
検索エンジンは AI コンテンツを検出できますか?
公開: 2023-08-04過去 1 年間の AI ツールの爆発的な増加は、デジタル マーケティング担当者、特に SEO 担当者に大きな影響を与えました。
コンテンツ作成には時間とコストがかかるため、マーケティング担当者は AI に支援を求めていますが、結果はまちまちです。
倫理的な問題にもかかわらず、繰り返し浮上する疑問の 1 つは、「検索エンジンは私の AI コンテンツを検出できるのか?」というものです。
この質問は、答えが「いいえ」の場合、AI を使用すべきかどうか、またどのように使用すべきかに関する他の多くの質問が無効になるため、特に重要であると考えられています。
機械生成コンテンツの長い歴史
機械生成または機械支援によるコンテンツ作成の頻度は前例のないものですが、それはまったく新しいことではなく、必ずしも否定的なものではありません。
ニュース Web サイトでは、ニュースを最初に速報することが不可欠であり、コンテンツ作成を迅速化するために株式市場や地震計などのさまざまなソースからのデータを長年利用してきました。
たとえば、次のようなロボットの記事を公開するのは事実として正しいです。
- 「今朝[時刻]/[日付]に[場所、都市]で[マグニチュード]の地震が検出されました。これは[最後のイベントの日付]以来初めての地震です。 さらなるニュースが続きます。」
このような更新は、この情報をできるだけ早く入手する必要がある最終読者にとっても役立ちます。
スペクトルの対極では、機械生成コンテンツの「ブラックハット」実装が数多く見られます。
Googleは、「付加価値を提供しない自動生成ページ」という旗印の下、マルコフチェーンを利用して低労力コンテンツを回転させるテキストを生成することを長年非難してきた。
特に興味深いのは、一部の人にとって主に混乱のポイントまたはグレーゾーンであることですが、「付加価値がない」という意味です。
LLM はどのようにして価値を付加できるのでしょうか?
GPTx 大規模言語モデル (LLM) と、会話の対話を改善する微調整された AI チャットボット ChatGPT が注目を集めたことにより、AI コンテンツの人気が急上昇しました。
技術的な詳細には立ち入りませんが、これらのツールについて考慮すべき重要な点がいくつかあります。
生成されたテキストは確率分布に基づいています
- たとえば、「SEO になるのは楽しいです。なぜなら…」と書くと、LLM はすべてのトークンを調べ、トレーニング セットに基づいて次に可能性の高い単語を計算しようとします。 一言で言えば、携帯電話の予測テキストの非常に高度なバージョンと考えることができます。
ChatGPT は生成人工知能の一種です
- これは、出力が予測できないことを意味します。 ランダム化された要素があり、同じプロンプトに対して異なる応答をする場合があります。
これら 2 つの点を理解すると、ChatGPT のようなツールには従来の知識がまったくなく、何も「認識」していないことが明らかになります。 この欠点が、すべてのエラー、または「幻覚」と呼ばれる現象の基礎となっています。
多数の文書化された出力は、このアプローチがどのように誤った結果を生成し、ChatGPT 自体が繰り返し矛盾する原因となるかを示しています。
これは、頻繁に幻覚が現れる可能性を考慮すると、AI が作成したテキストに「付加価値を加える」ことの一貫性について重大な疑問を引き起こします。
根本的な原因は LLM がテキストを生成する方法にあり、新しいアプローチがなければ簡単に解決できません。
これは、特に Your Money, Your Life (YMYL) に関するトピックでは重要な考慮事項であり、不正確な場合は人々の財政や生活に重大な損害を与える可能性があります。
今年、Men's Health や CNET などの主要出版物が、AI が生成した事実と異なる情報を掲載したことが摘発され、懸念が浮き彫りになりました。
Google は YMYL コンテンツで Search Generative Experience (SGE) コンテンツを抑制するのに苦労しているため、この問題を抱えているのはパブリッシャーだけではありません。
Googleは、生成された回答には注意すると述べ、特に「医療分野であるため、子供へのタイレノールの投与に関する質問には回答を示さない」という例まで挙げているにもかかわらず、SGEは明らかにそうするだろう。これは単に質問するだけでわかります。
マーケティング担当者が頼りにする毎日のニュースレター検索を入手します。
規約を参照してください。
Google の SGE と MUM
Google がユーザーのクエリに答えるための機械生成コンテンツの余地があると信じていることは明らかです。 Googleは、2021年5月にマルチタスク統合モデルであるMUMを発表して以来、これを示唆してきました。

MUM が取り組もうとした課題の 1 つは、人々が複雑なタスクに対して平均 8 つのクエリを発行するというデータに基づいていました。
最初のクエリでは、検索者はいくつかの追加情報を学習し、関連する検索を促し、それらのクエリに答えるための新しい Web ページを表示します。
Google は次のように提案しました。最初のクエリを取得し、ユーザーのフォローアップの質問を予測し、インデックスの知識を使用して完全な回答を生成できたらどうなるでしょうか?
