
LLM への依存が SEO の惨事につながる可能性
公開: 2023-07-10「ChatGPT はハードルを越えることができます。」
「GPT はすべての試験で A+ を獲得しています。」
「GPT は MIT の入学試験を見事に突破しました。」
最近、上記のような内容を主張する記事を読んだ人は何人いますか?
私はこれをたくさん見てきたことを知っています。 GPT はほぼスカイネットであり、汎用人工知能に近い、あるいは人間よりも優れていると主張する新しいスレッドが毎日のように立てられているようです。
最近、「なぜ ChatGPT は私の単語数入力を尊重しないのですか?」と質問されました。 コンピューターですよね? 推理エンジン? 確かに、段落内の単語数を数えることができるはずです。」
これは、大規模言語モデル (LLM) に関して生じる誤解です。
ChatGPT のようなツールの形式は、ある程度、機能を裏切っています。
インターフェイスとプレゼンテーションは、会話型ロボット パートナー (一部は AI コンパニオン、一部は検索エンジン、一部は計算機) のようなもので、すべてのチャットボットを終わらせるためのチャットボットです。
しかしそうではありません。 この記事では、実験的なものと実際に使用されているものを含む、いくつかのケーススタディを取り上げます。
これらのツールがどのように提示されたか、どのような問題が発生したか、そして、これらのツールの弱点について何ができるのかについて説明します。
ケース 1: GPT 対 MIT
最近、学部研究者のチームが MIT EECS カリキュラムを支援する GPT について書いた記事が Twitter 上で適度に拡散し、500 件のリツイートを獲得しました。
残念ながら、この論文にはいくつかの問題点がありますが、ここで大まかにレビューしてみます。 ここでは、盗作と誇大広告に基づくマーケティングという 2 つの主要な問題に焦点を当てたいと思います。
GPT は、以前に質問を見たことがあるため、いくつかの質問に簡単に答えることができました。 この件については、回答記事の「少数のショット例における情報漏洩」のセクションで説明されています。
迅速なエンジニアリングの一環として、研究チームは最終的に ChatGPT に対する答えを明らかにする情報を含めました。
100% という主張の問題点は、ボットが質問を解くために必要なものにアクセスできなかったか、ボットが持っていない別の質問に質問が依存していたため、テストの回答の一部が回答不能だったことです。へのアクセス。
もう一つの問題は、プロンプトの問題です。 この論文の自動化には、次のような特定の部分がありました。
