
ChatGPT がエンティティのコンテンツを最適化するのにどのように役立つか
公開: 2023-08-07ChatGPT を戦略的に利用すると、出力品質において人間の手作業を上回ることができます。
いいえ、ツールはより良いコンテンツを作成しません。
その代わりに、このテクノロジーを備えたライターは、Google のランキング基準に合わせて最適化されたコンテンツを作成できると私は信じています。
コンテンツのスコアリングとエンティティ抽出のさまざまな方法を検討することで、ツールの利点を最大化できるようにガイドすることを目指しています。
「キーワードを超えて: エンティティが最新の SEO 戦略に与える影響」では、関連するエンティティを Web サイト (つまり、トピック マップ) 全体に含める方法とその理由について説明しました。
この記事では、エンティティを使用してランキングの高い SEO コンテンツを作成する理由と方法に焦点を当てます。
エンティティ SEO と OpenAI はどのように関連していますか?
ソフトウェアが検索結果に対するエンティティの使用をどのように最適化するかを説明する前に、エンティティ SEO と OpenAI の ChatGPT の類似点を理解しましょう。
言語の構成要素
最も基本的なレベルでは、言語は以下を中心に構築されています。
- 主題:文章が何について (または誰について) 話しているのか。
- 述語:主語について何かを述べます。
たとえば、「猫はマットの上に座った」という文では、「猫」が主語であり、「マットの上に座った」が述語です。
Google の検索エンジンと OpenAI の ChatGPT はどちらも、言語の基本的な構造を理解するように設計されています。
セマンティック検索エンジンは、計算効率の高い方法でコンテンツを理解することに重点を置いています。
ChatGPT はさらに一歩進んで、より多くの計算を使用してコンテンツを生成します。
セマンティック検索エンジン
Google の検索エンジンは、基本的に Web ページ上の文の主題であるエンティティを識別します。
次に、それらのエンティティの周囲のコンテキストを使用して、述語、つまりそれらのエンティティについて何が言われているかを理解します。
これにより、Google はページのコンテンツとそれがユーザーの検索クエリにどのように関連するかを理解できるようになります。
検討中の関係は、Google のナレッジ グラフに示されています。
Google は記事を分析する際、ナレッジ グラフを使用してより深い洞察を取得します。
コンテンツ内の関連するエンティティと述語を識別し、その作品がどのキーワード検索に最も関連しているかを識別できるようにします。
OpenAIのChatGPT
一方、ChatGPT は、トランスフォーマー モデルと埋め込みを使用して、主語と述語の両方を理解します。
具体的には、モデルのアテンション メカニズムにより、文内の異なる単語間の関係を理解し、述語を効果的に理解できるようになります。
一方、埋め込みは、モデルが単語自体の関係と意味を理解するのに役立ちます。これには主題の理解も含まれます。

大きな違いにもかかわらず、ChatGPT とエンティティ SEO には共通の機能があります。
トピックに関連するエンティティと述語を認識します。 この共通点は、言語の理解にとって実体がいかに重要であるかを強調しています。
複雑さにもかかわらず、SEO 専門家はエンティティ、主語、およびそれらの述語に重点を置く必要があります。
では、この新しい理解をどのように利用してコンテンツを最適化できるのでしょうか?
