
正規表現を使用して Google Search Console API を最大限に活用する方法
公開: 2022-11-02Google Search Console は、実際のユーザーによる貴重な検索データを Google から直接提供する素晴らしいツールです。 チャートとテーブルは使いやすいですが、データの大部分は UI からアクセスできません。
この隠されたデータに到達する唯一の方法は、API を使用して、利用可能な貴重な検索データをすべて抽出することです (方法がわかれば)。 これは正規表現で可能です。
SMX Advanced で講演した、PayPal の会社である Honey の製品成長担当副社長である Eric Wu 氏によると、正規表現を使用して Google Search Console API を最大化する方法は次のとおりです。
GSC による SEO の問題の診断
成長が停滞または低下している、またはコアアップデートがドロップしているWebサイトで作業していますか?
ほとんどの SEO 専門家は、このような問題を診断するために Google Search Console (GSC) を使用します。
(または、リソースが許せば、Ryte などの有料ツールを使用したり、独自のプラットフォームを構築したりすることもできます。)
SEO コミュニティにとって幸いなことに、次のような GSC 分析に役立つ Looker Studio ダッシュボード (以前の Google Data Studio) が不足することはありません。
- Aleyda Solis の無料ダッシュボード。GSC データを使用して、Google コア アップデートによる最近の潜在的なランキングの変化を簡単に特定します。
- Discover と Google ニュースのトラフィック データを取得するようになった Google の検索トラフィック モニタリング ダッシュボード。
- Hannah Butler の Search Console Explorer Studio。 (また、GSC データを実際に操作して簡単に洞察を得たい場合は、Butler の Search Console Explorer Sheet を使用できます。)
ダッシュボードを使用すると、SEO は GSC を使用して複数回クリックして必要なデータを取得するのではなく、さまざまな傾向の概要を確認できます。
しかし、エンタープライズ サイトを分析している場合、いくつかの障害に遭遇する可能性があります。
- 特に大規模なサイトを扱っている場合、Looker Studio と Google スプレッドシートはどちらも読み込みに時間がかかります。
- GSC のインターフェースには、1,000 行のエクスポート制限があります。