もしそれがうまくいけば、このアプローチはユーザーにとっては素晴らしいかもしれないが、SEO が SERP 内で足場を築くために依存している多くの「ロングテール」またはゼロボリュームのキーワード戦略を本質的に一掃してしまうことになる。
Google が AI が生成した回答に適したクエリを特定できると仮定すると、多くの質問は「解決された」とみなされる可能性があります。
ここで疑問が生じます…
- Google はユーザーを自社の検索エコシステム内に留めて答えを自ら生成できるのに、なぜ検索者にあらかじめ生成された答えをウェブページに表示するのでしょうか?
Google には、ユーザーを自社のエコシステム内に留めておくための金銭的インセンティブがあります。 私たちはこれを実現するために、注目のスニペットからユーザーが SERP でフライトを検索できるようにするまで、さまざまなアプローチを見てきました。
生成されたテキストがすでに提供できる以上の価値を提供していないと Google が判断したとします。 その場合、単に検索エンジンにとってのコストとメリットの問題になります。
生成にかかる費用を吸収し、ユーザーに答えを待たせることで、ユーザーがすでに存在することがわかっているページに迅速かつ安価に誘導することで、長期的により多くの収益を生み出すことができるでしょうか?
AI コンテンツの検出
ChatGPT の使用量の爆発的な増加に伴い、テキスト コンテンツを入力してパーセンテージ スコアを出力できる数十の「AI コンテンツ ディテクタ」が登場しました。問題はそこにあります。
さまざまな検出器がこのパーセンテージ スコアにラベルを付ける方法には多少の違いがありますが、ほぼ常に同じ出力、つまり提供されたテキスト全体が AI によって生成されたものであるという確実性のパーセンテージが得られます。
このため、パーセンテージに「75% AI / 25% 人間」などのラベルが付けられると混乱が生じます。
多くの人はこれを、「AI がこのテキストの 100% を書いたことを 75% 確信している」という意味であるのに、「テキストは 75% が AI によって書かれ、25% が人間によって書かれた」という意味であると誤解します。
この誤解により、テキスト入力を微調整して AI 検出器を「通過」させる方法についてアドバイスを提供する人もいます。
たとえば、二重感嘆符 (!!) の使用は非常に人間的な特徴であるため、これを AI が生成したテキストに追加すると、AI 検出器は「99%+ 人間的」スコアを与えることになります。
これは、検出器を「だました」と誤解されます。
ただし、提供された通路が 100% AI によって生成されたものではなくなったため、これは検出器が完全に機能している例です。
残念ながら、AI 検出器を「だます」ことができるというこの誤解を招く結論は、Google などの検索エンジンが AI コンテンツを検出しないこととよく混同されており、Web サイト所有者に誤った安心感を与えています。
AI コンテンツに対する Google のポリシーとアクション
AI コンテンツに関する Google の声明はこれまで、施行に関して柔軟な余地を与えるほど曖昧でした。
ただし、今年 Google 検索セントラルで更新されたガイダンスが公開され、次のように明確に記載されています。
