
エンティティ SEO: 決定版ガイド
公開: 2023-04-06この記事はAndrew Ansleyと共著しています。
文字列ではなく、モノ。 これまでに聞いたことがない場合は、ナレッジ グラフを発表した有名な Google ブログの投稿から来ています。
発表から 11 周年を迎えるまであと 1 か月しかありませんが、多くの人は、SEO にとって「文字列ではなくモノ」が実際に何を意味するのかを理解するのにまだ苦労しています。
この引用は、Google が物事を理解しており、もはや単純なキーワード検出アルゴリズムではないことを伝えようとしています。
2012 年 5 月に、エンティティ SEO が誕生したと言えます。 Google の機械学習は、半構造化および構造化されたナレッジ ベースの助けを借りて、キーワードの背後にある意味を理解することができました。
言語のあいまいな性質は、最終的に長期的な解決策を持っていました.
エンティティが 10 年以上にわたって Google にとって重要であるとすれば、なぜ SEO はエンティティについていまだに混乱しているのでしょうか?
良い質問。 4 つの理由があります。
- 用語としてのエンティティ SEO は、SEO がその定義に慣れ、語彙に組み込むほど広く使用されていません。
- エンティティの最適化は、古いキーワード中心の最適化方法と大きく重複しています。 その結果、エンティティはキーワードと混同されます。 これに加えて、エンティティが SEO でどのような役割を果たしたかは明確ではなく、Google がこのテーマについて話すとき、「エンティティ」という言葉は「トピック」と置き換えられることがあります。
- エンティティを理解するのは退屈な作業です。 エンティティに関する深い知識が必要な場合は、Google の特許を読み、機械学習の基礎を理解する必要があります。 エンティティ SEO は、SEO に対するはるかに科学的なアプローチです。科学は万人向けではありません。
- YouTube は知識の配布に大きな影響を与えましたが、多くの教科の学習体験を平坦化しました。 プラットフォームで最も成功したクリエイターは、歴史的に視聴者を教育する際に簡単な方法をとってきました。 その結果、コンテンツ作成者は最近までエンティティに多くの時間を費やしていませんでした。 このため、NLP の研究者からエンティティについて学び、その知識を SEO に適用する必要があります。 特許と研究論文が重要です。 繰り返しますが、これは上記の最初の点を補強します。
この記事は、SEO が SEO に対するエンティティ ベースのアプローチを完全に習得することを妨げてきた 4 つの問題すべてに対する解決策です。
これを読むと、次のことがわかります。