- GSC には大きなサンプリングの問題があります。 Similar.ai によると、エンタープライズ SEO チームは GSC キーワードの 90% を見逃しています。 データを抽出する方法を知っていれば、実際には 14 倍のキーワードを取得できます。
GSC のサンプリング問題の克服
Explorer for Search は、GSC 分析に使用できるもう 1 つのツールです。 Noah Learner と Two Octobers のチームによって、GSC の API を使用してデータ パイプラインが構築され、BigQuery にデータが出力され (基本的には Google スプレッドシートをバイパスして CSV ファイルをダウンロード)、データポータルで情報が視覚化されます。
これにより、ほぼすべてのデータに到達していると確信できます。
特に多数の異なるカテゴリを持つ大規模な e コマース サイトの場合は、GSC のサンプリングの問題による注意事項がまだあります。 GSC は、これらのディレクトリから入ってくるすべてのデータを表示するとは限りません。
Similar.ai チームは、GSC API から最大限のデータを取得するためにさまざまなテストを実施した後、GSC サンプリング ギャップを埋める方法を発見しました。
彼らは、GSC ダッシュボード内に別のプロファイルとしてサブディレクトリを追加することで、Google がその下位レベルでより多くの情報を提供するため、さらに多くのデータを抽出できることを発見しました。
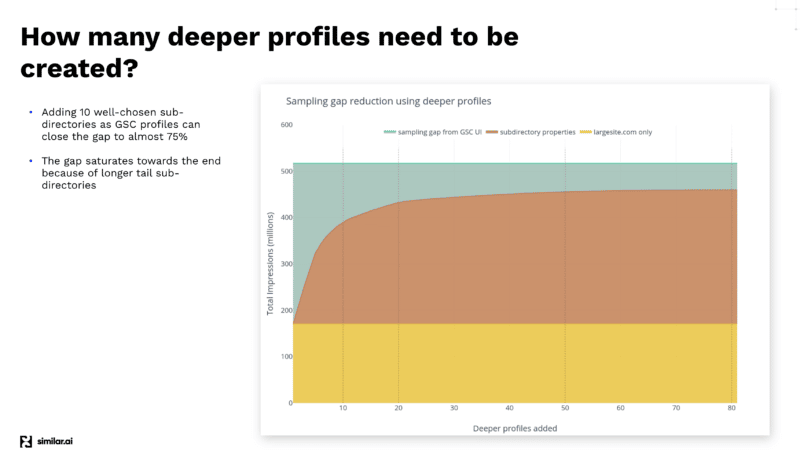
たとえば、example.com/televisions を見ていて、GSC プロファイルのサブディレクトリとして「televisions」を追加すると、Google はそのサブディレクトリ以下のキーワードとクリック情報のみを提供します。
これらのさまざまなサブディレクトリを多数追加することで、より多くの情報を抽出できます。
これでサンプリングの問題は解決しますが、正規表現を使用するとさらに多くのデータを取得できます。
正規表現を使用してより多くの GSC データを取得する
正規表現 (正規表現) は、データを理解するための強力なツールです。
2021 年 4 月、Google は GSC に正規表現のサポートを追加しました。これにより、SEO はオーガニック検索データを細かく分析する方法が増えました。
多くの場合、データは理解できなければ役に立ちません。 また、正規表現は、GSC の豊富なデータから実用的な洞察を引き出すのに役立ちます。
しかし、強力な正規表現であっても、学ぶのは難しい場合があります。
