
JavaScript SEO の一般的な問題を診断するためのガイド
公開: 2023-07-10正直に言うと、JavaScript と SEO は必ずしもうまく連携するとは限りません。 一部の SEO にとって、このトピックは複雑なベールに包まれているように感じることがあります。
良いニュースです。レイヤーを剥がしてみると、JavaScript ベースの SEO の問題の多くは、そもそも検索エンジン クローラーが JavaScript とどのように対話するかという基本に戻ってきます。
したがって、これらの基本を理解していれば、問題を掘り下げてその影響を理解し、開発者と協力して重要な問題を修正することができます。
この記事では、サイトが JS フレームワーク上に構築されている場合の一般的な問題の診断に役立ちます。 さらに、レンダリングに関してすべての技術的な SEO が必要とする基本的な知識を詳しく説明します。
レンダリングの概要
より詳細な内容に入る前に、全体像について話しましょう。
検索エンジンが JavaScript を利用したコンテンツを理解するには、ページをクロールしてレンダリングする必要があります。
問題は、検索エンジンが使用できるリソースが限られているため、いつそれらを使用する価値があるかを選択する必要があることです。 クローラーがページをレンダリング キューに送信したとしても、ページがレンダリングされるとは限りません。
ページをレンダリングしないことを選択した場合、またはコンテンツを適切にレンダリングできない場合は、問題が発生している可能性があります。
それは、フロントエンドが最初のサーバー応答で HTML をどのように提供するかによって決まります。
URL がブラウザーで構築されると、React、Vue、Gatsby などのフロントエンドがページの HTML を生成します。 クローラーは、結果のコンテンツを確認できるようにレンダリングを待機する URL を送信する前に、その HTML がサーバーからすでに利用可能であるかどうか (「事前レンダリングされた」HTML) を確認します。
事前にレンダリングされた HTML が利用できるかどうかは、フロントエンドの構成によって異なります。 サーバー経由またはクライアント ブラウザーで HTML が生成されます。
サーバーサイドレンダリング
名前がすべてを物語っています。 SSR セットアップでは、追加の JS の実行やレンダリングを必要とせずに、完全にレンダリングされた HTML ページがクローラーに供給されます。
そのため、ページがレンダリングされない場合でも、検索エンジンは HTML をクロールし、ページのコンテキスト (メタデータ、コピー、画像) を認識し、他のページ (ブレッドクラム、正規 URL、内部リンク) との関係を理解できます。
クライアント側のレンダリング
CSR では、HTML はすべての JavaScript コンポーネントとともにブラウザーで生成されます。 HTML をクロールできるようになる前に、JavaScript をレンダリングする必要があります。
レンダリング サービスがキューに送信されたページをレンダリングしないことを選択した場合、コピー、内部 URL、画像リンク、さらにはメタデータさえもクローラーが利用できないままになります。
その結果、検索エンジンには、検索クエリに対する URL の関連性を理解するためのコンテキストがほとんど、またはまったくありません。
注:最初の HTML 応答で提供される HTML と、レンダリング (表示) するために JS の実行が必要な HTML が混在する場合があります。 これはいくつかの要因によって決まりますが、最も一般的な要因には、フレームワーク、個々のサイト コンポーネントの構築方法、サーバー構成が含まれます。