- エンティティとは何か、なぜ重要なのか。
- セマンティック検索の歴史。
- SERP でエンティティを識別して使用する方法。
- エンティティを使用して Web コンテンツをランク付けする方法。
エンティティが重要な理由
エンティティ SEO は、ランク付けするコンテンツの選択とその意味の決定に関して、検索エンジンが向かう未来です。
これを知識ベースの信頼と組み合わせると、エンティティ SEO は今後 2 年間で SEO がどのように行われるかの未来になると私は信じています。
エンティティの例
では、エンティティをどのように認識しますか?
SERP には、おそらく見たことのあるエンティティの例がいくつかあります。
最も一般的な種類のエンティティは、場所、人、または企業に関連しています。
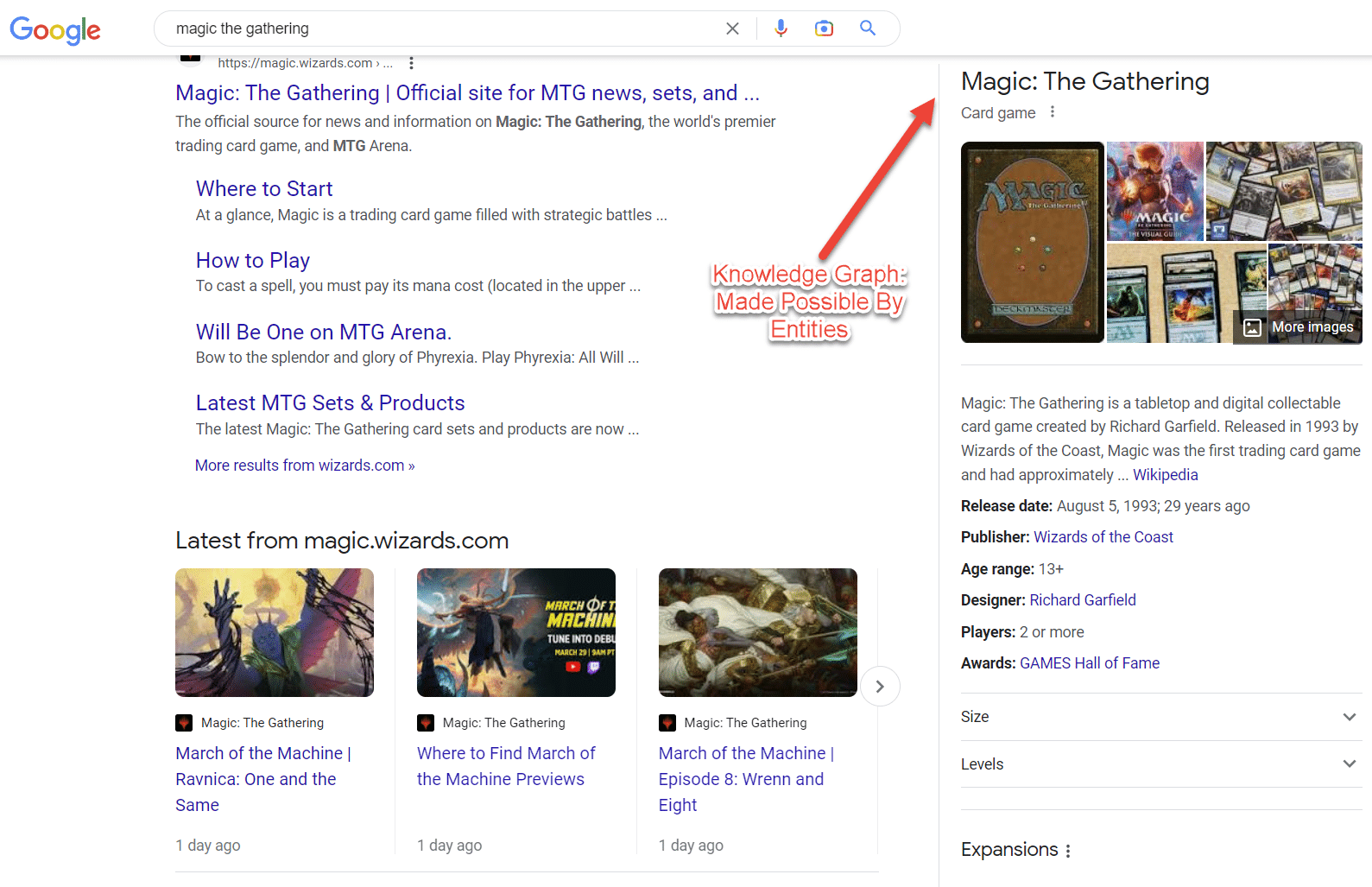
おそらく、SERP のエンティティの最も良い例はインテント クラスターです。 トピックが理解されればされるほど、これらの検索機能が出現します。
興味深いことに、エンティティに焦点を当てた SEO キャンペーンの実行方法を知っていれば、1 つの SEO キャンペーンで SERP の外観を変えることができます。
ウィキペディアのエントリはエンティティの別の例です。 ウィキペディアは、エンティティに関連付けられた情報の好例を提供します。
左上からわかるように、このエンティティには、解剖学的構造から人間にとっての重要性まで、「魚」に関連するあらゆる種類の属性があります。
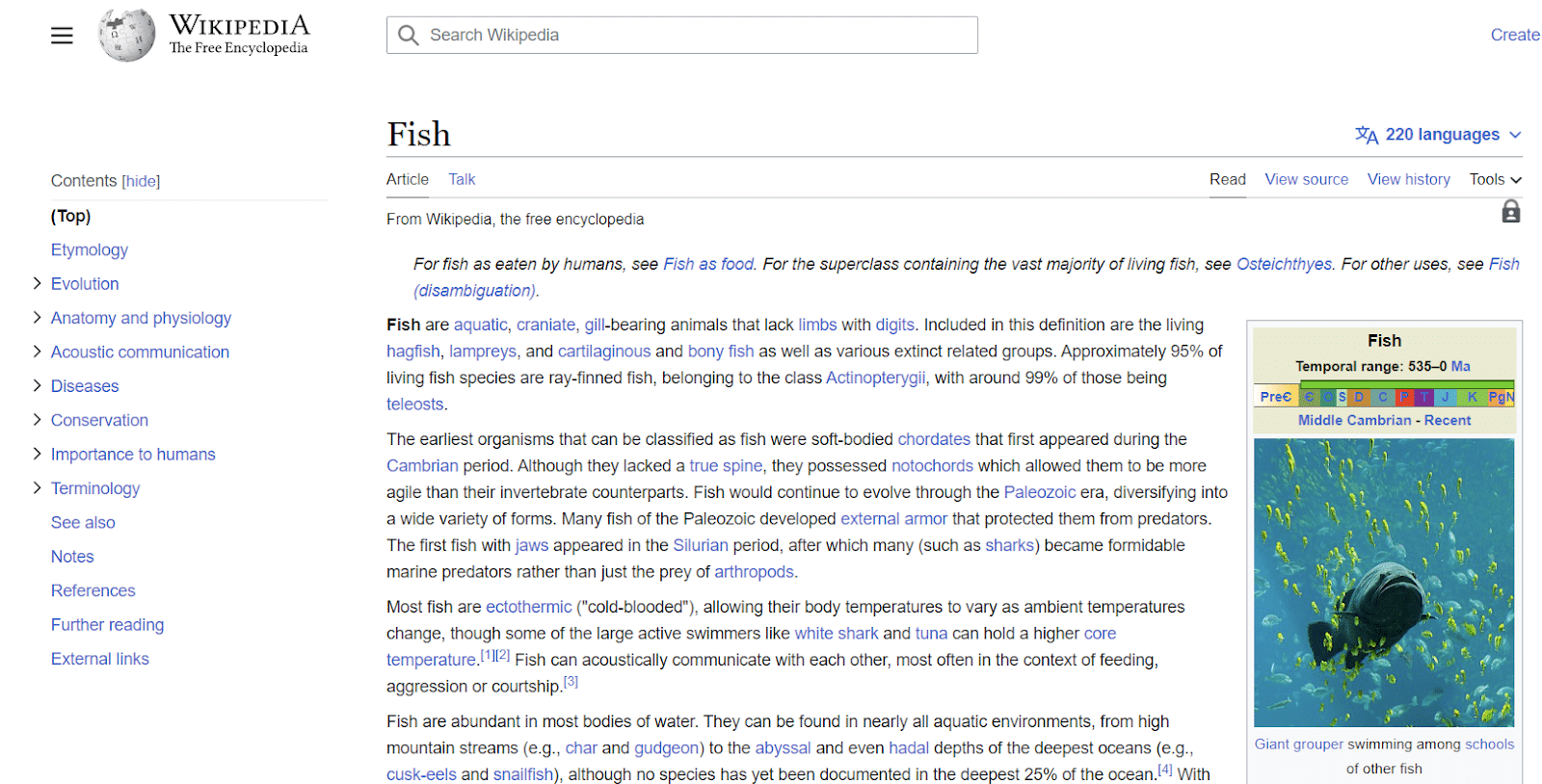
ウィキペディアにはトピックに関する多くのデータ ポイントが含まれていますが、すべてを網羅しているわけではありません。
エンティティとは
エンティティは、名前、タイプ、属性、および他のエンティティとの関係によって特徴付けられる、一意に識別可能なオブジェクトまたは物です。 エンティティは、エンティティ カタログに存在する場合にのみ存在すると見なされます。
エンティティ カタログは、各エンティティに一意の ID を割り当てます。 私の代理店には、各エンティティ (サービス、製品、およびブランドがすべて含まれる) に関連付けられた一意の ID を使用するプログラマティック ソリューションがあります。
単語または語句が既存のカタログに含まれていない場合でも、その単語または語句がエンティティではないという意味ではありませんが、通常、カタログ内に存在することで何かがエンティティであるかどうかを知ることができます。
ウィキペディアは何かが実体であるかどうかの決定要因ではありませんが、会社は実体のデータベースで最もよく知られていることに注意することが重要です.