正規表現を理解し、深く掘り下げるのに最適な場所は、GitHub にある Google の公式ドキュメントです。 (Google はその製品で RE2 を使用していますが、これは正規表現のフレーバーです。)
正規表現はあらゆる種類の異なるプログラミング言語で利用できますが、.htaccess ファイルを変更している人にさえ、ほぼどこでも見つけることができます。
次のいくつかのセクションでは、GSC の正規表現を活用するための使用例を示します。
正規表現情報クエリ
GSC で実際の情報検索クエリを見るときは、通常、次のことを理解する必要があります。
- 人々は実際にどのようにあなたのサイトに来ていますか?
- 彼らはどのような質問を抽出していますか?
それらを一過性の観点から見ると、GSC 内では難しい場合があります。
あなたは常に「何を」「どのように」「なぜ」「いつ」という言葉を探しています。
正規表現を使用して情報クエリを抽出する手間を軽減する方法がいくつかあります。
Daniel K. Cheung は、クリックまたはインプレッションを獲得した「何を」、「どのように」、「なぜ」、「いつ」を含むすべてのクエリを表示する正規表現文字列を共有しました。
-
"what|how|why|when"
そして、Steve Toth によって共有されたこの正規表現文字列は、前の例を一段と引き上げています。
-
^(who|what|where|when|why|how)[" "]
この文字列は、「who」、「what」、「where」、「when」、「why」、「how」のいずれかで始まり、その後にスペースが続く質問ベースのクエリをキャプチャする場合に使用できます。
これは、質問を開始するあらゆる種類の単語を探しているときに使用するのに最適なリストです。
- ある、できる、できない、できた、できなかった、した、しなかった、した、しなかった、しないだった、なかった、何、いつ、どこ、誰、誰、誰、なぜ、意志、意志、意志、意志
これらすべてを正規表現形式にすると、次のようになります。
-
^(are|can|can't|could|couldn't|did|didn't|do|does|doesn't|how|if|is|isn't|should|shouldn't|was|wasn't|were|weren't|what|when|where|who|whom|whose|why|will|won't|would|wouldn't)\s
この 178 文字の文字列では:
- キャレット (
^) は、クエリがこの単語で始まる必要があることを示しています。 - 単語は、カンマではなくパイプ (
|) で区切られます。 - すべての単語は括弧で囲まれています。