エンティティの新しいコンテンツの最適化
Google は、ウェブページ上のエンティティとその述語を識別します。 また、関連する可能性のあるページ間でそれらを比較します。
本質的には、ユーザーの検索クエリと Web 上で利用可能なコンテンツの間で最も一致するものを見つけようとする仲人のようなものです。
Google のアルゴリズムは高品質の結果を得るために最適化されているため、Google の結果の上位 10 件を調べることから最適化プロセスを開始します。
これにより、特定の検索語に対して Google が優先する属性についての洞察が得られます。
私たちの代理店では、記事を 10 ~ 20% 改善できる潜在的な機能強化を特定するフレームワークを適用しています。これについては以下で共有します。
適切な側面を優先するフレームワークは、コンテンツと最高ランクの素材との違いを示すことができます。
コンテンツ制作にあたっては、このフレームワークに従い、これらの優先事項を満たしていきます。
これらの基準をすべて満たせば、すぐに成功できると考えています。

チェックリストのエンティティ部分を掘り下げる
次のように考えてください。
Google が、特定のエンティティとその述語が同時に出現する頻度を追跡していると想像してください。
特定のトピックを検索しているユーザーにとって、どの組み合わせが最も重要であるかが判明します。
SEO の専門家としての目標は、これらの重要なエンティティをコンテンツに含めることです。Google がすでに気に入っていると表示している上位の結果をリバース エンジニアリングすることで、これらの重要なエンティティを特定できます。
ウェブページに、特定のユーザー検索に対して Google が期待するエンティティと述語が含まれている場合、コンテンツはより高いスコアを獲得します。
新しいエンティティ関係の例外については、今後の説明で触れます。
ここで、上位 10 件の結果の分析に役立つ、ChatGPT および NLP テクニックを戦略的に利用するツールが活躍します。
これを手動で試みると、消費する必要があるデータの規模が大きくなるため、時間がかかり、困難になる可能性があります。
ステップ 1: エンティティの抽出
この分析を行うには、Google のネイティブなエンティティと述語の抽出プロセスを模倣し、その結果を実行可能なアクション プラン/作成者のガイドに変える必要があります。
専門用語では、この演習は固有表現認識として知られており、さまざまな NLP ライブラリには独自のアプローチがあります。
幸いなことに、これらの手順を自動化する多くのコンテンツ作成ツールが市場で入手可能です。
ただし、SEO ツールの推奨事項に盲目的に従う前に、そのツールがうまく機能するものとそうでないものを理解しておくと役立ちます。
固有表現認識 (NER)
NER は、スポッティングと分類という 2 段階のプロセスであると考えてください。
スポッティング
- 最初のステップは「I Spy」のゲームのようなものです。 アルゴリズムはテキストを単語ごとに読み取り、エンティティとなる可能性のある単語またはフレーズを探します。 それは、誰かが本を読んで、人、場所、日付の名前を強調表示するのと似ています。
分類する
- アルゴリズムが潜在的なエンティティを検出したら、次のステップは、それぞれがどのようなタイプのエンティティであるかを把握することです。 これは、強調表示された単語を異なるバケット ( People用、 Locations用、 Dates用など) に分類するのと似ています。