JavaScript SEO ツールキット
JavaScript 関連の SEO 問題の特定に役立つツールは確かに存在します。
ブラウザ ツールと Google Search Console を使用して、多くの調査を行うことができます。 堅実なツールキットを構成する候補リストは次のとおりです。
- ソースの表示:ページを右クリックし、「ソースの表示」をクリックすると、ページの事前レンダリングされた HTML (サーバーの初期応答) が表示されます。
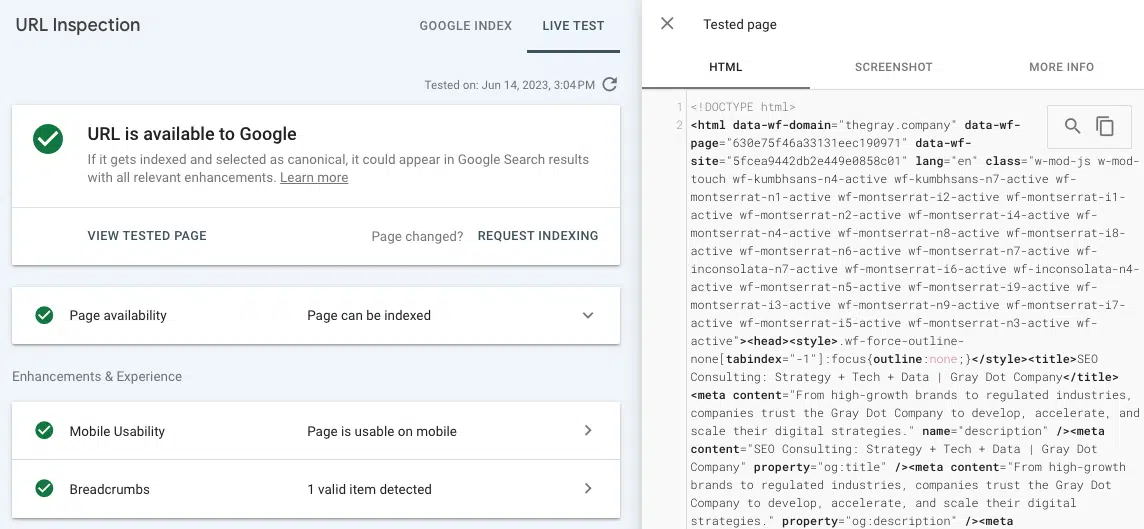
- ライブ URL のテスト (URL 検査): Google Search Console の URL 検査タブで、レンダリングされたページのスクリーンショット、HTML、その他の重要な詳細を表示します。 (多くのレンダリングの問題は、「ソースを表示」からの事前レンダリングされた HTML と、GSC でのライブ URL のテストからのレンダリングされた HTML を比較することで見つかります。)
- Chrome 開発者ツール:ページを右クリックして [検査] を選択すると、JavaScript エラーなどを表示するツールが開きます。
- Wappalyzer:この無料の Chrome 拡張機能をインストールすることで、サイトが構築されているスタックを確認し、フレームワーク固有の洞察を求めます。
JavaScript SEO に関する一般的な問題
問題 1: 事前レンダリングされた HTML は世界的に利用できない
前述したクロールとコンテキスト化に対する悪影響に加えて、検索エンジンがページをレンダリングするのにかかる時間とリソースの問題もあります。
クローラーがレンダリング プロセスに URL を入れることを選択した場合、その URL はレンダリング キューに入ります。 これは、クローラーが事前にレンダリングされた HTML 構造とレンダリングされた HTML 構造の不一致を感知する可能性があるために発生します。 (事前にレンダリングされた HTML がない場合、これは非常に意味があります。)
URL が Web レンダリング サービスを待機する時間は保証されません。 WRS をタイムリーなレンダリングに誘導する最善の方法は、URL の重要性を示す重要な権限シグナルがオンサイトに存在することを確認することです (例: トップ ナビゲーションでのリンク、正規として参照される多くの内部リンク)。 権限シグナルもクロールする必要があるため、これは少し複雑になります。
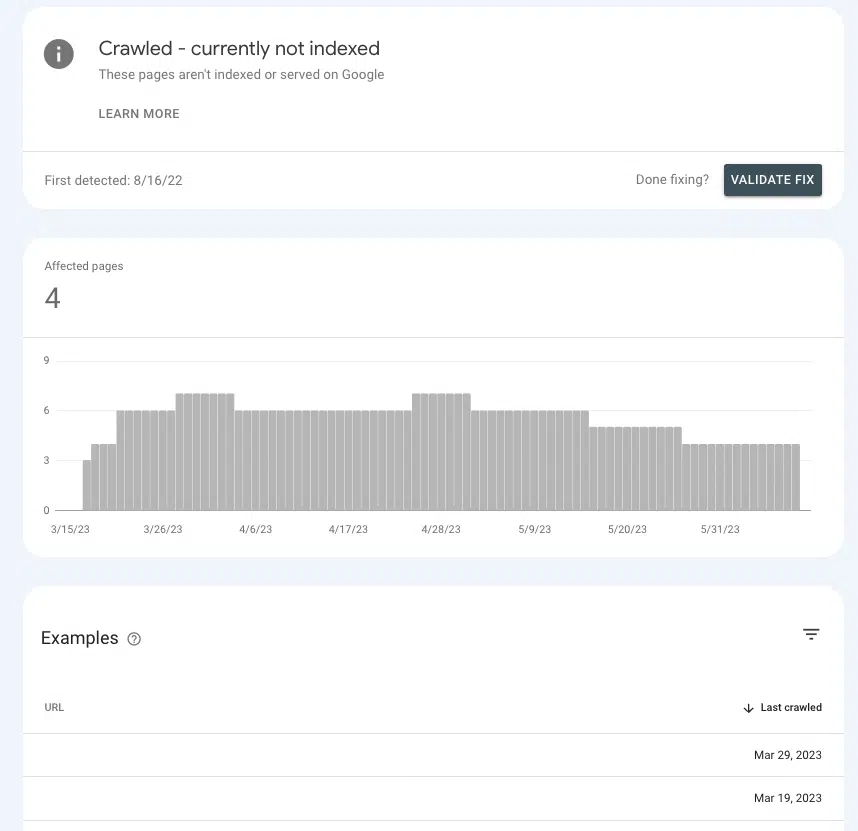
Google Search Console では、重要なページに適切な権限シグナルを送信しているのか、それともページを放置状態にしているのかを把握することができます。
[ページ] > [ページ インデックス] > [クロール済み - 現在インデックスされていません]に移動し、リスト内で優先ページの存在を探します。
それらが待合室にいる場合、それは、リソースを費やすほど重要なものであるかどうかを Google が確認できないためです。
よくある原因
デフォルトの設定
一般的なフロントエンドのほとんどは、「すぐに使える」クライアント側レンダリングに設定されているため、デフォルト設定が原因である可能性がかなり高くなります。
なぜほとんどのフロントエンドがデフォルトで CSR を選択するのか疑問に思っているなら、それはパフォーマンス上の利点のためです。 SSR はサイトの高速化や特定のインタラクティブな要素 (ページ間の固有の遷移など) の実装の可能性を制限する可能性があるため、開発者は必ずしも SSR を好むわけではありません。