- バックスラッシュと、単語の後にスペースを表す「s」(
\s) があります。
これは良いことですが、面倒なこともあります。
以下では、Wu が以前の単語のリストを単純化して、より正規表現に適した短いものにしました。これは、コピーと貼り付けに最適です。 このように維持することは、効率にも役立ちます。
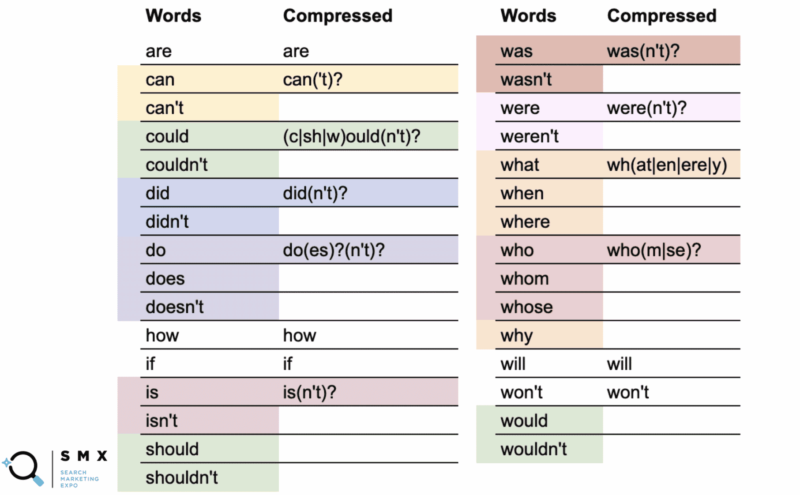
最初の列は通常の単語で、2 番目の列は圧縮された正規表現です。
たとえば、「can」という単語は、圧縮されたバージョンcan('t)?を使用します。 .
疑問符が示すのは、括弧内はオプションであることです。 圧縮された構文により、「できる」と「できない」の両方をカバーできます。
さらに興味深いことに、 (c|sh|w)ould(n't)?のように、単語の-ould部分が共通語基である場合、could/couldn't、should/shouldn't、および would/wouldn't でこれを行うことができます。 (c|sh|w)ould(n't)? . この短い文字列は、これら 6 つのケースすべてをカバーしています。
単語の長いリストを単純化すると、文字列が読みにくくなりましたが、すばらしいのは、正規表現フィールドにより適合し、コピーと貼り付けが簡単になることです。
-
^(are|can('t)?|(c|sh|w)ould(n't)?|did(n't)?|do(es)?(n't)?|how|if|is(n't)?|was(n't)?|were(n't)?|wh(at|en|ere|y)who(m|se)?|will|won't)\s
さらに一歩進めば、さらに圧縮できます。 この場合、Wu は文字数を 135 文字から 113 文字に減らしました。
-
^(are|can('t)?|how|if|wh(at|en|ere|y)|who(m|se)?|will|won't|((c|sh|w)ould|did(n't)?|do(es)?|was|is|were)(n't)?)\s
正規表現は非常に複雑になる可能性があります。 他の誰かから正規表現文字列を取得していて、何が何をしているのかを明確にしたい場合は、正規表現を使用して視覚化することができます。
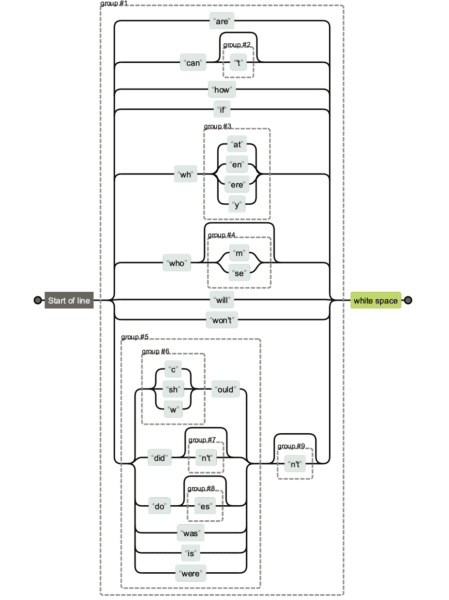
以下に、さまざまな正規表現文字列のバージョンの比較を示します。 最初のものを維持するのは簡単ですが、最後のものを維持して読むのは明らかに困難です。

しかし、正規表現が長い場合は特に、文字数が重要になることがあります。
Google Search Advocate の Daniel Waisberg によると、GSC の正規表現フィルターの制限は 4,096 文字です。