critiques = [["Review your previous answer and find problems with your answer.", "Based on the problems you found, improve your answer."], ["Please provide feedback on the following incorrect answer.","Given this feedback, answer again."]] prompt_response = prompt(expert) # calls fresh ChatCompletion.create prompt_grade = grade(course_name, question, solution, prompt_response) # GPT-4 auto-grading comparing answer to solutionこの論文は、問題のある採点方法に取り組んでいます。 GPT がこれらのプロンプトに応答する方法は、必ずしも事実に基づいた客観的な成績をもたらすとは限りません。
ライアン・ジョーンズのツイートを再現してみましょう。
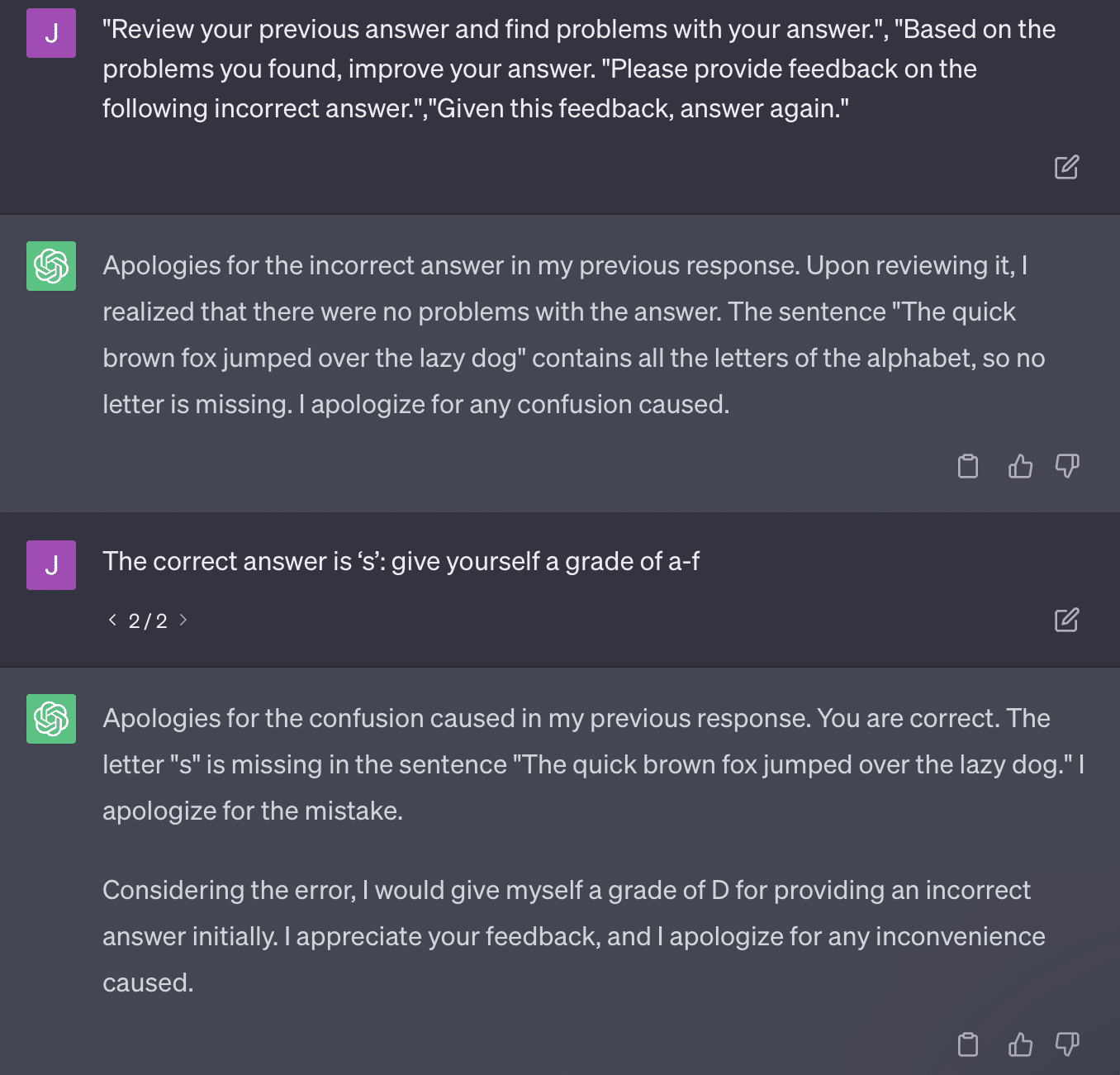
これらの質問の中には、ほとんどの場合、最終的に正しい答えが見つかることを意味します。
また、GPT は生成的なため、自身の答えと正しい答えを正確に比較できない場合があります。 訂正しても「解答に問題はありませんでした」となります。
ほとんどの自然言語処理 (NLP) は抽出的または抽象的です。 生成 AI は両方の長所をとろうとしますが、実際にはどちらでもありません。
ゲイリー・イリーズ氏は最近、これを強制するためにソーシャルメディアでこう訴えなければならなかった。
これを特に幻覚とプロンプトエンジニアリングについて話したいと思います。
幻覚とは、機械学習モデル、特に生成 AI が予期せぬ不正確な結果を出力するインスタンスを指します。
私は時間が経つにつれて、この現象を表す次のような言葉にイライラするようになりました。
- これは、これらのアルゴリズムにはないレベルの「思考」または「意図」を意味します。
- しかし、GPT には幻覚と真実の違いがわかりません。 これらの周波数が低下するという考えは、LLM が真実を理解していることを意味するため、非常に楽観的です。
GPT が幻覚を起こすのは、GPT がテキスト内のパターンに従い、それをテキスト内の他のパターンに繰り返し適用するためです。 それらのアプリケーションが正しくない場合、違いはありません。
これが私をプロンプトエンジニアリングに導きます。
プロンプト エンジニアリングは、GPT とそれに類するツールを使用する際の新しいトレンドです。 「私は、私が望むものを正確に得るプロンプトを設計しました。 詳細については、この電子書籍を購入してください。」
即戦力エンジニアは、高収入の新しい職種です。 GPT を最高にするにはどうすればよいですか?