シングルページのアプリケーション
サイトがシングルページ アプリケーションの場合、サイトは完全に JavaScript でラップされ、ブラウザーでページのすべてのコンポーネント (別名すべて) がクライアント側でレンダリングされ、新しいページはリロードせずに表示されます。
これにはいくつかのマイナスの影響がありますが、おそらく最も重要なのは、ページが検出できない可能性があることです。
これは、SEO に配慮した方法で SPA を設定することが不可能だと言っているわけではありません。 しかし、それを実現するにはかなりの開発作業が必要になる可能性があります。
問題 2: 一部のページ コンテンツがクローラーからアクセスできない
検索エンジンに URL をレンダリングさせることは、すべての要素がクロールできる場合に限り、優れた効果を発揮します。 ページをレンダリングしているが、アクセスできないページのセクションがある場合はどうなるでしょうか?
たとえば、SEO が内部リンク分析を行うと、複数のページにリンクされている URL に対して内部リンクがほとんど報告されていないことがわかります。
ライブ URL テスト ツールからレンダリングされた HTML にリンクが表示されない場合は、Google がアクセスできない JavaScript リソースでリンクが提供されている可能性があります。
原因を絞り込むには、欠落しているページ コンテンツまたは内部リンクが URL 全体のページのどこにあるかという点で共通点を探すとよいでしょう。
たとえば、すべての製品ページの同じセクションに表示される FAQ リンクであれば、開発者が修正を絞り込むのに大いに役立ちます。
よくある原因
JavaScript エラー
ここで免責事項から始めましょう。 遭遇する JavaScript エラーのほとんどは SEO にとっては重要ではありません。
したがって、エラーを探しに行き、開発者に長いリストを持って行き、「これらのエラーは何ですか?」という会話から始めても、開発者はそれをあまり良く受け取らないかもしれません。
問題について話し、「なぜ」を考えてアプローチすることで、彼らは JavaScript の専門家になれるようになります (なぜなら、彼らは専門家だからです!)。
そうは言っても、ページの残りの部分を解析不能にする可能性のある構文エラーが存在します (例: 「レンダリング ブロッキング」)。 これが発生すると、レンダラーは個々の HTML 要素を分解したり、DOM 内のコンテンツを構造化したり、関係を理解したりすることができなくなります。
一般に、この種のエラーはブラウザのビューにも何らかの影響を与えるため、認識可能です。
視覚的な確認に加えて、ページを右クリックして「検査」を選択し、「コンソール」タブに移動することで JavaScript エラーを確認することもできます。
マーケティング担当者が頼りにする毎日のニュースレター検索を入手します。
規約を参照してください。

コンテンツにはユーザーの操作が必要です
レンダリングに関して覚えておくべき最も重要なことの 1 つは、ユーザーがページを操作する必要があるコンテンツは Google ではレンダリングできないということです。 もっと簡単に言えば、何かを「クリック」することはできません。
なぜそれが重要なのでしょうか? 私たちの古くからの信頼できる友人であるアコーディオン ドロップダウンについて、また製品の詳細や FAQ などのコンテンツを整理するためにどれだけ多くのサイトがそれを使用しているかを考えてみてください。
