
Apache Sparkはどのようにして航空会社の分析に翼を与えることができますか?
公開: 2015-10-30世界の航空業界は急速に成長を続けていますが、一貫した堅調な収益性はまだ見られていません。 国際航空運送協会(IATA)によると、業界は過去10年間で収益を2倍にし、2005年の3,690億ドルから、2015年には7,270億ドルになると予想しています。

商用航空セクターでは、空港、飛行機メーカー、ジェットエンジンメーカー、旅行代理店、サービス会社など、バリューチェーンのすべてのプレーヤーがかなりの利益を上げています。
これらのプレーヤーはすべて、フライトトランザクションの解約率が高いため、非常に大量のデータを個別に生成します。 需要を特定して把握することがここでの鍵であり、航空会社が差別化するためのより大きな機会を提供します。 したがって、航空業界はビッグデータの洞察を利用して売上を伸ばし、利益率を向上させることができます。
ビッグデータとは、従来のデータ処理システムや手持ちのDBMSツールではコンピューティングを処理できないほど大規模で複雑なデータセットのコレクションを表す用語です。
Apache Sparkは、インタラクティブなクエリと反復アルゴリズム用に特別に設計されたオープンソースの分散クラスターコンピューティングフレームワークです。
Spark DataFrame抽象化は、RのネイティブデータフレームまたはPythons pandasパッケージに似た表形式のデータオブジェクトですが、クラスター環境に保存されます。
Fortunesの最新の調査によると、ApacheSparkは2015年の最も人気のあるテクノロジーです。
最大のHadoopベンダーであるClouderaは、GoodByeをHadoops MapReduceに、HelloをSparkに言っています。
SparkがHadoopよりも優れているのは、速度です。 Sparkは、ほとんどの操作をメモリ内で処理します。それらを分散物理ストレージからはるかに高速な論理RAMメモリにコピーします。 これにより、HadoopsMapReduceシステムで実行する必要のある低速で不格好な機械式ハードドライブとの間の書き込みおよび読み取りにかかる時間が短縮されます。
また、Sparkには、モノのインターネットとも呼ばれる接続されたデバイスからの履歴データを組み合わせてリアルタイムデータを分析するなど、ビジネス目標を強化するために巧妙に作成されたツール(リアルタイム処理、機械学習、インタラクティブSQL)が含まれています。
今日は、 ApacheSparkを使用してサンプルの空港データに関する洞察を収集しましょう。
以前のブログでは、新しいDataframes APIを使用してSparkで構造化データと半構造化データを処理する方法を確認し、JSONデータを効率的に処理する方法についても説明しました。
このブログでは、SQLを使用してDataFrameでデータをクエリする方法と、出力をCSV形式でファイルシステムに保存する方法について説明します。
DatabricksCSV解析ライブラリの使用
このために、Apache Sparkの作成者によって設立され、現在Sparkの開発と配布を処理しているDatabricksが提供するCSV解析ライブラリを使用します。
Sparkコミュニティは、約600人の貢献者で構成されており、貢献者の数の点で、オープンソースソフトウェアの主要な統治機関であるApacheSoftwareFoundation全体で最も活発なプロジェクトになっています。
Spark-csvライブラリは、Spark内のcsvデータを解析およびクエリするのに役立ちます。 このライブラリは、Hadoop互換のファイルシステムとの間でcsvデータを読み書きするために使用できます。
SparkDataFramesへのデータのロード
Databricksのspark-csv解析ライブラリを使用して、入力ファイルをSparkDataFramesにロードしましょう。
–packages com.databricks:spark-csv_2.10:1.0.3を指定することにより、Sparkシェルでこのライブラリを使用できます。
以下に示すようにシェルを起動している間:
$ bin / spark-shell –packages com.databricks:spark-csv_2.10:1.0.3
このコマンドを実行するとspark-csvパッケージが自動的にダウンロードされるため、インターネットに接続する必要があることを忘れないでください。 Spark1.4.0バージョンを使用しています
すでに作成されたSparkContext(sc)オブジェクトを使用してsqlContextを作成しましょう
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
import sqlContext.implicits._
次に、スキーマが次のようなairports.csv(airport csv github)ファイルからcsvデータをロードします。
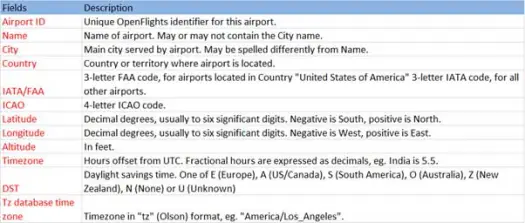
scala> val airportDF = sqlContext.load("com.databricks.spark.csv", Map("path" -> "/home /poonam/airports.csv", "header" -> "true"))ロード操作は、Databricksspark-csvライブラリを使用して*.csvファイルを解析し、ファイルの最初のヘッダー行と同じ列名を持つデータフレームを返します。
以下は、loadメソッドに渡されるパラメーターです。
- ソース: 「com.databricks.spark.csv」は、csvファイルとしてロードすることをsparkに指示します。
- オプション:
- path –ファイルが配置されているファイルのパス。
- ヘッダー: "header"-> "true"は、ファイルの最初の行を結果のデータフレームの列名にマップするようにsparkに指示します。
データフレームのスキーマを見てみましょう
データフレームのサンプルデータを確認してください
scala> airportDF.show

