
Web サイトとエンティティの EAT を改善する方法
公開: 2022-11-29専門性、権威性、信頼性 (EAT) の概念は、近年だけでなく、キーワードや Web サイトのランキングにおいて中心的な役割を果たしています。
SMX Next での講演で、Google の検索担当バイス プレジデントである Hyung-Jin Kim 氏は、Google が 10 年以上にわたってランキングの EAT 原則を実装してきたことを発表しました。
なぜEATはそれほど重要なのですか?
SMX 2022 の基調講演で、Kim 氏は次のように述べています。
「EAT は、個々のサイトを評価する方法のテンプレートです。 すべてのクエリとすべての結果に対してそれを行います。 それは、私たちが行うすべてのことに浸透しています。」
このステートメントから、EAT が YMYL ページだけでなく、すべてのトピックとキーワードで重要であることは明らかです。 今日、EAT は、Google のランキング アルゴリズムのさまざまな領域に影響を与えているようです。
数年間、Google は検索結果の誤った情報について大きなプレッシャーにさらされてきました。 これは、2019 年 2 月にミュンヘン セキュリティ カンファレンスで発表されたホワイト ペーパー「Google が偽情報と戦う方法」で強調されています。
Google は、検索システムを最適化して、ユーザーのコンテキストに応じてそれぞれの検索クエリに優れたコンテンツを提供し、最も信頼できるソースを検討したいと考えています。 ここでは、品質評価者が特別な役割を果たします。
「私たちの評価プロセスの重要な部分は、私たちのランキング システムと提案された改善がうまく機能しているかどうかについて、日常のユーザーからフィードバックを得ることです。 しかし、「よく働く」とはどういう意味ですか? 私たちは、システムが優れたコンテンツをどのように表示するかを詳細に説明する評価ガイドラインを公開しています。」
EAT基準による評価は、品質評価者にとって非常に重要です。
「彼らは、そのクエリが何を求めているかを理解していることに基づいて、それらのページが情報のニーズを満たしているかどうかを評価し、クエリのトピックに関してその情報源がどれほど権威的で信頼できるように見えるかなどを考慮します. 専門知識、権威性、信頼性などを評価するために、「EAT」と呼ばれることもありますが、評価者は情報源に関する評判調査を行うよう求められます。」
ドキュメントの関連性とソースの品質を区別する必要があります。 Google のランキング マジックは 2 つの領域で行われます。
- ドキュメント レベルでの関連性スコア。
- ドメインまたはエンティティ レベルでの EAT による品質評価。 (より深く掘り下げる:エンティティーと EAT: 権威と信頼におけるエンティティーの役割)
これは、ドキュメントおよびドメイン レベルでの品質スコアに関するさまざまな Google の広報担当者の声明を見れば明らかです。
SMX West 2016 のプレゼンテーション「Google の仕組み: Google ランキング エンジニアのストーリー」で、Paul Haahr は次のように述べています。
「私たちが抱えていたもう 1 つの問題は品質の問題で、これは特にひどいものでした。 2008 年、2009 年から 2011 年にかけてのことだと思います。低品質のコンテンツについて多くの苦情が寄せられていましたが、それは正しかったのです。
同じように低品質のものを見ていましたが、関連性指標は上昇し続けていました。これは、低品質のページが非常に関連性が高い可能性があるためです.
これは基本的に、私たちの世界観におけるコンテンツ形式の定義であるため、私たちはうまくやっていると思いました.
