
Google が EEAT を通じて著者を特定および評価する方法
公開: 2023-04-17Google は、検索結果をランク付けする際に、コンテンツ ソース、特に作成者をより重視しています。 Perspectives、About this result 、 About this authorのSERPの紹介は、これを明確にしています。
この記事では、Google が作成者の経験、専門知識、権威性、信頼性 (EEAT) を通じてコンテンツを評価する方法について説明します。
EEAT: Google の品質攻勢
Google は、検索結果の品質と SERP 上のユーザー エクスペリエンスを向上させるための EEAT コンセプトの重要性を強調しています。
コンテンツの一般的な品質、リンク シグナル (PageRank やアンカー テキストなど)、エンティティ レベルのシグナルなど、ページ上の要素はすべて重要な役割を果たします。
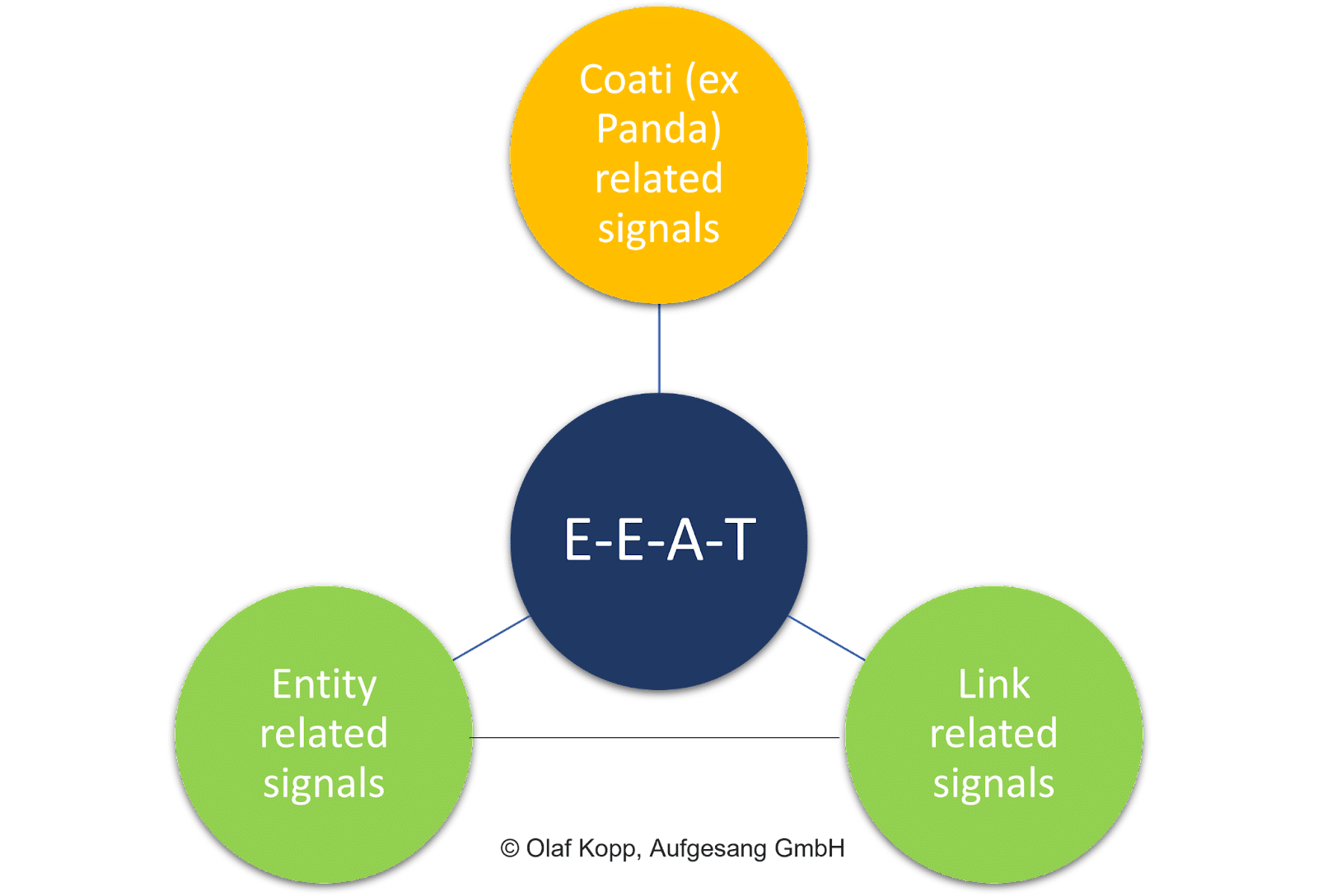
ドキュメント スコアリングとは対照的に、個々のコンテンツの評価は EEAT の焦点ではありません。
この概念には、ドメインと発信者エンティティに関連するテーマの参照があります。 検索の意図や個々のコンテンツ自体とは無関係です。
最終的に、EEAT は検索クエリとは独立した影響因子です。
EEAT は主にテーマ領域を指し、企業、組織、人々、およびそれらのドメインなどのエンティティに関連して、コンテンツのコレクションとオフページ シグナルを評価する評価レイヤーとして理解されます。
コンテンツのソースとしての著者の重要性