例を考えてみましょう。 「イーロン・マスクは 1971 年にプレトリアで生まれました。」という文があるとします。
スポッティング ステップでは、アルゴリズムは「イーロン マスク」、「プレトリア」、および「1971」を潜在的なエンティティとして識別する可能性があります。
分類ステップでは、「Elon Musk」をpersonとして、「Pretoria」をLocationとして、「1971」をDateとして分類します。
このアルゴリズムでは、ルールと大量のテキストでトレーニングされた機械学習モデルを組み合わせて使用します。
これらのモデルは、さまざまな種類のエンティティがどのように見えるかを例から学習しているため、新しいテキストに遭遇したときに経験に基づいた推測を行うことができます。
関係抽出(RE)
NER がテキスト内のエンティティを識別した後の次のステップは、これらのエンティティ間の関係を理解することです。
これは、関係抽出 (RE) と呼ばれるプロセスを通じて行われます。 これらの関係は本質的に、エンティティを接続する述語として機能します。
NLP のコンテキストでは、これらのつながりは、次の 3 つの項目のセットであるトリプルとして表されることがよくあります。
- テーマ。
- 述語。
- オブジェクトです。
通常、主語と目的語は NER によって識別されるエンティティであり、述語は RE によって識別されるそれらの間の関係です。
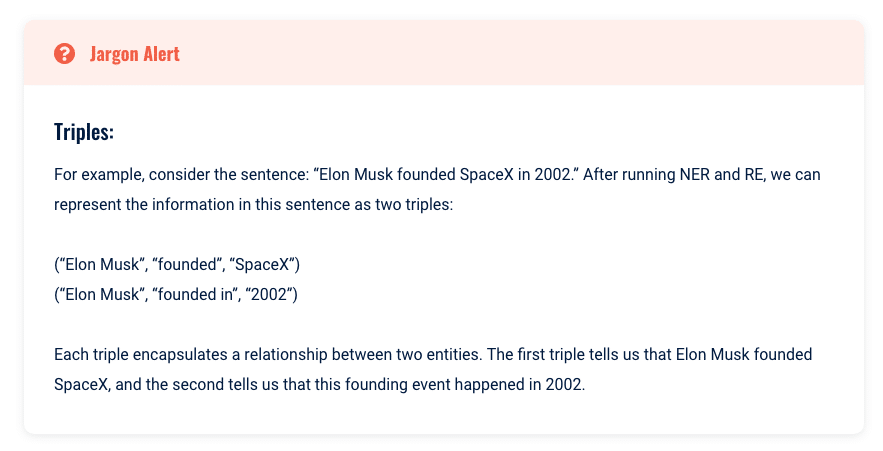
関係を解読して理解するためにトリプルを使用するという概念は、見事に単純化されています。 私たちは最小限の計算、時間、またはメモリで提示された核となるアイデアを把握できます。
実体とその述語だけに焦点を当てることで、何が言われているかをよく理解できるのは、言語の性質の証拠です。
余分な単語をすべて削除すると、重要な構成要素、つまり著者が織り上げている関係性のスナップショットが残ります。
関係を抽出してトリプルとして表現することは、NLP の重要なステップです。
これにより、コンピューターがテキストの物語と識別されたエンティティの周囲のコンテキストを理解できるようになり、人間の言語をより微妙に理解して生成できるようになります。
Google は依然として機械であり、Google の言語理解は人間の理解とは異なることを忘れないでください。
また、Google はコンテンツを書く必要はありませんが、計算需要のバランスを取る必要があります。 代わりに、コンテンツを検索クエリにリンクするという目的を達成するための最小限の情報を抽出できます。
ステップ 2: ライター用ガイドを作成する
有用な分析とロードマップを生成するには、エンティティとその関係を抽出する Google のプロセスを模倣する必要があります。
検索結果のトップ 10 に含まれるこれら 2 つの重要なアイデアを理解し、採用する必要があります。 幸いなことに、ロードマップの構築には複数のアプローチ方法があります。
- エンティティ抽出に頼ることができます
- キーワードフレーズを抽出できます。
エンティティルート
テストできるルートの 1 つは、InLinks などのツールに似た方法論です。
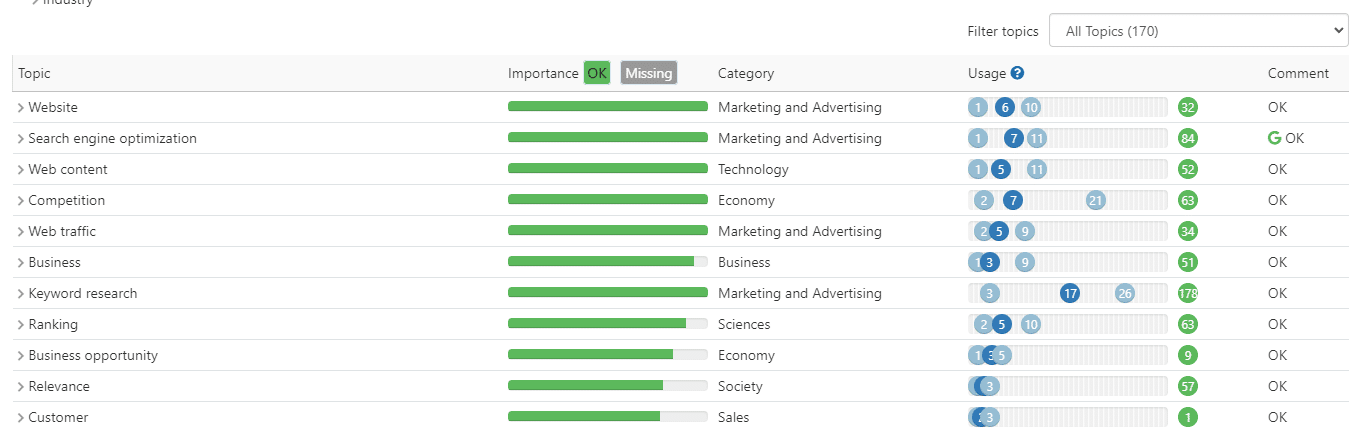
これらのプラットフォームは、上位 10 件の結果に対してエンティティ抽出を採用しており、おそらく Google Cloud の NER API を利用しています。
次に、コンテンツ内で抽出されたエンティティの最小頻度と最大頻度を決定します。
これらのエンティティの使用状況に基づいて、コンテンツが評価されます。