私たちの数字は、私たちがうまくやっていると言っていますが、ひどいユーザーエクスペリエンスを提供していて、必要なものを測定していないことがわかりました. そのため、私たちが最終的に行ったことは、品質の問題に直接関係する明示的な品質メトリックを定義することでした. それは関連性と同じではありません…
また、関連するシグナルとは別に品質関連のシグナルを開発し、それらを個別に改善することができました。 したがって、メトリクスが何かを見逃した場合、ランキング エンジニアがしなければならないことは、レーティング ガイドラインを修正するか、新しいメトリクスを開発することです。」
(この引用は、品質評価ガイドラインと EAT に関する講演の一部からのものです。)
Haahr は次のようにも述べています。
- 信頼性はEATの最も重要な部分です。
- 一般に、コンテンツおよび Web サイトの品質評価ガイドラインで言及されている、悪いコンテンツと良いコンテンツおよび Web サイトの基準は、ランキング システムがどのように機能するかのベンチマーク パターンです。
2016 年、John Mueller は Google Webmaster Hangout で次のように述べました。
「ほとんどの場合、ページのコンテンツとコンテキストを個別に理解し、検索で適切に表示されるように努めています。 ただし、ウェブサイト全体を見ている場合がいくつかあります。
たとえば、新しいページを Web サイトに追加し、そのページを以前に見たことがない場合、そこにあるコンテンツとコンテキストがわかりません。その場合、これがどのような種類の Web サイトであるかを理解することは、よりよく理解するのに役立ちます。検索でこの新しいページから始めるべきです。
つまり、ランキングに関しては両方が少しあるということです。 それは個々のページだけでなく、サイト全体でもあります。
おそらく、Google がすべての Web サイトに対して保持しているこの 1 つのサイト全体の番号があるという誤解があると思いますが、そうではありません。 Google ではさまざまな要因を検討しており、サイト全体の品質スコアを 1 つだけではありません。
そのため、さまざまなシグナルをまとめて調べようとしています。その中にはページごとのものもあれば、サイトごとのものもありますが、ウェブサイトのこれら 5 つのページから 1 つの数字が得られるわけではありません。 」
ここで Mueller は、従来の関連性評価に加えて、Web サイト全体のテーマのコンテキストに関連する評価基準もあると強調しています。
これは、ウェブサイト全体をテーマ別に分類および評価するために、Google が考慮に入れるシグナルがあることを意味します。 EATレーティングに近いことは明らかです。
EAT と品質評価者のガイドラインに関するさまざまな箇所は、前述の Google ホワイト ペーパーに記載されています。
「私たちは毎日検索を改善し続けています。 2017 年だけでも、Google は 20 万回以上の実験を実施し、その結果、検索に約 2,400 の変更が加えられました。 これらの変更はそれぞれ、ランキング システムの目標を定義し、アルゴリズムの継続的な評価を提供する外部評価者を導く、公開されている検索品質評価者ガイドラインに沿っていることを確認するためにテストされています。」
「システムはウェブページの真実性について主観的な判断を下すのではなく、ユーザーや他のウェブサイトがウェブページがカバーするトピックに関する専門知識、信頼性、または権威性をどのように評価しているかに相関する測定可能なシグナルに焦点を当てています。」