エンティティについて話すときは、任意のカタログを使用できます。 通常、エンティティは人、場所、または物ですが、アイデアや概念も含めることができます。
エンティティ カタログの例には次のようなものがあります。
- ウィキペディア
- ウィキデータ
- DBペディア
- フリーベース
- やご

エンティティは、非構造化データと構造化データの世界の間のギャップを埋めるのに役立ちます。
それらを使用して、構造化されていないテキストを意味的に強化することができますが、テキスト ソースを使用して、構造化された知識ベースを作成することができます。
テキスト内のエンティティの言及を認識し、これらの言及をナレッジ ベース内の対応するエントリに関連付けることは、エンティティ リンクのタスクとして知られています。
エンティティは、人間と機械の両方にとって、テキストの意味をよりよく理解することを可能にします。
人間は、言及されているコンテキストに基づいてエンティティのあいまいさを比較的簡単に解決できますが、これは機械にとって多くの困難と課題をもたらします。
エンティティのナレッジ ベース エントリは、そのエンティティについてわかっていることをまとめたものです。
世界が常に変化しているように、新しい事実も表面化しています。 これらの変化に遅れずについていくには、編集者とコンテンツ マネージャーによる継続的な努力が必要です。 これは大規模な要求の厳しいタスクです。
エンティティが言及されている文書の内容を分析することにより、新しい事実または更新が必要な事実を見つけるプロセスがサポートされるか、完全に自動化されることさえあります。
科学者はこれを知識ベース人口の問題と呼んでおり、エンティティのリンクが重要なのはそのためです。
エンティティは、キーワード クエリとドキュメントのコンテンツによって表現されるユーザーの情報ニーズのセマンティックな理解を容易にします。 したがって、エンティティを使用して、クエリおよび/またはドキュメントの表現を改善することができます。
Extended Named Entity の研究論文で、著者は約 160 のエンティティ タイプを特定しています。 リストの 7 つのスクリーンショットのうちの 2 つを次に示します。


エンティティの特定のカテゴリはより簡単に定義できますが、概念とアイデアはエンティティであることを覚えておくことが重要です。 これら 2 つのカテゴリは、Google が単独で拡張することは非常に困難です。
あいまいな概念を扱っている場合、1 ページだけで Google に教えることはできません。 エンティティーを理解するには、多くの記事と多くの参考文献が長期間維持される必要があります。
エンティティに関する Google の歴史
2010 年 7 月 16 日、Google は Freebase を買収しました。 この購入は、現在のエンティティ検索システムにつながる最初の大きなステップでした。

Freebase に投資した後、Google はウィキデータの方が優れたソリューションがあることに気付きました。 その後、Google は Freebase を Wikidata に統合する作業を行いましたが、これは予想よりもはるかに困難な作業でした。
5 人の Google の科学者が「Freebase から Wikidata へ: 大規模な移行」というタイトルの論文を書きました。 主なポイントは次のとおりです。
「Freebase は、オブジェクト、事実、型、およびプロパティの概念に基づいて構築されています。 各 Freebase オブジェクトには、「mid」(マシン ID) と呼ばれる安定した識別子があります。
「ウィキデータのデータ モデルは、アイテムとステートメントの概念に依存しています。 アイテムはエンティティを表し、「qid」と呼ばれる安定した識別子を持ち、複数の言語でラベル、説明、およびエイリアスを持つことができます。 他のウィキメディア プロジェクト (最も顕著なのはウィキペディア) の実体に関する詳細な記述とページへのリンク。 Freebase とは対照的に、ウィキデータのステートメントは真の事実をコード化することを目的としておらず、異なる情報源からの主張であるため、相互に矛盾することもあります…」
エンティティはこれらのナレッジ ベースで定義されますが、Google はまだ構造化されていないデータ (ブログなど) のエンティティの知識を構築する必要がありました。
Google は Bing および Yahoo と提携し、このタスクを達成するために Schema.org を作成しました。
Google は、ウェブサイト管理者が Google がコンテンツを理解するのに役立つツールを使用できるように、スキーマの指示を提供します。 覚えておいてください、Google は文字列ではなく、物に焦点を合わせたいと考えています。
グーグルの言葉で:
「ページに構造化データを含めることで、ページの意味について明確な手がかりを Google に提供することで、私たちを助けることができます。 構造化データは、ページに関する情報を提供し、ページのコンテンツを分類するための標準化された形式です。 たとえば、レシピ ページでは、材料、調理時間と温度、カロリーなどを確認できます。」
Google は次のように続けます。
「拡張ディスプレイを使用して Google 検索に表示されるようにするには、オブジェクトに必要なすべてのプロパティを含める必要があります。 一般に、より多くの推奨機能を定義すると、表示が強化された検索結果に情報が表示される可能性が高くなります。 ただし、可能なすべての推奨プロパティに不完全なデータ、不適切な形式のデータ、または不正確なデータを提供しようとするよりも、少数ではあるが完全で正確な推奨プロパティを提供することがより重要です。」
スキーマについてはさらに多くのことが言えますが、ページ コンテンツを検索エンジンに対して明確にしようとする SEO にとって、スキーマは素晴らしいツールであると言えます。
パズルの最後のピースは、「今後 20 年間の検索の改善」というタイトルの Google のブログ発表から得られます。
ドキュメントの関連性と品質は、この発表の背後にある主なアイデアです。 Google がページのコンテンツを決定するために使用した最初の方法は、完全にキーワードに焦点を合わせたものでした。
次に、Google はトピック レイヤーを検索に追加しました。 このレイヤーは、ナレッジ グラフと、Web 全体のデータを体系的にスクレイピングして構造化することによって可能になりました。
それが現在の検索システムにつながります。 Google は、5 億 7000 万のエンティティと 180 億のファクトから、10 年足らずで 8000 億のファクトと 80 億のエンティティになりました。 この数が増えると、エンティティ検索が改善されます。
エンティティ モデルは以前の検索モデルからどのように改善されていますか?