それはかなりのように思えます。 ただし、e コマース サイトがあり、ドメイン名、サブドメイン、または長いディレクトリを追加する必要がある場合は、その制限に達する可能性が高くなります。
正規表現ブランドのクエリ
GSC で正規表現の文字制限に達し始める可能性のある別の例は、ブランド クエリに使用する場合です。
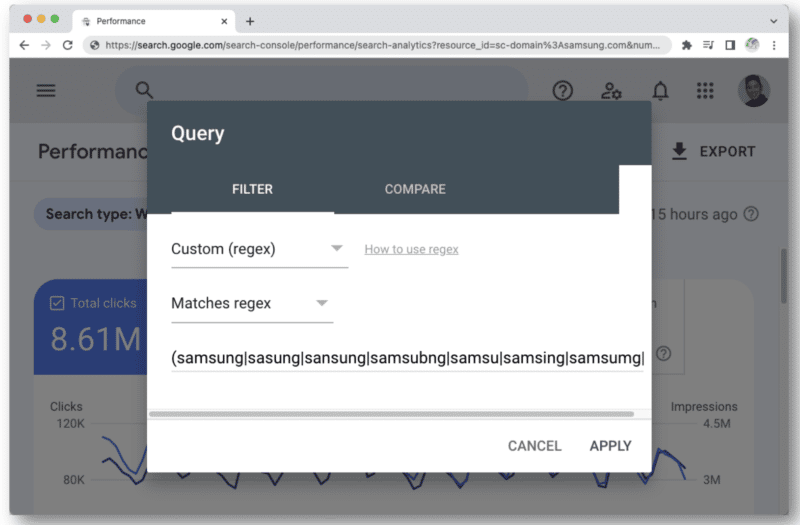
人が入力する可能性のあるブランド名のさまざまなタイプのスペルミスについて考えると、すぐにその 4,096 文字に遭遇します。 例えば:
- aamaung, damsung, mamsang, samsung, samaung, samsung, samesung, sameung, samgsung, samgung, samsang, samsaung, samsgu, samshgg, samshng, samsing, samsnug, samssung, samsu, samsuag, samsubg, samsubng, samsug, samsumg, samsumng 、サムスン g、サムスン b、サムスン、サムスン、サムスン、サムスン …
ここで、正規表現を理解することが役立ちます。 この文字列を使用すると、スペルミスとともにブランド名「samsung」をキャプチャできます。
-
(s+|a|d|z)[az\s]{1,4}m?[az\s]{1,6}(m|u|n|g|t|h|b|v)
多くの場合、人々は単語の中間部分のスペルを間違えます。 しかし、一般的に、それらは適切な形式と長さを取得し、この方法で構文にアプローチできます。
ブランド クエリのスペルミスについては、次の点を考慮してください。
- ブランド クエリを構成する主な文字。
- 子音。
- ハード子音を囲む文字。

赤字は、ブランド名を入力する際に一般的に見落とされない難しい子音です。 これらは、その特定のブランドを構成する主要な文字です。 「samsung」の場合、先頭に「s」、中間に「m」、最後に「n」と「g」が続きます。
キーボード上の主要な子音を囲む青い文字は、よくタイプミスするものです。 例では、「s」の周りに「a」、「d」、「z」が表示されます。 (各国のキーボードではレイアウトが異なりますが、コンセプトは同じです。)

上記の正規表現文字列は、「samsung」の可能なバリエーションをすべてキャプチャします。
ここでのもう 1 つの重要なトリックは[az\s]{1,4}にあります。
正規表現形式では、これは基本的に「任意の文字「a」から「z」、またはスペースを 1 ~ 4 回一致させたい」という意味です。