(E-)EAT のずっと前に、Google はコンテンツ ソースの評価を検索ランキングに含めようとしました。 たとえば、2009 年の Vince アップデートにより、ブランドが作成したコンテンツがランキングで有利になりました。
Knol や Google+ などのプロジェクトは終了して久しいが、Google は著者の評価のシグナルを収集しようとしてきた (つまり、ソーシャル グラフとユーザーの評価を介して)。
過去 20 年間、いくつかの Google 特許は、Knol などのコンテンツ プラットフォームや Google+ などのソーシャル ネットワークに直接的または間接的に言及してきました。
EEAT 基準に従ってコンテンツの出所または作成者を評価することは、検索結果の品質をさらに向上させるための重要なステップです。
AI によって生成されたコンテンツと従来のスパムが豊富にあるため、Google が劣悪なコンテンツを検索インデックスに含めることは意味がありません。
インデックスを作成し、情報検索中に処理する必要があるコンテンツが多いほど、より多くのコンピューティング パワーが必要になります。
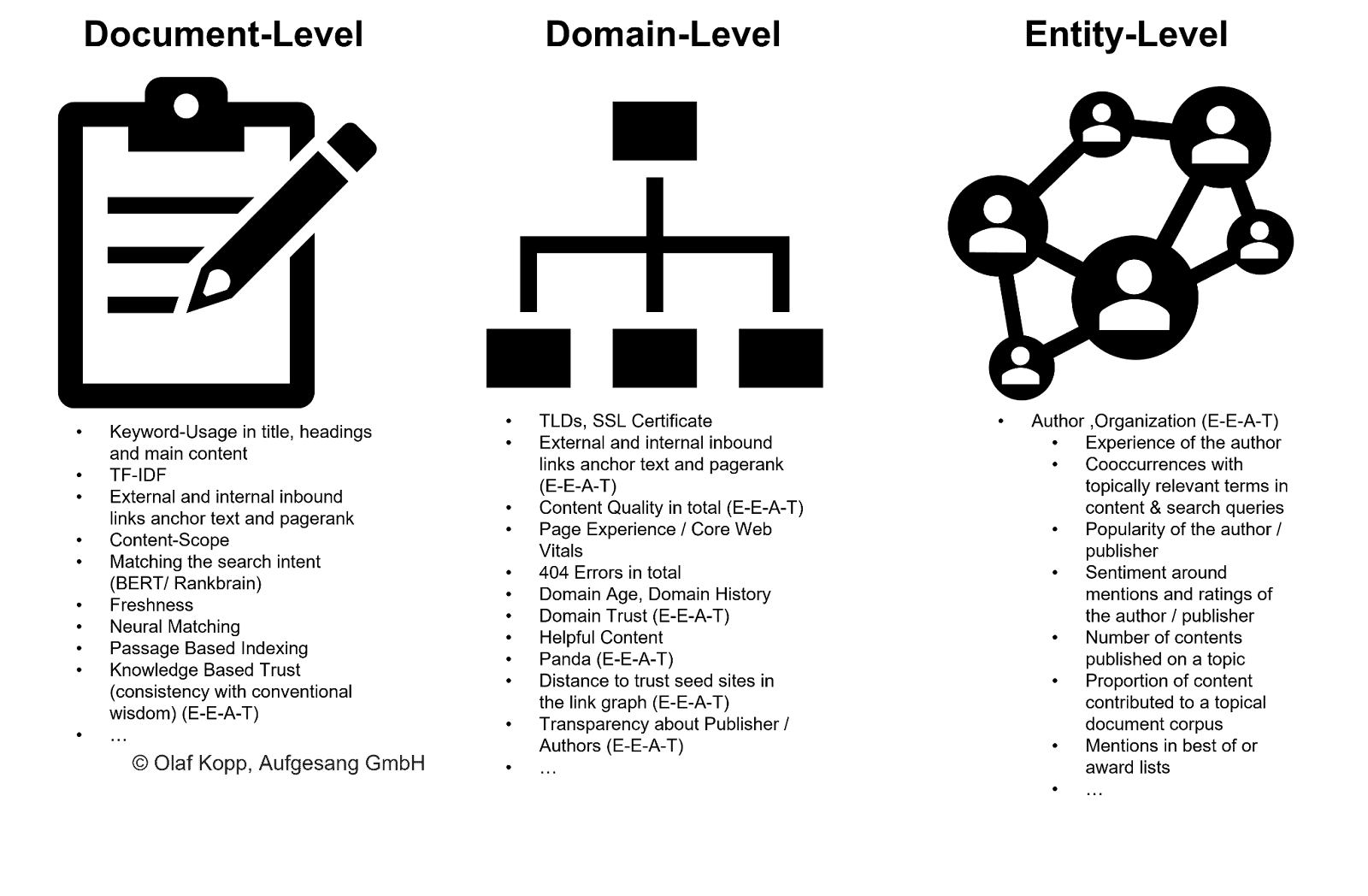
EEAT は、コンテンツのすべての部分をクロールする必要なく、より広いスケールで適用されるエンティティ、ドメイン、作成者レベルに基づいて Google をランク付けするのに役立ちます。
このマクロ レベルでは、発信元エンティティに従ってコンテンツを分類し、多かれ少なかれクロール バジェットを割り当てることができます。 Google はこの方法を使用して、コンテンツ グループ全体をインデックスから除外することもできます。
Google はどのようにして著者を特定し、コンテンツを属性付けできますか?