従来のキーワードベースの情報検索 (IR) モデルには、クエリと明示的に一致する用語がない (関連する) ドキュメントを検索できないという固有の制限があります。
ctrl + fを使用してページ上のテキストを検索する場合、従来のキーワード ベースの情報検索モデルに似たものを使用します。
毎日、膨大な量のデータが Web 上に公開されています。
Google が、すべての単語、すべての段落、すべての記事、およびすべての Web サイトの意味を理解することは不可能です。
代わりに、エンティティは、理解を深めながら Google が計算負荷を最小限に抑えることができる構造を提供します。
「概念ベースの検索方法は、補助構造に依存して、より高いレベルの概念空間でクエリとドキュメントの意味表現を取得することにより、この課題に対処しようとします。 このような構造には、制御された語彙 (辞書とシソーラス)、オントロジー、および知識リポジトリからのエンティティが含まれます。」
–エンティティ指向検索、第 8.3 章
エンティティに関する決定的な本を書いた Krisztian Balog は、従来の情報検索モデルに対する 3 つの可能な解決策を特定しています。
- 拡張ベース: エンティティをソースとして使用して、さまざまな用語でクエリを拡張します。
- Projection-based : クエリとドキュメントの間の関連性は、それらをエンティティの潜在空間に投影することによって理解されます
- エンティティ ベース: 用語ベースの表現を補強するために、クエリとドキュメントの明示的な意味表現がエンティティ空間で取得されます。
これら 3 つのアプローチの目標は、クエリに強く関連するエンティティを識別することによって、必要なユーザーの情報をより豊富に表現することです。
次に Balog は、エンティティ マッピングの投影ベースの方法に関連する 6 つのアルゴリズムを特定します (投影方法は、エンティティを 3 次元空間に変換し、ジオメトリを使用してベクトルを測定することに関連しています)。
- 明示的意味分析 (ESA) : 特定の単語の意味論は、ウィキペディアから派生した概念に対する単語の関連付けの強さを格納するベクトルによって記述されます。
- 潜在エンティティ空間モデル (LES) : 生成確率フレームワークに基づく。 ドキュメントの検索スコアは、潜在エンティティ空間スコアと元のクエリ可能性スコアの線形結合と見なされます。
- EsdRank: EsdRank は、クエリ エンティティとエンティティ ドキュメントの機能の組み合わせを使用して、ドキュメントをランク付けするためのものです。 これらはそれぞれ、以前からの LES のクエリ プロジェクション コンポーネントとドキュメント プロジェクション コンポーネントの概念に対応しています。 識別学習フレームワークを使用すると、エンティティの人気度やドキュメントの品質など、追加のシグナルも簡単に組み込むことができます
- 明示的セマンティック ランキング (ESR):明示的セマンティック ランキング モデルは、ナレッジ グラフからの関係情報を組み込み、エンティティ空間での "ソフト マッチング" を有効にします。
- 単語エンティティ デュエット フレームワーク:これは、用語ベースの表現とエンティティ ベースの表現の間のクロススペース相互作用を組み込み、4 つのタイプの一致につながります: クエリ用語からドキュメント用語、クエリ エンティティからドキュメント用語、クエリ用語からドキュメント エンティティ、およびクエリ エンティティエンティティを文書化します。
- 注目度ランキングモデル: これは、説明するのが最も複雑なものです。
バログは次のように書いています。
「クエリ エンティティごとに抽出される、合計 4 つの注意機能が設計されています。 エンティティのあいまい性機能は、エンティティの注釈に関連するリスクを特徴付けるためのものです。 これらは次のとおりです: (1) 表面形式が異なる実体にリンクされている確率のエントロピー (例えば、ウィキペディア)、(2) 注釈付き実体が表面形式の最も一般的な意味であるかどうか (すなわち、最高の共通性を持っているかどうか)スコア、および (3) 与えられた表面形式の最も可能性の高い候補と 2 番目に可能性の高い候補の間の共通性スコアの差. 4 番目の特徴は近接性であり、埋め込み空間でのクエリ エンティティとクエリの間のコサイン類似度として定義されます。具体的には、コーパスでスキップグラム モデルを使用して、エンティティ用語の結合をトレーニングします。エンティティの言及は、対応するエンティティ識別子に置き換えられます。クエリの埋め込みは、クエリ用語の埋め込みの重心と見なされます。」

今のところ、これら 6 つのエンティティ中心のアルゴリズムに表面レベルで精通していることが重要です。
主な要点は、2 つのアプローチが存在することです。ドキュメントを潜在エンティティ レイヤーに投影する方法と、ドキュメントの明示的なエンティティ アノテーションです。
3種類のデータ構造
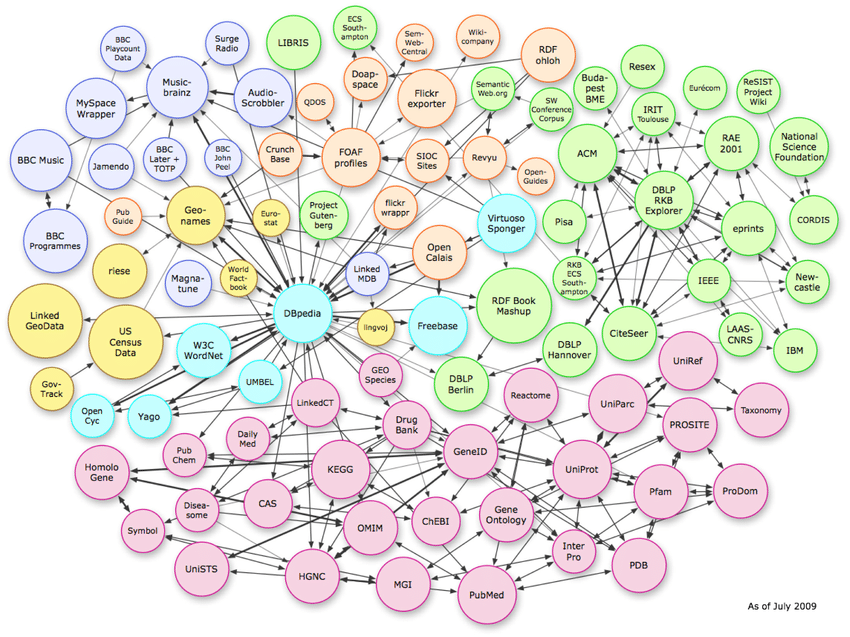
