
Serverless Framework、AWS、BigQueryを使用したアプリの構築
公開: 2021-01-28サーバーレスとは、サーバーとリソースの管理と割り当てがクラウドプロバイダーによって管理されるアプリケーションを指します。 これは、クラウドプロバイダーがリソースを動的に割り当てることを意味します。 アプリは、イベントによってトリガーされる可能性のあるステートレスコンテナーで実行されています。 上記の例の1つと、この記事で使用する例は、 AWSLambdaに関するものです。
つまり、「サーバーレスアプリケーション」は、イベント駆動型のクラウドベースのシステムであると判断できます。 このアプリは、サードパーティのサービス、クライアント側のロジック、およびリモート呼び出し(直接Function as a Serviceと呼びます)に依存しています。
サーバーレスフレームワークのインストールとAmazonAWS用の設定

1.サーバーレスフレームワーク
サーバーレスフレームワークはオープンソースフレームワークです。 これは、コマンドラインインターフェイスまたはCLIと、完全にサーバーレスのアプリケーション管理システムを提供するホストされたダッシュボードで構成されています。 フレームワークを使用すると、オーバーヘッドとコストが削減され、サーバーレスアプリケーションの迅速な開発と展開、およびセキュリティ保護が保証されます。
Serverless Frameworkのインストールに進む前に、まずNodeJSをセットアップする必要があります。 ほとんどのオペレーティングシステムで実行するのは非常に簡単です。ダウンロードしてインストールするには、公式のNodeJSサイトにアクセスする必要があります。 6.0.0より前のバージョンを選択することを忘れないでください。
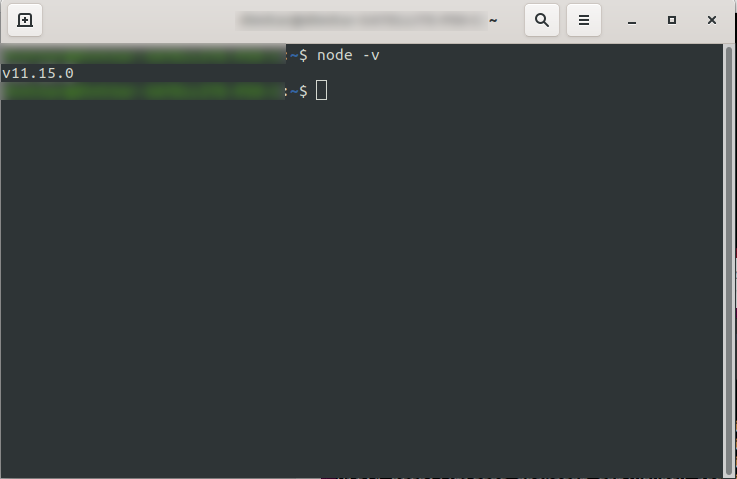
インストール後、コンソールでnode -vを実行することにより、NodeJSが使用可能であることを確認できます。 インストールしたノードのバージョンが返されます。
これで準備が整いました。サーバーレスフレームワークをインストールしてください。
これを行うには、ドキュメントに従ってフレームワークをセットアップおよび構成します。 必要に応じて、1つのプロジェクトにのみインストールできますが、DevriXでは通常、フレームワークをグローバルにインストールします。npm npm install -g serverless
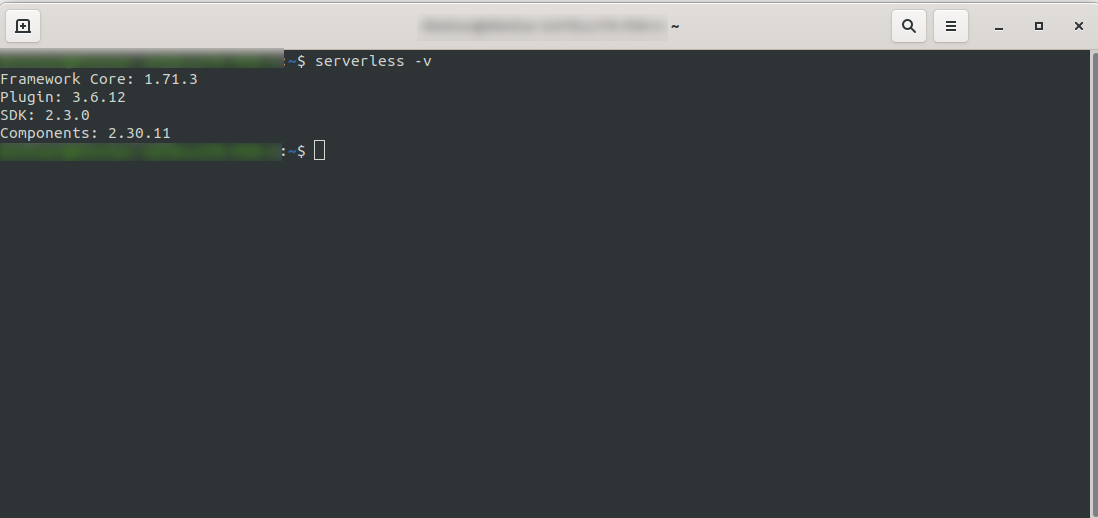
プロセスが終了するのを待ち、次のコマンドを実行してサーバーレスが正常にインストールされたことを確認しますserverless -v
2.AmazonAWSアカウントを作成します
サンプルアプリケーションの作成に進む前に、 AmazonAWSでアカウントを作成する必要があります。 まだお持ちでない場合は、Amazon AWSにアクセスし、右上隅にある[Create a AWS account ]をクリックして、手順に従ってアカウントを作成するだけです。
Amazonではクレジットカードの入力が必要なため、その情報を入力せずに続行することはできません。 登録とログインが成功すると、AWSマネジメントコンソールが表示されます。
すごい! それでは、アプリケーションの作成に進みましょう。
3. AWSプロバイダーを使用してサーバーレスフレームワークを構成し、サンプルアプリケーションを作成します
このステップでは、AWSプロバイダーを使用してサーバーレスフレームワークを設定する必要があります。 AWS Lambdaなどの一部のサービスには、そのサービスが所有するリソースへのアクセス許可があることを確認するために、それらにアクセスするときに資格情報が必要です。 AWSでは、AWS Identity and Access Manager(IAM)を使用してこれを実現することをお勧めします。
したがって、最初で最も重要なことは、 AWSでIAMユーザーを作成して、アプリケーション内で使用することです。
AWSコンソールで:
- [サービスの検索]フィールドにIAMと入力します。
- 「IAM」をクリックします。
- 「ユーザー」に移動します。