マテリアル内でエンティティが適切に使用されているかどうかを判断するために、これらのプラットフォームは多くの場合、独自のエンティティ認識アルゴリズムを考案します。
長所と短所
この方法は効果的であり、より信頼できるコンテンツを作成するのに役立ちます。 ただし、関係の抽出という重要な側面を見落としています。
エンティティの使用状況を上位の記事と照合することはできますが、コンテンツに関連する述語やエンティティ間の関係がすべて含まれているかどうかを検証するのは困難です。 (注: Google Cloud は関係抽出 API を公開していません。)
この戦略のもう 1 つの潜在的な落とし穴は、上位 10 記事に含まれるすべてのエンティティの包含を促進することです。
理想的には、すべてを包含したいと考えますが、現実には、一部のエンティティが他のエンティティよりも重みを持っています。
さらに問題を複雑にしているのは、検索結果には混合の意図が含まれることがよくあり、一部のエンティティは特定の検索意図に応える記事にのみ関連することを意味します。
たとえば、製品リスト ページのエンティティ構成は、ブログ投稿とは大きく異なります。
ライターにとって、単一単語のエンティティをコンテンツに関連するトピックに変換することも困難な場合があります。 特定の競合他社のオンとオフを切り替えると、これらの問題を解決できる可能性があります。
誤解しないでください。私はこれらのツールのファンであり、分析の一部として使用しています。
ここで紹介するすべてのアプローチにはそれぞれ長所と短所があり、そのすべてがコンテンツをある程度強化することができます。
ただし、私の目的は、テクノロジーと ChatGPT を使用してエンティティを最適化するさまざまな方法を提示することです。
キーワードフレーズルート
当社のツールで採用したもう 1 つの戦略には、競合上位 10 社から最も重要なキーワード フレーズを抽出することが含まれます。
キーワード フレーズの美しさはその透明性にあり、エンド ユーザーがキーワード フレーズが何を表しているのかを理解しやすくなります。
さらに、通常は、主語や実体だけではなく、主要なトピックの主語と述語を捉えます。
ただし、1 つの欠点は、ユーザーがこれらのキーワードをコンテンツにシームレスに組み込むのに苦労することが多いことです。
むしろ、キーワードを詰め込みすぎて、キーワード フレーズが体現するものの本質を見逃してしまう傾向があります。
残念ながら、開発者の観点から見ると、キーワード フレーズの本質を捉える能力に基づいてライターを評価し、採点することは困難です。
したがって、開発者はキーワード フレーズの正確な使用状況に基づいてスコアを付ける必要があり、これでは真に意図された動作が妨げられます。
キーワード フレーズ アプローチのもう 1 つの大きな利点は、キーワードが ChatGPT などの AI ツールの道しるべとして機能することが多く、生成テキスト モデルが主要なエンティティとその述語 (つまり、トリプル) を確実に捕捉できることです。
最後に、名詞の長いリストが与えられた場合と、キーワード フレーズのリストが与えられた場合の違いを考えてみましょう。
作家として、ばらばらの名詞のリストから一貫した物語を紡ぐのは難しいと感じるかもしれません。
しかし、キーワード フレーズが提示されると、それらが段落内でどのように自然に相互接続され、より一貫性のある意味のある物語に貢献するかを識別するのがはるかに簡単になります。
キーワードフレーズを抽出するためのさまざまなアプローチには何がありますか?