「ランキングアルゴリズムは、偽情報との戦いにおいて重要なツールです。 ランキングは、当社のアルゴリズムが最も権威があり信頼できると判断した関連情報を、信頼性の低い情報よりも高くします。 これらの評価は、ウェブサイトの各ウェブページによって異なる場合があり、ユーザーの検索に直接関係しています。 たとえば、全国規模の報道機関の記事は、現在の出来事に関する検索では信頼できると見なされますが、ガーデニングに関する検索では信頼性が低くなる可能性があります。」
「私たちのランキングシステムは、特定のコンテンツの意図や事実の正確さを特定するものではありません. ただし、専門知識、権威、信頼性の高い指標を持つサイトを特定するように特別に設計されています。」
「これらの「 YMYL」ページでは、信頼性と安全性の最も厳しい基準で運営することをユーザーが期待していると想定しています。 そのため、ユーザーのクエリが「YMYL」トピックに関連していることをアルゴリズムが検出した場合、ランキング システムでは、応答として提示するページの信頼性、専門知識、または信頼性に関する理解などの要素をより重視します。」
次のステートメントは特に興味深いもので、特定のコンテキストや関係するイベントにおいて、従来の関連性要因と比較して EAT がいかに強力であるかが明らかになります。
「この種のコンテンツの可視性を低下させるために、危機が進行している間、最新性や完全な単語の一致などの要因よりも権威を優先するようにシステムを設計しました。」
EAT の影響は、近年のさまざまな Google コア アップデートで見ることができます。
EAT はランキングに影響しますが、ランキング要素ではありません
ここ数年、EAT がランキングに影響を与えるかどうか、もしそうならどのように影響するかを中心に多くの議論が行われました。 ほとんどすべての SEO は、関連性スコアリングを補足する概念または一種のレイヤーであることに同意しています。
Google は、EAT がランキング要素ではないことを確認しています。 EATスコアもありません。
EAT はさまざまなシグナルまたは基準で構成され、Google のランキング アルゴリズムが専門知識、権威、および信頼 (品質) をどのように決定するかの青写真として機能します。
ただし、Google は、すべての検索クエリと結果にアルゴリズムで適用される評価についても言及しています。 つまり、評価の基礎として使用できるシグナルまたはデータが存在する必要があります。
Google は、検索評価者の手動評価を、自己学習ランキング アルゴリズム (キーワード: 教師あり機械学習) のトレーニング データとして使用して、高品質のコンテンツとソースのパターンを識別します。
これにより、Google は品質評価ガイドラインの EAT 評価基準に近づきました。
検索評価者によって高または低と評価されたコンテンツとソースが同じ特定のパターンを繰り返し示し、これらのパターン プロパティの頻度がしきい値に達した場合、Google は将来のランキングでこれらの基準/信号を考慮することもできます。
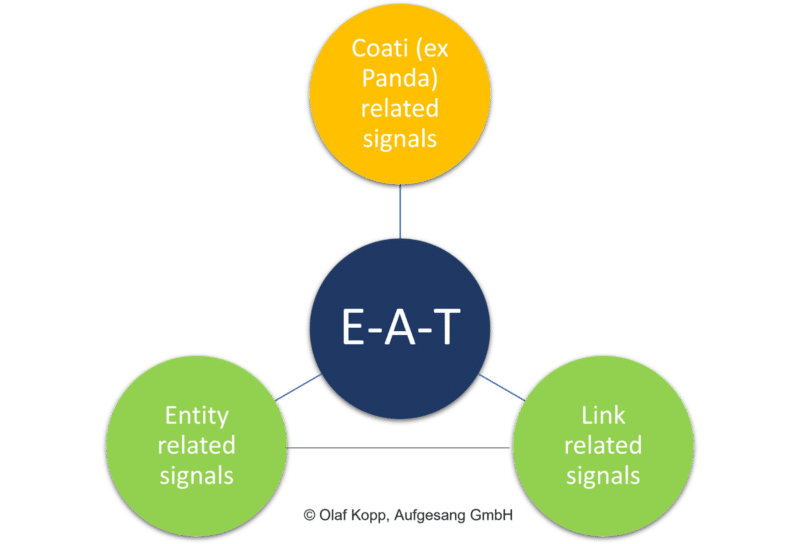
私の意見では、EAT はさまざまな起源で構成されています。
- エンティティ ベースの評価。
- Coati (ex-Panda) ベースの評価。
- リンクベースの評価。
ドメイン、出版社、著者などの情報源を評価するために、Google はナレッジ グラフやナレッジ ボールトなどのエンティティ ベースのインデックスにアクセスします。 エンティティを主題のコンテキストに持ち込むことができ、エンティティの接続を記録できます。