- 「ユーザーの追加」をクリックします。
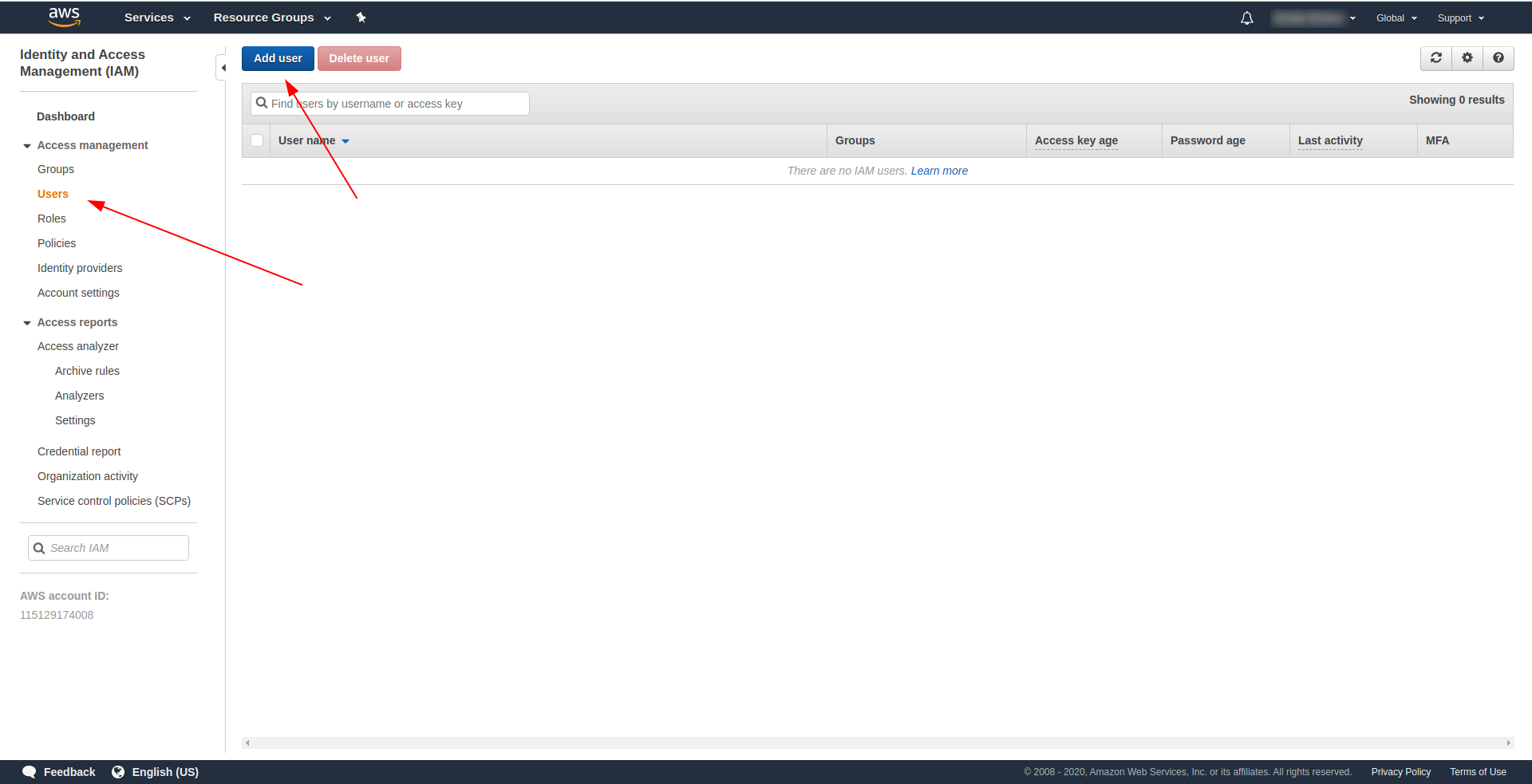
「ユーザー名」には、好きなものを使用してください。 たとえば、 serverless-adminを使用しています。 「アクセスタイプ」については、 「プログラムによるアクセス」にチェックを入れ、 「次の権限」をクリックしてください。
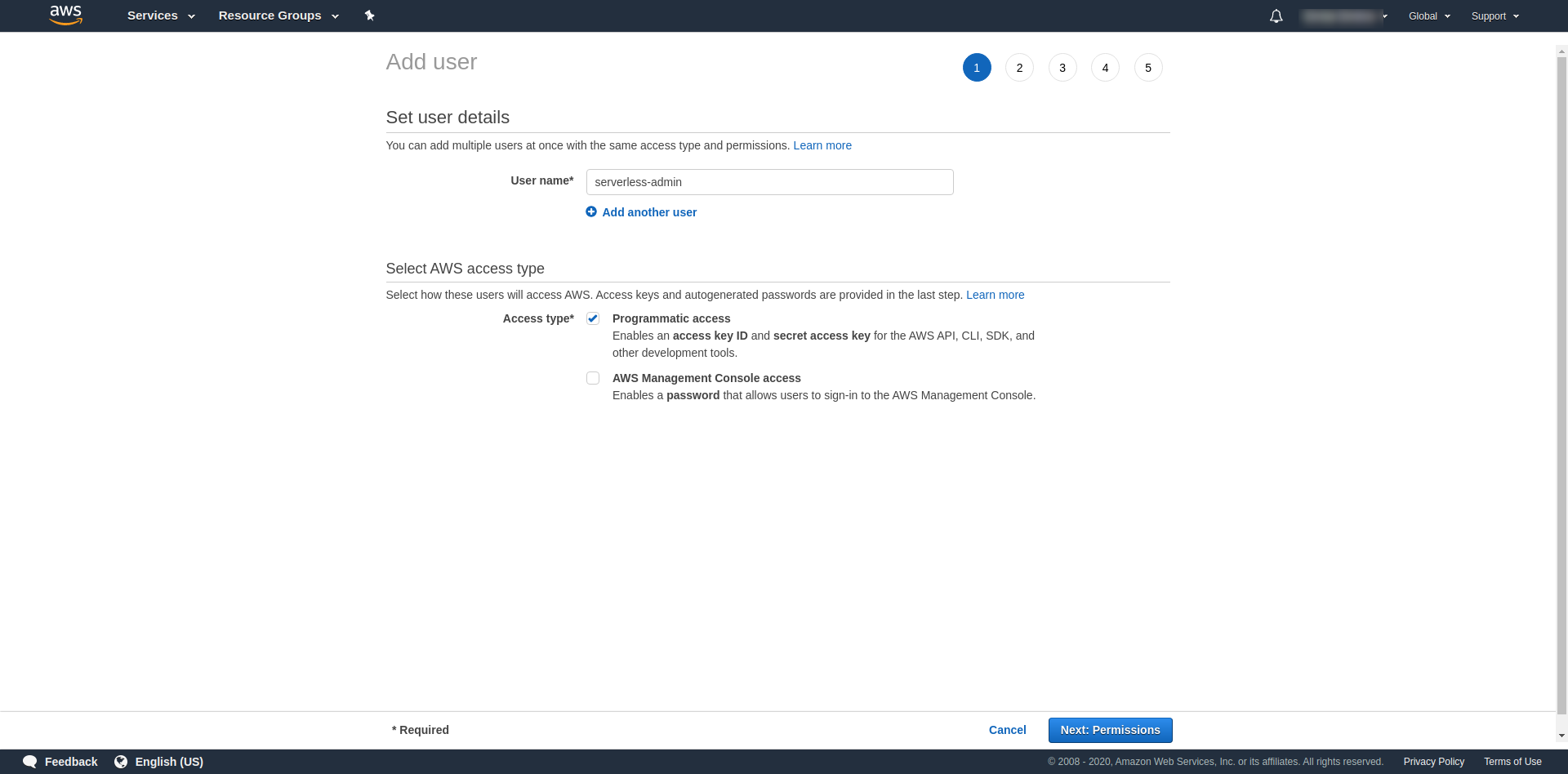
その後、ユーザーの権限を添付し、「既存のポリシーを直接添付」をクリックし、 「管理者アクセス」を検索してクリックする必要があります。 「次のタグ」をクリックして続行します
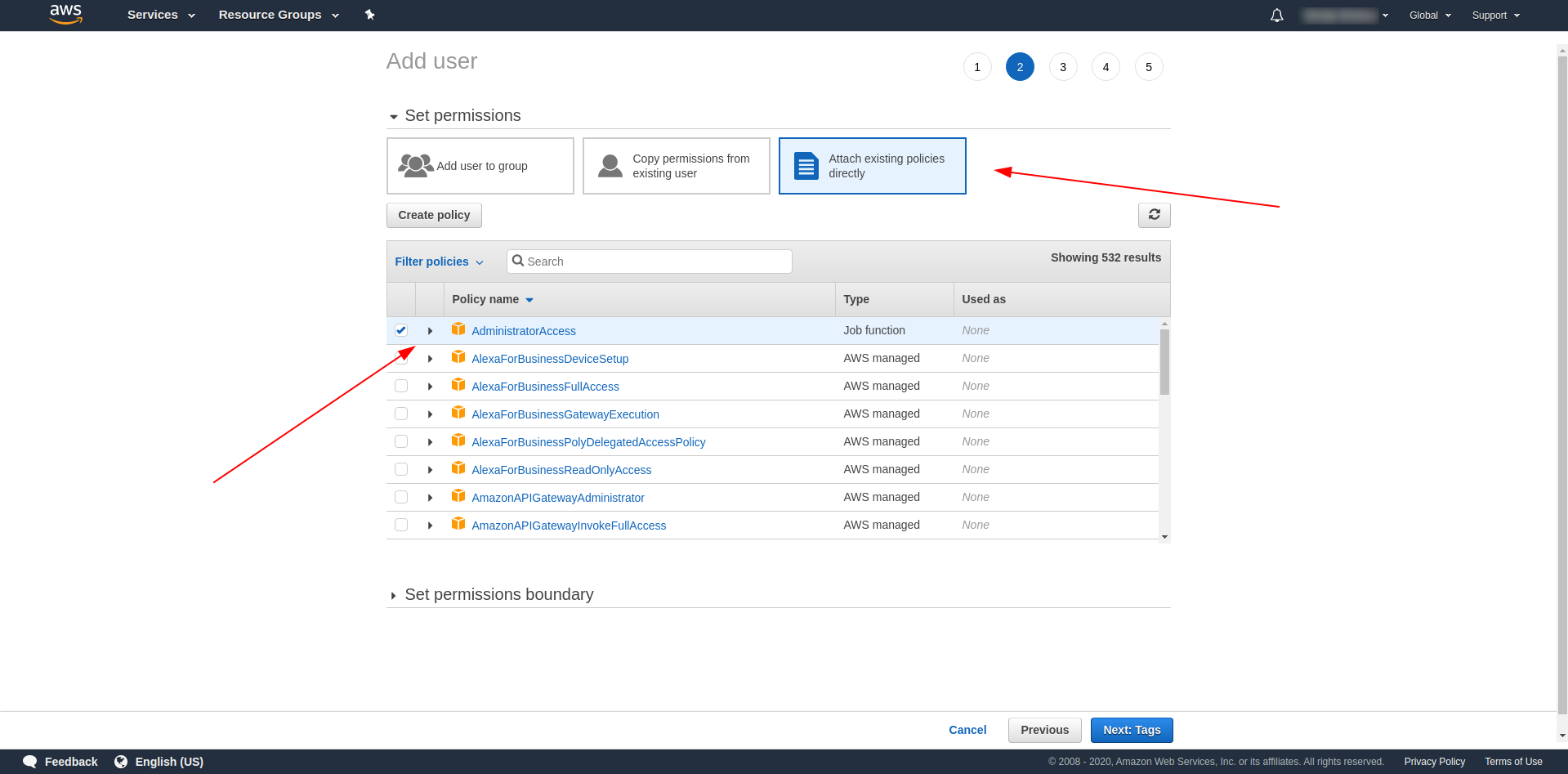
タグはオプションなので、 「次のレビュー」と「ユーザーの作成」をクリックして続行できます。 完了してロードされると、必要な資格情報を含む成功メッセージがページに表示されます。
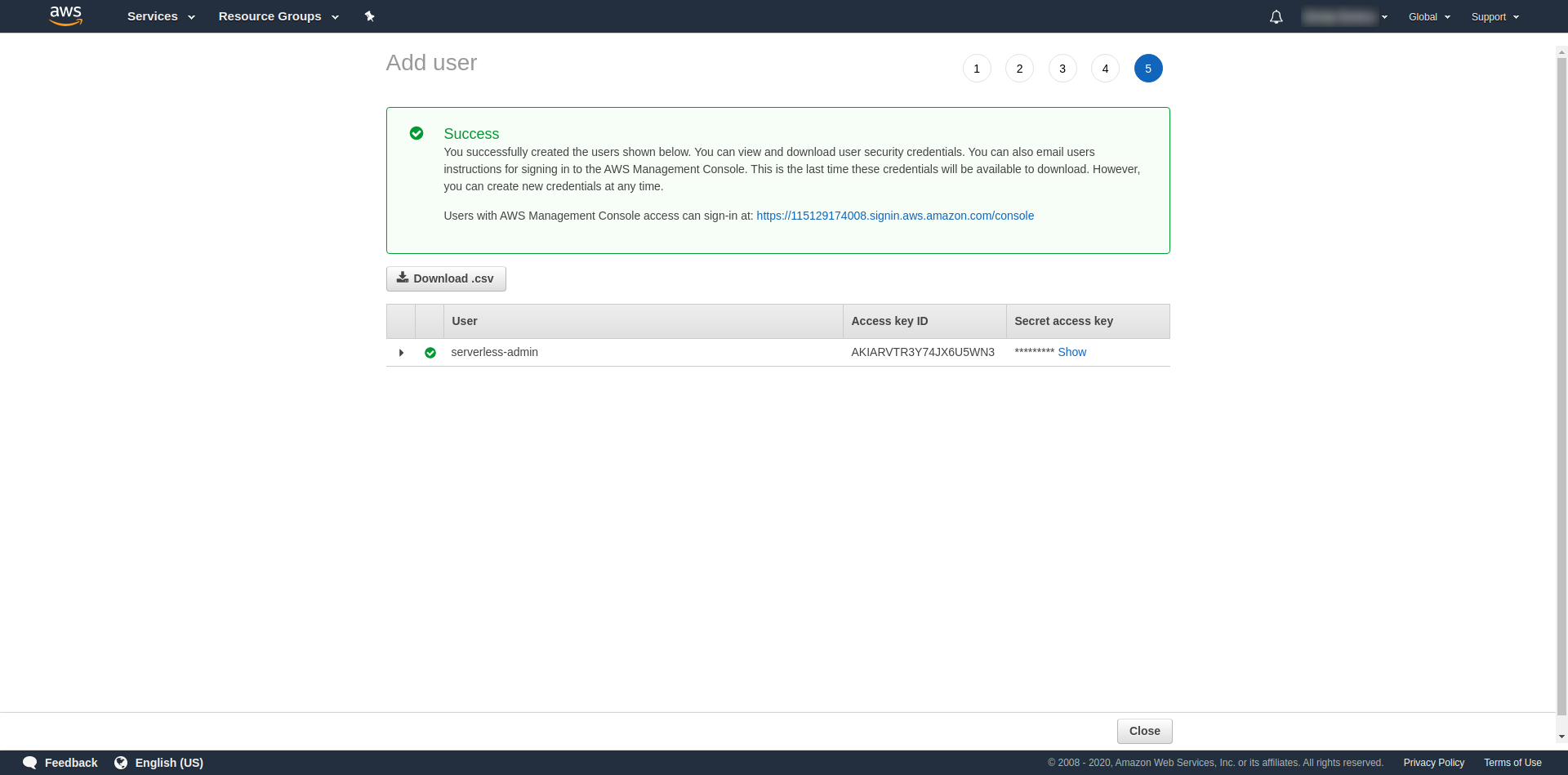
次に、次のコマンドを実行する必要があります。
serverless config credentials --provider aws --key key --secret secret --profile serverless-admin
キーとシークレットを上記のものに置き換えます。 AWSクレデンシャルはプロファイルとして作成されます。 〜/ .aws/credentialsファイルを開くことでそれを再確認できます。 AWSプロファイルで構成されている必要があります。 現在、以下の例では、これは1つだけです-私たちが作成したものです:
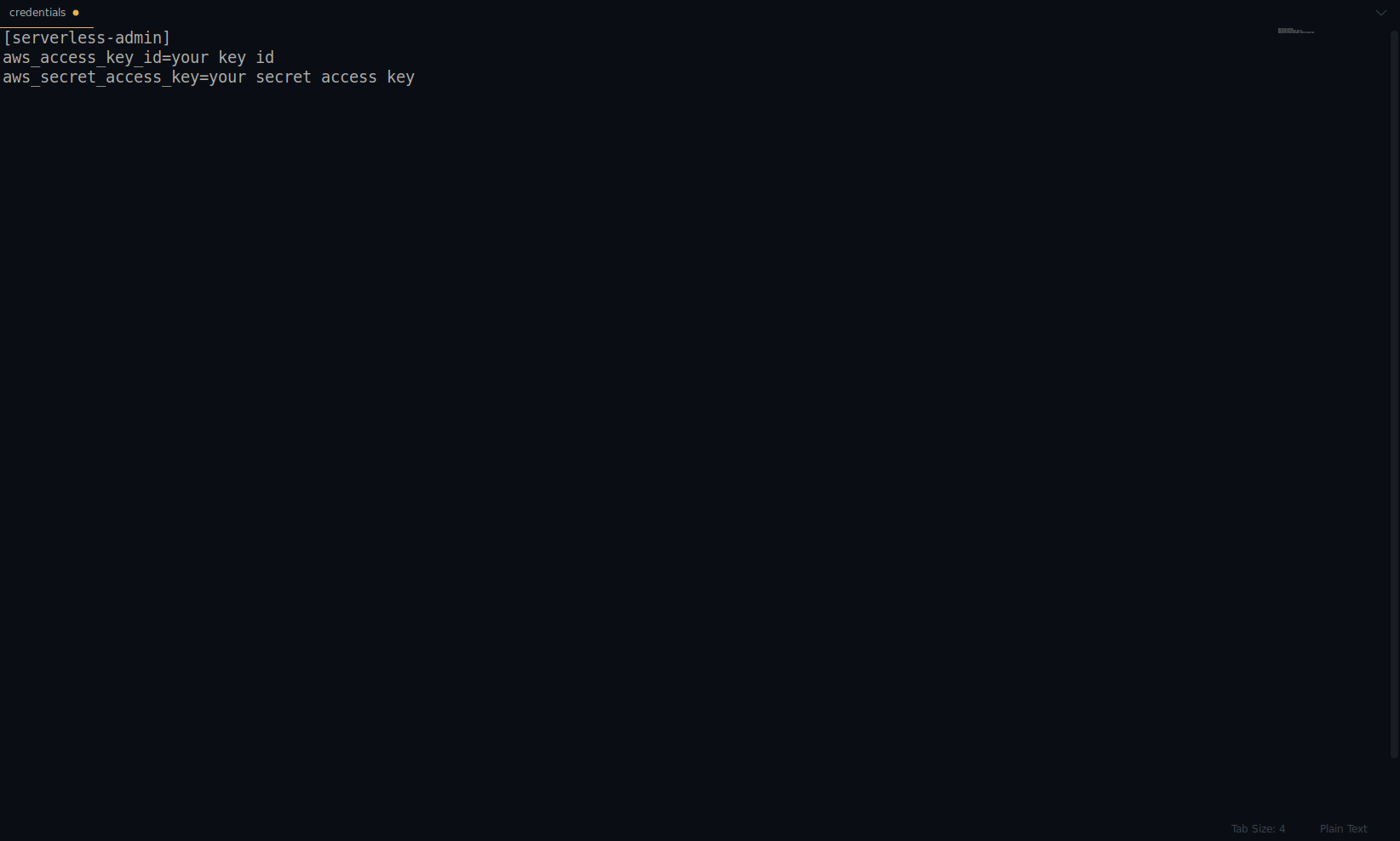
これまでのところ素晴らしい仕事です! NodeJSと組み込みの開始テンプレートを使用して1つのサンプルアプリケーションを作成することで続行できます。
注:さらに、この記事では、 serverlessの略であるslsコマンドを使用しています。
空のディレクトリを作成して入力します。 コマンドを実行します
ls create --template aws-nodejs
create –templateコマンドを使用して、使用可能なテンプレートの1つ(この場合はaws-nodejs)を指定します。これは、 NodeJSの「Helloworld」テンプレートアプリケーションです。
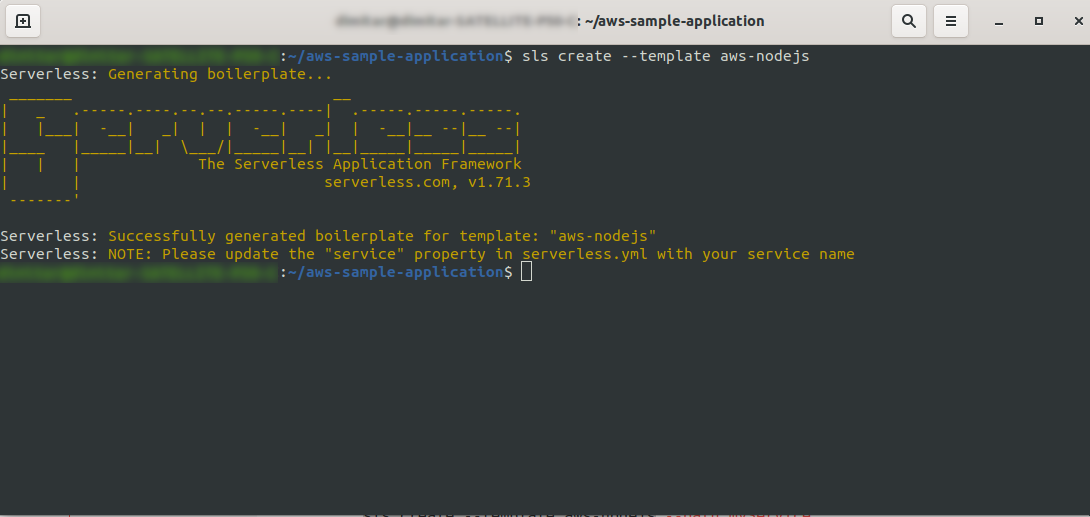
完了すると、ディレクトリは次のようになり、次のようになります。
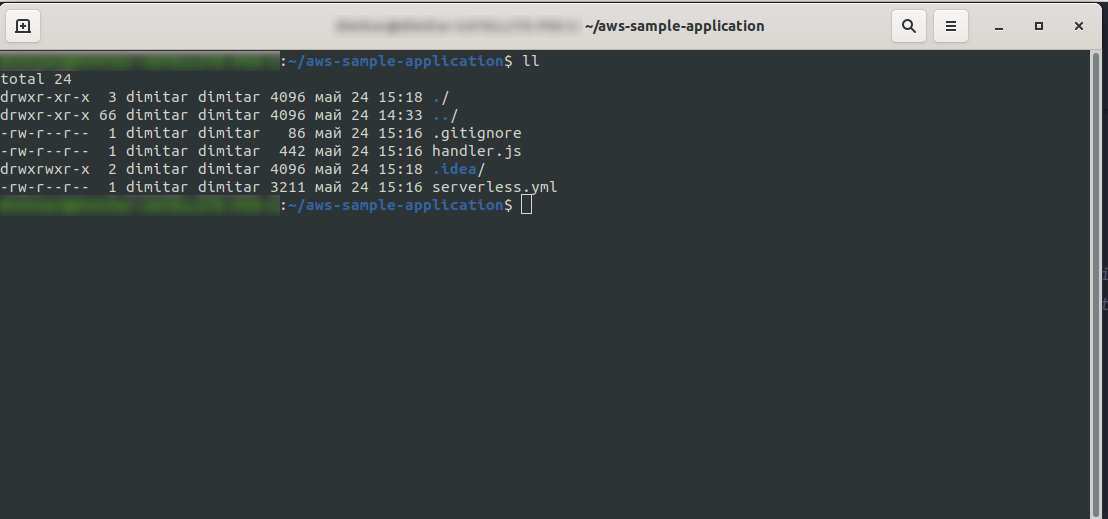
新しいファイルhandler.jsとserverless.ymlを作成しました。
handler.jsファイルには関数が保存され、 serverless.ymlには後で変更する構成プロパティが保存されます。 .ymlファイルが何であるか疑問に思っているなら、要するに、それは人間が読めるデータシリアル化言語です。 構成パラメーターを挿入するときに使用されるため、よく知っておくとよいでしょう。 しかし、 serverless.ymlファイルにあるものを見てみましょう:
サービス:aws-sample-application
プロバイダー:
名前:aws
ランタイム:nodejs12.x
関数:
こんにちは:
ハンドラー:handler.hello
- サービス: –当社のサービス名。
- プロバイダー: –プロバイダーのプロパティを含むオブジェクト。ここに表示されているように、プロバイダーはAWSであり、NodeJSランタイムを使用しています。
- 関数: –Lambdaにデプロイ可能なすべての関数を含むオブジェクトです。 この例では、 handler.jshello関数を指すhelloという名前の関数が1つだけあります。
アプリケーションのデプロイに進む前に、ここで1つの重要なことを行う必要があります。 以前、プロファイルを使用してAWSのクレデンシャルを設定しました( serverless-adminという名前を付けました)。 これで、サーバーレス構成にそのプロファイルとリージョンを使用するように指示するだけです。 serverless.ymlを開き、ランタイムのすぐ下のプロバイダープロパティの下に次のように入力します。