私たちは、キーワード フレーズがどのトピックについて書く必要があるかを効果的にガイドできることを確立しました。
ただし、市場に出回っているさまざまなツールでは、これらの重要なフレーズを抽出するためのさまざまなアプローチが採用されていることに注意することが重要です。
キーワード抽出は NLP の基本的なタスクであり、テキストの内容を要約する重要な単語やフレーズを特定することが含まれます。
人気のあるキーワード抽出アルゴリズムがいくつかあり、ページ上のエンティティをキャプチャする際にそれぞれ独自の長所と短所があります。
TF-IDF (用語頻度 - 逆文書頻度)
TF-IDF は SEO の間でよく議論されるポイントですが、誤解されることも多く、その洞察が必ずしも正しく適用されるわけではありません。
スコアリングに盲目的に従うと、驚くべきことに、コンテンツの品質が低下する可能性があります。
TF-IDF は、文書内の各単語の頻度と全文書にわたる希少性に基づいて文書内の各単語を重み付けします。
これはシンプルで迅速な方法ですが、単語の文脈や意味は考慮されません。
どのような価値を提供できるのか
スコアの高い単語は、個々のページでは頻繁に使用され、上位ページのコレクション全体では使用頻度が低い単語を表します。
一方で、これらの用語は、ユニークで特徴的な内容のマーカーと見なすこともできます。
これらにより、競合他社が徹底的にカバーしていないターゲット キーワード テーマ内の特定の側面やサブトピックが明らかになる可能性があり、独自の価値を提供できるようになります。
ただし、高スコアの用語は誤解を招く可能性もあります。
TF-IDF は、特定のランキング記事にとって固有に重要な用語の高いスコアを明らかにできますが、ランキングにとって一般に重要な用語やトピックを表すものではありません。
この基本的な例としては、企業のブランド名が挙げられます。 単一の文書または記事内で繰り返し使用することはできますが、他のランキング記事では決して使用できません。
それをコンテンツに含めてもまったく意味がありません。
一方、上位のページに一貫して出現する TF-IDF スコアの低い用語が見つかった場合は、ページに含めるべき重要な「ベースライン」コンテンツを示している可能性があります。
それらは一意ではないかもしれませんが、特定のキーワードまたはトピックとの関連性のために必要である可能性があります。
注: TF-IDF は多くの戦略を表しますが、追加の数学をバリエーションとして適用できます。 これらには、飽和点や利益逓減の計算を導入する BM25 などのアルゴリズムが含まれます。
さらに、TF-IDF は、その単語が含まれる上位 10 ページの割合を用語ごとに遡って表示することで大幅に改善でき、多くの場合改善されます。 ここで、アルゴリズムは注目すべき用語を特定するのに役立ちますが、上位 10 位の用語がその用語をどの程度共有しているかを示すことで、「ベースライン」用語をより深く理解するのにも役立ちます。
RAKE(高速自動キーワード抽出)
RAKE はすべてのフレーズを潜在的なキーワードとみなします。これは、複数の単語のエンティティをキャプチャするのに役立ちます。
ただし、単語の順序は考慮されていないため、意味のないフレーズが生成される可能性があります。