著者は個人エンティティ タイプに属します。 ナレッジ グラフに記録されている既知のエンティティと、ナレッジ ボールトなどのナレッジ リポジトリに記録されている未知または検証されていないエンティティを区別する必要があります。
エンティティがまだナレッジ グラフに取り込まれていない場合でも、Google は機械学習と言語モデルを使用して、構造化されていないコンテンツからエンティティを認識して抽出できます。 このソリューションは、自然言語処理のサブタスクであるエンティティ認識 (NER) と呼ばれます。
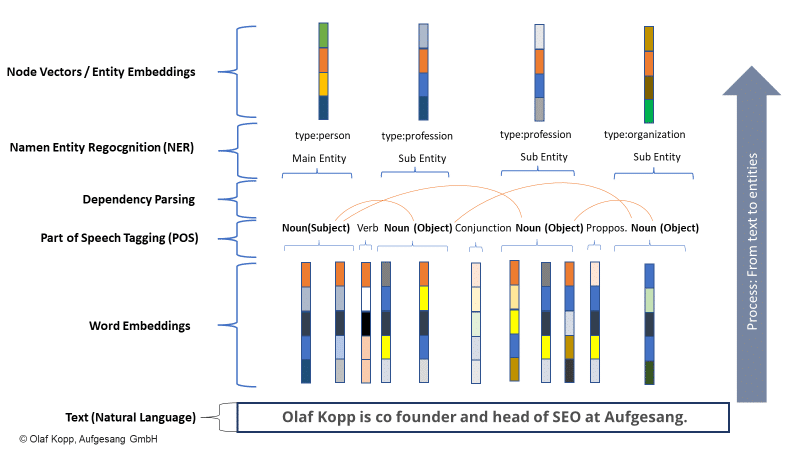
NER は言語パターンに基づいてエンティティを認識し、エンティティ タイプが割り当てられます。 一般的に言えば、名詞は (名前付きの) 実体です。
最新の情報検索システムは、これに単語埋め込み (Word2Vec) を使用します。
数値のベクトルはテキストの各単語またはテキストの段落を表し、エンティティはノード ベクトルまたはエンティティ埋め込み (Node2Vec/Entity2Vec) として表すことができます。
単語は、品詞 (POS) タグ付けによって文法クラス (名詞、動詞、前置詞など) に割り当てられます。
通常、名詞は実体です。 サブジェクトはメイン エンティティであり、オブジェクトはセカンダリ エンティティです。 動詞と前置詞は、エンティティを相互に関連付けることができます。
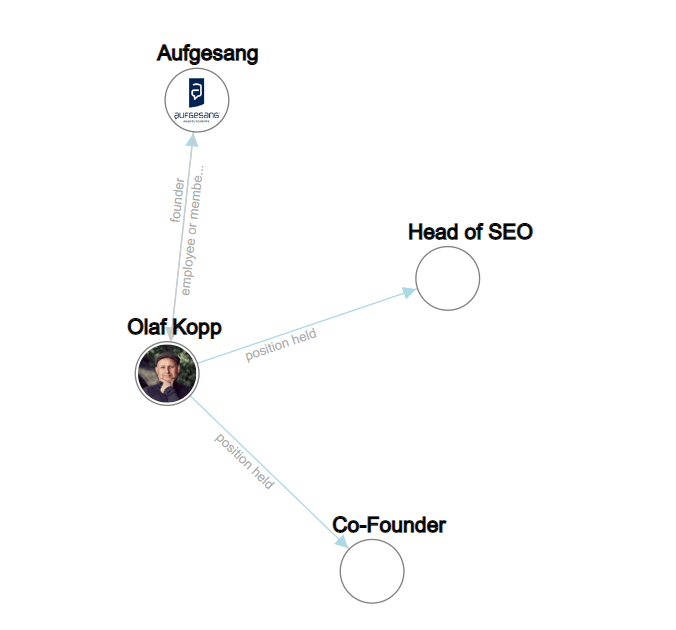
以下の例では、「olaf kopp」、「head of seo」、「cofounder」、および「aufgesang」が名前付きエンティティです。 (NN = 名詞)。
自然言語処理は、エンティティを識別し、エンティティ間の関係を判断できます。
これにより、エンティティの概念をより適切に捉えて理解するセマンティック スペースが作成されます。
これについて詳しくは、「Google が NLP を使用して検索クエリやコンテンツをよりよく理解する方法」をご覧ください。
作成者の埋め込みに対応するのは、ドキュメントの埋め込みです。 ドキュメントの埋め込みは、ベクトル空間分析によって作成者ベクトルと比較されます。 (詳細については、Google の特許「ドキュメントのベクトル表現の生成」を参照してください。)
すべてのタイプのコンテンツをベクトルとして表すことができるため、次のことが可能になります。
- ベクトル空間で比較される内容ベクトルと著者ベクトル。
- 類似性に従ってクラスター化されるドキュメント。
- 割り当てられる著者。
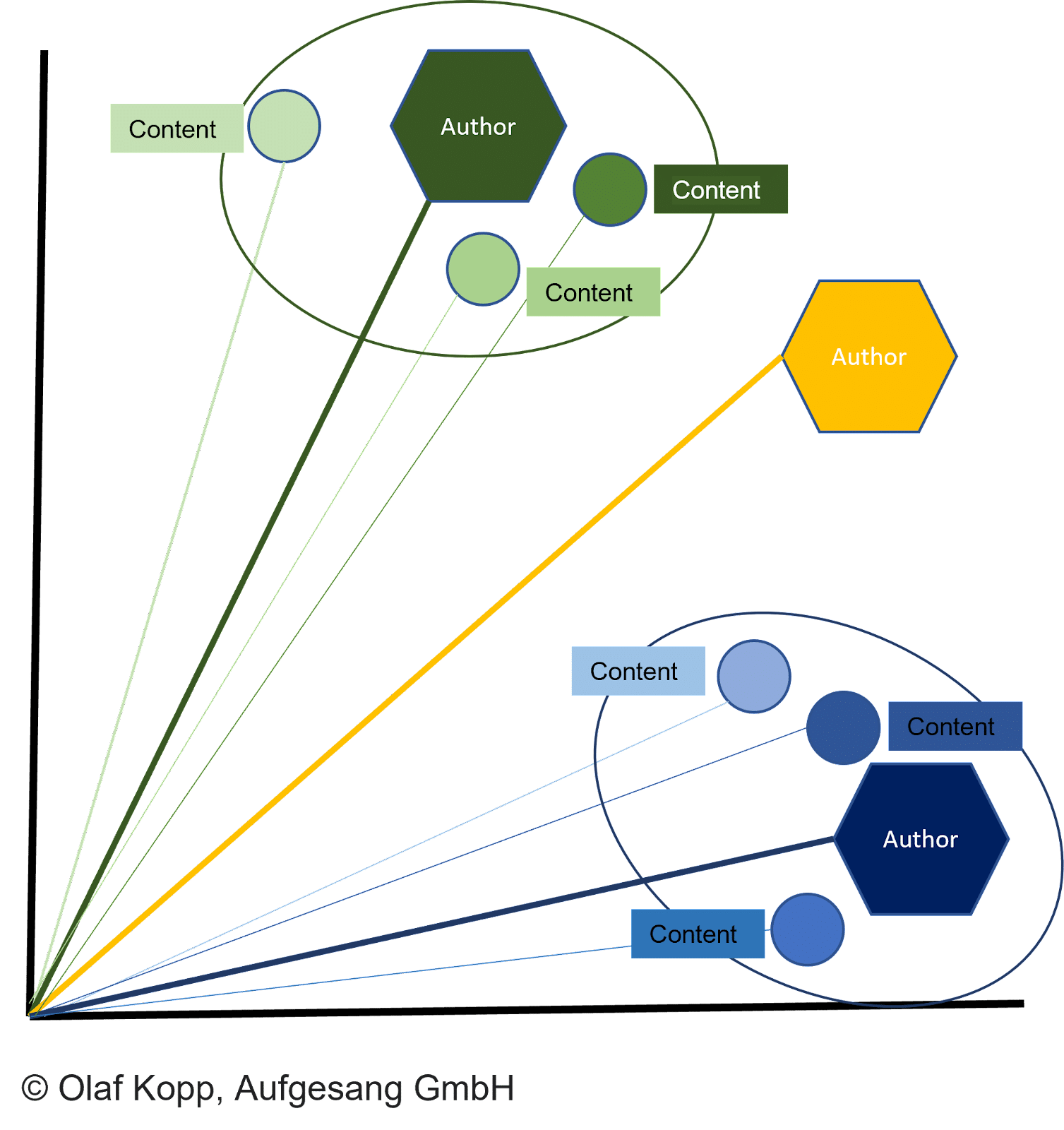
ドキュメント ベクトルと対応する作成者ベクトルの間の距離は、作成者がドキュメントを作成した確率を表します。