プロファイル:serverless-admin 地域:us-east-2
最後に、これが必要です。
プロバイダー: 名前:aws ランタイム:nodejs12.x プロファイル:serverless-admin 地域:us-east-2
注:リージョンを取得するには、コンソールにログインしたときにURLを検索するのが簡単な方法です。例:
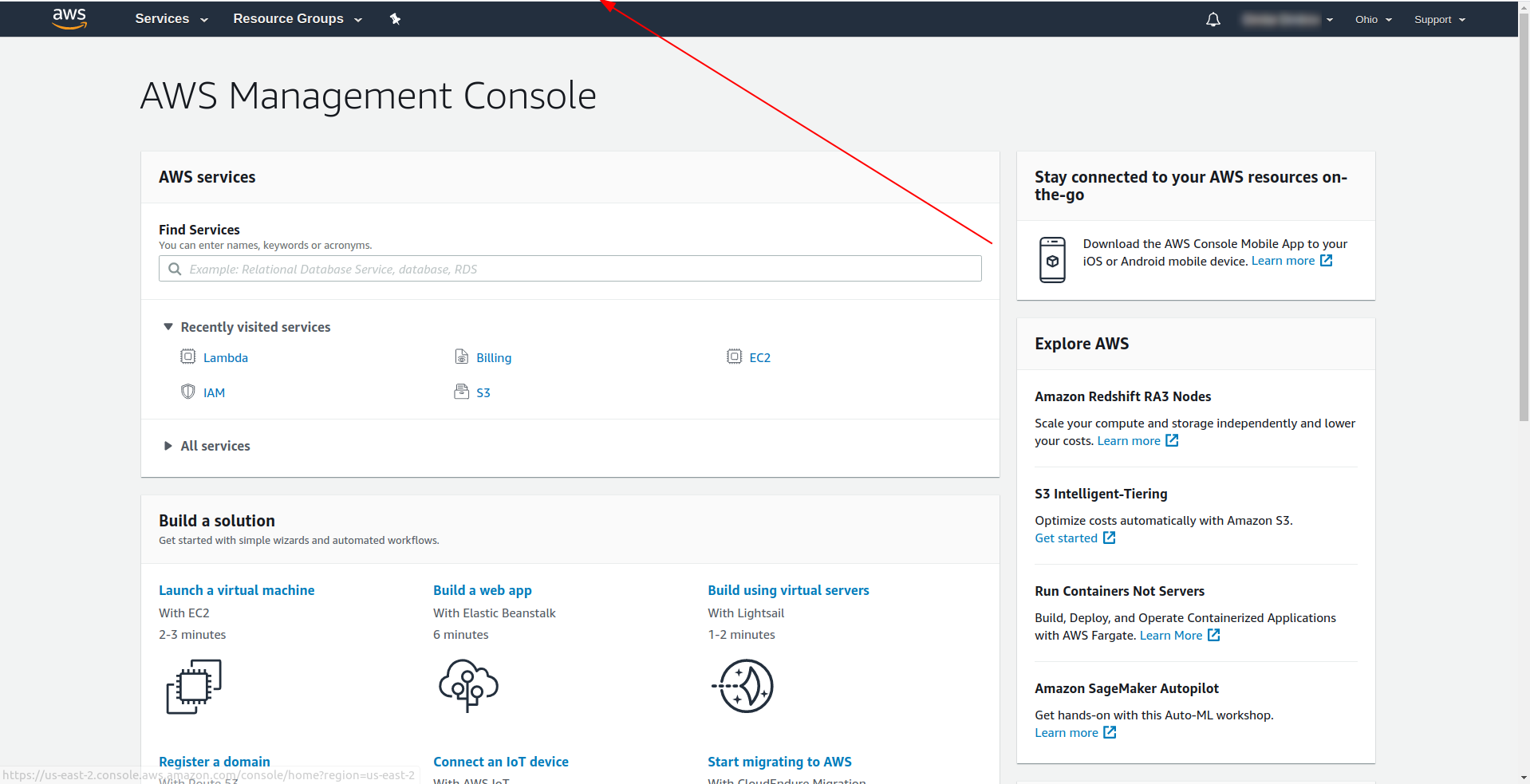
これで、生成されたテンプレートに関する必要な情報が得られました。 関数をローカルで呼び出してAWSLambdaにデプロイする方法を確認しましょう。
関数をローカルで呼び出すことで、アプリケーションをすぐにテストできます。
sls invoke local -f hello
関数を呼び出し(ただしローカルのみ!)、出力をコンソールに返します。
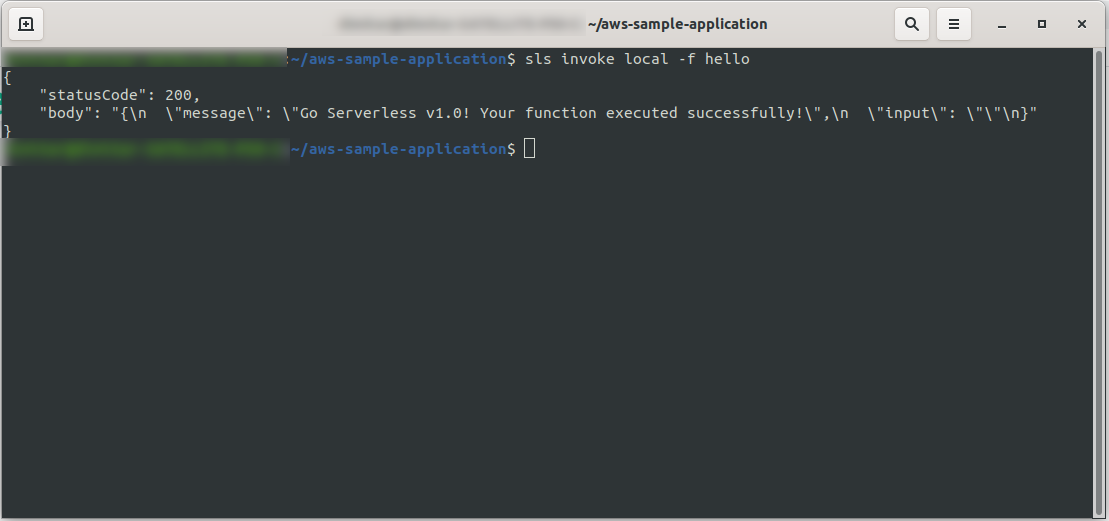
これで、すべて問題がなければ、関数をAWSLambdaにデプロイしてみることができます。
それで、それは複雑でしたか? いいえ、そうではありませんでした! Serverless Frameworkのおかげで、これは1行のコードにすぎません。
sls deploy -v
すべてが完了するのを待ちます。数分かかる場合があります。すべて問題がない場合は、次のように終了する必要があります。
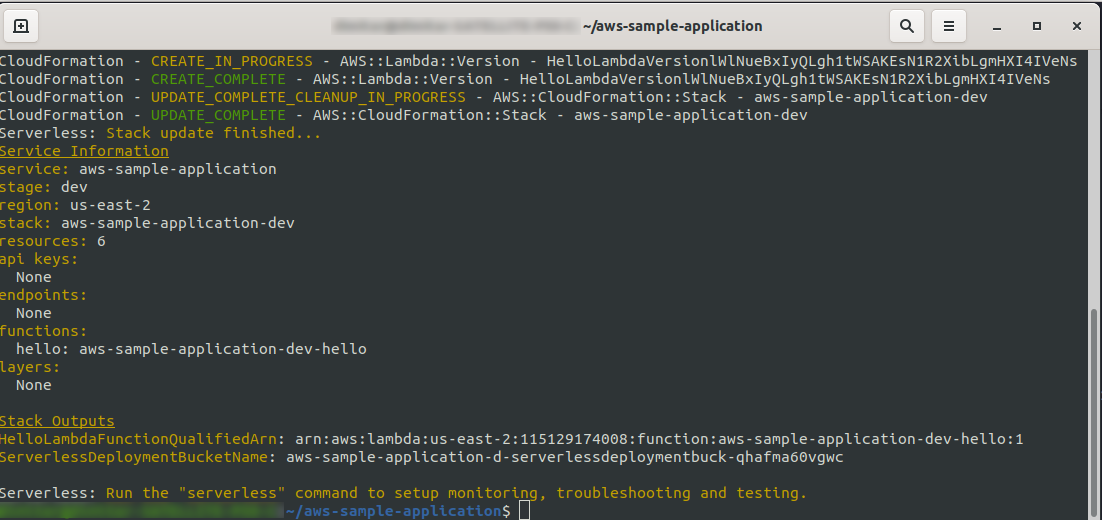
それでは、AWSで何が起こったのかを確認しましょう。 Lambdaに移動し(「サービスの検索」でLambdaと入力)、 Lambda関数が作成されていることを確認する必要があります。
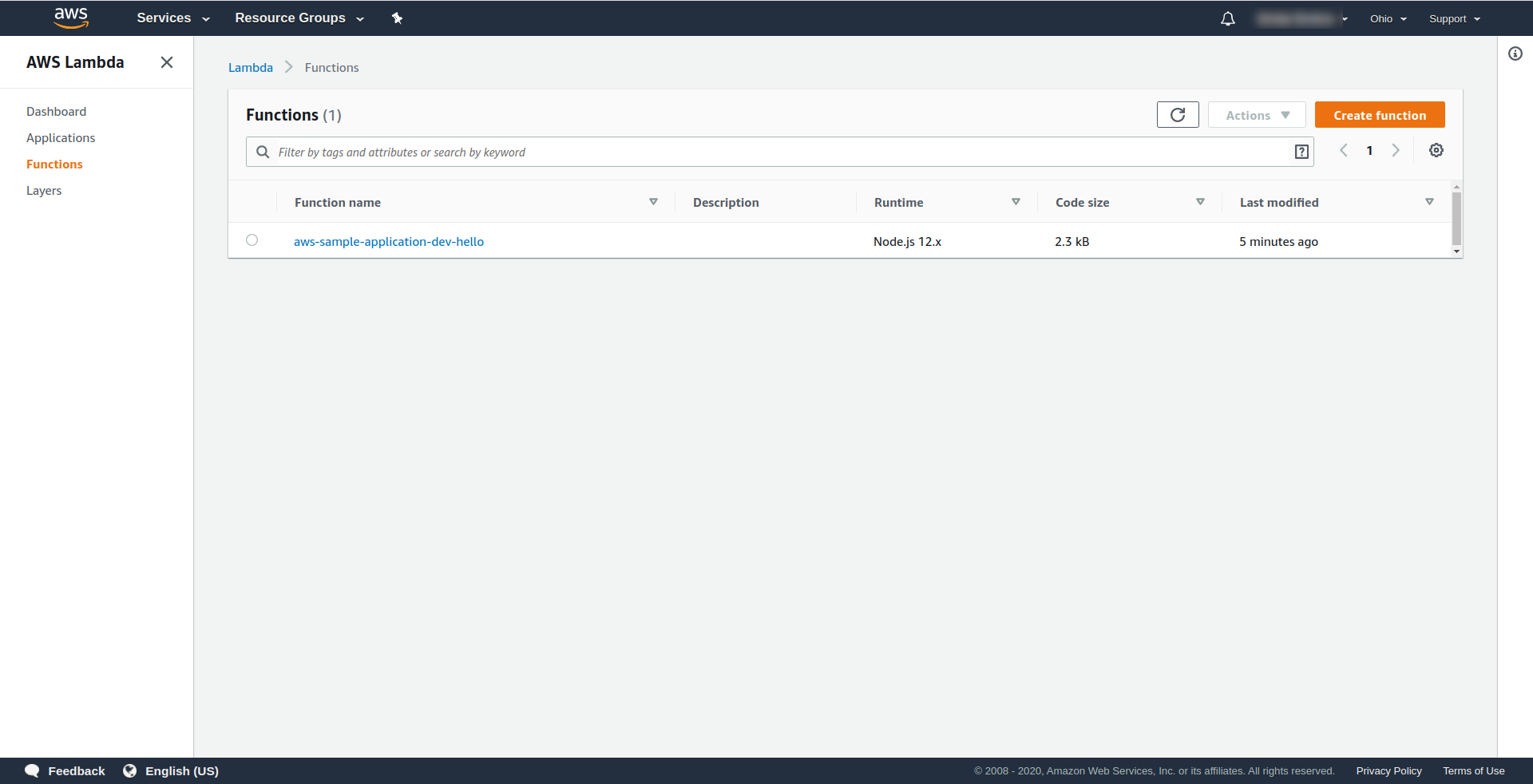
これで、AWSLambdaから関数を呼び出すことができます。 ターミナルタイプでsls invoke -f hello
以前と同じ出力を返す必要があります(ローカルでテストする場合)。
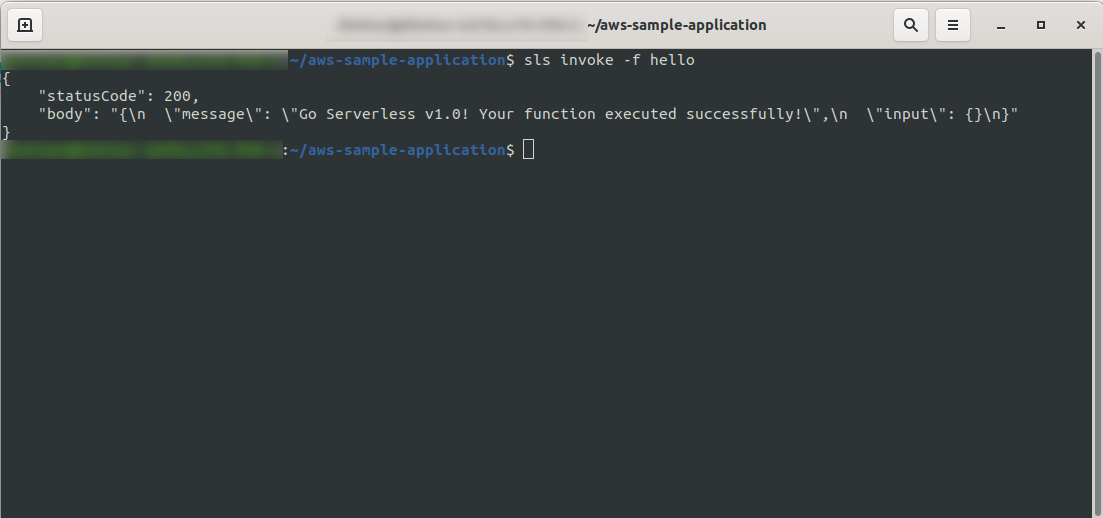
AWS Lambdaで関数を開き、[ Monitoring ]タブに移動して、[ View log in CloudWatch]をクリックすると、AWSの関数がトリガーされたことを確認できます。 「。
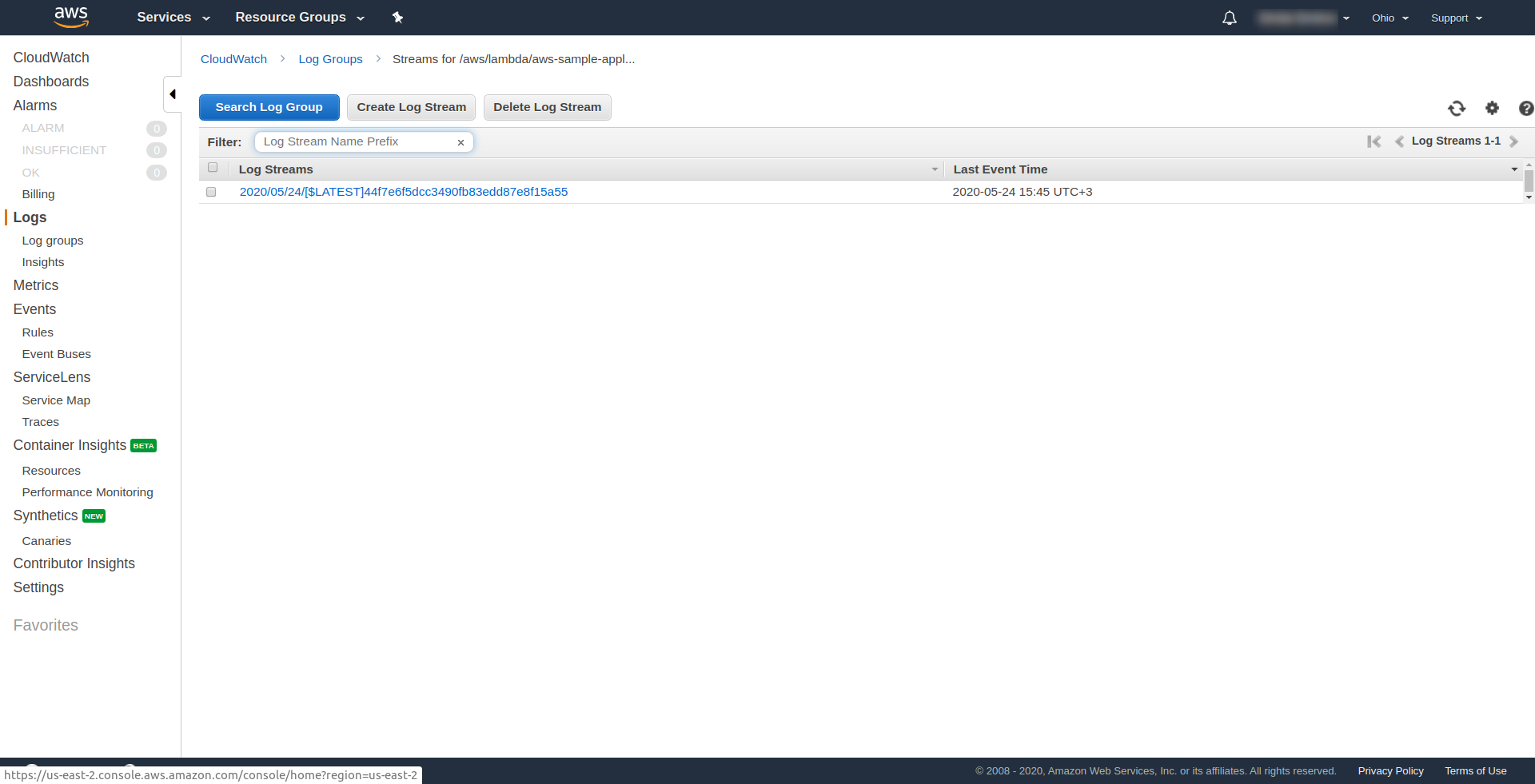
そこに1つのログがあるはずです。
さて、アプリケーションにはまだ1つ欠けているものがありますが、それは何ですか...? アプリにアクセスするエンドポイントがないので、AWSAPIGatewayを使用してエンドポイントを作成しましょう。
serverless.ymlファイルを開き、最初にコメントをクリーンアップする必要があります。 関数とそのhttpプロパティの下にeventsプロパティを追加する必要があります。 これは、サーバーレスフレームワークにAPIゲートウェイを作成し、アプリをデプロイするときにそれをLambda関数にアタッチするように指示します。 設定ファイルは次のように終了する必要があります。
サービス:aws-sample-application
プロバイダー:
名前:aws
ランタイム:nodejs12.x
プロファイル:serverless-admin
地域:us-east-2
関数:
こんにちは:
ハンドラー:handler.hello
イベント:
-http:
パス:/ hello
メソッド:get
httpでは、パスとHTTPメソッドを指定します。
以上ですsls deploy -vを実行して、アプリを再度デプロイしましょう。
完了すると、出力ターミナルに新しいものが1つ表示されます。これが、作成されたエンドポイントです。
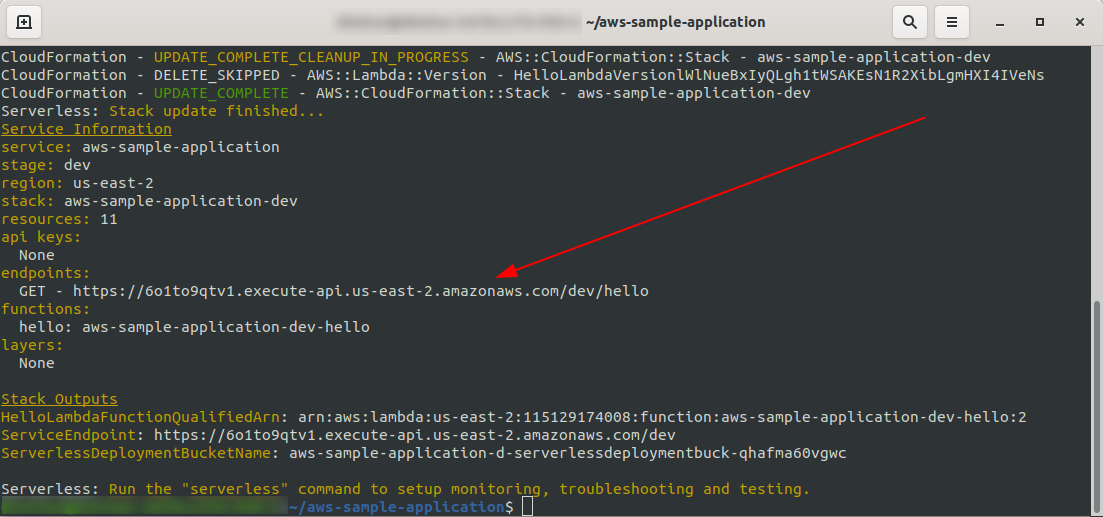
エンドポイントを開きましょう:
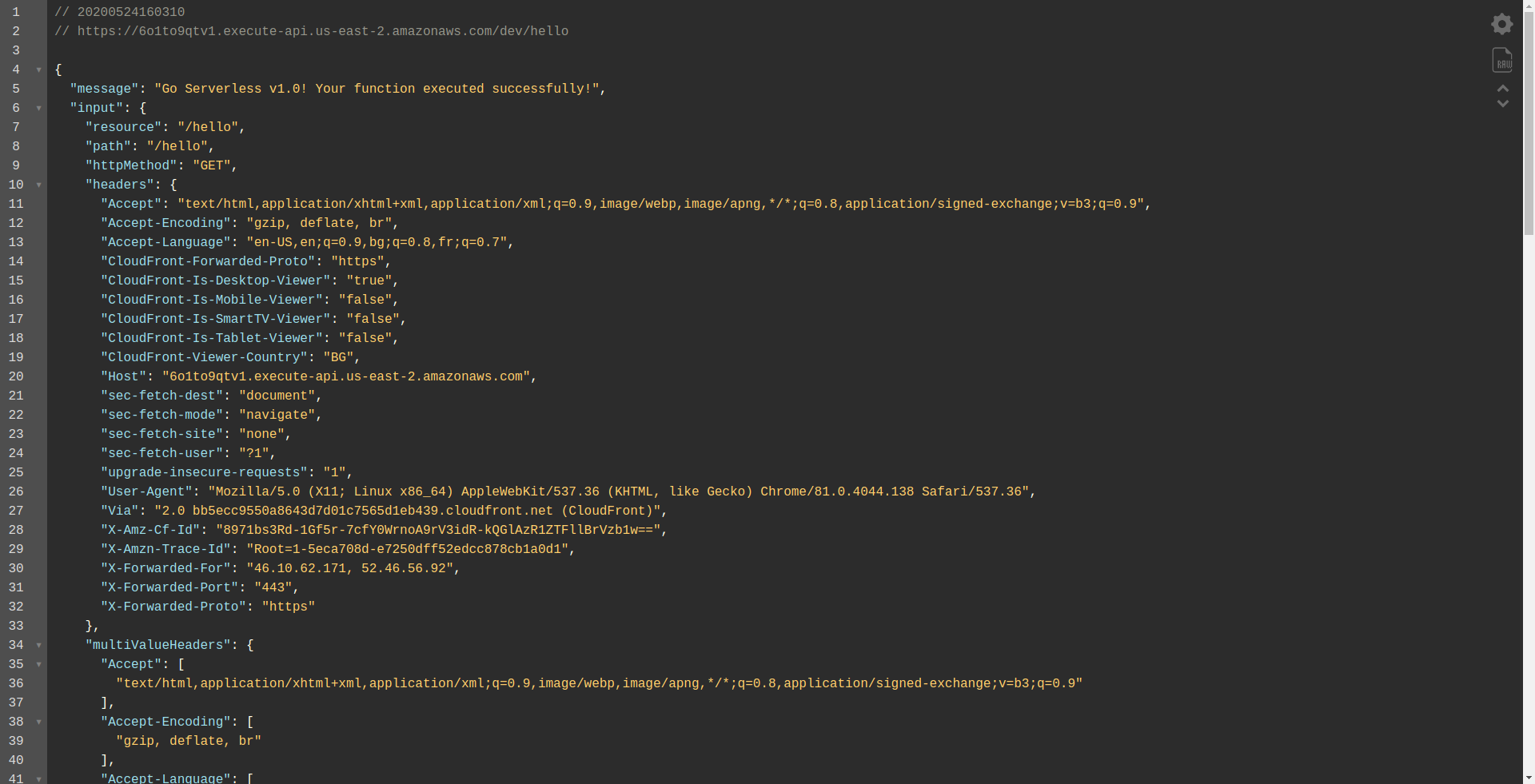
関数が実行され、出力とリクエストに関する情報が返されていることを確認する必要があります。 Lambda関数で何が変更されているかを確認しましょう。