一時テーブルを使用したCSVデータのクエリ:
テーブルに対してクエリを実行するには、SQLContextでsql()メソッドを呼び出します。
Airports DataFrameを作成し、CSVデータをロードしました。このDFデータをクエリするには、airportsという一時テーブルとして登録する必要があります。
>>
scala> airportDF.registerTempTable("airports")
データセットの南東部に空港がいくつあるかを調べてみましょう
scala> sqlContext.sql("select AirportID, Name, Latitude, Longitude from airports where Latitude<0 and Longitude>0").collect.foreach(println)
[1,Goroka,-6.081689,145.391881]
[2,Madang,-5.207083,145.7887]
[3,Mount Hagen,-5.826789,144.295861
]
[4,Nadzab,-6.569828,146.726242]
[5,Port Moresby Jacksons Intl,-9.443383,147.22005]
[6,Wewak Intl,-3.583828,143.669186]

SparkのSQLクエリで集計を実行できます
各国に空港があるユニークな都市がいくつあるかを調べます
scala> sqlContext.sql("select Country, count(distinct(City)) from airports group by Country").collect.foreach(println)
[Iceland,10]
[Greenland,4]
[Canada,131]
[Papua New Guinea,6]
各国の空港の平均高度(フィート)はどれくらいですか?
scala> sqlContext.sql("select Country , avg(Altitude) from airports group by Country").collect
res6: Array[org.apache.spark.sql.Row] =Array(
[Iceland,72.8],
[Greenland,202.75],
[Canada,852.6666666666666],
[Papua New Guinea,1849.0])
次に、各タイムゾーンで稼働している空港の数を確認しますか?
scala> sqlContext.sql("select Tz , count(Tz) from airports group by Tz").collect.foreach(println)
[America/Dawson_Creek,1]
[America/Coral_Harbour,3]
[America/Halifax,9]
[America/Toronto,48]
[America/Vancouver,19]
[America/Godthab,3]
[Pacific/Port_Moresby,6]
[Atlantic/Reykjavik,10]
[America/Thule,1]
[America/St_Johns,4]
[America/Winnipeg,14]
[America/Edmonton,27]
[America/Regina,10]
また、各国のこれらの空港の平均緯度と経度を計算することもできます
scala> sqlContext.sql("select Country, avg(Latitude), avg(Longitude) from airports group by Country").collect.foreach(println)
[Iceland,65.0477736,-19.5969224]
[Greenland,67.22490275,-54.124131999999996]
[Canada,53.94868565185185,-93.950036237037]
[Papua New Guinea,-6.118766666666666,145.51532]
異なるDSTがいくつあるかを数えましょう
scala> sqlContext.sql("select count(distinct(DST)) from airports").collect.foreach(println)
[4]
CSV形式でデータを保存する
これまで、csvデータを読み込んでクエリを実行していました。 次に、結果をCSV形式でファイルシステムに保存する方法を説明します。
すべての国の北西部にあるすべての空港に関するレポートをクライアントに送信するとします。
最初にそれを計算しましょう。
scala> val NorthWestAirportsDF=sqlContext.sql("select AirportID, Name, Latitude, Longitude from airports where Latitude>0 and Longitude<0")
NorthWestAirportsDF: org.apache.spark.sql.DataFrame = [AirportID: string, Name: string, Latitude: string, Longitude: string]
そしてそれをCSVファイルに保存します
scala> NorthWestAirportsDF.save("com.databricks.spark.csv", org.apache.spark.sql.SaveMode.ErrorIfExists, Map("path" -> "/home/poonam/NorthWestAirports.csv","header"->"true"))
以下は、saveメソッドに渡されるパラメーターです。
- ソース:データをcsvとして保存するようにsparkに指示するロードメソッドcom.databricks.spark.csvと同じです。
- SaveMode :これにより、ユーザーは、指定された出力パスがすでに存在する場合に実行する必要があることを事前に指定できます。 既存のデータが誤って失われたり上書きされたりしないようにします。 エラーをスローしたり、追加したり、上書きしたりできます。 ここでは、既存のファイルを上書きしたくないため、エラーErrorIfExistsをスローしました。
- オプション:これらのオプションは、 loadメソッドに渡したものと同じです。 オプション:
- path –保存する必要のあるファイルのパス。
- ヘッダー: "header"-> "true"は、データフレームの列名を結果の出力ファイルの最初の行にマップするようにsparkに指示します。
他のデータ形式をCSVに変換する
このライブラリを使用して、JSON、寄木細工、テキストなどの他のデータ形式をCSVに変換することもできます。
以前のブログでは、jsonデータを作成しました。 あなたはgithubでそれを見つけることができます
scala> val employeeDF = sqlContext.read.json("/home/poonam/employee.json")
CSVとして保存しましょう。
scala> employeeDF.save("com.databricks.spark.csv", org.apache.spark.sql.SaveMode.ErrorIfExists, Map("path" -> "/home/poonam/employee.csv", "header"->"true"))
結論:
この投稿では、 SparkSQLインタラクティブクエリを使用して空港データに関するいくつかの洞察を収集しました
Sparkのcsv解析ライブラリを調べました
次のブログでは、Sparkの非常に重要なコンポーネントであるSparkStreamingについて説明します。
Spark Streamingを使用すると、ユーザーはリアルタイムデータをSparkに収集し、発生時に処理して、結果を即座に提供できます。