距離が他のベクトルよりも小さく、特定のしきい値に達した場合、ドキュメントは作成者に帰属します。
これにより、偽のフラグの下でドキュメントが作成されるのを防ぐこともできます。 次に、既に説明したように、コンテンツで指定された著者名を使用して、著者ベクトルを著者エンティティに割り当てることができます。
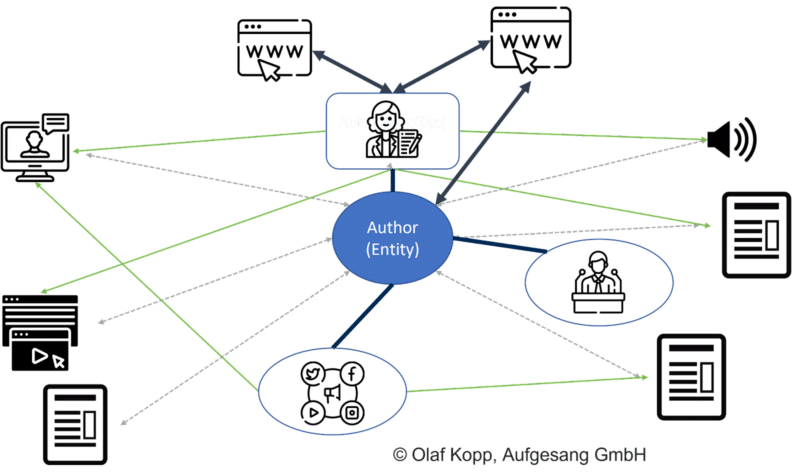
著者に関する重要な情報源は次のとおりです。
- その人物に関するウィキペディアの記事。
- 著者プロフィール。
- スピーカー プロファイル。
- ソーシャル メディアのプロフィール。
実体型の人物の名前でググると、ウィキペディアのエントリ、著者のプロフィール、著者に直結するドメインのURLが最初の20件の検索結果に表示されます。
モバイル SERP では、Google が個人エンティティと直接関係を確立しているソースを確認できます。
Google は、ソーシャル メディア プロファイルのアイコンの上のすべての結果を、エンティティを直接参照するソースとして認識しました。

この「olaf kopp」の検索クエリのスクリーンショットは、エンティティがソースにリンクされていることを示しています。
また、ナレッジ パネルの新しいバリアントも表示されます。 ここでベータテストの一部になったようです。
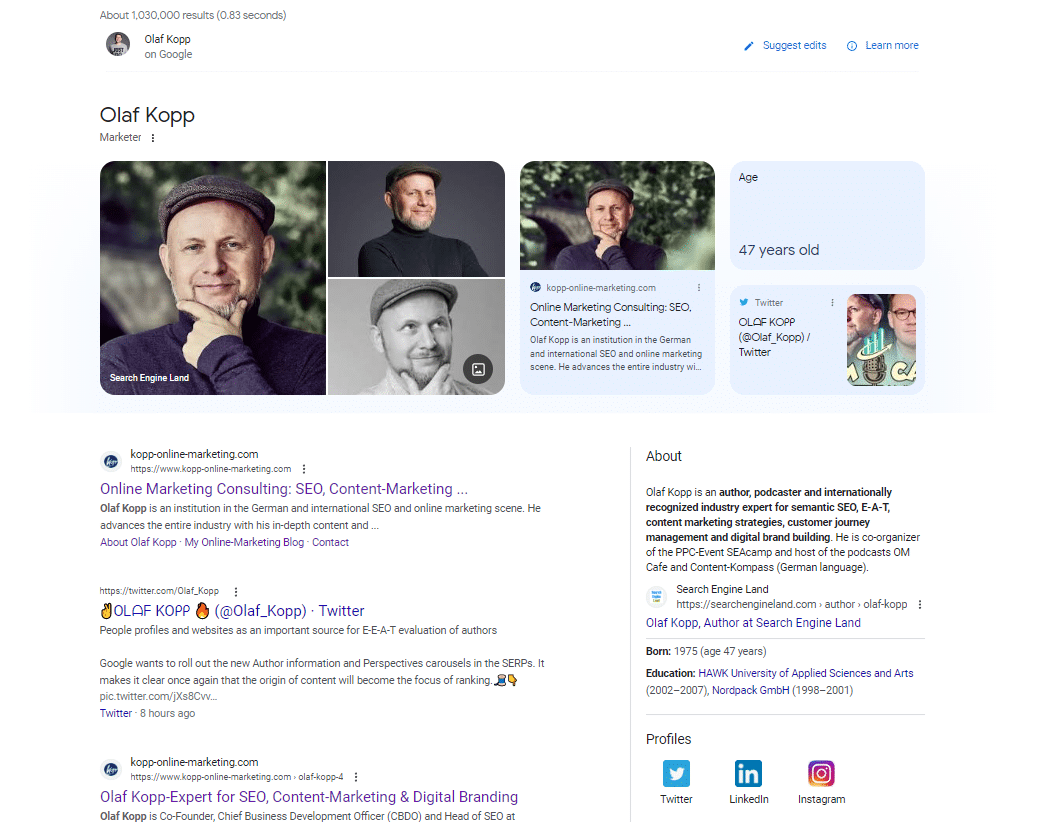
このスクリーンショットでは、画像と属性 (年齢) に加えて、Google が私のドメインとソーシャル メディア プロファイルを私のエンティティに直接リンクし、それらをナレッジ パネルに配信していることがわかります。
私に関するウィキペディアの記事がないため、アメリカの Search Engine Land の著者プロフィールとドイツのエージェンシー Web サイトの著者プロフィールから About の説明が配信されます。
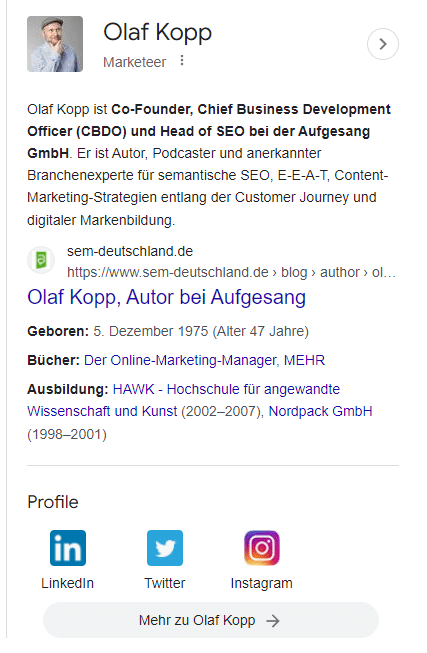
ウェブ上の個人プロフィールは、Google が著者を文脈化し、著者に関連付けられたソーシャル メディアのプロフィールとドメインを特定するのに役立ちます。
著者プロフィールの著者ボックスまたは著者コレクションは、Google がコンテンツを著者に割り当てるのに役立ちます。 あいまいさが生じる可能性があるため、著者名は識別子として不十分です。
一貫性を確保するために、すべての著者の説明に注意を払う必要があります。 Google はそれらを使用して、エンティティの有効性を相互に比較して確認できます。
検索マーケティング担当者が頼りにしている毎日のニュースレターを入手してください。
条件を参照してください。