AWS Lambdaを開き、関数をクリックします。
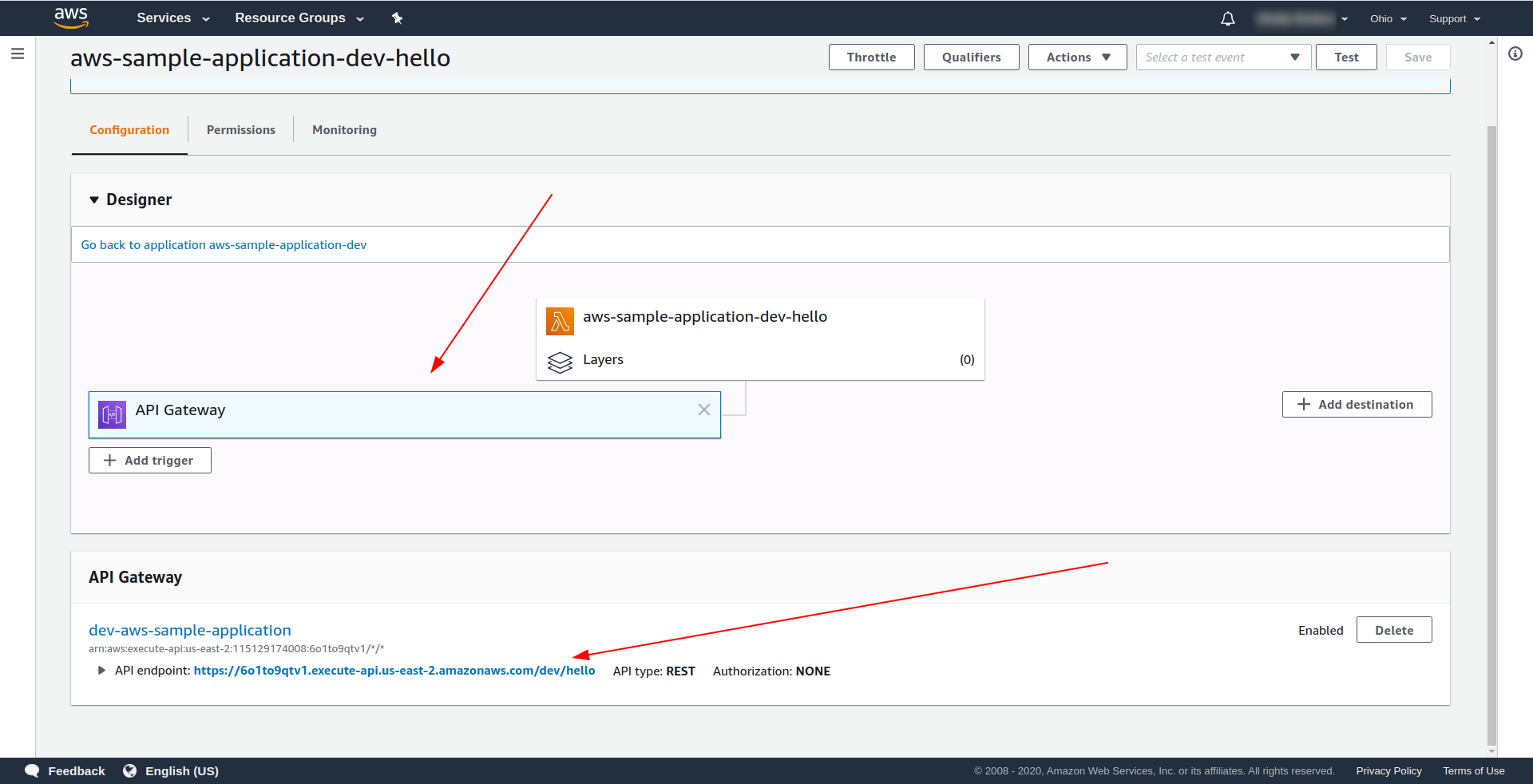
[デザイナー]タブの下に、LambdaとAPIエンドポイントにAPIゲートウェイが接続されていることがわかります。
すごい! 超シンプルなサーバーレスアプリケーションを作成し、AWS Lambdaにデプロイして、その機能をテストしました。 また、 AWSAPIGatewayを使用してエンドポイントを追加しました。
4.アプリケーションをオフラインで実行する方法
これまでのところ、ローカルで関数を呼び出すことができることはわかっていますが、serverless-offlineプラグインを使用してアプリケーション全体をオフラインで実行することもできます。
プラグインは、ローカル/開発マシンでAWSLambdaとAPIGatewayをエミュレートします。 リクエストを処理し、ハンドラーを呼び出すHTTPサーバーを起動します。
プラグインをインストールするには、appディレクトリで以下のコマンドを実行します
npm install serverless-offline --save-dev
次に、プロジェクトのserverless.yml内でファイルを開き、 pluginsプロパティを追加します。
プラグイン: -サーバーレス-オフライン
構成は次のようになります。
サービス:aws-sample-application
プロバイダー:
名前:aws
ランタイム:nodejs12.x
プロファイル:serverless-admin
地域:us-east-2
関数:
こんにちは:
ハンドラー:handler.hello
イベント:
-http:
パス:/ hello
メソッド:get
プラグイン:
-サーバーレス-オフライン
プラグインのインストールと構成が正常に行われたことを確認するには、
sls --verbose
あなたはこれを見るはずです:
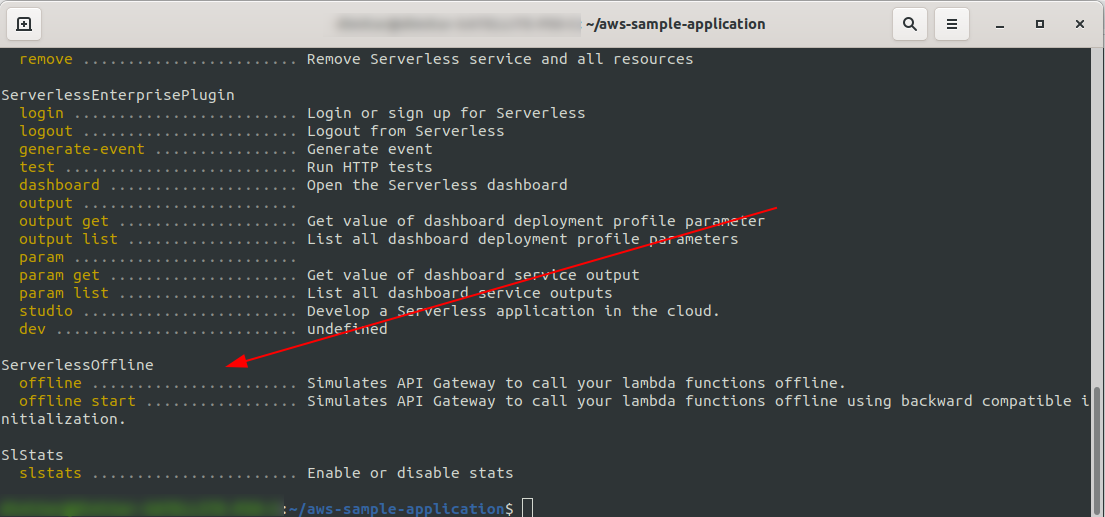
プロジェクトのルートで、コマンドを実行します
sls offline
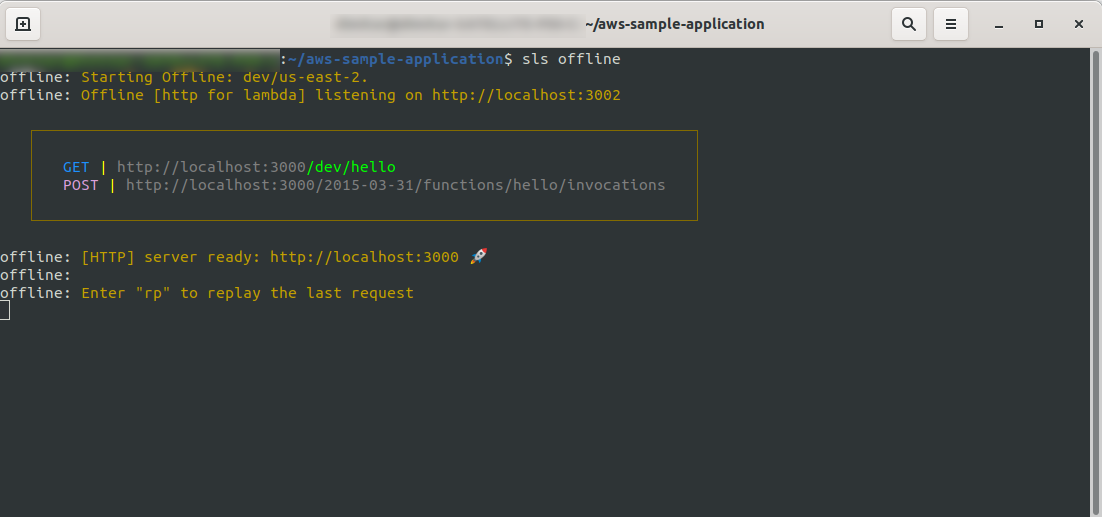
ご覧のとおり、 HTTPサーバーはポート3000でリッスンしており、関数にアクセスできます。たとえば、ここではhello関数用にhttp:// localhost:3000 / dev/helloがあります。 以前に作成したAPIGatewayからの応答と同じ応答があることを開きます。
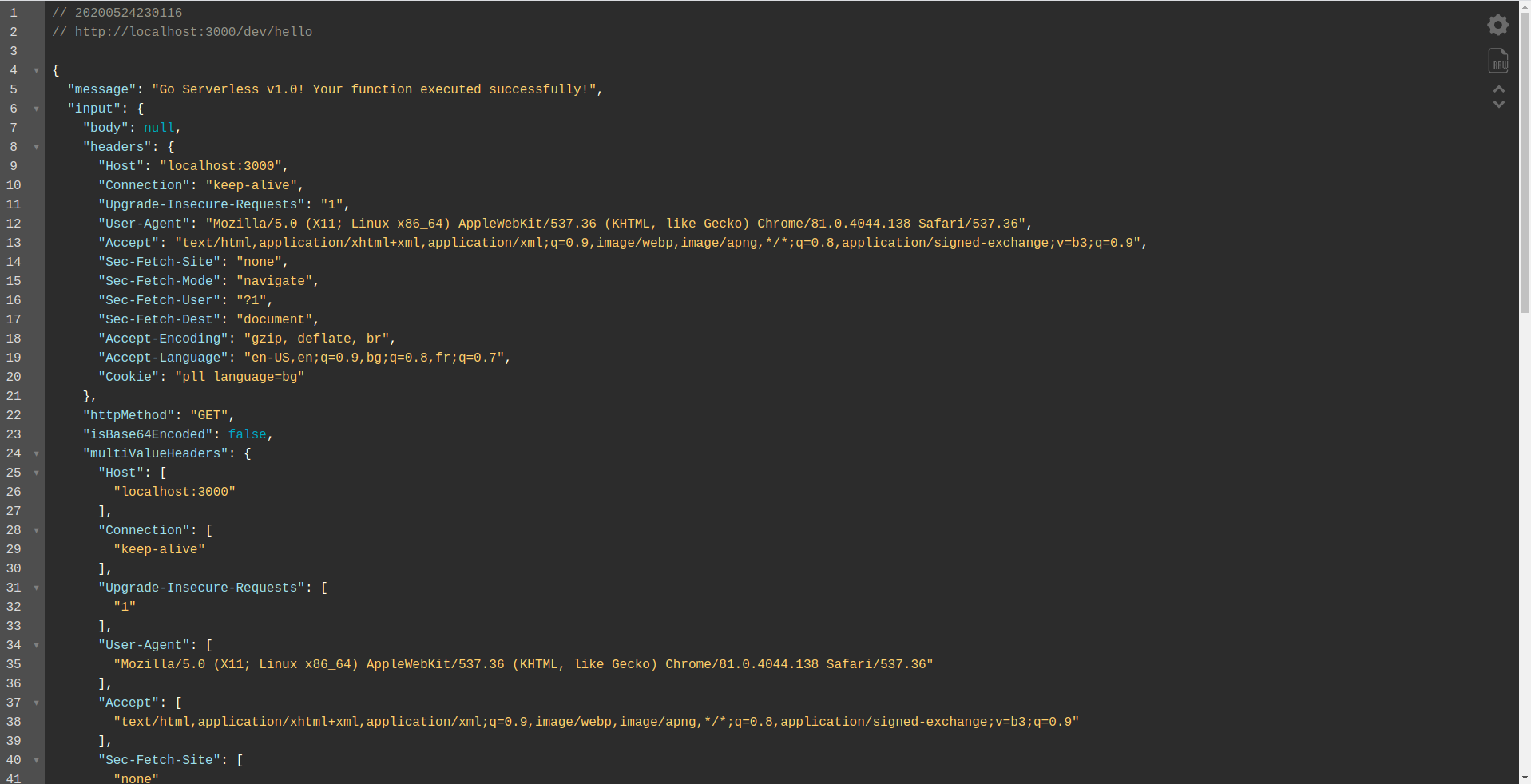
GoogleBigQuery統合を追加する

あなたはこれまで素晴らしい仕事をしました! サーバーレスを使用して完全に機能するアプリケーションがあります。 アプリを拡張し、 BigQuery統合を追加して、アプリがどのように機能し、統合がどのように行われるかを確認しましょう。
BigQueryは、サーバーレスのサービスとしてのソフトウェア(SaaS)であり、クエリをサポートする費用対効果の高い高速なデータウェアハウスです。 NodeJSアプリとの統合を続ける前に、アカウントを作成する必要があるので、次に進みましょう。

1. GoogleCloudConsoleを設定します
https://cloud.google.comにアクセスし、アカウントでログインしていない場合は、アカウントを作成して続行します。
Google Cloud Consoleにログインするときは、新しいプロジェクトを作成する必要があります。 ロゴの横にある3つのドットをクリックすると、「新しいプロジェクト」を選択するモーダルウィンドウが開きます。 」
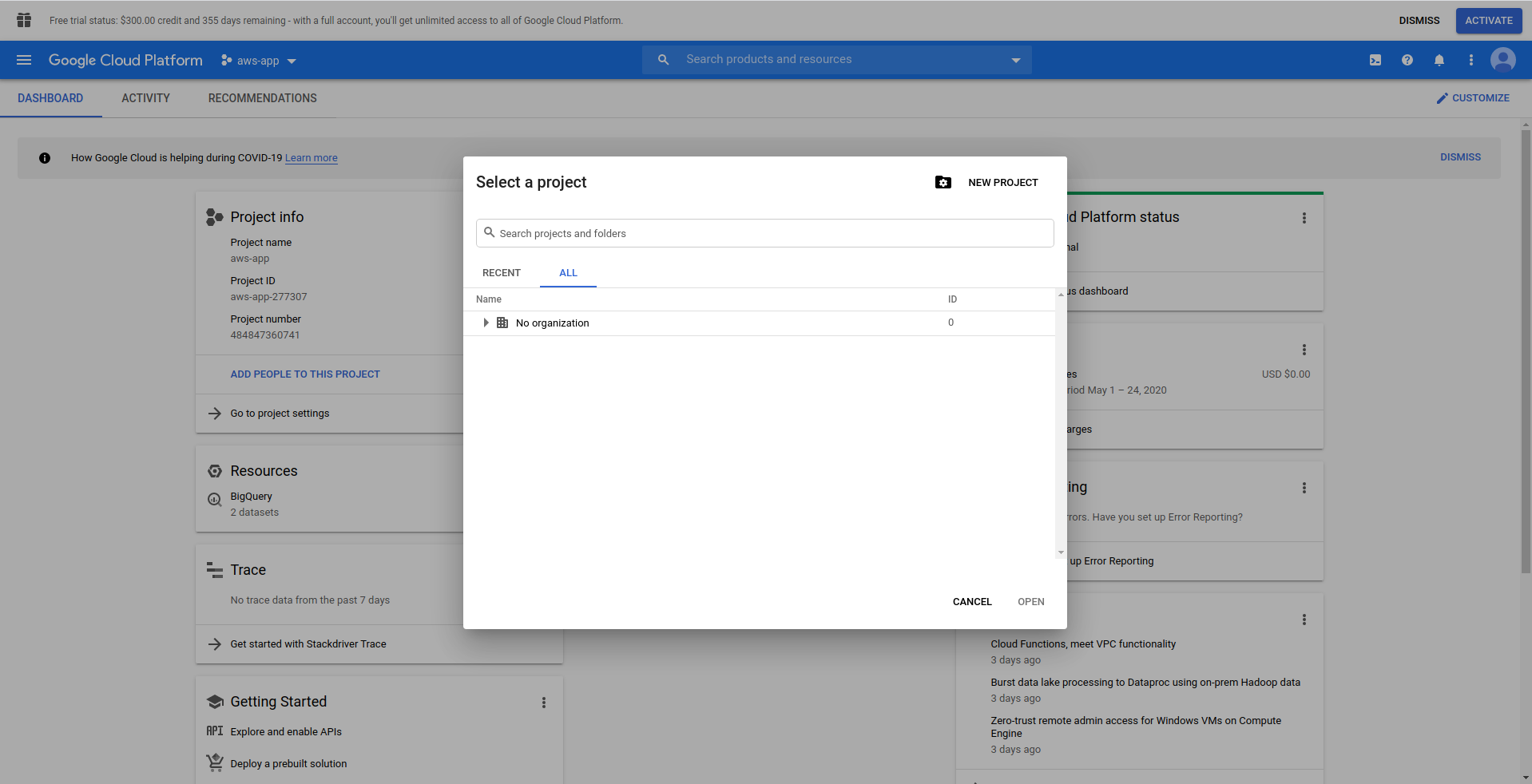
プロジェクトの名前を入力します。 bigquery-exampleを使用します。 プロジェクトを作成したら、ドロワーを使用してBigQueryに移動します。
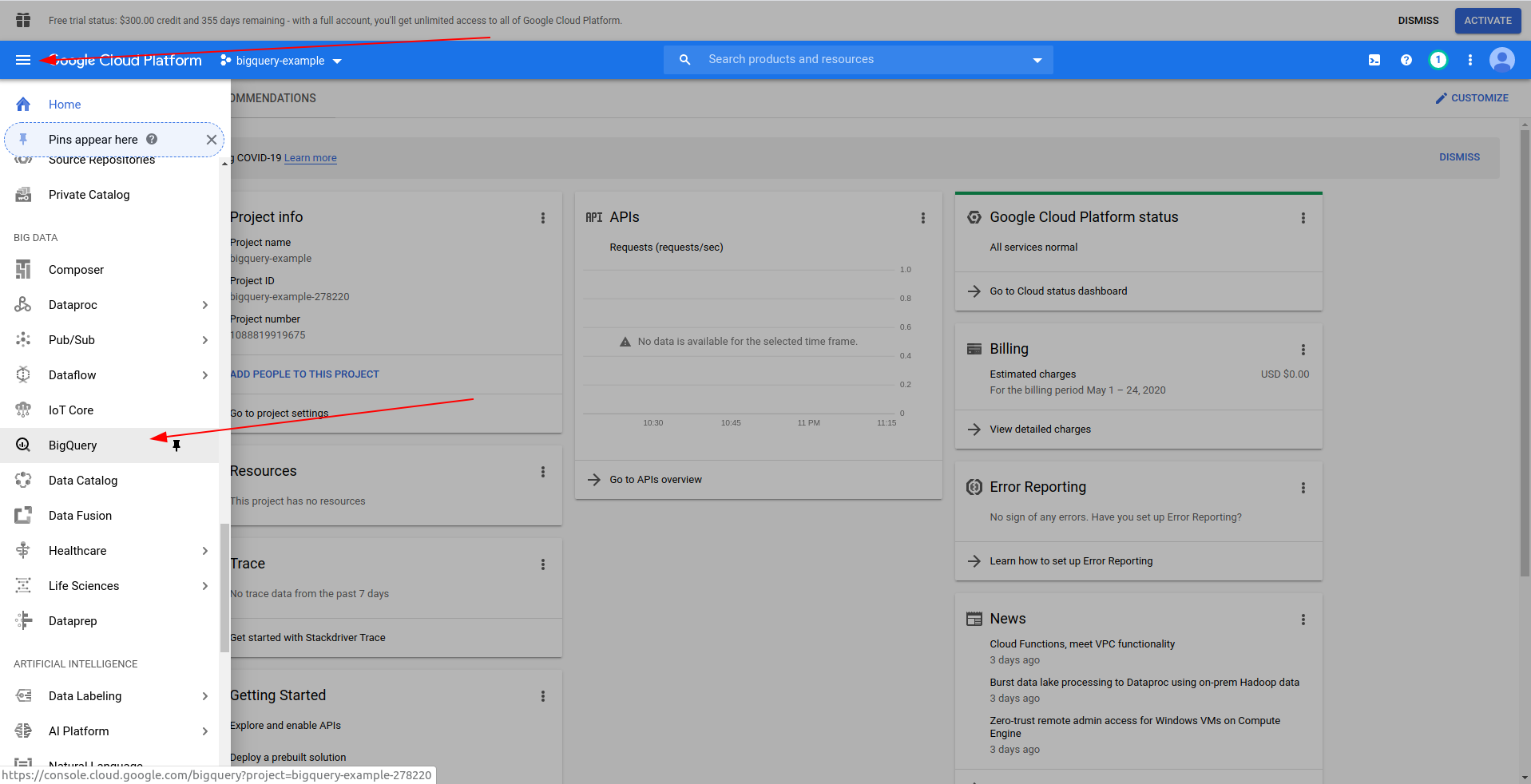
BigQueryが読み込まれると、左側に、アクセスできるプロジェクトのデータと、パブリックデータセットが表示されます。 この例では、公開データセットを使用しています。 それはcovid19_ecdcという名前です:
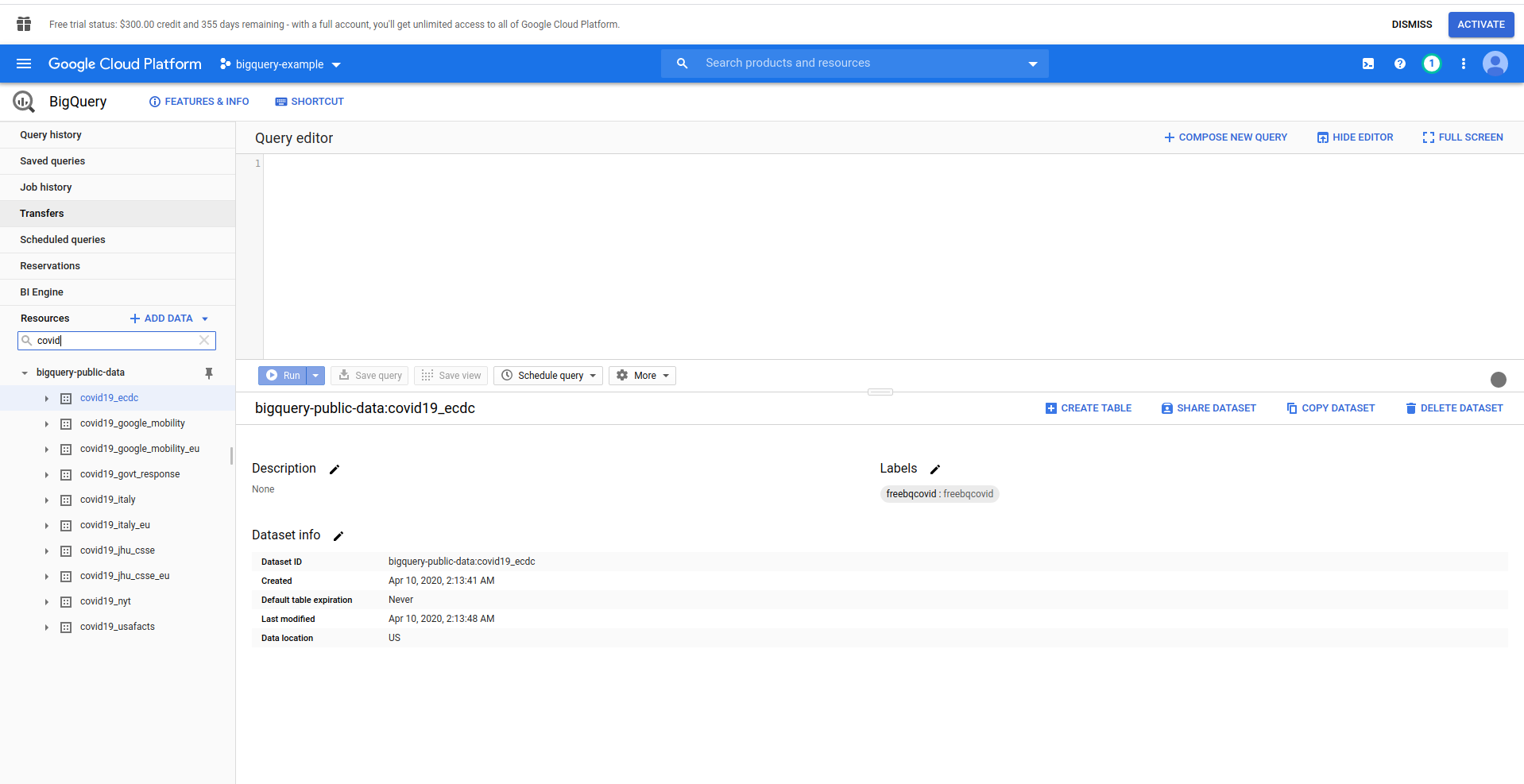
データセットと利用可能なテーブルを試してみてください。 その中のデータをプレビューします。 これは、1時間ごとに更新される公開データセットであり、 COVID-19の世界的なデータに関する情報が含まれています。
データにアクセスできるようにするには、IAMユーザー->サービスアカウントを作成する必要があります。 そのため、メニューで[ IAMと管理]、[サービスアカウント]の順にクリックします。
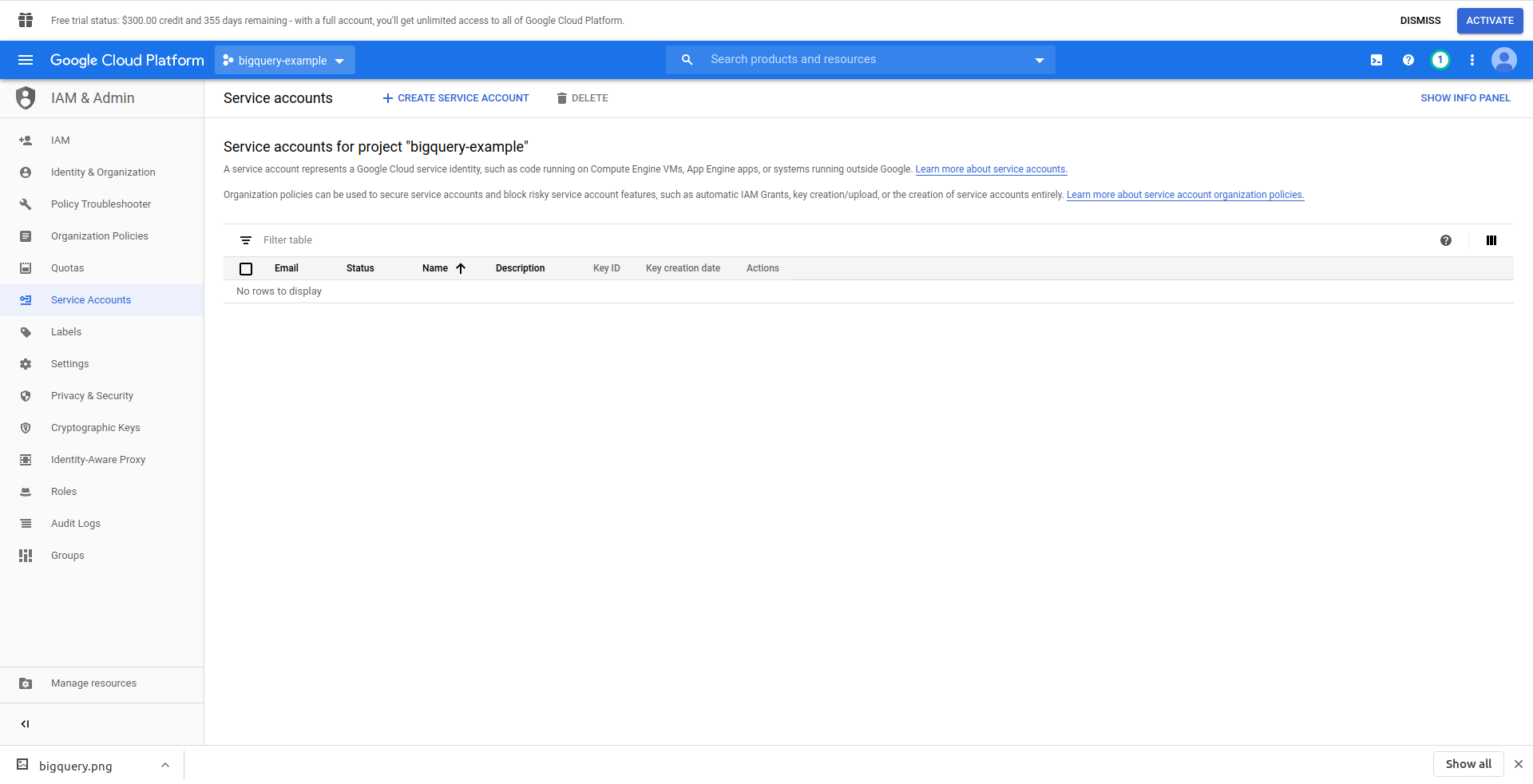
「サービスアカウントの作成」ボタンをクリックし、サービスアカウント名を入力して「作成」をクリックします。 次に、「サービスアカウントのアクセス許可」に移動し、 「BigQueryAdmin」を検索して選択します。
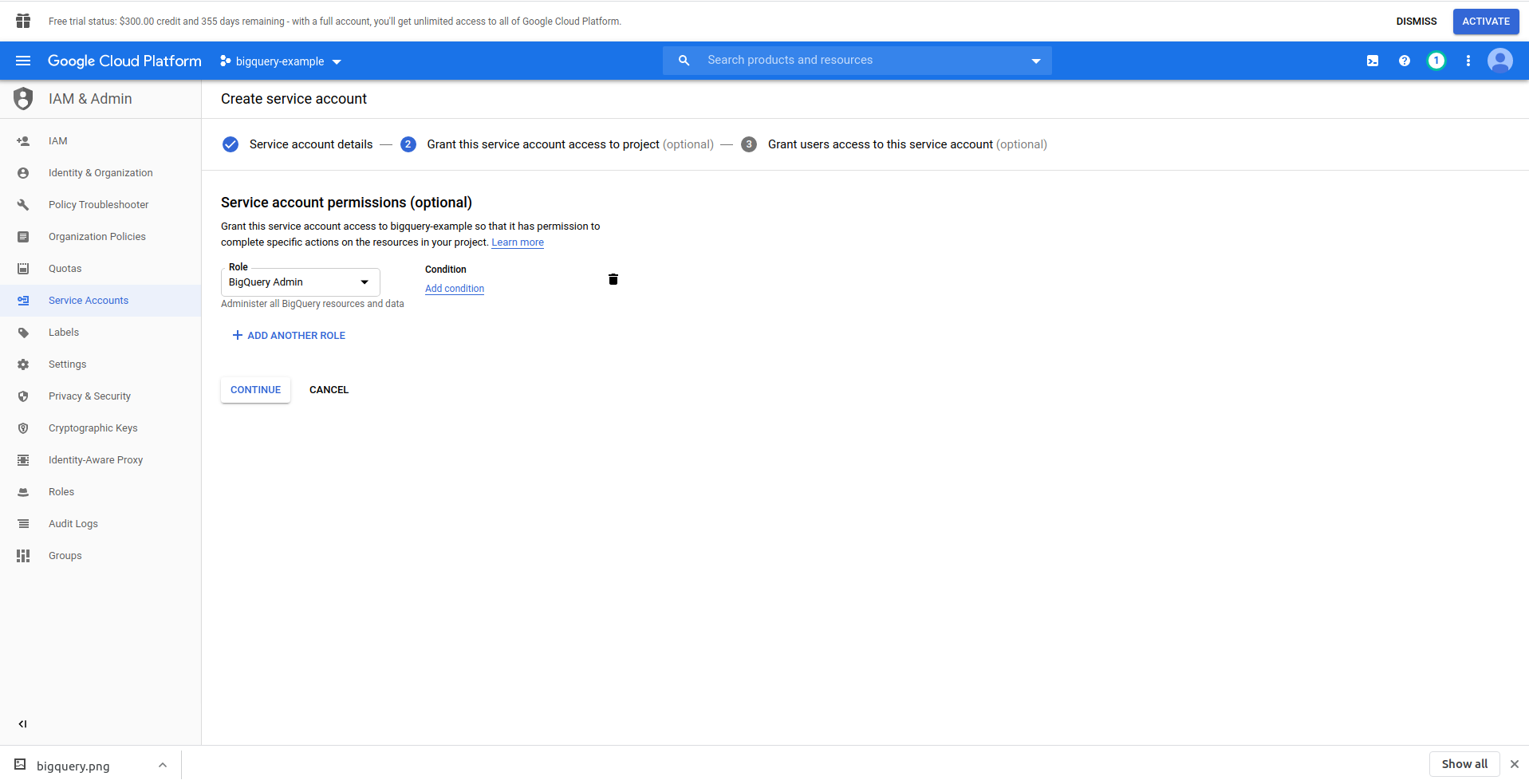
「続行」をクリックします。これが最後のステップです。ここでキーが必要なので、「キー」の下にある作成ボタンをクリックして、 JSONとしてエクスポートします。 これを安全な場所に保存してください。後で必要になります。 [完了]をクリックして、サービスアカウントの作成を終了します。
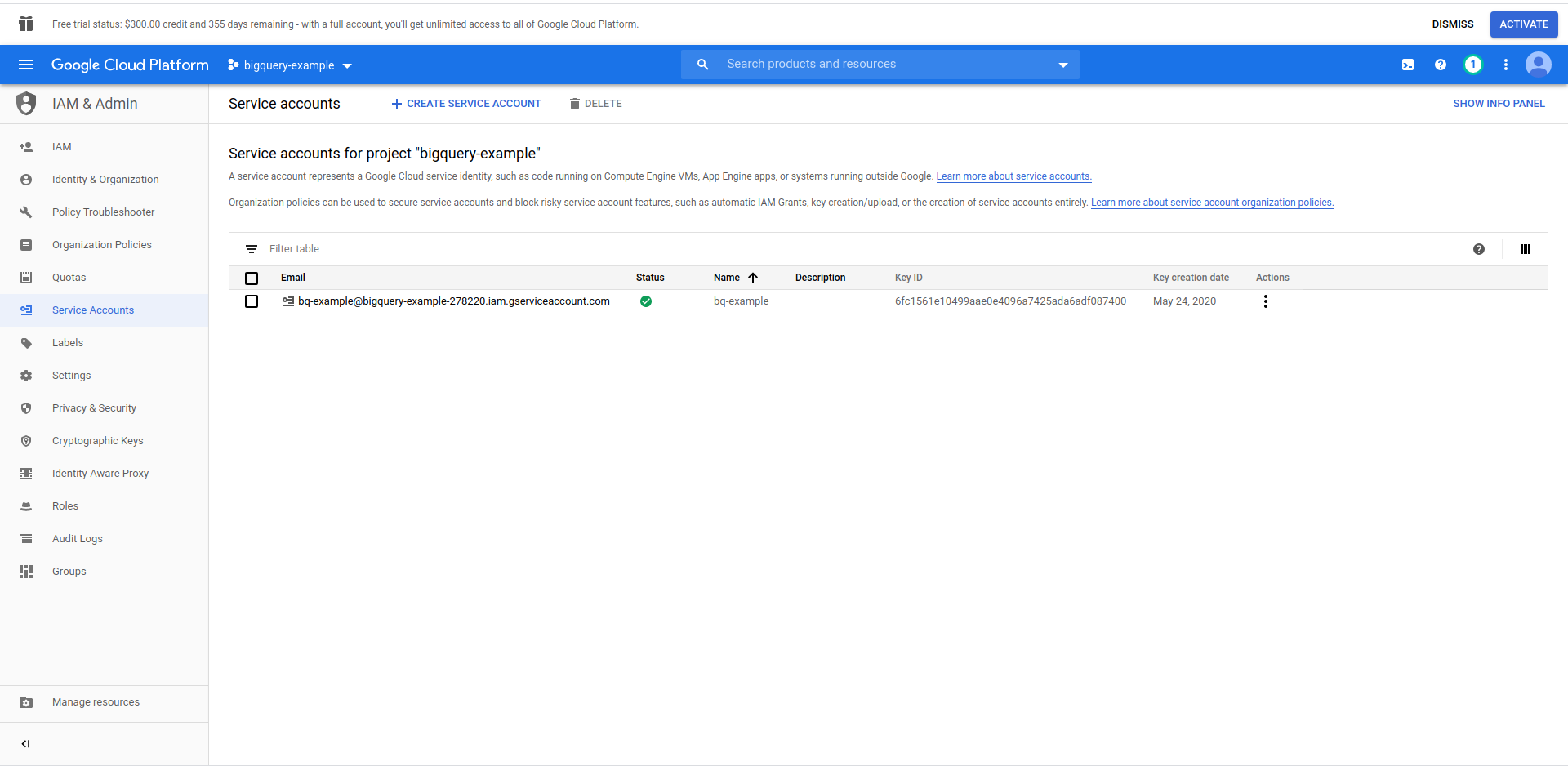
ここで、ここで生成されたクレデンシャルを使用してNodeJSBigQueryライブラリに接続します。
2.NodeJSBigQueryライブラリをインストールします
作成したプロジェクトで使用するには、 BigQueryNodeJSライブラリをインストールする必要があります。 appディレクトリで以下のコマンドを実行します。
まず、npminitを実行してnpm initを初期化します
すべての質問に回答し、 BigQueryライブラリのインストールに進みます。
npm install @google-cloud/bigquery
関数ハンドラーを変更し続ける前に、以前に作成したJSONファイルから秘密鍵を実行する必要があります。 これを行うには、サーバーレス環境変数を使用します。 詳細については、こちらをご覧ください。
serverless.ymlを開き、プロバイダープロパティに次のような環境プロパティを追加します。
環境:
PROJECT_ID:$ {file(./ config / bigquery-config.json):project_id}
CLIENT_EMAIL:$ {file(./ config / bigquery-config.json):client_email}
PRIVATE_KEY:$ {file(./ config / bigquery-config.json):private_key}
PROJECT_ID、PRIVATE_KEY 、およびCLIENT_EMAIL環境変数を作成します。これは、生成したJSONファイルから同じプロパティ(小文字)を取得します。 これをconfigフォルダーに配置し、 bigquery-config.jsonという名前を付けました。
今のところ、serverless.ymlファイルは次のようになっているはずです。
サービス:aws-sample-application
プロバイダー:
名前:aws
ランタイム:nodejs12.x
プロファイル:serverless-admin
地域:us-east-2
環境:
PROJECT_ID:$ {file(./ config / bigquery-config.json):project_id}
CLIENT_EMAIL:$ {file(./ config / bigquery-config.json):client_email}
PRIVATE_KEY:$ {file(./ config / bigquery-config.json):private_key}
関数:
こんにちは:
ハンドラー:handler.hello
イベント:
-http:
パス:/ hello
メソッド:get
プラグイン:
-サーバーレス-オフライン