「私たちはコンテンツの制作方法ではなく、コンテンツの品質に重点を置いています。」
これに先立って、Google 検索担当のダニー・サリバン氏は Twitter の保護活動に割って入り、「AI コンテンツが悪いとは言っていない」と断言した。
Googleは、スポーツのスコア、天気予報、トランスクリプトなど、AIが役立つコンテンツを生成する方法の具体例を挙げている。
Googleがそこに到達する手段よりも出力をはるかに重視していることは明らかで、「検索結果のランキングを操作することを主な目的としてコンテンツを生成することは、スパムポリシーに違反する」ことをさらに強調している。
SERP操作との戦いはGoogleに長年の経験があり、SpamBrainなどの自社システムの進歩により、UGCスパム、スクレイピング、クローキング、その他あらゆる形式のコンテンツを含む検索の99%が「スパムフリー」になったと主張している。世代。
多くの人がテストを実行して、Google が AI コンテンツにどのように反応するか、品質の境界線をどこに引くかを確認しました。
ChatGPT のリリース前に、私は主に教師なし GPT3 モデルによって生成された 10,000 ページのコンテンツからなる Web サイトを作成し、ビデオ ゲームに関する人々の質問にも答えました。
最小限のリンクで、サイトはすぐにインデックス付けされ、着実に成長し、毎月数千人の訪問者を獲得しました。
2022 年の 2 つの Google システム アップデート (役立つコンテンツ アップデートとその後のスパム アップデート) 中に、Google は突然、ほぼ完全にサイトを抑制しました。
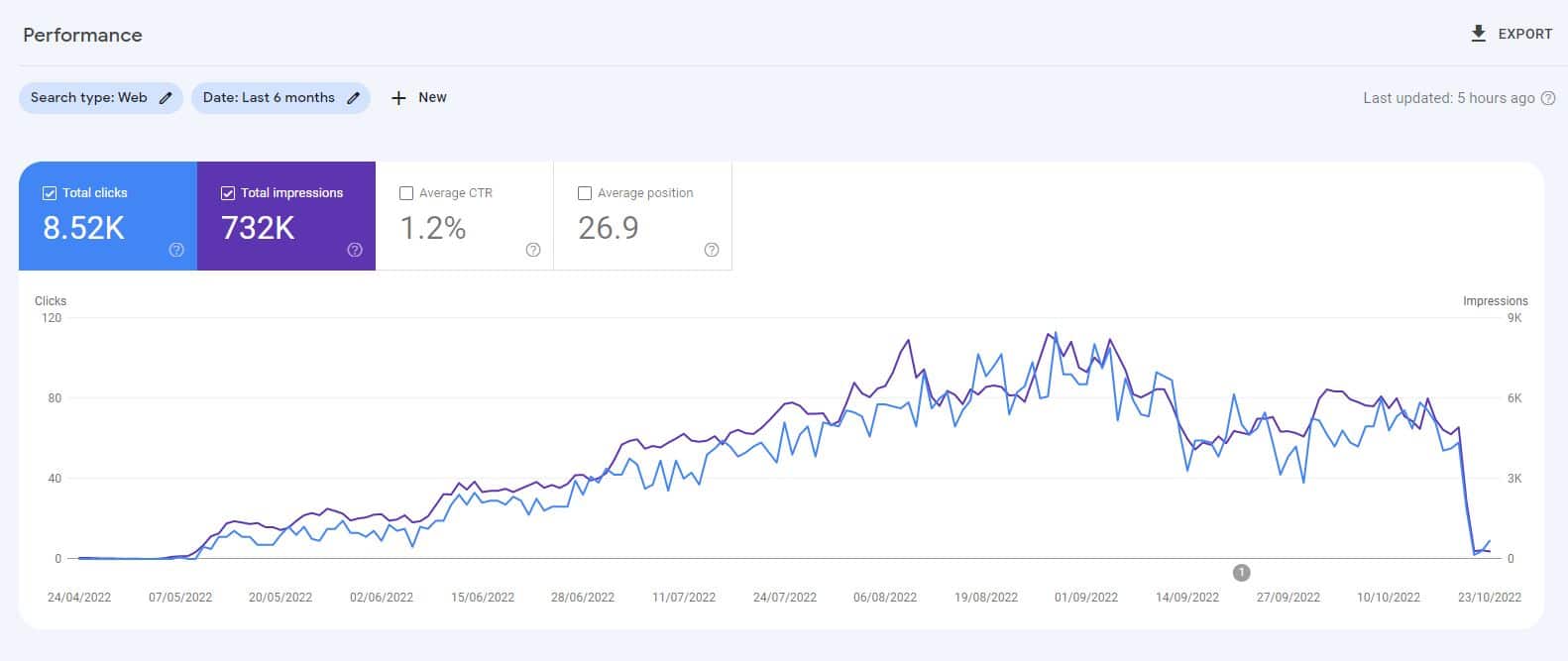
このような実験から「AIコンテンツは機能しない」と結論付けるのは間違いです。
しかし、このことは、当時の Google が次のことを行ったことを私に示しました。
- 監視されていない GPT-3 コンテンツを「品質」として分類していませんでした。
- 他の多数のシグナルを使用すると、そのような結果を検出して削除できます。
究極の答えを得るには、より良い質問が必要です
Google のガイドライン、検索システム、SEO の実験、常識に基づいて、「検索エンジンは AI コンテンツを検出できるか?」 おそらく間違った質問です。
良く言っても、それは非常に短期的な見方に過ぎません。
ほとんどのトピックでは、LLM はトレーニング データ以外の情報にライブ Web アクセスできるにもかかわらず、事実の正確性と Google の EEAT 基準を満たすという点で「高品質」のコンテンツを一貫して作成するのに苦労しています。
AI は、これまでコンテンツが不足していたクエリに対する回答を生成する点で大幅な進歩を遂げています。 しかし、Google が SGE とともにより高い長期目標を目指しているため、この傾向は薄れる可能性があります。
Google のナレッジ システムは、ユーザーを多数の小さなサイトに誘導するのではなく、多くのロングテール クエリに応えるための回答を提供し、長文の専門コンテンツに焦点が戻ると予想されています。
この記事で表明された意見はゲスト著者の意見であり、必ずしも Search Engine Land とは限りません。 スタッフの著者はここにリストされています。