個々のドキュメントとドメイン全体に関連するコンテンツの品質を評価するために、Google は現在、Panda または Coati の実証済みのアルゴリズムに頼ることができます。
PageRank は、Google によって公式に確認された EAT の唯一のシグナルです。 Google は 20 年以上にわたり、リンクを使用して信頼と権威を評価してきました。
Google の特許と公式声明に基づいて、アルゴリズム EAT 評価の具体的なシグナルをこのインフォグラフィックにまとめました。
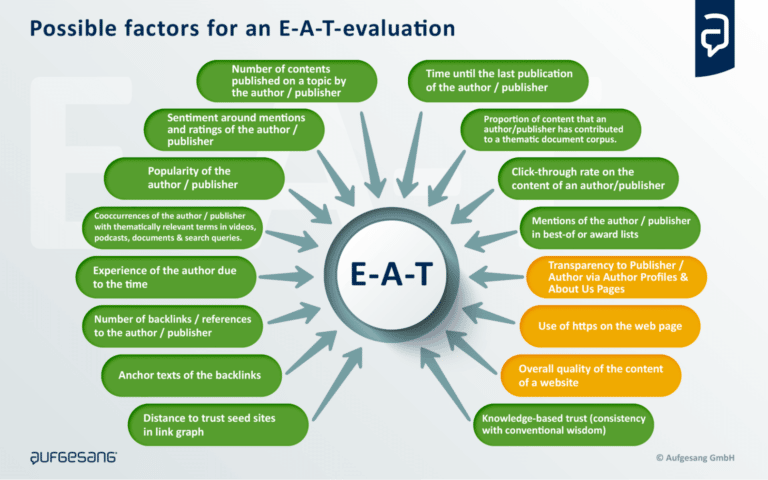
SEO は、EAT にプラスの影響を与えるために、これらの可能性のあるシグナルを区別する必要があります。
オンページ
あなた自身のウェブサイトから来るシグナル。 これは、コンテンツ全体と詳細についてです。
ページ外
外部ソースからの信号。 これは、Google がクロールできる外部コンテンツ、動画、音声、または検索クエリである可能性があります。
ここでは、テーマに関連する用語に関連する会社、出版社、著者、またはドメインの名前からのリンクと共起が特に重要です。
これらの共起が頻繁に現れるほど、主なエンティティがトピックおよび関連するキーワード クラスターと関係がある可能性が高くなります。
これらの共起は、Google によって識別可能またはクロール可能である必要があります。 そうして初めて、Google に認識され、EAT の概念に組み込まれます。 オンライン テキストでの共起に加えて、検索クエリでの共起も Google のソースです。
感情
Google は自然言語処理を使用して、人、製品、および企業エンティティの周囲の雰囲気を分析します。

Google、Yelp、またはその他のプラットフォームからのレビューは、評価を残すオプションとともにここで使用できます.
Google の特許は、「レビュー可能なエンティティのランキング シグナルとしてのセンチメント検出」など、これに対処しています。
これらの調査結果を通じて、SEOse は EAT シグナルにプラスの影響を与えるための具体的な手段を導き出すことができます。
検索マーケティング担当者が頼りにしている毎日のニュースレターを入手してください。
条件を参照してください。
EATを改善する15の方法
Google は EAT により、最終的には、マーケティング担当者が何世紀にもわたって人々の心にあるメッセージと組み合わせてブランドを確立するために使用してきた「テーマ別のブランド ポジショニング」を適応させようとしています。
特定のテーマのコンテキストで人やプロバイダーを認識する頻度が高いほど、その製品、サービス プロバイダー、および媒体に対する信頼が高まります。
さらに、このエンティティが次の場合、権限が増加します。
- 他の市場参加者よりも、テーマのコンテキストでより頻繁に言及されています。
- 他の信頼できる権威主義的な情報源から積極的に参照されています。
この繰り返しにより、脳内のニューラルネットワークが再訓練されます。 私たちは、テーマ別の権威と信頼性を備えたブランドとして認識されています。
その結果、Google のニューラル ネットワークは誰が権威であるかを学習し、1 つまたは複数のトピックについて信頼できるかどうかも学習します。 これは特に、認識、検討、選好の段階での共起に当てはまります。
トピックのカスタマー ジャーニーで自分自身を位置付けるほど、Google が関連付けるキーワード クラスターが広くなります。 このリンクが描かれている場合、あなたはあなた自身のコンテンツで関連するセットに属しています.