次に、 handler.jsを開き、BigQueryライブラリをインポートします。ファイルの先頭の「usestrict」に次の行を追加します。
const {BigQuery} = require('@google-cloud/bigquery');
次に、BigQueryライブラリにクレデンシャルを通知する必要があります。 この目的のために、資格情報を使用してBigQueryをインスタンス化する新しい定数を作成します。
const bigQueryClient = new BigQuery({
projectId:process.env.PROJECT_ID、
資格情報: {
client_email:process.env.CLIENT_EMAIL、
private_key:process.env.PRIVATE_KEY
}
});
次に、BigQuerySQLクエリを作成しましょう。 ブルガリアのCOVID-19症例に関する最新情報を取得したいと思います。 続行する前にBigQueryクエリエディターを使用してテストしているため、カスタムクエリを作成しました。
SELECT * FROM `bigquery-public-data.covid19_ecdc.covid_19_geographic_distribution_worldwide` WHERE geo_ ORDER BY date DESC LIMIT 1
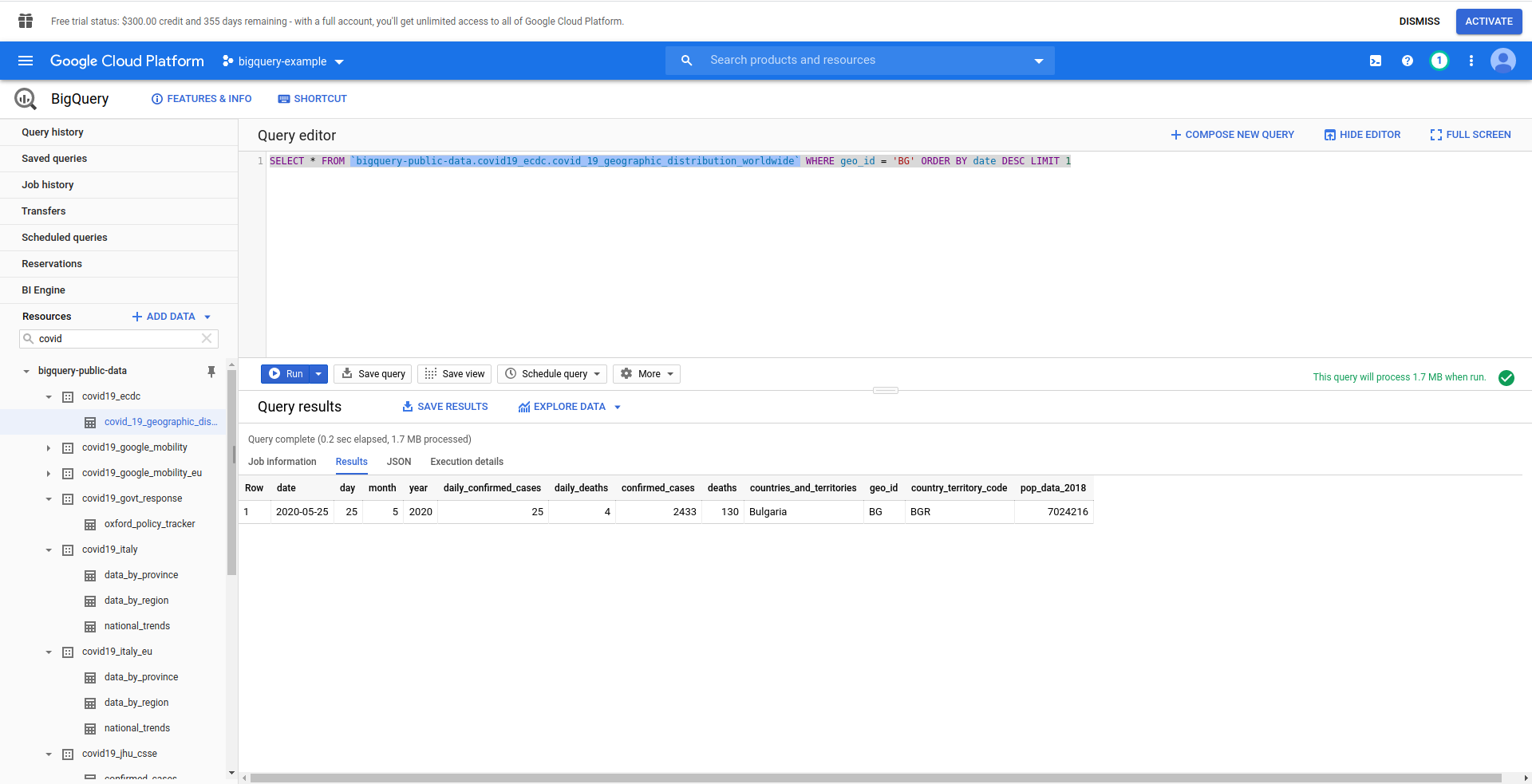
良い! それをNodeJSアプリに実装しましょう。
handler.jsを開き、以下のコードを貼り付けます
const query ='SELECT * FROM `bigquery-public-data.covid19_ecdc.covid_19_geographic_distribution_worldwide` WHERE geo_id = \'BG \'ORDER BY date DESC LIMIT 1';
const options = {
クエリ:クエリ
}
const [job] = await bigQueryClient.createQueryJob(options);
const [rows] = await job.getQueryResults();
クエリとオプションの定数を作成しました。 次に、クエリをジョブとして実行し、そこから結果を取得します。
また、クエリから生成された行を返すようにreturnハンドラーを変更しましょう。
戻る {
statusCode:200、
本文:JSON.stringify(
{{
行
}、
ヌル、
2
)、
};
完全なhandler.jsを見てみましょう:
'厳密に使用';
const {BigQuery} = require('@ google-cloud / bigquery');
const bigQueryClient = new BigQuery({
projectId:process.env.PROJECT_ID、
資格情報: {
client_email:process.env.CLIENT_EMAIL、
private_key:process.env.PRIVATE_KEY
}
});
module.exports.hello=非同期イベント=>{
const query ='SELECT * FROM `bigquery-public-data.covid19_ecdc.covid_19_geographic_distribution_worldwide` WHERE geo_id = \'BG \'ORDER BY date DESC LIMIT 1';
const options = {
クエリ:クエリ
}
const [job] = await bigQueryClient.createQueryJob(options);
const [rows] = await job.getQueryResults();
戻る {
statusCode:200、
本文:JSON.stringify(
{{
行
}、
ヌル、
2
)、
};
};
わかった! 関数をローカルでテストしてみましょう。
sls invoke local -f hello
出力が表示されます。
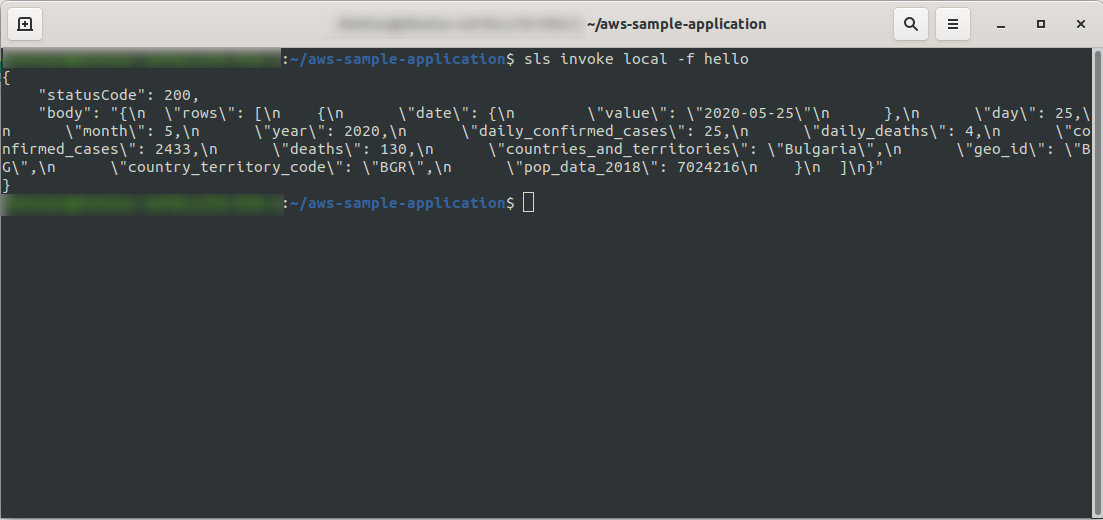
