
10億通のメールで朝食
公開: 2020-02-05スムーズなブラックフライデーは私たちが求めるすべてです
ブラックフライデーの週末の毎日午前8時頃の太平洋標準時(PST)に朝食をとるまでに、Twilio SendGridは米国東部標準時(EST)で計算された10億通以上の電子メールをすでに処理していました。
統計を見ると、感謝祭からサイバーマンデーまでの165億通以上のメールを処理し、感謝祭の前の火曜日から始まる1週間は223億通以上のメールを処理しました。 これらはビジネスにとって本当に良い数字です。 エンジニアリング組織の観点からは、アラートが発生したり、顧客エクスペリエンスが低下したりすることなくこれを行うことは、非常に満足のいくものでした。
同僚のSaraSaediniaが書いた、このブログ記事「1日で40億通以上のメールをインフラストラクチャにスケーリングする」を読むことをお勧めします。このブログ記事では、この規模でスムーズに運用することの重要性について説明しています。 ここでは、メールのお客様にとって1年で最も重要な週末をこれまでで最もスムーズにした準備に焦点を当てます。
どうやってこれをシームレスなブラックフライデーの週末にしたのですか? 最大の送信日数を処理するには、綿密な計画、多数の地域スイングテスト、データを分析する多数の人々、およびテレメトリ観測に基づいてシステムの改善を検証する際のフィードバックループの強化が必要です。 お客様を喜ばせ続け、適切な通信を適切な受信者に迅速に送信できるようにするために、さらに多くの自動化と改善を行っています。
私たちのビジネスを理解する
SendGridのビジネスモデルでは、常に稼働している必要があります。メールを受け入れて配信するためのメンテナンスウィンドウはありません。 お客様は、メールを途切れることなく受け入れて配信する信頼性の高いサービスを求めています。 つまり、ハードウェアとソフトウェアのすべてのインフラストラクチャの変更は、目立った遅延なしに電子メールの処理と配信を継続しながら行う必要があります。
次のグラフに示すように、処理する電子メールの数は過去数年間で大幅に増加しています。
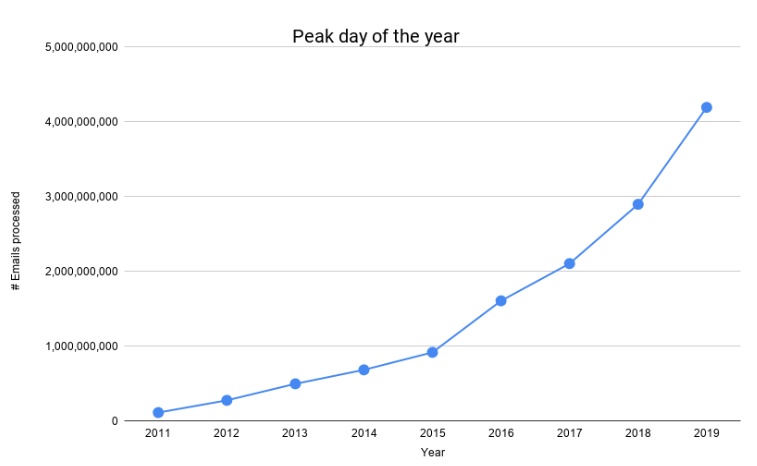
2016年半ばに最初の1B日があり、このブラックフライデーに最初の4B日がありました。 これは、4年以内に400%の成長です。 増え続ける規模に対応し、コストを管理しやすくし、お客様の信頼性を高めるために、メール処理パイプラインを再設計および進化させる必要がありました。
ブラックフライデーが来ています
人々は私に「なぜブラックフライデーとサイバーマンデーはあなたにとってとても重要なのですか?」と尋ねます。 今週のサイバーマンデーでは、前年のピークより45%多くのメールを処理しました。 ブラックフライデーは、米国で最も重要な小売および支出イベントの1つです。 伝統的に、それは小売業者がその年の黒字(正味プラス)になる日です。 EメールマーケティングとトランザクションEメールの使用は、すべてのビジネスにとって重要になっています。
小売業者からマーケティングの自動化を提供する企業まで、ブラックフライデーの週末に確実にメールを配信する際に問題が発生すると、収益が大幅に減少する可能性があります。 結果として、今週末は私たちにとって週末を定義するビジネスであることがよくあります。 私たちは、エンジニア、サポートエージェント、カスタマーサクセスマネージャー、エグゼクティブ、そして最も重要なこととして、お客様のためにできる限り簡単にするために最善を尽くしています。
ブラックフライデーの準備
では、ブラックフライデーに向けてどのように準備するのでしょうか。 Tシャツを買います! (そして、たくさんの仕事をします。)私たちがどのように準備するかについて読んでください。
Twilio SendGridIrvineOfficeのメンバー

TwilioSendGridデンバーオフィスのメンバーの一部。

統計
いくつかの統計から始めましょう:
- ブラックフライデーで41億通以上のメールを処理し、サイバーマンデーで42億通以上のメールを処理しました
- 感謝祭からサイバーマンデーまでの165億通以上のメールを処理