RAKE アルゴリズムを上位 10 ページのそれぞれに個別に適用すると、各ページのキー フレーズのリストが生成されます。
次のステップは、重複、つまり複数の上位ページに表示されるキー フレーズを探すことです。
これらの一般的なフレーズは、ターゲット キーワードに関連して検索エンジンが期待する特に重要なトピックを示している可能性があります。
これらのフレーズを(意味のある自然な方法で)独自のコンテンツに組み込むことで、ページの関連性が向上し、その結果、ターゲットのキーワードに対するランキングが向上する可能性があります。
ただし、すべての共有フレーズが必ずしも有益であるわけではないことに注意することが重要です。 一般的なものであるか、トピックに広く関連しているため、一般的なものもあります。
目標は、特定のキーワードに関連する重要な意味とコンテキストを伝える共有フレーズを見つけることです。
すべてのキーワード抽出テクニックは、頭を使って競合他社やキーワードをオンまたはオフにできるようにすることで改善できます。
競合他社や特定のキーワードをオンまたはオフにする機能は、前述の問題を解決するのに役立ちます。
競合他社
キーワード
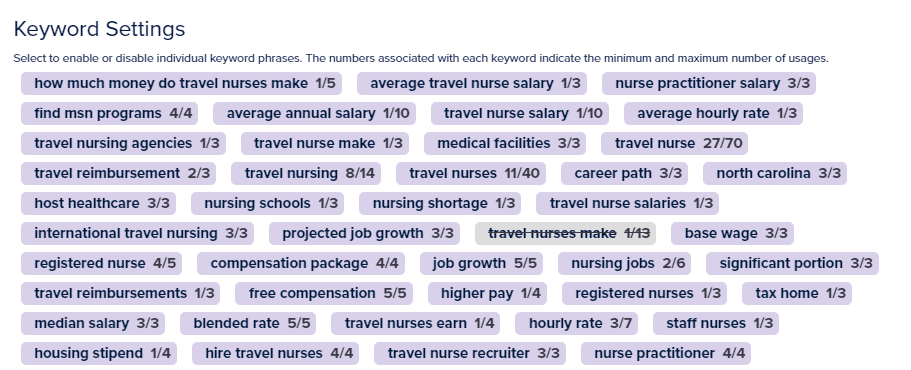
このアプローチは基本的に、RAKE (個々の文書内のキー フレーズを識別する) と、より TF-IDF に似た戦略 (文書のコレクション全体にわたる用語の重要性を考慮する) の両方の長所を組み合わせる方法を提供します。
そうすることで、ターゲットキーワードのコンテンツ状況をより包括的に理解し、独自で関連性の高いコンテンツを作成することができます。
YAKE (さらに別のキーワード抽出ツール)
最後に、 YAKE は単語の頻度とテキスト内での位置を考慮します。
これは、文書の最初または最後に表示される重要なエンティティを識別するのに役立ちます。
ただし、途中に表示される重要なエンティティが見逃される可能性があります。
各アルゴリズムはテキストをスキャンし、さまざまな基準 (頻度、位置、意味の類似性など) に基づいて潜在的なキーワードを特定します。
次に、潜在的なキーワードごとにスコアを割り当てます。 最もスコアの高いキーワードが最終的なキーワードとして選択されます。
これらのアルゴリズムはエンティティを効果的にキャプチャできますが、制限があります。
たとえば、まれなエンティティを見逃したり、テキスト内にキーワードとして表示されなかったりする可能性があります。 また、複数の名前を持つエンティティや、異なる方法で参照されるエンティティに苦労することもあります。
要約すると、キーワードは通常の NER よりもいくつかの機能強化を提供します。
- ライターにとっては理解しやすいです。
- これらは述語とエンティティの両方をキャプチャします。
- 次のセクションで説明するように、これらは AI がエンティティに最適化されたコンテンツを作成するためのより良い道しるべとして機能します。
OpenAI
ChatGPT と OpenAI は、SEO における真の変革者です。
その可能性を最大限に引き出すには、知識豊富な SEO 専門家が正しい道に沿って誘導し、綿密に構築されたエンティティ マップが関連トピックの執筆をガイドする必要があります。
次のようなシナリオを考えてみましょう。