アコーディオンのコーディング方法によっては、JS が実行されるまでドロップダウンにコンテンツが入力されない場合、Google はドロップダウン内のコンテンツをレンダリングできない場合があります。
確認するには、ページを「検査」し、「非表示」コンテンツ (アコーディオンをクリックすると表示される内容) が HTML 内にあるかどうかを確認します。
そうでない場合は、Googlebot や他のクローラーがページのレンダリングされたバージョンでこのコンテンツを認識しないことを意味します。
問題 3: サイトのセクションがクロールされない
Google がページをクロールしてキューに送信する場合、ページをレンダリングする場合とレンダリングしない場合があります。 ページをクロールしなければ、その機会すらありません。
Google がページをクロールしているかどうかを理解するには、 [設定] > [クロール統計] の [クロール統計] レポートが便利です。
過去 3 か月間の 200 ステータス ページのすべてのクロール インスタンスを表示するには、[クロール リクエスト: OK (200)] を選択します。 次に、フィルタリングを使用して、個々の URL またはディレクトリ全体を検索します。
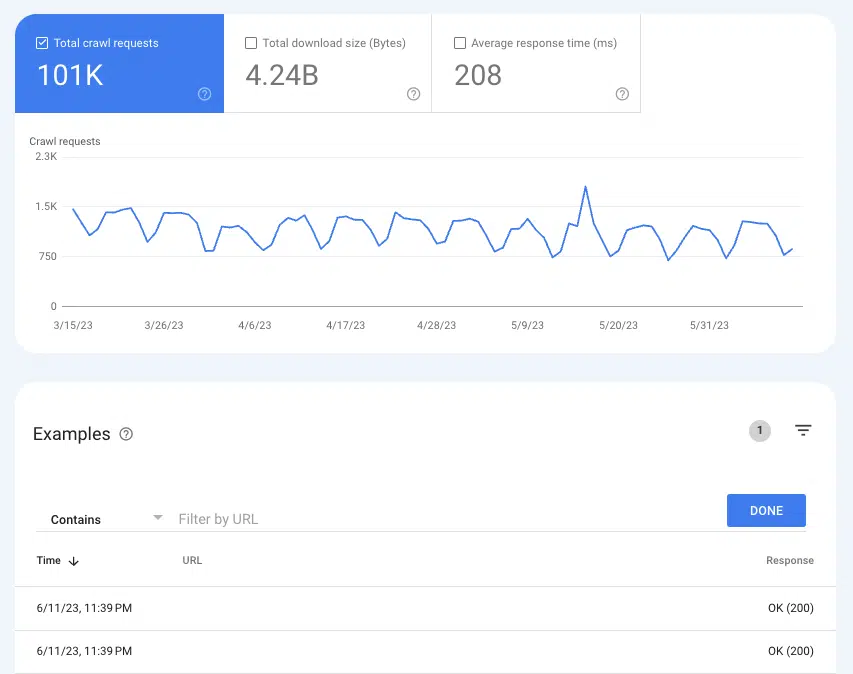
URL がクロール ログに表示されない場合は、Google がページを検出してクロールできない可能性が高くなります (または、ページが 200 ではない場合は、まったく別の問題になります)。
よくある原因
内部リンクはクロールできません
リンクは、クローラーが新しいページにたどる道路標識です。 これが、孤立ページが大きな問題となる理由の 1 つです。
適切にリンクされたサイトがあり、サイト監査で孤立したページが表示される場合は、事前にレンダリングされた HTML でリンクが使用できないことが原因である可能性が高くなります。
簡単に確認する方法は、報告された孤立ページにリンクしている URL にアクセスすることです。 ページ上で右クリックし、「ソースを表示」をクリックします。
次に、CMD + f を使用して、孤立したページの URL を検索します。 事前にレンダリングされた HTML には表示されないが、ブラウザーでレンダリングするとページには表示される場合は、問題 4 に進んでください。
XML サイトマップが更新されない
XML サイトマップは、Google が新しいページを検出し、クロールでどの URL を優先するかを理解するのに役立ちます。
XML サイトマップがなければ、リンクをたどることによってのみページを発見できます。
したがって、事前レンダリングされた HTML を持たないサイトの場合、サイトマップが古くなったり欠落したりすると、Google がページをレンダリングし、他のページへの内部リンクをたどって、キューに入れ、レンダリングし、リンクをたどるなどの処理を待つことになります。
使用しているフロントエンドによっては、動的な XML サイトマップを作成できるプラグインにアクセスできる場合があります。
多くの場合、カスタマイズが必要となるため、SEO 担当者は、サイトマップに含めるべきではない URL と、その理由に関するロジックを熱心に文書化することが重要です。
これは、お気に入りの SEO ツールでサイトマップを実行することで比較的簡単に確認できます。
問題 4: 内部リンクが見つからない
クローラーへの内部リンクが利用できないことは、潜在的な発見の問題であるだけでなく、公平性の問題でもあります。 リンクは参照 URL からターゲット URL に SEO の価値を伝達するため、ページとドメインの権威の両方を高める上で重要な要素となります。