- ピーク時に3億1500万通以上のメールを処理
- ブラックフライデーとサイバーマンデーは、それぞれ8時間連続で2億2,000万通以上のメールを処理していました。
- これはすべて、配信可能な電子メールのエンドツーエンド時間の中央値が1.9秒である
- 平均して、メッセージごとにおよそ5.5のイベントを発行します。 これに基づいて、私たちのシステムは、感謝祭からサイバーマンデーまでの91億以上のイベント、サイバーマンデーだけで23億以上のイベントを発行および処理しました。
課題
これまでに見たことのないスケール:テストの対象となるスケールは、予測されるピーク負荷と一致する必要があります。 昨年の準備のために4月上旬に最初のテストを行ったとき、平日の平均ボリュームはピーク予測の半分未満でした。 1時間ごとのピークは、テストするピークの半分でもありませんでした。
環境の管理:電子メールはステートフルワークフローです。メッセージの状態を追跡する必要があります。 そのため、メッセージがパイプラインを移動するときに、メッセージがバウンスするか延期されるかを追跡し、重複を防ぎます。 そのため、私たちのメールパイプラインはハイブリッドクラウドとオンプレミスアーキテクチャであり、自動スケーリングは魔法の修正ではありません。 私たちの課題は、データセンターサービスの効率を最大化すると同時に、顧客のコストに影響を与えることなく大量の急増を処理する能力を準備することです。
スケーリングは線形ではありません:すべてのシステムが線形にスケーリングするわけではありません。 予測されるスケールは最初にテストを開始したときよりもはるかに高いため、単純な数学モデルでハードウェアのニーズを計算することはできません。 また、盲目的にスケーリングするサービスは依存関係を過負荷にし、データベースのような依存関係はメール転送エージェント(MTA)と同じようにスケーリングしないことを覚えておくことも重要です。

投資のバランスをとる:革新を続け、メール配信に関連するお客様のニーズを確実にサポートするため、お客様がアクセスできず、必要に応じて機能しない場合、当社の機能はお客様に価値を提供しないことを理解しています。 バランスを見つけ、システムのテスト、学習、アップグレード、および改善に適切に投資して、規模の信頼性と回復力を高める必要があります。 そうすることで、イノベーションへの投資を継続することができます。
どうやってやったの?
私たちは1つのチームとして一緒にそれを行いました。 私たちが言うように、腕を組んで。 今年の4月から11月までの準備には、多くのチームの100人以上のメンバーが参加しました。 ピーク予測のモデリング、可観測性基準の定義、観測からの学習、必要な変更のエンジニアリング、計画、および管理には、複数の人々からのさまざまなスキルが必要です。
私たちはお互いを正直に保ち、集中力を保ち、目標を達成しながら、お互いを信頼しました。
効果的で絶えず改善されているプロセスは私たちの友人でした。
計画
お客様のメールを処理するための3つのデータセンターがあります。 未到達の規模を計画するために、利用可能な2つのデータセンターのみでピーク予測トラフィックを処理できることを検証します。 高可用性SLAを満たすために、インフラストラクチャにはリージョンフェイルオーバーが組み込まれています。 これは、リージョン間でトラフィックをフェイルオーバーする機能があることを意味します。
標準的な運用手順として年間を通じて頻繁にこの機能を活用し、サービス品質を維持しながらブラックフライデー/サイバーマンデーのピークボリュームに対応できることを実証する取り組みの一環として、この機能を加速しています。 システムテレメトリがサービスレベル目標(SLO)のしきい値に近づくと、複数のリージョンをすばやく活用して公称状態を再開できます。 次に、収集したテレメトリを活用して、変更が必要な場所を特定します。
並行して、システムの可用性の正確な数値目標を提供するサービスレベル目標(SLO)と、システムへのプローブの成功頻度を提供するサービスレベルインジケーター(SLI)のレビューと強化を開始しました。
観察、学習、コミュニケーション