これらの共起は、たとえば次の方法で生成できます。
- 適切なオンページ コンテンツ。
- 適切な内部リンク。
- 適切なオフページ コンテンツ。
- 外部/着信リンク、アンカー テキスト、および検索パターンに影響を与えるリンクの環境。
特にオフページのシグナルに関しては、クリエイティブな余裕がたくさんあります。 しかし、ここで共起を引き起こす典型的なSEO対策もありません。
その結果、SEO の責任者はますますテクノロジー、編集、マーケティング、PR の間のインターフェースになりつつあります。
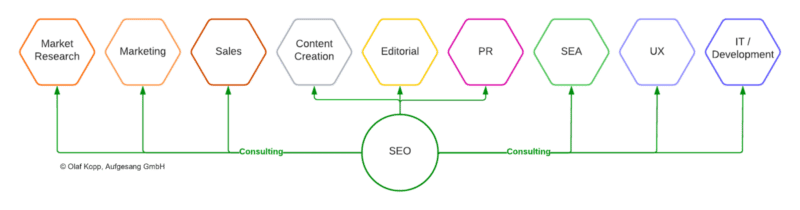
以下は、EAT を最適化するために考えられる具体的な対策の概要です。
1. 自分のウェブサイトに十分なトピック関連のコンテンツを作成する
ウェブサイト内にセマンティック トピック ワールドを構築することで、Google はあなたがトピックに関する深い知識と専門知識を持っていることを示します。
2. 意味的に適切なコンテンツをメイン コンテンツにリンクする
セマンティック トピックの世界を構築するときは、個々のコンテンツを意味のある形で相互にリンクする必要があります。
ユーザージャーニーの可能性も考慮に入れる必要があります。 消費者が次にまたは追加で興味を持っていることは何ですか?
発信リンクは、他の信頼できる情報源を参照していることをユーザーと Google に示す場合に役立ちます。
3. 著者、査読者、共著者、影響力のある著名な専門家と協力する
「認識済み」とは、次の方法で Google によってオンラインで専門家として既に認識されていることを意味します。
- オンライン出版物。
- アマゾンの著者プロフィール。
- 自分のブログやウェブサイト。
- ソーシャル メディアのプロフィール。
- 大学のウェブサイトのプロフィール。
- もっと。
著者が、それぞれのテーマのコンテキストで Google がクロールできる参考文献を示すことが重要です。 これは特に YMYL トピックに推奨されます。
トピックに関する Web で見つけられるコンテンツを以前から公開している著者は、トピック オントロジーのエンティティとして知られている可能性が高いため、推奨されます。
4. トピックに関するコンテンツのシェアを拡大する
企業または著者がトピックに関して公開するコンテンツが多いほど、そのトピックに関連するドキュメント コーパスのシェアが大きくなります。
これにより、トピックに関するテーマの権威が高まります。 このコンテンツがあなたのウェブサイトで公開されているか、他のメディアで公開されているかは問題ではありません。 重要なのは、それらが Google によって記録できることです。
たとえば、トピックに関連する独自のコンテンツの割合は、他の関連する権威あるメディアのゲスト記事を通じて、Web サイトを超えて拡大できます。 権威があればあるほど良い。
コンテンツのシェアを増やすその他の方法には、次のようなものがあります。
- テーマに沿った適切なゲスト投稿を作成し、このコンテンツを自分のウェブサイトやソーシャル メディアのプロフィールにリンクします。
- 関連トピックに関するインタビューの手配。
- 専門イベントでの講演。
- 講演者としてウェビナーに参加。
5. 簡単な言葉で文章を書く
Google は自然言語処理を使用してコンテンツを理解し、エンティティのデータをマイニングします。
単純な文の構造は、複雑な文よりも Google にとって理解しやすいものです。 また、エンティティを名前で呼び、人称代名詞を限られた範囲でのみ使用する必要があります。 読みやすさを考慮して、論理的な段落と小見出しを付けてコンテンツを作成する必要があります。
6. コンテンツ作成に TF-IDF 分析を使用する