これにより、ブランド クエリの途中で発生する可能性のある奇妙なスペルミスがすべて捕捉されます。つまり、同じキーを複数回押したり、誤ってスペースを押したりする可能性があります。
さらに、ブランド名には一定の長さがあります (「samsung」は 7 文字です)。 人々はおそらく 20 ~ 50 文字を入力することはないでしょう。
したがって、この正規表現では、「samsung」の「s」と「m」の間で、誰かが 1 ~ 4 文字をタイプミスすると推測しています。 そして、最後の「m」から「g」まで、スペースを含めて 1 ~ 6 文字のタイプミスをします。
これらすべてを追加すると、ブランド化されたクエリのさまざまなバリエーションを包括的にキャプチャできます。
もう 1 つの注意点は、ブランド名がクエリのさまざまな部分に表示される可能性があることです。

そのため、ブランド名自体が確実に取得されるようにする必要があります。 次のいずれかである必要があります。
- クエリの開始時。
- クエリの途中 (つまり、スペースで囲まれています)。
- またはクエリの最後に。
これの正規表現は次のとおりです。
-
(^|\s)(s+|a|d|z)[az\s]{1,4}m?[az\s]{1,6}(m|u|n|g|t|h|b|v)(\s|$)
これにより、ブランド名「samsung」が最初、中間、または最後にあるすべてのクエリがキャプチャされます。
- 文字列の開始 =
^ - スペースで囲む =
\s - 文字列の終わり =
$
JC Chouinard の投稿、正規表現 (RegEx) in Google Search Console では、正規表現の例についてさらに深く掘り下げています。
正規表現と GSC API の動作
Wu 氏と彼のチームが、コア アップデート後にトラフィックの低下に遭遇したクライアントと協力したとき、正規表現が役に立ちました。
e コマース サイトのさまざまな問題を調べたところ、問題が一部の製品詳細ページにあることがわかりました。
GSC での分析のためにページタイプをセグメント化する必要がありました。 しかし、米国製品と海外製品では URL 構造が異なるため、これは複雑な作業でした。

サイトの国際的な製品 URL には言語と国コードが含まれていましたが、米国の製品 URL には含まれていませんでした。
製品のスラッグ、カテゴリ、およびサブカテゴリには文字とダッシュが存在するため、正規表現構文を使用することさえ困難でした。 さらに、米国のページのみをキャプチャするために、国際製品の URL を除外する必要がありました。
すべての米国製品のランディング ページと詳細ページ (i18n ページではない) を取得するために、次の正規表現文字列を考え出しました。