ChatGPT にアクセスして、ほぼすべてのテーマについて記事を書くように依頼すると、すぐに応じてくれることに気づいたかもしれません。
ただし、問題は、結果の記事がキーワードでランク付けされるように最適化されるかどうかです。
一般的なコンテンツと検索に最適化されたコンテンツを明確に区別する必要があります。
AI にコンテンツの執筆を任せると、通常の読者にアピールする記事が生成される傾向があります。
ただし、SEO に最適化されたコンテンツは別の調子で踊ります。
Google は、読みやすく、定義や必要な背景知識が含まれているコンテンツを好む傾向があり、基本的に読者が検索クエリに対する答えを見つけるためのフックを豊富に提供しています。
ChatGPT はトランスフォーマー アーキテクチャを利用しており、トレーニングの対象となったデータ内で観察された頻度とパターンに基づいてコンテンツを生成する傾向があります。 このデータのごく一部は、Google の上位記事で構成されています。
対照的に、Google は時間が経つにつれて、ユーザーにとっての有効性に合わせて検索結果を調整します。つまり、最も適切なコンテンツが生き残ることになります。
これらの不朽の記事に含まれるエンティティは、基本的なコンテンツとしてエミュレートすることが不可欠であり、ChatGPT がそのまま生成するものとは大きく異なる傾向があります。
重要な点は、読みやすさの観点から勝者となるコンテンツと、Google 環境で勝者となるコンテンツには違いがあるということです。 Web コンテンツの世界では、実用性がすべてに優先します。
ニールセンがずっと前に示したように、スキャン可能性は最高の地位にあります。

ユーザーは、Web コンテンツを上から下に読むよりもスキャンすることを好みます。 通常、この動作は F 字型のパターンに従います。 検索でうまくいくコンテンツを書くには、単に上から下に読まれるように書かれたものではなく、簡単にスキャンできることに重点を置く必要があります。
すぐに使えるChatGPT
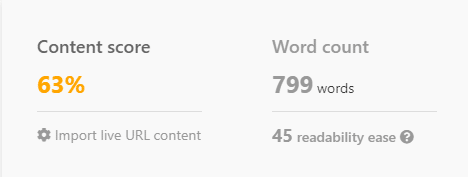
スコアリングに Noble と Inlinks を使用して、ChatGPT がすぐにどのように動作するかを観察してみましょう。
細心の注意を払って作成されたプロンプトであっても、Google の最初のページで何が機能しているかというコンテキストがなければ、ChatGPT は的を外して、競合する可能性が低いコンテンツを作成してしまうことがよくあります。
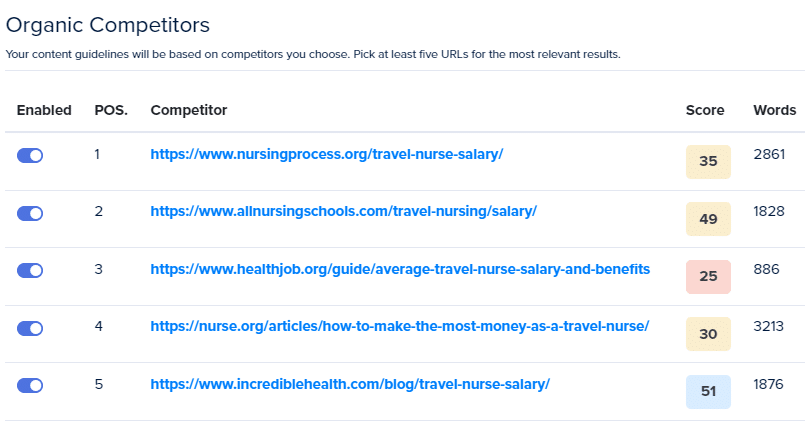
私は ChatGPT に「出張看護師の時給はいくらか」に関する記事を書くよう促しました。

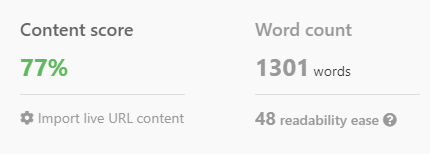
SEO分析と組み合わせる場合
ただし、ChatGPT は、SERP 分析やランキングに重要なキーワードと組み合わせることで真の力を発揮します。
ChatGPT にこれらの用語を含めるように依頼することで、AI はトピックに関連したコンテンツを生成するように誘導されます。

覚えておくべき重要なポイントがいくつかあります