上の画像は、ベクトル空間に存在する複雑な関係を示しています。 この例ではナレッジ グラフの接続を示していますが、これと同じパターンをページごとのスキーマ レベルで複製できます。
エンティティを理解するには、アルゴリズムが使用する 3 種類のデータ構造を理解することが重要です。
- 構造化されていないエンティティの説明を使用して、他のエンティティへの参照を認識し、明確にする必要があります。 有向エッジ (ハイパーリンク) は、各エンティティから、その説明で言及されている他のすべてのエンティティに追加されます。
- 半構造化された環境 (ウィキペディアなど) では、他のエンティティへのリンクが明示的に提供される場合があります。
- 構造化データを扱う場合、RDF トリプルはグラフ (つまり、ナレッジ グラフ) を定義します。 特に、サブジェクトおよびオブジェクト リソース (URI) はノードであり、述語はエッジです。
IR スコアの半構造化された混乱するコンテキストの問題は、ドキュメントが単一のトピック用に構成されていない場合、IR スコアが 2 つの異なるコンテキストによって希釈され、別のテキスト ドキュメントに相対的なランクが失われる可能性があることです。
IR スコアの希薄化には、構造化されていない語彙関係と不適切な単語の近接性が含まれます。
相互に補完する関連語は、ドキュメントの段落またはセクション内で密接に使用して、コンテキストをより明確に示し、IR スコアを向上させる必要があります。
エンティティの属性と関係を利用すると、5 ~ 20% の範囲で相対的に改善されます。 エンティティ タイプの情報を活用することは、25% から 100% 以上の範囲の相対的な改善で、さらにやりがいがあります。
ドキュメントにエンティティで注釈を付けると、構造化されていないドキュメントに構造がもたらされ、ナレッジ ベースにエンティティに関する新しい情報を入力するのに役立ちます。
ウィキペディアをエンティティ SEO フレームワークとして使用する
ウィキペディアのページの構造
- タイトル (I.)
- リードセクション (II.)
- 曖昧さ回避リンク (II.a)
- インフォボックス (II.b)
- 導入テキスト (II.c)
- 目次 (III.)
- 本文の内容 (IV.)
- 付録と底辺 (V.)
- 参考文献とメモ (Va)
- 外部リンク (Vb)
- カテゴリ (Vc)
ウィキペディアのほとんどの記事には、記事の簡単な要約である「リード」という導入テキストが含まれています。通常は 4 段落以内の長さです。 これは、記事に興味を持たせる方法で書く必要があります。
最初の文と冒頭の段落は特に重要です。 最初の文は、「記事で説明されているエンティティの定義と考えることができます。」 最初の段落では、あまり詳細を省いてより精巧な定義を提供しています。
リンクの価値は、ナビゲーションの目的を超えています。 記事間の意味的な関係を捉えます。 さらに、アンカー テキストは、エンティティ名のバリエーションの豊富なソースです。 ウィキペディアのリンクは、特に、テキスト内のエンティティの言及を識別して曖昧さをなくすために使用できます。
- エンティティに関する重要な事実を要約します (インフォボックス)。
- 簡単な紹介。
- 内部リンク。 編集者に与えられた重要な規則は、実体または概念の最初の出現のみにリンクすることです。
- エンティティの一般的な類義語をすべて含めます。
- カテゴリページ指定。
- ナビゲーション テンプレート。
- 参考文献。
- Wiki ページを理解するための特別な解析ツール。
- 複数のメディア タイプ。
エンティティを最適化する方法
以下は、検索用にエンティティを最適化する際の重要な考慮事項です。
- 意味的に関連する単語をページに含めること。
- ページ上の単語とフレーズの頻度。
- ページ上の概念の構成。
- ページ上の非構造化データ、半構造化データ、および構造化データを含みます。
- 主語-述語-目的語のペア (SPO)。
- 本のページとして機能する、サイト上の Web ドキュメント。
- Web サイト上の Web ドキュメントの編成。
- エンティティの既知の機能である概念を Web ドキュメントに含めます。
重要な注意: エンティティ間の関係に重点が置かれている場合、ナレッジ ベースはしばしばナレッジ グラフと呼ばれます。
意図はユーザーの検索ログやその他のコンテキストと併せて分析されるため、人物 1 の同じ検索フレーズが人物 2 とは異なる結果を生成する可能性があります。その人物は、まったく同じクエリで異なる意図を持つ可能性があります。
ページが両方のタイプの意図をカバーしている場合、そのページは Web ランキングの候補として適しています。 ナレッジ ベースの構造を使用して、クエリ インテント テンプレートをガイドできます (前のセクションで説明したように)。
People Also Ask、People Search For、および Autocomplete は、送信されたクエリに意味的に関連しており、現在の検索方向をさらに深く掘り下げるか、検索タスクの別の側面に移動します。
私たちはこれを知っているので、どうすれば最適化できるのでしょうか?