各テストは大量の情報を提供しました。 私たちが直面した課題の1つは、ローテーションするテストチーム全体で観察結果を効果的に文書化して伝達し、複数のシステム間でデータを分析することでした。 標準のチームダッシュボードがありますが、各メンバーは、観察する特定の何かを持つことができます。
複数のチームによって管理されている複数のサービスのためにダンプされたすべての技術情報を分析するために、テストチームとのレトロな作業を開始しました。 これらのレトロは長く、ほとんどの期間、テストごとに1つまたは2つのチームにしか役立ちませんでした。 最終的には、レトロなメモにSlackスレッドを使用するようになり、テストごとに数十人の会議時間を節約できました。
テスト管理チームには、2人のエンジニアリングマネージャー、1人のアーキテクトと1人のシニアエンジニアが参加しました。 管理者は計画と依存関係の管理において極めて重要でしたが、より技術的な人々がエンドツーエンドのシステムレベルで情報の処理と分析を支援しました。
入手可能な情報の分析に基づいて、SLIがSLOに厳密に準拠していることを繰り返し検証しました。 システムの潜在的な劣化を事前に特定するために、アラートを微調整し、特定の重要なアラートの感度を高めました。
優先順位付けと実装
提案された変更にチケットを発行し、チームはこれらのチケットに優先順位を付けました。 ここでの最初の課題は、複数のチームボード間でこれらのチケットを管理することでした。 もう1つの課題は、ブラックフライデーの仕事を他の優先事項に対して冷酷に優先することでした。
困難な問題の解決策を考え出すための創造的な自由をエンジニアに提供する必要がありました。 同時に、これらのソリューションが長期計画に沿っていることを確認する必要がありました。 また、私たちが常に利益相反を意識していることも非常に重要でした。つまり、私たちを噛むために戻ってくる可能性のある短期的な解決策を避けることを意味しました。
実装された変更を検証することが、今後のテストの目標になります。
ブラックフライデーに近づいたときにテンポを維持して上げることは、計画と実行における大きな課題でした。
加速
9月に入ると、毎週複数のストレステストを実行し始めました。 これには、問題をより迅速に特定、修正、検証する必要がありました。 それはまた、はるかに速い学習と適応のサイクルを私たちに提供しました。
前述のメールパイプラインのフルスイングテストに加えて、同時にサポートサービスのストレステストも開始しました。 同じ時期に、最大の顧客の1つと負荷テストを実施し、ホリデーシーズン中に予想されるバースト送信を問題なく処理できることを確認しました。
長い時間と仕事の管理の難しさのために、私たちのチームは燃え尽きていました。 必要に応じてテストを停止するために必要な最も重要なアラートをリストアップし、感度を高めました。 これにより、早朝にシステムを監視するために立ち会う必要なしに、テストを開始することができました。
注意してスピードを上げる
9月末に近づくにつれ、正しい方向に十分な速さで進んでいないのではないかという懸念がありました。 私たちはタイガーチームを作成しました。これは、複数のチームにまたがるチケットのいずれかに取り組むことができるスペシャリストのチームであり、日常レベルではるかにスリムなプロセスで作業するチームです。
ブラックフライデーに備えて、運用インフラストラクチャとメール処理ソフトウェアを大幅に改善しました。 これらの変更は明確に優先されており、チームは互いに素晴らしい調整を行う必要がありました。 SendGridを最優先する人々にとっては素晴らしい経験でした。 公開会社のビジネスユニットのコアエンジンをすべてスタートアップのペースで実行しながら、アプリケーション、インフラストラクチャに変更を加え、ハードウェア容量を増やしていました。 何よりも、お客様へのサービスエクスペリエンスを低下させることなく、すべてを実行しました。
今後の計画
2019年のブラックフライデーの準備に多くの人的時間を費やしました。今年の学習は、2020年のブラックフライデーとサイバーマンデーの準備の多くを自動化するのに役立ちます。ストレスのない、記録的な年を迎えることを楽しみにしています。 -私たちの顧客と私たちの従業員のための休日の送信の途方もない量。