ChatGPT にはトピックに関連する多くの主要なエンティティが組み込まれますが、SERP 結果を分析するツールを使用すると、コンテンツ内のエンティティの組み合わせを大幅に強化できます。
また、これらの違いは主題に応じてより顕著になる可能性がありますが、この実験を何度も実行すると、これが一貫した傾向であることがわかります。
キーワードに基づくアプローチは、次の 2 つの要件を同時に満たします。
- 最も重要なエンティティが確実に含まれるようにします。
- 述語と実体の両方が含まれるため、より厳密な評価システムを提供します。
追加の洞察
ChatGPT だけでは必要なコンテンツの長さを実現するのが難しい場合があります。
ページの意図がブログ形式の投稿から逸脱すればするほど、ChatGPT と ChatGPT を個別に使用する SEO ツールとの間のパフォーマンスのギャップが顕著になります。
AI の機能にもかかわらず、人間の要素を覚えておくことが不可欠です。 検索結果が混在しているため、すべてのページを分析する必要はありません。
さらに、キーワード抽出技術は確実ではなく、特殊なケースでは、無関係な固有名詞がスコアリング システムを通過する可能性があります。
したがって、人間の介入と AI の間の最適なバランスには、異なる意図を持つ競合サイトを手動で無効にし、キーワード リストを精査して明らかに間違ったキーワードを取り除くことが含まれます。
最後のステップ: さらに一歩進める
これまで説明してきた方法は出発点であり、競合他社よりも広範囲のエンティティとその述語をカバーするコンテンツを作成できるようになります。
このアプローチに従うことで、Google がすでに好むページの特徴を反映したコンテンツを作成することになります。
ただし、これは単なる出発点であることを忘れないでください。 これらの競合ページはおそらくしばらく前から存在しており、より多くのバックリンクとユーザー指標を獲得している可能性があります。
それらを上回るパフォーマンスを目標とする場合は、コンテンツをさらに目立たせる必要があります。
ウェブが AI によって生成されたコンテンツでますます飽和するにつれ、Google が新しいエンティティ関係を確立するために信頼できるウェブサイトを優先し始めるのではないかと推測するのは自然なことです。 これにより、コンテンツの評価方法が変わり、独創的な考えや革新性がより重視されることになるでしょう。
ライターとして、これは単に上位 10 件の結果に含まれる主題を組み込む以上のことを意味します。 代わりに、現在のトップ 10 にはない独自の視点を提供できるか、と自問してください。
ツールだけの問題ではありません。 それは私たち、戦略家、思想家、クリエイターに関するものです。
重要なのは、私たちがこれらのツールをどのように活用するか、そしてソフトウェアの計算能力と人間の心の創造的な輝きとのバランスをどのように取るかということです。
チェスの世界と同じように、真に違いを生むのは、機械の精度と人間の創意工夫の組み合わせです。
したがって、この新しい SEO の時代を受け入れ、視聴者の共感を呼び、広大なデジタル環境の中で目立つコンテンツを作成し、エクスペリエンスを作り上げましょう。
この記事で表明された意見はゲスト著者の意見であり、必ずしも Search Engine Land とは限りません。 スタッフの著者はここにリストされています。