著者の EEAT 評価に関する興味深い Google の特許
次の特許は、Google がどのように著者を識別し、それにコンテンツを割り当て、EEAT に関して評価するかについて考えられる方法論を垣間見せています。
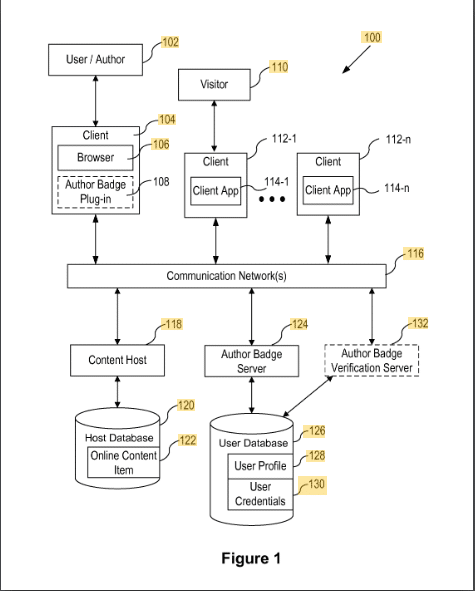
コンテンツ作成者バッジ
この特許は、コンテンツがバッジを介して作成者に割り当てられる方法を説明しています。
コンテンツは、電子メール アドレスや著者名などの ID を使用して著者バッジに割り当てられます。 検証は、作成者のブラウザのアドオンを介して行われます。
著者ベクトルの生成
Google は 2016 年にこの特許に署名し、有効期限は 2036 年まで延長されました。ただし、特許出願は米国でのみ行われており、世界中の Google 検索でまだ使用されていないことが示唆されています。
この特許は、著者がトレーニングデータに基づいてベクトルとして表現される方法を説明しています。
ベクトルは、著者の典型的な文体と言葉の選択に基づいて識別される固有のパラメーターになります。
このようにして、以前は作者に帰属していなかったコンテンツをそれらに割り当てたり、類似の作者をクラスターにグループ化したりできます。
その後、1 人または複数の作成者のコンテンツ ランキングを、検索におけるユーザーの過去のユーザー行動 (たとえば、Discover で) に基づいて調整できます。
したがって、すでに発見されている著者のコンテンツと同様の著者のコンテンツは、より上位にランク付けされます。
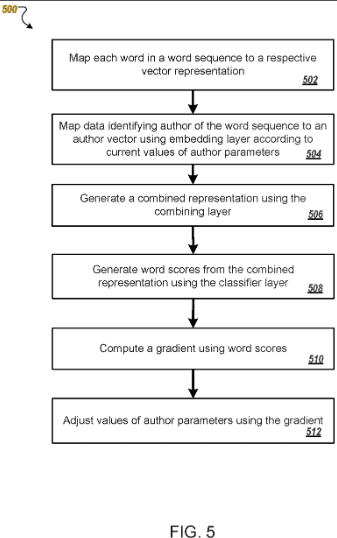
この特許は、著者や単語の埋め込みなど、いわゆる埋め込みに基づいています。
今日、埋め込みはディープ ラーニングと自然言語処理の技術標準です。
したがって、Google のような方法が著者の認識と帰属にも使用されることは明らかです。
著者の評判スコア
この特許は 2008 年に Google によって最初に署名され、2029 年まで有効です。この特許はもともと、長い間閉鎖されていた Google Knol プロジェクトに言及しています。
したがって、Google が 2017 年にオンライン コンテンツの収益化という新しいタイトルで再びそれを描いた理由は、さらにエキサイティングです。 Knol は 2012 年に Google によって閉鎖されました。
この特許は、評判スコアの決定に関するものです。 これには、次の要因を考慮することができます。
- 作者の枠のレベル。
- 著名メディアへの掲載。
- 出版物の数。
- 最近のリリースの年齢。
- 著者が公式に著者として活動している期間。
- 著者のコンテンツによって生成されたリンクの数。