アプリケーションのデプロイを続行して、HTTPエンドポイントを介してテストし、 sls deploy -vを実行します。
終了するのを待って、エンドポイントを開きます。 結果は次のとおりです。
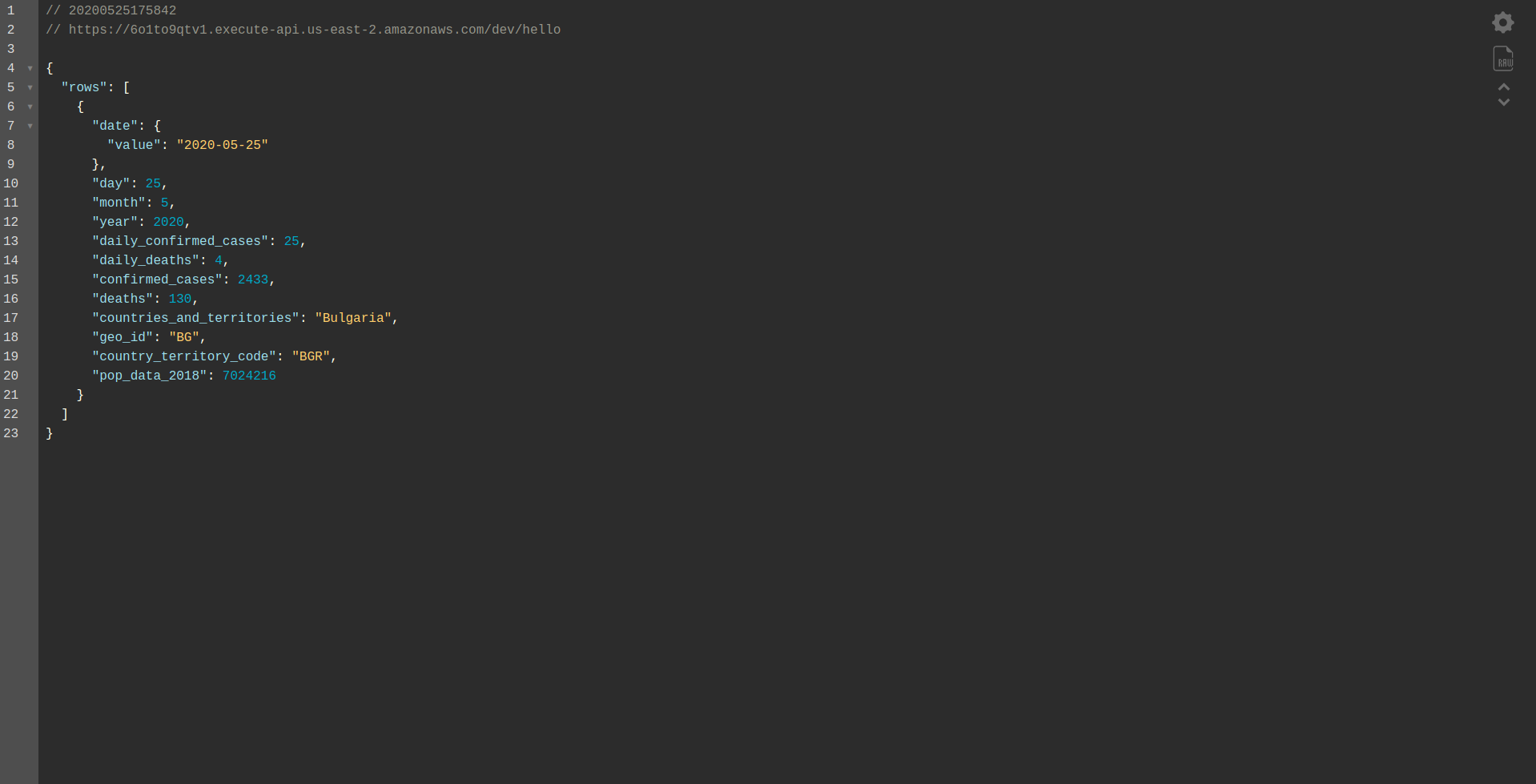
素晴らしい! これで、BigQueryからデータを取得して応答を返すアプリケーションができました。 最後に、オフラインで動作していることを確認しましょう。 sls offline実行する
そして、ローカルエンドポイントをロードします。
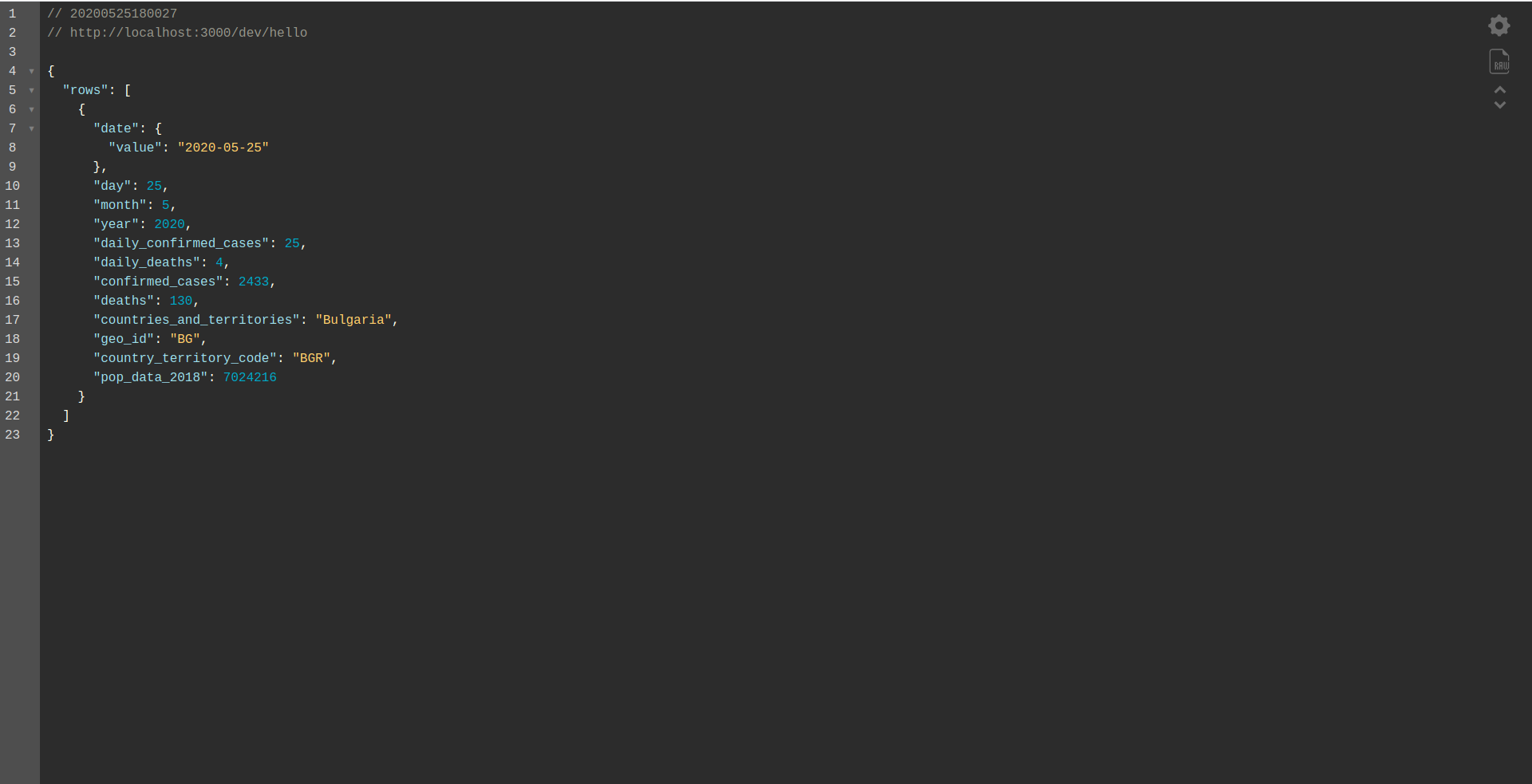
よくやった仕事。 私たちはプロセスのほぼ終わりにあります。 最後のステップは、アプリと動作を少し変更することです。 AWS API Gatewayの代わりに、 ApplicationLoadBalancerを使用します。 次の章でそれを達成する方法を見てみましょう。
ALB –AWSのアプリケーションロードバランサー
AWSAPIGatewayを使用してアプリケーションを作成しました。 この章では、APIGatewayをApplicationLoad Balancer(ALB)に置き換える方法について説明します。
まず、APIGatewayと比較してアプリケーションロードバランサーがどのように機能するかを見てみましょう。
アプリケーションロードバランサーでは、特定のパス( / hello /など)をターゲットグループ(リソースのグループ、この場合はLambda関数)にマップします。
ターゲットグループには、1つのLambda関数のみを関連付けることができます。 ターゲットグループが応答する必要があるときはいつでも、アプリケーションロードバランサーはLambdaに要求を送信し、関数は応答オブジェクトで応答する必要があります。 API Gatewayと同様に、 ALBはすべてのHTTPリクエストを処理します。
ALBとAPIGatewayの間にはいくつかの違いがあります。 主な違いの1つは、API GatewayがHTTPS(SSL)のみをサポートしているのに対し、ALBはHTTPとHTTPSの両方をサポートしていることです。
しかし、APIGatewayの長所と短所をいくつか見てみましょう。
APIゲートウェイ:
長所:
- 優れたセキュリティ。
- 実装は簡単です。
- 展開が迅速で、すぐに実行できます。
- スケーラビリティと可用性。
短所:
- トラフィックが多い場合は、かなり高額になる可能性があります。
- さらにオーケストレーションが必要になるため、開発者にとってはある程度の困難が伴います。
- APIシナリオによるパフォーマンスの低下は、アプリケーションの速度と信頼性に影響を与える可能性があります。
API Gatewayを使用する代わりに、ALBの作成と切り替えを続けましょう。
1. ALBとは何ですか?
アプリケーションロードバランサーを使用すると、開発者は着信トラフィックを構成およびルーティングできます。 これは「 ElasticLoadBalancing」の機能です。 クライアントの単一の連絡先として機能し、着信アプリケーショントラフィックを複数のゾーンのEC2インスタンスなどの複数のターゲットに分散します。
2.AWSUIを使用してアプリケーションロードバランサーを作成します
Amazon AWSのUIを使用してアプリケーションロードバランサー(ALB)を作成しましょう。 「サービスの検索」でAWSコンソールにログインします。 」と入力して「 EC2 」と入力し、「ロードバランサー」を見つけます。 」
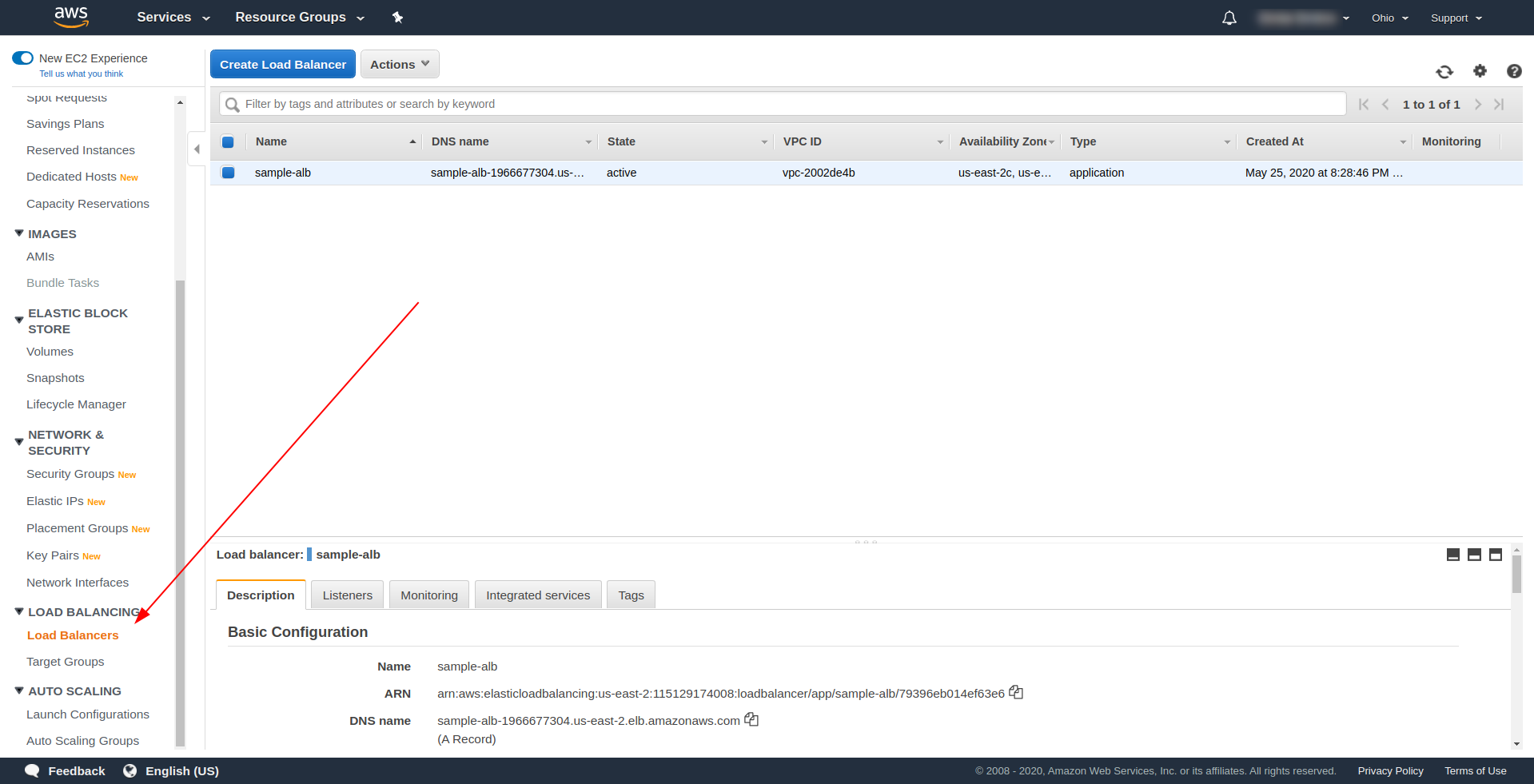
「アプリケーションロードバランサー」の下の「ロードバランサーの作成」をクリックし、「作成」を選択します。 名前には、選択項目を入力します。「 sample-alb」を使用し、スキーム「インターネットに接続」を選択します。IPアドレスタイプはipv4です。
「リスナー」では、HTTPとポート80をそのままにします。HTTPSを使用する前にドメインを用意して確認する必要がありますが、HTTPS用に構成できます。
アベイラビリティーゾーン– VPCの場合、ドロップダウンから使用しているものを選択し、すべての「アベイラビリティーゾーン」にマークを付けます。