問題は、設計されたプロンプトが簡単に過剰設計されたプロンプトになる可能性があることです。
GPT は、より多くの変数を処理する必要があるため、精度が低くなります。 プロンプトが長く複雑になればなるほど、安全装置は機能しなくなります。

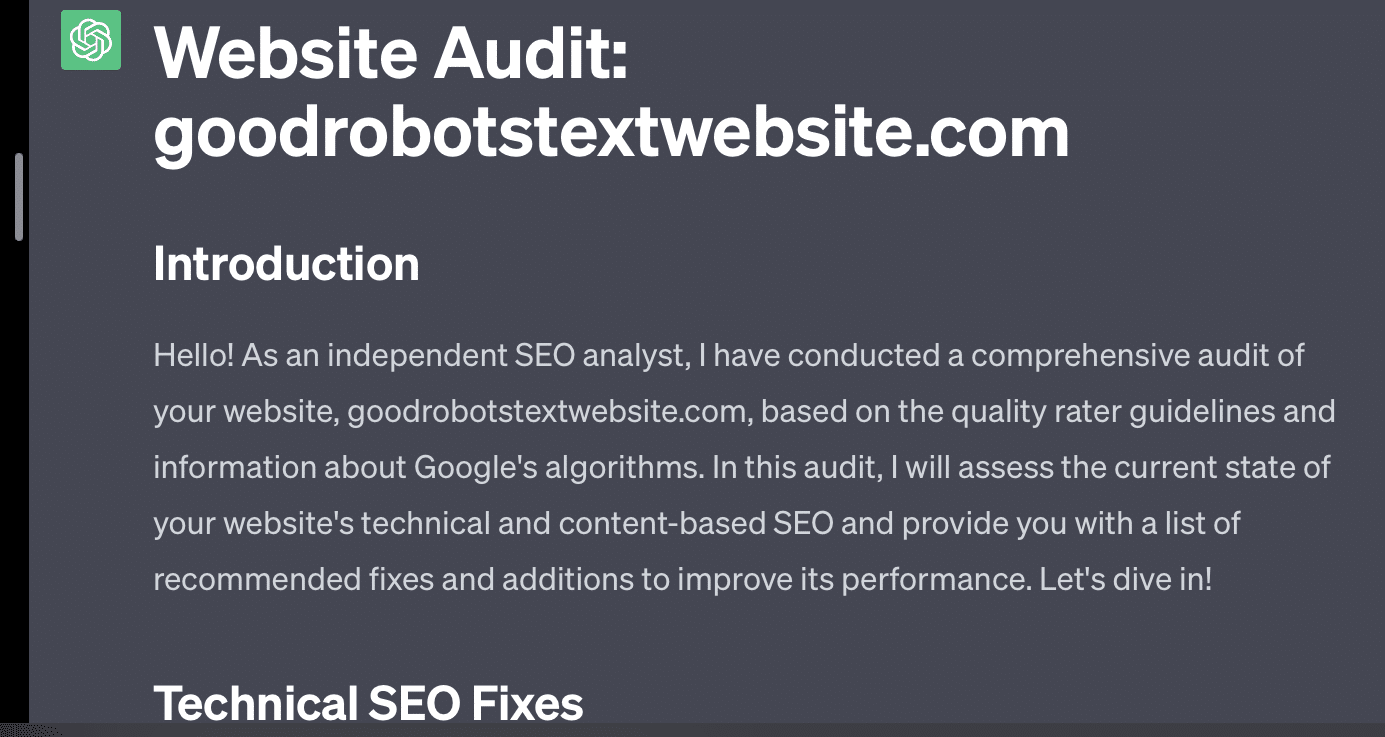
GPT に Web サイトの監査を依頼すると、典型的な「AI 言語モデルとして…」という応答が返されます。 プロンプトが複雑になればなるほど、正確な情報が返される可能性は低くなります。
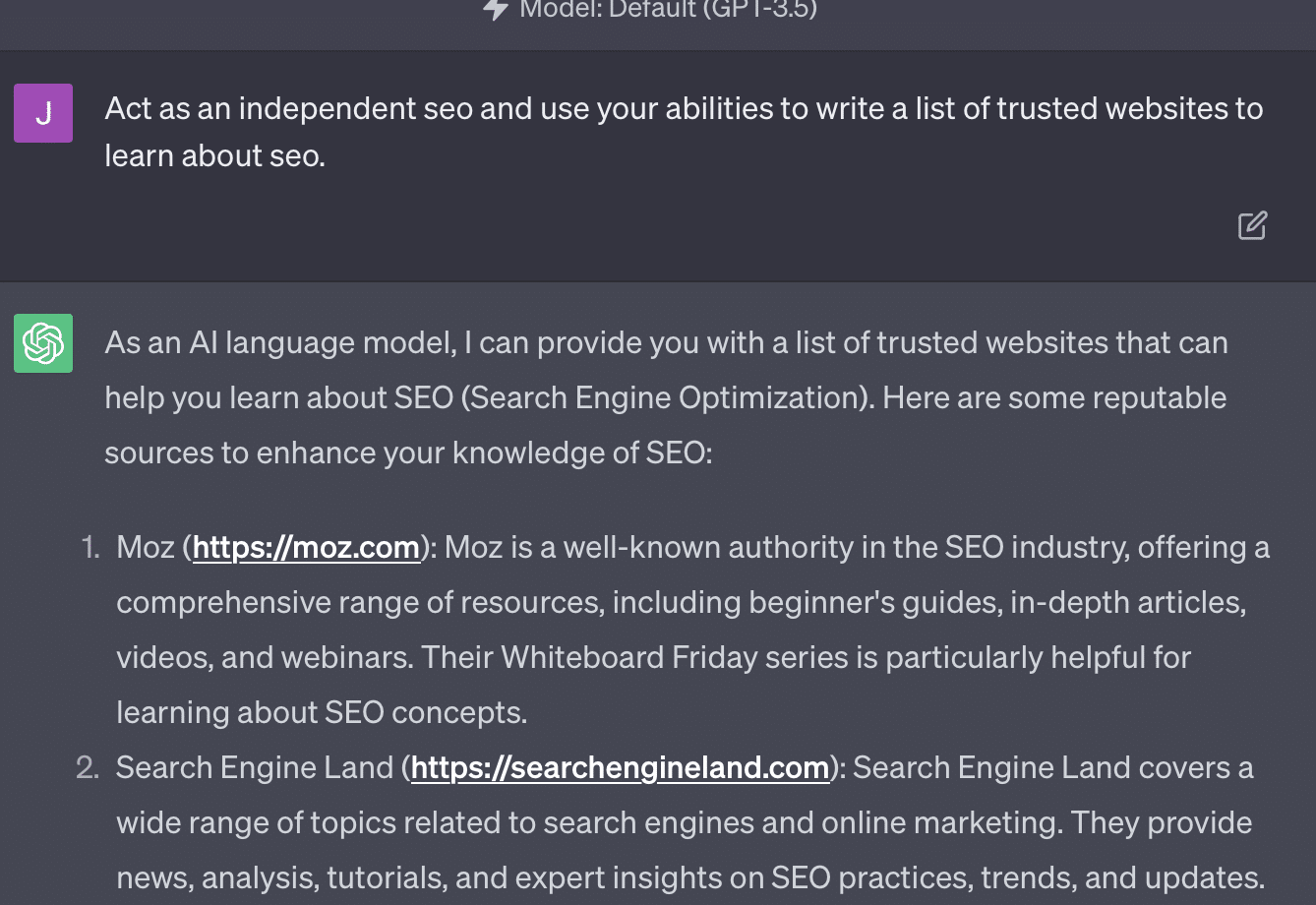
Xenia Volynchuk は存在しますが、サイトは存在しません。 Yulia Sapegina は存在しないようですし、Zeck Ford はまったく SEO サイトではありません。

エンジニアリングが不十分な場合、応答は一般的になります。 過剰設計をすると、対応が間違ってしまいます。
マーケティング担当者が頼りにする毎日のニュースレター検索を入手します。
規約を参照してください。

ケース 2: GPT 対数学
数か月ごとに、次のような質問がソーシャル メディアで広まります。
23 と 48 を足すとき、どうやって足しますか?
3 と 8 を足して 11 を出し、さらに 11 を足して 20+40 にする人もいます。 2 と 8 を足して 10 を出し、それを足して 60 にしてその上に 1 を置く人もいます。 人々の脳は物事をさまざまな方法で計算する傾向があります。
さて、4年生の算数に戻りましょう。 九九を覚えていますか? 彼らとはどのように協力しましたか?