著者は、トピックごとに複数の評価スコアを持ち、サブジェクト エリアごとに複数のエイリアスを持つことができます。
この特許で指摘されている点の多くは、Knol のようなクローズド プラットフォームに関連しています。 したがって、この特許は現時点では十分なはずです。
エージェントランク
この Google の特許は 2005 年に最初に署名され、2026 年までの最短期間があります。
米国に加えて、スペイン、カナダ、および世界中でも登録されており、Google 検索で使用される可能性が高くなります。
この特許は、デジタル コンテンツがエージェント (発行者および/または作成者) に割り当てられる方法を説明しています。 このコンテンツは、エージェントのランクなどに基づいてランク付けされます。
エージェント ランクは、検索クエリの検索意図とは無関係であり、エージェントに割り当てられたドキュメントとそのバックリンクに基づいて決定されます。
エージェント ランクは、1 つの検索クエリ、検索クエリ クラスター、またはサブジェクト エリア全体のみを参照します。
「エージェントのランクは、オプションで、検索語または検索語のカテゴリに関連して計算することもできます。 たとえば、検索語 (または検索語の構造化されたコレクション、つまりクエリ) は、スポーツや医療の専門分野などのトピックに分類でき、エージェントは各トピックに関して異なるランクを持つことができます。」
オンライン コンテンツの作成者の信頼性
この Google の特許は 2008 年に最初に署名され、最短期間は 2029 年で、これまでのところ米国でのみ登録されています。
Justin Lawyer は、著者の特許評判スコアと同じ方法でそれを開発し、検索での使用に直接関係しています。
この特許には、上記の特許と同様の点が見出される。
私にとって、信頼と権威の観点から著者を評価するための最もエキサイティングな特許です。
この特許は、著者の信頼性をアルゴリズムで判断するために使用できるさまざまな要因を参照しています。
作成者の信頼度と評判スコアの影響下で、検索エンジンがドキュメントをランク付けする方法について説明します。
作成者は、コンテンツを公開するさまざまなトピックの数に応じて、複数の評価スコアを持つことができます。
著者の評判スコアは、発行者とは無関係です。
この特許でも、リンクが EEAT 評価の要因の 1 つとして挙げられています。 公開されたコンテンツへのリンクの数は、作成者の評判スコアに影響を与える可能性があります。
レピュテーション スコアの次のシグナルが挙げられます。
- 著者が主題分野でコンテンツを制作してきた期間。
- 作者の意識。
- ユーザーによる公開コンテンツの評価。
- 別の出版社が平均以上の評価で著者のコンテンツを公開した場合。
- 著者が公開したコンテンツの量。