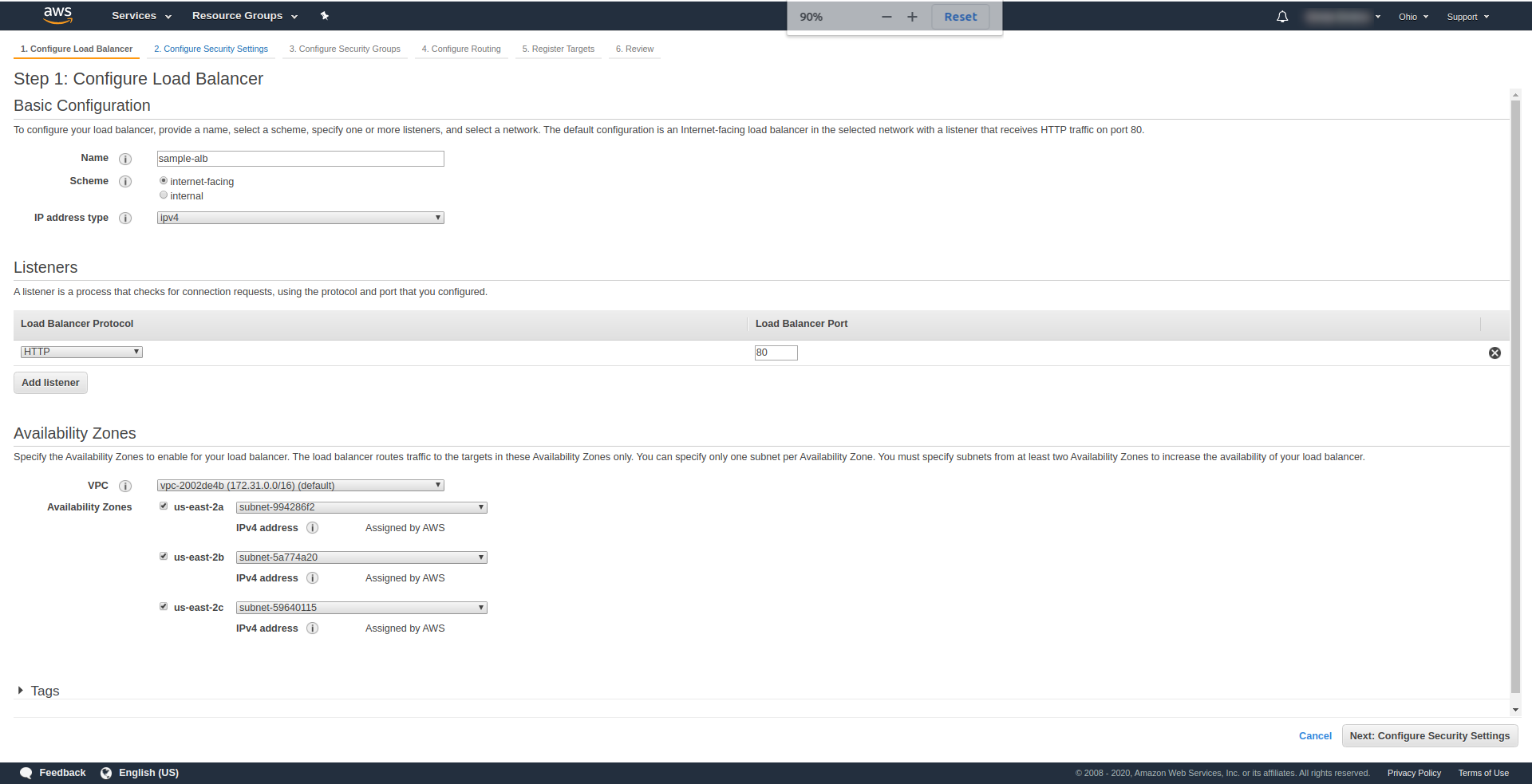
「次へセキュリティ設定を構成する」をクリックして、ロードバランサーのセキュリティを改善するように求めます。 [次へ]をクリックします。
「ステップ3.セキュリティグループの設定」で、「セキュリティグループの割り当て」で「新しいセキュリティグループの作成」を選択します。 次に、「次へ:ルーティングの構成」をクリックして続行します。 「。 ステップ4で、上のスクリーンショットに示されているように構成します。
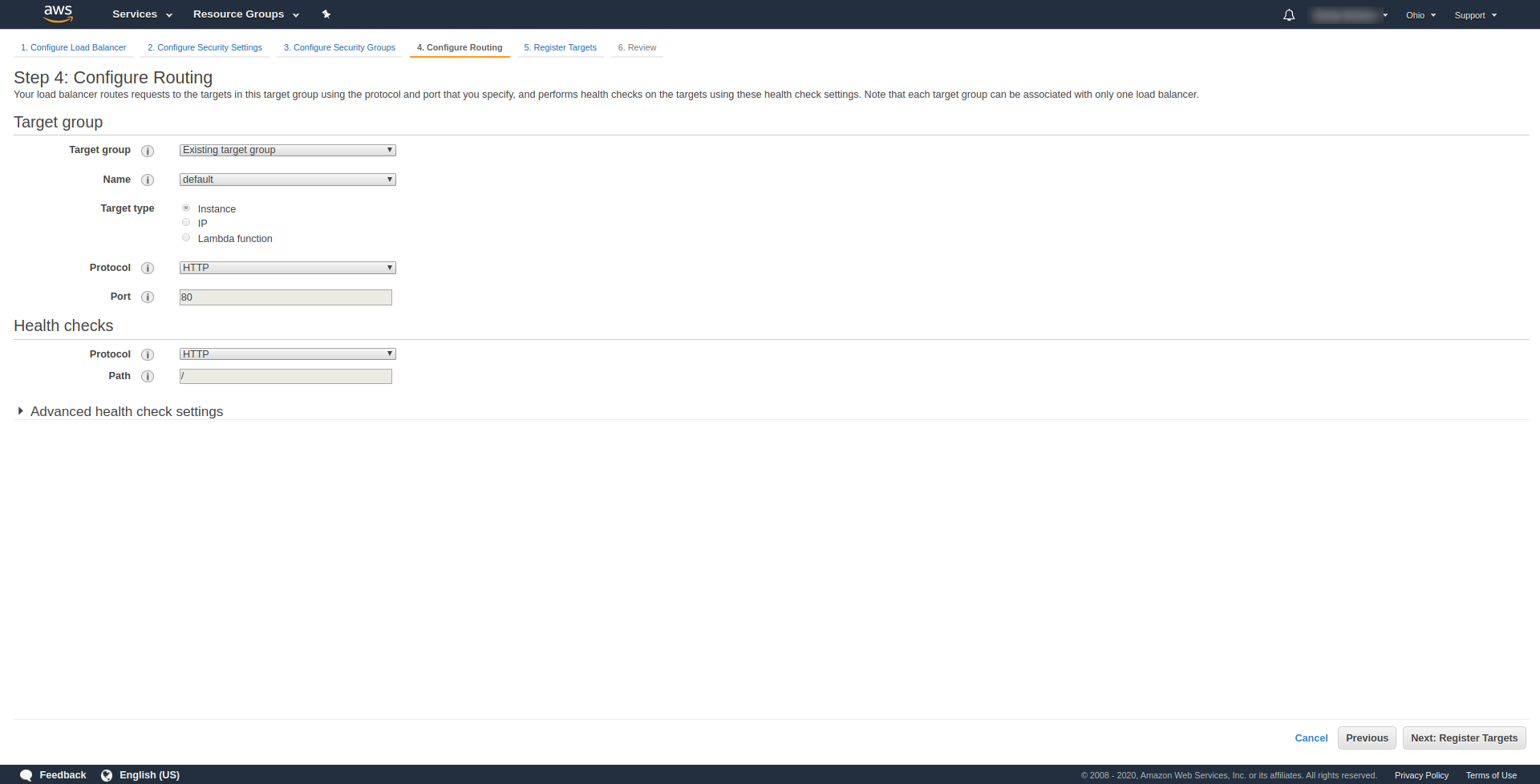
[次へ] 、[次へ]、[作成]の順にクリックします。
ロードバランサーに戻り、スクリーンショットに示すようにARNをコピーします。
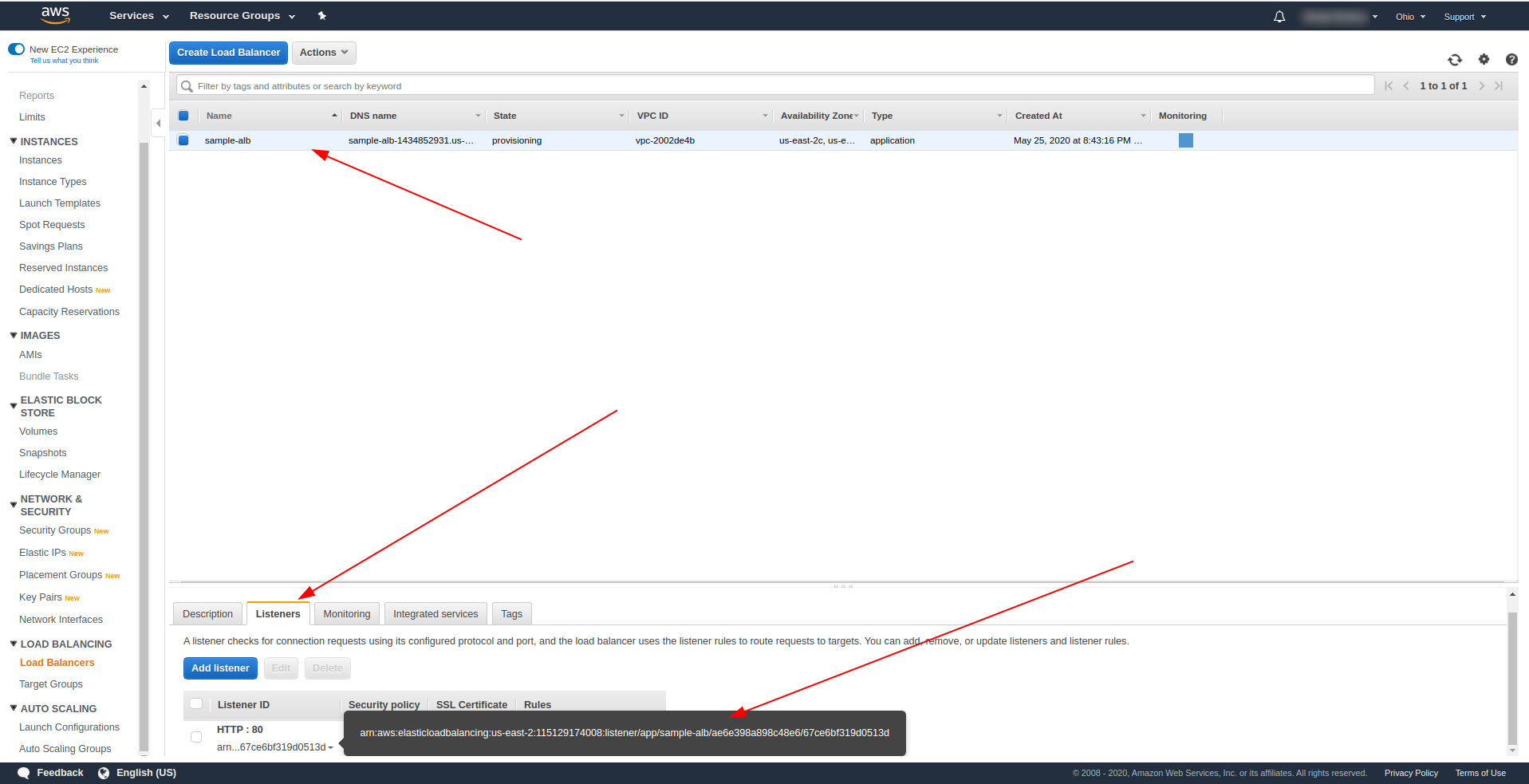
次に、serverless.ymlを変更し、APIGatewayhttpプロパティを削除する必要があります。 eventsプロパティの下で、httpプロパティを削除し、albプロパティを追加します。 関数オブジェクトは次のように終了する必要があります。
こんにちは:
ハンドラー:handler.hello
イベント:
-アルバ:
listenerArn:arn:aws:elasticloadbalancing:us-east-2:115129174008:listener / app / sample-alb / ae6e398a898c48e6 / 67ce6bf319d0513d
優先度:1
条件:
パス:/ hello
ファイルを保存し、アプリケーションをデプロイするためのコマンドを実行しますsls deploy -v
正常にデプロイした後、AWSロードバランサーに戻り、スクリーンショットに示すようにDNS名を見つけます。
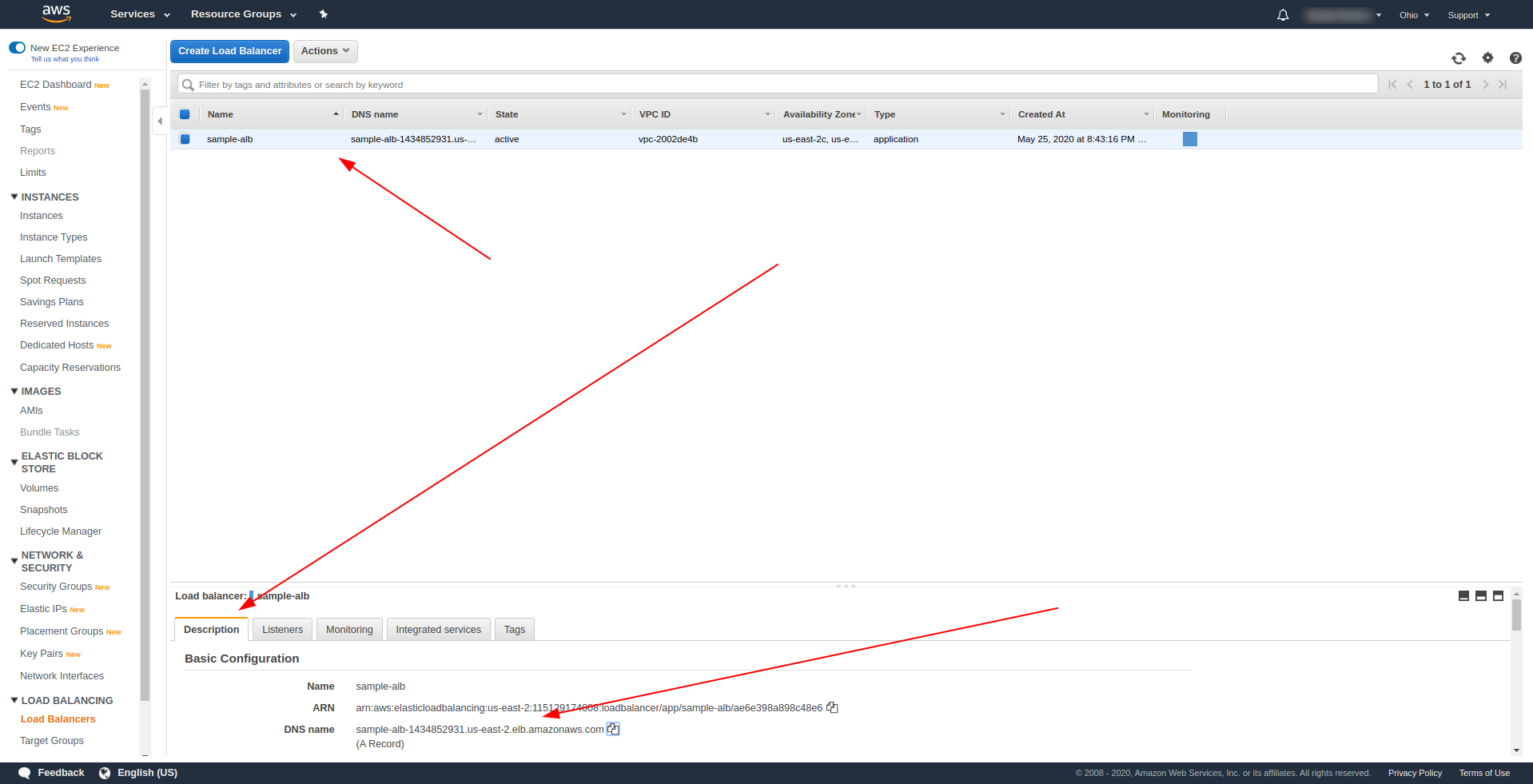
DNS名をコピーし、パス/helloと入力します。
それは機能し、最終的にコンテンツをダウンロードするオプションを提供するはずです:)。 これまでのところ、アプリケーションロードバランサーは正常に機能していますが、アプリケーションはエンドユーザーに対して適切な応答を返す必要があります。 これを行うには、 handler.jsを開き、returnステートメントを次のステートメントに置き換えます。
戻る {
statusCode:200、
statusDescription: "200 OK"、
ヘッダー:{
"Content-Type": "application / json"
}、
isBase64Encoded:false、
本文:JSON.stringify(rows)
}
ALBの違いは、応答にコンテナーstatusDescription、ヘッダー、およびisBase64Encodedを含める必要があることです。 ファイルを保存して再度デプロイしてください。ただし、今回はアプリケーション全体ではなく、変更した機能のみをデプロイします。 以下のコマンドを実行します。
sls deploy -f hello
このように、デプロイする関数helloのみを定義しています。 正常にデプロイされたら、パスを含むDNS名に再度アクセスすると、適切な応答が得られるはずです。
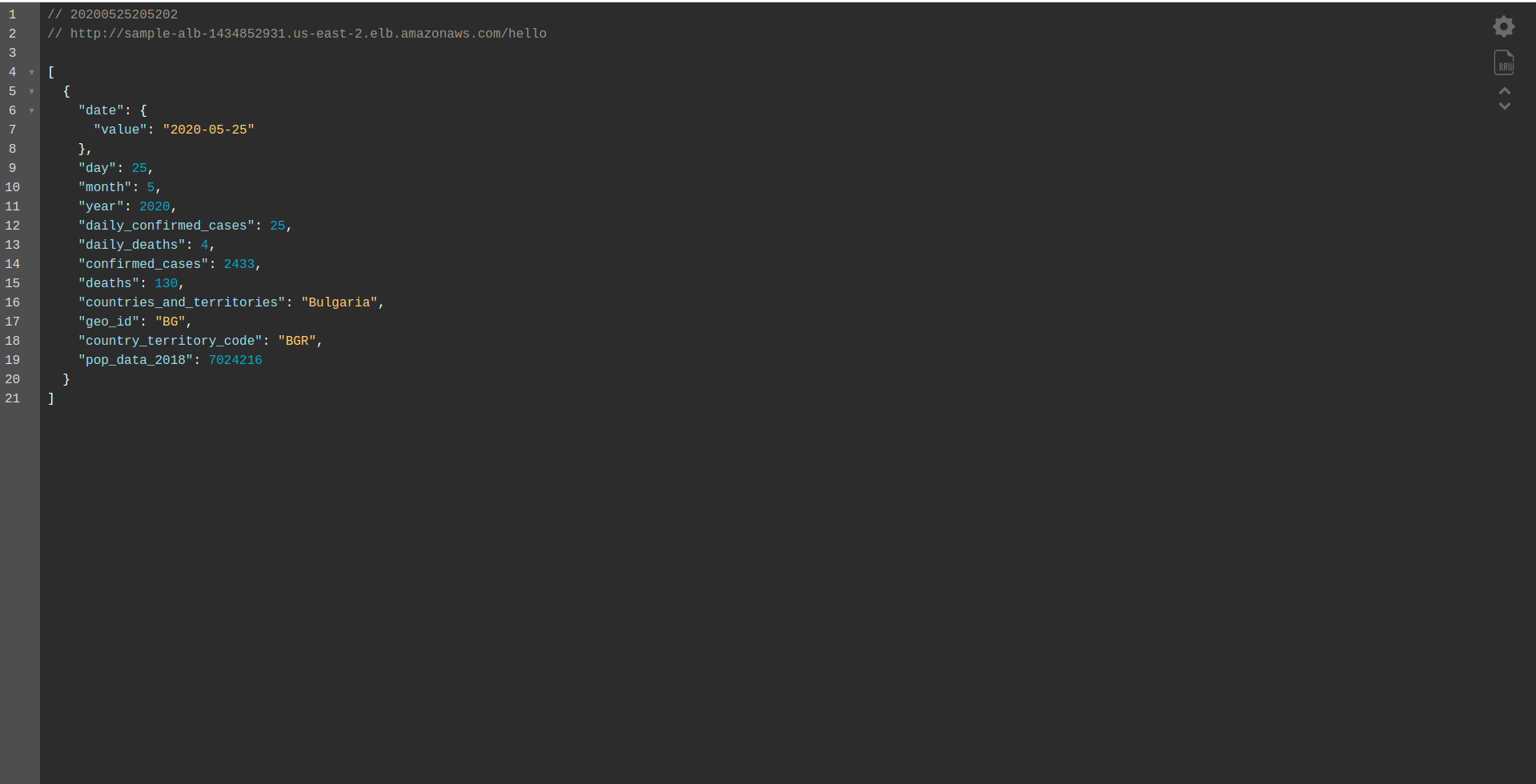
すごい! これで、APIGatewayがApplicationLoadBalancerに置き換えられました。 アプリケーションのロードバランサーはAPIGatewayよりも安価であり、特にトラフィックが多いと予想される場合は、ニーズに合わせてアプリケーションを拡張できるようになりました。
最後の言葉
Serverless Framework、AWS、 BigQueryを使用して簡単なアプリケーションを作成し、その主な使用法について説明しました。 サーバーレスは未来であり、サーバーレスを使用してアプリケーションを処理するのは簡単です。 学習を続け、Serverless Frameworkに飛び込んで、そのすべての機能とその秘密を探ります。 また、非常に簡単で便利なツールです。