ホームページからのリンクは良い例です。 通常、Web サイト上で最も権限のあるページであるため、ホームページから別のページへのリンクは大きな重要性を持ちます。
これらのリンクがクロールできない場合、それは壊れたライトセーバーを持つようなものです。 最も強力なツールの 1 つが役に立たなくなります (冗談です)。
よくある原因
リンクにアクセスするにはユーザーの操作が必要です
前に使用したアコーディオンの例は、コンテンツがユーザー インタラクションの背後に隠れている 1 つの例にすぎません。 広範な影響を与える可能性があるもう 1 つの問題は、特に製品のカタログが充実している e コマース サイトの場合、無限スクロール ページネーションです。
無限スクロール設定では、ユーザーが特定のポイントを超えてスクロールするか (遅延読み込み)、または「もっと見る」ボタンをタップしない限り、製品リスト (カテゴリ) ページ上の無数の製品が読み込まれません。
そのため、たとえ JavaScript がレンダリングされても、クローラはまだ読み込まれていない製品の内部リンクにアクセスできません。 ただし、これらの製品をすべて 1 つのページに読み込むと、ページのパフォーマンスが低下するため、ユーザー エクスペリエンスに悪影響を及ぼします。
これが、SEO が通常、結果のすべてのページに個別のクロール可能な URL を持たせる真のページネーションを好む理由です。
サイトで遅延読み込みを最適化し、すべての製品を事前レンダリングされた HTML に追加する方法はありますが、これにより、レンダリングされた HTML と事前レンダリングされた HTML の間に差異が生じます。
事実上、これにより、より多くのページがレンダリング キューに送信され、クローラーが必要以上に激しく動作する原因が生まれます。そして、それが SEO にとって良くないことはわかっています。
少なくとも、無限スクロールの最適化に関する Google の推奨事項に従ってください。
リンクが正しくコーディングされていない
Google がサイトをクロールするとき、またはキュー内の URL をレンダリングするとき、ページのステートレス バージョンがダウンロードされます。 これが、適切な href タグとアンカー (最も頻繁に見られるリンク構造) を使用することが非常に重要である理由の大きな部分を占めています。 クローラーは、ルーター、スパン、または onClick などのリンク形式を追跡できません。
以下をフォローできます:
- <a href="https://example.com">
- <a href="/relative/path/file">
フォローできません:
- <a routerLink="some/path">
- <span href="https://example.com">
- <a>
開発者の目的では、これらはすべてリンクをコーディングする有効な方法です。 SEO への影響は追加のコンテキスト層であり、それを知るのは SEO の仕事ではありません。
優れた SEO の仕事の大きな部分は、ドキュメントを通じて開発者にそのコンテキストを提供することです。
問題 5: メタデータが欠落している
HTML ページでは、タイトル、説明、正規 URL、メタ ロボット タグなどのメタデータはすべて head 内にネストされます。
明らかな理由から、メタデータの欠落は SEO にとって有害ですが、SPA にとってはさらに有害です。 自己参照正規 URL のような要素は、JS ページがレンダリング キューを正常に通過できる可能性を高めるために重要です。
事前にレンダリングされた HTML に存在する必要があるすべての要素のうち、head がインデックス作成にとって最も重要です。