- 著者が最後に出版したのは何年前ですか。
- 著者による同様のトピックに関する以前の出版物の評価。
特許からの評判スコアに関するその他の興味深い情報:
- 作成者は、コンテンツを公開するさまざまなトピックの数に応じて、複数の評価スコアを持つことができます。
- 著者の評判スコアは、発行者とは無関係です。
- 重複したコンテンツや抜粋が複数回公開された場合、評判スコアが低下する可能性があります。
- 公開されたコンテンツへのリンクの数は、評判スコアに影響を与える可能性があります。
さらに、この特許は著者の信頼性要因にも対応しています。 次の影響要因が挙げられます。
- 企業内での著者の職業または役割に関する検証済みの情報。 また、会社の信頼性も考慮されます。
- 公開されたコンテンツのトピックに対する職業の関連性。
- 著者の教育と訓練のレベル。
- 時間に基づく著者の経験。 著者がトピックについて発表している期間が長ければ長いほど、その著者の信頼性は高くなります。 著者/出版社の経験は、主題分野での最初の出版日を介して、Google のアルゴリズムで判断できます。
- トピックで公開されたコンテンツの数。 著者がトピックに関する多くの記事を公開している場合、その著者は専門家であり、一定の信頼性があると見なすことができます。
- 最後のリリースまでの経過時間。 著者がトピックについて最後に公開してからの時間が長いほど、このトピックの評判スコアが低下する可能性があります。 内容が最新であるほど高くなります。
- 賞およびベスト・オブ・リストにおける著者/出版社の言及。
ランク付けされた検索結果を再ランク付けするシステムおよび方法
この Google の特許は 2013 年に最初に署名され、2033 年までの最短期間があります。米国および世界中で登録されているため、Google が使用する可能性が高くなります。
この特許の発明者の中には、いくつかの EEAT 関連の Google 特許に関与した Chung Tin Kwok がいます。
この特許は、検索エンジンが、著者のコンテンツへの参照に加えて、著者のスコア付けにおいて、著者が主題文書コーパスに貢献できる割合を考慮する方法について説明しています。
「いくつかの実施形態では、それぞれのエンティティの元の著者スコアを決定することは、それぞれのエンティティに関連付けられていると識別された既知のコンテンツのインデックス内のコンテンツの複数の部分を識別することを含み、複数の部分の各部分は所定の量を表す既知のコンテンツのインデックス内のデータの、既知のコンテンツのインデックス内のコンテンツの部分の最初のインスタンスである複数の部分のパーセンテージを計算します。」
これは、引用スコアを含む、著者のスコアに基づく検索結果の再ランキングについて説明しています。 引用スコアは、著者のドキュメントへの参照数に基づいています。