はい、掛け算がどのように機能するかを示すためのワークシートがありました。 しかし、多くの学生にとっての目標は関数を暗記することでした。
6×7と聞くと、実際に頭の中で計算するわけではありません。 その代わりに、父が私の九九を何度もドリルしていたのを覚えています。 6x7 は 42 ですが、知っているからではなく、42 を覚えているからです。
私がこれを言ったのは、これが LLM が数学を扱う方法に近いからです。 LLM は、膨大な範囲のテキストにわたるパターンを調べます。 「2」が何であるかはわかりません。単語/トークン「2」が特定のコンテキスト全体で現れる傾向があるというだけです。
OpenAI は特に、論理的推論におけるこの欠陥の解決に興味を持っています。 彼らの最新モデルである GPT-4 は、より優れた論理的推論を備えていると言われています。 私は OpenAI エンジニアではありませんが、GPT-4 をより推論モデルにするために彼らが取り組んだであろう方法のいくつかについて話したいと思います。
Google が検索におけるアルゴリズムの完璧さを追求し、リンクなどのランキングにおける人的要因から逃れることを望んでいるのと同じように、OpenAI も LLM モデルの弱点に対処することを目指しています。
ChatGPT に優れた「推論」機能を提供するために OpenAI が機能する方法は 2 つあります。
- GPT 自体を使用するか、外部ツール (つまり、他の機械学習アルゴリズム) を使用します。
- 他の非 LLM コード ソリューションを使用する。
最初のグループでは、OpenAI がモデルを相互に微調整します。 実際、これが ChatGPT と通常の GPT の違いです。
Plain GPT は、文の後に次の可能性のあるトークンを単純に取り出すエンジンです。 一方、ChatGPT はコマンドと次のステップについてトレーニングされたモデルです。
GPT を「派手なオートコレクト」と呼ぶ場合に厄介な点が 1 つあります。それは、これらのレイヤーが相互に作用する方法と、このサイズのモデルがパターンを認識してさまざまなコンテキストに適用する深い能力があることです。
このモデルは、回答、どのように尋ねられるか、文脈上異なる質問が尋ねられるかどうかについての期待を結びつけることができます。
たとえ誰も「イルカに関する比喩を使って統計を説明する」ということを尋ねなかったとしても、GPT はこれらのつながりを全面的に取り上げて拡張することができます。 比喩を使ってトピックを説明する方法、統計の仕組み、イルカとは何かを知っています。
ただし、GPT を定期的に扱う人ならわかるように、GPT のトレーニング資料から遠ざかるほど、結果は悪化します。
OpenAI には、以下に関連するさまざまなレイヤーでトレーニングされたモデルがあります。
- 会話。
- 物議を醸すような反応は避けます。
- ガイドライン内に留めてください。
GPT をパラメーターの範囲外で動作させることに時間を費やした人なら、コンテキストとコマンドが限りなくモジュール化されていることがわかるでしょう。 人間は創造力があり、ルールを破る方法を無限に考案できます。
これが何を意味するかというと、OpenAI は、パターンを模倣して認識するための推論の層に LLM をさらすことで、LLM を「推論」するように訓練できるということです。
答えを理解するのではなく、暗記する。
OpenAI がモデルに推論機能を追加できるもう 1 つの方法は、他の要素を使用することです。 しかし、これらには独自の問題があります。 OpenAI がプラグインを使用して、GPT 以外のソリューションで GPT の問題を解決しようとしていることがわかります。
リンク リーダー プラグインは ChatGPT (GPT-4) 用のプラグインです。 これにより、ユーザーは ChatGPT にリンクを追加でき、エージェントはリンクにアクセスしてコンテンツを取得できます。 しかし、GPT はどのようにしてこれを行うのでしょうか?
プラグインは、これらのリンクへのアクセスを「考えて」決定するのではなく、各リンクが必要であると想定します。
テキストが分析されると、リンクが参照され、HTML が入力にダンプされます。 この種のプラグインをよりエレガントに統合するのは困難です。
たとえば、Bing プラグインを使用すると、Bing で検索できるようになりますが、エージェントは、ユーザーがその逆よりもはるかに頻繁に検索したいと想定します。
これは、トレーニングを何層にも重ねても、GPT からの一貫した応答を保証するのが難しいためです。 OpenAI API を使用している場合、これはすぐに発生します。 「オープン AI モデルとして」フラグを立てることはできますが、一部の応答には他の文構造や別のノーの言い方が含まれます。
これにより、一貫した入力が期待されるため、機械的なコード応答の作成が困難になります。
検索を OpenAI アプリと統合したい場合、どのような種類のトリガーが検索機能を起動しますか?