幸いなことに、この問題は、サイトが衛生レポートに使用する SEO ツールに関わらず、メタデータの欠落により大量のエラーを引き起こすため、非常に簡単に発見できます。 次に、ソース コード内の先頭を検索して確認できます。
よくある原因
メタデータ ビークルの欠如または誤った構成
JS フレームワークでは、プラグインがヘッドを作成し、メタデータをヘッドに挿入します。 (最も一般的な例は React Helmet です。) プラグインがすでにインストールされている場合でも、通常は正しく構成する必要があります。
繰り返しになりますが、これは SEO 担当者ができるすべての分野であり、開発者に問題を提起し、その理由を説明し、十分に文書化された受け入れ基準に向けて緊密に取り組むことです。
問題 6: リソースがクロールされない
スクリプト ファイルとイメージは、レンダリング プロセスにおける重要な構成要素です。
これらにも独自の URL があるため、クロール可能性の法則も適用されます。 ファイルのクロールがブロックされている場合、Google はページを解析して表示することができません。
URL がクロールされているかどうかを確認するには、GSC クロール統計で過去のリクエストを表示します。
- 画像: [設定] > [クロール統計] > [クロール リクエスト] に移動します: 画像
- JavaScript: [設定] > [クロール統計] > [クロール リクエスト] に移動します: 画像
よくある原因
robots.txt によってブロックされたディレクトリ
通常、スクリプト URL と画像 URL は両方とも専用のサブドメインまたはサブフォルダーにネストされるため、robots.txt 内の disallow 式によりクロールが防止されます。
一部の SEO ツールは、スクリプト ファイルや画像ファイルがブロックされているかどうかを通知しますが、画像ファイルやスクリプト ファイルがどこにネストされているかがわかれば、問題を見つけるのは非常に簡単です。 これらの URL 構造は robots.txt で検索できます。
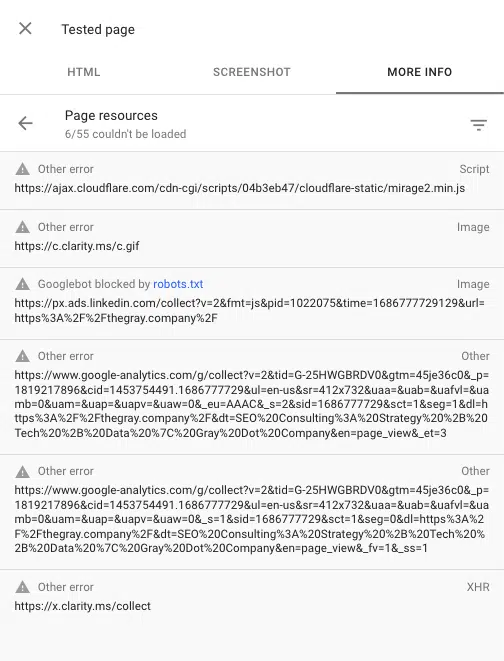
Google Search Console の URL 検査ツールを使用すると、ページのレンダリング時にブロックされたスクリプトを確認することもできます。 「ライブ URL をテスト」し、[テスト済みページの表示] > [詳細情報] > [ページ リソース]に移動します。
ここでは、レンダリング プロセス中にロードに失敗したスクリプトを確認できます。 ファイルが robots.txt によってブロックされている場合、そのようにマークされます。
JavaScript と友達になる
はい、JavaScript には SEO の問題が伴う可能性があります。 しかし、SEO が進化するにつれて、ベスト プラクティスは優れたユーザー エクスペリエンスと同義になりつつあります。
優れたユーザー エクスペリエンスは JavaScript に依存することがよくあります。 したがって、SEO の仕事は JavaScript をコード化することではありませんが、検索エンジンがそれをどのように操作し、表示し、使用するかを知る必要があります。
レンダリング プロセスと JS フレームワークにおけるいくつかの一般的な SEO 問題をしっかりと理解すれば、問題を特定し、開発者の強力な味方になることができるようになります。
この記事で表明された意見はゲスト著者の意見であり、必ずしも Search Engine Land とは限りません。 スタッフの著者はここにリストされています。