インクルード: /([^/]+/){1,2}p?
除外: /[a-zA-Z]{2}|[a-zA-Z]{2}-[a-zA-Z]{2}/
内訳は次のとおりです。

チームは、カテゴリ、サブカテゴリ、およびすべての製品を一致させたいと考えていたため、次のものが含まれていました。
- スラッシュ以外の任意の文字 =
[^/]+ - 1 つまたは 2 つのディレクトリ =
/){1,2} - 製品スラッグ =
p?が続く場合があります。
キャレット ( ^ ) は通常、文字列の開始を意味します。 しかし、( [^/]のように) 括弧内にある場合は、否定 (つまり、「このボックス内には何もない」) を示します。
この文字列/([^/]+/){1,2}p? は、「スラッシュ以外の任意の数の文字が必要で、スラッシュ (ディレクトリを示す) の前にあり、その後に文字 'p' (製品スラッグのプレフィックス) が続く場合がある」という意味です。
同時に、チームは、文字とダッシュを含む国と言語の組み合わせを一致させたくなかったため、次のものを除外しました。
- 任意の 2 文字のディレクトリ =
[a-zA-Z]{2} - 2 文字 + 2 文字の言語と国の組み合わせ =
[a-zA-Z]{2}-[a-zA-Z]{2}
すべての言語と国コードに一致する正規表現を独自に作成するのは、すべての組み合わせが考えられるため面倒です。そのため、情報クエリの場合のようにアプローチすることはできませんでした (組み合わせのすべてのタイプが除外されました)。
しかし、これらの正規表現文字列を作成した後でさえ、問題がありました。
Google Search Console には、正規表現文字列を貼り付けるフィールドが 1 つしかありません。 正規表現に一致するか、正規表現に一致しないかのいずれかを選択する必要があります。両方を同時に使用することはできません。
これは、正規表現文字列を結合できる GSC API が役立つ場所です。
Google Search Console API のドキュメントには、今すぐ試すリンクがあります。
クリックするとコンソールが開き、サイトを選択して Web ビューから API リクエストを行うことができます。
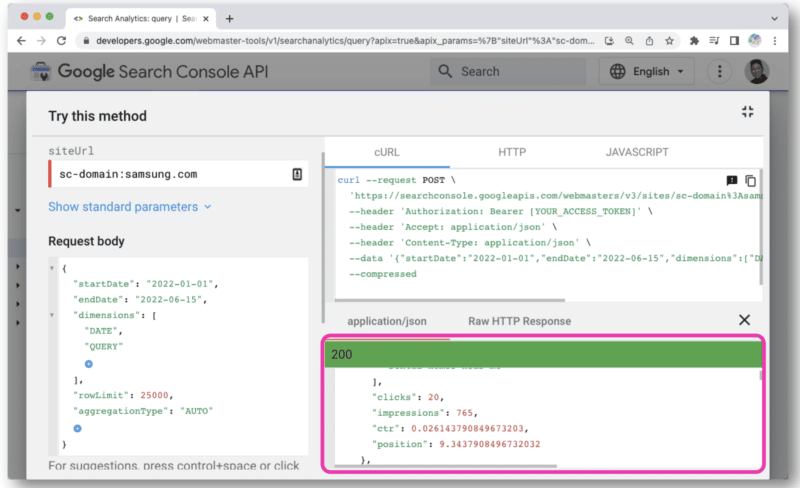
しかし、API クエリをより適切に管理するために、Wu は、デスクトップまたは Paw (Mac ネイティブ) で Postman を使用することをお勧めします。
Postman を使用すると、クエリを作成し、後で使用できるように保存できます。 また、他のサイトにアクセスできる場合は、毎回新しいクエリを作成する必要はありません。 サイト名を変数で変更し、複数のリクエストを作成するだけです。