ドキュメントには、できるだけ多くの検索意図のバリエーションを含める必要があります。 Web サイトには、クラスターのすべての検索意図のバリエーションが含まれている必要があります。 クラスタリングは、次の 3 種類の類似性に依存します。
- 語彙的類似性。
- セマンティックな類似性。
- 類似性をクリックします。
トピックカバレッジ
それは何ですか –> 属性リスト –> 各属性専用のセクション –> 各セクションは、そのトピックに完全に特化した記事にリンクしています –> 対象者を指定し、サブセクションの定義を指定する必要があります –> 考慮すべきこと? ⇒メリットは? –> モディファイヤのメリット –> ___ とは –> 機能は? –> 入手方法 –> 入手方法 –> 誰ができるか –> すべてのカテゴリに戻るリンク

Google は、Google がコンテンツをどのように見ているかを示す、顕著性スコア (「強さ」や「自信」という言葉の使い方と同様) を提供するツールを提供しています。

上記の例は、2018 年のエンティティに関する Search Engine Land の記事からのものです。
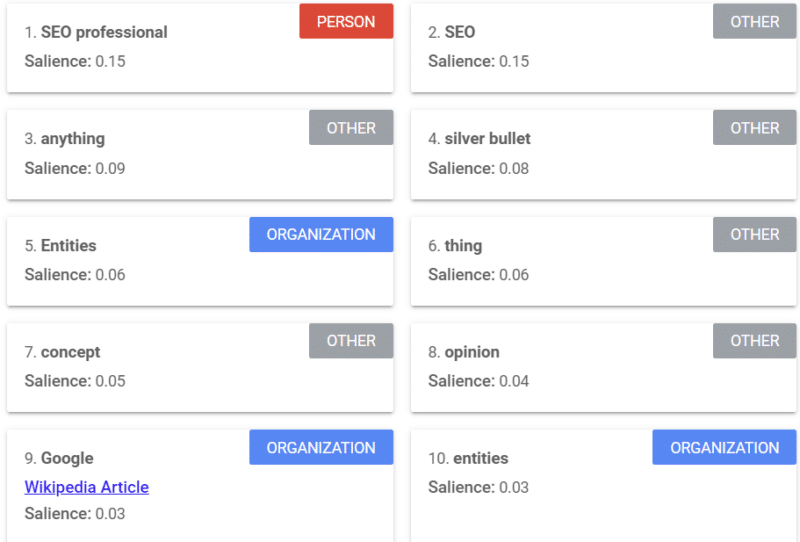
例から人、その他、および組織を確認できます。 このツールは、Google Cloud の Natural Language API です。
エンティティについて話すとき、すべての単語、文、および段落が重要です。 考えを整理する方法によって、コンテンツに対する Google の理解が変わる可能性があります。
SEO に関するキーワードを含めることはできますが、Google はそのキーワードをあなたが理解してもらいたい方法で理解しますか?
ツールに 1 つか 2 つの段落を配置し、例を再構成および変更して、顕著性がどのように増減するかを確認してください。
「曖昧さ回避」と呼ばれるこの作業は、エンティティにとって非常に重要です。 言語はあいまいなので、Google にとって言葉のあいまいさを軽減する必要があります。
最新の曖昧さ回避アプローチでは、次の 3 種類の証拠が考慮されます。
エンティティとメンションの以前の重要性。
言及を囲むテキストと候補エンティティとの間の文脈上の類似性、およびドキュメント内のエンティティをリンクするすべての決定間の一貫性。
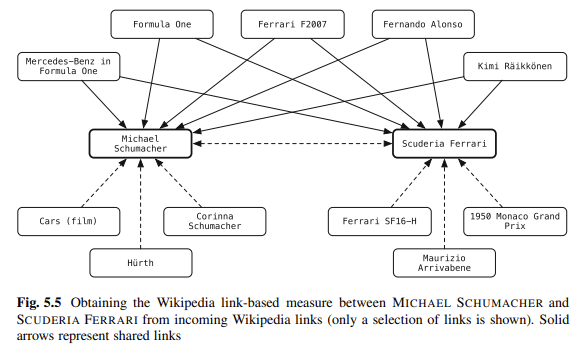
スキーマは、コンテンツのあいまいさを解消するための私のお気に入りの方法の 1 つです。 ブログ内のエンティティをナレッジ リポジトリにリンクしています。 バログは次のように述べています。
「構造化されていないテキスト内のエンティティを構造化されたナレッジ リポジトリに [リンク] することで、ユーザーの情報消費活動に大きな力を与えることができます。」
たとえば、ドキュメントの読者は、1 回のクリックでコンテキスト情報または背景情報を取得でき、関連するエンティティに簡単にアクセスできます。
エンティティの注釈は、取得のパフォーマンスを向上させたり、検索結果とのユーザーの対話を促進したりするために、下流の処理でも使用できます。
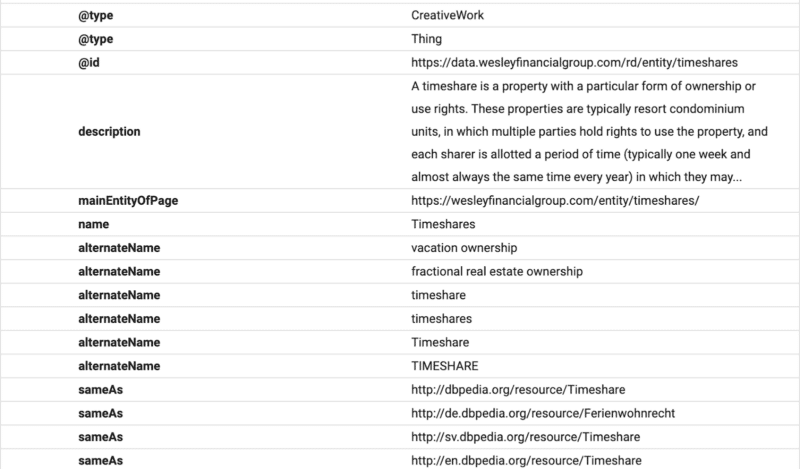
ここでは、FAQ スキーマを使用して Google 向けに FAQ コンテンツが構造化されていることがわかります。