著者のスコアリングのもう 1 つの基準は、トピック関連のドキュメントのコーパスに著者が貢献したコンテンツの割合です。
「ここで、それぞれのエンティティの著者スコアを決定することには、以下が含まれます。それぞれのエンティティの引用スコアを決定することです。ここで、引用スコアは、それぞれのエンティティに関連付けられたコンテンツが引用される頻度に対応します。元の著者スコアを決定します。ここで、元の著者スコアは、既知のコンテンツのインデックス内のコンテンツの最初のインスタンスである、それぞれのエンティティに関連付けられたコンテンツのパーセンテージに対応し、所定の関数を使用して引用スコアと元の著者スコアを組み合わせて生成します。著者のスコア。」
特許の目的は、「模倣者」を特定し、ランキングでコンテンツを格下げすることですが、著者の一般的な評価にも使用できます。
著者を評価するための重要な要素
上記の特許にリストされている著者評価の可能な要因に加えて、考慮すべきいくつかの要因があります (そのうちのいくつかは、私の記事「Google が EAT を評価する 14 の方法」で既に言及しました)。
- トピックに関するコンテンツの全体的な品質: ドメインや形式に関係なく、トピック全体として著者がコンテンツについて提供する品質は、EEAT の要因となる可能性があります。 このためのシグナルは、コンテンツ レベルでのユーザー シグナル、リンク、およびその他の品質シグナルです。
- PageRank または著者のコンテンツへの参照。
- コンテンツ (ポッドキャスト、ビデオ、Web サイト、PDF、書籍) における著者と関連するトピックまたは用語の共起。
- 関連するトピックまたは用語を含む検索クエリでの著者の共起。
作成者エンティティへの EEAT の適用
機械学習手法により、大規模な非構造化コンテンツからセマンティック構造を認識してマッピングすることが可能になります。
これにより、Google は以前にナレッジ グラフに表示されていたよりも多くのエンティティを認識して理解できるようになります。
その結果、コンテンツのソースはますます重要な役割を果たします。 EEAT は、ドキュメント、コンテンツ、ドメインを超えてアルゴリズム的に適用できます。
この概念は、コンテンツの作成者エンティティ (つまり、作成者とコンテンツに責任を持つ組織) も対象とすることができます。
今後数年間で、Google 検索に対する EEAT の影響がさらに大きくなると思います。 この要素は、個々のコンテンツの関連性の最適化と同じくらいランキングにとって重要です。
この記事で表明された意見はゲスト著者のものであり、必ずしも Search Engine Land ではありません。 スタッフの著者はここにリストされています。