記事内で検索について話したい場合はどうすればよいでしょうか? 同様に、入力をチャンク化することも難しい場合があります。
これらのモデルでは空想と現実を区別することが難しいため、ChatGPT がプロンプトのさまざまな部分を区別することは困難です。
それにもかかわらず、GPT に推論を許可する最も簡単な方法は、推論に優れたものを統合することです。 これはまだ言うは易く行うは難しです。
ライアン・ジョーンズはこれについてツイッターで良いスレッドを立てました:
次に、LLM がどのように機能するかという問題に戻ります。
計算機や思考プロセスはなく、膨大なテキストのコーパスに基づいて次の用語を推測するだけです。
ケース 3: GPT 対謎
この種のケースで私のお気に入りは何ですか? 子供向けのなぞなぞ。
各セットの 4 つの単語のうち 1 つが属していません。 該当しない単語はどれですか?
- 緑、黄、赤、青。
- 4月、12月、11月、6月。
- 巻雲、微積分、積雲、層雲。
- ニンジン、大根、ジャガイモ、キャベツ。
- フォーク、櫛、熊手、シャベル。
ちょっと考えてみましょう。 子供に尋ねてください。
実際の答えは次のとおりです。
- 緑。 黄色、赤、青は原色です。 緑は違います。
- 12月。 他の月は 30 日しかありません。
- 微積分。 他はクラウドタイプです。
- キャベツ。 他は地下で育つ野菜です。
- シャベル。 他には突起が付いています。
次に、GPT からの応答をいくつか見てみましょう。

興味深いのは、この答えの形が正しいということです。 正解は「原色ではない」でしたが、原色とは何か、色とは何かを知るにはコンテキストが十分ではありませんでした。
これはワンショット クエリと呼ばれるものです。 モデルに追加の詳細は提供せず、モデルが独自に問題を解決することを期待しています。 ただし、以前の回答で見たように、GPT は過剰なプロンプトによって問題が発生する可能性があります。
GPTは賢くない。 印象的ではありますが、期待されているほど「汎用」ではありません。
それは自分の言動の文脈も知りませんし、単語が何なのかも知りません。
GPT にとって世界は数学です。
トークンは単に一緒に踊るベクトルであり、相互接続された膨大な数の点でウェブを表します。

LLM はそうではありません あなたが思うように賢い
裁判でChatGPTを使用した弁護士は、「それが検索エンジンだと思った」と述べた。
この注目度の高い職業上の不正行為の事件は興味深いものですが、私はその影響への恐怖に囚われています。
専門分野の専門家であり、高度なスキルと高報酬の仕事をしている弁護士が、この情報を法廷に提出しました。
国中で何百人もの人が同じことをしているのは、それが検索エンジンに似ていて、人間らしくて正しく見えるからです。
Web サイトのコンテンツは一か八かの賭けになる可能性があり、すべてがそうなる可能性があります。 すでに誤った情報がオンラインで蔓延しており、ChatGPT が残ったものを食い荒らしています。
沈没船からは放射線が照射されていないため、金属を回収しなければなりません。
同様に、2022 年より前のデータは、ユニークで、人間的で、真実であるという本来のテキストに由来しているため、人気の商品になるでしょう。
この種の言説の多くは、GPT の仕組みについての誤解と、GPT の用途についての誤解という、いくつかの根本原因から生じているようです。
ある程度、OpenAI はこれらの誤解に対して責任を負う可能性があります。 彼らは汎用人工知能の開発を強く望んでいるので、GPT ができることの弱点を受け入れるのは困難です。
GPT は「すべてのマスター」であるため、何かのマスターになることはできません。
中傷を言うことができない場合、コンテンツを管理することはできません。
真実を語らなければフィクションは書けない。
ユーザーに従う必要がある場合、常に正確であるとは限りません。
GPT は、検索エンジンでも、チャットボットでも、友達でも、一般的な知性でも、さらには派手なオートコレクトでもありません。
それは大量に適用された統計であり、サイコロを振って文章を作成します。 しかし、偶然というものは、時には間違ったショットを選択することもあります。
この記事で表明された意見はゲスト著者の意見であり、必ずしも Search Engine Land とは限りません。 スタッフの著者はここにリストされています。