直接書き込みます。
Sparkのメモリキャッシュは、同じデータを何度も使用する必要がある機械学習アルゴリズムに適しています。 Sparkは、Direct Acyclic Graph(DAG)を使用して、複雑なジョブ、複数ステップのデータパイプラインを実行できます。
SparkはScalaで記述されており、JVM(Java仮想マシン)で実行されます。 Sparkは、Java、Scala、Python、およびR言語用の開発APIを提供します。 SparkはHadoopYARN、Apache Mesosで実行され、独自のスタンドアロンクラスターマネージャーを備えています。
2014年には、わずか23分で100TBデータ(1兆レコード)のベンチマークをソートすることで世界記録の1位を獲得しましたが、YahooによるHadoopの以前の記録は約72分でした。 これは、スパークソートされたデータが3倍速く、10分の1のマシンであることが証明されています。 すべての並べ替えは、実際にスパークインメモリキャッシュ機能を使用せずに、ディスク(HDFS)で行われました。
スパークエコシステム
Sparkは、次のコンポーネントを提供することを実現するために、高度な分析を一度に実行することを目的としています。
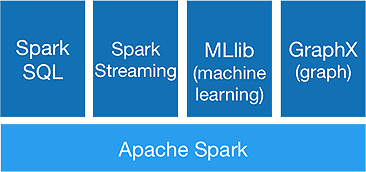
1.スパークコア:
SparkコアAPIは、Apache Sparkフレームワークのベースであり、ジョブスケジューリング、タスク分散、メモリ管理、I / O操作、および障害からの回復を処理します。 Sparkの主要な論理データユニットはRDD(Resilient Distributed Dataset)と呼ばれ、後で並列処理されるように分散された方法でデータを格納します。 それは怠惰に操作を計算します。 したがって、メモリを常に占有する必要はなく、他のジョブがそれを利用できます。
2.Spark SQL:
低レイテンシでインタラクティブなクエリ機能を提供します。 新しいDataFrameAPIは、構造化データと半構造化データの両方を保持し、すべてのSQL操作と関数で計算を実行できるようにします。
3.スパークストリーミング:
マイクロバッチでデータを収集して処理するリアルタイムストリーミングAPIを提供します。
これは、RDDの連続シーケンスに他ならないDstreamを使用して、受信データのビジネスロジックを計算し、結果を即座に生成します。
4.MLlib :
これは、 Sparkの機械学習ライブラリ(Mahoutの約9倍高速)であり、機械学習だけでなく、分類、回帰、協調フィルタリングなどの統計アルゴリズムを提供します。
5.GraphX :
GraphX APIは、グラフを処理し、グラフ並列計算を実行する機能を提供します。 PageRankなどのグラフアルゴリズムや、グラフを分析するためのさまざまな関数が含まれています。
SparkはHadoop時代の終わりを示しますか?
Sparkはまだ若いシステムであり、Hadoopほど成熟していません。 HBaseのようなNOSQL用のツールはありません。 より高速なデータ処理のための高いメモリ要件を考慮すると、それがコモディティハードウェアで実行されているとは言えません。 Sparkには独自のストレージシステムはありません。 そのためにHDFSに依存しています。
そのため、Hadoop MapReduceは、データのパイプライン処理があまり含まれていない特定のバッチジョブに適しています。
「新しいテクノロジーが古いテクノロジーに完全に取って代わることは決してありません。 どちらかと言えば共存したいのです。」
結論
このブログでは、Sparkのようなツールが必要な理由、クラスターコンピューティングシステムとそのコアコンポーネントを高速化する理由について説明しました。 次のパートでは、SparkコアAPI RDD、変換、およびアクションについて詳しく説明します。