一方、Paw は、全体を見て利用するのがはるかに簡単です。
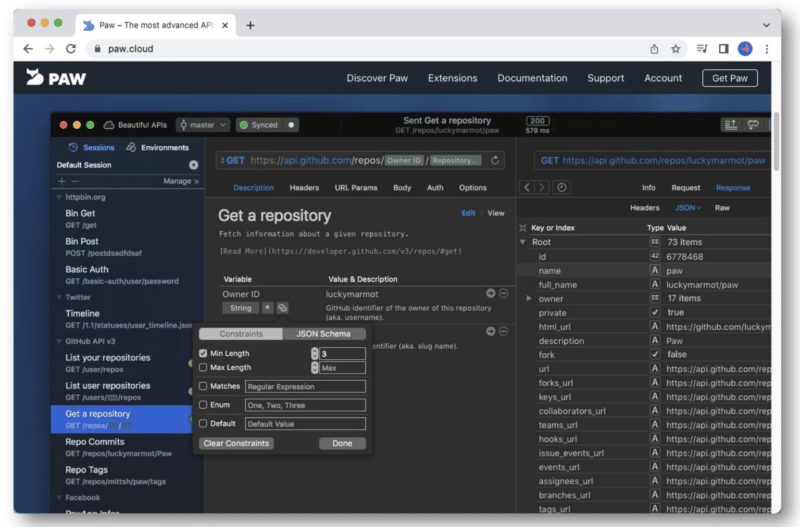
API にアクセスするには、API キーを取得する必要があります。 (Chouinard の役立つチュートリアルはこちらです。)
この情報を取得すると、クライアント ID とクライアント シークレットが得られます。これを Postman または Paw 内の OAuth 2.0 認証に追加します。
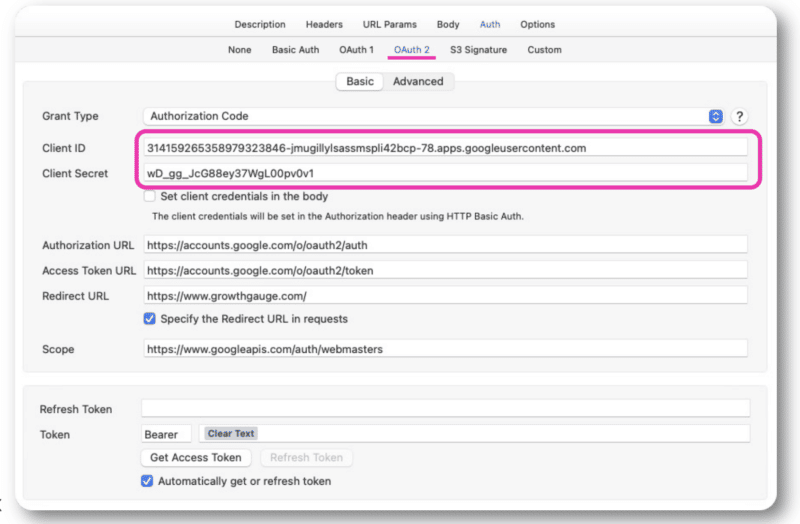
そこから、通常のアカウントでサインインできるようになります。
Wu は主に、Paw の正規表現文字列を使用して GSC API リクエストを作成しました。 クエリはインターフェイスの途中で入力されます。
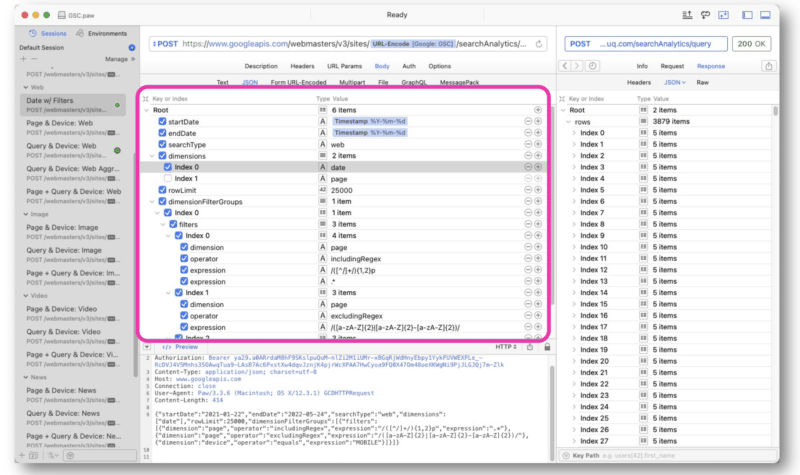
Google からの応答は、GSC API Web ビューの応答と似ています。 その後、データをエクスポートして処理できます。
データは JSON 形式であるため、情報が乱雑で読みにくい場合があります。

このために、JQ と呼ばれる無料のオープンソース コマンドライン JSON プロセッサを使用して、情報をきれいに印刷できます。

スプレッドシートにデータを入力するまで、データはそれほど役に立ちません。 Paw から JQ にエクスポートしたファイルをパイプします。 それを開いて、各行を反復処理します。各要素を保存して、CSV に出力できるようにします。
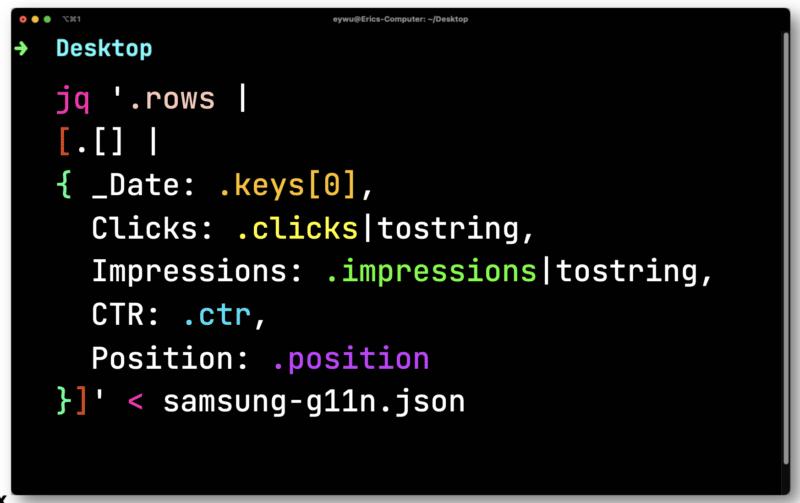
ここでは、浮動小数点数 (小数点以下の桁数) であるクリック数とインプレッション数を変換する必要があります。 どちらも CSV と互換性のある文字列に変換する必要があります。
JQ は、次のはるかに単純な形式を出力します。
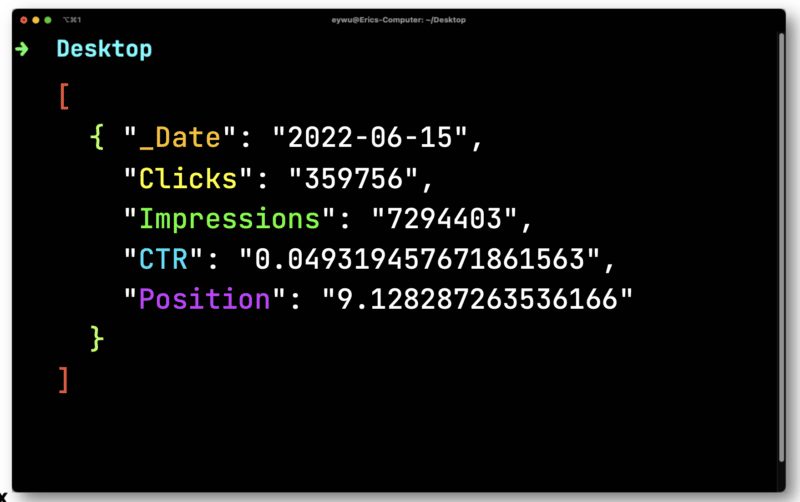
次に、Dasel を使用してこの形式を取得し、CSV にします。
そして、これが最終結果です。
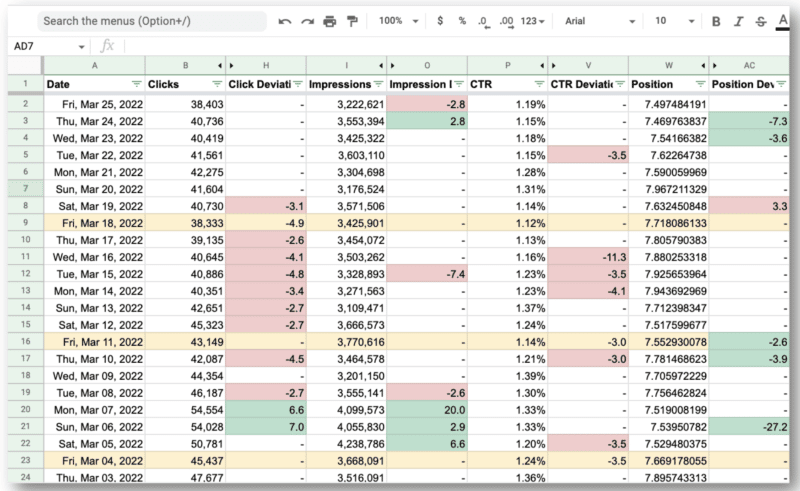
Wu のチームにとって驚くべきことは、Google Search Console API と正規表現を使用して次のことができたことです。
- すべての国際的なクエリを除外し、主要な問題を抱えていた米国だけを調べます。
- サイトに問題があった日を特定します。
視聴: Google Search Console API を最大限に活用する
以下は、Wu の SMX Advanced プレゼンテーションの完全なビデオです。