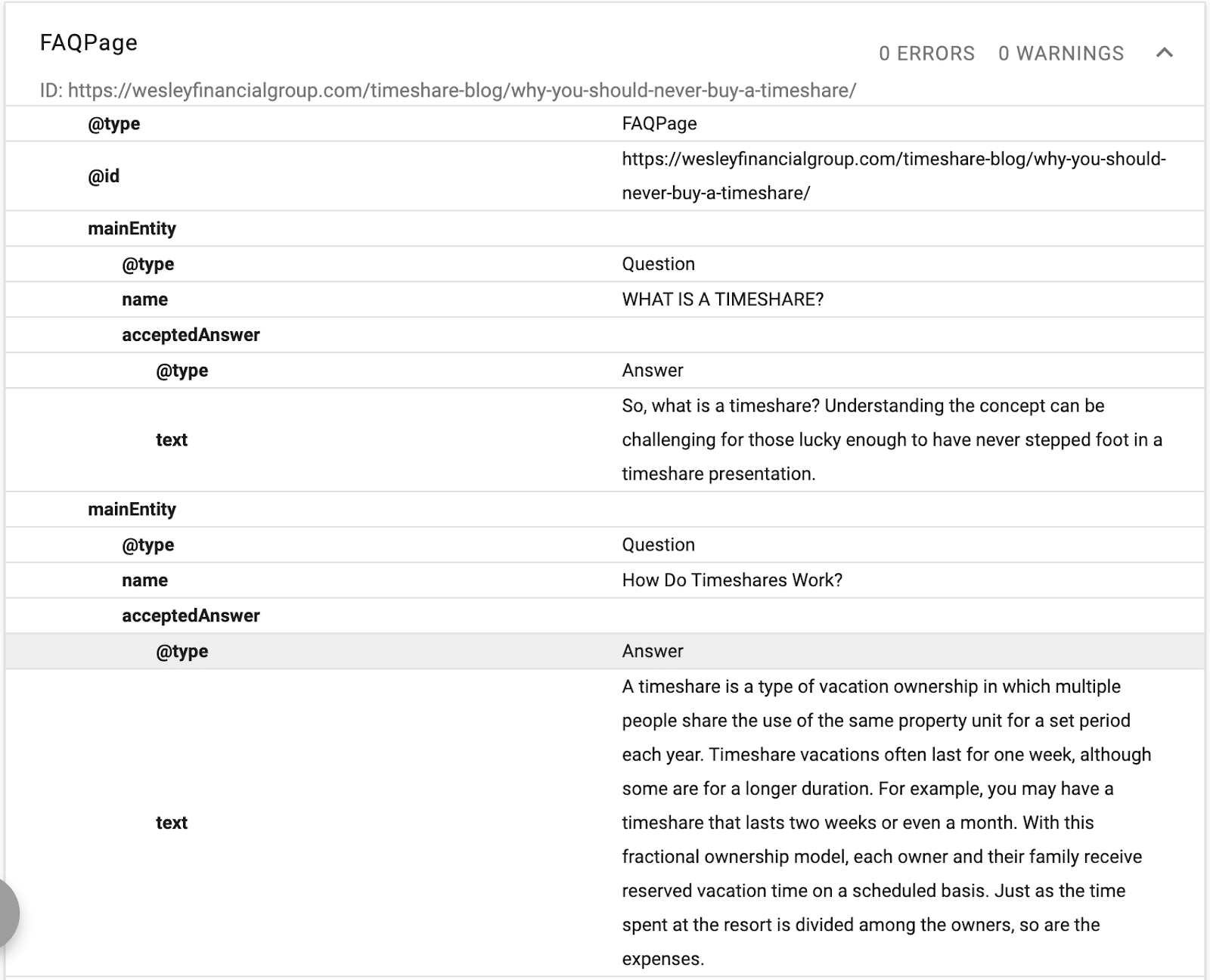
この例では、テキストの説明、ID、およびページのメイン エンティティの宣言を提供するスキーマを確認できます。
(Google はコンテンツの階層を理解したいと考えているため、H1 ~ H6 が重要です。)
代替名と宣言と同じものが表示されます。 これで、Google がコンテンツを読み取ると、どの構造化データベースがテキストに関連付けられるかがわかり、エンティティにリンクされた単語の同義語と代替バージョンが作成されます。
スキーマを使用して最適化すると、エンティティ識別、エンティティ抽出、およびエンティティ チャンクとも呼ばれる NER (名前付きエンティティ認識) が最適化されます。
アイデアは、Named Entity Disambiguation > Wikiification > Entity Linking に取り組むことです。
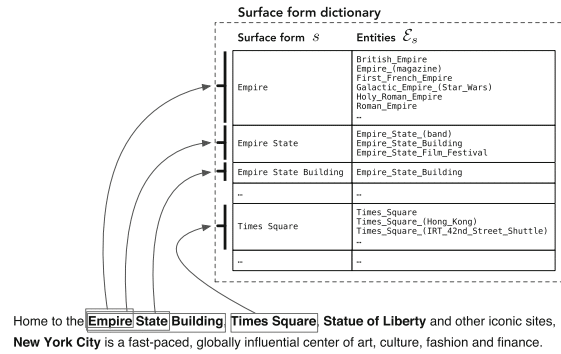
「ウィキペディアの出現により、他の貴重なリソース (具体的には、ハイパーリンク、カテゴリ、およびリダイレクトと曖昧さ回避ページ) とともにエンティティの包括的なカタログを提供することで、大規模なエンティティの認識と曖昧さ回避が容易になりました。」
– エンティティ指向検索
方法 SEOツールの提案を超えて
ほとんどの SEO は、コンテンツを最適化するために何らかのオンページ ツールを使用しています。 すべてのツールは、独自のコンテンツの機会とコンテンツの深さの提案を特定する能力に限界があります。
ほとんどの場合、ページ上のツールは上位の SERP 結果を集計し、エミュレートするための平均を作成しているだけです。
SEO 担当者は、Google が同じ再ハッシュされた情報を探しているわけではないことを覚えておく必要があります。 他の人がやっていることを真似することはできますが、独自の情報がシード サイト/オーソリティ サイトになるための鍵となります。
Google が新しいコンテンツを処理する方法を簡単に説明すると、次のようになります。
ドキュメントが特定のエンティティに言及していることが判明すると、そのドキュメントをチェックして、そのエンティティのナレッジ ベース エントリを更新できる新しい事実を発見できる可能性があります。
バログは次のように書いています。
「私たちは、関心のある特定のエンティティ セットの KB エントリへの変更を暗示する可能性のあるコンテンツ (ニュース記事、ブログ投稿など) を自動的に識別することにより、編集者が変更を常に把握できるようにしたいと考えています (つまり、特定の編集者がの責任者)。"
ナレッジ ベース、エンティティ認識、および情報のクロール可能性を改善する人は誰でも、Google の愛を得るでしょう。
ナレッジ リポジトリで行われた変更は、元のソースとしてのドキュメントまでさかのぼることができます。
トピックをカバーするコンテンツを提供し、珍しいまたは新しいレベルの深さを追加した場合、Google はドキュメントにその固有の情報が追加されたかどうかを識別できます。
最終的に、この新しい情報が一定期間にわたって維持されると、Web サイトがオーソリティになる可能性があります。