TF-IDF 分析用のツールを使用して、トピックのコンテンツに表示される意味的に関連するサブエンティティを特定できます。 このような用語を使用すると、専門知識が示されます。
7. 表面的で内容の薄いコンテンツを避ける
ドメインに内容の薄いコンテンツや表面的なコンテンツが多数存在すると、Google がウェブサイトの品質を低下させる可能性があります。 代わりに、内容の薄いコンテンツや表面的なコンテンツを削除または統合してください。
8.知識のギャップを埋める
オンラインで目にするほとんどのコンテンツは、数百または数千の他のコンテンツで既に言及されている既存の情報のキュレーションまたはコピーです。
真の専門知識は、トピックに新しい視点と側面を追加することによって達成されます。
9. コンセンサスを遵守する
Google はある科学論文で、知識に基づく信頼を、一般的な意見と情報のコンセンサスに基づいてコンテンツ ソースを評価する方法であると説明しています。
これは、特に YMYL トピック (つまり、医療トピック) の場合、最初の検索結果でコンテンツをランク付けするために重要です。
10. 信頼できる情報源へのリンクを含む事実に基づくコンテンツを作成する
情報と声明は事実で裏付けられ、信頼できる情報源への適切なリンクで裏付けられる必要があります。
これは、YMYL トピックでは特に重要です。
11. 著者、出版社、およびその他のコンテンツとコミットメントについて透明性を保つ
著者ボックスは、Google の直接的なランキング シグナルではありませんが、これまで知られていなかった著者の実体について詳しく調べるのに役立ちます。
インプリントと「About us」ページも利点です。 また、次へのリンクを含めます。
- コミットメント。
- コンテンツ。
- 著者、講演者、協会会員としてのプロフィール。
- ソーシャル メディアのプロフィール。
エンティティ名は、表現へのリンク テキストとして有利です。 スキーマ マークアップなどの構造化データも推奨されます。
12. 広告バナーや推奨広告を多用しない
Web サイトの使用に影響を与える攻撃的な広告 (つまり、Outbrain または Taboola 広告) は、信頼スコアの低下につながる可能性があります。
13. マーケティングとコミュニケーションを通じて、自分の Web サイトの外で共起を作成する
EAT では、次のようなテーマでブランドとしての地位を確立することが重要です。
- Google がそれらをより迅速かつ簡単に割り当てることができるように、Web サイトから主題に関連する専門の出版物にリンクします。
- テーマに関連する環境からのリンクを構築します。
- Google での検索パターンに影響を与えたり、検索クエリで適切な同時発生を作成したりするためのオフライン広告 (テレビ広告、チラシ、広告)。 これは純粋なイメージ広告ではなく、対象分野でのポジショニングに貢献する広告であることに注意してください。
- サプライヤーまたはパートナーと協力して、適切な共起を確保する。
- 適切な共起の PR キャンペーンを作成します。 (純粋なイメージPRはありません。)
- あなた自身のエンティティの周りのソーシャルネットワークでバズを生成します.
14. 自分のウェブサイトでユーザーシグナルを最適化する
各主要キーワードの検索意図を分析します。 コンテンツの目的は常に検索意図と一致する必要があります。
15. 素晴らしいレビューを作成する
人々は、公の場で企業との否定的な経験を報告する傾向があります。
これは EAT にとっても問題になる可能性があります。会社の周囲に否定的な感情が生じる可能性があるからです。 そのため、満足した顧客にポジティブな体験を共有してもらう必要があります。
この記事で表明された意見はゲスト著者のものであり、必ずしも Search Engine Land ではありません。 スタッフの著者はここにリストされています。