これはドメイン レーティングに基づく信頼性ではなく、局所的な報道に基づくものであり、はるかに価値があると私は信じています。
SEO へのエンティティ アプローチを使用すると、検索ボリュームのあるキーワードをターゲットにすることに制限されません。
ヘッド ターム (「フライ フィッシング ロッド」など) を検証するだけで、古き良きファッションの人間の思考に基づいた検索意図のバリエーションをターゲットにすることに集中できます。
ウィキペディアから始めます。 フライフィッシングの例では、釣りの Web サイトでは少なくとも次の概念をカバーする必要があることがわかります。
- 魚種、歴史、起源、発展、技術の向上、拡大、フライフィッシングの方法、キャスティング、スペイキャスティング、トラウトのフライフィッシング、フライフィッシングの技術、冷水での釣り、ドライフライのトラウトフィッシング、トラウトのニンフィング、静水マス釣り、マス遊び、マスのリリース、ソルトウォーター フライ フィッシング、タックル、人工フライ、ノット。
上記のトピックは、フライフィッシングのウィキペディアのページからのものです。 このページはトピックの優れた概要を提供しますが、意味的に関連するトピックから得られるトピックのアイデアを追加したいと思います。
トピック「魚」については、語源、進化、解剖学と生理学、魚のコミュニケーション、魚の病気、保全、人間にとっての重要性など、いくつかのトピックを追加できます。
トラウトの解剖学と特定の釣り技術の有効性を関連付けた人はいますか?
1 つの釣りウェブサイトですべての魚種をカバーし、釣り方、ロッド、餌の種類を各魚にリンクしていますか?
ここまでで、トピックの拡張がどのように拡大するかを確認できるはずです。 コンテンツ キャンペーンを計画するときは、この点に留意してください。
ただ再ハッシュしないでください。 付加価値。 一意であること。 この記事に記載されているアルゴリズムをガイドとして使用してください。
結論
この記事は、エンティティに焦点を当てた一連の記事の一部です。 次回の記事では、エンティティに関する最適化の取り組みと、市場に出回っているエンティティに焦点を当てたツールについて詳しく説明します。
これらの概念の多くを説明してくれた 2 人の人物に感謝の言葉を述べて、この記事を締めくくりたいと思います。
SEO by the Sea の Bill Slawski 氏と、Holistic SEO の Koray Tugbert 氏です。 Slawski はもう私たちと一緒ではありませんが、彼の貢献は SEO 業界に波及効果をもたらし続けています。
記事の内容については、次の情報源に大きく依存しています。これらの情報源は、このトピックに関する最高のリソースです。
- Extended Named Entity Hierarchy by ケティネ サトシ、スドウ キヨシ、ノバタ チカシ
- Krisztian Balog による Entity-Oriented Search 、情報検索シリーズ (INRE、ボリューム 39)
- エンティティ検出によるクエリ書き換え、Google の特許
- 検索クエリの改良、Google 特許
- エンティティと検索クエリの関連付け、Google 特許
この記事で表明された意見はゲスト著者のものであり、必ずしも Search Engine Land ではありません。 スタッフの著者はここにリストされています。